使用Ray进行大规模并行智能体仿真
https://www.anyscale.com/blog/massively-parallel-agentic-simulations-with-ray 译文
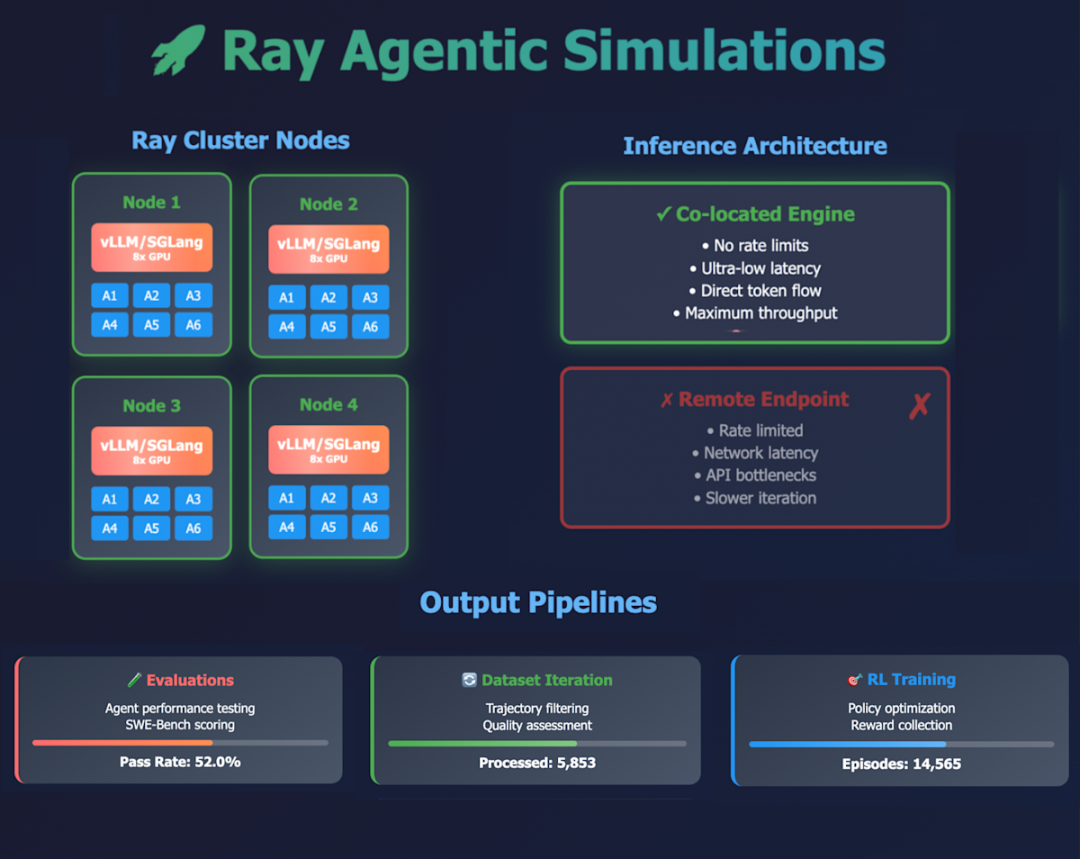
虽然在笔记本电脑上针对托管模型endpoint(如ChatGPT、Claude、Gemini或开源模型的模型提供商)运行单个智能体很容易,但在集群上并行运行成千上万个智能体则是一个重大挑战。这也是许多非常有用的LLM和智能体应用场景的重要诉求,包括以下场景:
a.运行评估: 智能体评估被用于智能体应用开发的内部循环中。它们对于帮助构建更好的LLM、为LLM编写更好的提示或改进智能体循环本身至关重要。
b.迭代数据集: 构建智能体依赖于问题陈述的数据集和验证解决方案的技术。智能体仿真使我们能够迭代这些数据集,过滤和改进它们,并为监督式微调收集解决方案轨迹。
c.运行强化学习(RL)训练: 智能体仿真是强化学习训练循环的重要组成部分。它们用于收集轨迹和奖励,这些轨迹和奖励用于通过强化学习更新策略。
当您从在笔记本电脑上运行单个智能体扩展到并行运行大量智能体时,您可能会遇到以下挑战:
-
隔离智能体:智能体需要被隔离,这样它们就不会相互干扰,也不会干扰系统的其他部分,并保持在合理的资源限制内。此外,智能体需要在定义明确的环境(如容器)中运行。
-
扩展模型推理和工具使用:如果您并行运行大量智能体,模型提供商的速率限制通常不够用,因此您需要弄清楚如何扩展推理。您可能还会使用需要随智能体一起扩展的通用工具,如MCP服务器。
-
使用自定义模型:如果您正在构建定制的智能体,很可能您也会训练或微调需要部署的自定义模型。
大多数这样的设置都涉及大量的样板代码和复杂的基础设施。
Ray 凭借简洁的 Python 风格 API,可直接应对上述挑战,支持大规模并行智能体仿真。它能够处理 CPU 与 GPU(或其他加速器)混合的工作负载,并支持推理服务器(如 vLLM 或 SGLang)等有状态服务。这使得推理过程可与仿真在同一集群中运行,从而实现模型与智能体的快速联合实验,以及联合扩展以避免模型速率限制问题。Ray 便捷的 Python 开发体验,便于对实验配置进行迭代,并能无缝扩展到超大规模运行场景。此外,Ray 的容错能力支持使用抢占式实例,有助于降低成本。
通过阅读本篇博客文章,你将了解到以下内容:
-
如何运行多个具备灵活隔离能力的沙箱环境,确保沙箱可在任意环境(非特权环境、容器嵌套环境等)中运行,无需单独搭建沙箱环境。
-
如何在单个 Ray 集群中同时运行推理和智能体执行任务,实现智能体与大语言模型设置的快速迭代,避免速率限制问题,同时轻松扩展并行智能体的数量。
-
针对上述三种应用场景(运行评估、数据集迭代、强化学习训练)的具体实例,以及一系列提升效率、简化迭代过程的实用技巧。
我们将以软件工程领域为背景,演示这些关键要点。为此,我们还开源了一个新数据集,其中包含从 cpython 代码仓库中抓取的 5500 个测试用例,并展示如何对其进行并行评估。文中所演示的技术具有通用性,同样适用于通用计算机使用、数据工程、科学研究等其他领域。
并行智能体仿真的隔离
在进行大量并行智能体仿真时,核心问题之一是如何实现智能体之间以及与系统环境的隔离。具体有以下几种方案可供选择:
-
基于容器的全文件系统隔离:Docker 是众多软件工程师熟知的行业标准,在非对抗性场景下,容器非常适合隔离工作负载,因此成为运行智能体的常用方式。不过,Docker 也存在一些缺点:容器镜像的构建、推送、拉取和存储成本较高,且速率限制问题较为繁琐。此外,在超级计算机或其他容器内部等非特权环境中运行 Docker 也颇具挑战性。通过使用 Podman 或 Apptainer 等其他容器Runtime,可在一定程度上解决部分问题(下文将展示具体实现方法)。
-
基于控制组(cgroups)和根目录切换(chroot)的进程隔离:通过 Linux 控制组(cgroups)和根目录切换(chroot)对进程进行隔离,是一种更轻量级的智能体运行方式。从底层实现来看,容器技术的原理与之类似,但直接使用这些基础技术,能更灵活地控制隔离过程。例如,在这种方式下,主机的大部分文件系统和软件包可被复用,智能体无需拉取和推送容器镜像,同时仍能实现良好的隔离效果。尽管从零开始实现该方案复杂度较高,但借助 bubblewrap 等便捷的命令行工具,可简化操作流程(下文将展示具体实现方法)。
-
基于虚拟机(VM)或远程执行的隔离:在某些场景下,需要更重量级的隔离机制。例如,若要在 Mac 系统上运行 Linux 应用,或在 ARM 架构设备上运行 x86_64 架构应用,就需要借助虚拟机。在极少数情况下,若容器或控制组提供的隔离程度无法满足需求,虚拟机或微虚拟机可能是更合适的选择。此外,你也可能希望使用独立的 Kubernetes 集群或借助其他云服务提供商来执行智能体。与容器或控制组等较简单的隔离方式相比,这些方案通常需要更多的基础设施层面工作,例如额外的错误处理和通信机制配置。
