Tensor Core的MMA与WMMA
文章目录
- WMMA与MMA区别
- 使用 WMMA 指令
- 使用 MMA 指令
- Tensor Core详解之mma
- 参考
WMMA与MMA区别
WMMA:Warp Matrix Multiply Accumulate
MMA:Matrix Multiply Accumulate
使用 WMMA 指令
WMMA 是一种较高级别的编程接口,允许开发者以“矩阵片段”为单位进行操作,而不需要关心线程间数据分布的细节。
步骤:
- 1.加载矩阵(wmma.load)
使用 wmma.load 操作将矩阵 A、B 和 C 从内存加载到寄存器中。
每个线程的寄存器中会保存矩阵的一个“片段”(fragment)。 - 2.执行矩阵乘加运算(wmma.mma)
使用 wmma.mma 对已加载的矩阵片段执行乘加运算:D=A×B+C
每个线程的寄存器中会保存结果矩阵 D 的一个片段。 - 3.存储结果(wmma.store)
使用 wmma.store 将结果矩阵 D 的片段写回内存。
也可以将 D 作为 wmma.mma 的参数 C,实现原地更新。
特点:
- wmma.load 和 wmma.store 会自动处理矩阵元素在线程之间的分布(“隐式处理矩阵元素的组内方式”)。
- 开发者无需手动管理数据在 warp 内的分布。
使用 MMA 指令
MMA 是一种更底层的接口,提供更高的灵活性,但需要开发者显式管理线程间的数据分布。
步骤:
- 与 WMMA 类似,也需要 warp 内所有线程协同执行。
- 不同之处在于:在调用 mma 操作之前,必须显式地将矩阵元素分配到不同线程中。
- MMA 支持更多种类的矩阵格式,包括结构化稀疏矩阵(如“缩流矩阵”,可能是指压缩稀疏行/列格式)。
- 当矩阵 A 是结构化稀疏矩阵时,可以使用专门的 MMA 变体来提高效率。
特点:
- 更灵活,支持更多矩阵类型和稀疏格式。
- 需要开发者手动处理数据在 warp 内的分布。
| 对比项 | WMMA (Warp Matrix Multiply Accumulate API) | MMA (Matrix Multiply Accumulate Instruction) |
|---|---|---|
| 定义层级 | CUDA C++ 提供的 高级 API,封装在 nvcuda::wmma namespace 中 | GPU 底层 PTX 指令(mma.sync 等),直接由硬件执行 |
| 使用难度 | 接口类似 C++ 模板库,开发者易于调用(如 wmma::load_matrix_sync / wmma::mma_sync) | 需要写 PTX 汇编或 inline PTX,开发复杂度高 |
| 适用对象 | 给普通 CUDA 程序员使用,降低学习成本 | 给编译器后端和高性能库开发者(cuBLAS、CUTLASS)使用 |
| 可控粒度 | 支持固定 tile 大小 (16x16x16, 8x32x16, 32x8x16),由 API 限制 | 灵活,直接暴露硬件支持的各种矩阵 tile 形状 |
| 可移植性 | 跨 GPU 架构相对稳定,NVIDIA 保证 API 向后兼容 | 随 GPU 架构变化(Volta → Turing → Ampere → Hopper),指令格式可能不同 |
| 性能 | 性能接近底层 MMA(API 最终会编译成 MMA 指令) | 理论上最佳性能,但需要开发者手工调度、对齐、bank conflict 处理 |
| 典型使用场景 | 在 CUDA kernel 里写 warp 级 GEMM 或 TensorCore 加速计算 | 实现 cuBLAS、CUTLASS、深度学习框架内核时用 |
| 开发成本 | 简单,几行代码即可实现 Tensor Core 计算 | 高,需要理解 GPU 架构、寄存器布局和 PTX 编写 |
WMMA = 面向开发者的 高级封装 API,写起来友好,效率接近硬件极限;
MMA = 底层 硬件指令,灵活且性能最高,但写起来很复杂,通常由编译器和高性能库使用。
Tensor Core详解之mma
参考:
- Toy HGEMMM Library using Tensor Cores with MMA/WMMA/CuTe
HGEMM CUDA Kernels in Toy-HGEMM Library
void hgemm_naive_f16(torch::Tensor a, torch::Tensor b, torch::Tensor c);
void hgemm_sliced_k_f16(torch::Tensor a, torch::Tensor b, torch::Tensor c);
