【完整源码+数据集+部署教程】染色体图像分割系统: yolov8-seg-KernelWarehouse
背景意义
研究背景与意义
随着生物医学领域的快速发展,染色体图像的分析与处理已成为细胞遗传学研究中的重要任务。染色体的形态特征不仅与细胞的遗传信息密切相关,还在疾病的诊断、治疗和预后评估中发挥着关键作用。传统的染色体图像分析方法往往依赖于人工观察和手动标注,这不仅耗时耗力,而且容易受到主观因素的影响,导致结果的不一致性和可靠性不足。因此,开发一种高效、准确的染色体图像分割系统显得尤为重要。
近年来,深度学习技术的迅猛发展为图像处理领域带来了革命性的变化。特别是目标检测和实例分割任务中,YOLO(You Only Look Once)系列模型因其优越的实时性和准确性而受到广泛关注。YOLOv8作为该系列的最新版本,进一步提升了模型的性能,能够在保持高精度的同时实现快速推理。然而,尽管YOLOv8在一般目标检测任务中表现出色,但在染色体图像的实例分割任务中,仍然面临着一些挑战,例如背景复杂性、染色体重叠以及不同类别染色体形态的多样性等。
本研究旨在基于改进的YOLOv8模型,构建一个高效的染色体图像分割系统。我们将利用“autokary4”数据集,该数据集包含1300幅染色体图像,涵盖24个类别的染色体实例。这一丰富的数据集为模型的训练和评估提供了坚实的基础。通过对数据集的深入分析,我们可以识别出不同类别染色体的特征,进而优化模型的结构和参数设置,以提高分割精度和鲁棒性。
在研究意义方面,首先,基于改进YOLOv8的染色体图像分割系统将为细胞遗传学研究提供一种自动化的分析工具,极大地提高了染色体分析的效率和准确性。其次,该系统的成功应用将为临床诊断提供重要的技术支持,尤其是在遗传疾病的筛查和癌症的早期检测中,能够帮助医生更快速、准确地识别异常染色体,进而制定相应的治疗方案。此外,本研究还将推动深度学习技术在生物医学领域的应用,探索其在其他生物图像分析任务中的潜力。
综上所述,基于改进YOLOv8的染色体图像分割系统的研究不仅具有重要的理论价值,还有助于推动生物医学图像处理技术的发展。通过本研究,我们希望能够为染色体图像分析提供新的思路和方法,促进相关领域的进步,为人类健康事业做出贡献。
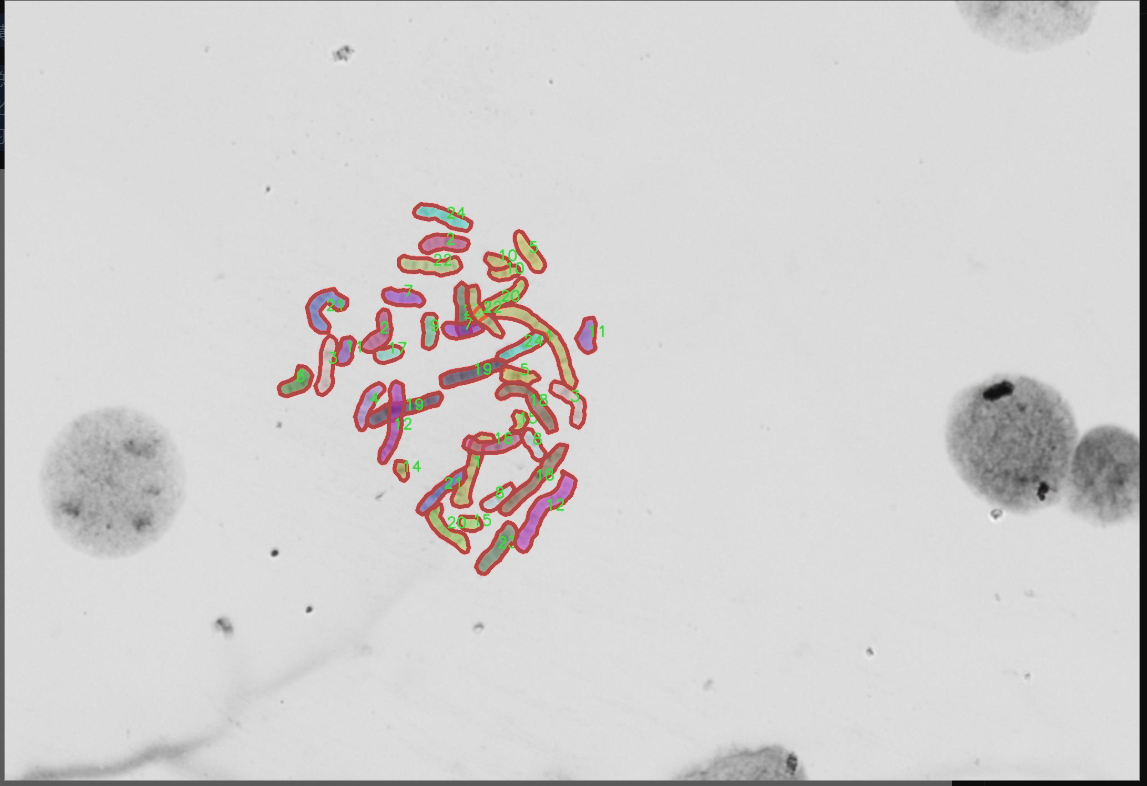
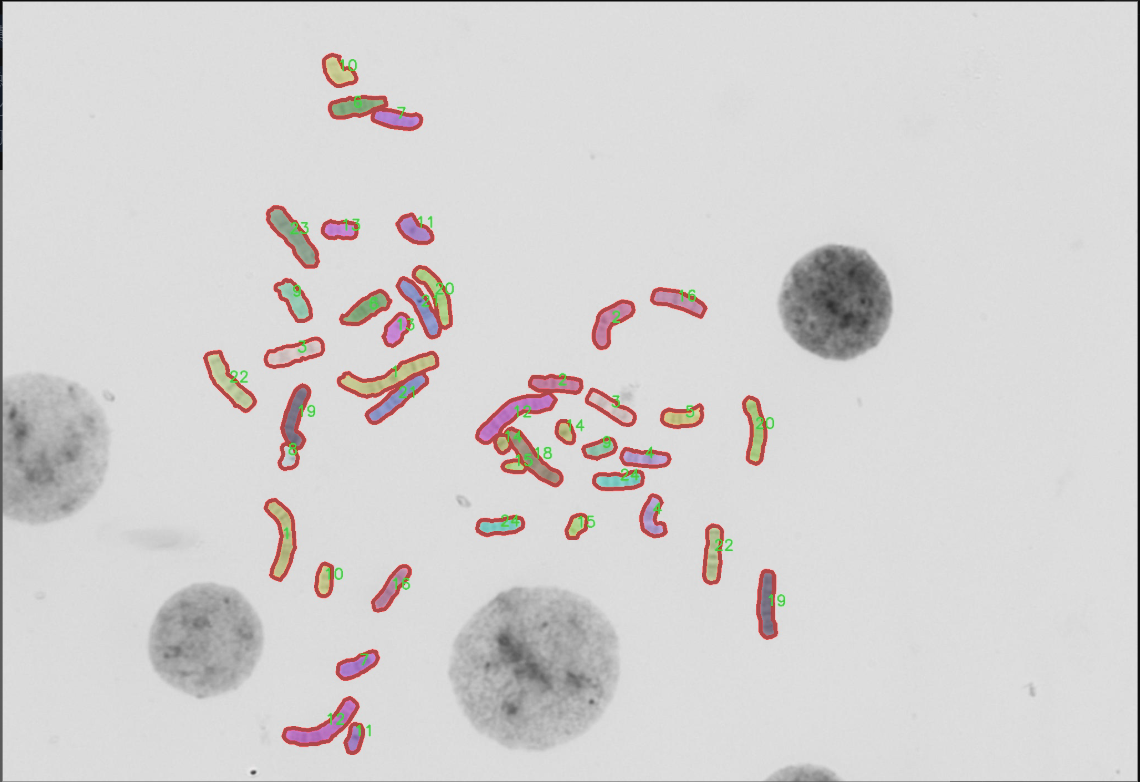
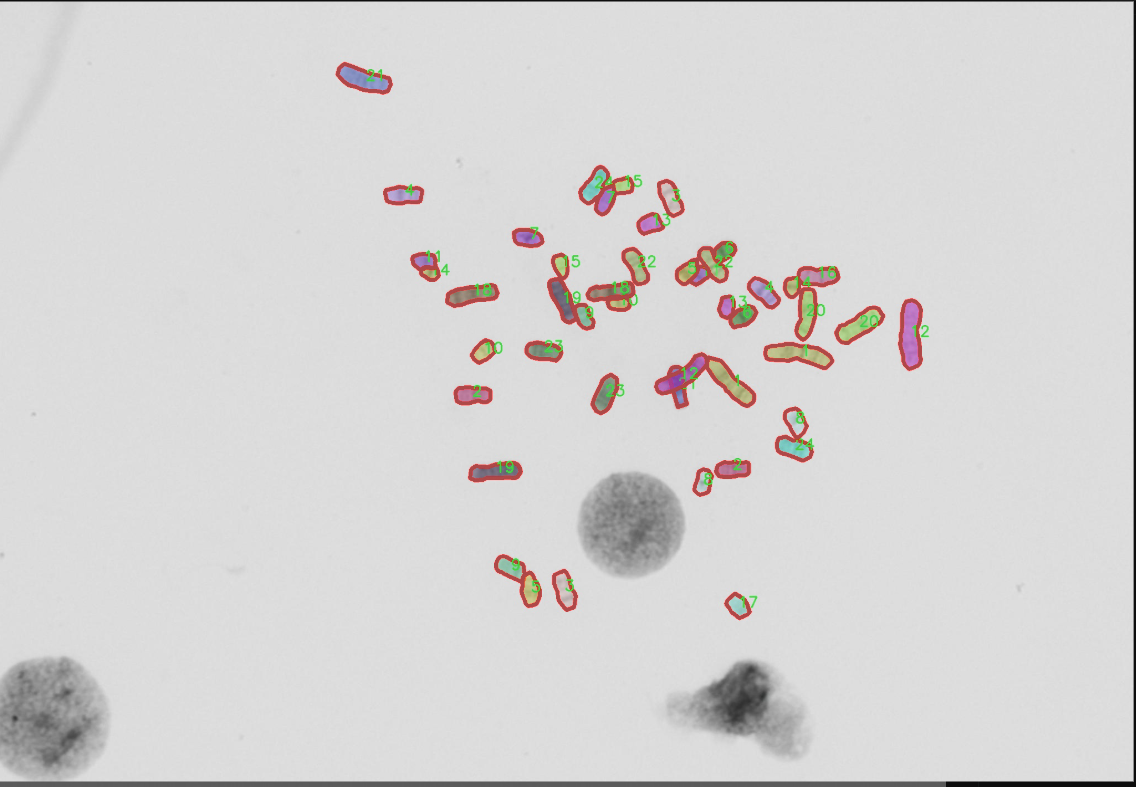
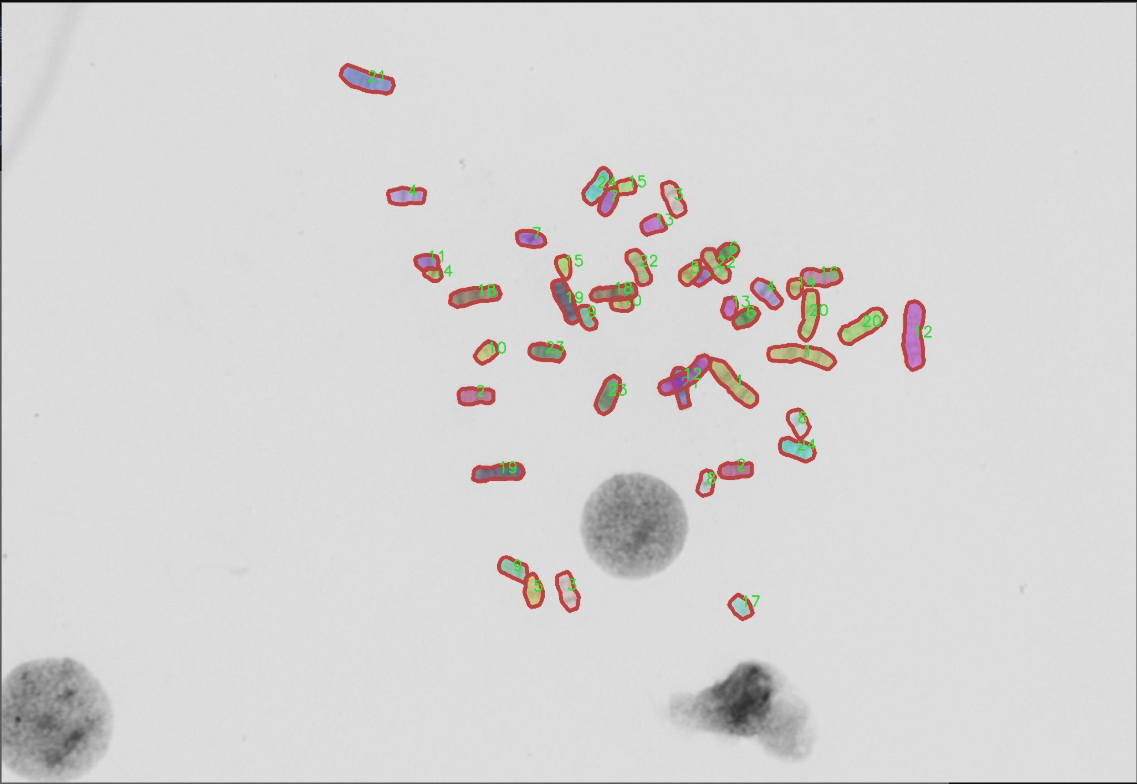
图片效果
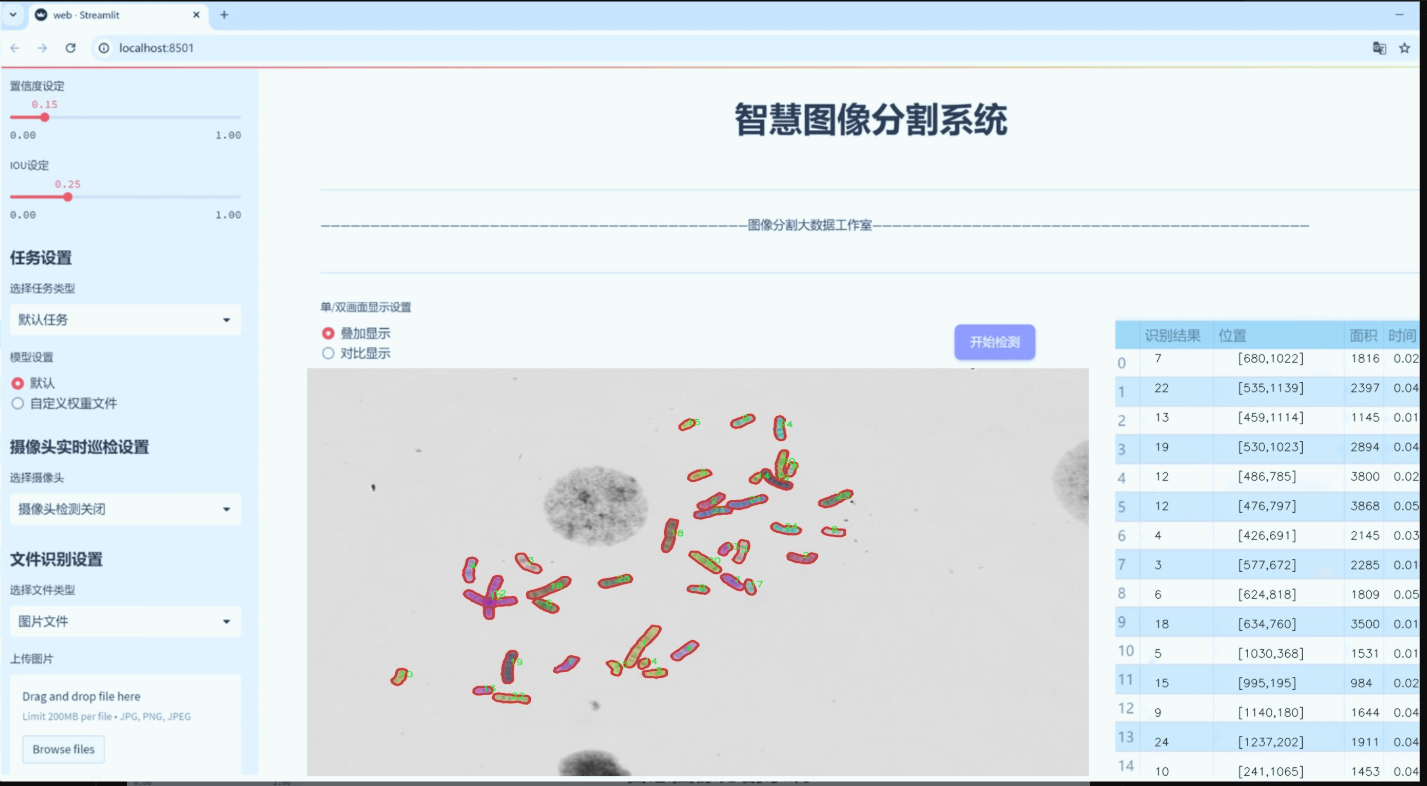
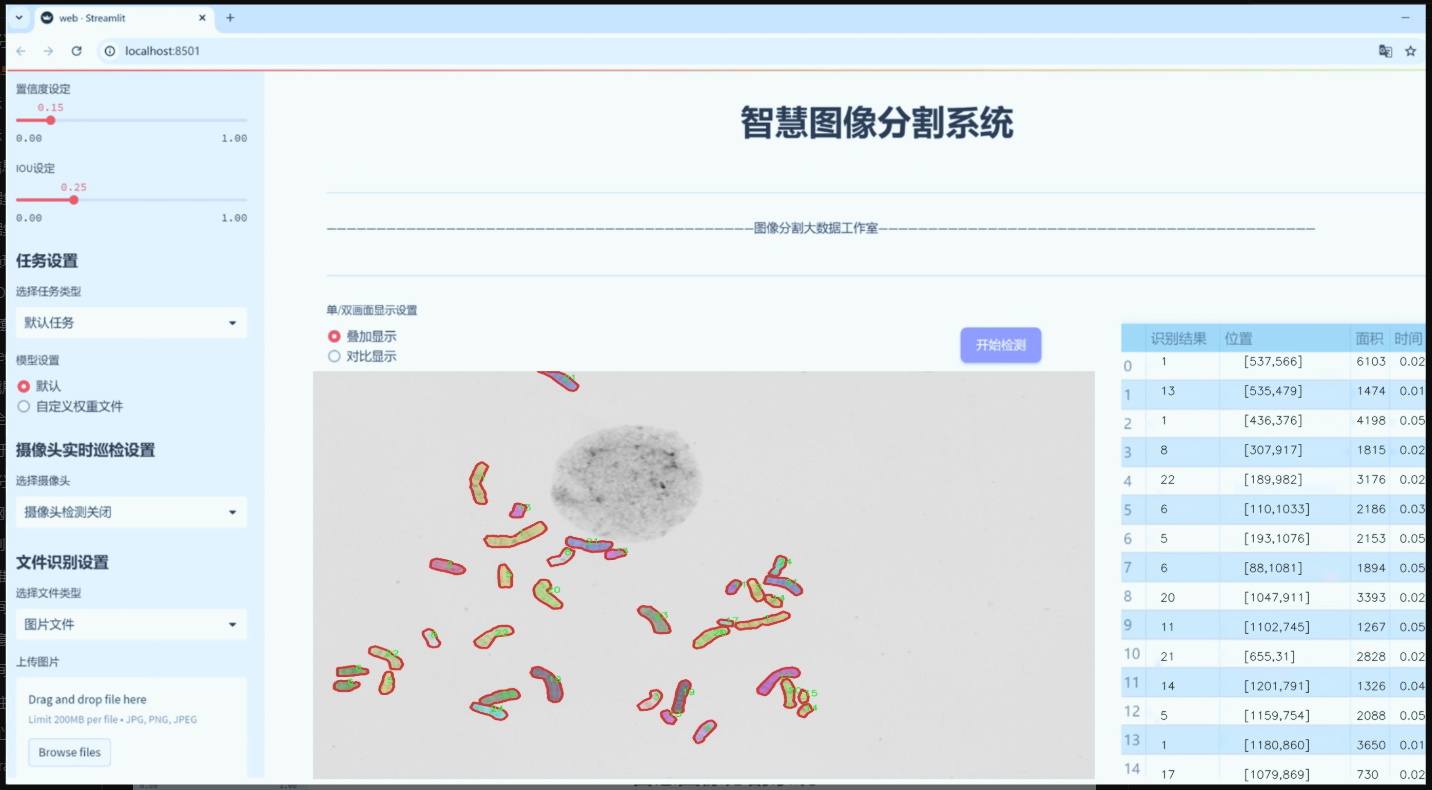
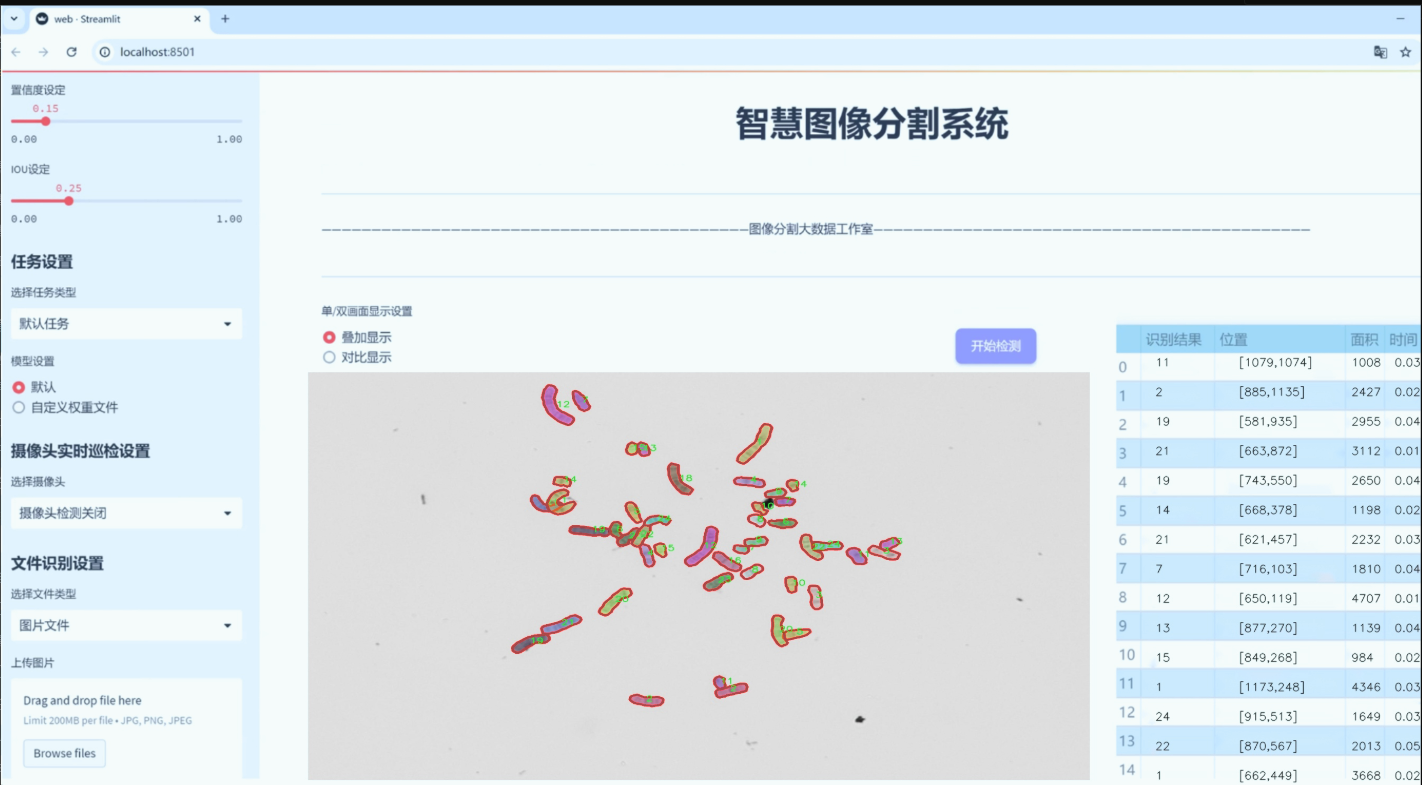
数据集信息
数据集信息展示
在本研究中,我们采用了名为“autokary4”的数据集,以训练和改进YOLOv8-seg的染色体图像分割系统。该数据集的设计旨在为染色体图像分析提供丰富的样本,助力于生物医学领域的研究与应用。通过精确的图像分割,研究人员能够更好地识别和分析染色体的结构与功能,从而为遗传学、细胞生物学等领域的深入研究提供重要的数据支持。
“autokary4”数据集包含24个类别,涵盖了不同类型的染色体图像。这些类别的命名采用了数字形式,从“1”到“24”,分别对应不同的染色体特征或类型。具体而言,这些类别可能代表了不同的染色体形态、大小、结构特征或染色体的特定状态。这种细致的分类使得数据集在图像分割任务中具有高度的针对性和实用性,为YOLOv8-seg模型的训练提供了多样化的样本。
在数据集的构建过程中,研究团队确保了样本的多样性和代表性。每个类别的图像均经过精心挑选,涵盖了不同的染色体图像拍摄条件和背景,以增强模型的泛化能力。数据集中的图像不仅包括了清晰的染色体图像,还包含了在不同光照、对比度和分辨率下拍摄的样本。这种多样性有助于提高YOLOv8-seg在实际应用中的鲁棒性,使其能够在不同的实验条件下保持高效的分割性能。
