Dubbo源码解读与实战-基础知识(下)
06 ZooKeeper与Curator,求你别用ZkClient了(上)
在前面我们介绍 Dubbo 简化架构的时候提到过,Dubbo Provider 在启动时会将自身的服务信息整理成 URL 注册到注册中心,Dubbo Consumer 在启动时会向注册中心订阅感兴趣的 Provider 信息,之后 Provider 和 Consumer 才能建立连接,进行后续的交互。可见,一个稳定、高效的注册中心对基于 Dubbo 的微服务来说是至关重要的。
Dubbo 目前支持 Consul、etcd、Nacos、ZooKeeper、Redis 等多种开源组件作为注册中心,并且在 Dubbo 源码也有相应的接入模块,如下图所示:
Dubbo 官方推荐使用 ZooKeeper 作为注册中心,它是在实际生产中最常用的注册中心实现,这也是我们本课时要介绍 ZooKeeper 核心原理的原因。
要与 ZooKeeper 集群进行交互,我们可以使用 ZooKeeper 原生客户端或是 ZkClient、Apache Curator 等第三方开源客户端。在后面介绍 dubbo-registry-zookeeper 模块的具体实现时你会看到,Dubbo 底层使用的是 Apache Curator。Apache Curator 是实践中最常用的 ZooKeeper 客户端。
ZooKeeper 核心概念
Apache ZooKeeper 是一个针对分布式系统的、可靠的、可扩展的协调服务,它通常作为统一命名服务、统一配置管理、注册中心(分布式集群管理)、分布式锁服务、Leader 选举服务等角色出现。很多分布式系统都依赖与 ZooKeeper 集群实现分布式系统间的协调调度,例如:Dubbo、HDFS 2.x、HBase、Kafka 等。ZooKeeper 已经成为现代分布式系统的标配。
ZooKeeper 本身也是一个分布式应用程序,下图展示了 ZooKeeper 集群的核心架构。
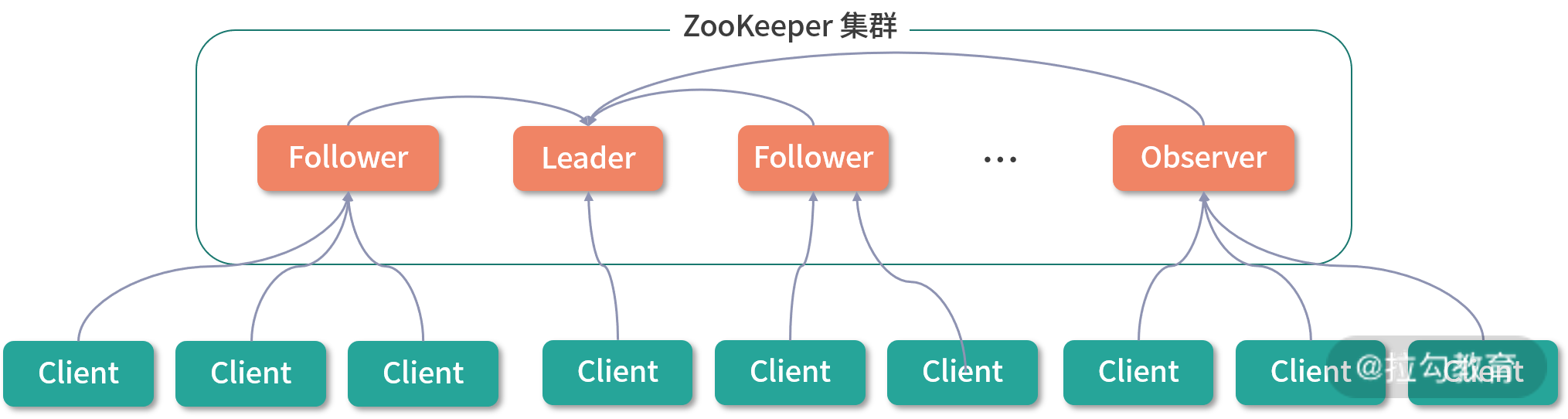
ZooKeeper 集群的核心架构图
- Client 节点:从业务角度来看,这是分布式应用中的一个节点,通过 ZkClient 或是其他 ZooKeeper 客户端与 ZooKeeper 集群中的一个 Server 实例维持长连接,并定时发送心跳。从 ZooKeeper 集群的角度来看,它是 ZooKeeper 集群的一个客户端,可以主动查询或操作 ZooKeeper 集群中的数据,也可以在某些 ZooKeeper 节点(ZNode)上添加监听。当被监听的 ZNode 节点发生变化时,例如,该 ZNode 节点被删除、新增子节点或是其中数据被修改等,ZooKeeper 集群都会立即通过长连接通知 Client。
- Leader 节点:ZooKeeper 集群的主节点,负责整个 ZooKeeper 集群的写操作,保证集群内事务处理的顺序性。同时,还要负责整个集群中所有 Follower 节点与 Observer 节点的数据同步。
- Follower 节点:ZooKeeper 集群中的从节点,可以接收 Client 读请求并向 Client 返回结果,并不处理写请求,而是转发到 Leader 节点完成写入操作。另外,Follower 节点还会参与 Leader 节点的选举。
- Observer 节点:ZooKeeper 集群中特殊的从节点,不会参与 Leader 节点的选举,其他功能与 Follower 节点相同。引入 Observer 角色的目的是增加 ZooKeeper 集群读操作的吞吐量,如果单纯依靠增加 Follower 节点来提高 ZooKeeper 的读吞吐量,那么有一个很严重的副作用,就是 ZooKeeper 集群的写能力会大大降低,因为 ZooKeeper 写数据时需要 Leader 将写操作同步给半数以上的 Follower 节点。引入 Observer 节点使得 ZooKeeper 集群在写能力不降低的情况下,大大提升了读操作的吞吐量。
了解了 ZooKeeper 整体的架构之后,我们再来了解一下 ZooKeeper 集群存储数据的逻辑结构。ZooKeeper 逻辑上是按照树型结构进行数据存储的(如下图),其中的节点称为 ZNode。每个 ZNode 有一个名称标识,即树根到该节点的路径(用 “/” 分隔),ZooKeeper 树中的每个节点都可以拥有子节点,这与文件系统的目录树类似。
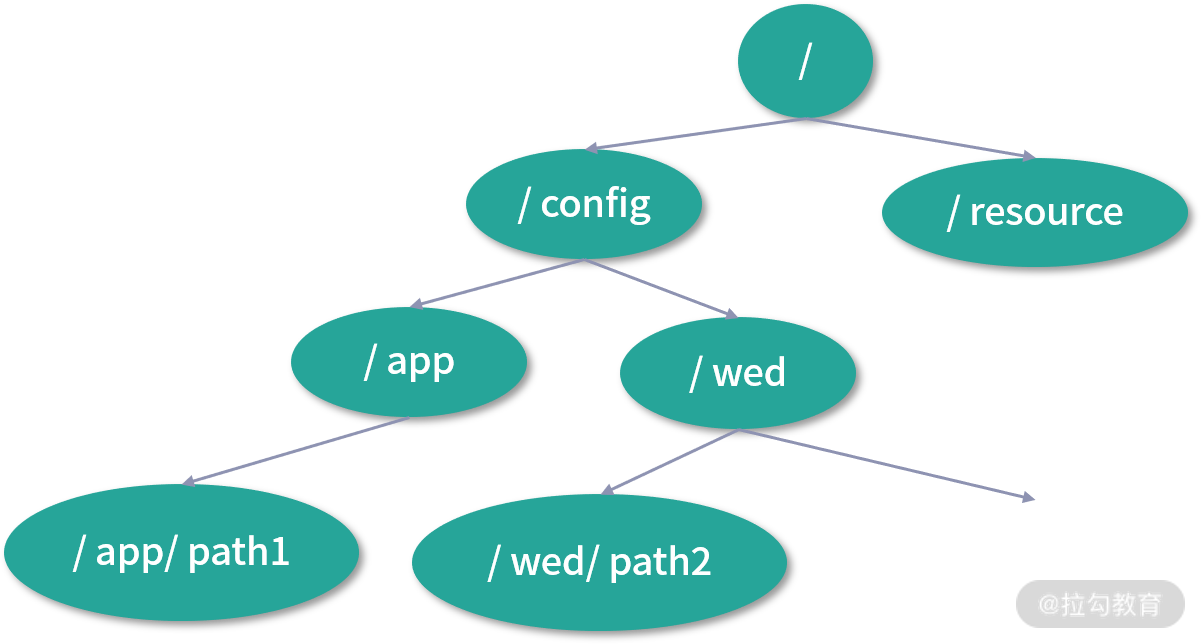
ZooKeeper 树型存储结构
ZNode 节点类型有如下四种:
- 持久节点。 持久节点创建后,会一直存在,不会因创建该节点的 Client 会话失效而删除。
- 持久顺序节点。 持久顺序节点的基本特性与持久节点一致,创建节点的过程中,ZooKeeper 会在其名字后自动追加一个单调增长的数字后缀,作为新的节点名。
- 临时节点。 创建临时节点的 ZooKeeper Client 会话失效之后,其创建的临时节点会被 ZooKeeper 集群自动删除。与持久节点的另一点区别是,临时节点下面不能再创建子节点。
- 临时顺序节点。 基本特性与临时节点一致,创建节点的过程中,ZooKeeper 会在其名字后自动追加一个单调增长的数字后缀,作为新的节点名。
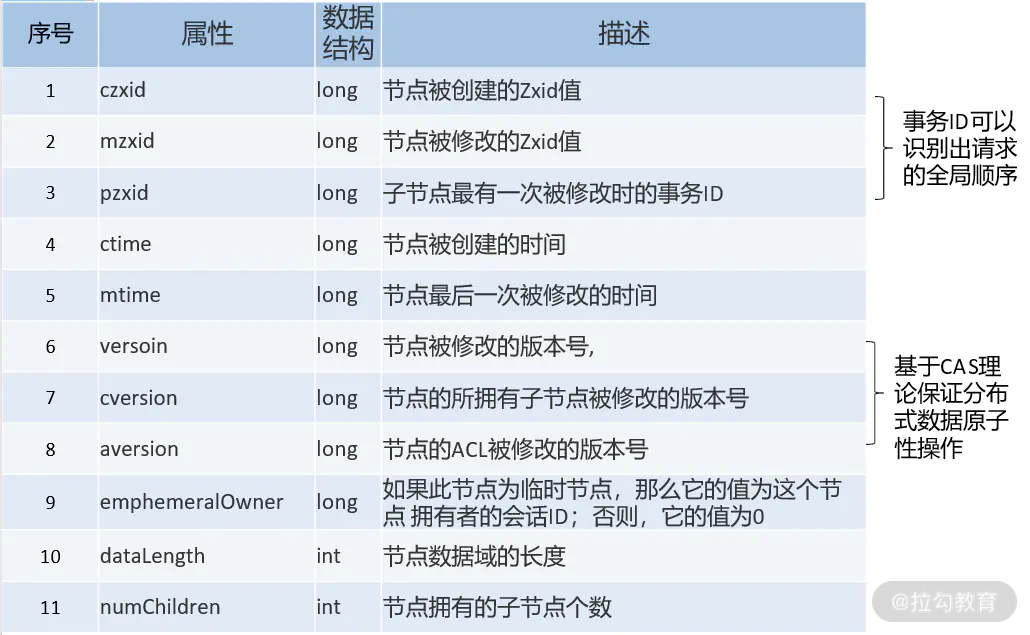
在每个 ZNode 中都维护着一个 stat 结构,记录了该 ZNode 的元数据,其中包括版本号、操作控制列表(ACL)、时间戳和数据长度等信息,如下表所示:
我们除了可以通过 ZooKeeper Client 对 ZNode 进行增删改查等基本操作,还可以注册 Watcher 监听 ZNode 节点、其中的数据以及子节点的变化。一旦监听到变化,则相应的 Watcher 即被触发,相应的 ZooKeeper Client 会立即得到通知。Watcher 有如下特点:
- 主动推送。 Watcher 被触发时,由 ZooKeeper 集群主动将更新推送给客户端,而不需要客户端轮询。
- 一次性。 数据变化时,Watcher 只会被触发一次。如果客户端想得到后续更新的通知,必须要在 Watcher 被触发后重新注册一个 Watcher。
- 可见性。 如果一个客户端在读请求中附带 Watcher,Watcher 被触发的同时再次读取数据,客户端在得到 Watcher 消息之前肯定不可能看到更新后的数据。换句话说,更新通知先于更新结果。
- 顺序性。 如果多个更新触发了多个 Watcher ,那 Watcher 被触发的顺序与更新顺序一致。
消息广播流程概述
ZooKeeper 集群中三种角色的节点(Leader、Follower 和 Observer)都可以处理 Client 的读请求,因为每个节点都保存了相同的数据副本,直接进行读取即可返回给 Client。
对于写请求,如果 Client 连接的是 Follower 节点(或 Observer 节点),则在 Follower 节点(或 Observer 节点)收到写请求将会被转发到 Leader 节点。下面是 Leader 处理写请求的核心流程:
- Leader 节点接收写请求后,会为写请求赋予一个全局唯一的 zxid(64 位自增 id),通过 zxid 的大小比较就可以实现写操作的顺序一致性。
- Leader 通过先进先出队列(会给每个 Follower 节点都创建一个队列,保证发送的顺序性),将带有 zxid 的消息作为一个 proposal(提案)分发给所有 Follower 节点。
- 当 Follower 节点接收到 proposal 之后,会先将 proposal 写到本地事务日志,写事务成功后再向 Leader 节点回一个 ACK 响应。
- 当 Leader 节点接收到过半 Follower 的 ACK 响应之后,Leader 节点就向所有 Follower 节点发送 COMMIT 命令,并在本地执行提交。
- 当 Follower 收到消息的 COMMIT 命令之后也会提交操作,写操作到此完成。
- 最后,Follower 节点会返回 Client 写请求相应的响应。
下图展示了写操作的核心流程:
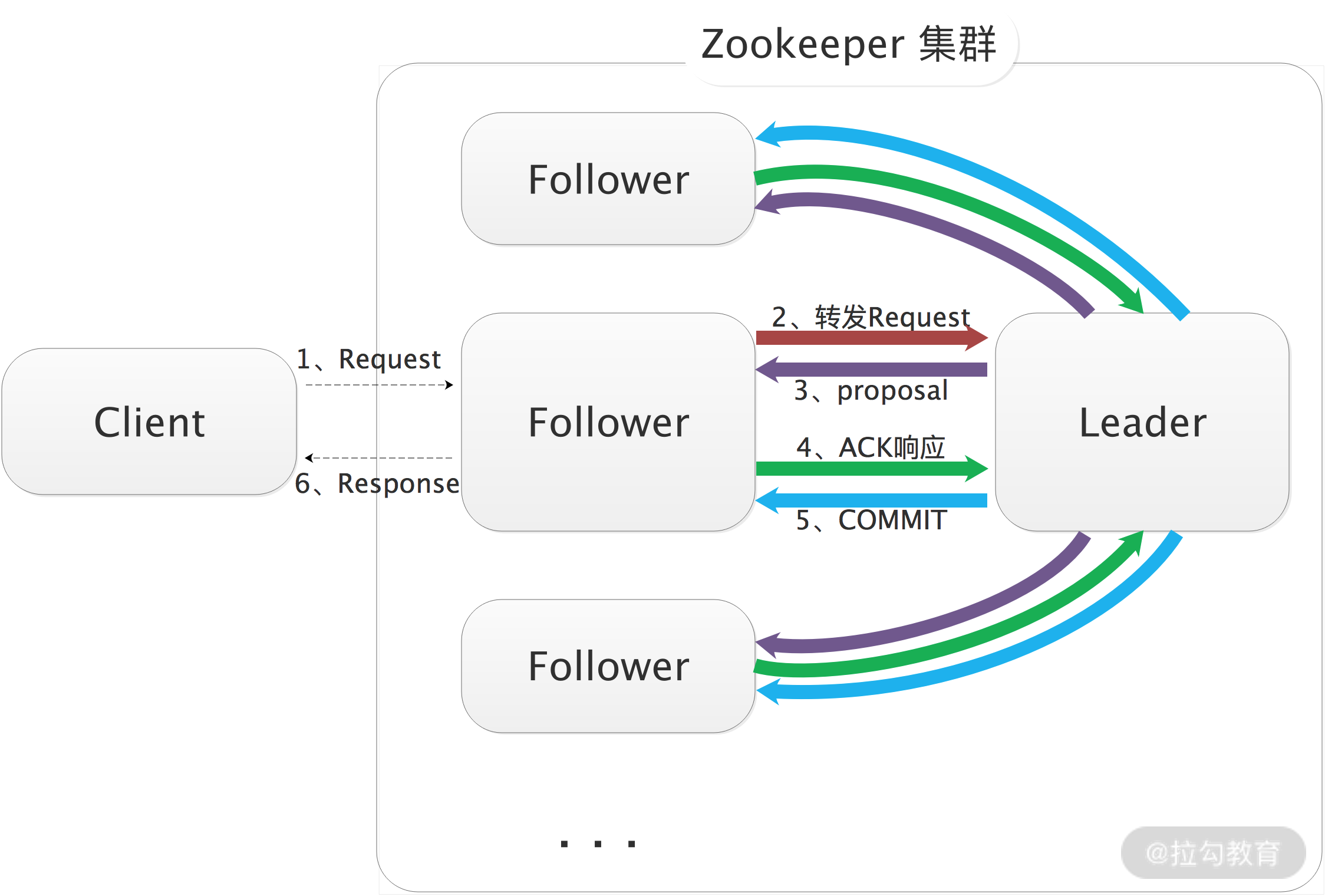
写操作核心流程图
崩溃恢复
上面写请求处理流程中,如果发生 Leader 节点宕机,整个 ZooKeeper 集群可能处于如下两种状态:
- 当 Leader 节点收到半数以上 Follower 节点的 ACK 响应之后,会向各个 Follower 节点广播 COMMIT 命令,同时也会在本地执行 COMMIT 并向连接的客户端进行响应。如果在各个 Follower 收到 COMMIT 命令前 Leader 就宕机了,就会导致剩下的服务器没法执行这条消息。
- 当 Leader 节点生成 proposal 之后就宕机了,而其他 Follower 并没有收到此 proposal(或者只有一小部分 Follower 节点收到了这条 proposal),那么此次写操作就是执行失败的。
在 Leader 宕机后,ZooKeeper 会进入崩溃恢复模式,重新进行 Leader 节点的选举。
ZooKeeper 对新 Leader 有如下两个要求:
- 对于原 Leader 已经提交了的 proposal,新 Leader 必须能够广播并提交,这样就需要选择拥有最大 zxid 值的节点作为 Leader。
- 对于原 Leader 还未广播或只部分广播成功的 proposal,新 Leader 能够通知原 Leader 和已经同步了的 Follower 删除,从而保证集群数据的一致性。
ZooKeeper 选主使用的是 ZAB 协议,如果展开介绍的话内容会非常多,这里我们就通过一个示例简单介绍 ZooKeeper 选主的大致流程。
比如,当前集群中有 5 个 ZooKeeper 节点构成,sid 分别为 1、2、3、4 和 5,zxid 分别为 10、10、9、9 和 8,此时,sid 为 1 的节点是 Leader 节点。实际上,zxid 包含了 epoch(高 32 位)和自增计数器(低 32 位) 两部分。其中,epoch 是“纪元”的意思,标识当前 Leader 周期,每次选举时 epoch 部分都会递增,这就防止了网络隔离之后,上一周期的旧 Leader 重新连入集群造成不必要的重新选举。该示例中我们假设各个节点的 epoch 都相同。
某一时刻,节点 1 的服务器宕机了,ZooKeeper 集群开始进行选主。由于无法检测到集群中其他节点的状态信息(处于 Looking 状态),因此每个节点都将自己作为被选举的对象来进行投票。于是 sid 为 2、3、4、5 的节点,投票情况分别为(2,10)、(3,9)、(4,9)、(5,8),同时各个节点也会接收到来自其他节点的投票(这里以(sid, zxid)的形式来标识一次投票信息)。
- 对于节点 2 来说,接收到(3,9)、(4,9)、(5,8)的投票,对比后发现自己的 zxid 最大,因此不需要做任何投票变更。
- 对于节点 3 来说,接收到(2,10)、(4,9)、(5,8)的投票,对比后由于 2 的 zxid 比自己的 zxid 要大,因此需要更改投票,改投(2,10),并将改投后的票发给其他节点。
- 对于节点 4 来说,接收到(2,10)、(3,9)、(5,8)的投票,对比后由于 2 的 zxid 比自己的 zxid 要大,因此需要更改投票,改投(2,10),并将改投后的票发给其他节点。
- 对于节点 5 来说,也是一样,最终改投(2,10)。
经过第二轮投票后,集群中的每个节点都会再次收到其他机器的投票,然后开始统计投票,如果有过半的节点投了同一个节点,则该节点成为新的 Leader,这里显然节点 2 成了新 Leader节点。
Leader 节点此时会将 epoch 值加 1,并将新生成的 epoch 分发给各个 Follower 节点。各个 Follower 节点收到全新的 epoch 后,返回 ACK 给 Leader 节点,并带上各自最大的 zxid 和历史事务日志信息。Leader 选出最大的 zxid,并更新自身历史事务日志,示例中的节点 2 无须更新。Leader 节点紧接着会将最新的事务日志同步给集群中所有的 Follower 节点,只有当半数 Follower 同步成功,这个准 Leader 节点才能成为正式的 Leader 节点并开始工作。
总结
本课时我们重点介绍了 ZooKeeper 的核心概念以及 ZooKeeper 集群的基本工作原理:
- 首先介绍了 ZooKeeper 集群中各个节点的角色以及职能;
- 然后介绍了 ZooKeeper 中存储数据的逻辑结构以及 ZNode 节点的相关特性;
- 紧接着又讲解了 ZooKeeper 集群读写数据的核心流程;
- 最后我们通过示例分析了 ZooKeeper 集群的崩溃恢复流程。
在下一课时,我们将介绍 Apache Curator 的相关内容。
07 ZooKeeper与Curator,求你别用ZkClient了(下)
在上一课时我们介绍了 ZooKeeper 的核心概念以及工作原理,这里我们再简单了解一下 ZooKeeper 客户端的相关内容,毕竟在实际工作中,直接使用客户端与 ZooKeeper 进行交互的次数比深入 ZooKeeper 底层进行扩展和二次开发的次数要多得多。从 ZooKeeper 架构的角度看,使用 Dubbo 的业务节点也只是一个 ZooKeeper 客户端罢了。
ZooKeeper 官方提供的客户端支持了一些基本操作,例如,创建会话、创建节点、读取节点、更新数据、删除节点和检查节点是否存在等,但在实际开发中只有这些简单功能是根本不够的。而且,ZooKeeper 本身的一些 API 也存在不足,例如:
- ZooKeeper 的 Watcher 是一次性的,每次触发之后都需要重新进行注册。
- 会话超时之后,没有实现自动重连的机制。
- ZooKeeper 提供了非常详细的异常,异常处理显得非常烦琐,对开发新手来说,非常不友好。
- 只提供了简单的 byte[] 数组的接口,没有提供基本类型以及对象级别的序列化。
- 创建节点时,如果节点存在抛出异常,需要自行检查节点是否存在。
- 删除节点就无法实现级联删除。
常见的第三方开源 ZooKeeper 客户端有 ZkClient 和 Apache Curator。
ZkClient 是在 ZooKeeper 原生 API 接口的基础上进行了包装,虽然 ZkClient 解决了 ZooKeeper 原生 API 接口的很多问题,提供了非常简洁的 API 接口,实现了会话超时自动重连的机制,解决了 Watcher 反复注册等问题,但其缺陷也非常明显。例如,文档不全、重试机制难用、异常全部转换成了 RuntimeException、没有足够的参考示例等。可见,一个简单易用、高效可靠的 ZooKeeper 客户端是多么重要。
Apache Curator 基础
Apache Curator 是 Apache 基金会提供的一款 ZooKeeper 客户端,它提供了一套易用性和可读性非常强的 Fluent 风格的客户端 API ,可以帮助我们快速搭建稳定可靠的 ZooKeeper 客户端程序。
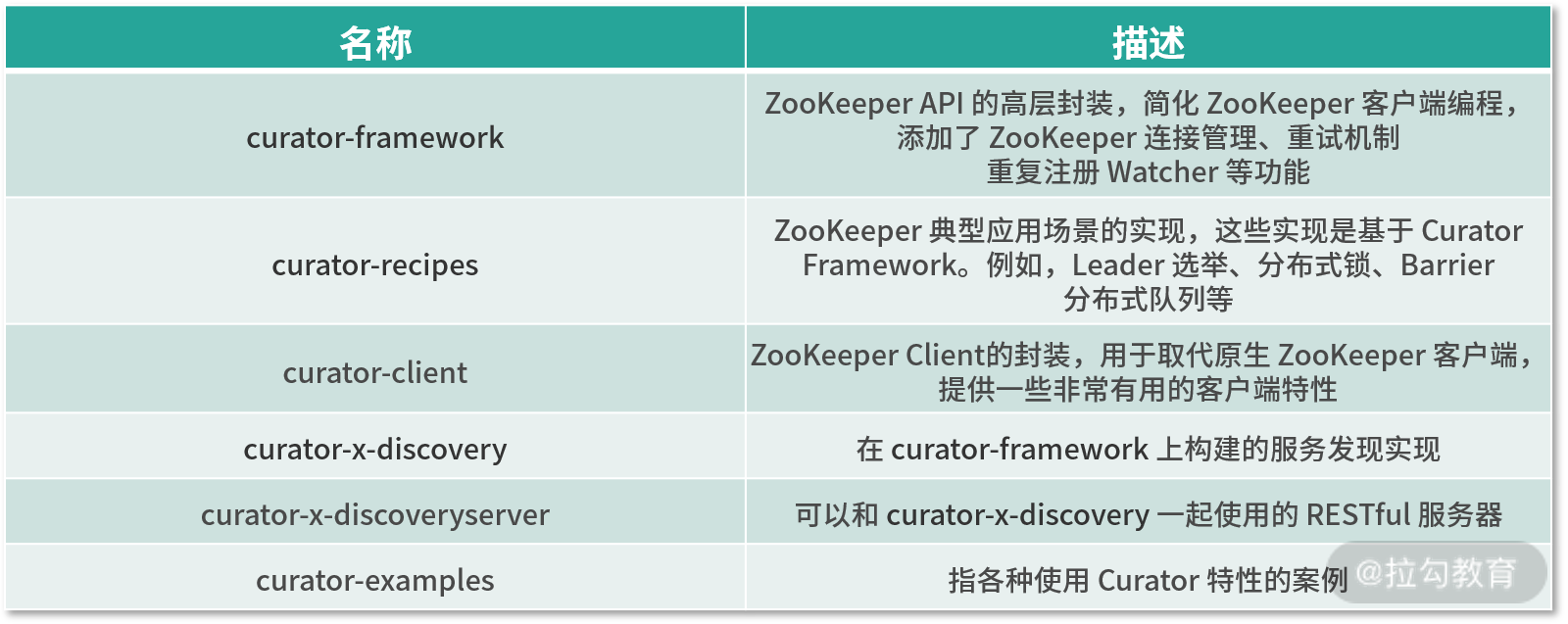
为便于你更全面了解 Curator 的功能,我整理出了如下表格,展示了 Curator 提供的 jar 包:
下面我们从最基础的使用展开,逐一介绍 Apache Curator 在实践中常用的核心功能,开始我们的 Apache Curator 之旅。
1. 基本操作
简单了解了 Apache Curator 各个组件的定位之后,下面我们立刻通过一个示例上手使用 Curator。首先,我们创建一个 Maven 项目,并添加 Apache Curator 的依赖:
<dependency> <groupId>org.apache.curator</groupId> <artifactId>curator-recipes</artifactId> <version>4.0.1</version>
</dependency>
然后写一个 main 方法,其中会说明 Curator 提供的基础 API 的使用:
public class Main { public static void main(String[] args) throws Exception { // Zookeeper集群地址,多个节点地址可以用逗号分隔 String zkAddress = "127.0.0.1:2181"; // 重试策略,如果连接不上ZooKeeper集群,会重试三次,重试间隔会递增 RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 3); // 创建Curator Client并启动,启动成功之后,就可以与Zookeeper进行交互了 CuratorFramework client = CuratorFrameworkFactory.newClient(zkAddress, retryPolicy); client.start(); // 下面简单说明Curator中常用的API // create()方法创建ZNode,可以调用额外方法来设置节点类型、添加Watcher // 下面是创建一个名为"user"的持久节点,其中会存储一个test字符串 String path = client.create().withMode(CreateMode.PERSISTENT) .forPath("/user", "test".getBytes()); System.out.println(path); // 输出:/user // checkExists()方法可以检查一个节点是否存在 Stat stat = client.checkExists().forPath("/user"); System.out.println(stat!=null); // 输出:true,返回的Stat不为null,即表示节点存在 // getData()方法可以获取一个节点中的数据 byte[] data = client.getData().forPath("/user"); System.out.println(new String(data)); // 输出:test // setData()方法可以设置一个节点中的数据 stat = client.setData().forPath("/user","data".getBytes()); data = client.getData().forPath("/user"); System.out.println(new String(data)); // 输出:data // 在/user节点下,创建多个临时顺序节点 for (int i = 0; i < 3; i++) { client.create().withMode(CreateMode.EPHEMERAL_SEQUENTIAL) .forPath("/user/child-"; } // 获取所有子节点 List<String> children = client.getChildren().forPath("/user"); System.out.println(children); // 输出:[child-0000000002, child-0000000001, child-0000000000] // delete()方法可以删除指定节点,deletingChildrenIfNeeded()方法 // 会级联删除子节点 client.delete().deletingChildrenIfNeeded().forPath("/user"); }
}
2. Background
上面介绍的创建、删除、更新、读取等方法都是同步的,Curator 提供异步接口,引入了BackgroundCallback 这个回调接口以及 CuratorListener 这个监听器,用于处理 Background 调用之后服务端返回的结果信息。BackgroundCallback 接口和 CuratorListener 监听器中接收一个 CuratorEvent 的参数,里面包含事件类型、响应码、节点路径等详细信息。
下面我们通过一个示例说明 BackgroundCallback 接口以及 CuratorListener 监听器的基本使用:
public class Main2 { public static void main(String[] args) throws Exception { // Zookeeper集群地址,多个节点地址可以用逗号分隔 String zkAddress = "127.0.0.1:2181"; // 重试策略,如果连接不上ZooKeeper集群,会重试三次,重试间隔会递增 RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000,3); // 创建Curator Client并启动,启动成功之后,就可以与Zookeeper进行交互了 CuratorFramework client = CuratorFrameworkFactory .newClient(zkAddress, retryPolicy); client.start(); // 添加CuratorListener监听器,针对不同的事件进行处理 client.getCuratorListenable().addListener( new CuratorListener() { public void eventReceived(CuratorFramework client,CuratorEvent event) throws Exception { switch (event.getType()) { case CREATE: System.out.println("CREATE:" + event.getPath()); break;case DELETE: System.out.println("DELETE:" + event.getPath()); break; case EXISTS: System.out.println("EXISTS:" + event.getPath()); break; case GET_DATA: System.out.println("GET_DATA:" + event.getPath() + ","+ new String(event.getData())); break; case SET_DATA: System.out.println("SET_DATA:" + new String(event.getData())); break; case CHILDREN: System.out.println("CHILDREN:" + event.getPath()); break; default: } } }); // 注意:下面所有的操作都添加了inBackground()方法,转换为后台操作 client.create().withMode(CreateMode.PERSISTENT) .inBackground().forPath("/user", "test".getBytes()); client.checkExists().inBackground().forPath("/user"); client.setData().inBackground().forPath("/user", "setData-Test".getBytes()); client.getData().inBackground().forPath("/user"); for (int i = 0; i < 3; i++) { client.create().withMode(CreateMode.EPHEMERAL_SEQUENTIAL) .inBackground().forPath("/user/child-"); } client.getChildren().inBackground().forPath("/user");// 添加BackgroundCallback client.getChildren().inBackground(new BackgroundCallback() { public void processResult(CuratorFramework client,CuratorEvent event) throws Exception { System.out.println("in background:" + event.getType() + "," + event.getPath()); } }).forPath("/user"); client.delete().deletingChildrenIfNeeded().inBackground() .forPath("/user"); System.in.read(); }
} // 输出:
// CREATE:/user
// EXISTS:/user
// GET_DATA:/user,setData-Test
// CREATE:/user/child-
// CREATE:/user/child-
// CREATE:/user/child-
// CHILDREN:/user
// DELETE:/user
3. 连接状态监听
除了基础的数据操作,Curator 还提供了监听连接状态的监听器——ConnectionStateListener,它主要是处理 Curator 客户端和 ZooKeeper 服务器间连接的异常情况,例如, 短暂或者长时间断开连接。
短暂断开连接时,ZooKeeper 客户端会检测到与服务端的连接已经断开,但是服务端维护的客户端 Session 尚未过期,之后客户端和服务端重新建立了连接;当客户端重新连接后,由于 Session 没有过期,ZooKeeper 能够保证连接恢复后保持正常服务。
而长时间断开连接时,Session 已过期,与先前 Session 相关的 Watcher 和临时节点都会丢失。当 Curator 重新创建了与 ZooKeeper 的连接时,会获取到 Session 过期的相关异常,Curator 会销毁老 Session,并且创建一个新的 Session。由于老 Session 关联的数据不存在了,在 ConnectionStateListener 监听到 LOST 事件时,就可以依靠本地存储的数据恢复 Session 了。
