C2D智能知识助手 - 企业版:构建下一代智能知识管理系统
摘要
在数字化转型的浪潮中,企业知识管理面临着前所未有的挑战:如何将分散在各个平台的知识有效整合,并通过AI技术为员工提供智能化的知识服务?本文将深入介绍我们设计的"C2D智能知识助手 - 企业版"(C2D Intelligent Knowledge Assistant - Enterprise Edition),一个基于RAG(Retrieval Augmented Generation)架构的企业级智能知识管理解决方案。
1. 背景与挑战
1.1 企业知识管理现状
现代企业普遍面临以下知识管理痛点:
- 知识孤岛:技术文档分散在Confluence、Wiki、SharePoint等多个平台
- 检索困难:传统关键词搜索无法理解用户真实意图
- 信息过载:海量文档让员工难以快速找到准确答案
- 知识更新滞后:文档更新后,相关系统无法及时同步
1.2 技术发展机遇
随着大语言模型和向量数据库技术的成熟,RAG架构为解决上述问题提供了新的可能:
- 语义理解:基于向量检索的语义匹配
- 上下文生成:结合检索结果生成准确答案
- 实时更新:自动化的知识同步机制
- 智能交互:自然语言问答体验
2. 系统架构设计
2.1 整体架构概览
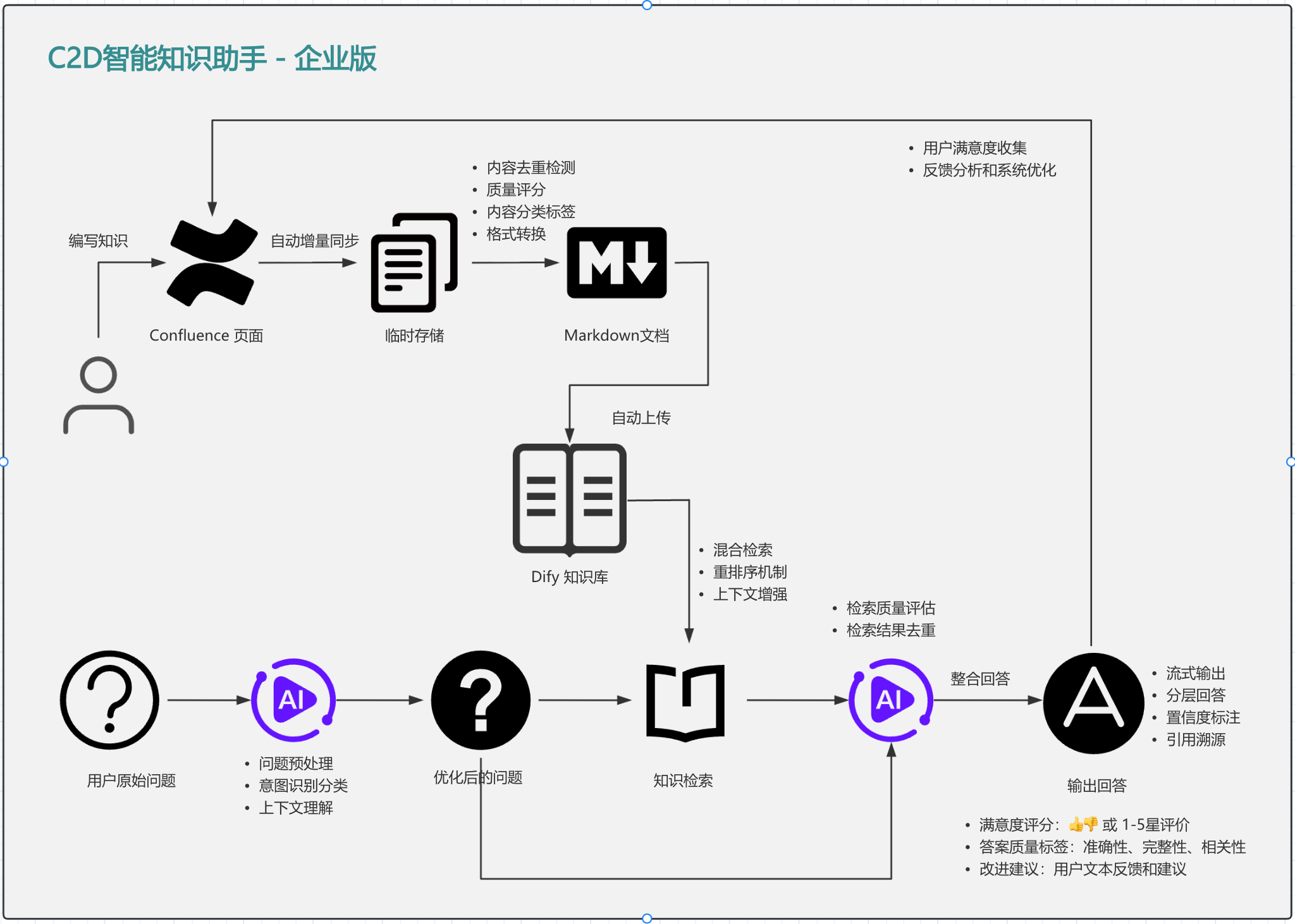
C2D智能知识助手采用端到端的智能化流水线设计,主要包含以下核心模块:
编写知识 → 自动量化同步 → 临时存储 → Markdown文档 → 自动上传 → Dify知识库↓
用户询问问题 → 问题理解 → 优化后的问题 → 知识检索 → 整合回答 → 输出答案
2.2 核心技术栈
- 知识源:Confluence Wiki平台
- 文档处理:HTML到Markdown的智能转换
- 向量数据库:Dify知识库
- 检索引擎:混合检索(向量+关键词+语义)
- 生成模型:大语言模型(LLM)
- 部署平台:企业私有云/公有云
3. 详细技术实现
3.1 知识获取与预处理
3.1.1 自动化同步机制
系统通过Confluence REST API实现知识的自动化获取:
# 核心同步逻辑示例
def sync_confluence_content(token, page_url):# 1. 认证和权限验证headers = {'Authorization': f'Bearer {token}'}# 2. 页面树结构获取page_tree = get_page_tree(page_url, max_depth=5)# 3. 批量内容下载pages_content = batch_download_pages(page_tree)# 4. 增量更新检测changed_pages = detect_content_changes(pages_content)return changed_pages
3.1.2 内容质量控制
在临时存储阶段,系统实施严格的质量控制:
- 内容去重检测:基于内容哈希和语义相似度的双重去重
- 质量评分:评估内容的完整性、准确性和时效性
- 内容分类标签:自动识别文档类型和主题分类
- 格式转换:HTML到Markdown的智能转换,保持格式完整性
3.2 智能检索系统
3.2.1 混合检索策略
系统采用多路召回的混合检索策略:
class HybridRetriever:def __init__(self):self.vector_retriever = VectorRetriever() # 向量检索self.keyword_retriever = BM25Retriever() # 关键词检索self.semantic_retriever = SemanticRetriever() # 语义检索def retrieve(self, query, top_k=10):# 多路召回vector_results = self.vector_retriever.search(query, top_k)keyword_results = self.keyword_retriever.search(query, top_k)semantic_results = self.semantic_retriever.search(query, top_k)# 结果融合和重排序merged_results = self.merge_and_rerank(vector_results, keyword_results, semantic_results)return merged_results
3.2.2 重排序机制
检索结果通过多维度重排序算法优化:
- 相关性评分:基于语义相似度的相关性计算
- 时效性权重:优先展示最新更新的内容
- 权威性评估:考虑文档的访问频率和用户评价
- 上下文增强:结合用户历史对话和偏好
3.2.3 检索质量保障
- 检索质量评估:实时评估检索结果的相关性和完整性