为了进一步提升模型的训练效果,数据集还进行了数据增强处理。通过对原始图像进行旋转、缩放、翻转和颜色调整等操作,研究团队生成了大量的变体图像。这些增强后的图像不仅增加了数据集的规模,还丰富了模型的训练样本,使其能够更好地适应各种复杂的图像特征。这种数据增强策略在深度学习模型的训练中被广泛应用,能够有效减少过拟合现象,提高模型的泛化能力。
在数据集的标注过程中,采用了精确的标注工具,确保每个染色体图像中的目标区域被准确标识。标注工作由经验丰富的生物医学专家完成,他们对染色体的形态和特征有着深入的理解。这种专业的标注不仅提高了数据集的质量,也为后续的模型训练和评估提供了可靠的基础。
总之,“autokary4”数据集为改进YOLOv8-seg的染色体图像分割系统提供了坚实的数据基础。通过丰富的类别设置、多样化的样本和精确的标注,该数据集不仅满足了研究需求,也为染色体图像分析的深入研究提供了广阔的前景。随着深度学习技术的不断发展,基于该数据集的研究将有望推动染色体图像分析的进步,为生物医学领域的科学探索提供新的动力。
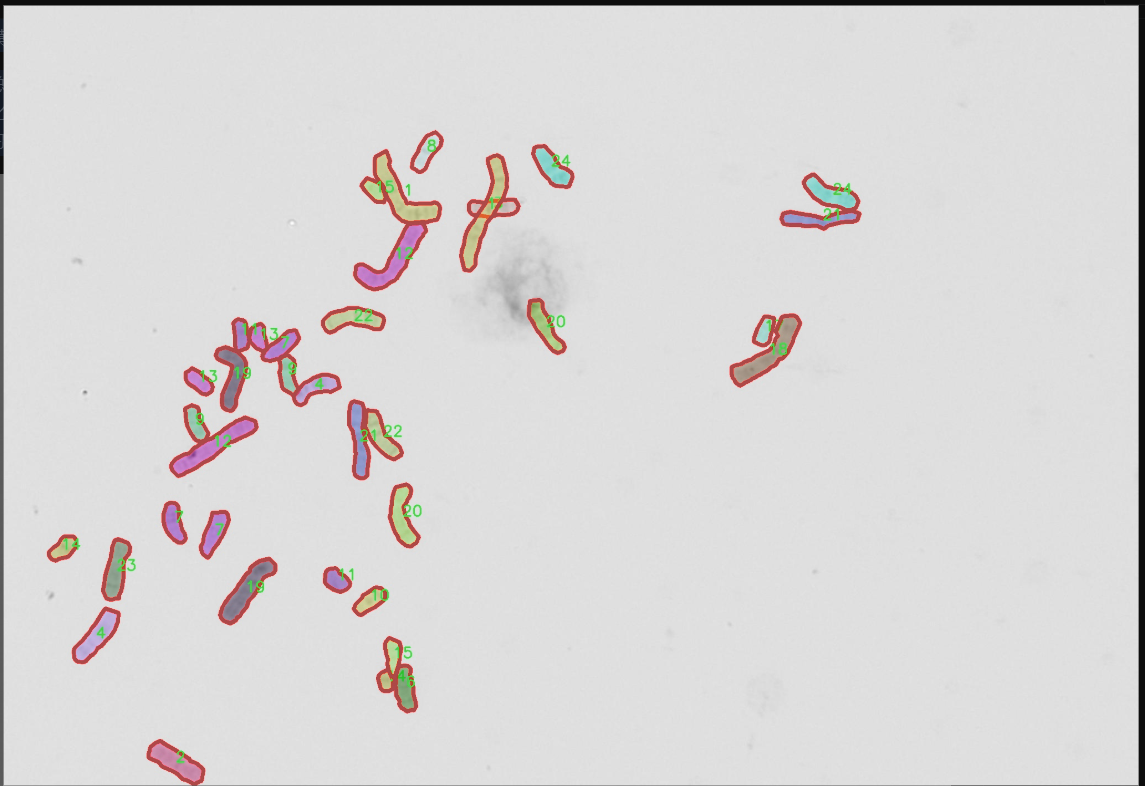
核心代码
以下是经过简化并添加详细中文注释的核心代码部分:
import torch
from torch import nn
import torch.nn.functional as F
from torch.nn.init import xavier_uniform_, constant_
定义一个将通道维度移到前面的模块
class to_channels_first(nn.Module):
def init(self):
super().init()
def forward(self, x):# 将输入的形状从 (N, H, W, C) 转换为 (N, C, H, W)return x.permute(0, 3, 1, 2)
定义一个将通道维度移到最后的模块
class to_channels_last(nn.Module):
def init(self):
super().init()
def forward(self, x):# 将输入的形状从 (N, C, H, W) 转换为 (N, H, W, C)return x.permute(0, 2, 3, 1)
构建归一化层
def build_norm_layer(dim, norm_layer, in_format=‘channels_last’, out_format=‘channels_last’, eps=1e-6):
layers = []
if norm_layer == ‘BN’:
if in_format == ‘channels_last’:
layers.append(to_channels_first()) # 转换格式
layers.append(nn.BatchNorm2d(dim)) # 添加批归一化层
if out_format == ‘channels_last’:
layers.append(to_channels_last()) # 转换格式
elif norm_layer == ‘LN’:
if in_format == ‘channels_first’:
layers.append(to_channels_last()) # 转换格式
layers.append(nn.LayerNorm(dim, eps=eps)) # 添加层归一化层
if out_format == ‘channels_first’:
layers.append(to_channels_first()) # 转换格式
else:
raise NotImplementedError(f’build_norm_layer does not support {norm_layer}')
return nn.Sequential(*layers) # 返回一个顺序容器
