Python数据挖掘之基础分类模型_支持向量机(SVM)
文章目录
- 一、什么是支持向量机(SVM)?
- 二、SVM的起源
- 1. 历史背景
- 2. 发展过程
- 三、SVM的基本原理
- 1. 线性SVM
- 一、什么是线性SVM?
- 二、线性SVM的数学原理(简要)
- 三、用Python实现线性SVM示意图
- 四、示例代码
- 五、输出效果说明
- 六、总结
- 2. 支持向量和边界
- 3. 优化问题
- 四、线性与非线性SVM
- 1. 线性SVM
- 2. 非线性SVM
- 一、什么是非线性SVM?
- 二、非线性SVM的核心思想
- 三、常用的核函数
- 四、用Python示例演示非线性SVM(以RBF核为例)
- 1. 说明
- 2. 代码示例
- 3. 说明
- 五、总结
- 六、可调参数的作用
- 五、核函数的作用
- 一、核函数的作用和原理
- 1. 核函数的基本作用
- 2. 核函数实现的核心思想
- 二、常用的核函数类型
- 三、示例:用Python演示不同核函数的效果
- 1. 安装必要的库
- 2. Python代码示例
- 3. 代码说明
- 四、总结
- 六、SVM的应用领域
- 七、优缺点
- 1. 优点
- 2. 缺点
- 八、总结:为什么学习SVM?
- 案例
- 完整的支持向量机(SVM)分类案例
- 一、导入依赖库
- 二、生成数据集
- 三、划分训练集和测试集
- 四、创建和训练SVM模型
- 1. 试用不同核函数
- 五、评估模型
- 六、可视化决策边界
- 七、调优参数以获得更好效果
- 1. 使用GridSearchCV调参
- 2. 作用:
- **总结**
一、什么是支持向量机(SVM)?
支持向量机是一种监督学习算法,主要用于分类(如将数据分为两个类别)和回归(预测连续值)任务。它的核心思想是:在数据中找到一个“最佳的分割界线”或“超平面”,使得不同类别的样本被尽可能清楚地划分开,而同时最大化两个类别之间的“间隔”或“边界”。换句话说,SVM试图找出一种分类方式,不仅能够正确分割所有训练数据,还能在未知数据上拥有较好的泛化能力。
二、SVM的起源
1. 历史背景
- Vladimir Vapnik与其团队:在20世纪60年代至80年代,Vladimir Vapnik 和其同事们致力于统计学习理论的研究,他们试图理解什么样的学习器才能具有良好的泛化能力。
- 最初的思想:早期的算法难以处理复杂、高维的数据,研究人员开始寻找一种更为强大和理论支持的分类方法。
- 正式提出:到了1990年代,Vapnik等人正式提出了支持向量机这一概念。此后,SVM逐渐演变成一种在实际中表现优异的机器学习模型。
2. 发展过程
- 早期限制:最初的SVM主要适用于线性可分的数据集。
- 非线性扩展:引入核函数,使得SVM可以处理非线性边界的问题。
- 广泛应用:随着计算能力的提升和优化算法的出现,SVM被广泛应用于各种领域,从文本到图像,再到生物医药。
三、SVM的基本原理
1. 线性SVM
- 目标:找出一个超平面(在二维空间就是一条直线)将两个类别的数据点尽可能分隔开。
- 最大间隔原则:选择那些使得最近的样本点(支持向量)到超平面的距离(即边界)最大的超平面。这种“最大化间隔”的策略,有助于提高模型对新数据的泛化能力。
- 数学表示:假设超平面定义为:w⋅x+b=0w \cdot x + b = 0w⋅x+b=0,其中 www 是法向量,bbb 是偏置。目标就是找到使得所有正样本满足 w⋅x+b≥1w \cdot x + b \geq 1w⋅x+b≥1,所有负样本满足 w⋅x+b≤−1w \cdot x + b \leq -1w⋅x+b≤−1 的参数。
一、什么是线性SVM?