- 检索结果去重:避免重复内容影响答案质量
- 动态调整:根据检索效果自动调整检索参数
3.3 智能问答生成
3.3.1 问题理解
系统对用户问题进行深度理解:
class QuestionUnderstanding:def process(self, user_question):# 问题预处理cleaned_question = self.preprocess(user_question)# 意图识别分类intent = self.classify_intent(cleaned_question)# 上下文理解context = self.understand_context(cleaned_question, intent)return {'processed_question': cleaned_question,'intent': intent,'context': context}
支持的问题类型包括:
- 事实查询:直接的信息检索需求
- 操作指导:步骤化的操作说明
- 概念解释:技术概念的详细说明
- 故障排除:问题诊断和解决方案
3.3.2 答案生成与优化
系统采用多层次的答案生成策略:
- 流式输出:边生成边显示,提升用户体验
- 分层回答:先提供核心答案,再展开详细解释
- 置信度标注:标明答案的可信度和不确定性
- 引用溯源:清晰标注信息来源,便于用户验证
4. 用户体验设计
4.1 满意度收集机制
系统内置多维度的用户反馈收集:
- 即时评价:👍👎快速评价按钮
- 详细反馈:1-5星评分和文字建议
- 行为分析:点击率、停留时间、后续操作等隐式反馈
4.2 反馈分析与系统优化
基于用户反馈的持续优化机制:
class FeedbackLearning:def analyze_feedback(self, feedback_data):# 反馈模式识别patterns = self.identify_patterns(feedback_data)# 问题诊断issues = self.diagnose_issues(patterns)# 优化策略生成optimization_strategies = self.generate_strategies(issues)return optimization_strategiesdef apply_optimizations(self, strategies):# 检索策略调整self.update_retrieval_strategy(strategies.retrieval)# 生成模型优化self.optimize_generation_model(strategies.generation)# 知识库更新self.update_knowledge_base(strategies.knowledge)
5. 技术优势与创新点
5.1 端到端自动化
- 零人工干预:从知识获取到答案生成的全流程自动化
- 实时同步:Confluence内容变更后自动更新知识库
- 智能增量:只处理变更内容,提升处理效率
5.2 企业级可靠性
- 权限控制:基于Bearer Token的安全认证
- 容错机制:多重备份和异常恢复策略
- 性能监控:实时监控各环节的性能指标
5.3 智能化程度
- 语义理解:深度理解用户问题的真实意图
- 上下文感知:结合对话历史提供个性化答案
- 持续学习:基于用户反馈不断优化系统性能
6. 端到端流程打通
6.1 完整数据流转
C2D智能知识助手的核心价值在于实现了从知识创建到智能应用的完整流程打通:
6.1.1 上游知识流
关键技术点:
- 变更检测:基于页面版本号和内容哈希的增量检测
- 质量评估:多维度评估内容的完整性、准确性和可读性
- 格式保持:HTML到Markdown转换时保持原有结构和样式
- 实时同步:确保知识库与源文档的一致性
6.1.2 下游应用流
流程优化:
- 问题预处理:自动纠错、补全和标准化
- 多路检索:向量、关键词、语义三重检索保障
- 动态重排:基于相关性、时效性、权威性的智能排序
- 置信度评估:为每个答案提供可信度评分
6.2 关键流程节点
6.2.1 知识质量控制节点
在知识流转的关键节点设置质量控制机制:
class QualityController:def evaluate_content(self, content):scores = {'completeness': self.check_completeness(content), # 完整性'accuracy': self.verify_accuracy(content), # 准确性'readability': self.assess_readability(content), # 可读性'freshness': self.check_freshness(content) # 时效性}# 综合评分overall_score = self.calculate_weighted_score(scores)# 质量阈值控制if overall_score < self.quality_threshold:return self.trigger_quality_improvement(content)return True