定义中心特征缩放模块
class CenterFeatureScaleModule(nn.Module):
def forward(self, query, center_feature_scale_proj_weight, center_feature_scale_proj_bias):
# 通过线性变换计算中心特征缩放
center_feature_scale = F.linear(query, weight=center_feature_scale_proj_weight, bias=center_feature_scale_proj_bias).sigmoid()
return center_feature_scale
定义DCNv3模块
class DCNv3(nn.Module):
def init(self, channels=64, kernel_size=3, stride=1, pad=1, dilation=1, group=4, offset_scale=1.0, center_feature_scale=False, remove_center=False):
super().init()
if channels % group != 0:
raise ValueError(f’channels must be divisible by group, but got {channels} and {group}')
self.channels = channelsself.kernel_size = kernel_sizeself.stride = strideself.dilation = dilationself.pad = padself.group = groupself.group_channels = channels // groupself.offset_scale = offset_scaleself.center_feature_scale = center_feature_scaleself.remove_center = int(remove_center)# 定义深度卷积层self.dw_conv = nn.Conv2d(channels, channels, kernel_size, stride=1, padding=(kernel_size - 1) // 2, groups=channels)# 定义偏移量和掩码的线性层self.offset = nn.Linear(channels, group * (kernel_size * kernel_size - remove_center) * 2)self.mask = nn.Linear(channels, group * (kernel_size * kernel_size - remove_center))self.input_proj = nn.Linear(channels, channels) # 输入投影层self.output_proj = nn.Linear(channels, channels) # 输出投影层self._reset_parameters() # 初始化参数# 如果启用中心特征缩放,定义相关参数if center_feature_scale:self.center_feature_scale_proj_weight = nn.Parameter(torch.zeros((group, channels), dtype=torch.float))self.center_feature_scale_proj_bias = nn.Parameter(torch.tensor(0.0, dtype=torch.float).view((1,)).repeat(group, ))self.center_feature_scale_module = CenterFeatureScaleModule()def _reset_parameters(self):# 重置参数constant_(self.offset.weight.data, 0.)constant_(self.offset.bias.data, 0.)constant_(self.mask.weight.data, 0.)constant_(self.mask.bias.data, 0.)xavier_uniform_(self.input_proj.weight.data)constant_(self.input_proj.bias.data, 0.)xavier_uniform_(self.output_proj.weight.data)constant_(self.output_proj.bias.data, 0.)def forward(self, input):""":param input: 输入张量 (N, H, W, C):return: 输出张量 (N, H, W, C)"""N, H, W, _ = input.shape # 获取输入的形状x = self.input_proj(input) # 输入投影x_proj = x # 保存输入投影的副本x1 = input.permute(0, 3, 1, 2) # 转换输入格式x1 = self.dw_conv(x1) # 深度卷积offset = self.offset(x1) # 计算偏移量mask = self.mask(x1).reshape(N, H, W, self.group, -1) # 计算掩码mask = F.softmax(mask, -1).reshape(N, H, W, -1) # 应用softmax# 这里假设有一个dcnv3_core_pytorch函数用于执行DCN操作x = dcnv3_core_pytorch(x, offset, mask, self.kernel_size, self.kernel_size, self.stride, self.stride, self.pad, self.pad, self.dilation, self.dilation, self.group, self.group_channels, self.offset_scale, self.remove_center)# 如果启用中心特征缩放if self.center_feature_scale:center_feature_scale = self.center_feature_scale_module(x1, self.center_feature_scale_proj_weight, self.center_feature_scale_proj_bias)center_feature_scale = center_feature_scale[..., None].repeat(1, 1, 1, 1, self.channels // self.group).flatten(-2)x = x * (1 - center_feature_scale) + x_proj * center_feature_scale # 结合输入和输出x = self.output_proj(x) # 输出投影return x # 返回结果
代码说明:
模块转换:to_channels_first 和 to_channels_last 类用于在不同的通道格式之间转换。
归一化层构建:build_norm_layer 函数根据输入格式和所需的归一化类型(批归一化或层归一化)构建相应的归一化层。
中心特征缩放模块:CenterFeatureScaleModule 用于计算中心特征缩放。
DCNv3模块:DCNv3 类实现了深度可分离卷积的核心功能,包括输入投影、深度卷积、偏移量和掩码的计算,并结合中心特征缩放(如果启用)。
这个程序文件实现了一个名为DCNv3的深度学习模块,主要用于计算机视觉任务中的卷积操作。该模块基于动态卷积(Dynamic Convolution)技术,允许根据输入特征动态调整卷积核的偏移和权重。以下是对代码的详细说明。