定义:
线性支持向量机(Linear SVM)是一种通过寻找一个线性超平面(在二维空间中是直线)来分割不同类别数据的分类模型。其目标是最大化“边界”或“间隔”,即支持向量到超平面的距离,以实现较好的分类性能和泛化能力。
基本思想:
- 给定两个类别的数据点,线性SVM试图找到一条直线(二维)或超平面(多维)能最有效地将它们分开。
- 在两侧找到离超平面最近的点,叫支持向量。
- 超平面的决策边界应使这些支持向量到它的距离(边界宽度)最大。
二、线性SVM的数学原理(简要)
在二维情况下,决策边界是直线:
w⋅x+b=0w \cdot x + b = 0 w⋅x+b=0
- 其中 www 是法向量(线的方向),bbb 是偏置。
- 对于正类样本 xix_ixi,约束条件:
w⋅xi+b≥1w \cdot x_i + b \geq 1 w⋅xi+b≥1
- 对于负类样本 xjx_jxj,约束条件:
w⋅xj+b≤−1w \cdot x_j + b \leq -1 w⋅xj+b≤−1
- 这样,超平面两侧的“边界超平面”定义为:
w⋅x+b=±1w \cdot x + b = \pm 1 w⋅x+b=±1
- 目标:最大化两边界之间的距离(边界宽度),即最大化:
2∥w∥\frac{2}{\|w\|} ∥w∥2
- 优化问题:
minw,b12∥w∥2\min_{w, b} \frac{1}{2} \|w\|^2 w,bmin21∥w∥2
在满足:
yi(w⋅xi+b)≥1y_i (w \cdot x_i + b) \geq 1 yi(w⋅xi+b)≥1
这是一个凸二次规划问题。
三、用Python实现线性SVM示意图
我将用scikit-learn库的SVC类(支持向量机分类器)来创建一个线性SVM候选模型,然后用Matplotlib绘制数据点、决策边界、支持向量和边界。
需要准备的内容:
- 安装
scikit-learn和matplotlib:
pip install scikit-learn matplotlib numpy
四、示例代码
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm# 生成线性可分的两个类别的数据
np.random.seed(42)
X = np.vstack((np.random.randn(20, 2) * 0.5 + [2, 2],np.random.randn(20, 2) * 0.5 + [-2, -2]
))
y = np.hstack((np.ones(20), -np.ones(20)))# 创建线性SVM模型
clf = svm.SVC(kernel='linear', C=1)
clf.fit(X, y)# 获取支持向量
support_vectors = clf.support_vectors_# 画出数据点
plt.scatter(X[y==1, 0], X[y==1, 1], color='blue', label='Positive class')
plt.scatter(X[y==-1, 0], X[y==-1, 1], color='red', label='Negative class')# 画支持向量
plt.scatter(support_vectors[:, 0], support_vectors[:, 1],s=100, linewidth=1, facecolors='none', edgecolors='k', label='Support Vectors')# 绘制决策边界和边界线
ax = plt.gca()