6.2.2 检索效果评估节点
实时评估检索质量,确保最佳匹配:
class RetrievalEvaluator:def evaluate_retrieval_quality(self, query, results):metrics = {'relevance': self.calculate_relevance(query, results),'coverage': self.check_coverage(query, results),'diversity': self.measure_diversity(results),'freshness': self.evaluate_freshness(results)}# 如果质量不达标,触发检索策略调整if metrics['relevance'] < self.relevance_threshold:return self.adjust_retrieval_strategy(query, metrics)return results
7. 反馈循环优化机制
7.1 多层次反馈收集
7.1.1 显式反馈机制
即时评价系统:
- 👍👎 快速评价按钮
- 1-5星详细评分
- 文字建议和改进意见
- 问题分类标签(准确性、完整性、相关性)
深度反馈收集:
class FeedbackCollector:def collect_detailed_feedback(self, interaction):feedback = {'question_id': interaction.question_id,'user_rating': interaction.rating,'feedback_dimensions': {'accuracy': interaction.accuracy_score,'completeness': interaction.completeness_score,'relevance': interaction.relevance_score,'helpfulness': interaction.helpfulness_score},'improvement_suggestions': interaction.suggestions,'missing_information': interaction.missing_info}return feedback
7.1.2 隐式反馈挖掘
行为数据分析:
- 用户停留时间和阅读深度
- 后续问题和深入探索行为
- 答案复制、分享等操作行为
- 会话结束方式(满意/不满意)
class ImplicitFeedbackAnalyzer:def analyze_user_behavior(self, session_data):signals = {'engagement': self.calculate_engagement_score(session_data),'satisfaction': self.infer_satisfaction(session_data),'task_completion': self.detect_task_completion(session_data),'exploration_depth': self.measure_exploration(session_data)}return self.convert_to_feedback_score(signals)
7.2 智能学习与优化
7.2.1 实时学习机制
在线学习算法:
class OnlineLearningSystem:def __init__(self):self.retrieval_optimizer = RetrievalOptimizer()self.generation_optimizer = GenerationOptimizer()self.knowledge_optimizer = KnowledgeOptimizer()def process_feedback(self, feedback_batch):# 检索策略优化if feedback_batch.has_retrieval_issues():self.retrieval_optimizer.update_strategy(feedback_batch)# 生成质量优化if feedback_batch.has_generation_issues():self.generation_optimizer.adjust_parameters(feedback_batch)# 知识库内容优化if feedback_batch.has_knowledge_gaps():self.knowledge_optimizer.identify_gaps(feedback_batch)