首先,文件导入了一些必要的库,包括PyTorch的核心模块和功能。接着定义了一些辅助类和函数。to_channels_first和to_channels_last类用于在不同的通道格式之间转换,分别将输入从“通道最后”(channels last)格式转换为“通道第一”(channels first)格式,反之亦然。这在处理输入数据时非常重要,因为不同的操作可能需要不同的格式。
build_norm_layer函数用于构建归一化层,可以选择使用批归一化(Batch Normalization)或层归一化(Layer Normalization),并根据输入和输出格式进行相应的格式转换。build_act_layer函数则用于构建激活函数层,支持ReLU、SiLU和GELU等常用激活函数。
_is_power_of_2函数用于检查一个数是否是2的幂,这在某些情况下可以提高计算效率。
CenterFeatureScaleModule类实现了一个中心特征缩放模块,用于对特征进行缩放处理。
DCNv3_pytorch类是DCNv3模块的具体实现。它的构造函数接收多个参数,包括通道数、卷积核大小、步幅、填充、扩张率、分组数等。构造函数中首先进行了一些参数验证,然后初始化了一些卷积层、线性层和其他参数。特别地,如果启用了中心特征缩放功能,则会初始化相关的权重和偏置。
_reset_parameters方法用于初始化各个层的参数,确保模型在训练开始时具有良好的初始状态。
forward方法是模块的前向传播逻辑。它接收输入数据,经过一系列的线性变换和卷积操作,最终输出处理后的特征图。该方法还包含了对中心特征缩放的处理逻辑。
DCNv3类是DCNv3模块的另一种实现,主要区别在于它使用了自定义的卷积类Conv,而不是直接使用PyTorch的卷积层。该类的构造函数和前向传播逻辑与DCNv3_pytorch类似。
DCNv3_DyHead类则是DCNv3模块的一个变体,主要用于处理动态头部的特征。它的构造函数和前向传播逻辑也与前面的类相似,但专注于处理特定的输入和输出格式。
总体而言,这个文件实现了一个灵活且高效的动态卷积模块,适用于各种计算机视觉任务,能够根据输入特征动态调整卷积操作,从而提高模型的表现。
11.5 ultralytics\data_init_.py
以下是代码中最核心的部分,并附上详细的中文注释:
导入基础数据集类
from .base import BaseDataset
导入构建数据加载器和YOLO数据集的函数
from .build import build_dataloader, build_yolo_dataset, load_inference_source
导入不同类型的数据集类
from .dataset import ClassificationDataset, SemanticDataset, YOLODataset
定义模块的公开接口,包含所有需要被外部访问的类和函数
all = (
‘BaseDataset’, # 基础数据集类
‘ClassificationDataset’, # 分类数据集类
‘SemanticDataset’, # 语义分割数据集类
‘YOLODataset’, # YOLO目标检测数据集类
‘build_yolo_dataset’, # 构建YOLO数据集的函数
‘build_dataloader’, # 构建数据加载器的函数
‘load_inference_source’ # 加载推理源的函数
)
代码注释说明:
导入模块:
from .base import BaseDataset:从当前包的base模块中导入BaseDataset类,这是所有数据集的基础类。
from .build import build_dataloader, build_yolo_dataset, load_inference_source:从build模块中导入三个函数,分别用于构建数据加载器、构建YOLO数据集和加载推理源。
