OpenCV3-边缘检测-图像金字塔和轮廓检测
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 1. 边缘检测
- 1.1 Canny边缘检测流程
- 2. 图像金字塔和轮廓检测
- 2.1 轮廓检测
- 2.5 轮廓检测结果
- 2.7 轮廓特征与近似
- 边界矩形
- 外接圆
- 2.3 图像金字塔定义
- 2.4 金字塔制作方法
- 2.2 模版匹配
- 2.6 匹配效果展示
- 总结
前言
1. 边缘检测
1.1 Canny边缘检测流程
- 使用高斯滤波器,以平滑图像,滤除噪声。
- 计算图像中每个像素点的梯度强度和方向。
- 应用非极大值(Non-Maximum Suppression)抑制,以消除边缘检测带来的杂散响应。
- 应用双阈值(Double-Threshold)检测来确定真实的和潜在的边缘。
- 通过抑制孤立的弱边缘最终完成边缘检测。
高斯滤波器
就是去掉噪音点


梯度就是Gx和Gy,方向就是tan

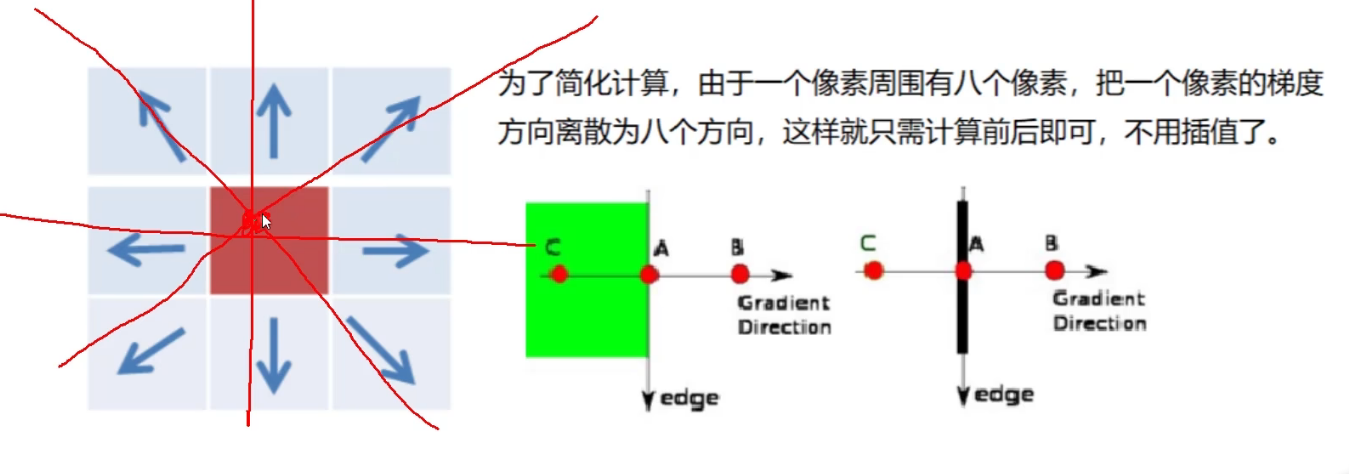
第一A是边界点,第二A比B,C都大的话,梯度方向是横着的,A就保存下来了,然后边界是和梯度垂直的,这样就得出了A的边界
其实就是比较这个点和周围两个点的梯度浮值大小,它是最大的就保存下来,不然就抑制掉
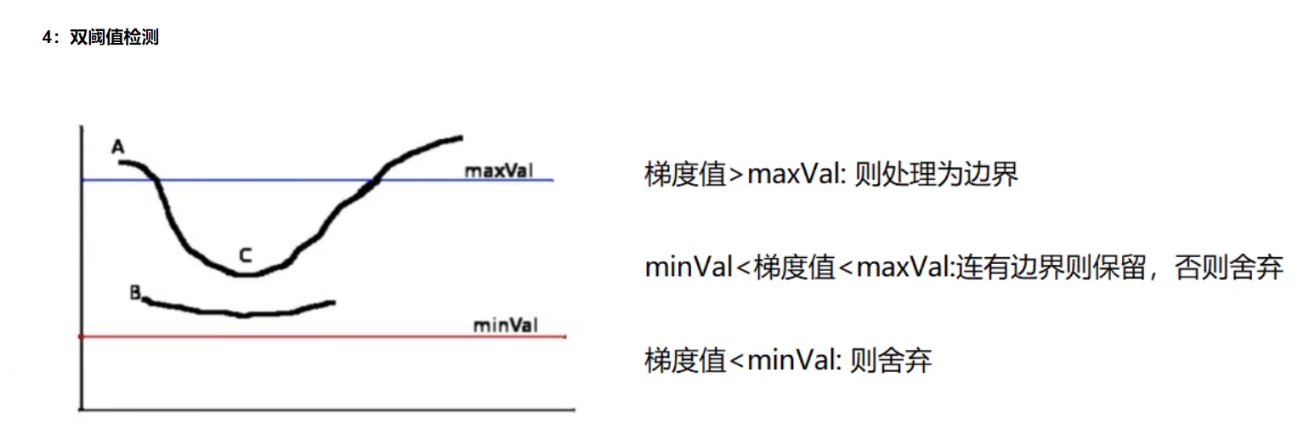
C连有边界A—》C保留
B没有连有边界—》舍弃
img=cv2.imread("../img/lena.jpg",cv2.IMREAD_GRAYSCALE)v1=cv2.Canny(img,80,150)
v2=cv2.Canny(img,50,100)res = np.hstack((v1,v2))
cv_show(res,'res')
Canny就是Canny检测,上面的步骤都是分装好了的,然后80和150就是maxVal和minVal
minVal太小—》要求不高—》边界很多
maxVal太大—》边界太少

50,100比较小,所以显示边界更多–》好像也没那么好看
img=cv2.imread("../img/car.png",cv2.IMREAD_GRAYSCALE)v1=cv2.Canny(img,120,250)
v2=cv2.Canny(img,50,100)res = np.hstack((v1,v2))
cv_show(res,'res')

