Linux(操作系统)文件系统--对打开文件的管理
Linux(操作系统)文件系统–>对打开文件的管理
Linux系统中对文件管理的分类
操作系统中对文件的管理分为两种:
第一种:对 “已经打开了的文件” 的管理
第二种:对 “未打开的文件” 的管理。
我们今天主要讲第一种:操作系统对 “已经打开了的文件” 的管理。
为什么分为这两类:
当我们要对文件进行一些操作的时候,无论是往文件中写入内容,还是查看文件里面的内容,我们第一步都是打开文件。只有打开文件之后,我们才能有后续对文件的其他操作。
而当我们不需要使用文件,不需要操作文件的时候,文件自然是不需要打开,就好好存储着就行。
所以我们对文件的管理就分为:对“未打开的文件”的管理,对“打开的文件”的管理。
那么当我们使用鼠标点击打开文件,还是使用指令打开文件,还是在我们写的代码中调用函数打开文件,在电脑中,操作系统中,实际上是谁打开的文件呢?
答案就是:是进程在打开文件,是进程在对文件操作。
因为我们上述提到的鼠标点击,指令打开,运行程序,归根结底其实都是程序运行后形成进程,然后进程执行相关代码指令去打开文件,操作文件。
而且要对文件操作,文件必须得先加载到内存当中,因为CPU只和内存交互。
回顾操作系统内容
今天呢,我们就从最外层(用户层面)开始,由浅入深的去理解操作系统和各种语言提供的库函数(本文我们用C语言来举例)是如何高效的管理“打开的文件” 以及 如何高效的处理对文件的操作(这个内容在下一节)。
那么在正式讲解之前,我们先回顾一下操作系统的相关概念,详细可见:十万个为什么之操作系统-CSDN博客
接下来我们就通过下面这两张图来粗略的回顾一下操作系统的内容:
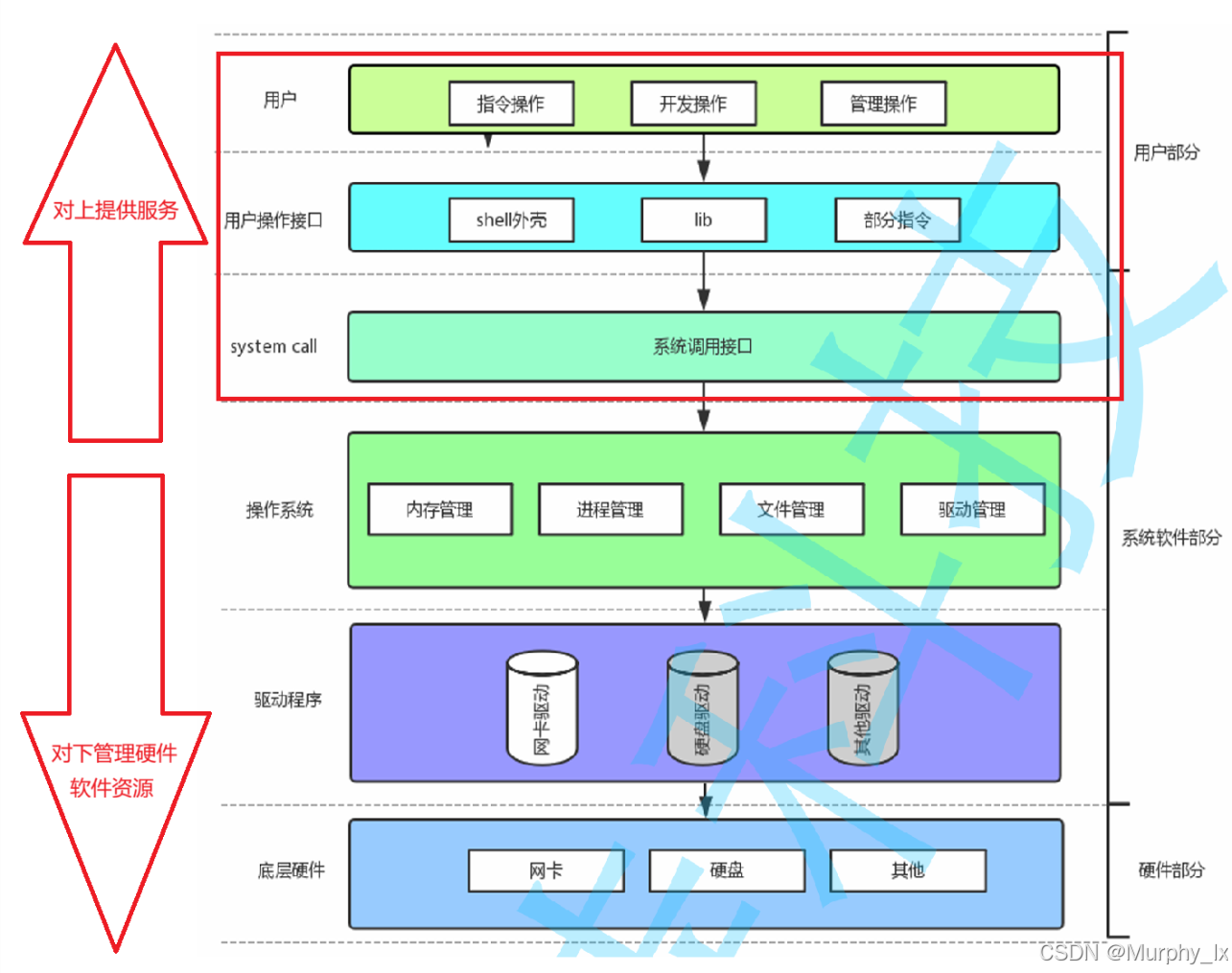
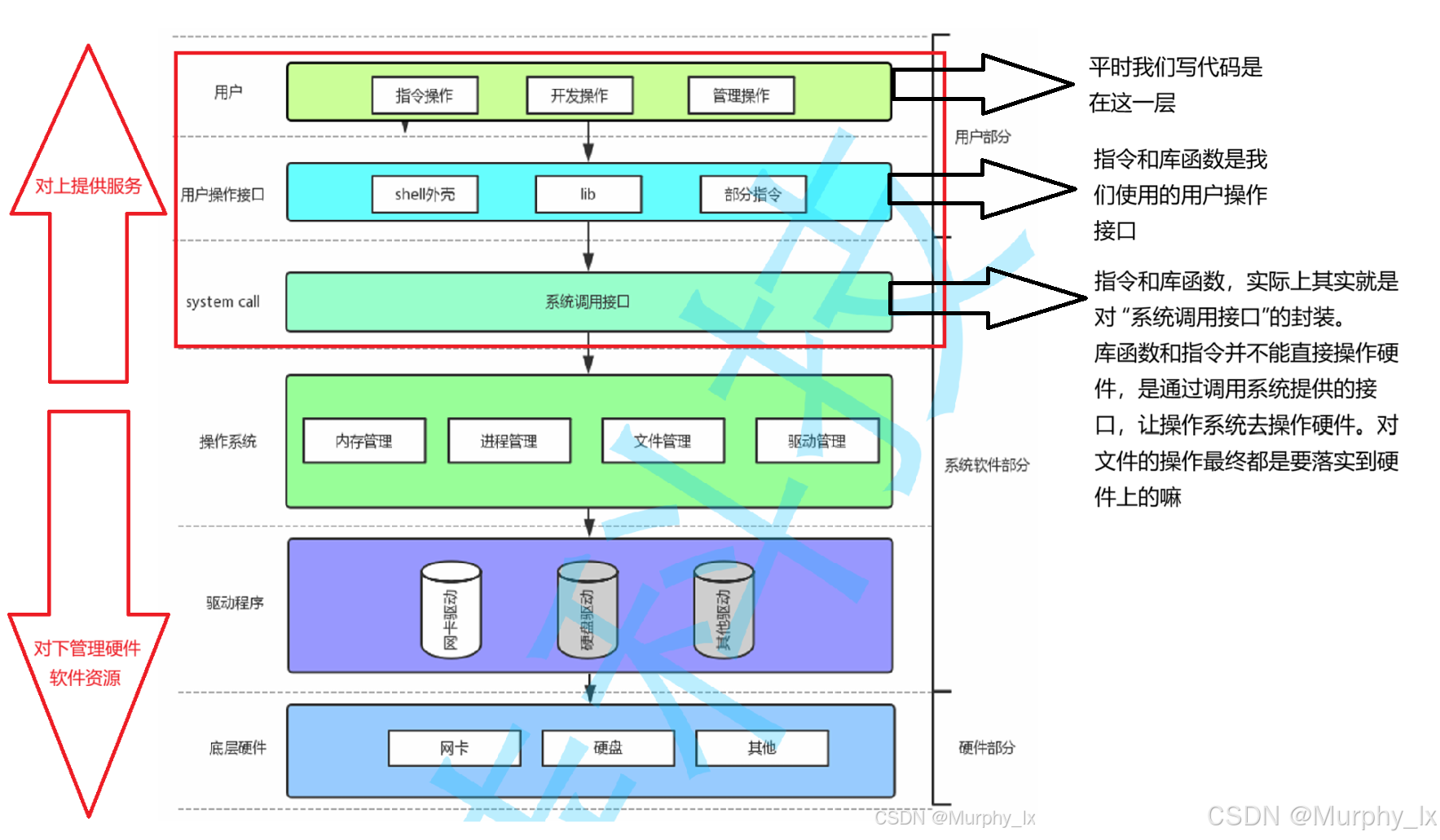
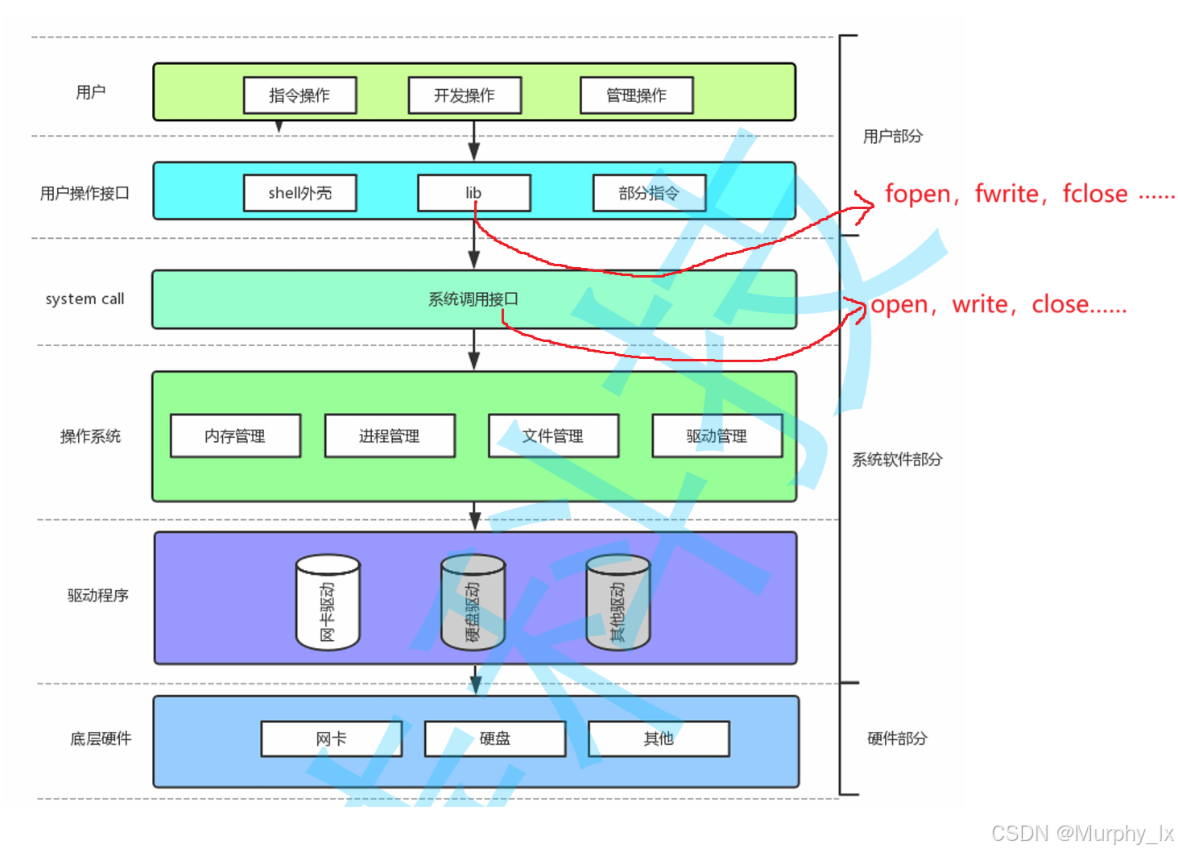
从上面的图中,我们可以知道,我们平时使用的指令昂,各种语言的库函数昂,实际上都是调用系统提供的接口。
操作系统 和 语言的分工
(接上文)而且我们知道,操作系统最主要的任务就是管理好软硬件资源。所以说,管理文件是操作系统的事情。
那各种语言对系统函数的封装又起到什么作用呢?
笼统一点说就是:
- 对上(面向用户/应用程序):提供更友好、安全、便捷的接口。库函数(如C语言的
fprintf)封装了底层的系统调用(如write),提供了格式化I/O、缓冲等功能,极大地方便了程序员,提高了开发效率和使用安全性。 - 对下(面向操作系统):并非是直接帮助内核管理文件资源,而是通过缓冲技术等优化手段,将多次零散的I/O请求合并为少量批次请求。这极大地减少了系统调用的次数,从而减少了用户态和内核态的切换开销,不仅提升了应用程序的性能,也间接减轻了内核的负担,让操作系统能更高效地进行全局管理和调度,提高了整个系统的效率。
通过上面的陈述,我们必须得理解的一件事情就是:管理文件是操作系统的事情。库函数更多是起到辅佐作用。就像皇帝和臣子的关系一样,皇帝主管理主决策,臣子主辅佐。
所以我们理解对打开文件的管理也要分两个层面:
第一个层面是皇帝是怎么管理的,怎么决策的。
第二个层面是臣子怎么辅佐皇帝的,具体体现在什么方面。
正文
内容引入:
本节内容的重点不在库函数是如何辅佐操作系统,本节内容的重点是:操作系统是如何管理这些“打开了的文件”。不过我们还是要从表层入手:
以下是 C 语言中文件操作相关库函数的表格总结,所有函数均来自 <stdio.h>头文件:
C语言核心文件操作库函数一览表:
| 函数声明 | 功能描述 | 头文件 |
|---|---|---|
| 文件打开与关闭 | ||
FILE *fopen(const char *filename, const char *mode); | 打开文件并返回文件指针 | <stdio.h> |
FILE *freopen(const char *filename, const char *mode, FILE *stream); | 重新定向文件流 | <stdio.h> |
int fclose(FILE *stream); | 关闭文件流 | <stdio.h> |
