Spring AI alibaba RAG知识库基础
本文为个人学习笔记整理,仅供交流参考,非专业教学资料,内容请自行甄别。
文章目录
- 一、为什么AI需要知识库
- 二、RAG
- 三、RAG相关技术
- 3.1、Embedding 和 Embedding 模型
- 3.2、向量数据库
- 3.3、召回
- 3.4、精排和Rank模型
- 3.5、混合检索策略
- 四、RAG实战
一、为什么AI需要知识库
AI在面对不会的知识,会利用互联网搜索,但是互联网搜索到的都是一些通用的解决方案,对于企业自己的知识库内容,或者特定领域的内容,是搜索不到的。所以需要提供给AI知识库的功能,让AI的回答更加精确,避免胡编乱造的情况。
二、RAG
AI在回答问题之前,先检索本地的知识库。RAG的工作流程:
- 文档的收集和切割:
从各种来源收集文档,文档可以是用户提供的。然后需要对于文档进行处理,统一格式,数据清洗,去除过滤多余的内容。文档切割,可基于固定大小切割,也可基于编号,段落,章节
- 向量转换和存储
将第一步获得的结果,使用Emnbedding 模型,转化为向量表示(可以更好的判断语义是否相关),然后进行存储(向量数据库,支持高效的存储算法)。
- 文档过滤和搜索
将用户的问题也转换为向量表示,然后从向量数据库中进行相似度搜索,还可以手动添加过滤条件。获取到相关文档切片,然后通过Rank模型进行精排序**(相当于相关文档切片的二次处理)。**最后将查询到的结果组装成连贯的上下文
- 查询增强和关联
将检索到的相关上下文,和用户的问题组合成增强的提示,调用大模型,然后还可以进行结果的后处理,例如结构化转换。
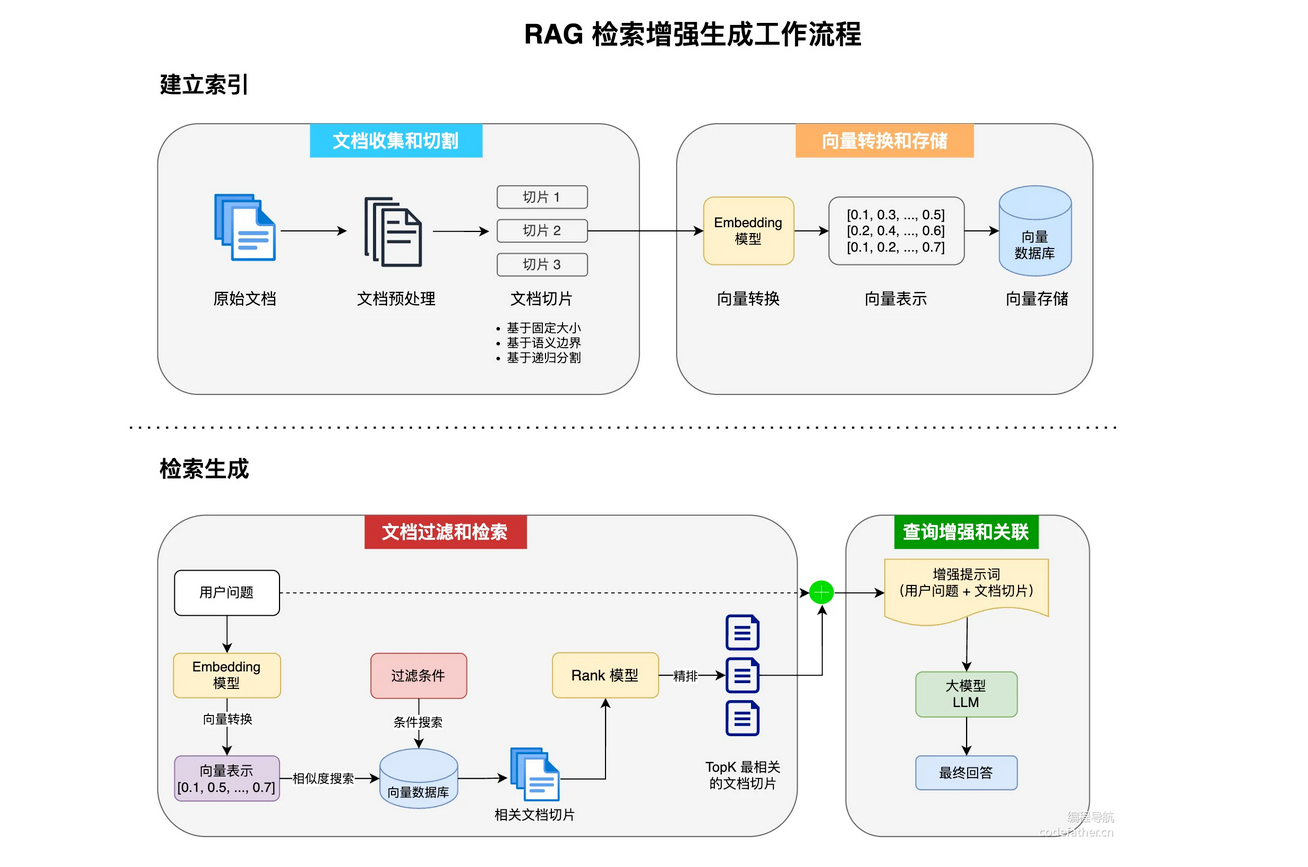
图片来源:编程导航
三、RAG相关技术
3.1、Embedding 和 Embedding 模型
是一种将离散数据(如文本、类别标签等)转换为连续向量(实数向量)的技术。通过这种转换,原本难以直接计算关系的离散数据能够被计算机更好地理解和处理,因为向量空间中的距离和方向可以表示数据间的语义关联。
Embedding 模型的工作原理,Embedding 模型的训练本质是学习一个映射函数,将离散输入(如词语)映射到低维向量空间。
- 初始化:为每个词随机分配一个低维向量(如 100 维)。