容器是目前最通用且应用最广泛的隔离机制,能与现有生态系统良好集成,因此在多数情况下应作为首选方案。而借助 bubblewrap 等工具实现的进程隔离方式,其应用潜力尚未得到充分挖掘。这种方式极为轻量,便于迭代,还可与 uv 等包管理器、Linux 发行版原生包管理器,或 NixOS、Guix 等技术结合使用,灵活定义智能体运行所需的环境。为了能针对不同场景选择最适合的隔离方式,我们的部署方案应具备灵活的环境支持能力。
智能体仿真的智能体框架
智能体框架围绕大语言模型构建,旨在使其能有效解决特定领域的问题(本文以软件工程领域为例)。该框架主要包含以下组成部分:
-
给大语言模型的提示词:通常以模板形式呈现,包含 GitHub 问题描述、软件仓库中特定操作指令等占位符内容。
-
大语言模型可使用的工具:如 Shell 命令、文件编辑工具、Python 解释器、用于收集问题与解决方案相关信息的搜索工具,以及任何可通过 MCP 服务器形式提供的其他工具。
-
智能体循环:该循环会反复向大语言模型发起查询,并执行其输出的操作。此外,它还可与用户进行交互式沟通,允许用户调整大语言模型提出的行动方案。
尽管本文聚焦于软件工程领域,但这种框架设计具有通用性,同样适用于通用计算机操作、数据科学工作负载、科学研究等其他专业领域。
部分智能体框架支持对大语言模型的操作进行多种形式的沙箱隔离。有些框架专为终端用户设计,用于解决特定问题;还有些框架则针对大规模实验(如评估或强化学习训练)进行了优化。尽管这些应用场景需要不同的解决方案,但理想情况下,它们应共享相同的提示词和工具调用逻辑,以确保在实验数据集上进行的各类实验,能直接反映终端用户的实际使用体验。以下是一些我们已知的软件工程领域智能体框架:
-
终端用户常用框架:这类框架通常支持交互式使用,例如 Claude Code、Gemini CLI、Qwen Code 和 Aider。它们一次仅支持一个会话,一般不提供沙箱隔离功能,但可与实际工作负载环境一同在容器中运行。其中部分框架也可适配,用于评估或强化学习训练等场景。
-
OpenHands:一款功能全面的热门智能体Runtime,既可供终端用户使用,也适用于评估和强化学习训练场景(附带评估工具集)。它主要基于 Docker 构建,还提供远程 Kubernetes Runtime。该框架对 MCP 服务器、浏览器、自定义工具等各类工具均有良好的通用支持。
-
SWE-agent:由 SWE-bench 作者开发的智能体,可用于解决软件工程问题。其轻量版本 mini-swe-agent 在隔离方式上灵活性最高,代码简洁且易于修改,能轻松适配各类工作负载。仅通过 bash 命令,它就能在软件工程任务中表现出色。
-
Terminal-bench:一款针对终端操作任务的智能体基准测试工具,包含用于适配其他基准测试(如 SWE-Bench)的评估工具集,以及名为 Terminus 的内置智能体框架。所有任务均以 Docker 镜像形式封装,评估工具集会为每个任务启动一个容器化环境。
-
R2E-Gym:提供类 Gym 的环境接口以及智能体包装器,不过更侧重于仿真和强化学习工作负载。它支持文件编辑器、bash、文件搜索等工具。
-
Smolagents:Hugging Face 旗下的一个库,同样注重轻量设计,同时具备更多集成功能,支持多种工具调用,并可通过 Docker 或 E2B 在沙箱环境中执行任务。
在本文中,我们选用 mini-swe-agent,主要因其代码简洁、易于修改,且无需额外复杂配置就能在软件工程问题中展现出良好性能。不过,下文演示的方法同样适用于其他框架。
cpython 问题数据集
本文使用的数据集源自 cpython 代码仓库,结构简单。类似的数据集也可从其他众多代码仓库中生成。该数据集采用简化的 SWE-bench 格式,专为运行完整测试套件进行验证而优化。我们从 cpython 仓库中抓取了约 5500 个问题,找到对应的拉取请求(PR),并提取出 base_commit(PR 的父提交)和 merge_commit(包含 PR 代码的提交)。该数据集可通过链接获取,用于抓取数据集的代码也可通过链接查看。
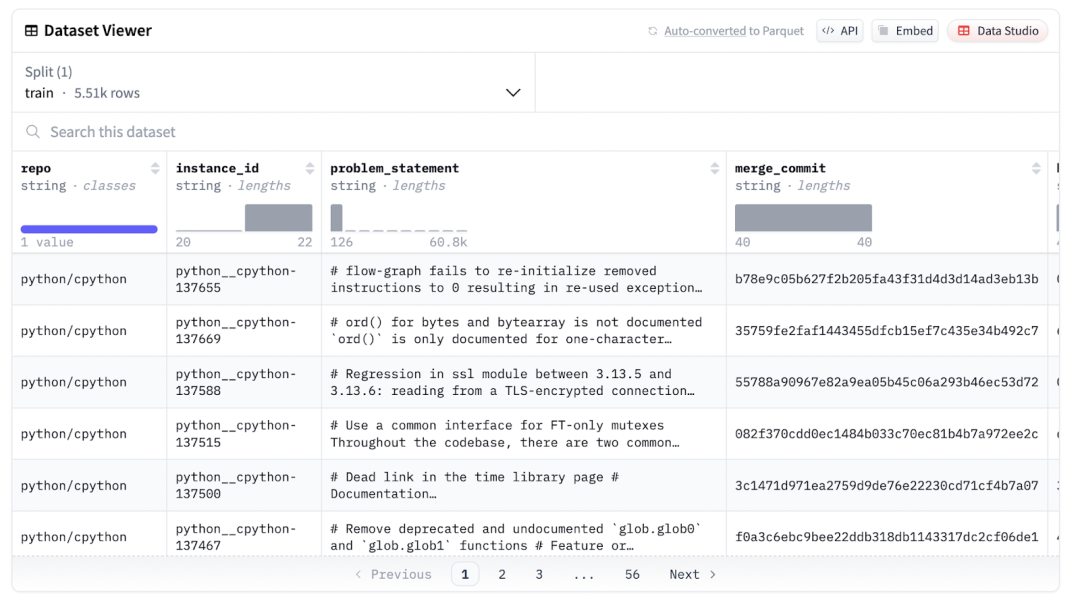
对于大语言模型生成的补丁 (patch),可按以下步骤进行验证:
-
基于 base_commit 检出 cpython 仓库代码。
-
应用大语言模型生成的补丁,但排除 Lib/test/* 目录下的修改(既避免下一步操作中出现冲突,也防止大语言模型删除或 “修复” 测试用例)。
-
在 Lib/test/* 目录下,应用原始 PR 差异(base_commit..merge_commit)中的修改(这些是人类在修复该问题的 PR 中添加的回归测试)。
-
执行 ./configure && make test 命令运行完整测试套件。在实际操作中,为确保测试稳定运行,需排除部分经常失败的测试用例。幸运的是,cpython 提供了 EXTRATESTOPTS 环境变量,可用于向测试套件传递额外参数。我们利用该机制,通过 --ignore 标志排除失败的测试用例。
在下一节中,我们将展示如何借助 Ray 并行生成补丁并进行验证。
使用 mini-swe-agent