FILE *tmpfile(void); | 创建临时文件(自动删除) | <stdio.h> |
| 文件读写操作 | ||
size_t fread(void *ptr, size_t size, size_t nmemb, FILE *stream); | 从文件读取数据块 | <stdio.h> |
size_t fwrite(const void *ptr, size_t size, size_t nmemb, FILE *stream); | 向文件写入数据块 | <stdio.h> |
int fgetc(FILE *stream); | 从文件读取单个字符 | <stdio.h> |
int getc(FILE *stream); | 从文件读取字符(通常为宏实现) | <stdio.h> |
int fputc(int char, FILE *stream); | 向文件写入单个字符 | <stdio.h> |
int putc(int char, FILE *stream); | 向文件写入字符(通常为宏实现) | <stdio.h> |
char *fgets(char *str, int n, FILE *stream); | 从文件读取一行字符串 | <stdio.h> |
int fputs(const char *str, FILE *stream); | 向文件写入字符串 | <stdio.h> |
int fprintf(FILE *stream, const char *format, ...); | 格式化输出到文件 | <stdio.h> |
int fscanf(FILE *stream, const char *format, ...); | 从文件格式化输入 | <stdio.h> |
int ungetc(int char, FILE *stream); | 将字符推回流中 | <stdio.h> |
本节内容呢,我们主要用到的就是文件的打开与关闭以及文件的读写操作。
首先呢,在对文件操作之前,我们都要先打开文件,打开文件后又要对文件有相关操作,那么我们就先来了解一下fopen函数以及与文件操作相关的库函数(由于讲解函数的篇幅太长,所以我放到一篇独立的文章中了,建议大家先去了解一下函数的使用,只需要了解一下如何使用就ok,再来接着看本文)(因为函数讲解中包含了一些没有讲解的内容,所以只建议大家简单了解一下函数的使用和参数含义就ok)
链接:Linux系统C语言中与文件操作相关的核心库函数讲解-CSDN博客
在C语言中,文件操作是程序与外部世界(磁盘文件)交互的重要桥梁。
#include <stdio.h>int main() {// 打开文件进行写入FILE *file = fopen("example.txt", "w");if (file == NULL) {// 错误处理return 1;}// 使用fprintf向文件写入数据fprintf(file, "Hello, File I/O!\n");fprintf(file, "Today is %s\n", "2024年");// 关闭文件fclose(file);return 0;
}
关键洞察:无论是上面提供的代码,还是C语言文件操作库函数一览表,我们都能发现:
对文件操作首先第一步就是先通过fopen打开文件,fopen函数会返回一个FILE*类型的指针。然后,后续对文件的 读和写、关闭操作则需要使用到fopen函数的返回值(一个类型为FILE*的参数)。
无论是fread、fwrite、fprintf还是fscanf,它们都接受一个FILE *类型的参数,这代表一个抽象的数据源或目标。这种设计使得我们可以用相同的方式处理各种数据源。
这个返回值呢,我们都叫它为文件流。
这个东西其实没有多么的高大上,名字看起来很唬人,这里我直接和大家说了:FILE其实就是一个上层的结构体,C语言封装了系统提供的函数的返回值(文件信息),并且C语言提供了一些辅佐功能。这部分就是下一节的内容了,也就是大臣如何辅佐皇帝。
紧接着接着让我们思考一个问题:这些文件操作函数是否只能用于磁盘文件?