这个就好像右边的好看了
2. 图像金字塔和轮廓检测
边缘是零零散散的,轮廓是一个整体
2.1 轮廓检测
cv2.findContours(img,mode,method)
mode:轮廓检索模式RETR_EXTERNAL :只检索最外面的轮廓;
RETR_LIST:检索所有的轮廓,并将其保存到一条链表当中;
RETR_CCOMP:检索所有的轮廓,并将他们组织为两层:顶层是各部分的外部边界,第二层是空洞的边界;
RETR_TREE:检索所有的轮廓,并重构嵌套轮廓的整个层次;method:轮廓逼近方法
CHAIN_APPROX_NONE:以Freeman链码的方式输出轮廓,所有其他方法输出多边形(顶点的序列)。
CHAIN_APPROX_SIMPLE:压缩水平的、垂直的和斜的部分,也就是,函数只保留他们的终点部分。
一般用RETR_TREE,就可以了

比如CHAIN_APPROX_NONE是四条线
CHAIN_APPROX_SIMPLE就是四个点了
为了更高的准确率,使用二值图像。
img = cv2.imread('../img/contours.png')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)#灰度图
ret, thresh = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
cv_show(thresh,'thresh')
threshold表示大于127的就是255白,不然就是0黑
这样就二值了

只能是二值
contours, hierarchy = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
contours包含了图像中检测到的所有轮廓的信息,每个轮廓都是由一系列连续的点构成。
2.5 轮廓检测结果
img = cv2.imread('../img/car.png')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
cv_show(thresh,'thresh')
contours, hierarchy = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
contours 给你所有点的坐标;
hierarchy 给你谁套谁的索引表;就是一个层级,现在还用不上
怎么用contours画出来呢
#传入绘制图像,轮廓,轮廓索引,颜色模式,线条厚度
# 注意需要copy,要不原图会变。。。
draw_img = img.copy()
res = cv2.drawContours(draw_img, contours, -1, (0, 0, 255), 2)
cv_show(res,'res')
在副本上画轮廓:
- -1 表示全部轮廓
- (0, 0, 255) = 红色(BGR)
- 2 = 线宽 2 px