在本文后续内容中,我们将使用 mini-swe-agent 作为人工智能智能体,主要因其轻量简洁、易于修改,且支持多种沙箱环境来执行智能体操作。凭借其简洁的特性,人们也能轻松研究其原理,并将其适配到软件工程之外的其他问题领域。mini-swe-agent 的一项关键设计决策,极大地简化了操作流程:智能体的每一个操作都对应一条简单的 bash 命令,无需持久化的 Shell 会话。此外,mini-swe-agent 支持多种隔离环境:
-
本地执行:直接在 bash 命令中执行每条指令,不进行特殊隔离。这种方式不建议在无用户交互的场景下使用,但适用于本地交互式操作 —— 用户可在执行每条命令前对其进行检查。
-
容器环境执行:支持通过 Docker、Podman 或 Apptainer 等工具在容器环境中执行。若选择容器进行隔离,我们通常优先选用 Podman,因为它无需守护进程,且可配置在多种环境(包括容器内部和非特权环境)中运行。在超级计算机上运行时,Apptainer 是不错的选择。
-
bubblewrap 进程隔离执行:借助 bubblewrap 工具对进程进行隔离,无需搭建和维护容器镜像的开销,就能实现隔离环境运行。该功能可通过此环境配置启用。例如,我们可使用它来搭建 cpython 环境;结合启动命令,还能构建更复杂的环境,如为处理 Python 代码库的软件工程智能体配置基于 uv 的 Python 虚拟环境。
安装并运行 Podman 以使用 mini-swe-agent
sudo apt-get -y install podman# The following is required if you want to run podman inside of a container
sudo cp /usr/share/containers/containers.conf /etc/containers/containers.conf && sudo sed -i 's/^#cgroup_manager = "systemd"/cgroup_manager = "cgroupfs"/' /etc/containers/containers.conf && sudo sed -i 's/^#events_logger = "journald"/events_logger = "file"/' /etc/containers/containers.conf
sudo apt-get install containers-storage
sudo cp /usr/share/containers/storage.conf /etc/containers/storage.conf
sudo sed -i 's/^#ignore_chown_errors = "false"/ignore_chown_errors = "true"/' /etc/containers/storage.conf
# Depending on your execution environment (e.g. if some privileges are missing or if you need access to e.g. GPUs), you might also want to add some of the options from https://github.com/containers/podman/issues/20453#issuecomment-1912725982在已检出 mini-swe-agent 代码(代码仓库:https://github.com/SWE-agent/mini-swe-agent)的目录下,执行以下命令:
uv run --extra full mini-extra swebench --model openai/gpt-5-nano --subset verified --split test --workers 128 --output <output directory>为确保该基准测试成功运行,需在 swebench.yaml 文件中设置以下参数:在 environment 配置项下,添加 executable: "podman",同时设置 timeout: 3600 和 pull_timeout: 1200。
对于这类需要拉取大量容器镜像的工作负载,建议使用配备本地 NVMe 磁盘的机器。若在 AWS 上的 Anyscale 平台运行,系统会自动将这些磁盘配置为 RAID 阵列,以实现最佳性能。
借助 Ray 运行并行软件工程仿真
本节将展示如何利用 Ray 和 mini-swe-agent 运行大量并行仿真。我们将重点关注基于前文介绍的 cpython 问题数据集、类似 SWE-bench 风格的软件工程任务,但这些思路同样广泛适用于各类仿真环境。
从智能体生成数据