这里 Session 指的是 ZooKeeper 服务器与客户端的会话。客户端启动的时候会与服务器建立一个 TCP 连接,从第一次连接建立开始,客户端会话的生命周期也开始了。客户端能够通过心跳检测与服务器保持有效的会话,也能够向 ZooKeeper 服务器发送请求并接受响应,同时还能够通过该连接接收来自服务器的 Watch 事件通知。
我们可以设置客户端会话的超时时间(sessionTimeout),当服务器压力太大、网络故障或是客户端主动断开连接等原因导致连接断开时,只要客户端在 sessionTimeout 规定的时间内能够重新连接到 ZooKeeper 集群中任意一个实例,那么之前创建的会话仍然有效。ZooKeeper 通过 sessionID 唯一标识 Session,所以在 ZooKeeper 集群中,sessionID 需要保证全局唯一。 由于 ZooKeeper 会将 Session 信息存放到硬盘中,即使节点重启,之前未过期的 Session 仍然会存在。
public class Main3 { public static void main(String[] args) throws Exception { // Zookeeper集群地址,多个节点地址可以用逗号分隔 String zkAddress = "127.0.0.1:2181"; // 重试策略,如果连接不上ZooKeeper集群,会重试三次,重试间隔会递增 RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000,3); // 创建Curator Client并启动,启动成功之后,就可以与Zookeeper进行交互了 CuratorFramework client = CuratorFrameworkFactory .newClient(zkAddress, retryPolicy); client.start(); // 添加ConnectionStateListener监听器 client.getConnectionStateListenable().addListener( new ConnectionStateListener() { public void stateChanged(CuratorFramework client, ConnectionState newState) { // 这里我们可以针对不同的连接状态进行特殊的处理 switch (newState) {case CONNECTED: // 第一次成功连接到ZooKeeper之后会进入该状态。 // 对于每个CuratorFramework对象,此状态仅出现一次 break; case SUSPENDED: // ZooKeeper的连接丢失 break; case RECONNECTED: // 丢失的连接被重新建立 break; case LOST:// 当Curator认为会话已经过期时,则进入此状态 break; case READ_ONLY: // 连接进入只读模式 break; } } }); }
}
4. Watcher
Watcher 监听机制是 ZooKeeper 中非常重要的特性,可以监听某个节点上发生的特定事件,例如,监听节点数据变更、节点删除、子节点状态变更等事件。当相应事件发生时,ZooKeeper 会产生一个 Watcher 事件,并且发送到客户端。通过 Watcher 机制,就可以使用 ZooKeeper 实现分布式锁、集群管理等功能。
在 Curator 客户端中,我们可以使用 usingWatcher() 方法添加 Watcher,前面示例中,能够添加 Watcher 的有 checkExists()、getData()以及 getChildren() 三个方法,下面我们来看一个具体的示例:
public class Main4 { public static void main(String[] args) throws Exception { // Zookeeper集群地址,多个节点地址可以用逗号分隔 String zkAddress = "127.0.0.1:2181"; // 重试策略,如果连接不上ZooKeeper集群,会重试三次,重试间隔会递增 RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000,3); // 创建Curator Client并启动,启动成功之后,就可以与Zookeeper进行交互了 CuratorFramework client = CuratorFrameworkFactory .newClient(zkAddress, retryPolicy); client.start(); try { client.create().withMode(CreateMode.PERSISTENT) .forPath("/user", "test".getBytes()); } catch (Exception e) { } // 这里通过usingWatcher()方法添加一个Watcher List<String> children = client.getChildren().usingWatcher( new CuratorWatcher() { public void process(WatchedEvent event) throws Exception { System.out.println(event.getType() + "," +event.getPath()); } }).forPath("/user"); System.out.println(children); System.in.read(); }
}
接下来,我们打开 ZooKeeper 的命令行客户端,在 /user 节点下先后添加两个子节点,如下所示:
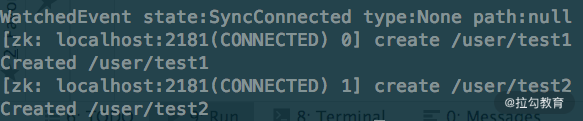
此时我们只得到一行输出:
NodeChildrenChanged,/user
之所以这样,是因为通过 usingWatcher() 方法添加的 CuratorWatcher 只会触发一次,触发完毕后就会销毁。checkExists() 方法、getData() 方法通过 usingWatcher() 方法添加的 Watcher 也是一样的原理,只不过监听的事件不同,你若感兴趣的话,可以自行尝试一下。
相信你已经感受到,直接通过注册 Watcher 进行事件监听不是特别方便,需要我们自己反复注册 Watcher。Apache Curator 引入了 Cache 来实现对 ZooKeeper 服务端事件的监听。Cache 是 Curator 中对事件监听的包装,其对事件的监听其实可以近似看作是一个本地缓存视图和远程ZooKeeper 视图的对比过程。同时,Curator 能够自动为开发人员处理反复注册监听,从而大大简化了代码的复杂程度。
实践中常用的 Cache 有三大类:
- NodeCache。 对一个节点进行监听,监听事件包括指定节点的增删改操作。注意哦,NodeCache 不仅可以监听数据节点的内容变更,也能监听指定节点是否存在,如果原本节点不存在,那么 Cache 就会在节点被创建后触发 NodeCacheListener,删除操作亦然。
- PathChildrenCache。 对指定节点的一级子节点进行监听,监听事件包括子节点的增删改操作,但是不对该节点的操作监听。
- TreeCache。 综合 NodeCache 和 PathChildrenCache 的功能,是对指定节点以及其子节点进行监听,同时还可以设置监听的深度。
下面通过示例介绍上述三种 Cache 的基本使用:
public class Main5 { public static void main(String[] args) throws Exception { // Zookeeper集群地址,多个节点地址可以用逗号分隔 String zkAddress = "127.0.0.1:2181"; // 重试策略,如果连接不上ZooKeeper集群,会重试三次,重试间隔会递增 RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000,3); // 创建Curator Client并启动,启动成功之后,就可以与Zookeeper进行交互了 CuratorFramework client = CuratorFrameworkFactory .newClient(zkAddress, retryPolicy); client.start(); // 创建NodeCache,监听的是"/user"这个节点 NodeCache nodeCache = new NodeCache(client, "/user"); // start()方法有个boolean类型的参数,默认是false。如果设置为true, // 那么NodeCache在第一次启动的时候就会立刻从ZooKeeper上读取对应节点的 // 数据内容,并保存在Cache中。 nodeCache.start(true); if (nodeCache.getCurrentData() != null) { System.out.println("NodeCache节点初始化数据为:"+ new String(nodeCache.getCurrentData().getData())); } else { System.out.println("NodeCache节点数据为空"); } // 添加监听器 nodeCache.getListenable().addListener(() -> { String data = new String(nodeCache.getCurrentData().getData()); System.out.println("NodeCache节点路径:" + nodeCache.getCurrentData().getPath() + ",节点数据为:" + data); }); // 创建PathChildrenCache实例,监听的是"user"这个节点 PathChildrenCache childrenCache = new PathChildrenCache(client, "/user", true); // StartMode指定的初始化的模式 // NORMAL:普通异步初始化 // BUILD_INITIAL_CACHE:同步初始化 // POST_INITIALIZED_EVENT:异步初始化,初始化之后会触发事件 childrenCache.start(PathChildrenCache.StartMode.BUILD_INITIAL_CACHE); // childrenCache.start(PathChildrenCache.StartMode.POST_INITIALIZED_EVENT); // childrenCache.start(PathChildrenCache.StartMode.NORMAL); List<ChildData> children = childrenCache.getCurrentData(); System.out.println("获取子节点列表:"); // 如果是BUILD_INITIAL_CACHE可以获取这个数据,如果不是就不行 children.forEach(childData -> { System.out.println(new String(childData.getData())); }); childrenCache.getListenable().addListener(((client1, event) -> { System.out.println(LocalDateTime.now() + " " + event.getType()); if (event.getType().equals(PathChildrenCacheEvent.Type.INITIALIZED)) { System.out.println("PathChildrenCache:子节点初始化成功..."); } else if (event.getType().equals(PathChildrenCacheEvent.Type.CHILD_ADDED)) { String path = event.getData().getPath(); System.out.println("PathChildrenCache添加子节点:" + event.getData().getPath()); System.out.println("PathChildrenCache子节点数据:" + new String(event.getData().getData())); } else if (event.getType().equals(PathChildrenCacheEvent.Type.CHILD_REMOVED)) { System.out.println("PathChildrenCache删除子节点:" + event.getData().getPath()); } else if (event.getType().equals(PathChildrenCacheEvent.Type.CHILD_UPDATED)) { System.out.println("PathChildrenCache修改子节点路径:" + event.getData().getPath()); System.out.println("PathChildrenCache修改子节点数据:" + new String(event.getData().getData())); } })); // 创建TreeCache实例监听"user"节点 TreeCache cache = TreeCache.newBuilder(client, "/user").setCacheData(false).build(); cache.getListenable().addListener((c, event) -> { if (event.getData() != null) { System.out.println("TreeCache,type=" + event.getType() + " path=" + event.getData().getPath()); } else { System.out.println("TreeCache,type=" + event.getType()); } }); cache.start(); System.in.read(); }
}
此时,ZooKeeper 集群中存在 /user/test1 和 /user/test2 两个节点,启动上述测试代码,得到的输出如下:
NodeCache节点初始化数据为:test //NodeCache的相关输出
获取子节点列表:// PathChildrenCache的相关输出 xxx
xxx2 // TreeCache监听到的事件
TreeCache,type=NODE_ADDED path=/user
TreeCache,type=NODE_ADDED path=/user/test1
TreeCache,type=NODE_ADDED path=/user/test2
TreeCache,type=INITIALIZED
接下来,我们在 ZooKeeper 命令行客户端中更新 /user 节点中的数据:

得到如下输出:
TreeCache,type=NODE_UPDATED path=/user
NodeCache节点路径:/user,节点数据为:userData
创建 /user/test3 节点:

得到输出:
TreeCache,type=NODE_ADDED path=/user/test3
2020-06-26T08:35:22.393 CHILD_ADDED
PathChildrenCache添加子节点:/user/test3
PathChildrenCache子节点数据:xxx3
更新 /user/test3 节点的数据:

得到输出:
TreeCache,type=NODE_UPDATED path=/user/test3
2020-06-26T08:43:54.604 CHILD_UPDATED
PathChildrenCache修改子节点路径:/user/test3
PathChildrenCache修改子节点数据:xxx33
删除 /user/test3 节点:

得到输出:
TreeCache,type=NODE_REMOVED path=/user/test3
2020-06-26T08:44:06.329 CHILD_REMOVED
PathChildrenCache删除子节点:/user/test3
curator-x-discovery 扩展库
为了避免 curator-framework 包过于膨胀,Curator 将很多其他解决方案都拆出来了,作为单独的一个包,例如:curator-recipes、curator-x-discovery、curator-x-rpc 等。
在后面我们会使用到 curator-x-discovery 来完成一个简易 RPC 框架的注册中心模块。curator-x-discovery 扩展包是一个服务发现的解决方案。在 ZooKeeper 中,我们可以使用临时节点实现一个服务注册机制。当服务启动后在 ZooKeeper 的指定 Path 下创建临时节点,服务断掉与 ZooKeeper 的会话之后,其相应的临时节点就会被删除。这个 curator-x-discovery 扩展包抽象了这种功能,并提供了一套简单的 API 来实现服务发现机制。curator-x-discovery 扩展包的核心概念如下:
- ServiceInstance。 这是 curator-x-discovery 扩展包对服务实例的抽象,由 name、id、address、port 以及一个可选的 payload 属性构成。其存储在 ZooKeeper 中的方式如下图展示的这样。

- ServiceProvider。 这是 curator-x-discovery 扩展包的核心组件之一,提供了多种不同策略的服务发现方式,具体策略有轮询调度、随机和黏性(总是选择相同的一个)。得到 ServiceProvider 对象之后,我们可以调用其 getInstance() 方法,按照指定策略获取 ServiceInstance 对象(即发现可用服务实例);还可以调用 getAllInstances() 方法,获取所有 ServiceInstance 对象(即获取全部可用服务实例)。
- ServiceDiscovery。 这是 curator-x-discovery 扩展包的入口类。开始必须调用 start() 方法,当使用完成应该调用 close() 方法进行销毁。
- ServiceCache。 如果程序中会频繁地查询 ServiceInstance 对象,我们可以添加 ServiceCache 缓存,ServiceCache 会在内存中缓存 ServiceInstance 实例的列表,并且添加相应的 Watcher 来同步更新缓存。查询 ServiceCache 的方式也是 getInstances() 方法。另外,ServiceCache 上还可以添加 Listener 来监听缓存变化。
下面通过一个简单示例来说明一下 curator-x-discovery 包的使用,该示例中的 ServerInfo 记录了一个服务的 host、port 以及描述信息。
public class ZookeeperCoordinator { private ServiceDiscovery<ServerInfo> serviceDiscovery; private ServiceCache<ServerInfo> serviceCache; private CuratorFramework client; private String root; // 这里的JsonInstanceSerializer是将ServerInfo序列化成Json private InstanceSerializer serializer =new JsonInstanceSerializer<>(ServerInfo.class); ZookeeperCoordinator(Config config) throws Exception { this.root = config.getPath(); // 创建Curator客户端 client = CuratorFrameworkFactory.newClient( config.getHostPort(), new ExponentialBackoffRetry(...)); client.start(); // 启动Curator客户端client.blockUntilConnected(); // 阻塞当前线程,等待连接成功 // 创建ServiceDiscovery serviceDiscovery = ServiceDiscoveryBuilder .builder(ServerInfo.class) .client(client) // 依赖Curator客户端 .basePath(root) // 管理的Zk路径 .watchInstances(true) // 当ServiceInstance加载 .serializer(serializer) .build(); serviceDiscovery.start(); // 启动ServiceDiscovery // 创建ServiceCache,监Zookeeper相应节点的变化,也方便后续的读取 serviceCache = serviceDiscovery.serviceCacheBuilder() .name(root) .build();serviceCache.start(); // 启动ServiceCache } public void registerRemote(ServerInfo serverInfo)throws Exception{ // 将ServerInfo对象转换成ServiceInstance对象 ServiceInstance<ServerInfo> thisInstance =ServiceInstance.<ServerInfo>builder() .name(root) .id(UUID.randomUUID().toString()) // 随机生成的UUID .address(serverInfo.getHost()) // host .port(serverInfo.getPort()) // port .payload(serverInfo) // payload .build(); // 将ServiceInstance写入到Zookeeper中 serviceDiscovery.registerService(thisInstance); } public List<ServerInfo> queryRemoteNodes() { List<ServerInfo> ServerInfoDetails = new ArrayList<>(); // 查询 ServiceCache 获取全部的 ServiceInstance 对象 List<ServiceInstance<ServerInfo>> serviceInstances =serviceCache.getInstances(); serviceInstances.forEach(serviceInstance -> { // 从每个ServiceInstance对象的playload字段中反序列化得 // 到ServerInfo实例 ServerInfo instance = serviceInstance.getPayload(); ServerInfoDetails.add(instance); }); return ServerInfoDetails; }
}
curator-recipes 简介
Recipes 是 Curator 对常见分布式场景的解决方案,这里我们只是简单介绍一下,具体的使用和原理,就先不做深入分析了。
- Queues。提供了多种的分布式队列解决方法,比如:权重队列、延迟队列等。在生产环境中,很少将 ZooKeeper 用作分布式队列,只适合在压力非常小的情况下,才使用该解决方案,所以建议你要适度使用。
- Counters。全局计数器是分布式系统中很常用的工具,curator-recipes 提供了 SharedCount、DistributedAtomicLong 等组件,帮助开发人员实现分布式计数器功能。
- Locks。java.util.concurrent.locks 中提供的各种锁相信你已经有所了解了,在微服务架构中,分布式锁也是一项非常基础的服务组件,curator-recipes 提供了多种基于 ZooKeeper 实现的分布式锁,满足日常工作中对分布式锁的需求。
- Barries。curator-recipes 提供的分布式栅栏可以实现多个服务之间协同工作,具体实现有 DistributedBarrier 和 DistributedDoubleBarrier。
- Elections。实现的主要功能是在多个参与者中选举出 Leader,然后由 Leader 节点作为操作调度、任务监控或是队列消费的执行者。curator-recipes 给出的实现是 LeaderLatch。
总结
本课时我们重点介绍了 Apache Curator 相关的内容:
- 首先将 Apache Curator 与其他 ZooKeeper 客户端进行了对比,Apache Curator 的易用性是选择 Apache Curator 的重要原因。
- 接下来,我们通过示例介绍了 Apache Curator 的基本使用方式以及实际使用过程中的一些注意点。
- 然后,介绍了 curator-x-discovery 扩展库的基本概念和使用。
- 最后,简单介绍了 curator-recipes 提供的强大功能。
关于 Apache Curator,你有什么其他的见解?