from .dataset import ClassificationDataset, SemanticDataset, YOLODataset:从dataset模块中导入三种不同类型的数据集类,分别用于分类、语义分割和YOLO目标检测。
定义公开接口:
all__是一个特殊变量,用于定义模块的公开接口,指定哪些类和函数可以被外部导入。这里列出了基础数据集类、三种数据集类以及三个构建和加载的函数。这样做可以控制模块的可见性,避免不必要的内部实现被外部访问。
这个程序文件是Ultralytics YOLO项目中的一个初始化文件,文件名为__init.py,通常用于标识一个目录为Python包。文件的开头包含了一条注释,表明该项目是Ultralytics YOLO,并且遵循AGPL-3.0许可证。
在文件中,首先从同一包的其他模块中导入了一些类和函数。具体来说,导入了BaseDataset类,这通常是一个基础数据集类,可能为其他数据集类提供通用的方法和属性。此外,还导入了三个函数:build_dataloader、build_yolo_dataset和load_inference_source,这些函数可能用于构建数据加载器、构建YOLO数据集以及加载推理所需的数据源。
接下来,文件定义了__all__变量,这是一个特殊的变量,用于指定当使用from module import *语句时,哪些名称会被导入。在这里,__all__包含了四个类和三个函数的名称,分别是BaseDataset、ClassificationDataset、SemanticDataset、YOLODataset、build_yolo_dataset、build_dataloader和load_inference_source。这意味着这些名称是该模块的公共接口,用户可以直接使用它们。
总的来说,这个文件的主要功能是组织和导出Ultralytics YOLO项目中的数据集相关的类和函数,使得其他模块能够方便地使用这些功能。
12.系统整体结构(节选)
程序整体功能和构架概括
该程序是Ultralytics YOLO项目的一部分,主要集中在深度学习模型的构建、训练和评估上。它包含了多个模块,分别实现了不同的功能,如模型架构、注意力机制、性能评估和数据处理等。以下是对各个模块的整体功能和构架的概括:
模型架构:convnextv2.py实现了ConvNeXtV2模型,提供了灵活的卷积神经网络结构,适用于图像分类任务。
注意力机制:attention.py实现了多种注意力模块,增强了特征表示能力,适用于各种视觉任务。
性能评估:metrics.py提供了多种评估指标的计算功能,包括IoU、AP、混淆矩阵等,帮助用户评估模型性能。
动态卷积:dcnv3.py实现了动态卷积模块,允许根据输入特征动态调整卷积操作,提升模型表现。
数据处理:init.py文件组织和导出数据集相关的类和函数,便于其他模块的使用。
文件功能整理表
文件路径 功能描述
ultralytics/nn/backbone/convnextv2.py 实现ConvNeXtV2模型,提供灵活的卷积神经网络结构,适用于图像分类任务。
ultralytics/nn/extra_modules/attention.py 实现多种注意力机制模块,增强特征表示能力,适用于各种视觉任务。
ultralytics/utils/metrics.py 提供多种评估指标的计算功能,包括IoU、AP、混淆矩阵等,帮助用户评估模型性能。
ultralytics/nn/extra_modules/ops_dcnv3/modules/dcnv3.py 实现动态卷积模块,允许根据输入特征动态调整卷积操作,提升模型表现。
ultralytics/data/init.py 组织和导出数据集相关的类和函数,便于其他模块的使用。
这个表格总结了每个文件的主要功能,帮助理解Ultralytics YOLO项目的整体架构和模块间的关系。
13.图片、视频、摄像头图像分割Demo(去除WebUI)代码