本节将提供一个简单有效的代码示例,用于从智能体生成轨迹数据。通过名为 Engine 的 Actor(Ray 中的分布式计算单元),我们在集群的每个节点上启动一个 vllm 或 sglang 服务器,然后借助 Ray tasks generate_rollout(每个问题陈述对应一个任务),针对这些服务器运行大量并行仿真。每个任务都会使用 mini-swe-agent 中的 swebench-single 脚本生成轨迹。这种部署方式简化了推理配置,因为我们可直接使用 vllm 和 sglang 的命令行界面(CLI)启动推理引擎。此外,也可采用其他方案,例如借助 Ray Serve LLM 部署集中式大语言模型引擎,并将模型暴露为所有智能体可连接的全局endpoint,或结合 sglang 路由器使用 sglang。
import requests
import subprocess
from pathlib import Pathfrom datasets import load_dataset
import rayENGINE_ADDRESS = "http://127.0.0.1:8000"@ray.remote(num_gpus=8)
class Engine:def __init__(self, model: str):self.model = modelself.engine_process = subprocess.Popen(["/usr/local/bin/uv", "run", "--with", "vllm","vllm", "serve", self.model,"--tensor-parallel-size", "8","--max-model-len", "64000", "--enable-expert-parallel",# You can add --data-parallel-size if you want to use# data parallel replicas in addition to tensor and expert parallel"--enable-auto-tool-choice", "--tool-call-parser", "qwen3_coder"],)# If you want to use sglang instead, use the following code:# self.engine_process = subprocess.Popen(# ["/usr/local/bin/uv", "run", "--with", "sglang[all]",# "-m", "sglang.launch_server",# "--model-path", self.model, "--tp-size", "8",# "--enable-ep-moe", "--host", "0.0.0.0", "--port", "8000"],# )def wait_for_engine(self):while True:try:result = requests.get(ENGINE_ADDRESS + "/health", timeout=10)except requests.exceptions.ConnectionError:continueif result.status_code == 200:return@ray.remote(num_cpus=1, scheduling_strategy="SPREAD")
def generate_rollout(model: str, dataset_name: str, instance_id: str, target_dir: str):model_path = "hosted_vllm/" + modeltarget_path = Path(target_dir) / instance_id/ f"{instance_id}.traj.json"result = subprocess.run(["/usr/local/bin/uv", "run", "mini-extra", "swebench-single","--model", model_path, "--subset", dataset_name,"--split", "train", "--instance", instance_id,"--environment-class", "bubblewrap","--output", target_path,],env={"HOSTED_VLLM_API_BASE": ENGINE_ADDRESS + "/v1","LITELLM_MODEL_REGISTRY_PATH": "/mnt/shared_storage/pcmoritz/model_registry.json",},capture_output=True,)return result# For this example, we use 5 nodes with 8 GPUs each
num_shards = 5
model = "Qwen/Qwen3-235B-A22B-Instruct-2507-FP8"
dataset_name = "pcmoritz/cpython_dataset"
dataset = load_dataset(dataset_name, split="train")executors = [Engine.remote(model) for i in range(num_shards)]