答案是:不! 实际上,C程序在启动时会自动打开三个特殊的文件流,它们与普通的文件流具有相同的FILE *类型:
#include <stdio.h>int main() {char buffer[100];// 使用fgets从标准输入读取(等同于gets)printf("请输入您的姓名: ");fgets(buffer, sizeof(buffer), stdin);// 使用fprintf向标准输出写入(等同于printf)fprintf(stdout, "您好, %s", buffer);// 使用fprintf向标准错误写入fprintf(stderr, "这是一个错误消息示例\n");return 0;
}
有趣的是,标准输入输出并非磁盘文件,而是预定义的文件流。 例如,我们常用的printf函数实际上是fprintf(stdout, ...)的简化版,这揭示了文件操作与用户交互的统一性。
理解三种标准流:
(标准流的内容涉及到本文后续的一些知识,大家可以先将就看,看不懂就跳过,先看后文)
核心概念
stdin(标准输入):- 概念: 程序默认的输入来源。当程序需要读取数据时(例如,用户输入、另一个程序的输出),它通常从
stdin读取。 - 默认关联: 在交互式命令行环境中,默认关联到用户的键盘。程序会等待用户从键盘输入数据。
- 概念: 程序默认的输入来源。当程序需要读取数据时(例如,用户输入、另一个程序的输出),它通常从
stdout(标准输出):- 概念: 程序默认的输出目的地。程序产生的正常结果、状态信息等通常写入
stdout。 - 默认关联: 在交互式命令行环境中,默认关联到用户的屏幕/终端。程序输出的信息会显示在终端窗口上。
- 概念: 程序默认的输出目的地。程序产生的正常结果、状态信息等通常写入
stderr(标准错误):- 概念: 程序默认的错误信息和诊断信息的输出目的地。用于输出错误消息、警告、调试信息等,这些信息通常需要与程序的正常输出区分开来。
- 默认关联: 在交互式命令行环境中,默认也关联到用户的屏幕/终端。错误信息会显示在终端窗口上,通常与
stdout的输出混合在一起(除非重定向)。 - 关键区别:
stderr的核心价值在于它与stdout是分离的流。这允许用户或系统管理员将程序的正常输出 (stdout) 和错误输出 (stderr) 分别处理(例如,将正常输出保存到文件,同时让错误信息仍然显示在屏幕上)。
定义归属:C 语言标准 vs. Linux 系统
stdin,stdout,stderr是 C 语言标准库 (<stdio.h>) 的定义:- C 语言标准 (如 C11、C17) 规定了程序启动时,必须自动打开三个预定义的
FILE*类型的流:stdin,stdout,stderr。 - 标准定义了它们的抽象行为:
stdin用于输入,stdout用于正常输出,stderr用于错误输出。 - 标准定义了操作它们的函数:如
printf(...)等价于fprintf(stdout, ...),scanf(...)等价于fscanf(stdin, ...),perror(...)等价于fprintf(stderr, ...)。 - 标准没有规定它们具体对应什么物理设备或文件。 它只定义了这些流的逻辑存在和行为接口 (
FILE*)。
- C 语言标准 (如 C11、C17) 规定了程序启动时,必须自动打开三个预定义的
- Linux (和其他 Unix-like 系统) 负责实现这些标准流:(下文很快就会讲到,这里属于提前剧透了)
- Linux 操作系统遵循 POSIX 标准(很大程度上基于 Unix 哲学),它规定了程序启动时如何创建进程环境。
- 当一个 C 程序在 Linux 命令行 (shell) 中启动时,Linux (通过 shell) 会为这个新进程自动打开三个文件描述符 (File Descriptors):
- 文件描述符 0 (FD 0): 标准输入 (
stdin) - 文件描述符 1 (FD 1): 标准输出 (
stdout) - 文件描述符 2 (FD 2): 标准错误 (
stderr)
- 文件描述符 0 (FD 0): 标准输入 (
- 连接点: C 标准库在 Linux 上的实现 (
glibc或musl) 负责将 C 语言层面的FILE* stdin/stdout/stderr绑定到操作系统层面的文件描述符 0/1/2。 - 初始关联: Shell 在启动程序时,默认会将这三个文件描述符连接到它自己正在使用的终端设备 (Terminal Device)。终端设备在 Linux 中表现为
/dev/tty(当前控制终端)或更具体的/dev/pts/N(伪终端从设备)。
与键盘和屏幕的关系(硬件关联)
- 默认情况下的关联:
- 在用户登录 Linux 系统并打开一个终端窗口(如 GNOME Terminal, Konsole, xterm, 或者纯文本的控制台)时,系统会创建一个终端会话。
- 这个终端会话由一个终端设备文件(如
/dev/pts/0)表示。这个设备文件抽象了物理的(或虚拟的)键盘和显示器。 - 当你在终端里运行一个程序(例如
./myprogram)时:- Shell (如
bash,zsh) 是终端的当前前台进程组。 - Shell 创建新进程 (
myprogram)。 - Shell 将新进程的 FD 0 (
stdin), FD 1 (stdout), FD 2 (stderr) 继承或复制到自己当前使用的终端设备文件 (/dev/pts/0)。
- Shell (如
- 因此:
- 程序从
stdin(FD 0) 读取数据,实际上是从/dev/pts/0读取。这个设备文件会将用户的键盘输入传递给程序。 - 程序向
stdout(FD 1) 或stderr(FD 2) 写入数据,实际上是向/dev/pts/0写入。这个设备文件负责将数据渲染到终端窗口的屏幕上显示给用户。