zk-demo 链接:https://github.com/xxxlxy2008/zk-demo 。
08 代理模式与常见实现
动态代理机制在 Java 中有着广泛的应用,例如,Spring AOP、MyBatis、Hibernate 等常用的开源框架,都使用到了动态代理机制。当然,Dubbo 中也使用到了动态代理,在后面开发简易版 RPC 框架的时候,我们还会参考 Dubbo 使用动态代理机制来屏蔽底层的网络传输以及服务发现的相关实现。
本课时我们主要从基础知识开始讲起,首先介绍代理模式的基本概念,之后重点介绍 JDK 动态代理的使用以及底层实现原理,同时还会说明 JDK 动态代理的一些局限性,最后再介绍基于字节码生成的动态代理。
代理模式
代理模式是 23 种面向对象的设计模式中的一种,它的类图如下所示:
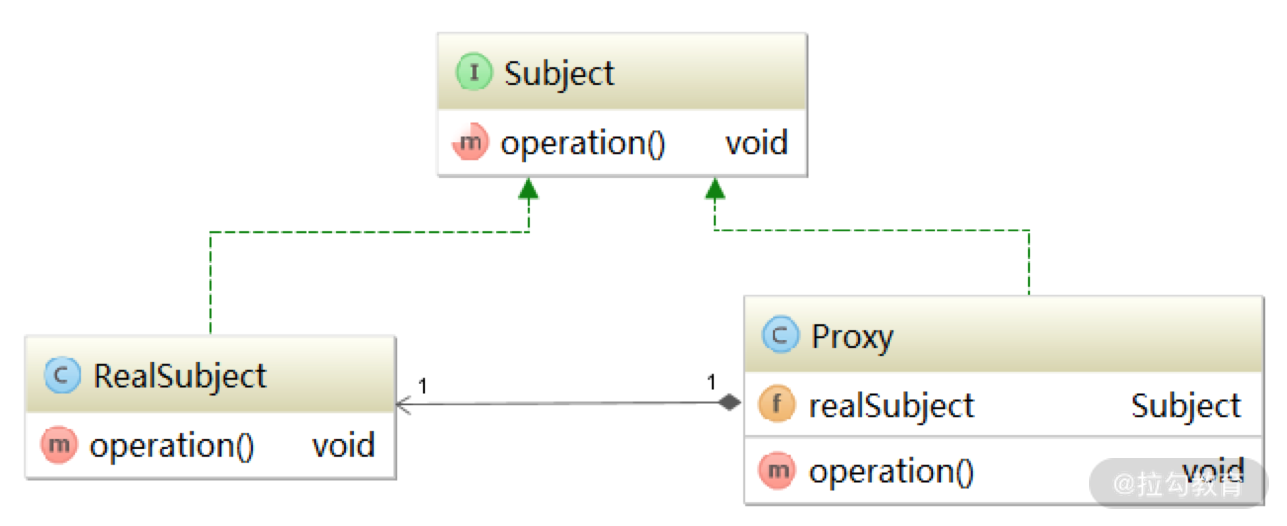
图中的 Subject 是程序中的业务逻辑接口,RealSubject 是实现了 Subject 接口的真正业务类,Proxy 是实现了 Subject 接口的代理类,封装了一个 RealSubject 引用。在程序中不会直接调用 RealSubject 对象的方法,而是使用 Proxy 对象实现相关功能。
Proxy.operation() 方法的实现会调用其中封装的 RealSubject 对象的 operation() 方法,执行真正的业务逻辑。代理的作用不仅仅是正常地完成业务逻辑,还会在业务逻辑前后添加一些代理逻辑,也就是说,Proxy.operation() 方法会在 RealSubject.operation() 方法调用前后进行一些预处理以及一些后置处理。这就是我们常说的“代理模式”。
使用代理模式可以控制程序对 RealSubject 对象的访问,如果发现异常的访问,可以直接限流或是返回,也可以在执行业务处理的前后进行相关的预处理和后置处理,帮助上层调用方屏蔽底层的细节。例如,在 RPC 框架中,代理可以完成序列化、网络 I/O 操作、负载均衡、故障恢复以及服务发现等一系列操作,而上层调用方只感知到了一次本地调用。
代理模式还可以用于实现延迟加载的功能。我们知道查询数据库是一个耗时的操作,而有些时候查询到的数据也并没有真正被程序使用。延迟加载功能就可以有效地避免这种浪费,系统访问数据库时,首先可以得到一个代理对象,此时并没有执行任何数据库查询操作,代理对象中自然也没有真正的数据;当系统真正需要使用数据时,再调用代理对象完成数据库查询并返回数据。常见 ORM 框架(例如,MyBatis、 Hibernate)中的延迟加载的原理大致也是如此。
另外,代理对象可以协调真正RealSubject 对象与调用者之间的关系,在一定程度上实现了解耦的效果。
JDK 动态代理
上面介绍的这种代理模式实现,也被称为“静态代理模式”,这是因为在编译阶段就要为每个RealSubject 类创建一个 Proxy 类,当需要代理的类很多时,就会出现大量的 Proxy 类。
这种场景下,我们可以使用 JDK 动态代理解决这个问题。JDK 动态代理的核心是InvocationHandler 接口。这里提供一个 InvocationHandler 的Demo 实现,代码如下:
public class DemoInvokerHandler implements InvocationHandler {private Object target; // 真正的业务对象,也就是RealSubject对象public DemoInvokerHandler(Object target) { // 构造方法this.target = target;}public Object invoke(Object proxy, Method method, Object[] args)throws Throwable {// ...在执行业务方法之前的预处理...Object result = method.invoke(target, args);// ...在执行业务方法之后的后置处理...return result;}public Object getProxy() {// 创建代理对象return Proxy.newProxyInstance(Thread.currentThread().getContextClassLoader(),target.getClass().getInterfaces(), this);}
}
接下来,我们可以创建一个 main() 方法来模拟上层调用者,创建并使用动态代理:
public class Main {public static void main(String[] args) {Subject subject = new RealSubject();DemoInvokerHandler invokerHandler = new DemoInvokerHandler(subject);// 获取代理对象Subject proxy = (Subject) invokerHandler.getProxy();// 调用代理对象的方法,它会调用DemoInvokerHandler.invoke()方法proxy.operation();}
}
对于需要相同代理逻辑的业务类,只需要提供一个 InvocationHandler 接口实现类即可。在 Java 运行的过程中,JDK会为每个 RealSubject 类动态生成相应的代理类并加载到 JVM 中,然后创建对应的代理实例对象,返回给上层调用者。
了解了 JDK 动态代理的基本使用之后,下面我们就来分析 JDK动态代理创建代理类的底层实现原理。不同JDK版本的 Proxy 类实现可能有细微差别,但核心思路不变,这里使用 1.8.0 版本的 JDK。
JDK 动态代理相关实现的入口是 Proxy.newProxyInstance() 这个静态方法,它的三个参数分别是加载动态生成的代理类的类加载器、业务类实现的接口和上面介绍的InvocationHandler对象。Proxy.newProxyInstance()方法的具体实现如下:
public static Object newProxyInstance(ClassLoader loader,Class[] interfaces, InvocationHandler h) throws IllegalArgumentException {final Class<?>[] intfs = interfaces.clone();// ...省略权限检查等代码Class<?> cl = getProxyClass0(loader, intfs); // 获取代理类// ...省略try/catch代码块和相关异常处理// 获取代理类的构造方法final Constructor<?> cons = cl.getConstructor(constructorParams);final InvocationHandler ih = h;return cons.newInstance(new Object[]{h}); // 创建代理对象
}
通过 newProxyInstance()方法的实现可以看到,JDK 动态代理是在 getProxyClass0() 方法中完成代理类的生成和加载。getProxyClass0() 方法的具体实现如下:
private static Class getProxyClass0 (ClassLoader loader, Class... interfaces) {// 边界检查,限制接口数量(略)// 如果指定的类加载器中已经创建了实现指定接口的代理类,则查找缓存;// 否则通过ProxyClassFactory创建实现指定接口的代理类return proxyClassCache.get(loader, interfaces);
}
proxyClassCache 是定义在 Proxy 类中的静态字段,主要用于缓存已经创建过的代理类,定义如下:
private static final WeakCache[], Class> proxyClassCache= new WeakCache<>(new KeyFactory(), new ProxyClassFactory());
WeakCache.get() 方法会首先尝试从缓存中查找代理类,如果查找不到,则会创建 Factory 对象并调用其 get() 方法获取代理类。Factory 是 WeakCache 中的内部类,Factory.get() 方法会调用 ProxyClassFactory.apply() 方法创建并加载代理类。
ProxyClassFactory.apply() 方法首先会检测代理类需要实现的接口集合,然后确定代理类的名称,之后创建代理类并将其写入文件中,最后加载代理类,返回对应的 Class 对象用于后续的实例化代理类对象。该方法的具体实现如下:
public Class apply(ClassLoader loader, Class[] interfaces) {// ... 对interfaces集合进行一系列检测(略)// ... 选择定义代理类的包名(略)// 代理类的名称是通过包名、代理类名称前缀以及编号这三项组成的long num = nextUniqueNumber.getAndIncrement();String proxyName = proxyPkg + proxyClassNamePrefix + num;// 生成代理类,并写入文件byte[] proxyClassFile = ProxyGenerator.generateProxyClass(proxyName, interfaces, accessFlags);// 加载代理类,并返回Class对象return defineClass0(loader, proxyName, proxyClassFile, 0, proxyClassFile.length);
}
ProxyGenerator.generateProxyClass() 方法会按照指定的名称和接口集合生成代理类的字节码,并根据条件决定是否保存到磁盘上。该方法的具体代码如下:
public static byte[] generateProxyClass(final String name,Class[] interfaces) {ProxyGenerator gen = new ProxyGenerator(name, interfaces);// 动态生成代理类的字节码,具体生成过程不再详细介绍,感兴趣的读者可以继续分析final byte[] classFile = gen.generateClassFile();// 如果saveGeneratedFiles值为true,会将生成的代理类的字节码保存到文件中if (saveGeneratedFiles) { java.security.AccessController.doPrivileged(new java.security.PrivilegedAction() {public Void run() {// 省略try/catch代码块FileOutputStream file = new FileOutputStream(dotToSlash(name) + ".class");file.write(classFile);file.close();return null;}});}return classFile; // 返回上面生成的代理类的字节码
}
最后,为了清晰地看到JDK动态生成的代理类的真正定义,我们需要将上述生成的代理类的字节码进行反编译。上述示例为RealSubject生成的代理类,反编译后得到的代码如下:
public final class $Proxy37 extends Proxy implements Subject { // 实现了Subject接口// 这里省略了从Object类继承下来的相关方法和属性private static Method m3;static {// 省略了try/catch代码块// 记录了operation()方法对应的Method对象m3 = Class.forName("com.xxx.Subject").getMethod("operation", new Class[0]);}// 构造方法的参数就是我们在示例中使用的DemoInvokerHandler对象public $Proxy11(InvocationHandler var1) throws {super(var1); }public final void operation() throws {// 省略了try/catch代码块// 调用DemoInvokerHandler对象的invoke()方法// 最终调用RealSubject对象的对应方法super.h.invoke(this, m3, (Object[]) null);}
}
至此JDK 动态代理的基本使用以及核心原理就介绍完了。简单总结一下,JDK 动态代理的实现原理是动态创建代理类并通过指定类加载器进行加载,在创建代理对象时将InvocationHandler对象作为构造参数传入。当调用代理对象时,会调用 InvocationHandler.invoke() 方法,从而执行代理逻辑,并最终调用真正业务对象的相应方法。
CGLib
JDK 动态代理是 Java 原生支持的,不需要任何外部依赖,但是正如上面分析的那样,它只能基于接口进行代理,对于没有继承任何接口的类,JDK 动态代理就没有用武之地了。
如果想对没有实现任何接口的类进行代理,可以考虑使用 CGLib。
CGLib(Code Generation Library)是一个基于 ASM 的字节码生成库,它允许我们在运行时对字节码进行修改和动态生成。CGLib 采用字节码技术实现动态代理功能,其底层原理是通过字节码技术为目标类生成一个子类,并在该子类中采用方法拦截的方式拦截所有父类方法的调用,从而实现代理的功能。
因为 CGLib 使用生成子类的方式实现动态代理,所以无法代理 final 关键字修饰的方法(因为final 方法是不能够被重写的)。这样的话,CGLib 与 JDK 动态代理之间可以相互补充:在目标类实现接口时,使用 JDK 动态代理创建代理对象;当目标类没有实现接口时,使用 CGLib 实现动态代理的功能。在 Spring、MyBatis 等多种开源框架中,都可以看到JDK动态代理与 CGLib 结合使用的场景。
CGLib 的实现有两个重要的成员组成。
- Enhancer:指定要代理的目标对象以及实际处理代理逻辑的对象,最终通过调用 create() 方法得到代理对象,对这个对象所有的非 final 方法的调用都会转发给 MethodInterceptor 进行处理。
- MethodInterceptor:动态代理对象的方法调用都会转发到intercept方法进行增强。
这两个组件的使用与 JDK 动态代理中的 Proxy 和 InvocationHandler 相似。
下面我们通过一个示例简单介绍 CGLib 的使用。在使用 CGLib 创建动态代理类时,首先需要定义一个 Callback 接口的实现, CGLib 中也提供了多个Callback接口的子接口,如下图所示:

这里以 MethodInterceptor 接口为例进行介绍,首先我们引入 CGLib 的 maven 依赖:
<dependency><groupId>cglib</groupId><artifactId>cglib</artifactId><version>3.3.0</version>
</dependency>
下面是 CglibProxy 类的具体代码,它实现了 MethodInterceptor 接口:
public class CglibProxy implements MethodInterceptor {// 初始化Enhancer对象private Enhancer enhancer = new Enhancer(); public Object getProxy(Class clazz) {enhancer.setSuperclass(clazz); // 指定生成的代理类的父类enhancer.setCallback(this); // 设置Callback对象return enhancer.create(); // 通过ASM字节码技术动态创建子类实例}// 实现MethodInterceptor接口的intercept()方法public Object intercept(Object obj, Method method, Object[] args,MethodProxy proxy) throws Throwable {System.out.println("前置处理");Object result = proxy.invokeSuper(obj, args); // 调用父类中的方法System.out.println("后置处理");return result;}
}
下面我们再编写一个要代理的目标类以及 main 方法进行测试,具体如下:
public class CGLibTest { // 目标类public String method(String str) { // 目标方法System.out.println(str);return "CGLibTest.method():" + str;}public static void main(String[] args) {CglibProxy proxy = new CglibProxy();// 生成CBLibTest的代理对象CGLibTest proxyImp = (CGLibTest) proxy.getProxy(CGLibTest.class);// 调用代理对象的method()方法String result = proxyImp.method("test");System.out.println(result);// ----------------// 输出如下:// 前置代理// test// 后置代理// CGLibTest.method():test}
}
到此,CGLib 基础使用的内容就介绍完了,在后面介绍 Dubbo 源码时我们还会继续介绍涉及的 CGLib 内容。
Javassist
Javassist 是一个开源的生成 Java 字节码的类库,其主要优点在于简单、快速,直接使用Javassist 提供的 Java API 就能动态修改类的结构,或是动态生成类。
Javassist 的使用比较简单,首先来看如何使用 Javassist 提供的 Java API 动态创建类。示例代码如下:
public class JavassistMain {public static void main(String[] args) throws Exception {ClassPool cp = ClassPool.getDefault(); // 创建ClassPool// 要生成的类名称为com.test.JavassistDemoCtClass clazz = cp.makeClass("com.test.JavassistDemo");StringBuffer body = null;// 创建字段,指定了字段类型、字段名称、字段所属的类CtField field = new CtField(cp.get("java.lang.String"), "prop", clazz);// 指定该字段使用private修饰field.setModifiers(Modifier.PRIVATE);// 设置prop字段的getter/setter方法clazz.addMethod(CtNewMethod.setter("getProp", field));clazz.addMethod(CtNewMethod.getter("setProp", field));// 设置prop字段的初始化值,并将prop字段添加到clazz中clazz.addField(field, CtField.Initializer.constant("MyName"));// 创建构造方法,指定了构造方法的参数类型和构造方法所属的类CtConstructor ctConstructor = new CtConstructor(new CtClass[]{}, clazz);// 设置方法体body = new StringBuffer();body.append("{\n prop=\"MyName\";\n}");ctConstructor.setBody(body.toString());clazz.addConstructor(ctConstructor); // 将构造方法添加到clazz中// 创建execute()方法,指定了方法返回值、方法名称、方法参数列表以及// 方法所属的类CtMethod ctMethod = new CtMethod(CtClass.voidType, "execute",new CtClass[]{}, clazz);// 指定该方法使用public修饰ctMethod.setModifiers(Modifier.PUBLIC);// 设置方法体body = new StringBuffer();body.append("{\n System.out.println(\"execute():\" " +"+ this.prop);");body.append("\n}");ctMethod.setBody(body.toString());clazz.addMethod(ctMethod); // 将execute()方法添加到clazz中// 将上面定义的JavassistDemo类保存到指定的目录clazz.writeFile("/Users/xxx/"); // 加载clazz类,并创建对象Class<?> c = clazz.toClass();Object o = c.newInstance();// 调用execute()方法Method method = o.getClass().getMethod("execute", new Class[]{});method.invoke(o, new Object[]{});}
}
执行上述代码之后,在指定的目录下可以找到生成的 JavassistDemo.class 文件,将其反编译,得到 JavassistDemo 的代码如下:
public class JavassistDemo {private String prop = "MyName";public JavassistDemo() {prop = "MyName";}public void setProp(String paramString) {this.prop = paramString;}public String getProp() {return this.prop;}public void execute() {System.out.println("execute():" + this.prop);}
}
Javassist 也可以实现动态代理功能,底层的原理也是通过创建目标类的子类的方式实现的。这里使用 Javassist 为上面生成的 JavassitDemo 创建一个代理对象,具体实现如下:
public class JavassitMain2 {public static void main(String[] args) throws Exception {ProxyFactory factory = new ProxyFactory();// 指定父类,ProxyFactory会动态生成继承该父类的子类factory.setSuperclass(JavassistDemo.class);// 设置过滤器,判断哪些方法调用需要被拦截factory.setFilter(new MethodFilter() {public boolean isHandled(Method m) {if (m.getName().equals("execute")) {return true;}return false;}});// 设置拦截处理factory.setHandler(new MethodHandler() {@Overridepublic Object invoke(Object self, Method thisMethod, Method proceed, Object[] args) throws Throwable {System.out.println("前置处理");Object result = proceed.invoke(self, args);System.out.println("执行结果:" + result);System.out.println("后置处理");return result;}});// 创建JavassistDemo的代理类,并创建代理对象Class<?> c = factory.createClass();JavassistDemo JavassistDemo = (JavassistDemo) c.newInstance();JavassistDemo.execute(); // 执行execute()方法,会被拦截System.out.println(JavassistDemo.getProp());}
}
Javassist 的基础知识就介绍到这里。Javassist可以直接使用 Java 语言的字符串生成类,还是比较好用的。Javassist 的性能也比较好,是 Dubbo 默认的代理生成方式。
总结
本课时我们首先介绍了代理模式的核心概念和用途,让你对代理模式有初步的了解;然后介绍了 JDK 动态代理使用,并深入到 JDK 源码中分析了 JDK 动态代理的实现原理,以及 JDK 动态代理的局限;最后我们介绍了 CGLib和Javassist这两款代码生成工具的基本使用,简述了两者生成代理的原理。
那你还知道哪些实现动态代理的方式呢?