ray.get([executor.wait_for_engine.remote() for executor in executors])results = []
for record in dataset:result = generate_rollout.remote(model,dataset_name,record["instance_id"],"/mnt/shared_storage/pcmoritz/rollouts")results.append(result)ray.get(results)在本实验中,我们将环境类设置为 bubblewrap,以确保同一机器上运行的所有智能体相互隔离,并与系统环境隔离。同时,我们将结果写入共享 NFS 卷,以便在下一步进行后续后处理和筛选。通常,将轨迹文件和其他输出文件(如日志)写入 NFS 是一种实用方案,这不仅便于查看部分进度,还能在生成脚本重新执行时,从上次中断处恢复进度(类似传统数据处理中的行级 checkpoint 机制)。
在上述配置中,有多个参数可根据需求调整:
-
vLLM 引擎参数:包括各类并行策略(张量并行、专家并行、数据并行等),具体可参考 vLLM 优化指南。最佳配置通常取决于硬件条件和所用模型的架构。
-
每个引擎对应的智能体数量:可通过调整 generate_rollout 装饰器中的 num_cpus 参数来控制(增大该值可减少每个引擎对应的智能体数量)。实践表明,每个引擎搭配 64-128 个智能体效果较好。最优智能体数量取决于环境中消耗的时间(CPU 工作)与大语言模型评估消耗的时间(GPU 工作)的比例:该比例越高,所需智能体数量越多,才能确保有足够大的批处理规模,使推理引擎达到饱和运行状态。
数据筛选与后处理
本节将介绍如何利用 Ray 对数据集进行筛选和后处理,以评估轨迹质量(例如通过分配奖励信号实现)。通常,为每个问题实例分配一个 Ray task是高效的做法。若使用独立的奖励模型,可采用与智能体大语言模型类似的部署方式。对于更复杂的场景,考虑到评分和筛选属于批处理数据处理工作负载,使用 Ray Data 和 Ray Data LLM 进行数据集准备会更为合适。
以下将以 “cpython 问题数据集” 部分描述的验证流程为例进行实现。智能体轨迹已在之前的步骤中生成并写入 NFS。在本步骤中,针对每个问题实例,我们将提取智能体生成的补丁,并在完整的 cpython 测试套件(包括人类在 PR 中提交的回归测试 —— 智能体在未作弊的情况下无法获取这些测试)中对其进行测试。若补丁代码通过所有测试,奖励值设为 1;否则设为 0。根据具体配置,验证步骤既可作为轨迹生成过程的一部分,也可独立执行。在文章的最后一节,我们将展示如何将轨迹生成和验证过程整合到强化学习框架中。
以下是上述验证流程的实现代码:
import json
from pathlib import Path
import re
import subprocess
import tempfilefrom datasets import load_dataset
import rayTEST_CMD = """
./configure && prlimit --as=34359738368 make test TESTOPTS="\--ignore test.test_embed.InitConfigTests.test_init_setpythonhome \--ignore test.test_os.TestScandir.test_attributes \--ignore test.test_pathlib.test_pathlib.PathSubclassTest.test_is_mount \--ignore test.test_pathlib.test_pathlib.PathSubclassTest.test_stat \--ignore test.test_pathlib.test_pathlib.PathTest.test_is_mount \--ignore test.test_pathlib.test_pathlib.PathTest.test_stat \--ignore test.test_pathlib.test_pathlib.PosixPathTest.test_is_mount \--ignore test.test_pathlib.test_pathlib.PosixPathTest.test_stat \--ignore test.test_pathlib.PathSubclassTest.test_is_mount \--ignore test.test_pathlib.PathSubclassTest.test_stat \--ignore test.test_pathlib.PathTest.test_is_mount \--ignore test.test_pathlib.PathTest.test_stat \--ignore test.test_pathlib.PosixPathTest.test_is_mount \--ignore test.test_pathlib.PosixPathTest.test_stat \--ignore test.test_perf_profiler.* \--ignore test.test_pdb.PdbTestInline.test_quit \--ignore test.test_pdb.PdbTestInline.test_quit_after_interact"