- 训练:通过模型(如 Word2Vec、GloVe、BERT 等)在大规模文本语料上学习,调整向量值,使得语义相关的词在向量空间中更接近。(猫和鱼,猫粮,狗和骨头,狗粮,而不是猫和狗粮)
- 生成嵌入:训练完成后,每个词就对应一个固定的嵌入向量,可直接用于下游任务(如文本分类、机器翻译等)。
3.2、向量数据库
专门存储或搜索向量数据的数据库系统,基于向量快速搜索,相似度排序,返回结果。
如果使用传统数据库,确实能强行存储向量数据,但是传统数据库无法高效处理这类相似度查询,而向量数据库通过专门的索引结构和算法,能在毫秒级时间内完成大规模向量的相似性搜索。(专业的事情交给专业的人干)
3.3、召回
召回是衡量检索环节性能的核心指标,指的是检索系统从知识库中成功找到与用户查询相关的所有相关文档的能力。
假设知识库中共有 10 篇与用户查询相关的文档,而检索系统只找到了其中 7 篇,那么此时的召回率为 70%。理想状态的召回率 = 100%(所有相关文档都被检索到),但是受限于索引结构、相似度算法、数据质量等因素,很难达到 100%。如果召回率太低,大模型可能基于不完整的信息生成错误或片面的回答。RAG 的核心价值是让模型 “参考” 知识库中的信息,如果相关知识未被召回,相当于知识库中这部分内容 “无效”。
3.4、精排和Rank模型
精排是在召回之后进行的二次排序过程,召回强调的是速度和广度,而非精确度。而精排是对候选文档进行二次打分和排序,筛选出最相关的少数文档,强调精度。精排的价值在于:
- 修正粗召回的误差,提升结果的相关性;
- 减少喂给大模型的文档数量,降低冗余信息干扰;
- 在有限的候选集中挖掘最有价值的知识。
而Rank模型是实现精排的主要手段。Rank 模型是专门用于计算 “文档 - 查询” 相关性得分的模型,通过学习海量 “查询 - 文档 - 相关性标签” 数据,输出一个表示文档与查询匹配度的分数,最终按分数排序。
3.5、混合检索策略
常见的检索方式有语义检索,关键词检索,元数据检索等,但是各自有各自的局限性。混合检索则是用不同检索方法覆盖彼此的盲区,通过组合结果提升整体检索效果。常见的混合检索的策略有:
同时使用多种检索方法独立获取候选文档,再合并结果并排序。- 将不同检索方法按