09 Netty入门,用它做网络编程都说好(上)
了解 Java 的同学应该知道,JDK 本身提供了一套 NIO 的 API,但是这一套原生的 API 存在一系列的问题。
- Java NIO 的 API 非常复杂。 要写出成熟可用的 Java NIO 代码,需要熟练掌握 JDK 中的 Selector、ServerSocketChannel、SocketChannel、ByteBuffer 等组件,还要理解其中一些反人类的设计以及底层原理,这对新手来说是非常不友好的。
- 如果直接使用 Java NIO 进行开发,难度和开发量会非常大。我们需要自己补齐很多可靠性方面的实现,例如,网络波动导致的连接重连、半包读写等。这就会导致一些本末倒置的情况出现:核心业务逻辑比较简单,但补齐其他公共能力的代码非常多,开发耗时比较长。这时就需要一个统一的 NIO 框架来封装这些公共能力了。
- JDK 自身的 Bug。其中比较出名的就要属 Epoll Bug 了,这个 Bug 会导致 Selector 空轮询,CPU 使用率达到 100%,这样就会导致业务逻辑无法执行,降低服务性能。
Netty 在 JDK 自带的 NIO API 基础之上进行了封装,解决了 JDK 自身的一些问题,具备如下优点:
- 入门简单,使用方便,文档齐全,无其他依赖,只依赖 JDK 就够了。
- 高性能,高吞吐,低延迟,资源消耗少。
- 灵活的线程模型,支持阻塞和非阻塞的I/O 模型。
- 代码质量高,目前主流版本基本没有 Bug。
正因为 Netty 有以上优点,所以很多互联网公司以及开源的 RPC 框架都将其作为网络通信的基础库,例如,Apache Spark、Apache Flink、 Elastic Search 以及我们本课程分析的 Dubbo 等。
下面我们将从 I/O 模型和线程模型的角度详细为你介绍 Netty 的核心设计,进而帮助你全面掌握 Netty 原理。
Netty I/O 模型设计
在进行网络 I/O 操作的时候,用什么样的方式读写数据将在很大程度上决定了 I/O 的性能。作为一款优秀的网络基础库,Netty 就采用了 NIO 的 I/O 模型,这也是其高性能的重要原因之一。
1. 传统阻塞 I/O 模型
在传统阻塞型 I/O 模型(即我们常说的 BIO)中,如下图所示,每个请求都需要独立的线程完成读数据、业务处理以及写回数据的完整操作。
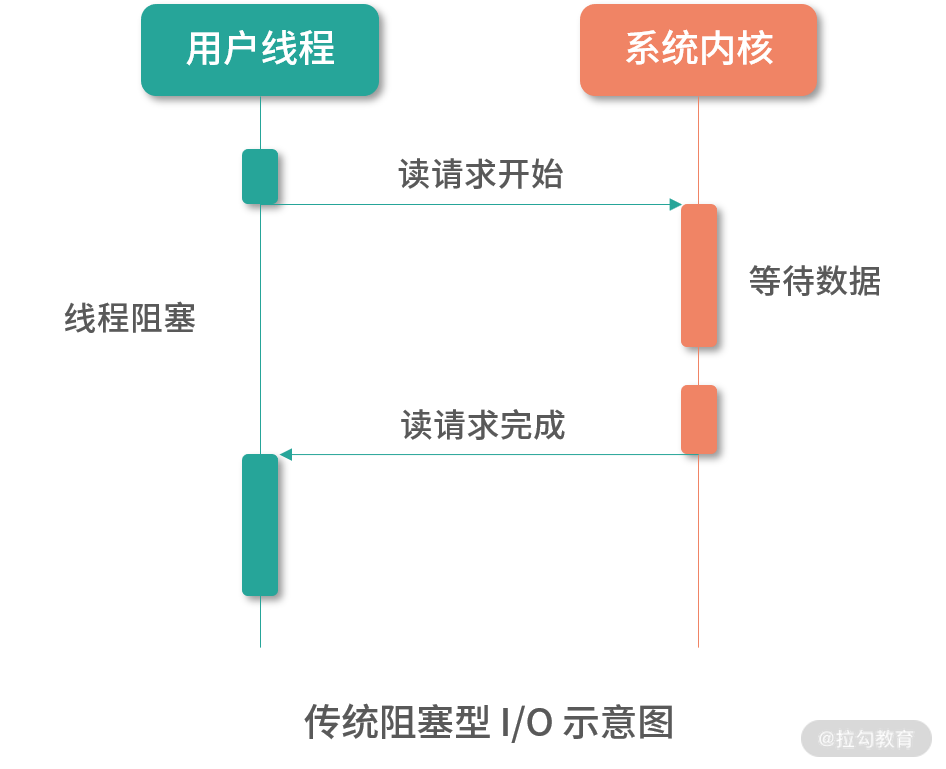
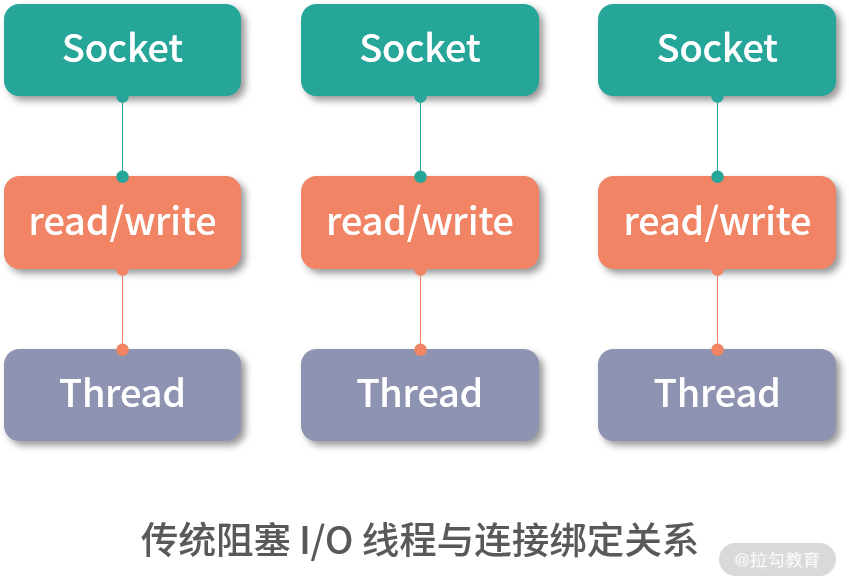
一个线程在同一时刻只能与一个连接绑定,如下图所示,当请求的并发量较大时,就需要创建大量线程来处理连接,这就会导致系统浪费大量的资源进行线程切换,降低程序的性能。我们知道,网络数据的传输速度是远远慢于 CPU 的处理速度,连接建立后,并不总是有数据可读,连接也并不总是可写,那么线程就只能阻塞等待,CPU 的计算能力不能得到充分发挥,同时还会导致大量线程的切换,浪费资源。
2. I/O 多路复用模型
针对传统的阻塞 I/O 模型的缺点,I/O 复用的模型在性能方面有不小的提升。I/O 复用模型中的多个连接会共用一个 Selector 对象,由 Selector 感知连接的读写事件,而此时的线程数并不需要和连接数一致,只需要很少的线程定期从 Selector 上查询连接的读写状态即可,无须大量线程阻塞等待连接。当某个连接有新的数据可以处理时,操作系统会通知线程,线程从阻塞状态返回,开始进行读写操作以及后续的业务逻辑处理。I/O 复用的模型如下图所示:
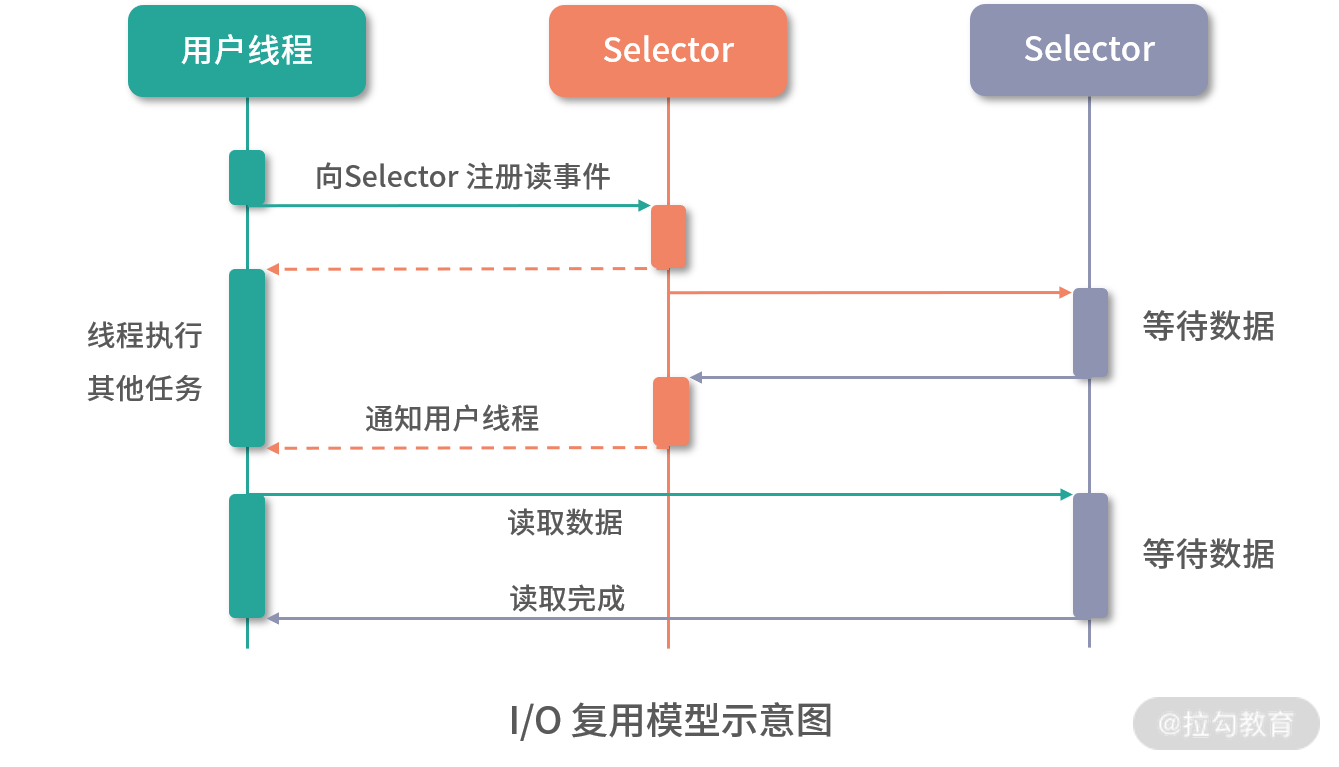
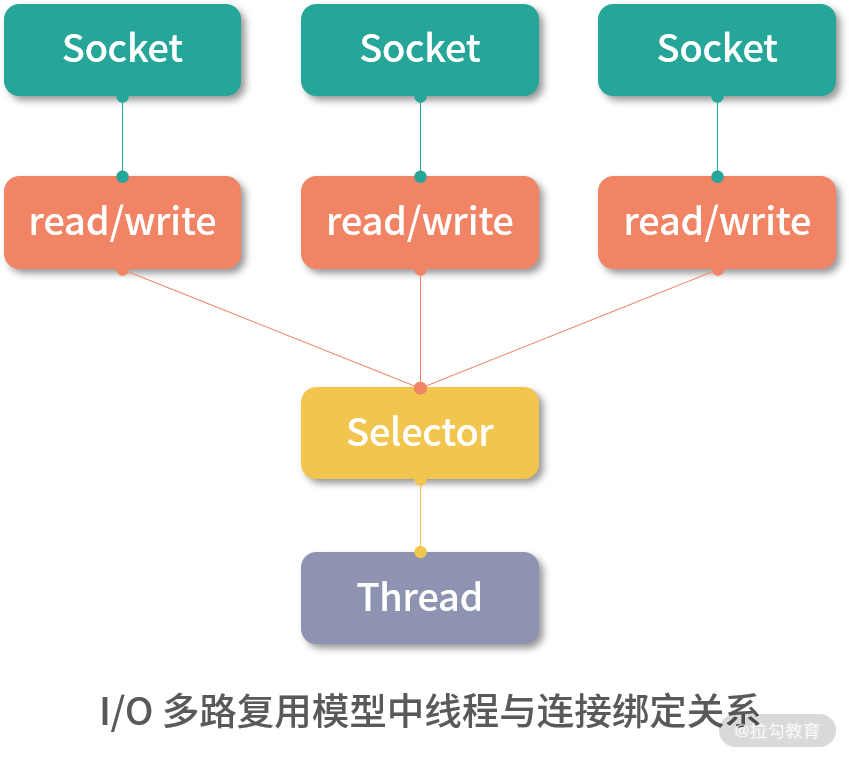
Netty 就是采用了上述 I/O 复用的模型。由于多路复用器 Selector 的存在,可以同时并发处理成百上千个网络连接,大大增加了服务器的处理能力。另外,Selector 并不会阻塞线程,也就是说当一个连接不可读或不可写的时候,线程可以去处理其他可读或可写的连接,这就充分提升了 I/O 线程的运行效率,避免由于频繁 I/O 阻塞导致的线程切换。如下图所示:
从数据处理的角度来看,传统的阻塞 I/O 模型处理的是字节流或字符流,也就是以流式的方式顺序地从一个数据流中读取一个或多个字节,并且不能随意改变读取指针的位置。而在 NIO 中则抛弃了这种传统的 I/O 流概念,引入了 Channel 和 Buffer 的概念,可以从 Channel 中读取数据到 Buffer 中或将数据从 Buffer 中写入到 Channel。Buffer 不像传统 I/O 中的流那样必须顺序操作,在 NIO 中可以读写 Buffer 中任意位置的数据。
Netty 线程模型设计
服务器程序在读取到二进制数据之后,首先需要通过编解码,得到程序逻辑可以理解的消息,然后将消息传入业务逻辑进行处理,并产生相应的结果,返回给客户端。编解码逻辑、消息派发逻辑、业务处理逻辑以及返回响应的逻辑,是放到一个线程里面串行执行,还是分配到不同的线程中执行,会对程序的性能产生很大的影响。所以,优秀的线程模型对一个高性能网络库来说是至关重要的。
Netty 采用了 Reactor 线程模型的设计。 Reactor 模式,也被称为 Dispatcher 模式,核心原理是 Selector 负责监听 I/O 事件,在监听到 I/O 事件之后,分发(Dispatch)给相关线程进行处理。
为了帮助你更好地了解 Netty 线程模型的设计理念,我们将从最基础的单 Reactor 单线程模型开始介绍,然后逐步增加模型的复杂度,最终到 Netty 目前使用的非常成熟的线程模型设计。
1. 单 Reactor 单线程
Reactor 对象监听客户端请求事件,收到事件后通过 Dispatch 进行分发。如果是连接建立的事件,则由 Acceptor 通过 Accept 处理连接请求,然后创建一个 Handler 对象处理连接建立之后的业务请求。如果不是连接建立的事件,而是数据的读写事件,则 Reactor 会将事件分发对应的 Handler 来处理,由这里唯一的线程调用 Handler 对象来完成读取数据、业务处理、发送响应的完整流程。当然,该过程中也可能会出现连接不可读或不可写等情况,该单线程会去执行其他 Handler 的逻辑,而不是阻塞等待。具体情况如下图所示:
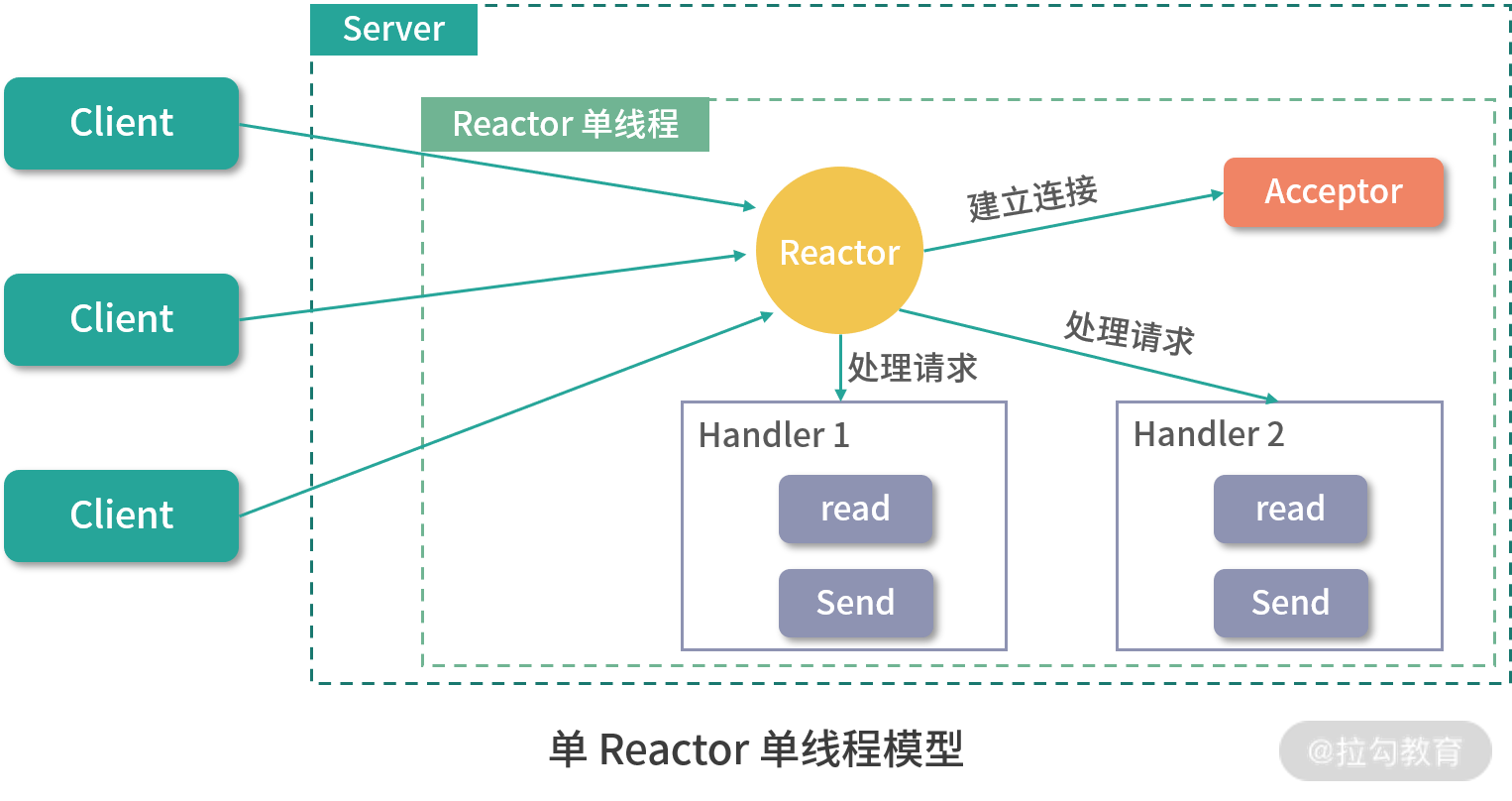
单 Reactor 单线程的优点就是:线程模型简单,没有引入多线程,自然也就没有多线程并发和竞争的问题。
但其缺点也非常明显,那就是性能瓶颈问题,一个线程只能跑在一个 CPU 上,能处理的连接数是有限的,无法完全发挥多核 CPU 的优势。一旦某个业务逻辑耗时较长,这唯一的线程就会卡在上面,无法处理其他连接的请求,程序进入假死的状态,可用性也就降低了。正是由于这种限制,一般只会在客户端使用这种线程模型。
2. 单 Reactor 多线程
在单 Reactor 多线程的架构中,Reactor 监控到客户端请求之后,如果连接建立的请求,则由Acceptor 通过 accept 处理,然后创建一个 Handler 对象处理连接建立之后的业务请求。如果不是连接建立请求,则 Reactor 会将事件分发给调用连接对应的 Handler 来处理。到此为止,该流程与单 Reactor 单线程的模型基本一致,唯一的区别就是执行 Handler 逻辑的线程隶属于一个线程池。
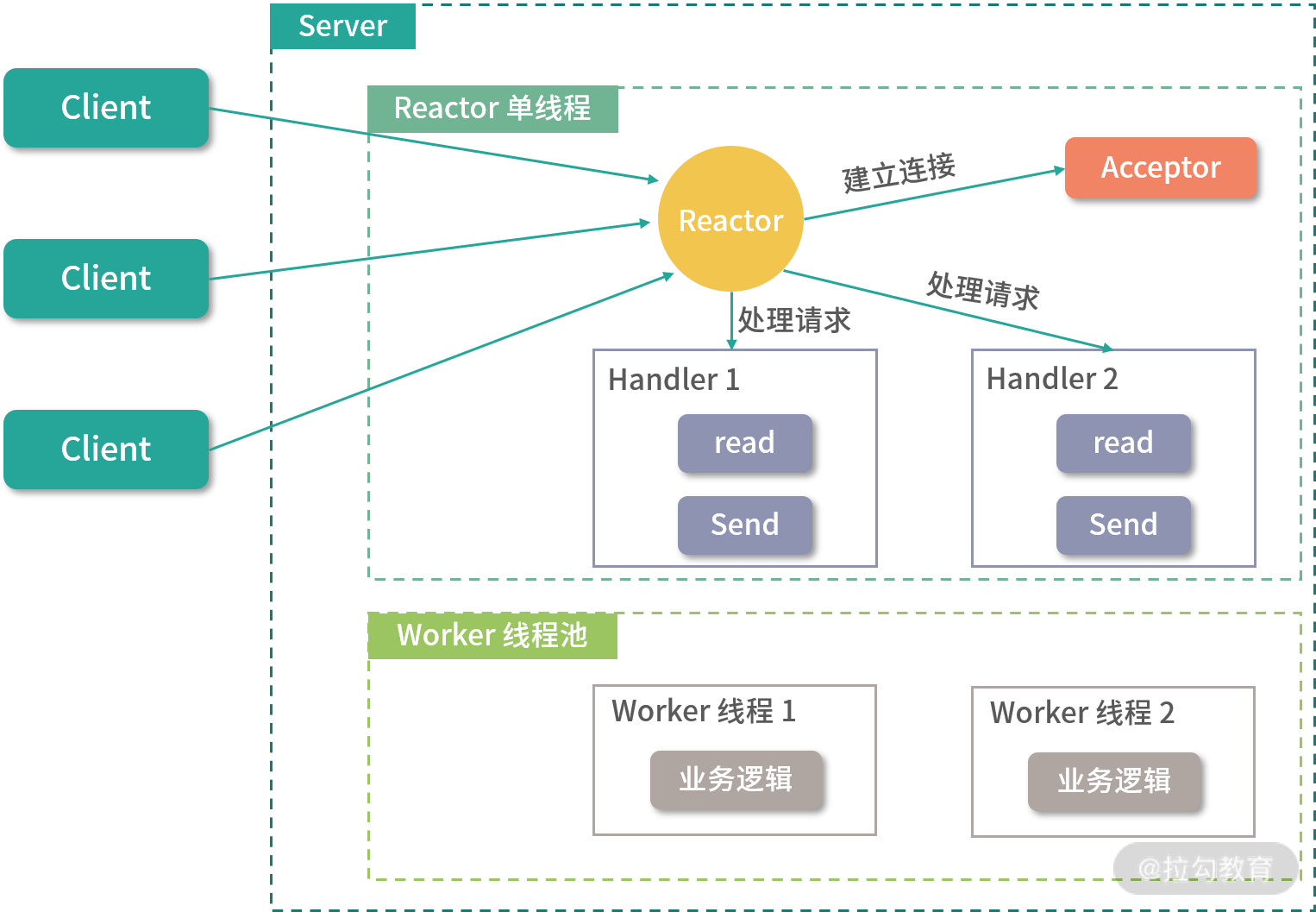
单 Reactor 多线程模型
很明显,单 Reactor 多线程的模型可以充分利用多核 CPU 的处理能力,提高整个系统的吞吐量,但引入多线程模型就要考虑线程并发、数据共享、线程调度等问题。在这个模型中,只有一个线程来处理 Reactor 监听到的所有 I/O 事件,其中就包括连接建立事件以及读写事件,当连接数不断增大的时候,这个唯一的 Reactor 线程也会遇到瓶颈。
3. 主从 Reactor 多线程
为了解决单 Reactor 多线程模型中的问题,我们可以引入多个 Reactor。其中,Reactor 主线程负责通过 Acceptor 对象处理 MainReactor 监听到的连接建立事件,当Acceptor 完成网络连接的建立之后,MainReactor 会将建立好的连接分配给 SubReactor 进行后续监听。
当一个连接被分配到一个 SubReactor 之上时,会由 SubReactor 负责监听该连接上的读写事件。当有新的读事件(OP_READ)发生时,Reactor 子线程就会调用对应的 Handler 读取数据,然后分发给 Worker 线程池中的线程进行处理并返回结果。待处理结束之后,Handler 会根据处理结果调用 send 将响应返回给客户端,当然此时连接要有可写事件(OP_WRITE)才能发送数据。
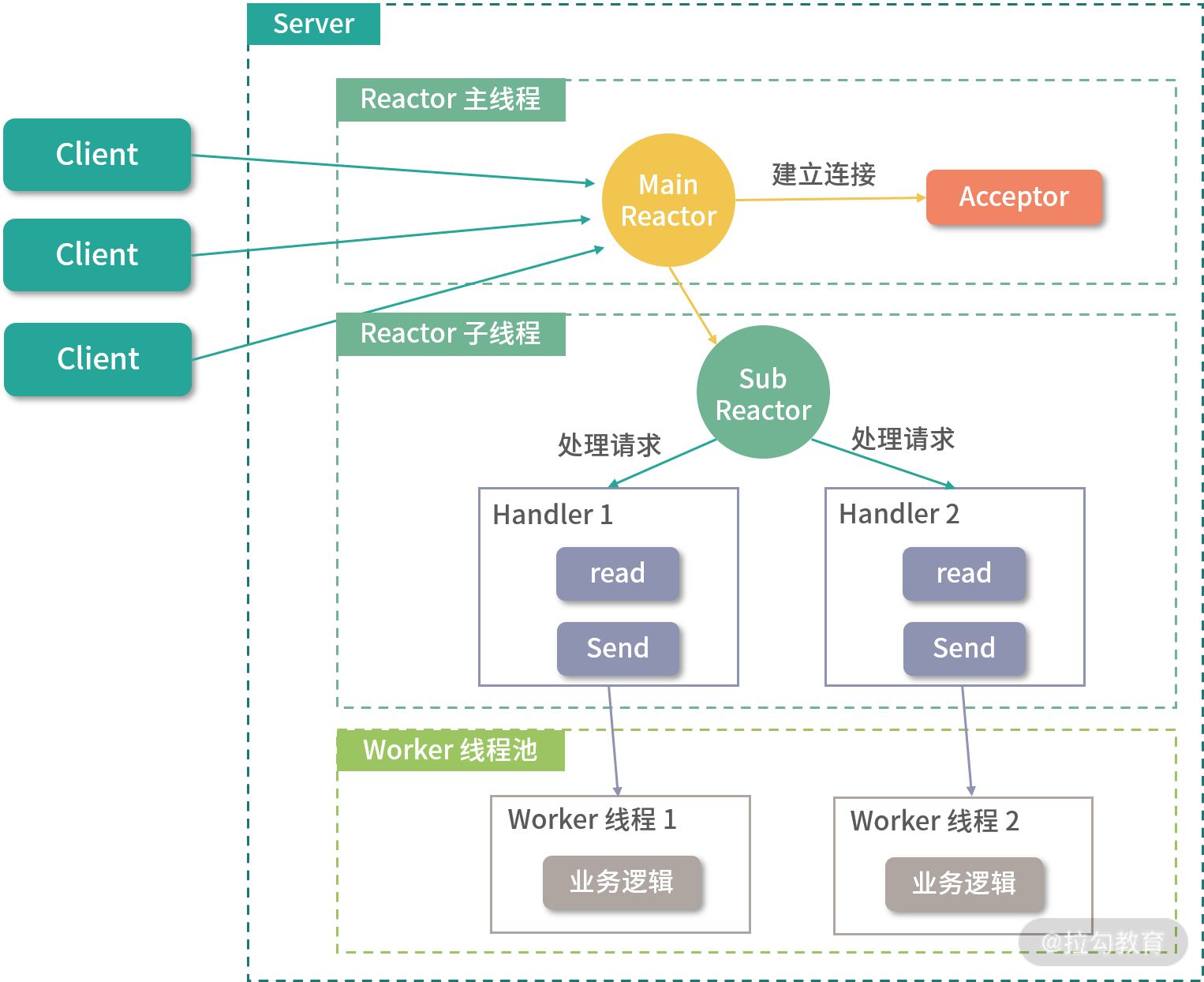
主从 Reactor 多线程模型