xlim = ax.get_xlim()
ylim = ax.get_ylim()# 创建网格以绘制决策边界
xx = np.linspace(xlim[0], xlim[1], 200)
yy = np.linspace(ylim[0], ylim[1], 200)
YY, XX = np.meshgrid(yy, xx)
xy = np.vstack([XX.ravel(), YY.ravel()]).T
Z = clf.decision_function(xy).reshape(XX.shape)# 绘制决策边界
contour = ax.contour(XX, YY, Z, levels=[-1, 0, 1], colors='k', linestyles=['--', '-', '--'])# 获取支持向量的系数
w = clf.coef_[0]
b = clf.intercept_[0]# 计算边界线和两个边界线(支持向量到决策边界的线)
# 决策边界:w·x + b = 0
# 支持边界:w·x + b = ±1
# 画出这些线
x_pts = np.array(ax.get_xlim())
# 支持边界线
for level in [-1, 0, 1]:y_pts = -(w[0] * x_pts + b + level) / w[1]linestyle = '--' if level != 0 else '-'plt.plot(x_pts, y_pts, color='k', linestyle=linestyle)plt.legend()
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('Linear SVM Decision Boundary')
plt.show()
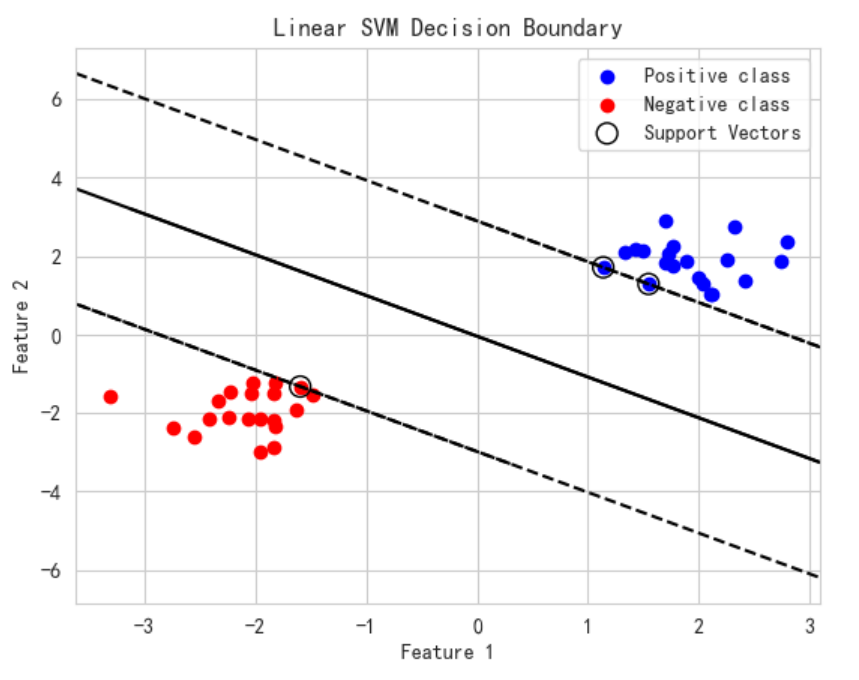
五、输出效果说明
- 数据点:蓝色和红色代表两类数据。
- 支持向量:用空心黑色圈圈标出,支持向量是支持超平面决策的关键数据点。
- 决策边界:中间实线,代表模型区分两类的直线。
- 边界线:虚线代表边界(距离超平面最近的支持向量所在线)。
- 边界距离(间隔):最大化的边界,使支持向量尽可能远离决策面,增强模型的稳定性。
六、总结
- 线性SVM通过最大化边界距离,找到最佳的直线(超平面)将两类数据分开。
- 利用支持向量定义超平面位置。
- 核函数可扩展到非线性问题,但这里仅介绍线性版。
2. 支持向量和边界
- 支持向量:在训练中,距离超平面最近的那些数据点叫支持向量,它们起到了决定超平面位置的关键作用。
- 边界:由支持向量定义的两条平行边界,分别是距离超平面最近的正负样本的最远距离。
3. 优化问题
- 目标:最大化边界距离,也就是最大化 2∣∣w∣∣\frac{2}{||w||}∣∣w∣∣2,同时保证所有点都被正确分类(满足约束条件)。
- 解决方法:通过二次规划算法求解,得到最优的 w,bw, bw,b,从而确定分类超平面。
四、线性与非线性SVM
1. 线性SVM
- 适合数据线性可分的场景,即数据可以用一条直线(二维)或一个超平面(多维)完美分割。
- 实现简单,速度快,且理论基础完整。
- 例子:两类点可以用一条直线清楚划开。
2. 非线性SVM
- 许多实际问题,数据点无法用一条直线或超平面划分。
- 解决方案:使用核函数(后续会详细介绍):将数据映射到高维空间,在高维空间中找到线性超平面,从而实现非线性分类。
- 这样,即使在原始空间中边界很复杂,核函数也可以帮助找到合适的分类边界。
一、什么是非线性SVM?