void hgemm_t_8x8_sliced_k_f16x4(torch::Tensor a, torch::Tensor b, torch::Tensor c);
void hgemm_t_8x8_sliced_k_f16x4_pack(torch::Tensor a, torch::Tensor b, torch::Tensor c);
void hgemm_t_8x8_sliced_k_f16x4_bcf(torch::Tensor a, torch::Tensor b, torch::Tensor c);
void hgemm_t_8x8_sliced_k_f16x4_pack_bcf(torch::Tensor a, torch::Tensor b, torch::Tensor c);
void hgemm_t_8x8_sliced_k_f16x8_pack_bcf(torch::Tensor a, torch::Tensor b, torch::Tensor c);
void hgemm_t_8x8_sliced_k_f16x8_pack_bcf_dbuf(torch::Tensor a, torch::Tensor b, torch::Tensor c);
void hgemm_t_8x8_sliced_k16_f16x8_pack_dbuf(torch::Tensor a, torch::Tensor b, torch::Tensor c);
void hgemm_t_8x8_sliced_k16_f16x8_pack_dbuf_async(torch::Tensor a, torch::Tensor b, torch::Tensor c);
void hgemm_t_8x8_sliced_k32_f16x8_pack_dbuf(torch::Tensor a, torch::Tensor b, torch::Tensor c);
void hgemm_t_8x8_sliced_k32_f16x8_pack_dbuf_async(torch::Tensor a, torch::Tensor b, torch::Tensor c);
void hgemm_t_16x8_sliced_k32_f16x8_pack_dbuf(torch::Tensor a, torch::Tensor b, torch::Tensor c);
void hgemm_t_16x8_sliced_k32_f16x8_pack_dbuf_async(torch::Tensor a, torch::Tensor b, torch::Tensor c);
void hgemm_cublas_tensor_op_nn(torch::Tensor a, torch::Tensor b, torch::Tensor c);
void hgemm_cublas_tensor_op_tn(torch::Tensor a, torch::Tensor b, torch::Tensor c);
void hgemm_wmma_m16n16k16_naive(torch::Tensor a, torch::Tensor b, torch::Tensor c);
void hgemm_wmma_m16n16k16_mma4x2(torch::Tensor a, torch::Tensor b, torch::Tensor c);
void hgemm_wmma_m16n16k16_mma4x2_warp2x4(torch::Tensor a, torch::Tensor b, torch::Tensor c);
void hgemm_wmma_m16n16k16_mma4x2_warp2x4_dbuf_async(torch::Tensor a, torch::Tensor b, torch::Tensor c);
void hgemm_wmma_m32n8k16_mma2x4_warp2x4_dbuf_async(torch::Tensor a, torch::Tensor b, torch::Tensor c);
void hgemm_wmma_m16n16k16_mma4x2_warp2x4_stages(torch::Tensor a, torch::Tensor b, torch::Tensor c, int stages, bool swizzle, int swizzle_stride);
void hgemm_wmma_m16n16k16_mma4x2_warp2x4_stages_dsmem(torch::Tensor a, torch::Tensor b, torch::Tensor c, int stages, bool swizzle, int swizzle_stride);