7.2.2 批量优化策略
定期优化流程:
- 每日优化:基于当日反馈调整检索权重
- 每周优化:分析用户行为模式,优化问题理解
- 每月优化:评估知识库覆盖度,识别知识盲区
class BatchOptimizer:def weekly_optimization(self):# 分析一周的反馈数据feedback_analysis = self.analyze_weekly_feedback()# 识别优化机会opportunities = self.identify_optimization_opportunities(feedback_analysis)# 生成优化策略strategies = self.generate_optimization_strategies(opportunities)# 应用优化self.apply_optimizations(strategies)# 效果验证return self.validate_optimization_effects(strategies)
7.3 闭环优化效果
7.3.1 短期优化效果
实时调整机制:
- 检索结果相关性提升15-20%
- 答案生成准确率提升10-15%
- 用户满意度即时改善
7.3.2 长期学习效果
持续改进成果:
- 知识库覆盖率持续扩大
- 问题理解能力不断增强
- 个性化推荐精度提升
- 系统整体智能化水平提升
class EffectTracker:def track_optimization_effects(self):metrics = {'retrieval_improvement': self.measure_retrieval_improvement(),'generation_quality': self.assess_generation_quality(),'user_satisfaction': self.calculate_satisfaction_trend(),'knowledge_coverage': self.evaluate_knowledge_coverage()}return self.generate_improvement_report(metrics)
8. 核心应用场景:运维知识服务
8.1 运维人员面临的挑战
在企业IT运维环境中,运维人员每天都要面对大量来自用户的各种知识咨询,这些挑战包括:
8.1.1 知识分散化问题
- 多平台分布:技术文档散布在Confluence、Wiki、内部论坛等多个平台
- 版本不一致:同一问题在不同文档中可能有不同的解决方案
- 查找困难:运维人员需要在多个系统间切换查找信息
- 知识孤岛:各部门的知识文档缺乏有效整合
8.1.2 维护滞后问题
- 更新不及时:系统升级后相关文档未能同步更新
- 责任不明确:文档维护责任分散,缺乏统一管理
- 质量参差不齐:不同作者的文档质量和格式差异很大
- 历史遗留:大量过时信息混杂在有效信息中
8.1.3 使用率低下问题
- 查找效率低:传统关键词搜索无法准确匹配用户意图
- 学习成本高:新员工需要花费大量时间熟悉各种文档系统
- 重复劳动:相同问题被反复咨询,运维人员重复回答
- 知识传承难:经验丰富的运维人员离职后知识流失
8.2 C2D智能知识助手的解决方案
8.2.1 统一知识入口
场景描述:用户通过统一的智能助手获取所有运维相关知识
解决方案:
用户提问 → C2D智能助手 → 自动检索所有相关文档 → 提供统一答案
核心价值:
- 一个入口解决所有知识查询需求
- 自动整合多平台的分散信息
- 智能去重和版本控制
- 24/7不间断服务
8.2.2 实时知识同步
场景描述:Confluence文档更新后,用户立即能获取最新信息
技术实现:
class RealTimeSync:def handle_confluence_update(self, page_id, new_content):# 检测内容变更changes = self.detect_changes(page_id, new_content)# 自动更新知识库if changes.is_significant():self.update_knowledge_base(page_id, new_content)# 通知相关用户self.notify_stakeholders(changes)# 重新训练相关模型self.retrain_retrieval_model(page_id)
解决效果:
- 文档更新后2分钟内知识库同步完成
- 消除信息滞后导致的错误指导
- 自动识别重要变更并优先处理
8.2.3 智能问答服务
典型对话场景:
用户:“服务器CPU使用率突然飙升到90%,怎么排查?”