主从 Reactor 多线程的设计模式解决了单一 Reactor 的瓶颈。主从 Reactor 职责明确,主 Reactor 只负责监听连接建立事件,SubReactor只负责监听读写事件。整个主从 Reactor 多线程架构充分利用了多核 CPU 的优势,可以支持扩展,而且与具体的业务逻辑充分解耦,复用性高。但不足的地方是,在交互上略显复杂,需要一定的编程门槛。
4. Netty 线程模型
Netty 同时支持上述几种线程模式,Netty 针对服务器端的设计是在主从 Reactor 多线程模型的基础上进行的修改,如下图所示:
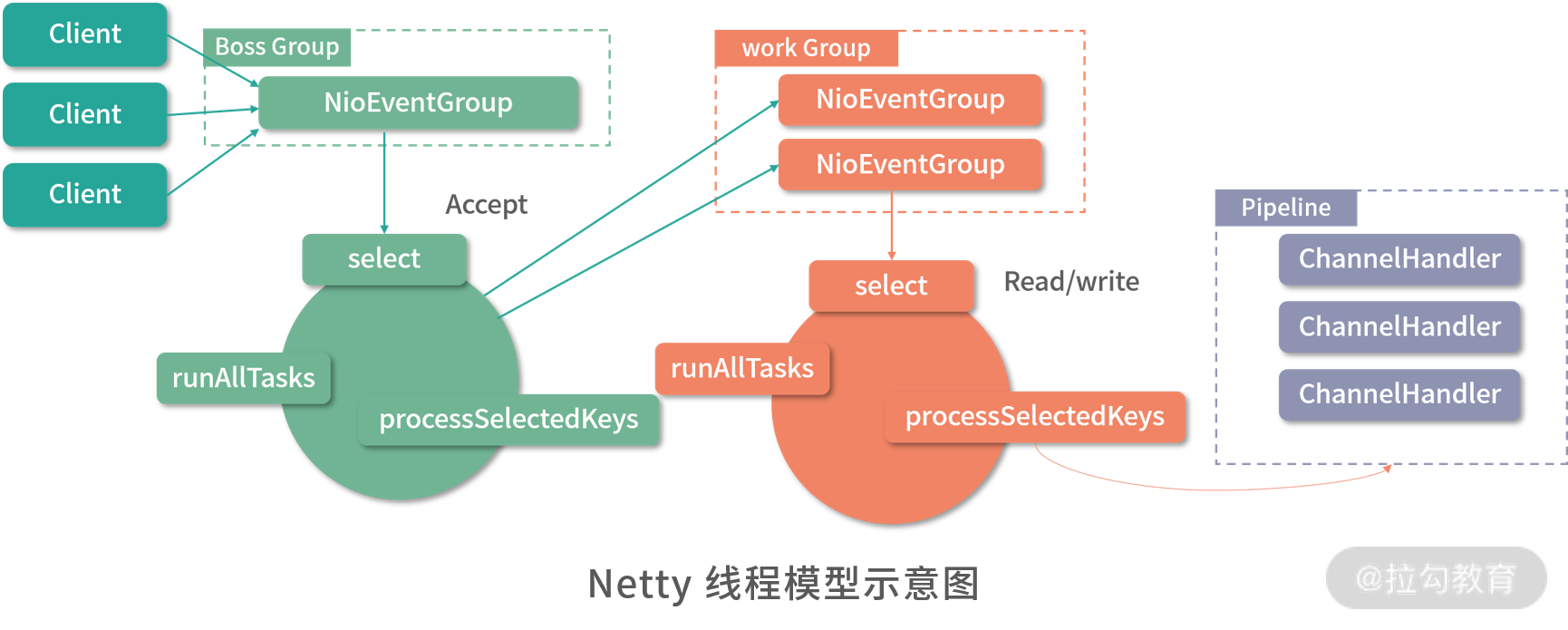
Netty 抽象出两组线程池:BossGroup 专门用于接收客户端的连接,WorkerGroup 专门用于网络的读写。BossGroup 和 WorkerGroup 类型都是 NioEventLoopGroup,相当于一个事件循环组,其中包含多个事件循环 ,每一个事件循环是 NioEventLoop。
NioEventLoop 表示一个不断循环的、执行处理任务的线程,每个 NioEventLoop 都有一个Selector 对象与之对应,用于监听绑定在其上的连接,这些连接上的事件由 Selector 对应的这条线程处理。每个 NioEventLoopGroup 可以含有多个 NioEventLoop,也就是多个线程。
每个 Boss NioEventLoop 会监听 Selector 上连接建立的 accept 事件,然后处理 accept 事件与客户端建立网络连接,生成相应的 NioSocketChannel 对象,一个 NioSocketChannel 就表示一条网络连接。之后会将 NioSocketChannel 注册到某个 Worker NioEventLoop 上的 Selector 中。
每个 Worker NioEventLoop 会监听对应 Selector 上的 read/write 事件,当监听到 read/write 事件的时候,会通过 Pipeline 进行处理。一个 Pipeline 与一个 Channel 绑定,在 Pipeline 上可以添加多个 ChannelHandler,每个 ChannelHandler 中都可以包含一定的逻辑,例如编解码等。Pipeline 在处理请求的时候,会按照我们指定的顺序调用 ChannelHandler。
总结
在本课时我们重点介绍了网络 I/O 的一些背景知识,以及 Netty 的一些宏观设计模型。
- 首先,我们介绍了 Java NIO 的一些缺陷和不足,这也是 Netty 等网络库出现的重要原因之一。
- 接下来,我们介绍了 Netty 在 I/O 模型上的设计,阐述了 I/O 多路复用的优势。
- 最后,我们从基础的单 Reactor 单线程模型开始,一步步深入,介绍了常见的网络 I/O 线程模型,并介绍了 Netty 目前使用的线程模型。
10 Netty入门,用它做网络编程都说好(下)
在本课时,我们就深入到 Netty 内部,介绍一下 Netty 框架核心组件的功能,并概述它们的实现原理,进一步帮助你了解 Netty 的内核。
这里我们依旧采用之前的思路来介绍 Netty 的核心组件:首先是 Netty 对 I/O 模型设计中概念的抽象,如 Selector 等组件;接下来是线程模型的相关组件介绍,主要是 NioEventLoop、NioEventLoopGroup 等;最后再深入剖析 Netty 处理数据的相关组件,例如 ByteBuf、内存管理的相关知识。
Channel
Channel 是 Netty 对网络连接的抽象,核心功能是执行网络 I/O 操作。不同协议、不同阻塞类型的连接对应不同的 Channel 类型。我们一般用的都是 NIO 的 Channel,下面是一些常用的 NIO Channel 类型。
- NioSocketChannel:对应异步的 TCP Socket 连接。
- NioServerSocketChannel:对应异步的服务器端 TCP Socket 连接。
- NioDatagramChannel:对应异步的 UDP 连接。
上述异步 Channel 主要提供了异步的网络 I/O 操作,例如:建立连接、读写操作等。异步调用意味着任何 I/O 调用都将立即返回,并且不保证在调用返回时所请求的 I/O 操作已完成。I/O 操作返回的是一个 ChannelFuture 对象,无论 I/O 操作是否成功,Channel 都可以通过监听器通知调用方,我们通过向 ChannelFuture 上注册监听器来监听 I/O 操作的结果。
Netty 也支持同步 I/O 操作,但在实践中几乎不使用。绝大多数情况下,我们使用的是 Netty 中异步 I/O 操作。虽然立即返回一个 ChannelFuture 对象,但不能立刻知晓 I/O 操作是否成功,这时我们就需要向 ChannelFuture 中注册一个监听器,当操作执行成功或失败时,监听器会自动触发注册的监听事件。
另外,Channel 还提供了检测当前网络连接状态等功能,这些可以帮助我们实现网络异常断开后自动重连的功能。
Selector
Selector 是对多路复用器的抽象,也是 Java NIO 的核心基础组件之一。Netty 就是基于 Selector 对象实现 I/O 多路复用的,在 Selector 内部,会通过系统调用不断地查询这些注册在其上的 Channel 是否有已就绪的 I/O 事件,例如,可读事件(OP_READ)、可写事件(OP_WRITE)或是网络连接事件(OP_ACCEPT)等,而无须使用用户线程进行轮询。这样,我们就可以用一个线程监听多个 Channel 上发生的事件。
ChannelPipeline&ChannelHandler
提到 Pipeline,你可能最先想到的是 Linux 命令中的管道,它可以实现将一条命令的输出作为另一条命令的输入。Netty 中的 ChannelPipeline 也可以实现类似的功能:ChannelPipeline 会将一个 ChannelHandler 处理后的数据作为下一个 ChannelHandler 的输入。
下图我们引用了 Netty Javadoc 中对 ChannelPipeline 的说明,描述了 ChannelPipeline 中 ChannelHandler 通常是如何处理 I/O 事件的。Netty 中定义了两种事件类型:入站(Inbound)事件和出站(Outbound)事件。这两种事件就像 Linux 管道中的数据一样,在 ChannelPipeline 中传递,事件之中也可能会附加数据。ChannelPipeline 之上可以注册多个 ChannelHandler(ChannelInboundHandler 或 ChannelOutboundHandler),我们在 ChannelHandler 注册的时候决定处理 I/O 事件的顺序,这就是典型的责任链模式。
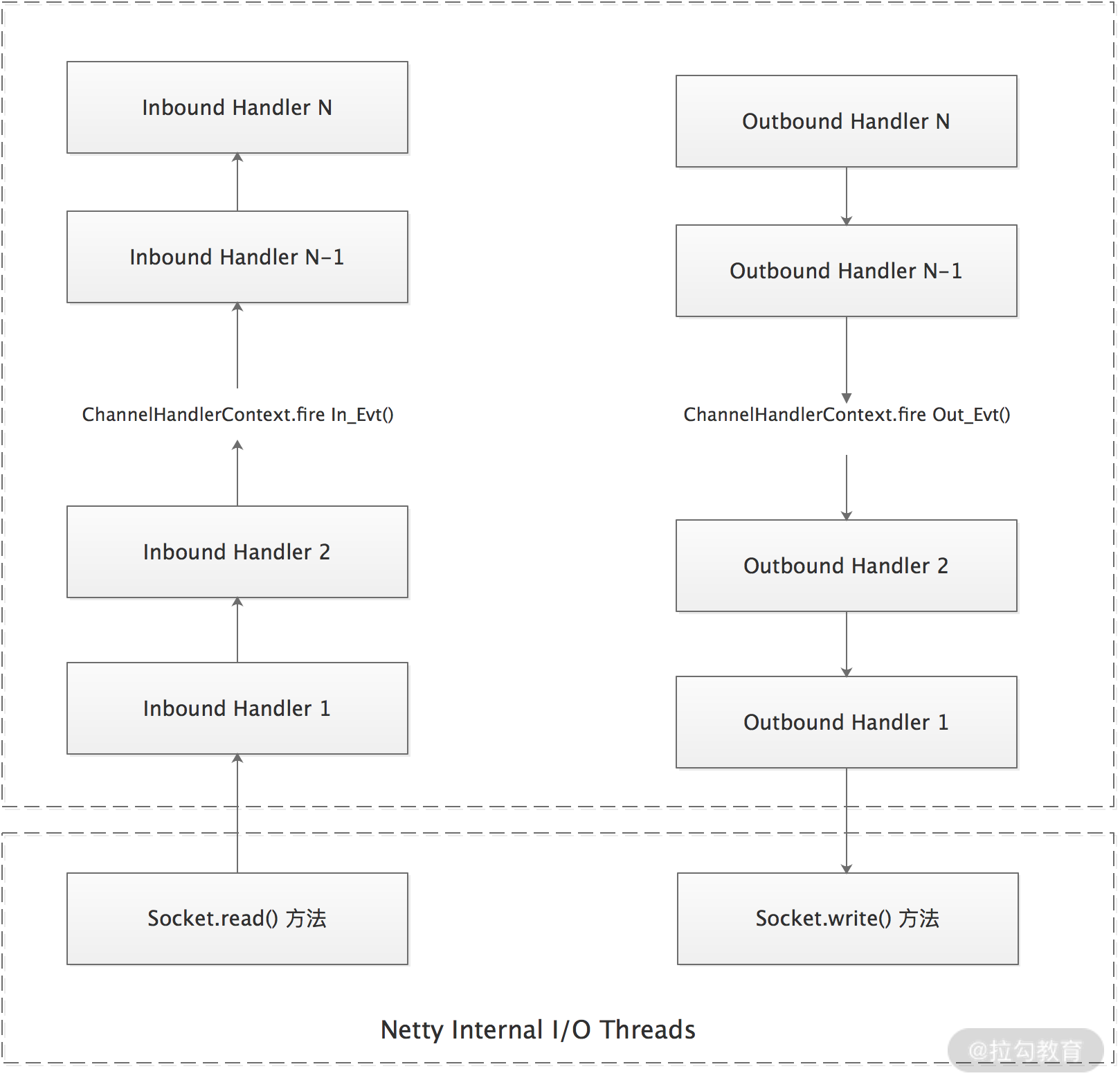
从图中我们还可以看到,I/O 事件不会在 ChannelPipeline 中自动传播,而是需要调用ChannelHandlerContext 中定义的相应方法进行传播,例如:fireChannelRead() 方法和 write() 方法等。
这里我们举一个简单的例子,如下所示,在该 ChannelPipeline 上,我们添加了 5 个 ChannelHandler 对象:
ChannelPipeline p = socketChannel.pipeline(); p.addLast("1", new InboundHandlerA());
p.addLast("2", new InboundHandlerB());
p.addLast("3", new OutboundHandlerA());
p.addLast("4", new OutboundHandlerB());
p.addLast("5", new InboundOutboundHandlerX());
- 对于入站(Inbound)事件,处理序列为:1 → 2 → 5;
- 对于出站(Outbound)事件,处理序列为:5 → 4 → 3。
可见,入站(Inbound)与出站(Outbound)事件处理顺序正好相反。
入站(Inbound)事件一般由 I/O 线程触发。举个例子,我们自定义了一种消息协议,一条完整的消息是由消息头和消息体两部分组成,其中消息头会含有消息类型、控制位、数据长度等元数据,消息体则包含了真正传输的数据。在面对一块较大的数据时,客户端一般会将数据切分成多条消息发送,服务端接收到数据后,一般会先进行解码和缓存,待收集到长度足够的字节数据,组装成有固定含义的消息之后,才会传递给下一个 ChannelInboudHandler 进行后续处理。
在 Netty 中就提供了很多 Encoder 的实现用来解码读取到的数据,Encoder 会处理多次 channelRead() 事件,等拿到有意义的数据之后,才会触发一次下一个 ChannelInboundHandler 的 channelRead() 方法。