这样直接就把轮廓画出来了,在原图的基础上
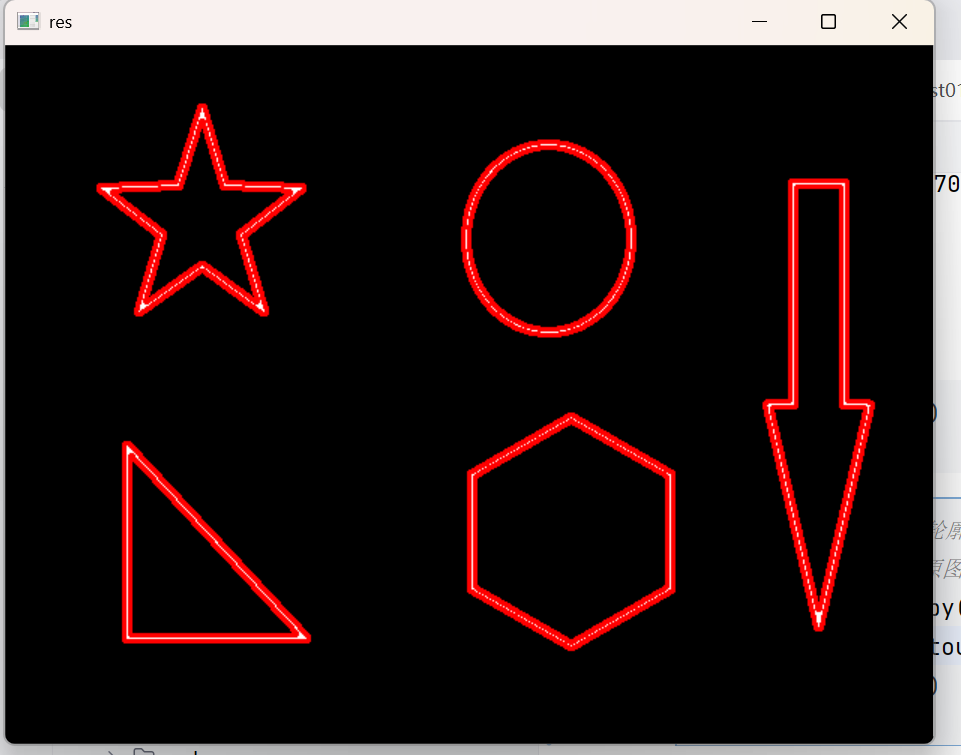
draw_img = img.copy()
res = cv2.drawContours(draw_img, contours, 0, (0, 0, 255), 2)
cv_show(res,'res')
如果不用copy(),那么draw_img 和img就是同一个东西
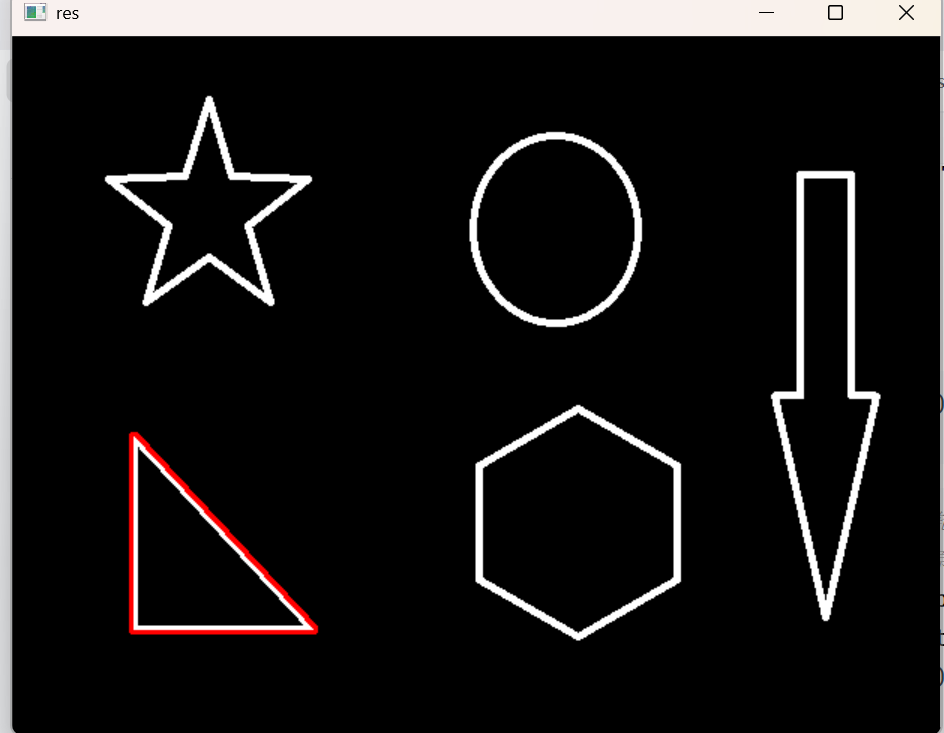
0就表示画第一个轮廓了
1就是表示第二个
2.7 轮廓特征与近似
cnt = contours[0]
#面积
cv2.contourArea(cnt)
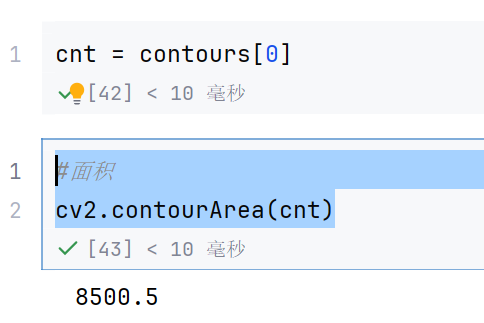
这个意思就是取出第0个轮廓,然后求面积
#周长,True表示闭合的
cv2.arcLength(cnt,True)
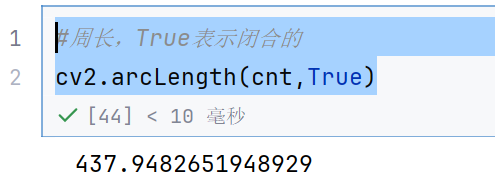
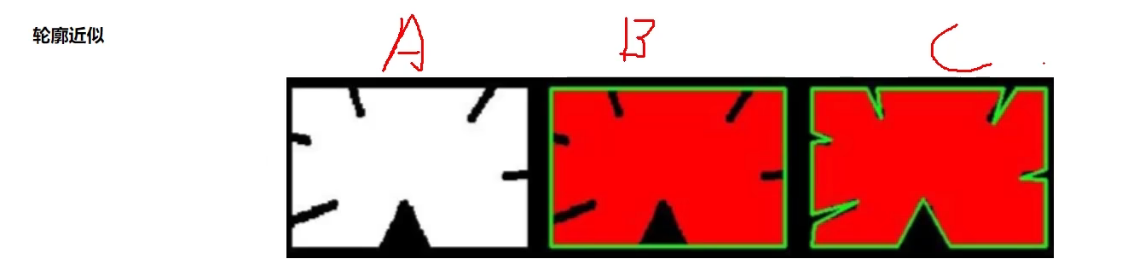
右边两个是两种轮廓近似
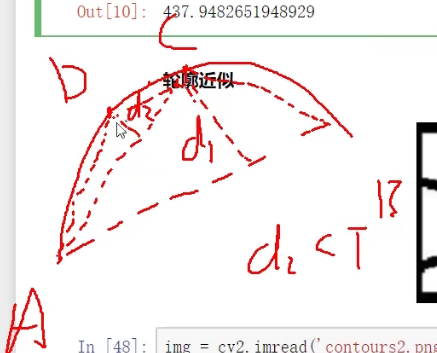
意思就是看一个曲线弯不弯,如果不弯–》最大距离小—》直接看为一个直线
如果很弯–》最大距离大----》看为多个直线
img = cv2.imread('../img/contours2.png')gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
contours, hierarchy = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
cnt = contours[0]draw_img = img.copy()
res = cv2.drawContours(draw_img, [cnt], -1, (0, 0, 255), 2)
cv_show(res,'res')
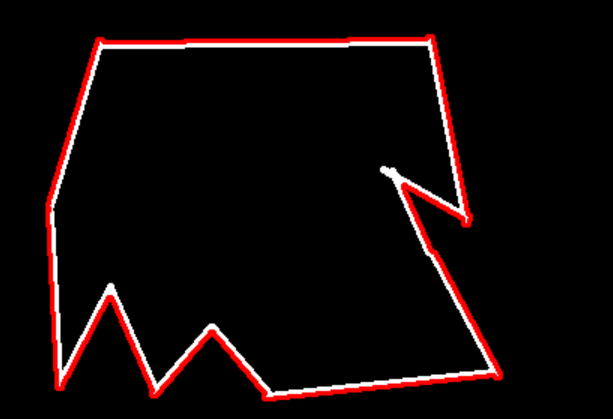
这个是画轮廓,画第0个轮廓
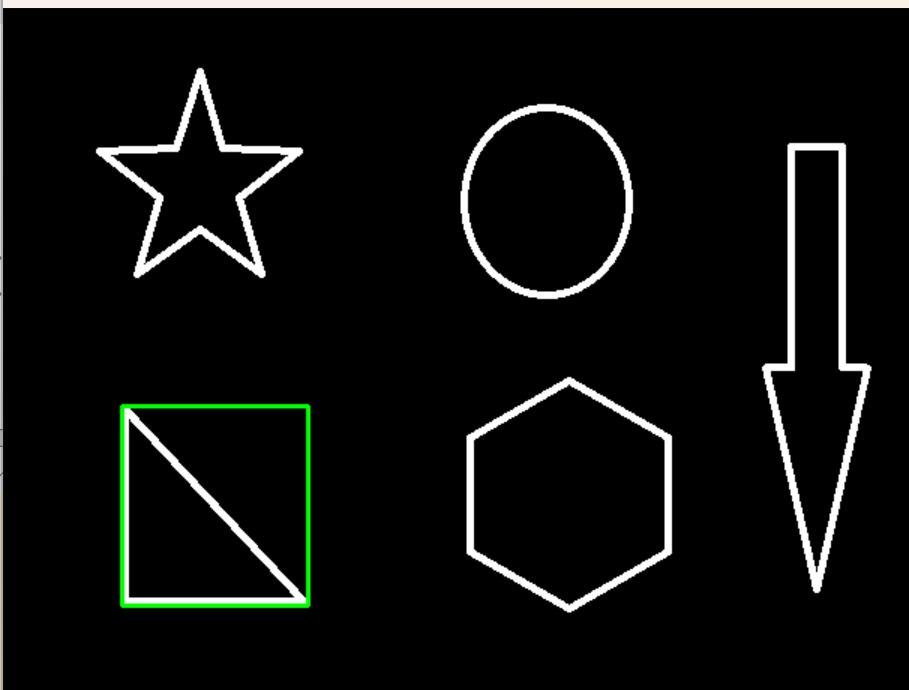
epsilon = 0.15*cv2.arcLength(cnt,True)
approx = cv2.approxPolyDP(cnt,epsilon,True)draw_img = img.copy()
res = cv2.drawContours(draw_img, [approx], -1, (0, 0, 255), 2)
cv_show(res,'res')
approxPolyDP是近似函数
cnt表示是哪个轮廓
epsilon是最大距离比较值,就是最大距离到底大不大的参考值
True 表示 闭合(closed) 拟合:
让算法把轮廓的首尾点当成同一点处理,强制形成封闭多边形。
若写 False,则只生成一条开放折线,首尾不连接,画出来会“缺一条边”。
epsilon = 0.15*cv2.arcLength(cnt,True)
计算轮廓周长,取 15 % 作为最大允许偏差(越大→顶点越少→形状越简化)。
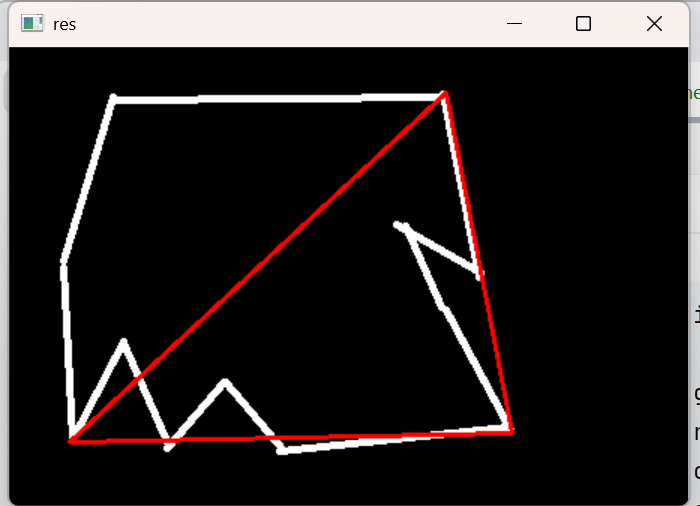
epsilon = 0.05*cv2.arcLength(cnt,True)
approx = cv2.approxPolyDP(cnt,epsilon,True)draw_img = img.copy()
res = cv2.drawContours(draw_img, [approx], -1, (0, 0, 255), 2)
cv_show(res,'res')
我们缩小epsilon ,就画得越精确
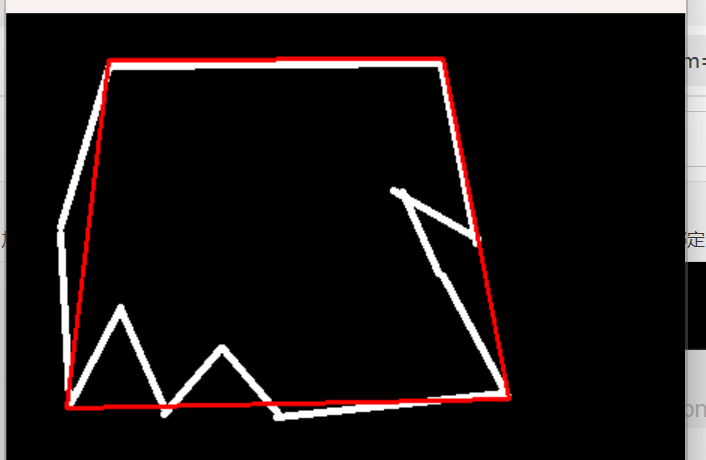
边界矩形
img = cv2.imread('../img/contours.png')gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
contours, hierarchy = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
cnt = contours[0]x,y,w,h = cv2.boundingRect(cnt)
img = cv2.rectangle(img,(x,y),(x+w,y+h),(0,255,0),2)
cv_show(img,'img')
x,y,w,h = cv2.boundingRect(cnt)
计算外接矩形( upright,非旋转)
返回左上角坐标 (x,y) 和宽度 w、高度 h
area = cv2.contourArea(cnt)
x, y, w, h = cv2.boundingRect(cnt)
rect_area = w * h
extent = float(area) / rect_area
print ('轮廓面积与边界矩形比',extent)