void hgemm_wmma_m16n16k16_mma4x2_warp4x4_stages_dsmem(torch::Tensor a, torch::Tensor b, torch::Tensor c, int stages, bool swizzle, int swizzle_stride);
void hgemm_wmma_m16n16k16_mma4x4_warp4x4_stages_dsmem(torch::Tensor a, torch::Tensor b, torch::Tensor c, int stages, bool swizzle, int swizzle_stride);
void hgemm_mma_m16n8k16_naive(torch::Tensor a, torch::Tensor b, torch::Tensor c);
void hgemm_mma_m16n8k16_mma2x4_warp4x4(torch::Tensor a, torch::Tensor b, torch::Tensor c);
void hgemm_mma_m16n8k16_mma2x4_warp4x4_stages(torch::Tensor a, torch::Tensor b, torch::Tensor c, int stages, bool swizzle, int swizzle_stride);
void hgemm_mma_m16n8k16_mma2x4_warp4x4_stages_dsmem(torch::Tensor a, torch::Tensor b, torch::Tensor c, int stages, bool swizzle, int swizzle_stride);
void hgemm_mma_m16n8k16_mma2x4_warp4x4x2_stages_dsmem(torch::Tensor a, torch::Tensor b, torch::Tensor c, int stages, bool swizzle, int swizzle_stride);
void hgemm_mma_m16n8k16_mma2x4_warp4x4x2_stages_dsmem_x4(torch::Tensor a, torch::Tensor b, torch::Tensor c, int stages, bool swizzle, int swizzle_stride);
void hgemm_mma_m16n8k16_mma2x4_warp4x4x2_stages_dsmem_rr(torch::Tensor a, torch::Tensor b, torch::Tensor c, int stages, bool swizzle, int swizzle_stride);
void hgemm_mma_m16n8k16_mma2x4_warp4x4_stages_dsmem_tn(torch::Tensor a, torch::Tensor b, torch::Tensor c, int stages, bool swizzle, int swizzle_stride);
void hgemm_mma_stages_block_swizzle_tn_cute(torch::Tensor a, torch::Tensor b, torch::Tensor c, int stages, bool swizzle, int swizzle_stride);
void hgemm_mma_m16n8k16_mma2x4_warp4x4x2_stages_dsmem_swizzle(torch::Tensor a, torch::Tensor b, torch::Tensor c, int stages, bool swizzle, int swizzle_stride);
void hgemm_mma_m16n8k16_mma2x4_warp4x4x2_stages_dsmem_tn_swizzle_x4(torch::Tensor a, torch::Tensor b, torch::Tensor c, int stages, bool swizzle, int swizzle_stride);
为啥mma版本的naive不用m16n16k16?
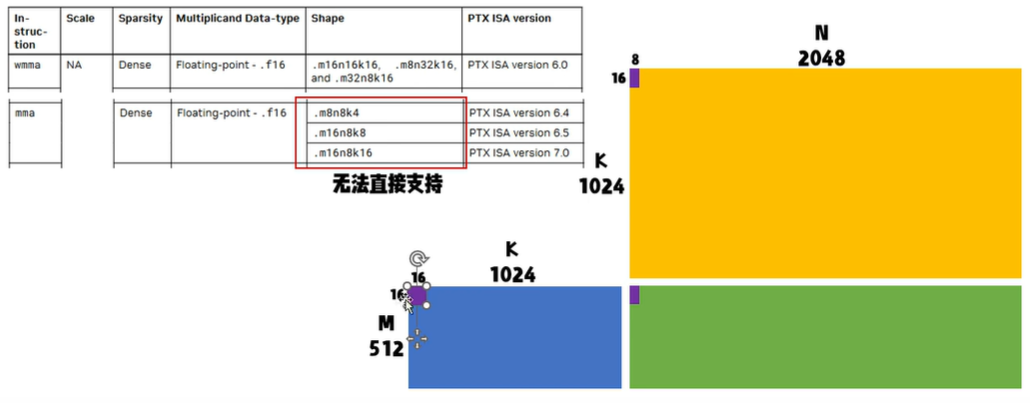
以hgemm_mma.cu中的hgemm_mma_m16n8k16_naive_kernel函数为例
// only 1 warp per block(32 threads), m16n8k16. A, B, C: all row_major.