- 程序从
- 关键点:
stdin/stdout/stderr本身不是硬件,它们是抽象的数据流。- 它们默认关联到的终端设备文件 (
/dev/tty,/dev/pts/N) 是 Linux 对键盘和显示器硬件的抽象。 - 这种关联是动态的和可配置的!也就是
stdin可以不是对键盘的抽象,它也可以是一个普通的文件打开后的文件流(后面很快就会讲到了)
重定向:打破默认关联
重定向的底层原理我会在这一篇讲解,然后我会单独写一篇文章来复现这个重定向功能:
链接:Linux下写一个简陋的shell程序(2)-CSDN博客
Linux shell 提供了强大的重定向 (Redirection) 功能,可以改变程序启动时 stdin, stdout, stderr关联的实际目标:
- 改变输入来源 (
stdin):./myprogram < input.txt:程序从input.txt文件读取输入,而不是键盘。command1 | ./myprogram:程序从管道读取输入,即command1命令的stdout输出成为myprogram的stdin输入。
- 改变输出目的地 (
stdout):./myprogram > output.txt:程序的正常输出写入output.txt文件,而不是屏幕。./myprogram >> output.txt:追加输出到文件。./myprogram | command2:程序的stdout输出通过管道成为command2命令的stdin输入。
- 改变错误输出目的地 (
stderr):./myprogram 2> errors.log:程序的错误信息写入errors.log文件,而不是屏幕。./myprogram 2>&1:将stderr(FD 2) 合并重定向到stdout(FD 1) 的当前目标(通常是屏幕或文件)。./myprogram > output.txt 2>&1:将stdout和stderr都重定向到output.txt。./myprogram > output.txt 2> errors.log:将stdout重定向到output.txt,将stderr重定向到errors.log。
重定向的本质: Shell 在启动程序之前,修改了将要传递给新进程的文件描述符 0、1、2 所指向的实际文件或管道,而不是默认的终端设备文件。
总结
- 概念定义 (C 语言):
stdin,stdout,stderr是 C 标准库 (<stdio.h>) 定义的三个预打开的FILE*流,分别代表默认输入、默认正常输出和默认错误输出。 - 实现关联 (Linux 系统): Linux (POSIX) 在进程创建时提供文件描述符 0、1、2。C 标准库实现将
FILE* stdin/stdout/stderr绑定到这些 FD。 - 硬件关联 (默认情况): Shell 默认将新进程的 FD 0/1/2 连接到它自己使用的终端设备文件 (
/dev/tty,/dev/pts/N)。这个设备文件抽象了物理的键盘 (输入) 和屏幕 (输出)。 - 核心特性 (灵活性):
stdin/stdout/stderr与键盘/屏幕的关联是默认且最常见的,但不是固定的。Linux Shell 的重定向机制允许将它们关联到文件、管道、其他程序的输入/输出,甚至网络套接字等,实现了强大的输入/输出控制和程序间通信 (IPC)。这种“一切皆文件描述符”的抽象是 Unix/Linux 设计哲学的精髓之一。
上面的内容呢,我们已经了解了C语言中操作文件相关的库函数的使用(我给了大家链接的)。并且引出了文件流,和标准文件流的概念,还有Linux中重定向的内容(重定向这个算是一个番外)。其中提到了很多陌生的知识,比如文件描述符,以及怎么去理解标准文件流和文件描述符的关系。接下来,我们都会一一解决:
Linux系统管理“打开文件”的底层结构和过程
本文一开始就提到过,C语言中的库函数实际上都是封装的系统提供的接口,本文的内容主要是去理解操作系统如何管理这些被打开了的文件的,所以接下来我们开始了解一下与操作文件相关的系统函数。
我们先了解一些简单的:
这些函数直接与 Linux 内核交互,提供了底层的文件操作能力。所有函数声明均来自 POSIX 标准头文件:
Linux 文件操作系统调用一览表:
| 函数声明 | 功能描述 | 头文件 |
|---|---|---|
| 文件打开/创建与关闭 | ||
int open(const char *pathname, int flags); | 打开或创建文件 | <fcntl.h> |
int open(const char *pathname, int flags, mode_t mode); | 打开或创建文件(带权限) | <fcntl.h> |
int creat(const char *pathname, mode_t mode); | 创建文件(等效于 open(O_CREAT|O_WRONLY|O_TRUNC)) | <fcntl.h> |
int close(int fd); | 关闭文件描述符 | <unistd.h> |
| 文件读写操作 | ||
ssize_t read(int fd, void *buf, size_t count); | 从文件描述符读取数据 | <unistd.h> |
ssize_t write(int fd, const void *buf, size_t count); | 向文件描述符写入数据 | <unistd.h> |
ssize_t pread(int fd, void *buf, size_t count, off_t offset); | 从指定位置读取(不改变偏移量) | <unistd.h> |