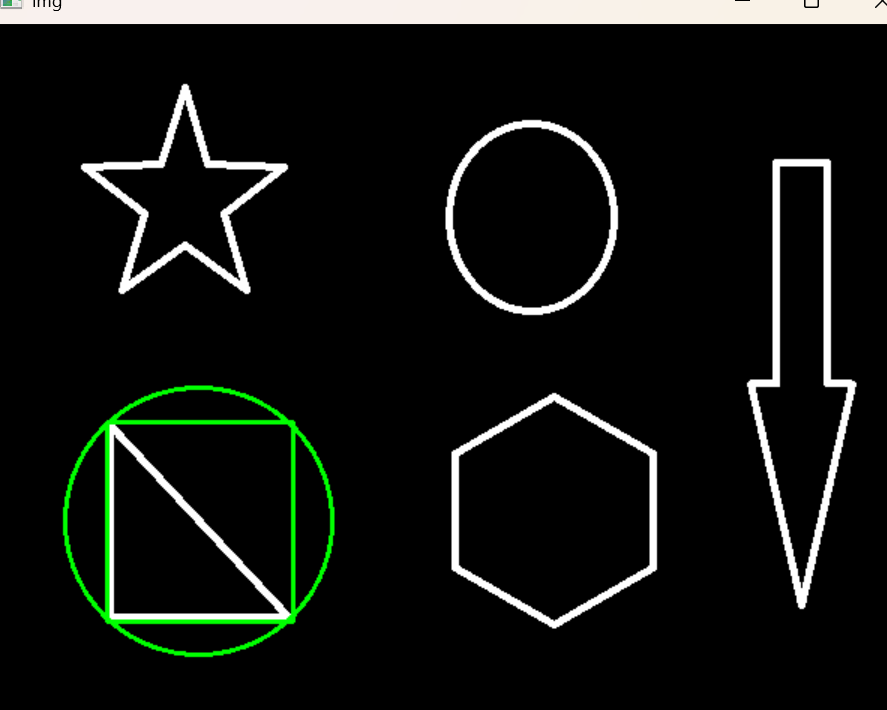
外接圆
(x,y),radius = cv2.minEnclosingCircle(cnt)
center = (int(x),int(y))
radius = int(radius)
img = cv2.circle(img,center,radius,(0,255,0),2)
cv_show(img,'img')
2.3 图像金字塔定义
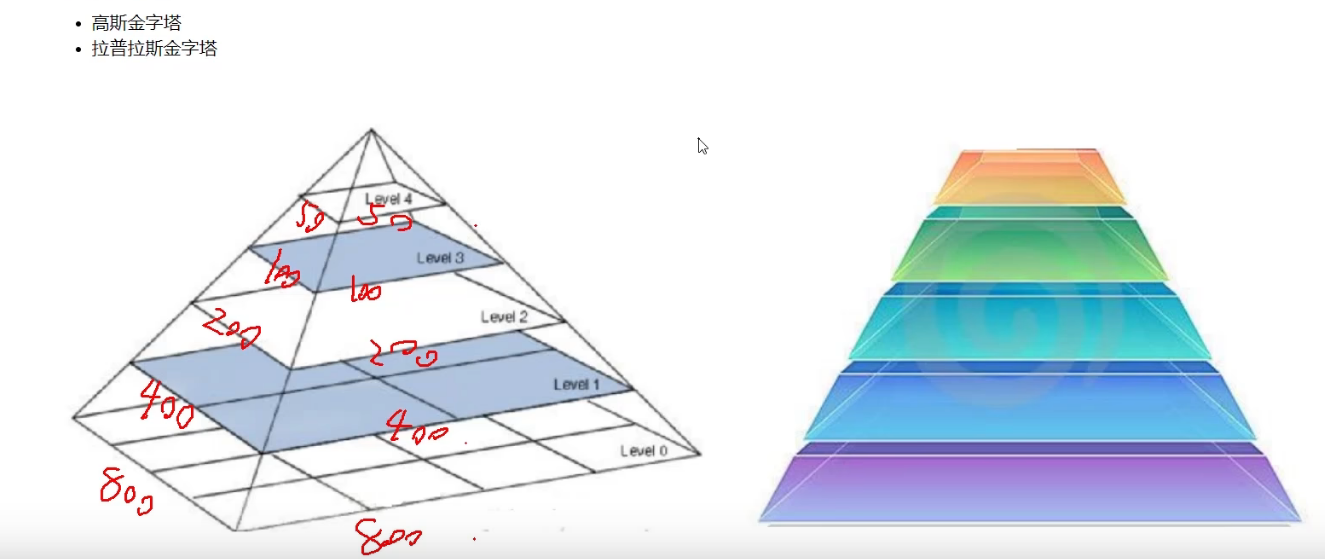
向下采样的意思是形状越来越小,所有是往金字塔尖的方向采样的