"""def safe_subprocess_run(path: Path, command: str | list[str], **kwargs):"""Run the command in a subprocess with error handling."""try:result = subprocess.run(command,text=True,**kwargs)except Exception as e:with open(path / "tests.exception", "w") as f:f.write(str(e))return Noneif result.returncode != 0:if result.stdout:with open(path / "tests.out", "w") as f:f.write(result.stdout)if result.stderr:with open(path / "tests.err", "w") as f:f.write(result.stderr)return Nonereturn resultdef run_tests(path: Path, instance: dict[str, str], trajectory: dict):with tempfile.TemporaryDirectory() as working_dir:# check out the repository at the base_commitif not safe_subprocess_run(path,f"git init && git remote add origin https://github.com/{instance['repo']} && "f"git fetch --depth 1 origin {instance['merge_commit']} && "f"git fetch --depth 1 origin {instance['base_commit']} && git checkout FETCH_HEAD && cd ..",shell=True,cwd=working_dir,capture_output=True,):return# apply patch from the submissionif trajectory["info"]["submission"]with tempfile.NamedTemporaryFile(mode="w", delete=False) as f:f.write(trajectory["info"]["submission"])print(f"wrote submission patch to {f.name}")if not safe_subprocess_run(path,["git", "apply", "--exclude", "Lib/test/*", f.name],cwd=working_dir,capture_output=True,):return# apply patches from the PR merge commit (tests only)result = safe_subprocess_run(path,["git", "diff", instance["base_commit"], instance["merge_commit"]],cwd=working_dir,capture_output=True,)if not result:returnif result.stdout != "":with tempfile.NamedTemporaryFile(mode="w", delete=False) as f:f.write(result.stdout)print(f"wrote test patch to {f.name}")if not safe_subprocess_run(path,["git", "apply", "--include", "Lib/test/*", f.name],cwd=working_dir,capture_output=True,):return# run full test suitewith open(path / "tests.log", "w") as f:result = safe_subprocess_run(path,TEST_CMD,shell=True,cwd=working_dir,stdout=f,stderr=subprocess.STDOUT,)if not result:returnreturn {"path": str(path), "exit_code": result.returncode}@ray.remote(num_cpus=1)