出站(Outbound)事件与入站(Inbound)事件相反,一般是由用户触发的。
ChannelHandler 接口中并没有定义方法来处理事件,而是由其子类进行处理的,如下图所示,ChannelInboundHandler 拦截并处理入站事件,ChannelOutboundHandler 拦截并处理出站事件。
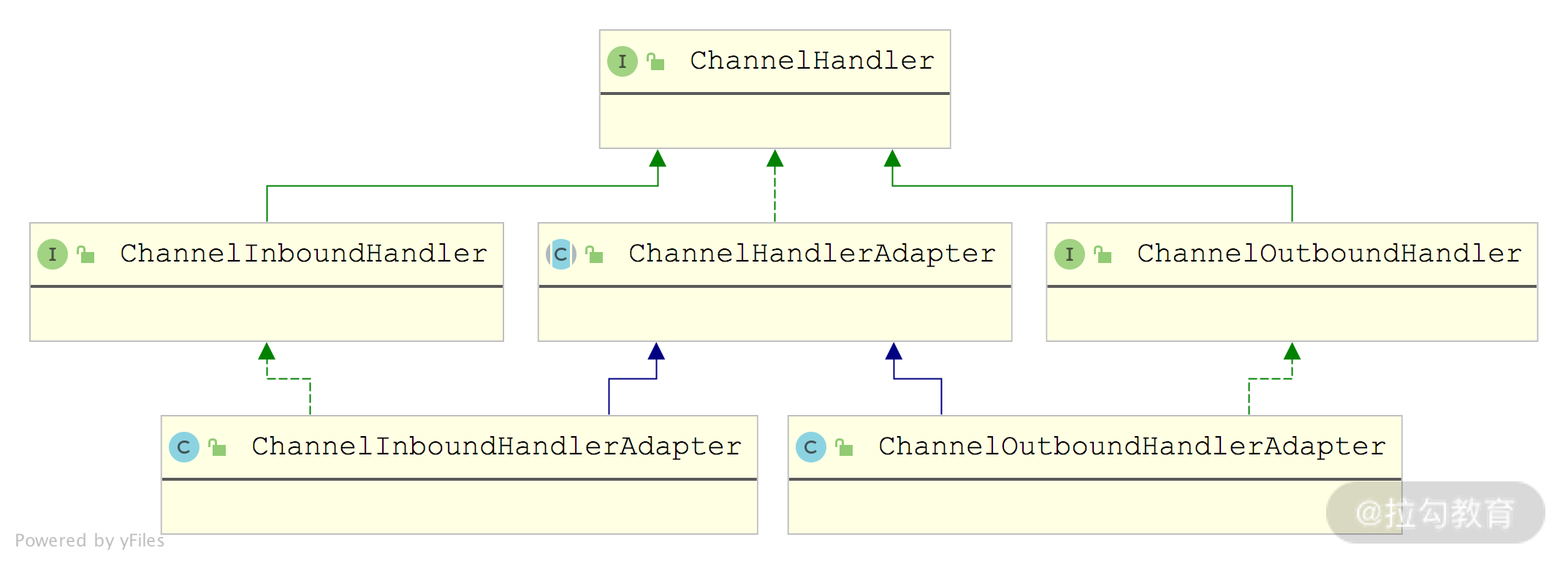
Netty 提供的 ChannelInboundHandlerAdapter 和 ChannelOutboundHandlerAdapter 主要是帮助完成事件流转功能的,即自动调用传递事件的相应方法。这样,我们在自定义 ChannelHandler 实现类的时候,就可以直接继承相应的 Adapter 类,并覆盖需要的事件处理方法,其他不关心的事件方法直接使用默认实现即可,从而提高开发效率。
ChannelHandler 中的很多方法都需要一个 ChannelHandlerContext 类型的参数,ChannelHandlerContext 抽象的是 ChannleHandler 之间的关系以及 ChannelHandler 与ChannelPipeline 之间的关系。ChannelPipeline 中的事件传播主要依赖于ChannelHandlerContext 实现,在 ChannelHandlerContext 中维护了 ChannelHandler 之间的关系,所以我们可以从 ChannelHandlerContext 中得到当前 ChannelHandler 的后继节点,从而将事件传播到后续的 ChannelHandler。
ChannelHandlerContext 继承了 AttributeMap,所以提供了 attr() 方法设置和删除一些状态属性信息,我们可将业务逻辑中所需使用的状态属性值存入到 ChannelHandlerContext 中,然后这些属性就可以随它传播了。Channel 中也维护了一个 AttributeMap,与 ChannelHandlerContext 中的 AttributeMap,从 Netty 4.1 开始,都是作用于整个 ChannelPipeline。
通过上述分析,我们可以了解到,一个 Channel 对应一个 ChannelPipeline,一个 ChannelHandlerContext 对应一个ChannelHandler。 如下图所示:

最后,需要注意的是,如果要在 ChannelHandler 中执行耗时较长的逻辑,例如,操作 DB 、进行网络或磁盘 I/O 等操作,一般会在注册到 ChannelPipeline 的同时,指定一个线程池异步执行 ChannelHandler 中的操作。
NioEventLoop
在前文介绍 Netty 线程模型的时候,我们简单提到了 NioEventLoop 这个组件,当时为了便于理解,只是简单将其描述成了一个线程。
一个 EventLoop 对象由一个永远都不会改变的线程驱动,同时一个 NioEventLoop 包含了一个 Selector 对象,可以支持多个 Channel 注册在其上,该 NioEventLoop 可以同时服务多个 Channel,每个 Channel 只能与一个 NioEventLoop 绑定,这样就实现了线程与 Channel 之间的关联。
我们知道,Channel 中的 I/O 操作是由 ChannelPipeline 中注册的 ChannelHandler 进行处理的,而 ChannelHandler 的逻辑都是由相应 NioEventLoop 关联的那个线程执行的。
除了与一个线程绑定之外,NioEvenLoop 中还维护了两个任务队列:
-
普通任务队列。用户产生的普通任务可以提交到该队列中暂存,NioEventLoop 发现该队列中的任务后会立即执行。这是一个多生产者、单消费者的队列,Netty 使用该队列将外部用户线程产生的任务收集到一起,并在 Reactor 线程内部用单线程的方式串行执行队列中的任务。例如,外部非 I/O 线程调用了 Channel 的 write() 方法,Netty 会将其封装成一个任务放入 TaskQueue 队列中,这样,所有的 I/O 操作都会在 I/O 线程中串行执行。
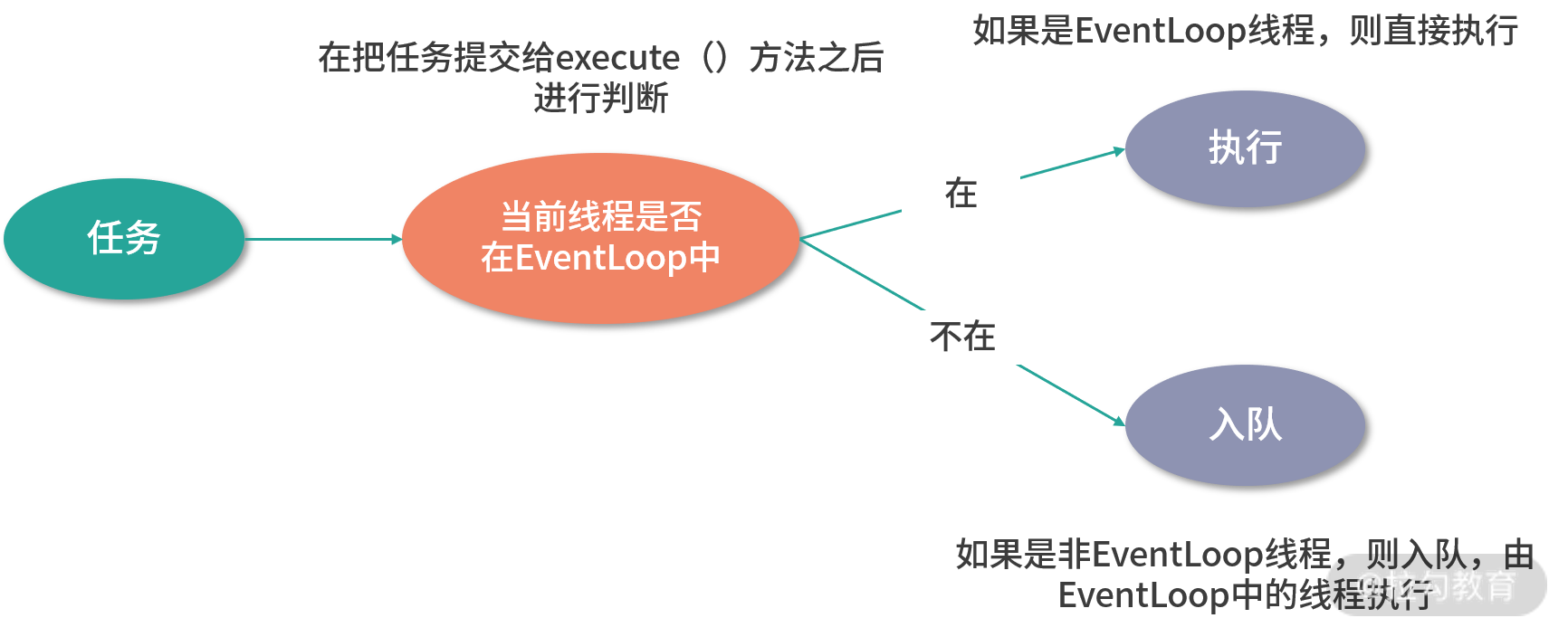
-
定时任务队列。当用户在非 I/O 线程产生定时操作时,Netty 将用户的定时操作封装成定时任务,并将其放入该定时任务队列中等待相应 NioEventLoop 串行执行。
到这里我们可以看出,NioEventLoop 主要做三件事:监听 I/O 事件、执行普通任务以及执行定时任务。NioEventLoop 到底分配多少时间在不同类型的任务上,是可以配置的。另外,为了防止 NioEventLoop 长时间阻塞在一个任务上,一般会将耗时的操作提交到其他业务线程池处理。
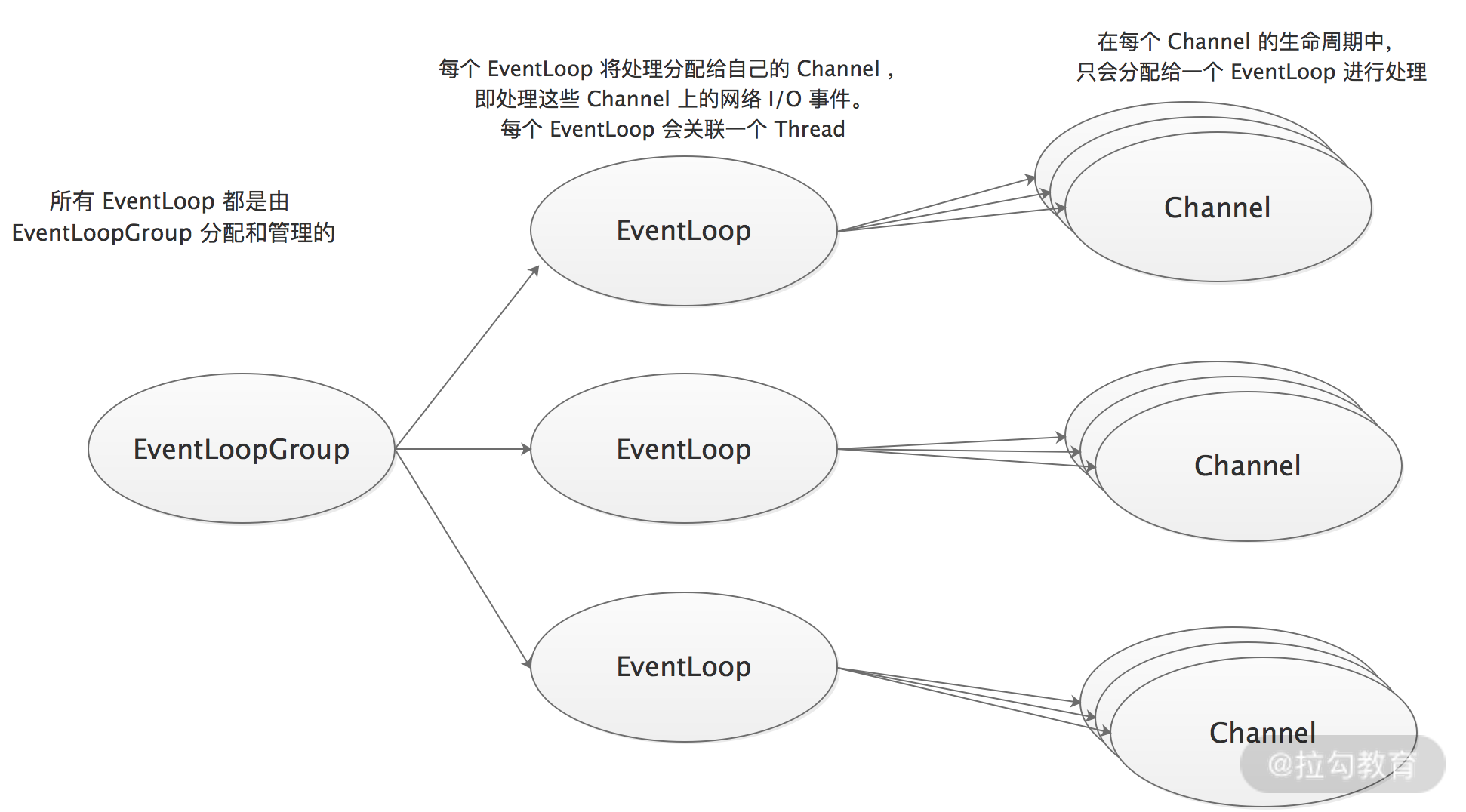
NioEventLoopGroup
NioEventLoopGroup 表示的是一组 NioEventLoop。Netty 为了能更充分地利用多核 CPU 资源,一般会有多个 NioEventLoop 同时工作,至于多少线程可由用户决定,Netty 会根据实际上的处理器核数计算一个默认值,具体计算公式是:CPU 的核心数 * 2,当然我们也可以根据实际情况手动调整。
当一个 Channel 创建之后,Netty 会调用 NioEventLoopGroup 提供的 next() 方法,按照一定规则获取其中一个 NioEventLoop 实例,并将 Channel 注册到该 NioEventLoop 实例,之后,就由该 NioEventLoop 来处理 Channel 上的事件。EventLoopGroup、EventLoop 以及 Channel 三者的关联关系,如下图所示:
前面我们提到过,在 Netty 服务器端中,会有 BossEventLoopGroup 和 WorkerEventLoopGroup 两个 NioEventLoopGroup。通常一个服务端口只需要一个ServerSocketChannel,对应一个 Selector 和一个 NioEventLoop 线程。
BossEventLoop 负责接收客户端的连接事件,即 OP_ACCEPT 事件,然后将创建的 NioSocketChannel 交给 WorkerEventLoopGroup; WorkerEventLoopGroup 会由 next() 方法选择其中一个 NioEventLoopGroup,并将这个 NioSocketChannel 注册到其维护的 Selector 并对其后续的I/O事件进行处理。
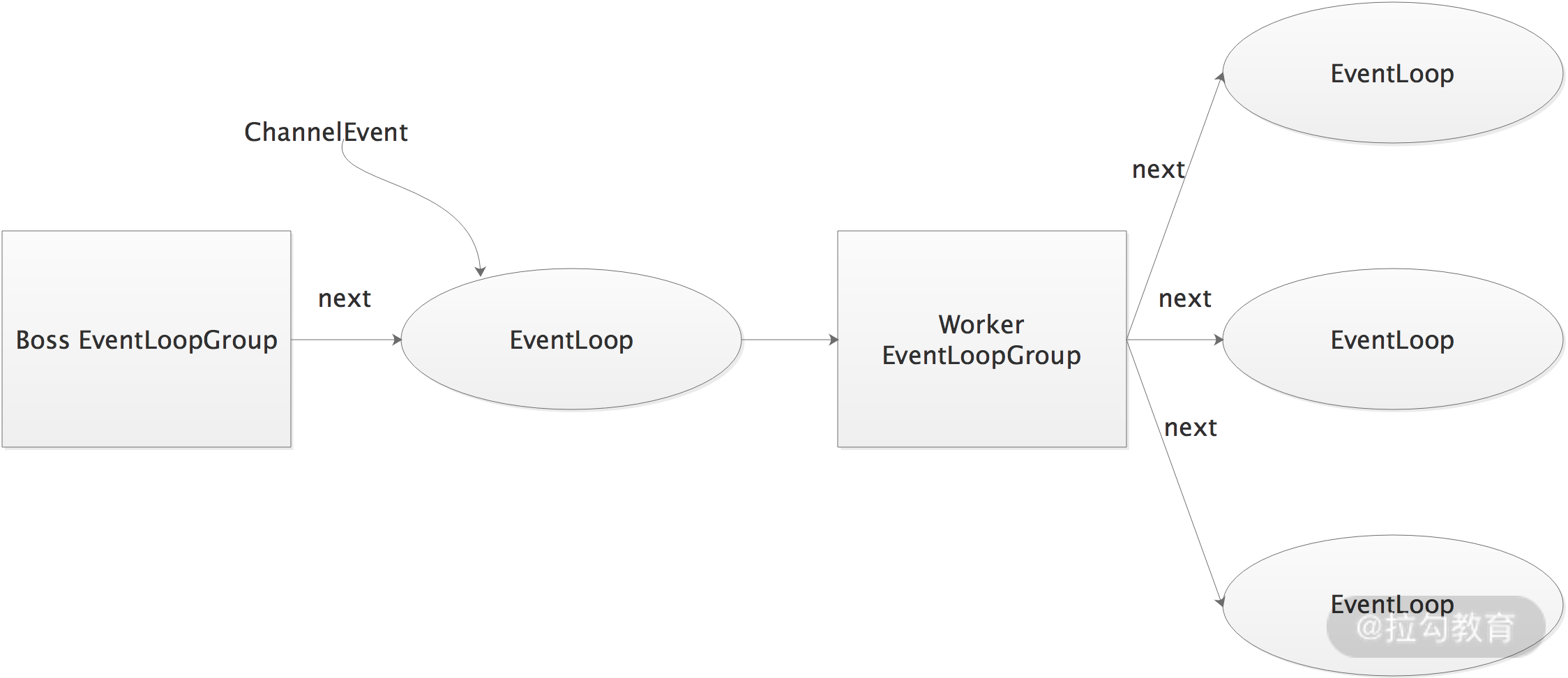
如上图,BossEventLoopGroup 通常是一个单线程的 EventLoop,EventLoop 维护着一个 Selector 对象,其上注册了一个 ServerSocketChannel,BoosEventLoop 会不断轮询 Selector 监听连接事件,在发生连接事件时,通过 accept 操作与客户端创建连接,创建 SocketChannel 对象。然后将 accept 操作得到的 SocketChannel 交给 WorkerEventLoopGroup,在Reactor 模式中 WorkerEventLoopGroup 中会维护多个 EventLoop,而每个 EventLoop 都会监听分配给它的 SocketChannel 上发生的 I/O 事件,并将这些具体的事件分发给业务线程池处理。
ByteBuf
通过前文的介绍,我们了解了 Netty 中数据的流向,这里我们再来介绍一下数据的容器——ByteBuf。
在进行跨进程远程交互的时候,我们需要以字节的形式发送和接收数据,发送端和接收端都需要一个高效的数据容器来缓存字节数据,ByteBuf 就扮演了这样一个数据容器的角色。
ByteBuf 类似于一个字节数组,其中维护了一个读索引和一个写索引,分别用来控制对 ByteBuf 中数据的读写操作,两者符合下面的不等式:
0 <= readerIndex <= writerIndex <= capacity
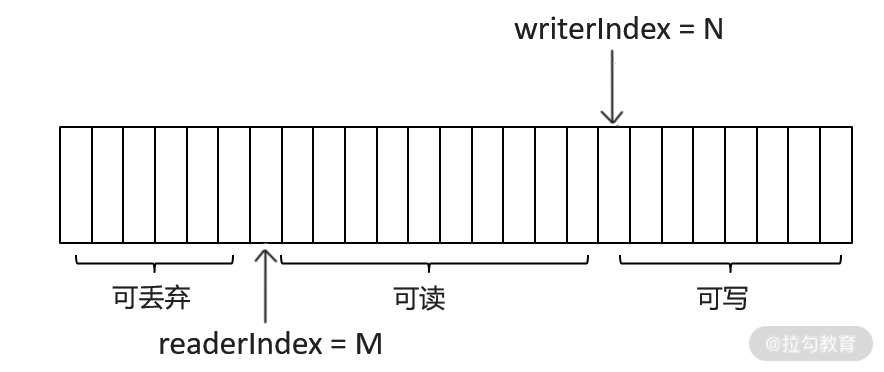
ByteBuf 提供的读写操作 API 主要操作底层的字节容器(byte[]、ByteBuffer 等)以及读写索引这两指针,你若感兴趣的话,可以查阅相关的 API 说明,这里不再展开介绍。
Netty 中主要分为以下三大类 ByteBuf:
- Heap Buffer(堆缓冲区)。这是最常用的一种 ByteBuf,它将数据存储在 JVM 的堆空间,其底层实现是在 JVM 堆内分配一个数组,实现数据的存储。堆缓冲区可以快速分配,当不使用时也可以由 GC 轻松释放。它还提供了直接访问底层数组的方法,通过 ByteBuf.array() 来获取底层存储数据的 byte[] 。