就是对应位置相乘,加在一起,最后归一化
然后因为图像变小,所以行和列也要除以变小
向上采样就是从尖到点
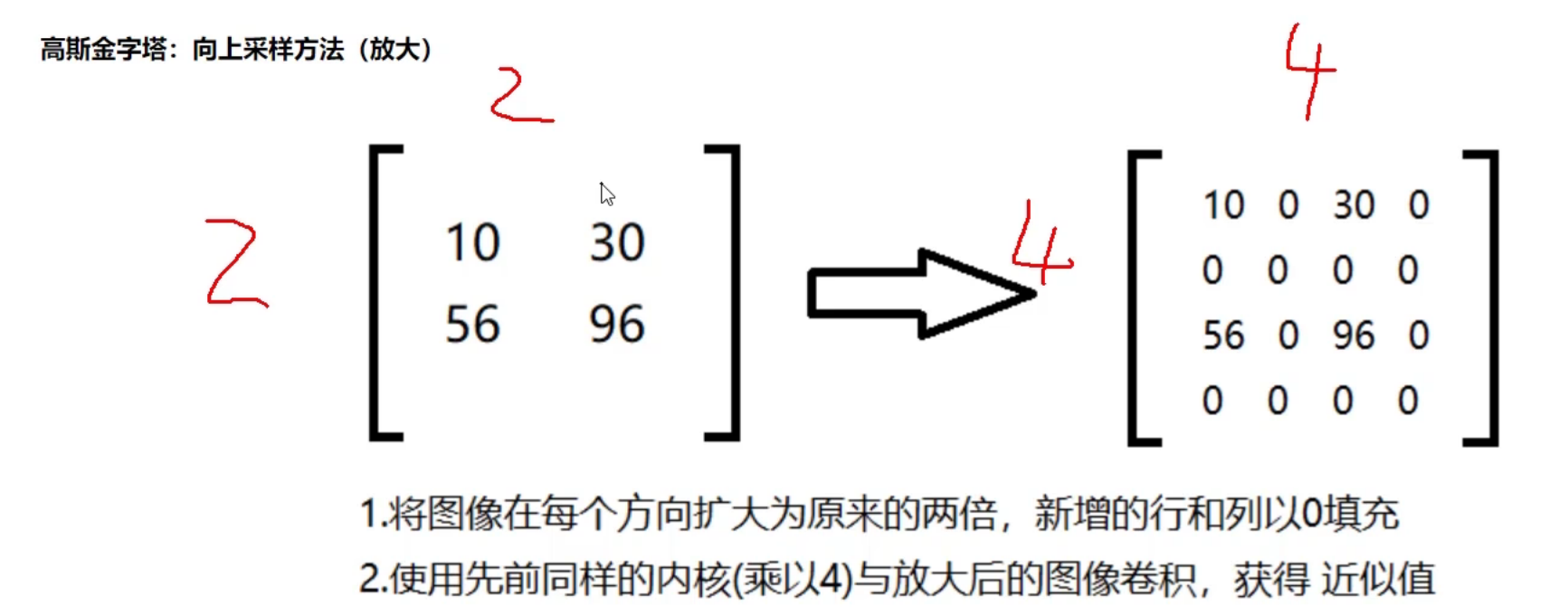
10为11,然后1扩充为22,补充值为0
然后把10的值非给周围2*2的0
2.4 金字塔制作方法
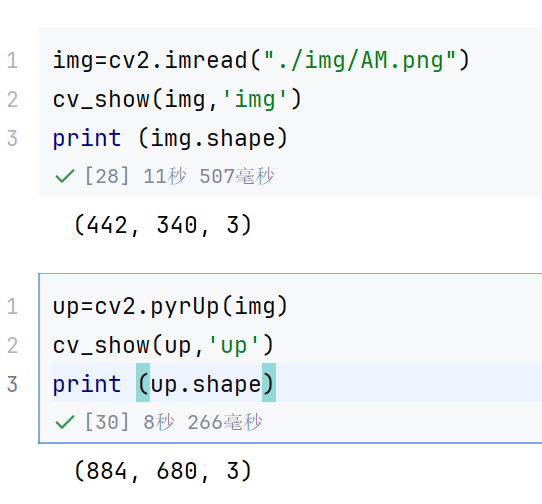
img=cv2.imread("./img/AM.png")
cv_show(img,'img')
print (img.shape)

up=cv2.pyrUp(img)
cv_show(up,'up')
print (up.shape)
这个就是向上采样,变大了
down=cv2.pyrDown(img)
cv_show(down,'down')
print (down.shape)


up2=cv2.pyrUp(up)
cv_show(up2,'up2')
print (up2.shape)
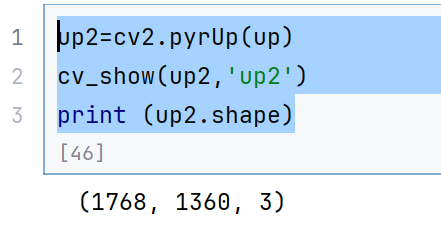
这个就是两次上采样了,非常大了
#%%
up=cv2.pyrUp(img)
up_down=cv2.pyrDown(up)
cv_show(up_down,'up_down')