ssize_t pwrite(int fd, const void *buf, size_t count, off_t offset); | 向指定位置写入(不改变偏移量) | <unistd.h> |
(同理,这里也是建议大家先去了解一下这些函数的使用方法先,了解一下函数参数的意义和怎么使用函数)(大家可以根据我在本文讲解的进度去选择性的查看,比如我讲open函数的时候,大家就可以先只看open函数的使用,别的函数可以到时候再看)
链接:Linux系统中与操作文件相关的系统调用-CSDN博客
在上面我传给大家的链接中,我已经详细的讲解了open函数的使用,接下来我们简单的去用一下open函数,观察一下fopen是怎么封装open函数的。
fopen的底层原理 和 重定向的底层原理
这里我就不给大家过多铺垫了,直接给大家输出结果:(这个结果也是重定向指令的底层原理,重定向指令的使用 和 fopen函数的使用是差不多的,大家可以点击去番外看,链接:Linux下写一个简陋的shell程序(2)-CSDN博客)
include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>int main() {int fd = open("log.txt",O_WRONLY);return 0;
}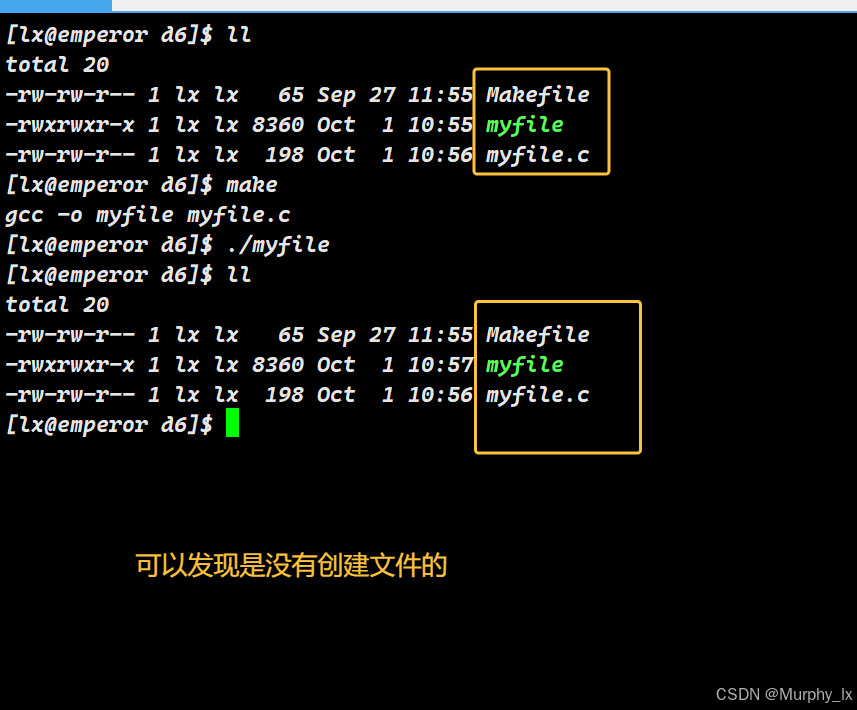
当以写方式打开文件,但文件不存在的时候,只有一个O_WRONLY是不会创建文件的。
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>int main() {int fd = open("log.txt",O_WRONLY|O_CREAT,0666);const char* str = "aaaaaa\n";write(fd,str,strlen(str));close(fd);return 0;
}
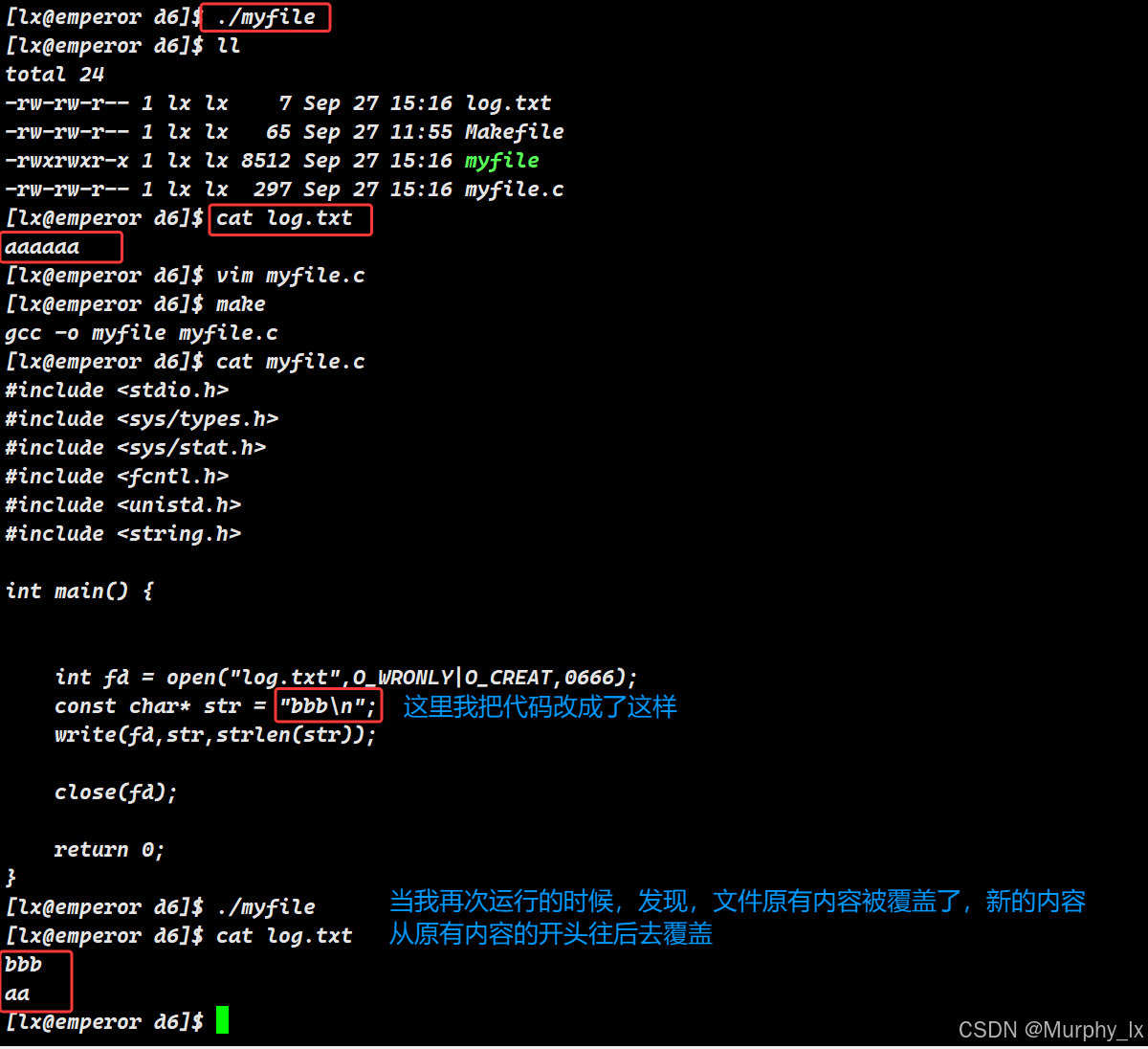
当我们加入O_CREAT的时候,就可以在文件不存在的时候,创建文件了。不过我们这个时候每次向文件写入新内容,结果都是新内容从文件原有内容的其实位置开始往后覆盖。并不符合fopen函数中的任何一种模式。
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>int main() {int fd = open("log.txt",O_WRONLY|O_CREAT|O_TRUNC,0666);const char* str = "aaaaaa\n";write(fd,str,strlen(str));close(fd);return 0;
}
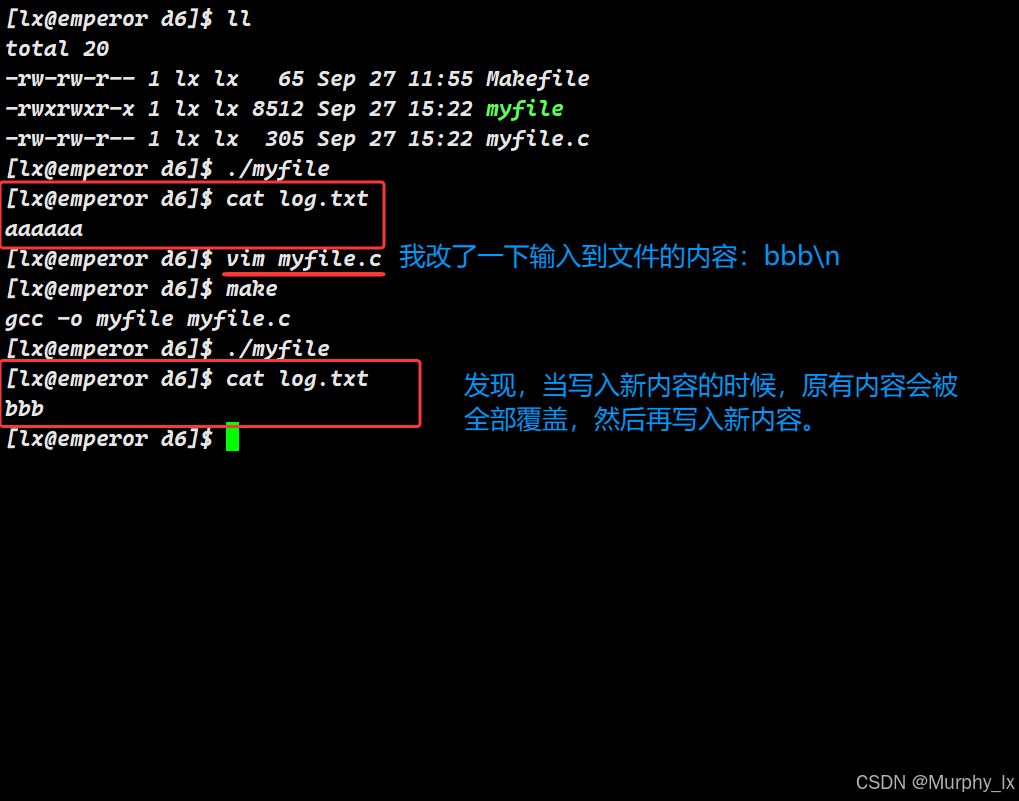
这个时候我们就能发现,open使用O_WRONLY|O_CREAT|O_TRUNC这三个参数的结果是和以w方式使用fopen的结果是一样的。也就是:
FILE *file = fopen("log.txt", "w");
//封装着:
int fd = open("log.txt",O_WRONLY|O_CREAT|O_TRUNC,0666);同理以a方式(追加)使用fopen则是:
FILE *file = fopen("log.txt", "a");
//封装着:
int fd = open("log.txt",O_WRONLY|O_CREAT|O_APPEND,0666);其他模式也是同理。
文件描述符
接下来我们继续观察系统调用:
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>int main() {int fd1 = open("log1.txt",O_WRONLY|O_CREAT|O_TRUNC,0666); int fd2 = open("log2.txt",O_WRONLY|O_CREAT|O_TRUNC,0666);int fd3 = open("log3.txt",O_WRONLY|O_CREAT|O_TRUNC,0666);int fd4 = open("log4.txt",O_WRONLY|O_CREAT|O_TRUNC,0666);int fd5 = open("log5.txt",O_WRONLY|O_CREAT|O_TRUNC,0666);int fd6 = open("log6.txt",O_WRONLY|O_CREAT|O_TRUNC,0666);int fd7 = open("log7.txt",O_WRONLY|O_CREAT|O_TRUNC,0666);printf("fd1 = %d\n",fd1);printf("fd2 = %d\n",fd2);printf("fd3 = %d\n",fd3);printf("fd4 = %d\n",fd4);printf("fd5 = %d\n",fd5);printf("fd6 = %d\n",fd6);printf("fd7 = %d\n",fd7);return 0;}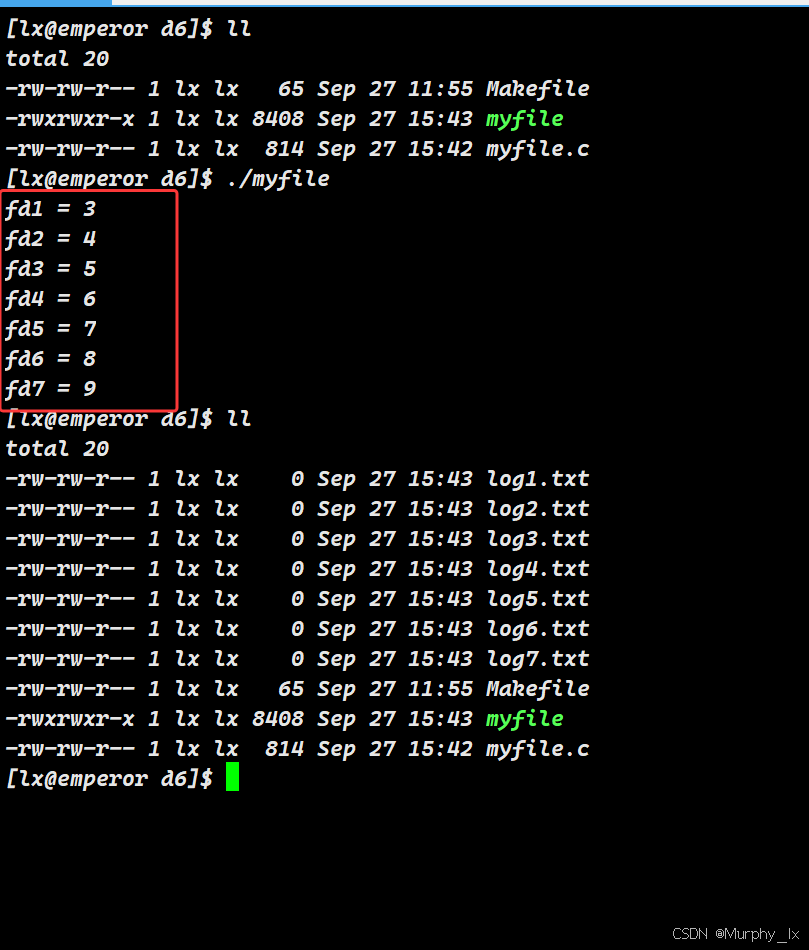
我们使用open函数,间接创建并直接打开了7个文件,7个open函数的返回值各不相同,可以看到open函数的返回值是从3开始,一直到9。
可以发现open的返回值是递增的,而是是顺序递增,很有规律。这是不是很像数组下标?
实际情况就是open函数的返回值的作用和数组下标差不多。open函数返回值正经的名字叫 “ 文件描述符 ”。
这个文件描述符不是什么高大上的东西,大家就把它理解为数组下标就好了。
从上面代码运行的结果我们发现open函数的返回值是从3开始的,那为什么是从3开始呢?既然说文件描述符和数组下标差不多,那为什么open函数的返回值(文件描述符)不从0开始呢?