定义:
非线性支持向量机(Non-linear SVM)是指它在特征空间中使用核函数(Kernel Trick)将原始数据映射到一个高维(甚至无限维)空间,并在这个高维空间中找到一个线性超平面,从而实现对原始数据的非线性分类。
相较于线性SVM:
- 线性SVM只适合数据在原空间中线性可分的问题。
- 非线性SVM可以处理复杂的边界,比如弯曲、环形等。
二、非线性SVM的核心思想
-
核函数的引入:
核函数允许我们在不显式计算高维映射的情况下,计算两个样本在高维空间中的内积。这就意味着:K(xi,xj)=⟨ϕ(xi),ϕ(xj)⟩K(x_i, x_j) = \langle \phi(x_i), \phi(x_j) \rangle K(xi,xj)=⟨ϕ(xi),ϕ(xj)⟩
其中 ϕ(⋅)\phi(\cdot)ϕ(⋅) 是映射到高维空间的特征映射。
-
边界非线性:
利用核函数,决策边界可以变得非常复杂(弯曲和环绕),以适应实际问题中的数据分布。
三、常用的核函数
| 核函数 | 公式 | 作用 |
|---|---|---|
| 线性核 | K(x,y)=xTyK(x, y) = x^T yK(x,y)=xTy | 线性问题,等于不映射 |
| 多项式核 | K(x,y)=(γxTy+r)dK(x, y) = (\gamma x^T y + r)^dK(x,y)=(γxTy+r)d | 学习多项式关系 |
| RBF(高斯核) | K(x,y)=exp(−γ∣x−y∣2)K(x, y) = \exp(-\gamma |x - y|^2)K(x,y)=exp(−γ∣x−y∣2) | 处理复杂非线性关系,最常用 |
四、用Python示例演示非线性SVM(以RBF核为例)
1. 说明
用scikit-learn的SVC(支持向量分类器)设置kernel='rbf',训练一组非线性数据(如环形状的分布),观察模型如何在这种非线性边界下进行分类。
2. 代码示例
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm
from sklearn.datasets import make_circles# 生成非线性可分数据(两个同心圆)
X, y = make_circles(n_samples=300, factor=0.5, noise=0.1)# 建立带RBF核的SVM分类器
clf = svm.SVC(kernel='rbf', gamma='scale') # gamma='scale'是推荐的参数调节方式
clf.fit(X, y)# 创建画布上的网格点
xx, yy = np.meshgrid(np.linspace(-1.5, 1.5, 500),np.linspace(-1.5, 1.5, 500))
mesh_points = np.c_[xx.ravel(), yy.ravel()]# 计算决策函数值
Z = clf.decision_function(mesh_points)
Z = Z.reshape(xx.shape)# 绘制分类区域
plt.contourf(xx, yy, clf.predict(mesh_points).reshape(xx.shape),alpha=0.8, cmap=plt.cm.Paired)# 绘制边界线(决策边界和支持向量边界)
plt.contour(xx, yy, Z, levels=[-1, 0, 1], linestyles=['--', '-', '--'], colors='k')# 展示样本点
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Set1, edgecolors='k')plt.title('Non-linear SVM with RBF Kernel')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()
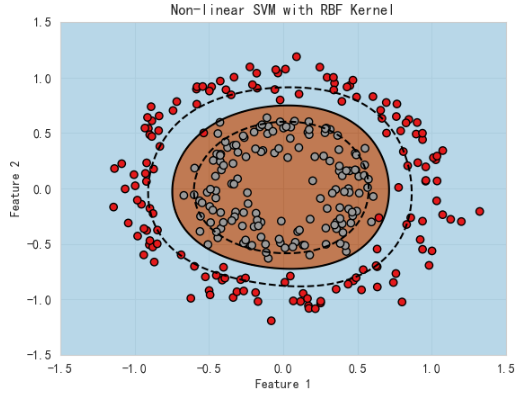
3. 说明
- 这个例子中,数据是两个同心圆,线性SVM难以处理,因为数据不是线性可分的。
- 使用
kernel='rbf'的非线性SVM可以在高维空间中找到一个线性超平面,实现环形边界的非线性分类。
-拟合完毕后,绘制了分类区域和边界,边界呈弯曲形,非常贴合数据。
五、总结
| 特点 | 描述 |
|---|---|
| 核技巧 | 通过核函数在高维空间映射,避免高维计算的复杂性 |
| 适用场景 | 复杂、非线性边界的数据集 |
| 核函数选择 | RBF常用,调节参数影响决策边界的复杂程度 |
六、可调参数的作用
- gamma:控制核函数的“宽度”,越大,模型越复杂,容易过拟合;越小,模型越简单,可能欠拟合。
- C:正则化参数,控制模型的容错能力和复杂度。
建议:
通过交叉验证调整gamma和C,获得最佳效果。
如果你需要我帮你更深入讲解核函数的数学原理,或者示例调参的代码,也可以告诉我!
五、核函数的作用
-
核函数(Kernel Function)是SVM中的关键组件,它允许我们在不显式计算高维空间映射的情况下,计算数据点在高维空间中的内积,从而实现非线性分类。
-
例如,高斯径向基函数(RBF)核可以把数据点映射到无限维空间,使得复杂的边界变得更容易找到。
-
常用核函数:
- 线性核:适合线性可分数据。
- 多项式核:可捕捉数据中的多项式关系。
- RBF核(高斯核):适用于大多数非线性边界,特别是数据的结构复杂时效果很好。
核函数的使用极大地增强了SVM的表达能力,使其可以处理复杂和非线性的问题。
一、核函数的作用和原理
1. 核函数的基本作用
在支持向量机中,核函数(Kernel Function)允许我们在不显式计算高维空间映射的情况下,直接计算两个样本在高维空间中的内积。这个过程叫做“核技巧(Kernel Trick)”。
为什么需要核函数?