对一个图片一会上采样,一会下采样,发现变模糊了点,因为上采样用的0填充的
每一次采样都会损失的
cv_show(np.hstack((img,up_down)),'up_down')

拉普拉斯金字塔
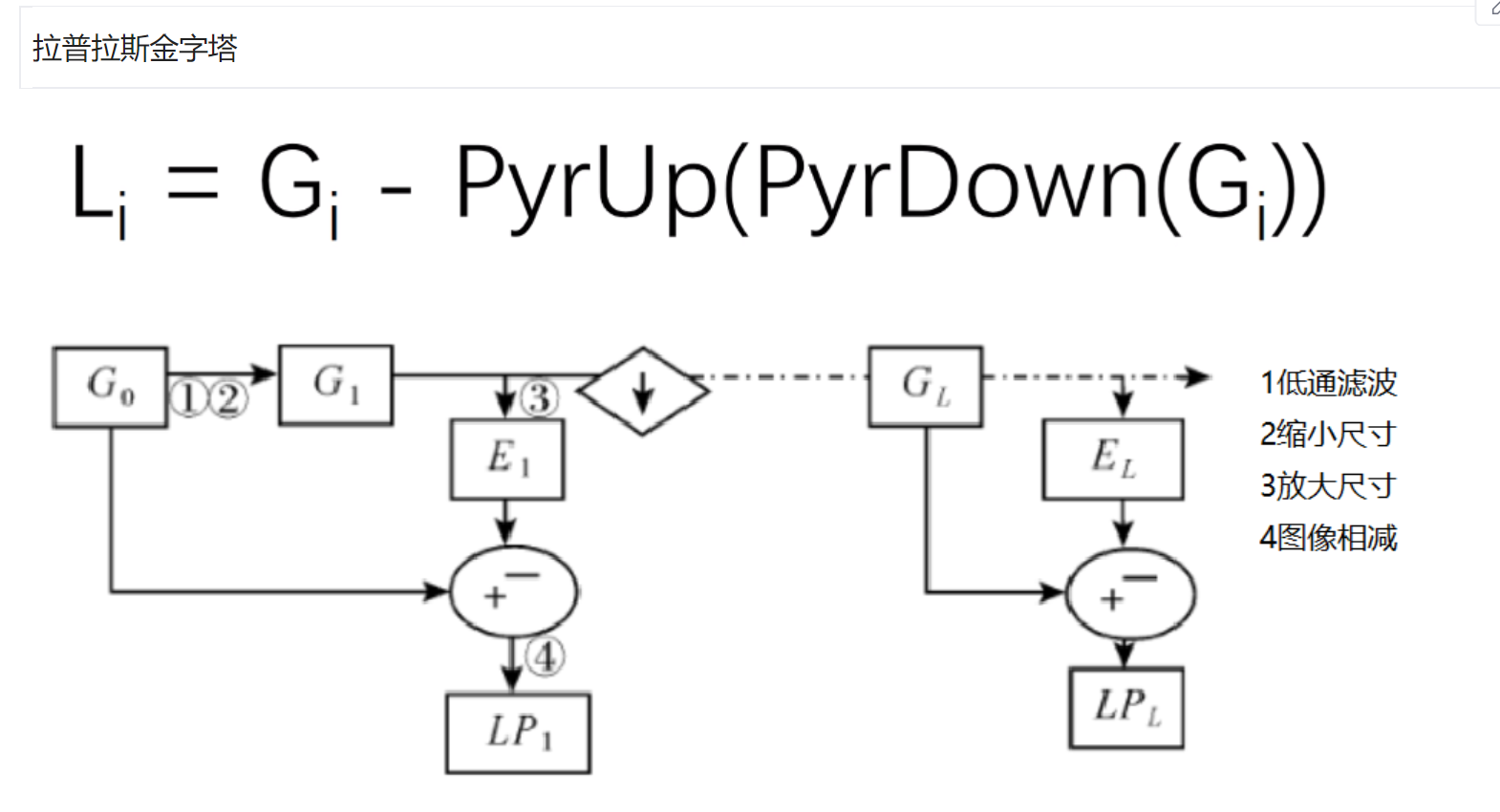
就是原始图像,减去先down在up的图像
然后每一层都是这样处理
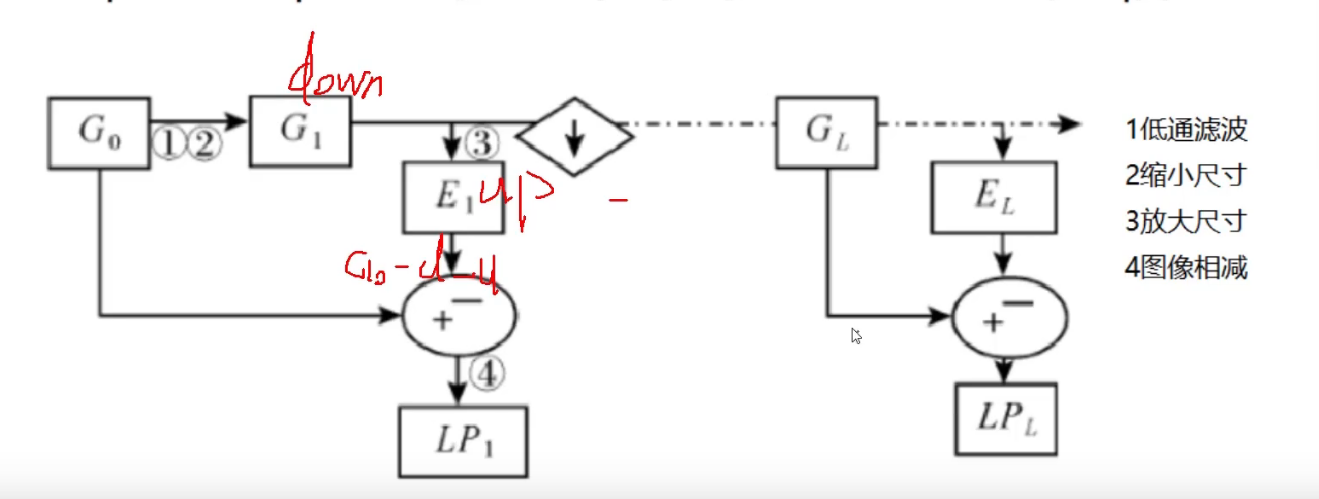
down=cv2.pyrDown(img)
down_up=cv2.pyrUp(down)
l_1=img-down_up
cv_show(l_1,'l_1')