def run_tests_safe(path: Path, instance: dict[str, str], trajectory: dict):try:# Note: We don't actually use the return values here, instead we# parse the test run log file to determine if the tests passed or notreturn run_tests(path, instance, trajectory)except Exception:returninstances = load_dataset("pcmoritz/cpython_dataset", split="train")
results = []for path in Path('/mnt/shared_storage/pcmoritz/rollouts').iterdir():if path.is_dir():json_file = path / f"{path.name}.traj.json"if not json_file.exists():continuewith open(json_file, 'r') as f:trajectory = json.load(f)instance = instances.filter(lambda x: x['instance_id'] == path.name)[0]if trajectory["info"]["submission"] and re.search(r'Binary files .+ and .+ differ', trajectory["info"]["submission"]):print(f"skipping instance {instance}")continueresults.append(run_tests_safe.remote(path, instance, trajectory))ray.get(results)在运行仿真时,我们发现以下技巧非常实用:
-
日志与输出存储:将仿真日志和输出写入 NFS 等分布式文件系统。这样不仅便于查看部分进度,还能在任务被抢占中断时,从上次中断处恢复(类似传统数据处理中的行级 checkpoint 机制)。
-
内存限制设置:为仿真任务设置合理的内存限制,防止单个 “异常” 智能体占用过多资源,影响其他智能体运行。若采用轻量级进程隔离方式,可通过 prlimit --as=<字节数内存限制> <命令> 包裹进程来实现内存限制。
-
文件系统保护:为避免智能体修改共享文件或系统文件,可使用容器镜像,或像前文智能体仿真那样使用 bubblewrap 等工具。在本评估场景中,由于多个 cpython 测试套件实例可并行运行且互不干扰,因此无需额外保护措施。
对于软件工程相关依赖(如本示例中编译 Python 3 所需的依赖),可通过容器文件配置,示例命令如下:
RUN sudo sed -i 's/# deb-src/deb-src/' /etc/apt/sources.list
RUN sudo apt update
RUN sudo apt build-dep -y python3-
我们发现,将初始问题陈述数据集标准化为 Hugging Face 数据集格式非常实用;随后,在数据处理的不同阶段(如轨迹生成和评分),为每个问题实例在 NFS 上创建一个文件夹,用于存储后续输出数据。
Anyscale 的任务仪表盘为监控智能体执行过程提供了便捷方式:
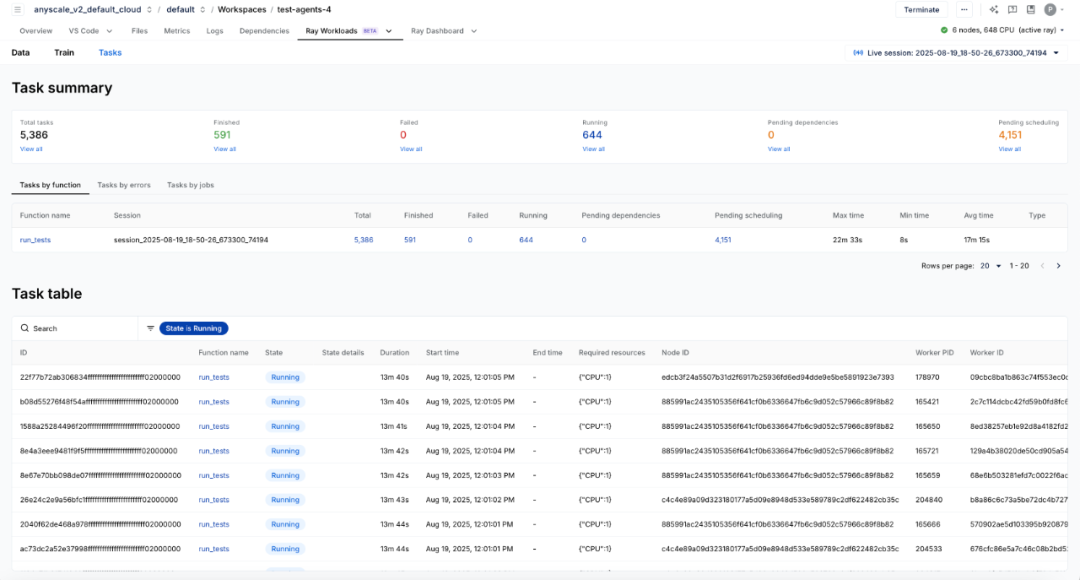
通过仪表盘的 “指标” 页面,还能识别执行过程中的资源瓶颈(如磁盘吞吐量、网络吞吐量、CPU/GPU 内存容量、CPU/GPU 计算吞吐量等),进而选择最适合当前工作负载的实例类型,或对 CPU 等资源进行超分配。
以下是我们的评估结果。首先,通过评估每个 base_commit 的完整测试套件,确定测试通过率的上限(即不应用大语言模型生成补丁时的测试通过率)。需注意,通过更精细地排除测试用例或优化测试环境,可进一步提高该上限。随后,我们使用 Qwen3 Coder 30B 和 Qwen3 235B 两个模型,记录它们生成的补丁在包含每个 PR 回归测试的完整测试套件中的通过率;同时,还记录了每个问题实例允许模型尝试 3 次(仅统计最成功的一次尝试)时的通过率。这些运行产生的轨迹数据可用于有监督微调,为后续运行和进一步微调提供更优的基准模型。
在以下实验中,我们将温度参数设为 0.7(相较于 mini-swe-agent 默认的 0.0,该值对 Qwen3 模型更有效)。
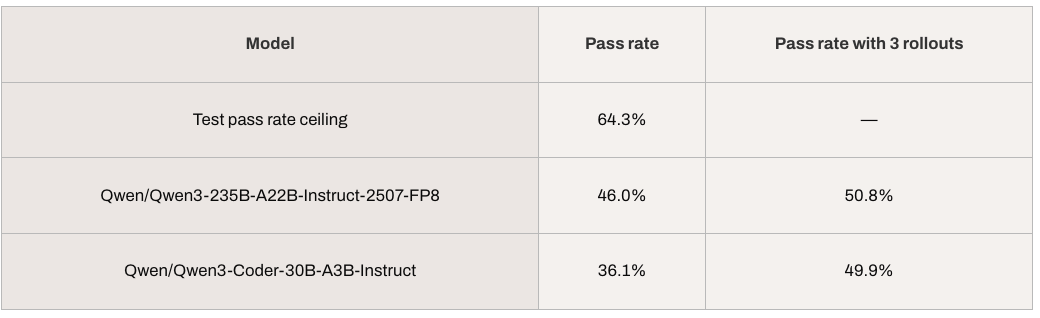
从结果可见,尽管这些模型在解决此类任务时表现尚可,但仍有提升空间。
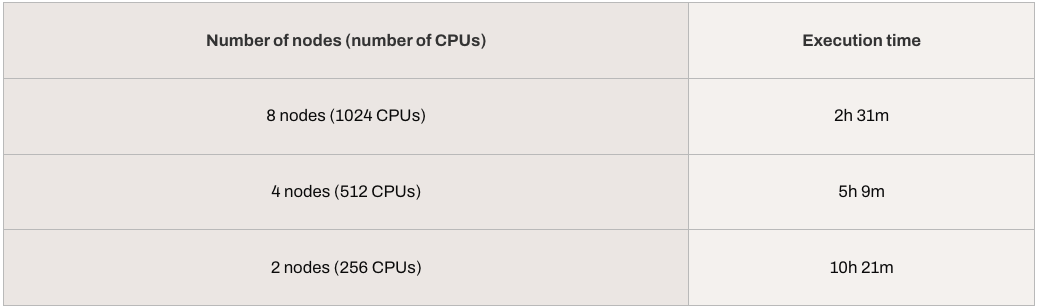
我们还提供了系统性能扩展数据 —— 评估完整 cpython 数据集时,我们使用了 c7a.32xlarge 节点。结果表明,执行时间与 CPU 数量呈线性关系:
借助 SkyRL 实现端到端强化学习