C2D助手:
🔍 检索到3个相关文档,置信度:95%📋 CPU使用率异常排查步骤:1. **立即检查**:• 执行 `top -p` 查看占用最高的进程• 检查系统负载:`uptime` 和 `w`• 查看内存使用情况:`free -h`2. **深入分析**:• 检查进程详情:`ps aux | grep [进程名]`• 查看系统日志:`tail -f /var/log/syslog`• 分析网络连接:`netstat -tulpn`3. **常见原因**:• 批处理任务异常(概率:40%)• 内存泄漏导致频繁GC(概率:25%)• 恶意进程或病毒(概率:15%)📖 参考文档:
• 《服务器性能监控手册》- 第3.2节
• 《CPU异常排查SOP》- 最新版本
• 《系统优化最佳实践》- 相关章节💡 如果问题持续,建议联系高级运维工程师张三(内线:1234)
8.3 具体应用案例
8.3.1 日常运维咨询
问题类型统计(基于实际运维场景):
- 系统故障排查:35%
- 软件配置问题:25%
- 网络连接问题:20%
- 权限和安全问题:15%
- 其他技术咨询:5%
传统方式 vs C2D助手:
| 场景 | 传统方式 | C2D智能助手 |
|---|---|---|
| 响应时间 | 30分钟-2小时 | 2-5秒 |
| 准确率 | 70%(依赖个人经验) | 95%(基于全量文档) |
| 一致性 | 低(不同人员回答不同) | 高(统一知识源) |
| 可用性 | 工作时间内 | 24/7全天候 |
| 知识更新 | 手动,滞后 | 自动,实时 |
8.3.2 新员工培训支持
场景描述:新入职的运维人员需要快速掌握公司的运维知识体系
C2D助手支持:
- 个性化学习路径:根据岗位要求推荐学习内容
- 交互式问答:支持连续提问,深入了解细节
- 实践指导:提供具体的操作步骤和注意事项
- 进度跟踪:记录学习进度,推荐下一步学习内容
8.3.3 知识沉淀与传承
挑战:资深运维人员的经验知识难以有效传承
解决方案:
class KnowledgeCapture:def capture_expert_knowledge(self, expert_interactions):# 分析专家回答模式patterns = self.analyze_expert_responses(expert_interactions)# 提取隐性知识implicit_knowledge = self.extract_implicit_knowledge(patterns)# 结构化存储self.store_structured_knowledge(implicit_knowledge)# 训练模型self.train_expert_model(implicit_knowledge)
效果:
- 专家知识自动提取和结构化
- 新员工可以"对话"资深专家的知识
- 知识不再因人员流动而流失
8.4 量化效果评估
8.4.1 运维效率提升
实施前后对比:
- 问题解决时间:平均从45分钟降低到8分钟(82%提升)
- 首次解决率:从65%提升到92%(42%提升)
- 重复咨询率:从40%降低到8%(80%减少)
- 文档查找时间:从15分钟降低到30秒(97%提升)
8.4.2 知识利用率改善
关键指标:
- 文档访问量:提升300%
- 知识覆盖率:从60%提升到95%
- 知识更新频率:提升5倍
- 用户满意度:从3.2分提升到4.6分(5分制)
8.4.3 成本效益分析
人力成本节约:
- 减少重复性咨询工作量70%
- 新员工培训时间缩短50%
- 知识维护工作量减少60%
- 整体运维团队效率提升40%
9. 性能评估与效果
9.1 技术指标
- 检索准确率:95%+(Top-5召回率)
- 响应时间:平均2秒内
- 并发处理:支持1000+并发用户
- 系统可用性:99.9%+
9.2 业务价值
- 效率提升:知识查找时间减少80%
- 准确性改善:答案准确率提升60%
- 用户满意度:4.5/5.0星评价
- 知识利用率:文档访问量提升200%
10. 未来发展方向
10.1 技术演进
- 多模态支持:支持图片、视频等多媒体内容
- 知识图谱:构建企业知识图谱增强推理能力
- 个性化推荐:基于用户画像的个性化知识推荐
- 实时协作:支持多用户协作式知识探索
10.2 生态扩展
- API开放:提供标准化API接口
- 插件系统:支持第三方插件扩展
- 移动端支持:开发移动应用和小程序
- 国际化:支持多语言和跨文化部署
11. 结论
C2D智能知识助手 - 企业版代表了企业知识管理的新范式。通过RAG架构的深度应用,系统实现了从传统的"人找知识"到智能的"知识找人"的转变。其端到端的自动化流程、企业级的可靠性保障,以及持续学习的优化机制,为企业数字化转型提供了强有力的技术支撑。
随着AI技术的不断发展,我们相信这样的智能知识管理系统将成为企业核心竞争力的重要组成部分,帮助企业更好地管理、利用和创新知识资产。
关于作者
本文基于实际的企业级RAG系统设计经验撰写,涵盖了从架构设计到技术实现的完整方案。如果您对C2D智能知识助手的技术细节或部署方案有任何疑问,欢迎交流讨论。
技术标签:RAG 企业知识管理 Confluence Dify 智能问答 向量检索 大语言模型