然后还可以弄第二层的
2.2 模版匹配
就是看一个局部图片与另一个图片的各个分部分更像
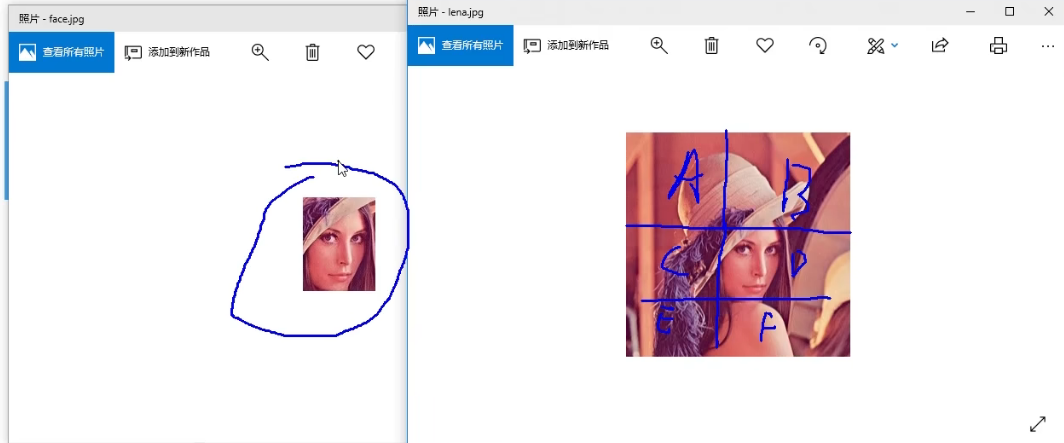
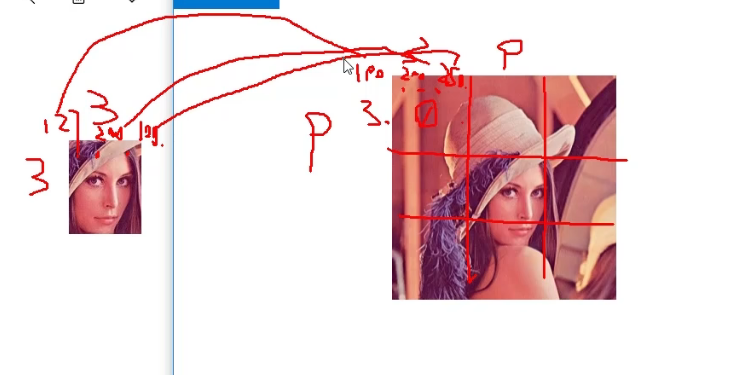
可以一个像素一个像素比,看看差异有多少----》相减,还是相减取平方—》不同算法
返回的是每一个窗口匹配的结果
#模版匹配
img = cv2.imread("./img/lena.jpg",0)
template = cv2.imread("./img/face.png",0)
h , w = template.shape[:2]
h
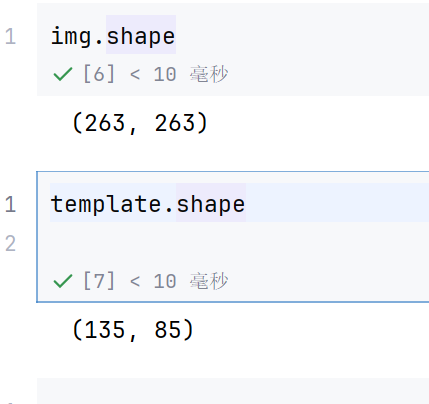
假如原图形是AxB大小,而模板是axb大小,则输出结果的矩阵是(A-a+1)x(B-b+1)
因为是把face图片挨着放入lena图片中比较的,比较完一次,就向右移动一个像素点,比较完一行,就向下移动一个像素点比较
TM_SQDIFF:计算平方不同,计算出来的值越小,越相关
TM_CCORR:计算相关性,计算出来的值越大,越相关
TM_CCOEFF:计算相关系数,计算出来的值越大,越相关
TM_SQDIFF_NORMED:计算归一化平方不同,计算出来的值越接近O,越相关
TM_CCORR_NORMED:计算归一化相关性,计算出来的值越接近1,越相关
TM_CCOEFF_NORMED:计算归一化相关系数,计算出来的值越接近1,越相关
res = cv2.matchTemplate(img, template, cv2.TM_SQDIFF)