- 很多数据在原空间中非线性可分,线性超平面无法有效分类。
- 通过映射到高维空间(可能是无限维),线性超平面就可能变得可行。
- 直接计算这些高维映射的点乘代价高昂甚至不可行,核函数提供了一个“捷径”,只需要在原始空间中用核函数计算两个点的“相似度”即可。
2. 核函数实现的核心思想
-
映射:把原空间中的样本 xxx 映射到一个高维空间 ϕ(x)\phi(x)ϕ(x)。
-
内积:在高维空间中,支持向量机的训练依赖于点积 ⟨ϕ(xi),ϕ(xj)⟩\langle \phi(x_i), \phi(x_j) \rangle⟨ϕ(xi),ϕ(xj)⟩。
-
核函数:定义为:
K(xi,xj)=⟨ϕ(xi),ϕ(xj)⟩K(x_i, x_j) = \langle \phi(x_i), \phi(x_j) \rangle K(xi,xj)=⟨ϕ(xi),ϕ(xj)⟩
这样,只需在算法中用核函数替代内积运算,无需显式计算映射。
二、常用的核函数类型
| 核函数 | 公式 | 说明 |
|---|---|---|
| 线性核 | K(x,y)=xTyK(x, y) = x^T yK(x,y)=xTy | 和普通内积一样,适合线性可分的情况 |
| 多项式核 | K(x,y)=(γxTy+r)dK(x, y) = (\gamma x^T y + r)^dK(x,y)=(γxTy+r)d | 可以学习到多项式关系,参数 ddd 控制多项式次数 |
| RBF(高斯径向基核) | K(x,y)=exp(−γ∣x−y∣2)K(x, y) = \exp(-\gamma |x - y|^2)K(x,y)=exp(−γ∣x−y∣2) | 最常用的核之一,适合复杂非线性边界 |
| Sigmoid核 | K(x,y)=tanh(γxTy+r)K(x, y) = \tanh(\gamma x^T y + r)K(x,y)=tanh(γxTy+r) | 模拟神经网络的激活函数 |
三、示例:用Python演示不同核函数的效果
我们用scikit-learn的SVC和make_circles(生成非线性数据)来演示不同核函数的分类效果。
1. 安装必要的库
pip install numpy matplotlib scikit-learn
2. Python代码示例
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm
from sklearn.datasets import make_circles# 生成非线性可分的数据:两个同心圆
X, y = make_circles(n_samples=300, factor=0.5, noise=0.1)kernels = ['linear', 'poly', 'rbf', 'sigmoid']
titles = ['Linear Kernel', 'Polynomial Kernel', 'RBF Kernel', 'Sigmoid Kernel']fig, axes = plt.subplots(2, 2, figsize=(12, 10))