大家还记得我们前面提到过的3个标准文件流吗?标准输入stdin,标准输出stdout,标准错误stderr。
当一个 C 程序在 Linux 命令行 (shell) 中启动时,Linux (通过 shell) 会为这个新进程自动打开三个文件描述符:
-
标准文件描述符:
- 0: 标准输入
stdin对应我们的键盘 - 1: 标准输出
stdout对应我们的屏幕 - 2: 标准错误
stderr(也指向屏幕,不过目的是和stdout不同的)
- 0: 标准输入
-
文件描述符是系统调用层面的抽象,代表了一个打开的文件。
所以文件描述符确实是从0开始的,只不过一开始我们不知道,是系统帮我们做了而已。
在C语言层面,当我们打开一个文件的时候,返回的是一个FILE*类型的指针,一般都叫它文件流,从而用来维护打开了的文件。
在系统层面,当我们打开一个文件的时候,则使用的是一个名为文件描述符的东西,来维护打开了的文件。
实际上FILE就是一个结构体,结构体中封装了这个叫文件描述符的东西。
文件描述符:
-
当程序通过系统调用(如
open())打开一个文件时,内核会返回一个文件描述符。 -
它是一个非负整数(例如 0, 1, 2, 3…),是进程级文件描述符表的索引,每个进程都有一个私有的文件描述符表,你可以把它想象成一个数组,文件描述符就是数组的下标。通过这个下标,就能找到对应的表项。
-
这个表项指向内核中维护的打开文件表,进而关联到真正的文件。
-
第一层:进程的文件描述符表 -> 内核的打开文件表
进程的文件描述符表项中,存储的是一个指向内核中“打开文件表”某个条目的指针。这个“打开文件表”是全局的,包含了像文件偏移量(当前读写位置)、文件的访问模式(只读、读写等)、以及一个指向文件更核心信息的指针等信息。
第二层:内核的打开文件表 -> 真正的文件(VFS inode)
“打开文件表”的条目最终指向的是文件在内存中的核心数据结构(在Linux中称为
inode)。inode包含了文件的所有元信息(大小、权限、所有者、数据块在磁盘上的位置等)。(这部分的内容在后面会讲,本节不讲,这部分是对未打开文件的管理的内容)
完整的文件描述符三层结构模型(发现CSDN的mermaid运行不出来,大家可能需要去别的地方运行来看一眼)(我还是直接把图贴出来吧)
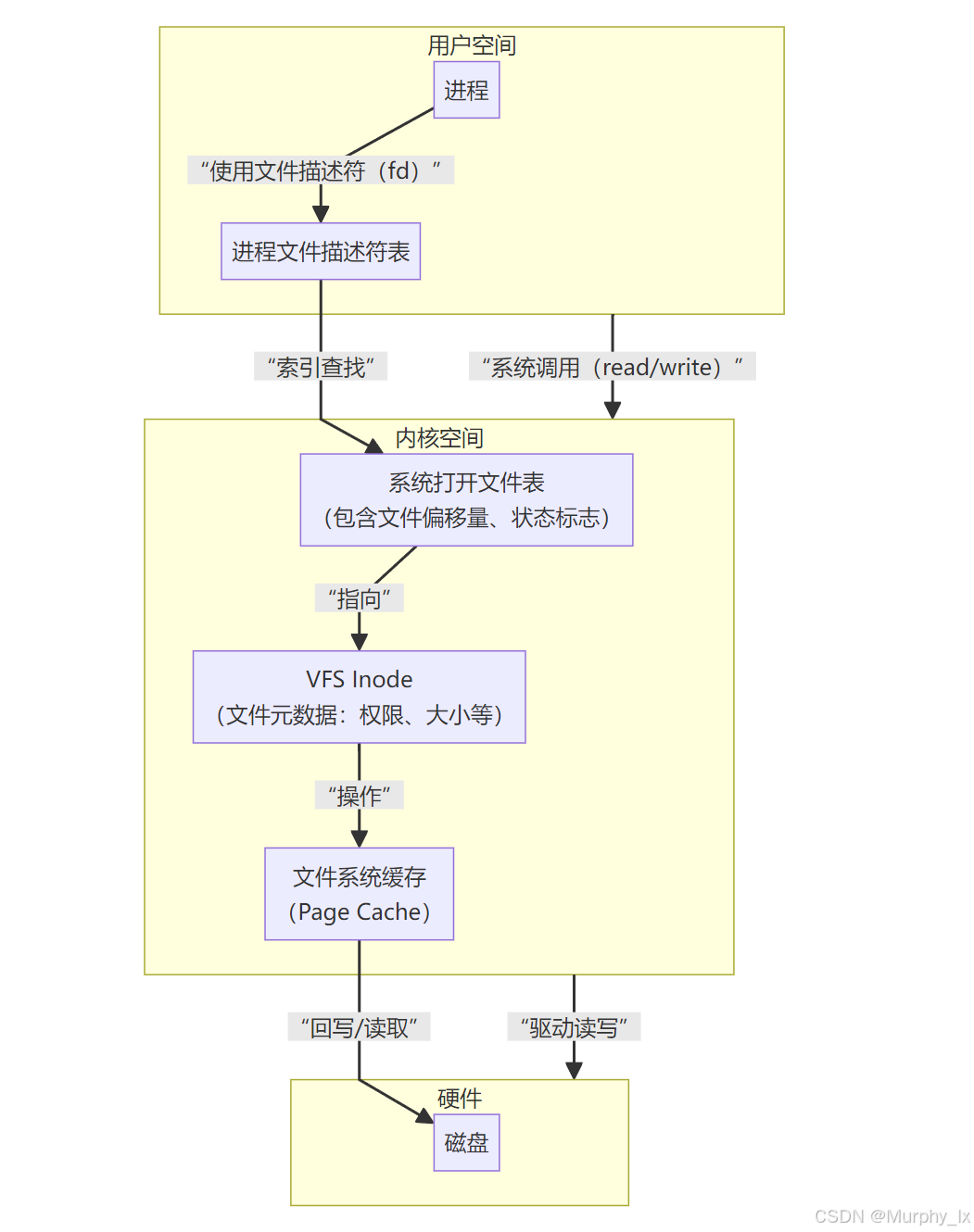
flowchart TDA[用户空间<br>应用程序]B[内核空间]C[硬件]subgraph A [用户空间]direction LRP[进程]PFD[进程文件描述符表]endsubgraph B [内核空间]direction LROFT[系统打开文件表<br>(包含文件偏移量、状态标志)]VFS[VFS Inode<br>(文件元数据:权限、大小等)]FC[文件系统缓存<br>(Page Cache)]endsubgraph C [硬件]Disk[磁盘]endA -- “系统调用(read/write)” --> BB -- “驱动读写” --> CP -- “使用文件描述符(fd)” --> PFDPFD -- “索引查找” --> OFTOFT -- “指向” --> VFSVFS -- “操作” --> FCFC -- “回写/读取” --> Disk
stderr与 stdout解析
在 Linux/Unix 系统中,stderr(标准错误)和 stdout(标准输出)是进程的两种独立输出流,虽然默认都指向终端屏幕,但设计目的和特性截然不同。
核心区别对比表
| 特性 | stdout(标准输出) | stderr(标准错误) |
|---|---|---|
| 用途 | 正常程序输出(结果、数据) | 错误消息、警告、诊断信息 |
| 缓冲策略 | 行缓冲(终端) 全缓冲(重定向到文件) | 无缓冲(立即输出) |
| 文件描述符 | 1 | 2 |
| 重定向独立性 | 可独立重定向 | 可独立重定向 |
| 输出优先级 | 低(可能被缓冲延迟) | 高(即时显示) |
| C 库函数 | printf(), puts() | fprintf(stderr, ...), perror() |
| 崩溃时可靠性 | 缓冲区内容可能丢失 | 内容几乎不会丢失(无缓冲) |
stderr的五大核心特点
1. 无缓冲机制(关键区别)
-
行为:数据直接写入目标设备,不经过缓冲区
-
意义:确保错误信息即时可见,即使程序崩溃也能输出
-
对比:
// stdout示例(可能丢失输出) printf("Normal message"); // 行缓冲,未换行可能不显示 abort(); // 程序崩溃,输出丢失// stderr示例(可靠输出) fprintf(stderr, "Error occurred!"); // 立即显示 abort(); // 崩溃前消息已输出
2. 独立的重定向通道
-
终端默认行为:
$ ./program Normal output # stdout Error message # stderr -
分离重定向:
# stdout重定向到文件,stderr保留在屏幕 $ ./program > output.log Error message # 仅显示错误# stderr重定向到文件 $ ./program 2> errors.log# 完全分离 $ ./program > output.log 2> errors.log
3. 高优先级输出
-
场景:当程序同时向两者输出时:
for (int i=0; i<5; i++) {printf("stdout %d\n", i);fprintf(stderr, "stderr %d\n", i); } -
实际输出顺序:
stderr 0 stderr 1 stderr 2 stderr 3 stderr 4 stdout 0 stdout 1 stdout 2 stdout 3 stdout 4 -
原因:
stderr无缓冲立即输出,stdout行缓冲需等待换行
4. 错误诊断专用通道
-
正确用法:
FILE *fp = fopen("data.txt", "r"); if (!fp) {// 错误信息发送到stderrfprintf(stderr, "Error: Failed to open file (errno=%d)\n", errno);perror("fopen"); // 自动附加错误描述exit(EXIT_FAILURE); } -
优势:
- 与正常输出分离,便于日志分析
- 即使
stdout被重定向,错误仍可见
5. 管道操作中的生存保障
-
危险管道:
$ ./program | grep "important" # 若程序崩溃,stdout内容丢失 -
安全方案:
# 合并stderr到stdout $ ./program 2>&1 | grep "important"# 分离处理 $ ./program 2> errors.log | grep "important"
内核级实现差异
虽然两者都是文件描述符,但内核处理方式不同:
// 标准流的内核初始化
void init_stdio(void) {// stdout (缓冲模式设置)setvbuf(stdout, NULL, _IOLBF, BUFSIZ); // 行缓冲// stderr (强制无缓冲)setbuf(stderr, NULL); // 相当于setvbuf(stderr, NULL, _IONBF, 0);
}
关键底层差异:
stderr的FILE结构体中_flags字段包含__SNBF标志(无缓冲),而stdout包含__SLBF(行缓冲)。
最佳实践指南
-
严格分离输出类型
// 正确示例 printf("Processing item %d\n", id); // stdout fprintf(stderr, "WARN: Invalid entry\n"); // stderr -
调试时优先使用 stderr
#ifdef DEBUG fprintf(stderr, "[DEBUG] Value=%d\n", var); // 即时显示调试信息 #endif -
关键错误添加额外信息
fprintf(stderr, "CRITICAL: %s:%d - %s\n", __FILE__, __LINE__, strerror(errno)); -
服务程序日志策略
// 重定向stderr到日志文件 freopen("/var/log/service.log", "a", stderr); setvbuf(stderr, NULL, _IOLBF, 0); // 改为行缓冲提高效率
特殊场景验证
Q:为什么有时看到混合输出?