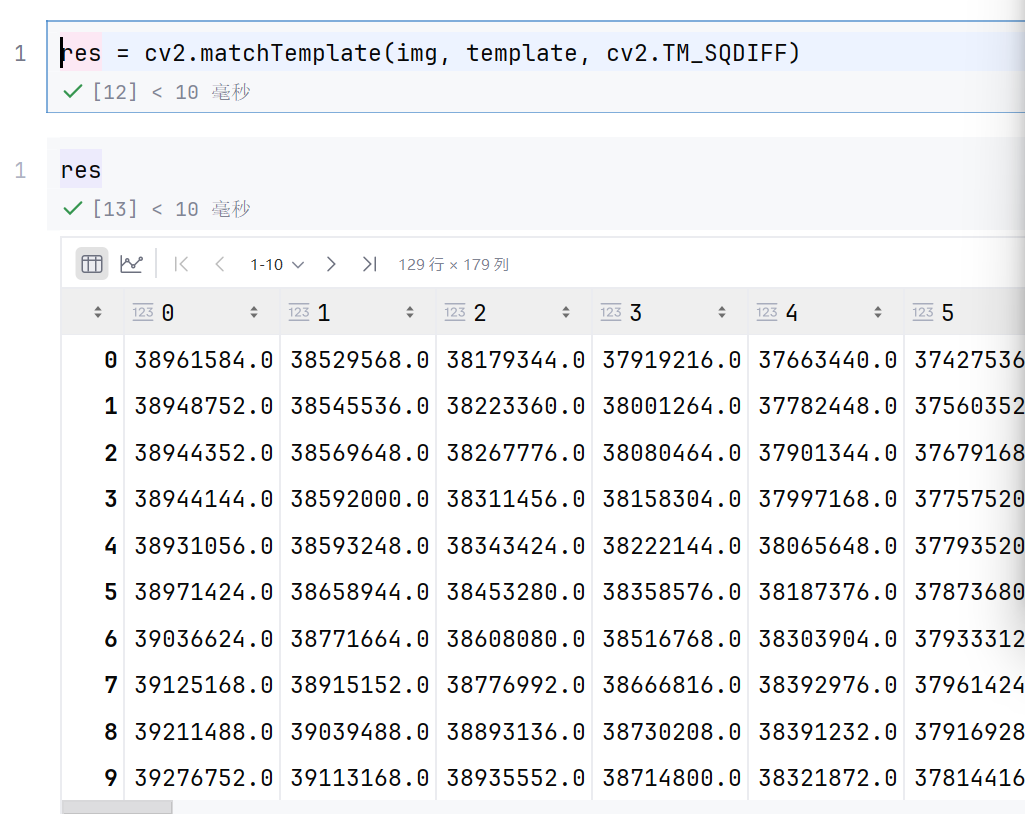
min_val , max_val , min_loc , max_loc = cv2.minMaxLoc(res)
返回的分别是最小值,最大值,最小值位置,最大值位置
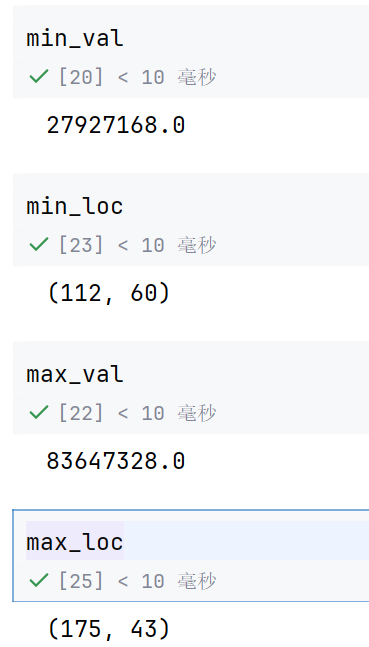
TM_SQDIFF:计算平方不同,计算出来的值越小,越相关
所以min_loc就是最相关的位置

min_loc是左上角的值
然后模版的长和宽都知道了,就可以求出来了
最好用归一化的结果,更可靠
2.6 匹配效果展示
methods = ['cv2.TM_CCOEFF', 'cv2.TM_CCOEFF_NORMED', 'cv2.TM_CCORR','cv2.TM_CCORR_NORMED', 'cv2.TM_SQDIFF', 'cv2.TM_SQDIFF_NORMED']
method = eval(meth) 的作用是:
把字符串变量 meth 当成 Python 表达式执行,并返回表达式的值。
在这段代码里,就是把 字符串形式的 OpenCV 常量名(例如 ‘cv2.TM_CCOEFF’)转换成真正的常量值(例如 cv2.TM_CCOEFF)
meth = 'cv2.TM_CCOEFF' # 字符串
method = eval(meth) # 执行后得到 cv2.TM_CCOEFF 这个整型常量
print(method) # 输出 5(OpenCV 内部数值)
#methods就是TM_CCOEFF,
for meth in methods:img2 = img.copy()#匹配方法的针织method = eval(meth) # 把字符串转成 OpenCV 常量print(method)res = cv2.matchTemplate(img, template, method) # 模板匹配min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res) # 找极值# 平方差类方法取最小值,其余取最大值if method in [cv2.TM_SQDIFF, cv2.TM_SQDIFF_NORMED]:top_left = min_locelse:top_left = max_locbottom_right = (top_left[0] + w, top_left[1] + h) # 计算右下角cv2.rectangle(img2, top_left, bottom_right, 255, 2) # 画结果矩形# ---------- 可视化 ----------plt.subplot(121), plt.imshow(res, cmap='gray')plt.xticks([]), plt.yticks([]) # 隐藏坐标轴plt.subplot(122), plt.imshow(img2, cmap='gray')plt.xticks([]), plt.yticks([])plt.suptitle(meth) # 图标题 = 方法名plt.show()

cv2.rectangle(img2, top_left, bottom_right, 255, 2) 的含义:
作用:在图像 img2 上画一个矩形框,标出模板匹配到的位置。
参数解释:
img2:目标图像(画框的载体)
top_left:矩形左上角坐标 (x, y)
bottom_right:矩形右下角坐标 (x, y)
255:矩形颜色(灰度图用 255 表示白色,RGB 图用 (0, 0, 255) 表示红色)
2:线条厚度(2 像素)
其中打印的res表示的每个像素点 模板的“相似度得分”,就是返回的每一个窗口得到的结果值
所以
打印出来的是一张“相似度表格”,用 imshow 就能变成热度图。
亮的位置说明比较相近度比较相近
那如何用目标在模版中匹配多个相近的呢,就是匹配多个对象
# 读取原图(彩色)
img_rgb = cv2.imread('./img/mario.jpg')
# 转成灰度图,加快匹配速度
img_gray = cv2.cvtColor(img_rgb, cv2.COLOR_BGR2GRAY)
# 读取模板(硬币)并取尺寸
template = cv2.imread('./img/mario_coin.jpg', 0)
h, w = template.shape[:2]
# 模板匹配:归一化相关系数法(越大越像)
res = cv2.matchTemplate(img_gray, template, cv2.TM_CCOEFF_NORMED)# 阈值:只保留相似度 ≥ 80% 的区域
threshold = 0.8
loc = np.where(res >= threshold) # 返回 (行索引数组, 列索引数组)# 遍历所有满足条件的点(*号解包,[::-1] 把 (row, col) 换成 (x, y))
for pt in zip(*loc[::-1]):# 计算右下角坐标bottom_right = (pt[0] + w, pt[1] + h)# 在原图上画红色矩形框cv2.rectangle(img_rgb, pt, bottom_right, (0, 0, 255), 2)# 显示结果
cv2.imshow("img_rgb", img_rgb)
cv2.waitKey(0)
cv2.destroyAllWindows()
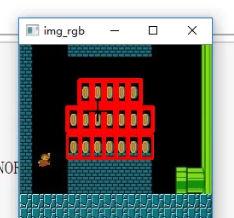
这样就找出来了多个金币了