【微调大模型】中的梯度概念
梯度
梯度说白了,就是模型训练过程中的指示牌,用于指示后续的训练过程。
想象一下:
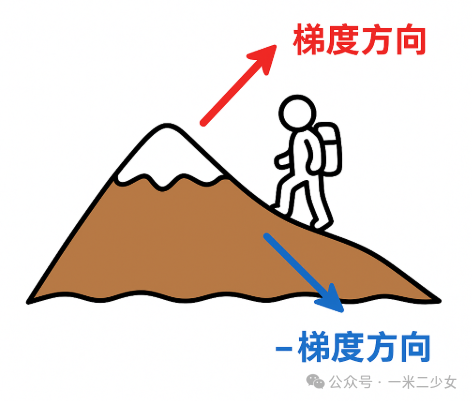
你站在一座大山上,四周雾蒙蒙,看不到山脚。你只知道要下山,但没地图。
怎么办?——你低头看看脚下,找一个坡度最陡、下得最快的方向,然后走一步。
这个“坡度最陡的方向”,就是数学里的梯度方向。
如果想下山,就要沿着梯度的反方向走——这就是著名的 梯度下降法。
真实的梯度
梯度就是函数的偏导组合,比如函数表达式为 ,对X的偏导和对Y的偏导组合。其对应的梯度为
损失函数:模型的行为矫正器
训练神经网络时,我们需要知道模型的预测和真实答案差了多少。这个指标学术上叫 损失函数(Loss Function)。
但换个更形象的名字,你可以把它理解成模型的 “行为矫正器”:
• 它不会直接给答案,而是不断打分:预测偏离多少。
• 分数越高,说明偏差越大;分数越低,说明模型越来越准。
• 然后通过梯度,把“怎么改”反馈回去。
就像老师批改作业:老师不会直接替你写对,而是用红笔标注错误,告诉你改哪里。这支“红笔”就是梯度。
梯度在大模型训练中
当参数数量从几百变成几千亿,梯度依然在发挥作用,只不过场景更复杂:
1️⃣ 梯度同步
多台机器一起训练时,每台 GPU 算自己那一份梯度,最后要“开会统一意见”,这就是 梯度同步。
2️⃣ 梯度裁剪
有时梯度会突然暴涨,像小孩暴冲。梯度裁剪就是给它套上安全带,防止训练崩掉。
3️⃣ 梯度累积
显存不够?就分批算,把小批次的梯度攒起来再更新,这就是 梯度累积。
4️⃣ 混合精度训练
梯度计算也能“节能减排”。用半精度(FP16)来算梯度,既快又省显存。
生活化总结
• 损失函数(行为矫正器) = 考试分数,告诉你“考砸了多少”。
• 梯度 = 老师批改时的红笔批注:“错在这里,往这个方向改!”
• 参数 = 学生的学习习惯。
• 优化器 = 学生的学习方式:是死记硬背(SGD),还是举一反三(Adam)。
训练模型的过程,就像学生在老师的指导下不断练习,直到习惯被矫正,成绩越来越好。
参考地址:
模型训练梯度指的是什么?5分钟轻松理解,无需数学公式