axes = axes.ravel()for idx, kernel in enumerate(kernels):clf = svm.SVC(kernel=kernel, degree=3 if kernel=='poly' else 3, gamma='auto')clf.fit(X, y)xx, yy = np.meshgrid(np.linspace(-1.5, 1.5, 500),np.linspace(-1.5, 1.5, 500))mesh_points = np.c_[xx.ravel(), yy.ravel()]Z = clf.decision_function(mesh_points) # 先打印维度确认print(f"{kernel} decision_function shape:", Z.shape)Z = Z.reshape(xx.shape)ax = axes[idx]ax.contourf(xx, yy, clf.predict(mesh_points).reshape(xx.shape), alpha=0.8, cmap=plt.cm.coolwarm)ax.contour(xx, yy, Z, levels=[-1, 0, 1], linestyles=['--', '-', '--'], colors='k')ax.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Set1, edgecolors='k')ax.set_title(titles[idx])ax.set_xlabel('Feature 1')ax.set_ylabel('Feature 2')plt.tight_layout()
plt.show()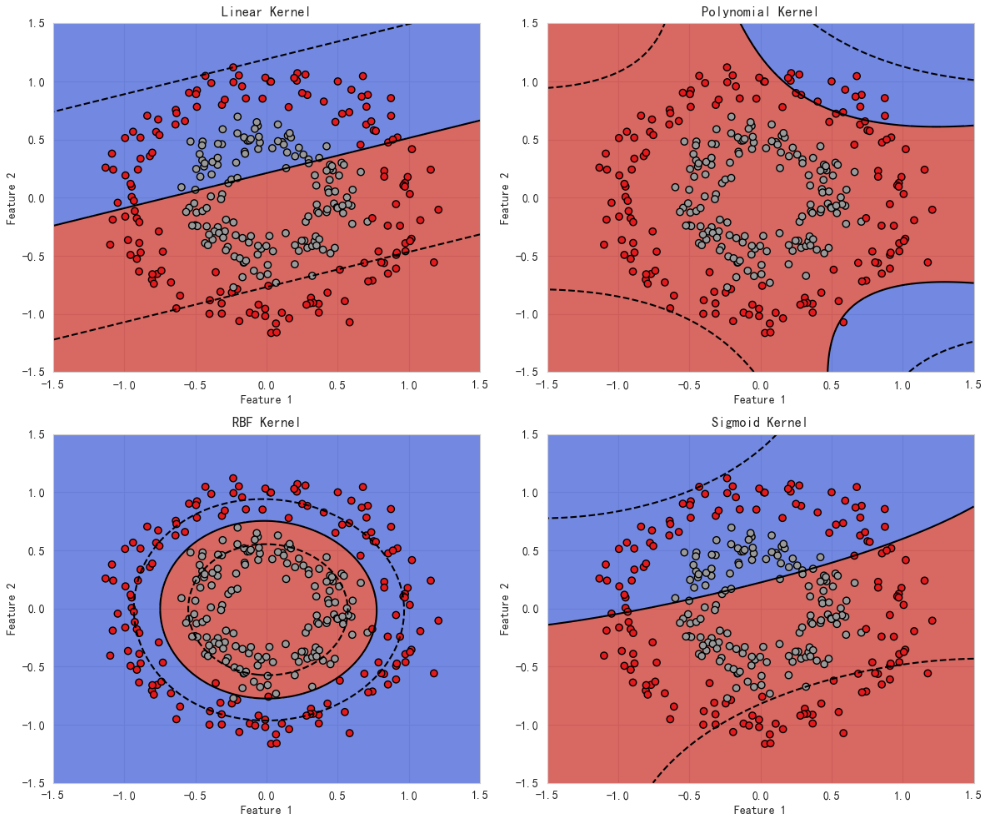
3. 代码说明
-
我们用
make_circles生成一个二类非线性分布的数据集。 -
不同核函数(linear、poly、多项式核、RBF、sigmoid)用
svm.SVC训练。 -
绘制决策边界和分类区域。
-
你会观察到:
- 线性核在非线性数据上表现差。
- RBF核能很好地适应复杂的边界。
- 多项式核也可以捕获一些非线性关系。
四、总结
- 核函数让SVM能在非线性问题上表现出色。
- 核技巧避免了高维映射的高昂计算成本,只需在原空间中用核函数计算相似度。
- 不同核函数适应不同的数据结构,选择合适的核函数是高性能SVM的关键之一。
六、SVM的应用领域
支持向量机因为其强大的分类能力和良好的泛化性能,被广泛应用于许多行业:
-
图像分类
- 例如识别手写数字(如MNIST数据集)、人脸识别、物体检测等。
-
文本分类
- 垃圾邮件检测:区分正常邮件和垃圾邮件。
- 情感分析:判断评论或社交媒体内容的积极或消极情绪。
-
生物信息学
- 基因表达数据分类,用于疾病预测。
- 蛋白质结构预测等生物学问题。
-
金融领域
- 信用评分:判断贷款申请人的信用风险。
- 股票趋势预测中的分类任务。
-
其他领域
- 语音识别、网络入侵检测等。
七、优缺点
1. 优点
-
高效:
- 在高维空间中仍能保持较好的性能,特别适合特征丰富但样本相对较少的情况。
-
准确:
- 通过最大化边界,增强模型的泛化能力。
-
理论基础牢固:
- 基于统计学习理论,具有良好的理论保障。
2. 缺点
-
参数敏感:
- 例如核函数的选择和参数调整(如核宽度、正则化参数)会对性能影响很大。
-
计算复杂度高:
- 在大规模数据集上,训练时间较长,因为涉及到的优化问题复杂。
-
缺少模型解释性:
- 作为“黑箱”模型,不像决策树那样容易理解决策过程。
八、总结:为什么学习SVM?