在这个博客小节中,我们将讨论如何在不使用WebUI的情况下,实现图像分割模型的使用。本项目代码已经优化整合,方便用户将分割功能嵌入自己的项目中。 核心功能包括图片、视频、摄像头图像的分割,ROI区域的轮廓提取、类别分类、周长计算、面积计算、圆度计算以及颜色提取等。 这些功能提供了良好的二次开发基础。
核心代码解读
以下是主要代码片段,我们会为每一块代码进行详细的批注解释:
import random
import cv2
import numpy as np
from PIL import ImageFont, ImageDraw, Image
from hashlib import md5
from model import Web_Detector
from chinese_name_list import Label_list
根据名称生成颜色
def generate_color_based_on_name(name):
…
计算多边形面积
def calculate_polygon_area(points):
return cv2.contourArea(points.astype(np.float32))
…
绘制中文标签
def draw_with_chinese(image, text, position, font_size=20, color=(255, 0, 0)):
image_pil = Image.fromarray(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(image_pil)
font = ImageFont.truetype(“simsun.ttc”, font_size, encoding=“unic”)
draw.text(position, text, font=font, fill=color)
return cv2.cvtColor(np.array(image_pil), cv2.COLOR_RGB2BGR)
动态调整参数
def adjust_parameter(image_size, base_size=1000):
max_size = max(image_size)
return max_size / base_size
绘制检测结果
def draw_detections(image, info, alpha=0.2):
name, bbox, conf, cls_id, mask = info[‘class_name’], info[‘bbox’], info[‘score’], info[‘class_id’], info[‘mask’]
adjust_param = adjust_parameter(image.shape[:2])
spacing = int(20 * adjust_param)
if mask is None:x1, y1, x2, y2 = bboxaim_frame_area = (x2 - x1) * (y2 - y1)cv2.rectangle(image, (x1, y1), (x2, y2), color=(0, 0, 255), thickness=int(3 * adjust_param))image = draw_with_chinese(image, name, (x1, y1 - int(30 * adjust_param)), font_size=int(35 * adjust_param))y_offset = int(50 * adjust_param) # 类别名称上方绘制,其下方留出空间