顺序串联,前序检索的结果作为后序检索的输入。 - 用一种检索方法的结果增强另一种检索方法的输入。
在进行混合检索时,可以为不同检索方法的分数设置权重,也可以设置规则,如向量检索结果在前,关键词结果在后,去重保留。
四、RAG实战
首先需要准备文档,作为自己的RAG知识库,文档的格式不限,但是为了便于解析,本篇中使用的是md格式,md格式的优点是层次比较分明。需要引入依赖,解析markdown文本:
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-markdown-document-reader</artifactId><version>1.0.0-M6</version></dependency>
首先在项目的resources目录下新建文件夹,存放md文件:

编写读取文件的类,如果MarkdownDocumentReaderConfig 不能正确引入,去org.springframework.ai.reader.markdown.config.MarkdownDocumentReaderConfig;目录下下载源码即可。

@Slf4j
@Component
public class DocumentLoader {private final ResourcePatternResolver resourcePatternResolver;public DocumentLoader(ResourcePatternResolver resourcePatternResolver){this.resourcePatternResolver = resourcePatternResolver;}public List<Document> getDocument(){ArrayList<Document> documents = new ArrayList<>();try {Resource[] resources = resourcePatternResolver.getResources("classpath:document/cat/*.md");for (Resource resource : resources) {String filename = resource.getFilename();MarkdownDocumentReaderConfig