A:终端设备驱动会合并两路流,但内容来源不同:
# 查看真实区别
$ ./program > output.txt # 只有stdout写入文件
$ ./program 2> errors.txt # 只有stderr写入文件
Q:何时需要强制刷新 stdout?
A:在输出关键信息后立即调用:
printf("Saving data...");
fflush(stdout); // 确保用户立即看到提示
save_data();
总结
stderr的本质是高优先级诊断通道,核心价值在于:
- 🚨 即时性:无缓冲确保关键错误不丢失
- 🧩 独立性:与正常输出物理分离
- 🛡️ 可靠性:程序崩溃时的最后救命通道
- 🔍 可诊断性:专为错误和警告设计
接下来我带大家看看代码:
下面这些结构体展示了早期 Linux 内核(2.6 版本左右)的实现方式,虽然现代内核有所变化,但核心概念保持一致。
核心结构体解析
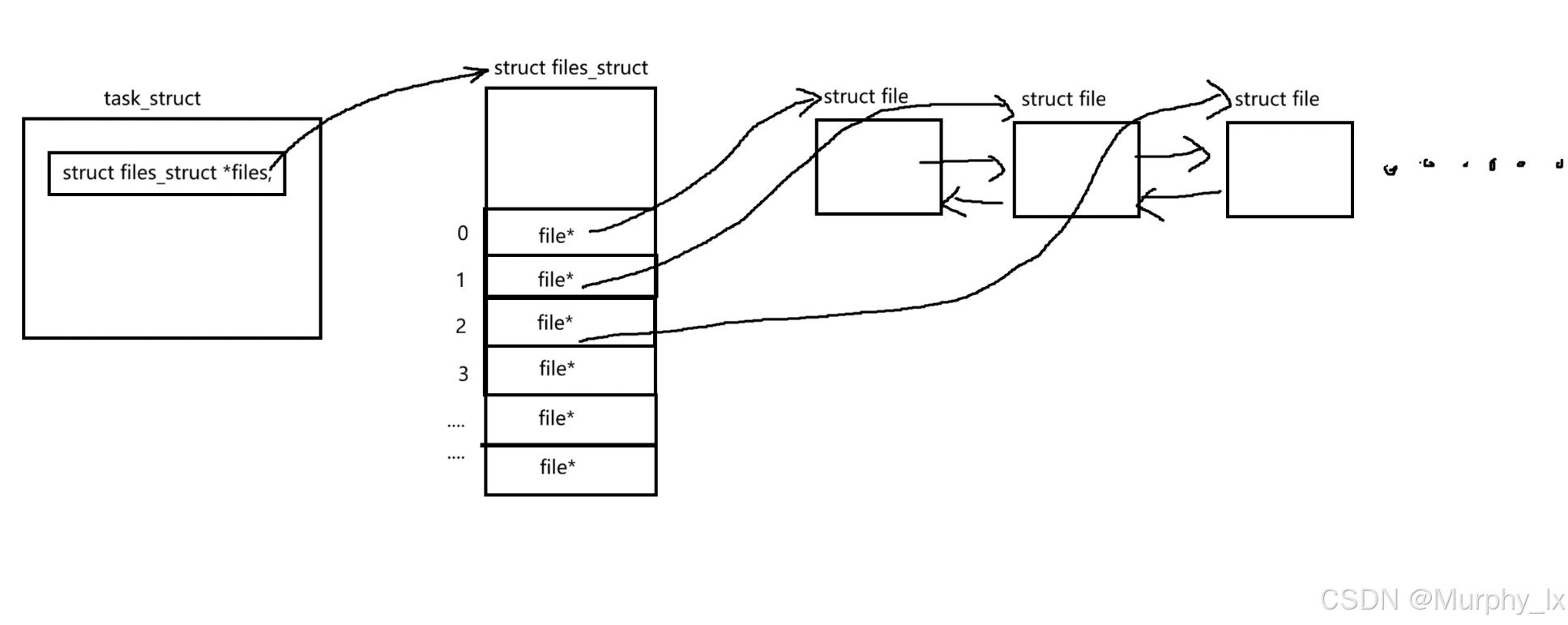
1. task_struct(进程描述符)
//Linux系统中的进程PCB(进程控制块)
struct task_struct {//.../* open file information */struct files_struct *files; // 指向进程的文件表//...
}
- 作用:Linux 中每个进程/线程都由一个
task_struct表示 - 关键成员:
files:指向该进程的files_struct结构,管理所有打开的文件
2. files_struct(进程文件表)
struct files_struct {atomic_t count; // 引用计数spinlock_t file_lock; // 保护文件表的自旋锁int max_fds; // 最大文件描述符数量int max_fdset; // 最大文件描述符集大小int next_fd; // 下一个可用的文件描述符struct file ** fd; // 文件指针数组(动态分配)fd_set *close_on_exec; // exec 时需要关闭的文件描述符位图fd_set *open_fds; // 已打开文件描述符位图fd_set close_on_exec_init; // 初始 close_on_exec 位图fd_set open_fds_init; // 初始 open_fds 位图struct file * fd_array[NR_OPEN_DEFAULT]; // 初始文件指针数组
};
- 作用:管理进程打开的所有文件
- 关键成员:
fd:指向文件指针数组(struct file*数组)fd_array:初始静态数组(通常大小为 64)open_fds:位图标记哪些文件描述符已使用close_on_exec:位图标记哪些文件在exec()后应关闭
struct file * fd_array[NR_OPEN_DEFAULT];
静态文件对象指针数组。这是 fd 指针数组的静态版本。当进程打开的文件数量不多时(少于 NR_OPEN_DEFAULT,通常是 32),内核直接使用这个静态数组,避免了动态内存分配的开销。只有当打开的文件数超过这个值时,fd 才会指向一个动态分配的更大的数组。
struct file ** fd;
文件对象指针数组。这是整个结构体的核心。fd 是一个指针,它指向一个动态分配的数组,数组中的每个元素都是一个指向 struct file 的指针。struct file 是内核中代表一个 “已打开文件” 的详细对象。数组的索引就是文件描述符号(如 0, 1, 2, …)。例如,fd[0] 指向标准输入对应的 struct file 对象。
3. file(文件对象)
struct file {struct list_head f_list; // 文件对象链表struct dentry *f_dentry; // 目录项(关联到 inode)struct vfsmount *f_vfsmnt; // 文件系统挂载点struct file_operations *f_op; // 文件操作函数表atomic_t f_count; // 引用计数unsigned int f_flags; // 打开标志(O_RDONLY 等)mode_t f_mode; // 文件访问模式loff_t f_pos; // 文件当前位置(读写偏移)struct fown_struct f_owner; // 异步 I/O 所有权unsigned int f_uid, f_gid; // 用户/组 ID// ... 其他字段 ...
};
- 作用:表示一个打开的文件实例
- 关键成员:
f_dentry:指向文件的目录项(dentry),通过它找到 inodef_op:文件操作函数表(包含 read/write 等函数指针)f_pos:当前文件读写位置f_count:引用计数(多个文件描述符可能共享同一个 file 对象)
完整关系与工作流程
1. 结构关系图
也可以用这幅图来简单理解一下:(struct file是用双向链表链接起来的,或者一些别的高级数据结构比如红黑树,我也有讲解红黑树和链表的内容,红黑树概念-CSDN博客,红黑树(含代码)-CSDN博客,封装红黑树-CSDN博客,(数据结构)双向链表-CSDN博客,C++中的list(1)-CSDN博客,C++中的list(2)简单复现list中的关键逻辑-CSDN博客)
2. 文件打开流程
- 进程调用
open("test.txt", O_RDWR) - 内核创建新的
struct file对象- 初始化
f_dentry指向 “test.txt” 的 dentry - 设置
f_op为文件系统的操作函数表 f_count = 1
- 初始化
- 在
files_struct中分配文件描述符:- 在
open_fds位图中找到空闲位(假设 fd=3) - 将
files_struct->fd[3]指向新创建的 file 对象
- 在
- 返回文件描述符 3 给进程
3. 文件读写流程
- 进程调用
read(3, buf, size) - 内核通过当前进程的
task_struct->files->fd[3]找到 file 对象 - 调用
file->f_op->read(file, buf, size, &file->f_pos) - 文件系统执行具体读取操作,更新
f_pos
4. 文件关闭流程
- 进程调用
close(3) - 内核将
files_struct->fd[3]设为 NULL - 清除
open_fds位图中对应位 - 减少 file 对象的
f_count - 若
f_count = 0,释放 file 对象
关键机制详解
1. 文件描述符分配
- 初始使用静态数组
fd_array(大小 NR_OPEN_DEFAULT=64) - 当打开文件超过 64 个时:
- 动态分配更大的文件指针数组
- 更新
files_struct->fd指向新数组 - 扩展位图大小
2. 文件描述符与 file 对象的关系
- 多对一关系:
- 多个文件描述符可指向同一个 file 对象(通过
dup())//dup()等会讲 - 每个文件描述符关闭时只减少引用计数
- 只有当所有引用都关闭时,file 对象才被释放
- 多个文件描述符可指向同一个 file 对象(通过
3. 标准输入/输出/错误
- 进程创建时预初始化:
fd_array[0]→ 标准输入(stdin)fd_array[1]→ 标准输出(stdout)fd_array[2]→ 标准错误(stderr)
- 对应的 file 对象在进程创建时初始化
4. 文件位置指针(f_pos)
- 每个 file 对象有自己的
f_pos - 不同文件描述符指向同一文件时:
- 若通过 dup 复制,共享同一个 file 对象和 f_pos
- 若独立 open,有各自独立的 file 对象和 f_pos
5. 文件操作函数表(f_op)
struct file_operations {loff_t (*llseek)(struct file *, loff_t, int);ssize_t (*read)(struct file *, char __user *, size_t, loff_t *);ssize_t (*write)(struct file *, const char __user *, size_t, loff_t *);int (*open)(struct inode *, struct file *);int (*flush)(struct file *);int (*release)(struct inode *, struct file *);// ... 其他操作 ...