else:mask_points = np.concatenate(mask)aim_frame_area = calculate_polygon_area(mask_points)mask_color = generate_color_based_on_name(name)try:overlay = image.copy()cv2.fillPoly(overlay, [mask_points.astype(np.int32)], mask_color)image = cv2.addWeighted(overlay, 0.3, image, 0.7, 0)cv2.drawContours(image, [mask_points.astype(np.int32)], -1, (0, 0, 255), thickness=int(8 * adjust_param))# 计算面积、周长、圆度area = cv2.contourArea(mask_points.astype(np.int32))perimeter = cv2.arcLength(mask_points.astype(np.int32), True)......# 计算色彩mask = np.zeros(image.shape[:2], dtype=np.uint8)cv2.drawContours(mask, [mask_points.astype(np.int32)], -1, 255, -1)color_points = cv2.findNonZero(mask)......# 绘制类别名称x, y = np.min(mask_points, axis=0).astype(int)image = draw_with_chinese(image, name, (x, y - int(30 * adjust_param)), font_size=int(35 * adjust_param))y_offset = int(50 * adjust_param)# 绘制面积、周长、圆度和色彩值metrics = [("Area", area), ("Perimeter", perimeter), ("Circularity", circularity), ("Color", color_str)]for idx, (metric_name, metric_value) in enumerate(metrics):......return image, aim_frame_area
处理每帧图像
def process_frame(model, image):
pre_img = model.preprocess(image)
pred = model.predict(pre_img)
det = pred[0] if det is not None and len(det)
if det:
det_info = model.postprocess(pred)
for info in det_info:
image, _ = draw_detections(image, info)
return image
if name == “main”:
cls_name = Label_list
model = Web_Detector()
model.load_model(“./weights/yolov8s-seg.pt”)
# 摄像头实时处理
cap = cv2.VideoCapture(0)
while cap.isOpened():ret, frame = cap.read()if not ret:break......# 图片处理
image_path = './icon/OIP.jpg'
image = cv2.imread(image_path)
if image is not None:processed_image = process_frame(model, image)......# 视频处理
video_path = '' # 输入视频的路径
cap = cv2.VideoCapture(video_path)
while cap.isOpened():ret, frame = cap.read()......
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