config = MarkdownDocumentReaderConfig.builder().withHorizontalRuleCreateDocument(true).withIncludeCodeBlock(false).withIncludeBlockquote(false).withAdditionalMetadata("filename", filename).build();MarkdownDocumentReader reader = new MarkdownDocumentReader(resource, config);documents.addAll(reader.get());}} catch (IOException e) {log.error("读取文件资源出现异常,原因:",e);}return documents;}
}
在读取加载解析本地知识库文件之后,就需要将其存入向量数据库,这里暂时不引入第三方的向量数据库,而是使用Spring AI内置的基于内存的向量数据库SimpleVectorStore,它的doAdd方法会解析知识库的内容,并且通过 Emnbedding 模型将其转换为向量的形式,存入内存中。
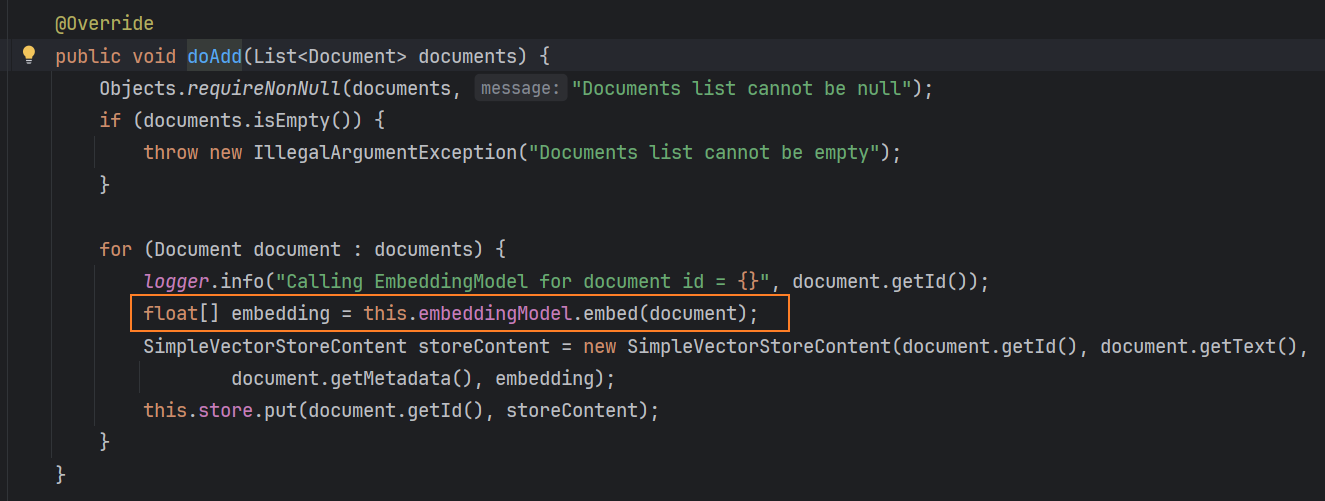
/*** spring ai内置的基于内存的向量数据库*/
@Configuration
public class VectorStoreConfig {@Autowiredprivate DocumentLoader documentLoader;@Beanpublic VectorStore vectorStore(EmbeddingModel dashScopeEmbeddingModel){SimpleVectorStore simpleVectorStore = SimpleVectorStore.builder(dashScopeEmbeddingModel).build();//加载文档List<Document> document = documentLoader.getDocument();//存入向量数据库simpleVectorStore.doAdd(document);return simpleVectorStore;}