template <const int MMA_M = 16, const int MMA_N = 8, const int MMA_K = 16>
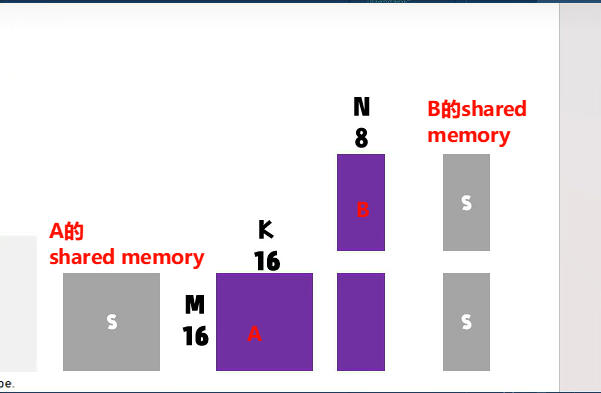
__global__ void hgemm_mma_m16n8k16_naive_kernel(half *A, half *B, half *C,int M, int N, int K) {const int bx = blockIdx.x;const int by = blockIdx.y;const int NUM_K_TILES = div_ceil(K, MMA_K);constexpr int BM = MMA_M; // 16constexpr int BN = MMA_N; // 8constexpr int BK = MMA_K; // 16__shared__ half s_a[MMA_M][MMA_K]; // 16x16__shared__ half s_b[MMA_K][MMA_N]; // 16x8__shared__ half s_c[MMA_M][MMA_N]; // 16x8const int tid = threadIdx.y * blockDim.x + threadIdx.x; // within blockconst int lane_id = tid % WARP_SIZE; // 0~31// s_a[16][16], 每行16,每线程load 8,需要2线程,共16行,需2x16=32线程const int load_smem_a_m = tid / 2; // row 0~15const int load_smem_a_k = (tid % 2) * 8; // col 0,8// s_b[16][8], 每行8,每线程load// 8,需要1线程,共16行,需16线程,只需一半线程加载const int load_smem_b_k = tid; // row 0~31, but only use 0~15const int load_smem_b_n = 0; // col 0const int load_gmem_a_m = by * BM + load_smem_a_m; // global mconst int load_gmem_b_n = bx * BN + load_smem_b_n; // global nif (load_gmem_a_m >= M && load_gmem_b_n >= N)return;uint32_t RC[2] = {0, 0};#pragma unrollfor (int k = 0; k < NUM_K_TILES; ++k) {// gmem_a -> smem_a,A从global memory搬运到shared memoryint load_gmem_a_k = k * BK + load_smem_a_k; // global col of aint load_gmem_a_addr = load_gmem_a_m * K + load_gmem_a_k;LDST128BITS(s_a[load_smem_a_m][load_smem_a_k]) =(LDST128BITS(A[load_gmem_a_addr]));// gmem_b -> smem_b:B从global memory搬运到shared memoryif (lane_id < MMA_K) {int load_gmem_b_k = k * MMA_K + load_smem_b_k; // global row of bint load_gmem_b_addr = load_gmem_b_k * N + load_gmem_b_n;LDST128BITS(s_b[load_smem_b_k][load_smem_b_n]) =(LDST128BITS(B[load_gmem_b_addr]));}__syncthreads();uint32_t RA[4];uint32_t RB[2];// ldmatrix for s_a, ldmatrix.trans for s_b. 从shared memory搬运到寄存器// s_a: (0,1)*8 -> 0,8 -> [(0~15),(0,8)]uint32_t load_smem_a_ptr =__cvta_generic_to_shared(&s_a[lane_id % 16][(lane_id / 16) * 8]);LDMATRIX_X4(RA[0], RA[1], RA[2], RA[3], load_smem_a_ptr);uint32_t load_smem_b_ptr = __cvta_generic_to_shared(&s_b[lane_id % 16][0]);LDMATRIX_X2_T(RB[0], RB[1], load_smem_b_ptr);HMMA16816(RC[0], RC[1], RA[0], RA[1], RA[2], RA[3], RB[0], RB[1], RC[0],RC[1]);__syncthreads();}// s_c[16][8],// https://docs.nvidia.com/cuda/parallel-thread-execution/index.html// #matrix-fragments-for-mma-m16n8k16-with-floating-point-type// [0~7][0~3 u32 -> 0~7 f16], [8~15][0~3 u32 -> 0~7 f16]LDST32BITS(s_c[lane_id / 4][(lane_id % 4) * 2]) = LDST32BITS(RC[0]);LDST32BITS(s_c[lane_id / 4 + 8][(lane_id % 4) * 2]) = LDST32BITS(RC[1]);__syncthreads();// store s_c[16][8]if (lane_id < MMA_M) {// store 128 bits per memory issue.int store_gmem_c_m = by * BM + lane_id;int store_gmem_c_n = bx * BN;int store_gmem_c_addr = store_gmem_c_m * N + store_gmem_c_n;LDST128BITS(C[store_gmem_c_addr]) = (LDST128BITS(s_c[lane_id][0]));}
}


参考
- 【CUDA进阶】MMA分析Bank Conflict与Swizzle(已完结)
- 【CUDA进阶】Tensor Core实战教程(已完结)
- 【CUDA进阶】Tensor Core实战教程(上)
- 【CUDA进阶】Tensor Core实战教程(下)