};
- 不同文件系统(ext4, proc, sysfs 等)提供不同的实现
- 通过
f_dentry->d_inode->i_fop初始化
示例:从文件描述符到磁盘读取
总结
- 层级关系:
task_struct→ 进程实体files_struct→ 进程的文件描述符表file→ 打开的文件实例
- 文件描述符本质:
- 是
files_struct->fd数组的索引 - 数组元素指向
struct file对象
- 是
- 关键特性:
- 静态数组与动态扩展
- 位图管理打开文件状态
- 文件位置与文件对象绑定
- 通过函数表实现多态(不同文件系统不同行为)
这种设计实现了:
- 高效的文件描述符管理(O(1) 访问)
- 灵活的文件共享机制
- 统一的VFS接口支持多种文件系统
- 安全的权限和状态管理
即使现代内核中这些结构有所变化(如使用RCU、更精细的锁等),这些核心概念仍然适用。
接下来简单给大家讲一下文件描述符的分配机制:(并不是怎么稀奇古怪的东西,只是有些地方大家需要注意一下)
文件描述符基本分配规则
- 最小可用整数原则
- 内核总是分配当前可用的最小非负整数
- 示例:
- 若当前打开 fd:0,1,2,5 → 新分配 fd=3
- 关闭 fd=1 后 → 新分配 fd=1(而非6)
我们使用下面这段代码来观察一下:
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>int main() {close(1);int fd = open("log.txt",O_WRONLY|O_CREAT|O_TRUNC,0666);printf("fd = %d\n",fd);return 0;
}
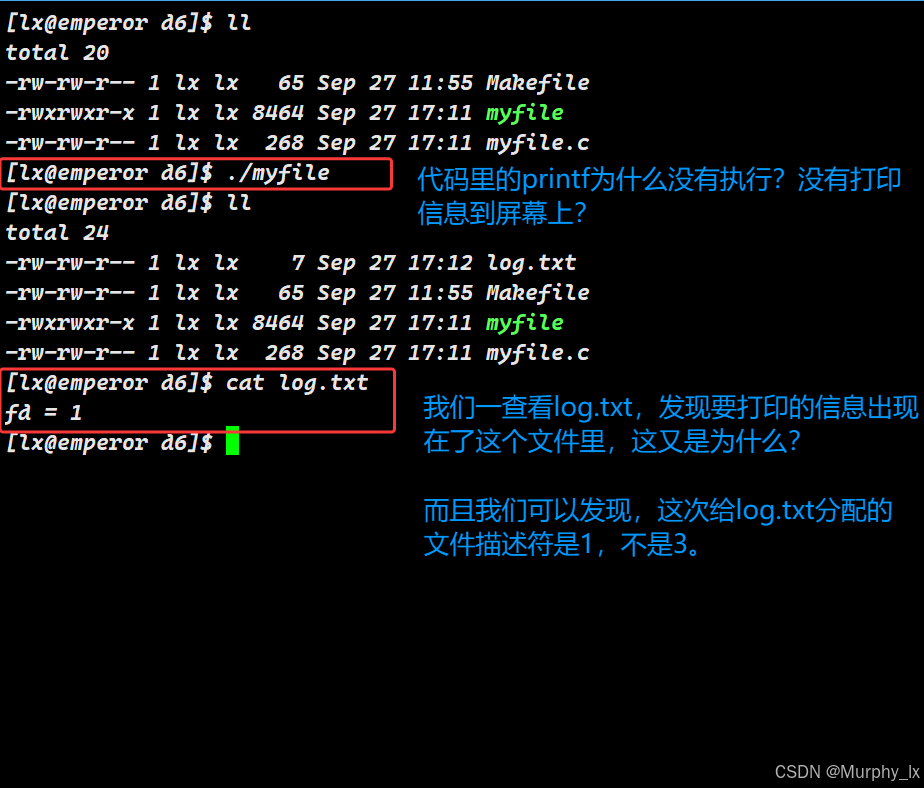
代码中我们使用close函数,close(1)释放了进程文件描述符表中下标为1的条目,使其变为空闲。这个条目之前指向代表“标准输出”的 struct file对象。该对象可能会因为引用计数减为0而被内核回收。
所以当我们新打开一个文件的时候,因为文件描述符的分配规则是:内核总是分配当前可用的最小非负整数,所以新打开的文件的文件描述符就是1。
前面我们说过,printf其实就是fprintf(stdout,...),printf("Hello")本质上等同于 fprintf(stdout, "Hello"),而 fprintf最终会通过 stdout所关联的文件描述符(即 1)执行 write系统调用。
在C标准库中,stdout是一个预定义的 FILE*类型的流(stream)。这个 FILE结构体内部有一个字段(通常是 _fileno)专门用来存储它对应的文件描述符,这个值在程序启动时被初始化为 1。
在C语言层面看来,只要是文件描述符为1的就是标准输出。
所以这个时候,新打开的文件就被C语言认为这是标准输出,从而printf打印的信息没有出现在屏幕上,而是出现在了log.txt里。
重定向过程:
所以说标准输出stdout并没有和屏幕绑定,而是可以根据用户需求灵活变换的。
同理,大家可以试一下下面这段代码:
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>int main() {close(0);int fd = open("log.txt",O_RDONLY,0666);printf("fd = %d\n",fd);int a = 0;scanf("%d",&a);printf("a = %d\n",a);return 0;
}
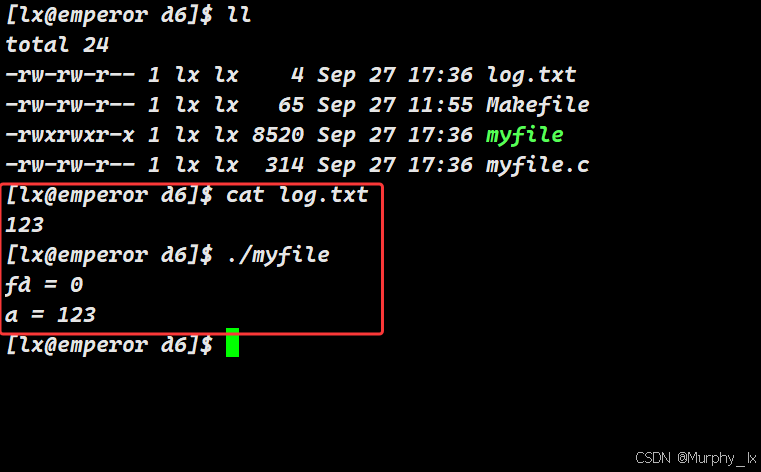
大家去执行这个代码就会发现,程序并不会等待我们去输入,它就直接把结果打印出来了。这是由于我们关闭了文件描述符为0的文件(也就是Linux系统默认帮我们打开的标准输入),然后打开log.txt时,文件描述符被设置为了0。所以scanf的时候,它直接从log.txt中读取信息,而不是从默认的标准输入(“键盘文件”)读取信息。所以a的结果就是123。
重定向过程:
所以以后呢,我们就可以通过close关闭文件,然后再open文件,这样就可以达到一个输入输出重定向的效果。不过这样做肯定是比较拉跨嘛,所以有一个函数是专门干这个事情的,这个函数就是dup2。
dup2()具体解析在:链接:Linux系统中与操作文件相关的系统调用-CSDN博客
所以本文还有一个番外就是写一个包含重定向指令的shell程序:链接:Linux下写一个简陋的shell程序(2)-CSDN博客
- 预设标准描述符
- 进程启动时自动分配:
- 0 = 标准输入(stdin)
- 1 = 标准输出(stdout)
- 2 = 标准错误(stderr)
- 新分配的 fd 从 3 开始
//大家可以用下面这个代码观察一下现象
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>int main() {int fd = open("log.txt",O_WRONLY|O_CREAT|O_TRUNC,0666);printf("fd = %d\n",fd);printf("%d\n", stdin->_fileno);//这里的_fileno其实就是文件描述符printf("%d\n", stdout->_fileno);printf("%d\n", stderr->_fileno);return 0;
}
- 上限限制
- 系统级上限:
/proc/sys/fs/file-max - 用户级上限:
/proc/sys/fs/nr_open - 进程级上限:
ulimit -n(默认通常为1024)