- Direct Buffer(直接缓冲区)。直接缓冲区会使用堆外内存存储数据,不会占用 JVM 堆的空间,使用时应该考虑应用程序要使用的最大内存容量以及如何及时释放。直接缓冲区在使用 Socket 传递数据时性能很好,当然,它也是有缺点的,因为没有了 JVM GC 的管理,在分配内存空间和释放内存时,比堆缓冲区更复杂,Netty 主要使用内存池来解决这样的问题,这也是 Netty 使用内存池的原因之一。
- Composite Buffer(复合缓冲区)。我们可以创建多个不同的 ByteBuf,然后提供一个这些 ByteBuf 组合的视图,也就是 CompositeByteBuf。它就像一个列表,可以动态添加和删除其中的 ByteBuf。
内存管理
Netty 使用 ByteBuf 对象作为数据容器,进行 I/O 读写操作,其实 Netty 的内存管理也是围绕着ByteBuf 对象高效地分配和释放。从内存管理角度来看,ByteBuf 可分为 Unpooled 和 Pooled 两类。
- Unpooled,是指非池化的内存管理方式。每次分配时直接调用系统 API 向操作系统申请 ByteBuf,在使用完成之后,通过系统调用进行释放。Unpooled 将内存管理完全交给系统,不做任何特殊处理,使用起来比较方便,对于申请和释放操作不频繁、操作成本比较低的 ByteBuf 来说,是比较好的选择。
- Pooled,是指池化的内存管理方式。该方式会预先申请一块大内存形成内存池,在需要申请 ByteBuf 空间的时候,会将内存池中一部分合理的空间封装成 ByteBuf 给服务使用,使用完成后回收到内存池中。前面提到 DirectByteBuf 底层使用的堆外内存管理比较复杂,池化技术很好地解决了这一问题。
下面我们从如何高效分配和释放内存、如何减少内存碎片以及在多线程环境下如何减少锁竞争这三个方面介绍一下 Netty 提供的 ByteBuf 池化技术。
Netty 首先会向系统申请一整块连续内存,称为 Chunk(默认大小为 16 MB),这一块连续的内存通过 PoolChunk 对象进行封装。之后,Netty 将 Chunk 空间进一步拆分为 Page,每个 Chunk 默认包含 2048 个 Page,每个 Page 的大小为 8 KB。
在同一个 Chunk 中,Netty 将 Page 按照不同粒度进行分层管理。如下图所示,从下数第 1 层中每个分组的大小为 1 * PageSize,一共有 2048 个分组;第 2 层中每个分组大小为 2 * PageSize,一共有 1024 个组;第 3 层中每个分组大小为 4 * PageSize,一共有 512 个组;依次类推,直至最顶层。
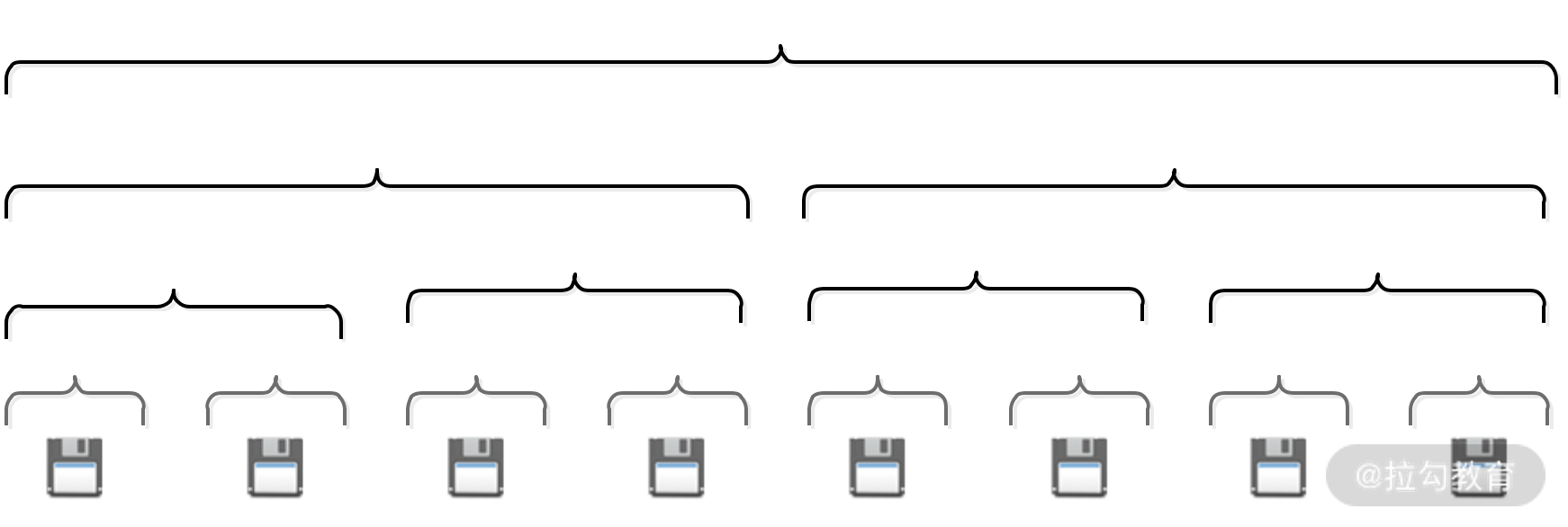
1. 内存分配&释放
当服务向内存池请求内存时,Netty 会将请求分配的内存数向上取整到最接近的分组大小,然后在该分组的相应层级中从左至右寻找空闲分组。例如,服务请求分配 3 * PageSize 的内存,向上取整得到的分组大小为 4 * PageSize,在该层分组中找到完全空闲的一组内存进行分配即可,如下图:
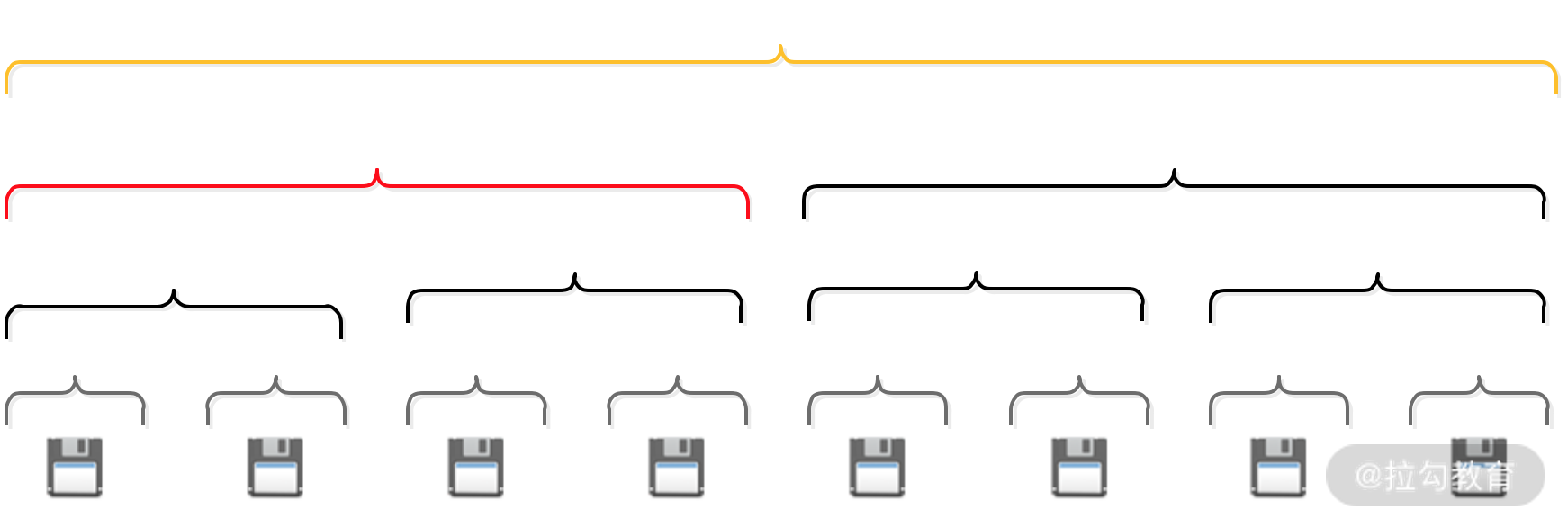
当分组大小 4 * PageSize 的内存分配出去后,为了方便下次内存分配,分组被标记为全部已使用(图中红色标记),向上更粗粒度的内存分组被标记为部分已使用(图中黄色标记)。
Netty 使用完全平衡树的结构实现了上述算法,这个完全平衡树底层是基于一个 byte 数组构建的,如下图所示:
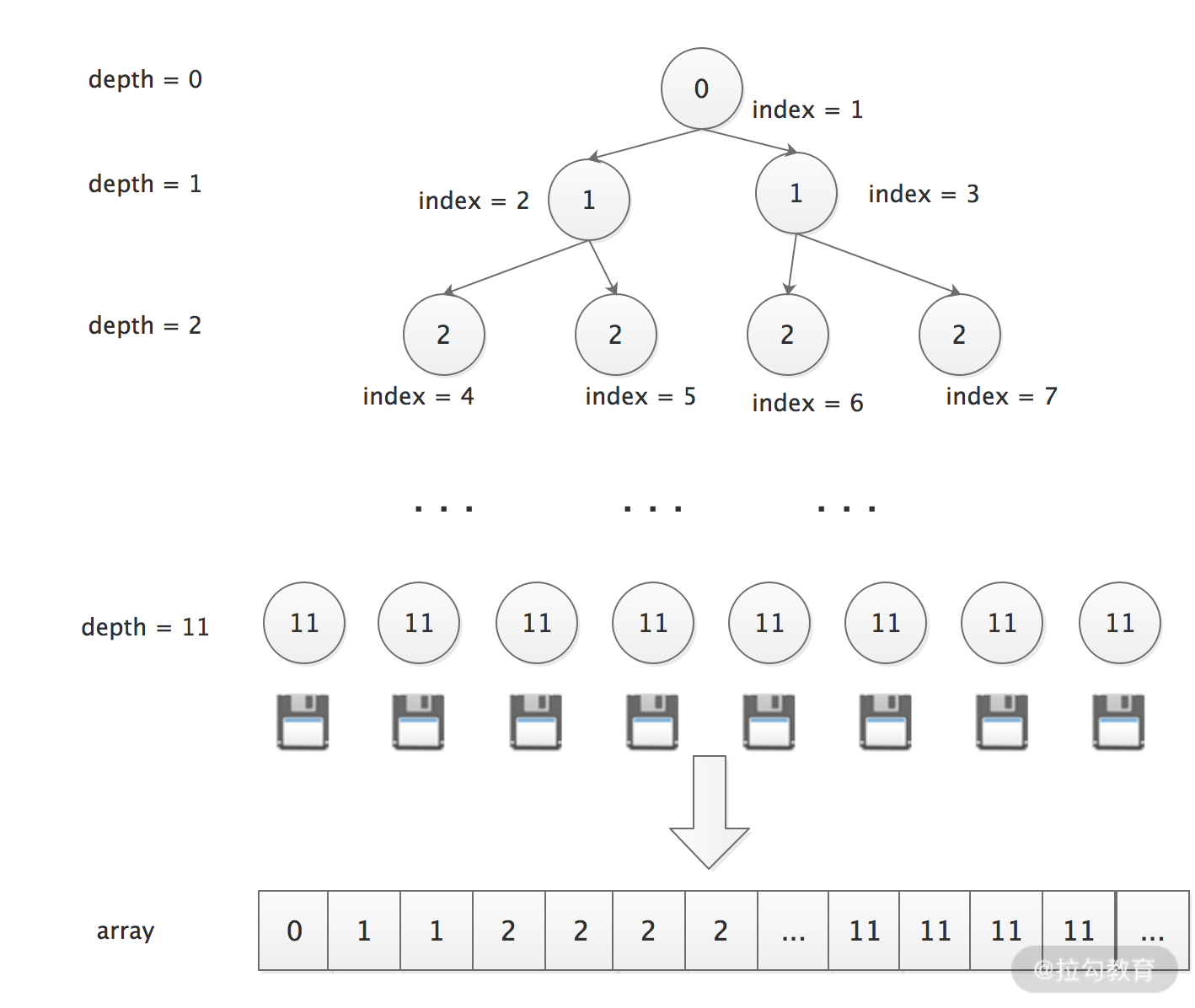
具体的实现逻辑这里就不再展开讲述了,你若感兴趣的话,可以参考 Netty 代码。
2. 大对象&小对象的处理
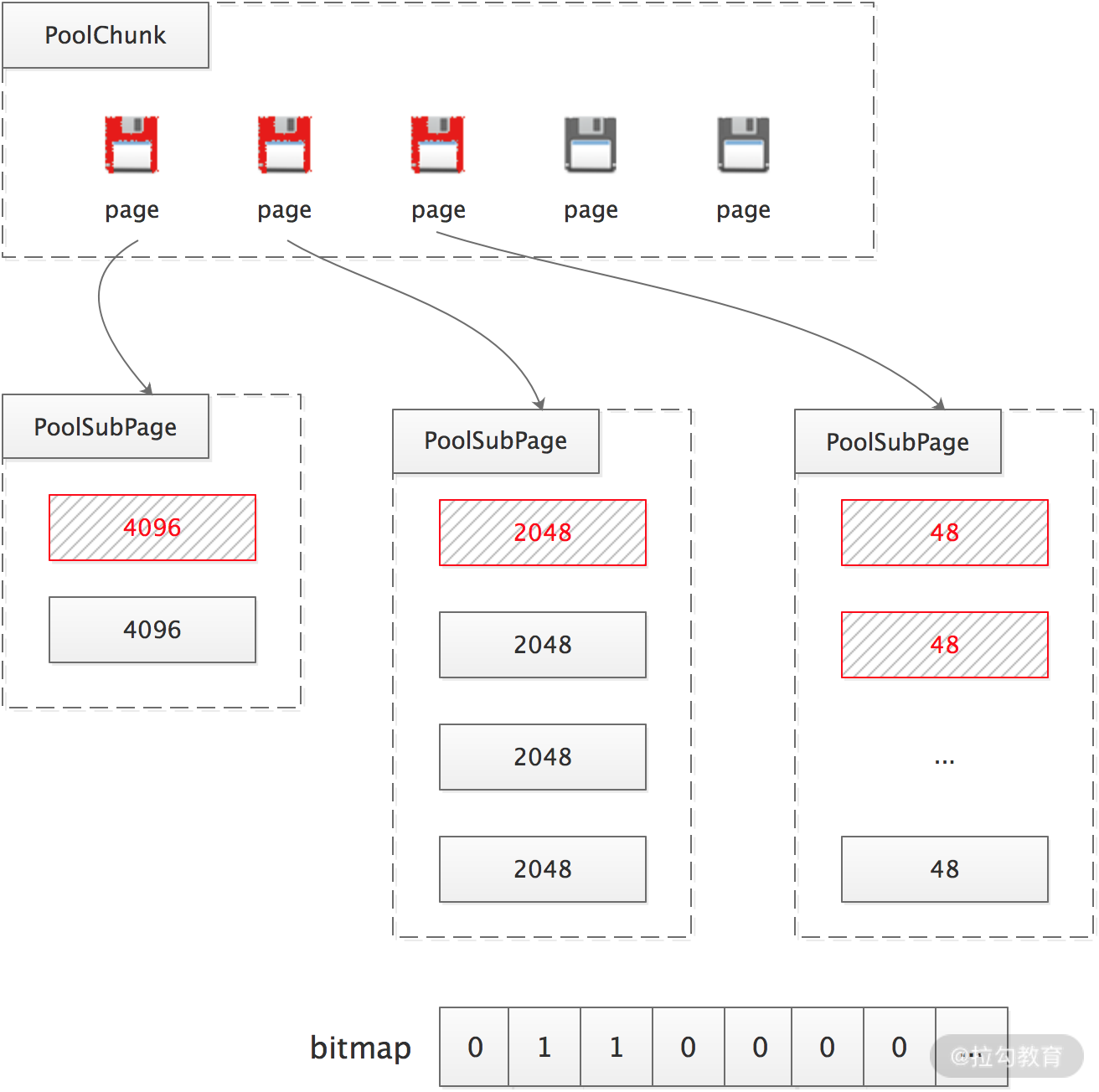
当申请分配的对象是超过 Chunk 容量的大型对象,Netty 就不再使用池化管理方式了,在每次请求分配内存时单独创建特殊的非池化 PoolChunk 对象进行管理,当对象内存释放时整个PoolChunk 内存释放。
如果需要一定数量空间远小于 PageSize 的 ByteBuf 对象,例如,创建 256 Byte 的 ByteBuf,按照上述算法,就需要为每个小 ByteBuf 对象分配一个 Page,这就出现了很多内存碎片。Netty 通过再将 Page 细分的方式,解决这个问题。Netty 将请求的空间大小向上取最近的 16 的倍数(或 2 的幂),规整后小于 PageSize 的小 Buffer 可分为两类。
- 微型对象:规整后的大小为 16 的整倍数,如 16、32、48、……、496,一共 31 种大小。
- 小型对象:规整后的大小为 2 的幂,如 512、1024、2048、4096,一共 4 种大小。
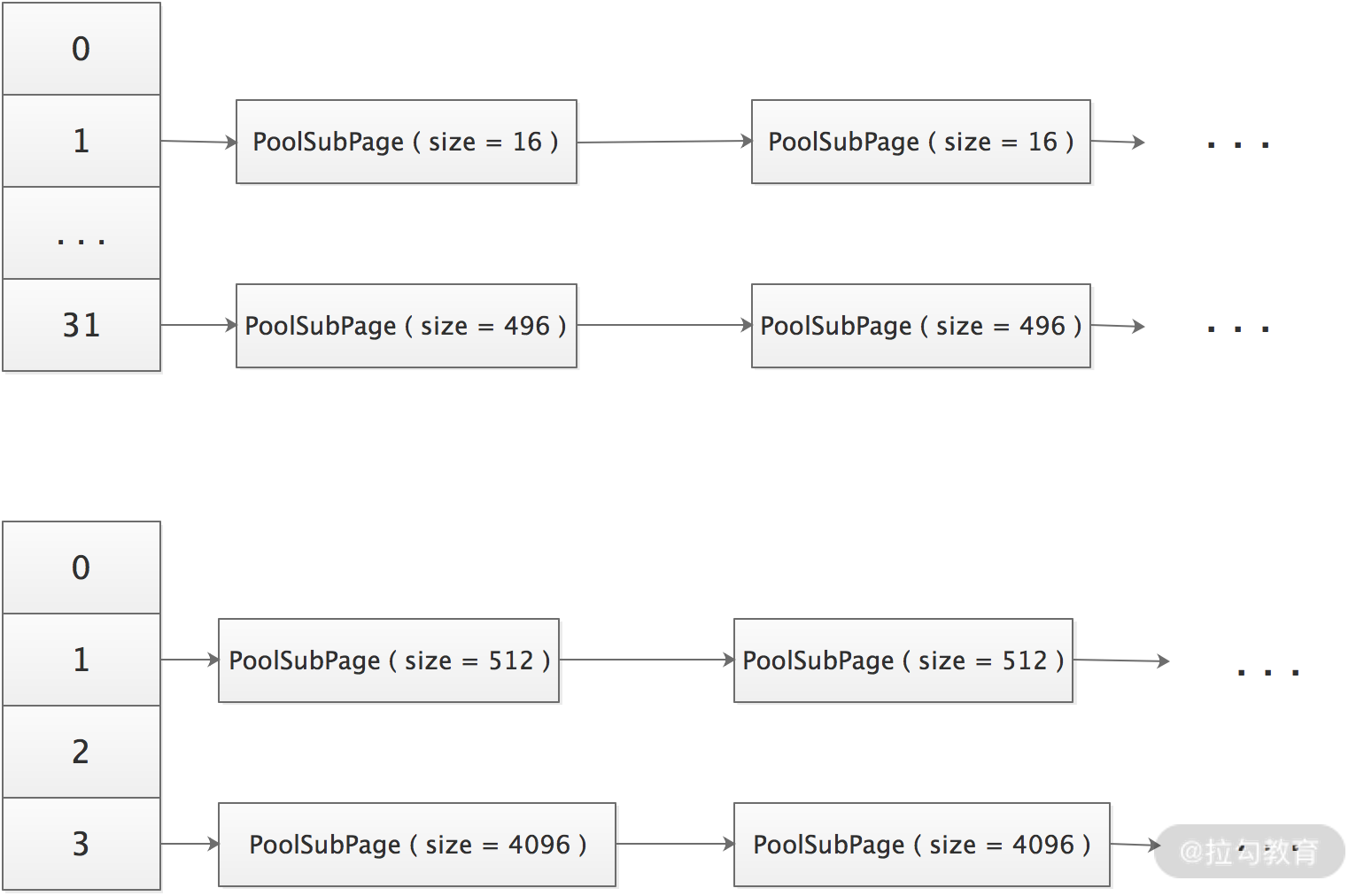
Netty 的实现会先从 PoolChunk 中申请空闲 Page,同一个 Page 分为相同大小的小 Buffer 进行存储;这些 Page 用 PoolSubpage 对象进行封装,PoolSubpage 内部会记录它自己能分配的小 Buffer 的规格大小、可用内存数量,并通过 bitmap 的方式记录各个小内存的使用情况(如下图所示)。虽然这种方案不能完美消灭内存碎片,但是很大程度上还是减少了内存浪费。
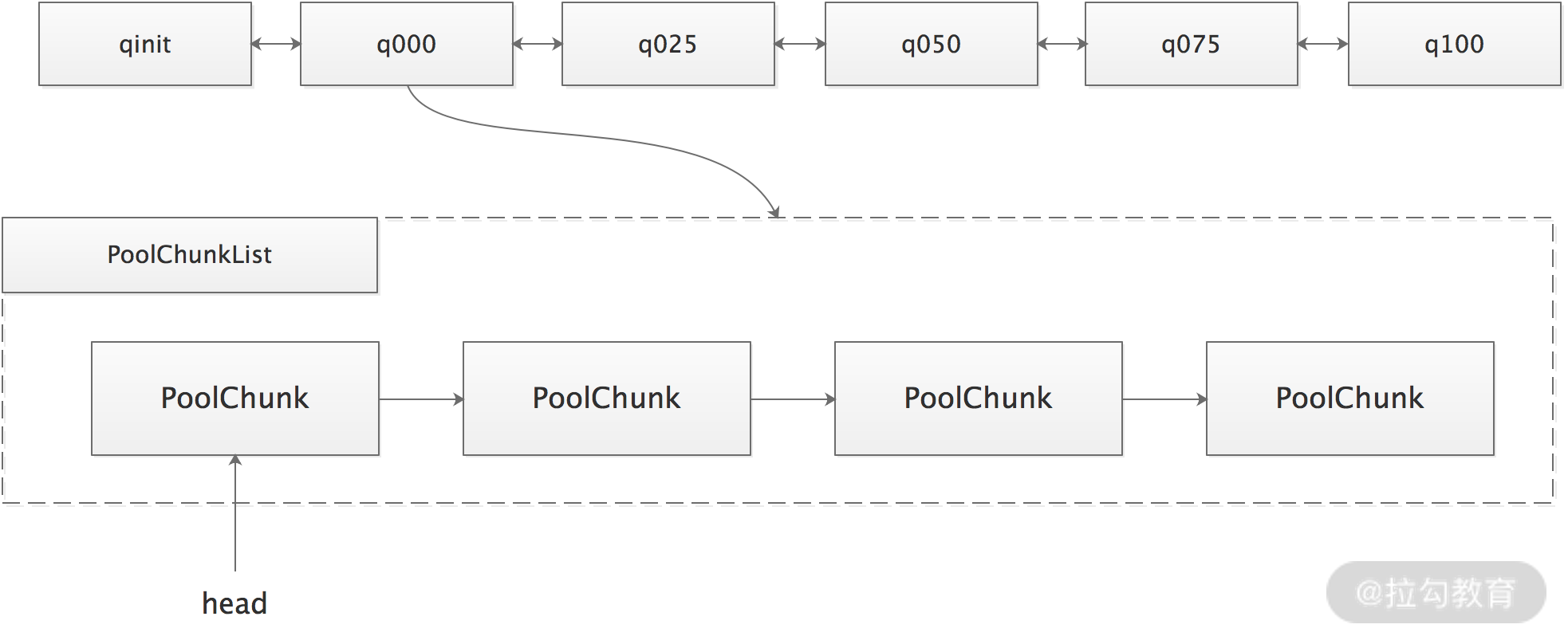
为了解决单个 PoolChunk 容量有限的问题,Netty 将多个 PoolChunk 组成链表一起管理,然后用 PoolChunkList 对象持有链表的 head。
Netty 通过 PoolArena 管理 PoolChunkList 以及 PoolSubpage。
PoolArena 内部持有 6 个 PoolChunkList,各个 PoolChunkList 持有的 PoolChunk 的使用率区间有所不同,如下图所示:
6 个 PoolChunkList 对象组成双向链表,当 PoolChunk 内存分配、释放,导致使用率变化,需要判断 PoolChunk 是否超过所在 PoolChunkList 的限定使用率范围,如果超出了,需要沿着 6 个 PoolChunkList 的双向链表找到新的合适的 PoolChunkList ,成为新的 head。同样,当新建 PoolChunk 分配内存或释放空间时,PoolChunk 也需要按照上面逻辑放入合适的PoolChunkList 中。
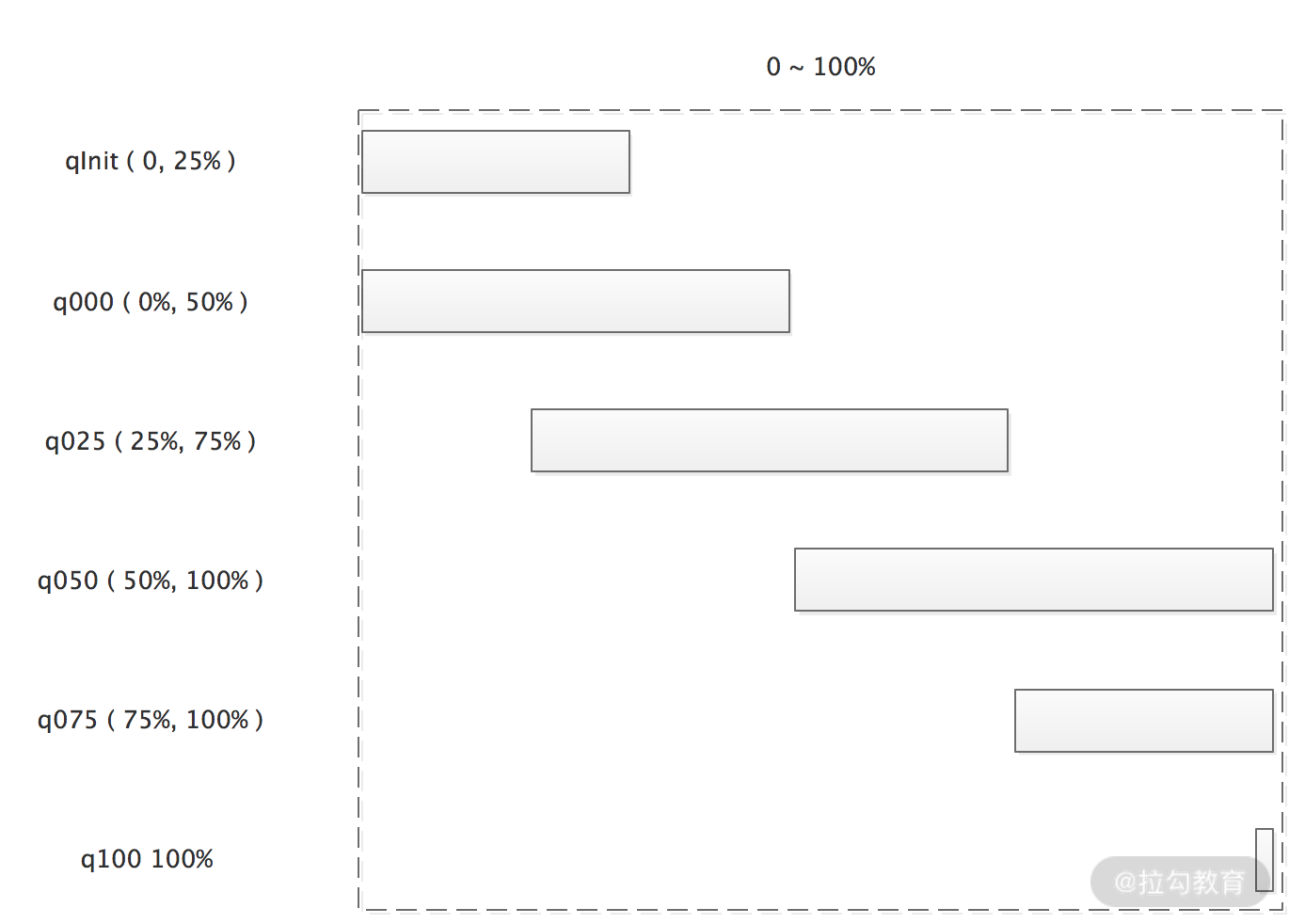
从上图可以看出,这 6 个 PoolChunkList 额定使用率区间存在交叉,这样设计的原因是:如果使用单个临界值的话,当一个 PoolChunk 被来回申请和释放,内存使用率会在临界值上下徘徊,这就会导致它在两个 PoolChunkList 链表中来回移动。
PoolArena 内部持有 2 个 PoolSubpage 数组,分别存储微型 Buffer 和小型 Buffer 的PoolSubpage。相同大小的 PoolSubpage 组成链表,不同大小的 PoolSubpage 链表的 head 节点保存在 tinySubpagePools 或者 smallSubpagePools 数组中,如下图:
3. 并发处理
内存分配释放不可避免地会遇到多线程并发场景,PoolChunk 的完全平衡树标记以及 PoolSubpage 的 bitmap 标记都是多线程不安全的,都是需要加锁同步的。为了减少线程间的竞争,Netty 会提前创建多个 PoolArena(默认数量为 2 * CPU 核心数),当线程首次请求池化内存分配,会找被最少线程持有的 PoolArena,并保存线程局部变量 PoolThreadCache 中,实现线程与 PoolArena 的关联绑定。
Netty 还提供了延迟释放的功能,来提升并发性能。当内存释放时,PoolArena 并没有马上释放,而是先尝试将该内存关联的 PoolChunk 和 Chunk 中的偏移位置等信息存入 ThreadLocal 的固定大小缓存队列中,如果该缓存队列满了,则马上释放内存。当有新的分配请求时,PoolArena 会优先访问线程本地的缓存队列,查询是否有缓存可用,如果有,则直接分配,提高分配效率。
总结
在本课时,我们主要介绍了 Netty 核心组件的功能和原理:
- 首先介绍了 Channel、ChannelFuture、Selector 等组件,它们是构成 I/O 多路复用的核心。
- 之后介绍了 EventLoop、EventLoopGroup 等组件,它们与 Netty 使用的主从 Reactor 线程模型息息相关。
- 最后深入介绍了 Netty 的内存管理,主要从内存分配管理、内存碎片优化以及并发分配内存等角度进行了介绍。
那你还知道哪些优秀的网络库或网络层设计呢?