本节将示例说明如何将上述方法与基于 Ray 运行的现有强化学习库集成。此类强化学习库有多种选择,我们选择 SkyRL 进行集成演示,主要因其对自定义生成器具有良好的支持。
Mini-SWE-Agent 与 SkyRL 的集成代码可通过链接获取。在 SkyRL 中,训练栈采用模块化设计,主要包含两个组件:训练器(trainer)和生成器(generator)。在本示例中,我们通过自定义生成器,使用 Mini-SWE-Agent 为 SWE-Bench 任务生成轨迹数据。
从整体设计来看,我们实现了一个 MiniSweAgentGenerator 类,其中包含自定义的 generate 方法,用于生成一批轨迹数据:
class MiniSweAgentGenerator(SkyRLGymGenerator):
async def generate_trajectory(self, prompt, ...): ...
async def generate(self, generator_input: GeneratorInput) -> GeneratorOutput:...prompts = generator_input["prompts"]env_extras = generator_input["env_extras"]tasks = []
for i in range(len(prompts)):tasks.append(self.generate_trajectory(prompts[i],env_extras[i],))all_outputs = await asyncio.gather(*tasks)在 generate_trajectory 方法中,我们启动一个 Ray task,为指定实例生成轨迹并进行评估。具体而言,该过程包含以下步骤:
-
轨迹生成
-
为当前实例初始化沙箱 / 环境。
-
在该环境中使用 Mini-SWE-Agent 生成轨迹。推理过程中,需将 Mini-SWE-Agent 配置为使用 SkyRL 提供的 HTTP endpoint。
-
轨迹生成完成后,存储生成的 git 补丁。
-
-
评估
-
使用指定的后端,为当前实例初始化一个全新的环境。
-
在该环境的工作目录中,应用模型生成的 git 补丁。
-
运行该实例的评估脚本:若脚本执行成功,表明实例问题已解决;否则视为未解决。
-
通过将该工作流程封装为 Ray task,我们能够在 Ray 集群的所有节点上扩展轨迹生成规模。
以下是核心代码框架:
@ray.remote(num_cpus=0.01)
def init_and_run(instance: dict, litellm_model_name: str, sweagent_config: dict, data_source):model = get_model(litellm_model_name, sweagent_config.get("model", {}))error = Nonetry:env = get_sb_environment(sweagent_config, instance, data_source)agent = DefaultAgent(model, env, **sweagent_config.get("agent", {}))exit_status, model_patch = agent.run(instance["problem_statement"])eval_result = evaluate_trajectory(instance, model_patch, sweagent_config, data_source)except Exception as e:error = str(e)return agent.messages, eval_result, errorclass MiniSweAgentGenerator(SkyRLGymGenerator):async def generate_trajectory(self, prompt, env_extras, ...):messages, eval_result, error = init_and_run.remote(env_extras["instance"], litellm_model_name, sweagent_config, data_source)...(注:完整实现包含额外的配置处理和错误处理逻辑,可通过链接查看。)
总结
本文展示了如何借助 Ray 实现大规模智能体仿真,以生成智能体轨迹、评估智能体性能并训练智能体。Ray 的灵活性使其能够在单个集群中运行所有相关工作负载(数据处理、模型服务和训练),简化了开发和实验配置,并能扩展到超大规模的问题实例处理场景。简单高效的沙箱隔离机制,也让各类智能体工作负载的大规模运行变得更加容易。
本文展示的所有示例均可在 Anyscale 平台上直接运行。得益于 Ray 的分布式特性,部署和评估需要使用 MCP 服务器等多个组件来解决特定问题的智能体,也变得十分便捷。
本文介绍的技术既可作为流水线的独立步骤单独运行,也可集成到不同的强化学习库中。SkyRL 凭借其灵活的生成器框架,极大地简化了这种集成过程,本文也对此提供了相应示例。