支持向量机凭借其坚实的理论基础、优异的分类性能,以及适应不同复杂度数据的能力,成为机器学习中的重要工具。它特别适合在特征空间复杂或数据量有限的情况下使用,帮助我们解决许多现实中的分类问题。
案例
完整的支持向量机(SVM)分类案例
一、导入依赖库
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm
from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.metrics import accuracy_score
numpy:数值计算matplotlib.pyplot:画图sklearn.svm:SVM模型make_moons:生成非线性可分数据集train_test_split:划分训练集和测试集GridSearchCV:参数调优accuracy_score:模型评估
二、生成数据集
# 生成一个非线性、二分类的“月亮”数据集
X, y = make_moons(n_samples=300, noise=0.2, random_state=42)# 可视化数据
plt.scatter(X[y==0][:,0], X[y==0][:,1], color='r', label='Class 0')
plt.scatter(X[y==1][:,0], X[y==1][:,1], color='b', label='Class 1')
plt.legend()
plt.title("Generated Moon Dataset")
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
plt.show()
效果:
这会产生一个弯曲的“月亮”形状数据集,明显非线性可分。
三、划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
- 训练集: 用于模型学习
- 测试集: 用于模型评估
四、创建和训练SVM模型
1. 试用不同核函数
# 使用线性核
clf_linear = svm.SVC(kernel='linear')
clf_linear.fit(X_train, y_train)# 使用RBF核(常用非线性核)
clf_rbf = svm.SVC(kernel='rbf', gamma='scale')
clf_rbf.fit(X_train, y_train)
五、评估模型
# 预测测试集
y_pred_linear = clf_linear.predict(X_test)
y_pred_rbf = clf_rbf.predict(X_test)# 输出准确率
print("Linear Kernel Accuracy:", accuracy_score(y_test, y_pred_linear))
print("RBF Kernel Accuracy:", accuracy_score(y_test, y_pred_rbf))
这会输出两个模型在测试集上的准确率。通常,非线性核如RBF会表现更优于线性核,尤其在数据非线性时。
六、可视化决策边界
定义一个绘图函数,用于展示不同模型的分类效果和决策边界。
def plot_decision_boundary(clf, X, y, title):# 生成网格点x_min, x_max = X[:,0].min() - 1, X[:,0].max() + 1y_min, y_max = X[:,1].min() - 1, X[:,1].max() + 1xx, yy = np.meshgrid(np.linspace(x_min, x_max, 500),np.linspace(y_min, y_max, 500))mesh_points = np.c_[xx.ravel(), yy.ravel()]# 计算预测值Z = clf.predict(mesh_points)# 可视化plt.contourf(xx, yy, Z.reshape(xx.shape), alpha=0.8, cmap=plt.cm.coolwarm)plt.scatter(X[:,0], X[:,1], c=y, edgecolors='k', cmap=plt.cm.Set1)plt.title(title)plt.xlabel("Feature 1")plt.ylabel("Feature 2")plt.show()# 线性核决策界
plot_decision_boundary(clf_linear, X, y, "SVM with Linear Kernel")
# RBF核决策界
plot_decision_boundary(clf_rbf, X, y, "SVM with RBF Kernel")
效果:
- 线性核:决策边界是一条直线,不能很好适应“月亮”形状数据。
- RBF核:决策边界弯曲,成功分隔两个类别。
七、调优参数以获得更好效果
1. 使用GridSearchCV调参
param_grid = {'C': [0.1, 1, 10, 100],'gamma': ['scale', 'auto', 0.1, 1, 10],'kernel': ['rbf']
}grid = GridSearchCV(svm.SVC(), param_grid, cv=5)
grid.fit(X_train, y_train)print("Best parameters:", grid.best_params_)
best_clf = grid.best_estimator_# 评估最优模型
y_pred_best = best_clf.predict(X_test)
print("Best model accuracy:", accuracy_score(y_test, y_pred_best))# 可视化边界
plot_decision_boundary(best_clf, X, y, "Tuned SVM with RBF Kernel")
2. 作用:
- 自动搜索出最优的
C和gamma参数。 - 改善模型效果。
总结
- 用非线性SVM可以有效解决复杂的分类问题,常用的核函数是RBF。
- 通过调参实现模型优化,获得最佳性能。
- 可视化决策边界,理解模型效果。