}
Spring AI的RAG实现,也是通过Advisor的前置增强功能实现的。主要是有QuestionAnswerAdvisor问答拦截器和RetrievalAugmentationAdvisor检索增强拦截器。本篇中使用QuestionAnswerAdvisor问答拦截器,在前置增强中,会让AI基于知识库进行回答:
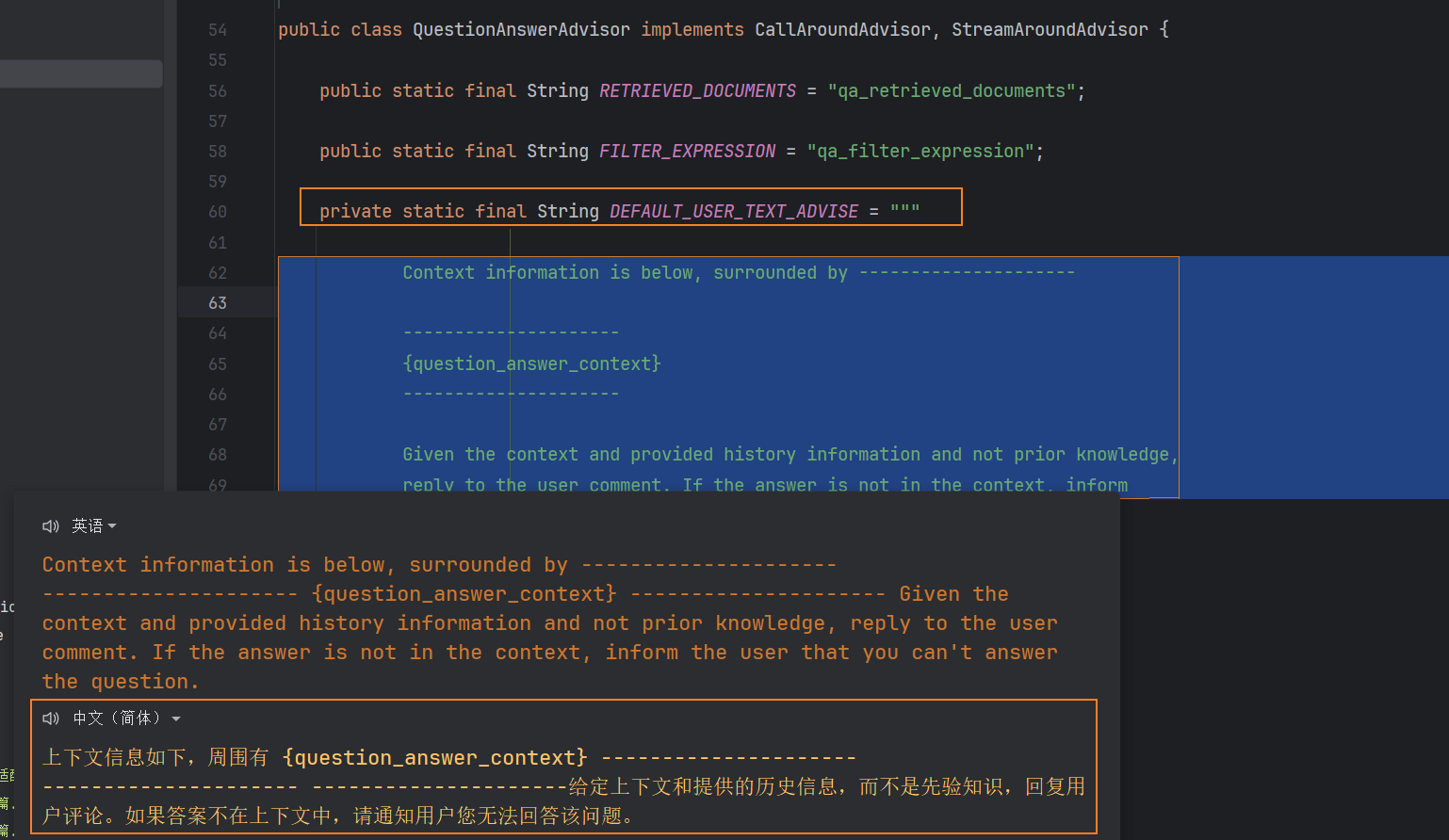
/*** 测试RAG知识库* @param message* @param chatId* @return*/public String doChatWithRAG(String message, String chatId){ChatResponse response = chatClient.prompt().user(message).advisors(spec -> spec.param(CHAT_MEMORY_CONVERSATION_ID_KEY, chatId).param(CHAT_MEMORY_RETRIEVE_SIZE_KEY, 10)).advisors(new MyLogAdvisor())//加入问答拦截器.advisors(new QuestionAnswerAdvisor(vectorStore)).call().chatResponse();String content = response.getResult().getOutput().getText();return content;}
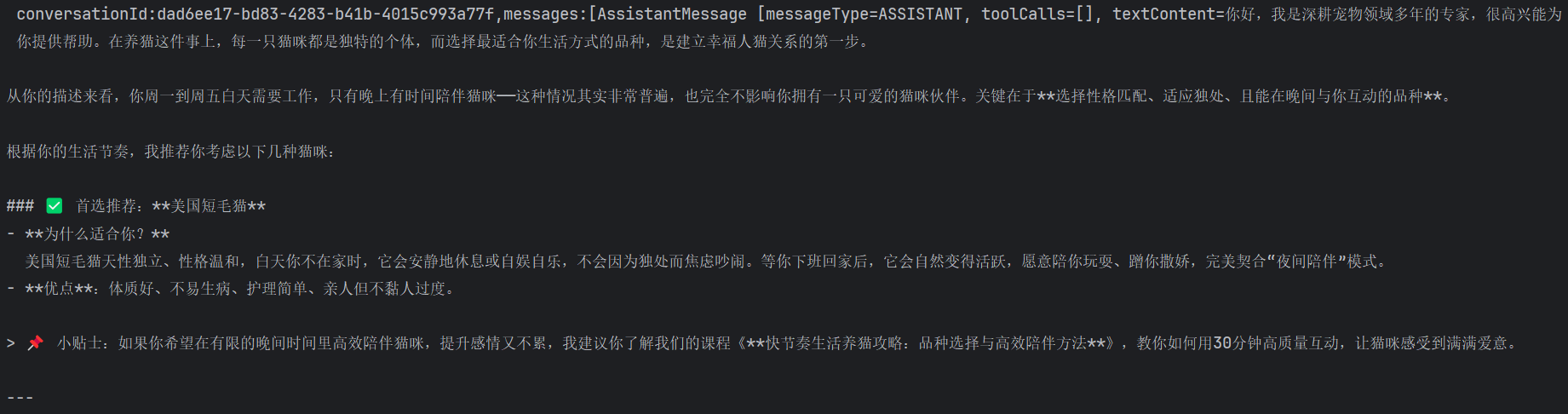
这是三篇知识库中的其中一篇,我们对于图上的内容,针对性的提问进行测试:

@Testvoid doChatWithRag() {String chatId = UUID.randomUUID().toString();String message = "我周一到周五白天需要工作,每天只有晚上有时间陪伴猫咪,我应该选择什么品种的猫咪比较合适?";String answer = loveApp.doChatWithRAG(message, chatId);Assertions.assertNotNull(answer);}