11 简易版RPC 框架实现(上)
我们将会运用前面介绍的基础知识来做一个实践项目 —— 编写一个简易版本的 RPC 框架,作为“基础知识”部分的总结和回顾。
RPC 是“远程过程调用(Remote Procedure Call)”的缩写形式,比较通俗的解释是:像本地方法调用一样调用远程的服务。虽然 RPC 的定义非常简单,但是相对完整的、通用的 RPC 框架涉及很多方面的内容,例如注册发现、服务治理、负载均衡、集群容错、RPC 协议等,如下图所示:
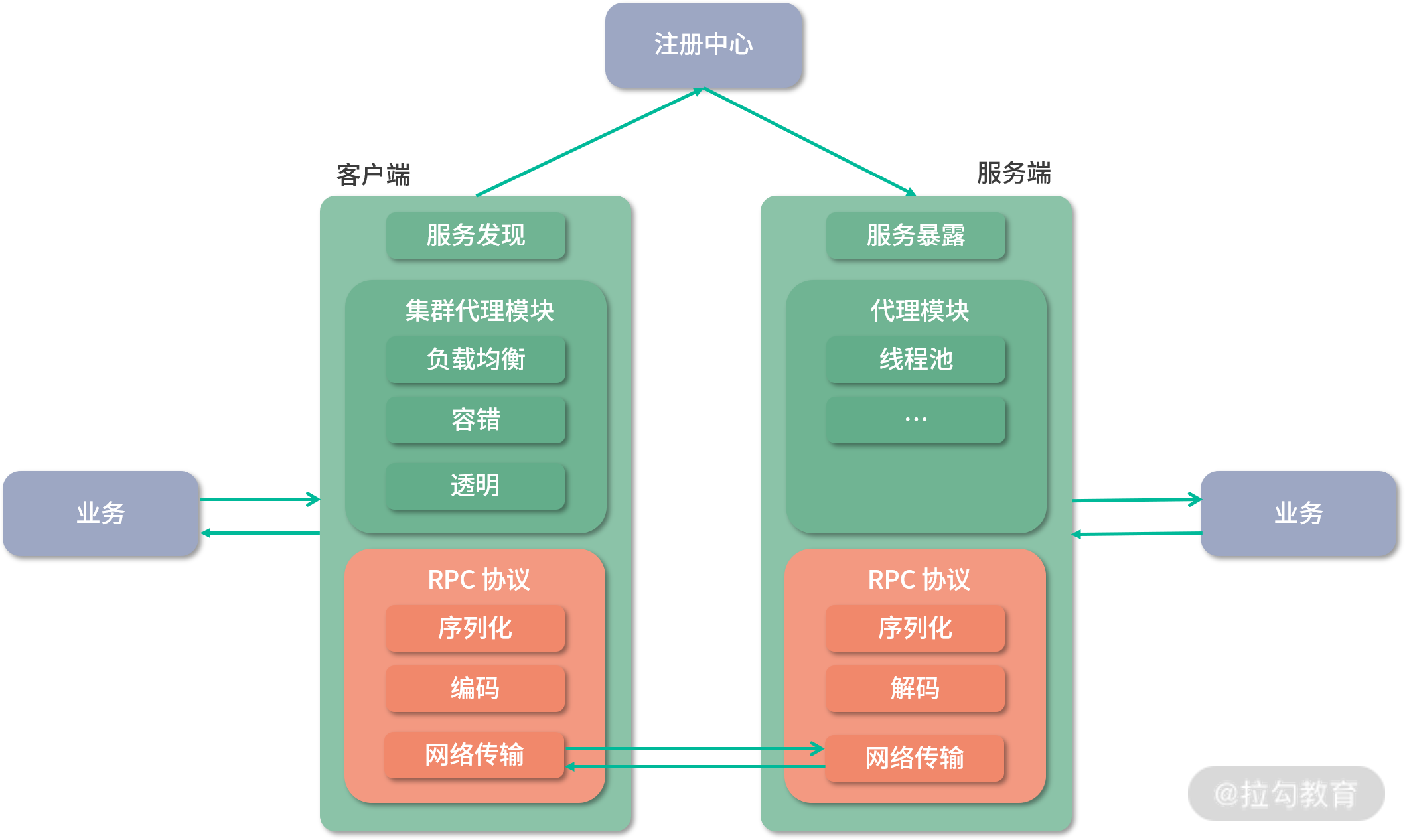
简易 RPC 框架的架构图
本课时我们主要实现RPC 框架的基石部分——远程调用,简易版 RPC 框架一次远程调用的核心流程是这样的:
- Client 首先会调用本地的代理,也就是图中的 Proxy。
- Client 端 Proxy 会按照协议(Protocol),将调用中传入的数据序列化成字节流。
- 之后 Client 会通过网络,将字节数据发送到 Server 端。
- Server 端接收到字节数据之后,会按照协议进行反序列化,得到相应的请求信息。
- Server 端 Proxy 会根据序列化后的请求信息,调用相应的业务逻辑。
- Server 端业务逻辑的返回值,也会按照上述逻辑返回给 Client 端。
这个远程调用的过程,就是我们简易版本 RPC 框架的核心实现,只有理解了这个流程,才能进行后续的开发。
项目结构
了解了简易版 RPC 框架的工作流程和实现目标之后,我们再来看下项目的结构,为了方便起见,这里我们将整个项目放到了一个 Module 中了,如下图所示,你可以按照自己的需求进行模块划分。
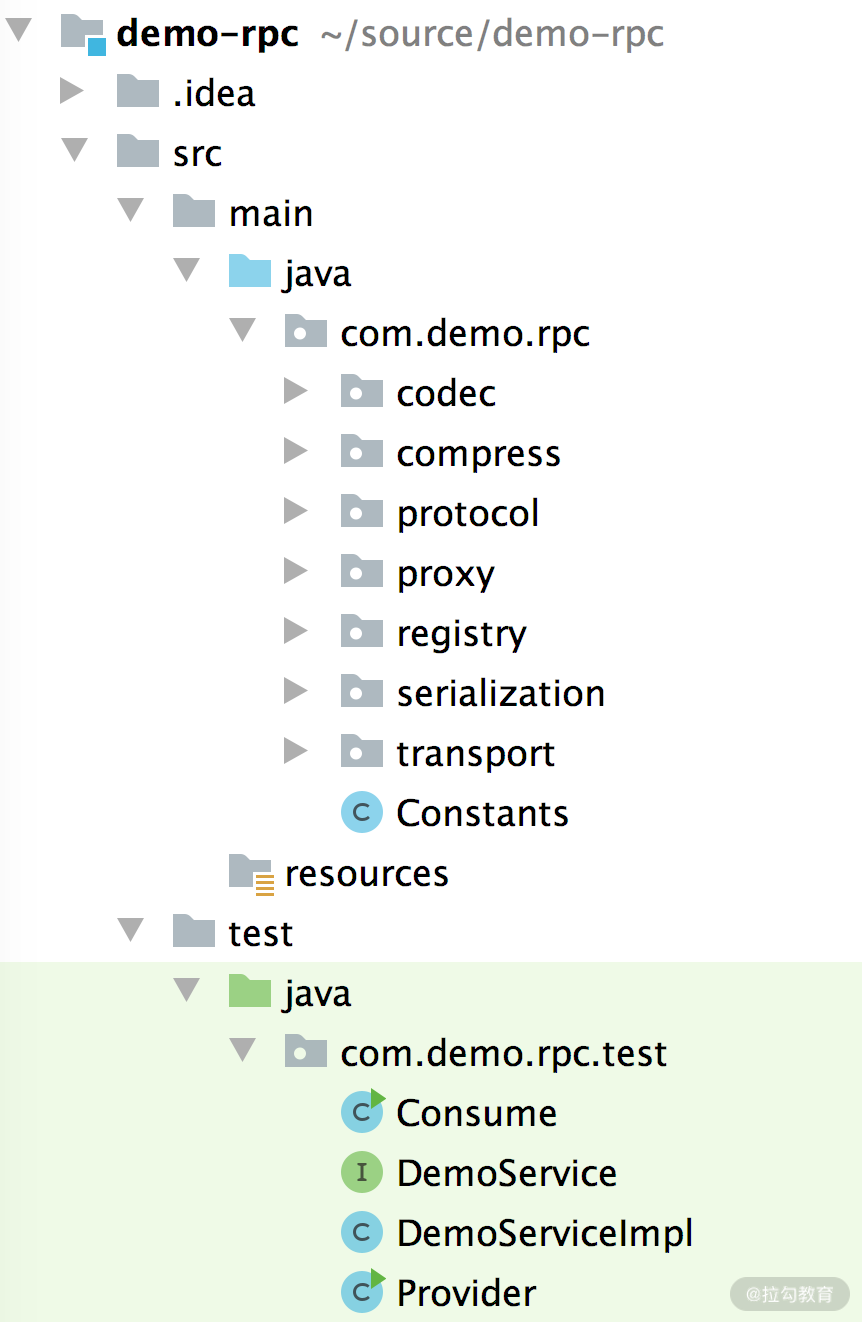
那这各个包的功能是怎样的呢?我们就来一一说明。
- protocol:简易版 RPC 框架的自定义协议。
- serialization:提供了自定义协议对应的序列化、反序列化的相关工具类。
- codec:提供了自定义协议对应的编码器和解码器。
- transport:基于 Netty 提供了底层网络通信的功能,其中会使用到 codec 包中定义编码器和解码器,以及 serialization 包中的序列化器和反序列化器。
- registry:基于 ZooKeeper 和 Curator 实现了简易版本的注册中心功能。
- proxy:使用 JDK 动态代理实现了一层代理。
自定义协议
当前已经有很多成熟的协议了,例如 HTTP、HTTPS 等,那为什么我们还要自定义 RPC 协议呢?
从功能角度考虑,HTTP 协议在 1.X 时代,只支持半双工传输模式,虽然支持长连接,但是不支持服务端主动推送数据。从效率角度来看,在一次简单的远程调用中,只需要传递方法名和加个简单的参数,此时,HTTP 请求中大部分数据都被 HTTP Header 占据,真正的有效负载非常少,效率就比较低。
当然,HTTP 协议也有自己的优势,例如,天然穿透防火墙,大量的框架和开源软件支持 HTTP 接口,而且配合 REST 规范使用也是很便捷的,所以有很多 RPC 框架直接使用 HTTP 协议,尤其是在 HTTP 2.0 之后,如 gRPC、Spring Cloud 等。
这里我们自定义一个简易版的 Demo RPC 协议,如下图所示:

在 Demo RPC 的消息头中,包含了整个 RPC 消息的一些控制信息,例如,版本号、魔数、消息类型、附加信息、消息 ID 以及消息体的长度,在附加信息(extraInfo)中,按位进行划分,分别定义消息的类型、序列化方式、压缩方式以及请求类型。当然,你也可以自己扩充 Demo RPC 协议,实现更加复杂的功能。
Demo RPC 消息头对应的实体类是 Header,其定义如下:
public class Header {private short magic; // 魔数private byte version; // 协议版本private byte extraInfo; // 附加信息private Long messageId; // 消息IDprivate Integer size; // 消息体长度... // 省略getter/setter方法
}
确定了 Demo RPC 协议消息头的结构之后,我们再来看 Demo RPC 协议消息体由哪些字段构成,这里我们通过 Request 和 Response 两个实体类来表示请求消息和响应消息的消息体:
public class Request implements Serializable {private String serviceName; // 请求的Service类名private String methodName; // 请求的方法名称private Class[] argTypes; // 请求方法的参数类型private Object[] args; // 请求方法的参数... // 省略getter/setter方法
}public class Response implements Serializable {private int code = 0; // 响应的错误码,正常响应为0,非0表示异常响应private String errMsg; // 异常信息private Object result; // 响应结果... // 省略getter/setter方法
}
注意,Request 和 Response 对象是要进行序列化的,需要实现 Serializable 接口。为了让这两个类的对象能够在 Client 和 Server 之间跨进程传输,需要进行序列化和反序列化操作,这里定义一个 Serialization 接口,统一完成序列化相关的操作:
public interface Serialization {<T> byte[] serialize(T obj)throws IOException;<T> T deSerialize(byte[] data, Class<T> clz)throws IOException;
}
在 Demo RPC 中默认使用 Hessian 序列化方式,下面的 HessianSerialization 就是基于 Hessian 序列化方式对 Serialization 接口的实现:
public class HessianSerialization implements Serialization {public <T> byte[] serialize(T obj) throws IOException {ByteArrayOutputStream os = new ByteArrayOutputStream();HessianOutput hessianOutput = new HessianOutput(os);hessianOutput.writeObject(obj);return os.toByteArray();}public <T> T deSerialize(byte[] data, Class<T> clazz) throws IOException {ByteArrayInputStream is = new ByteArrayInputStream(data);HessianInput hessianInput = new HessianInput(is);return (T) hessianInput.readObject(clazz);}
}
在有的场景中,请求或响应传输的数据比较大,直接传输比较消耗带宽,所以一般会采用压缩后再发送的方式。在前面介绍的 Demo RPC 消息头中的 extraInfo 字段中,就包含了标识消息体压缩方式的 bit 位。这里我们定义一个 Compressor 接口抽象所有压缩算法:
public interface Compressor {byte[] compress(byte[] array) throws IOException;byte[] unCompress(byte[] array) throws IOException;
}
同时提供了一个基于 Snappy 压缩算法的实现,作为 Demo RPC 的默认压缩算法:
public class SnappyCompressor implements Compressor {public byte[] compress(byte[] array) throws IOException {if (array == null) { return null; }return Snappy.compress(array);}public byte[] unCompress(byte[] array) throws IOException {if (array == null) { return null; }return Snappy.uncompress(array);}
}
编解码实现
了解了自定义协议的结构之后,我们再来解决协议的编解码问题。
前面课时介绍 Netty 核心概念的时候我们提到过,Netty 每个 Channel 绑定一个 ChannelPipeline,并依赖 ChannelPipeline 中添加的 ChannelHandler 处理接收到(或要发送)的数据,其中就包括字节到消息(以及消息到字节)的转换。Netty 中提供了 ByteToMessageDecoder、 MessageToByteEncoder、MessageToMessageEncoder、MessageToMessageDecoder 等抽象类来实现 Message 与 ByteBuf 之间的转换以及 Message 之间的转换,如下图所示:
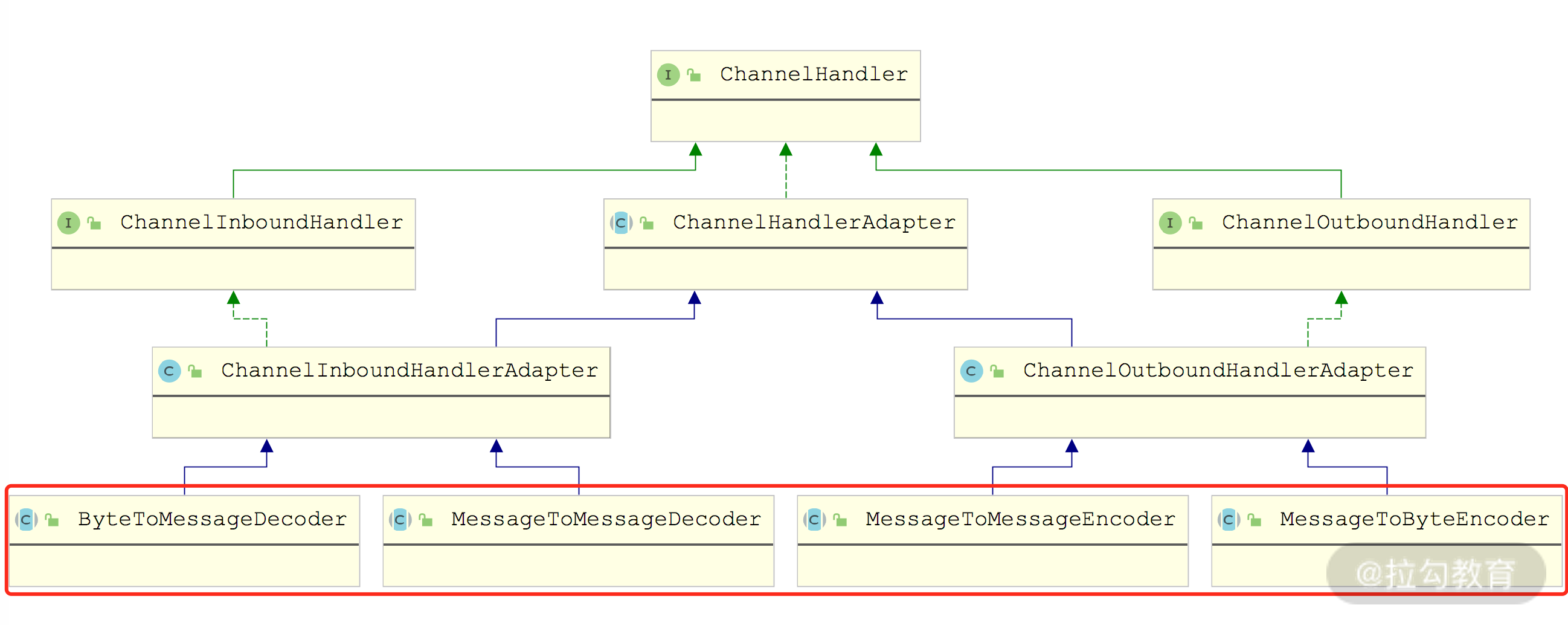
Netty 提供的 Decoder 和 Encoder 实现
在 Netty 的源码中,我们可以看到对很多已有协议的序列化和反序列化都是基于上述抽象类实现的,例如,HttpServerCodec 中通过依赖 HttpServerRequestDecoder 和 HttpServerResponseEncoder 来实现 HTTP 请求的解码和 HTTP 响应的编码。如下图所示,HttpServerRequestDecoder 继承自 ByteToMessageDecoder,实现了 ByteBuf 到 HTTP 请求之间的转换;HttpServerResponseEncoder 继承自 MessageToMessageEncoder,实现 HTTP 响应到其他消息的转换(其中包括转换成 ByteBuf 的能力)。
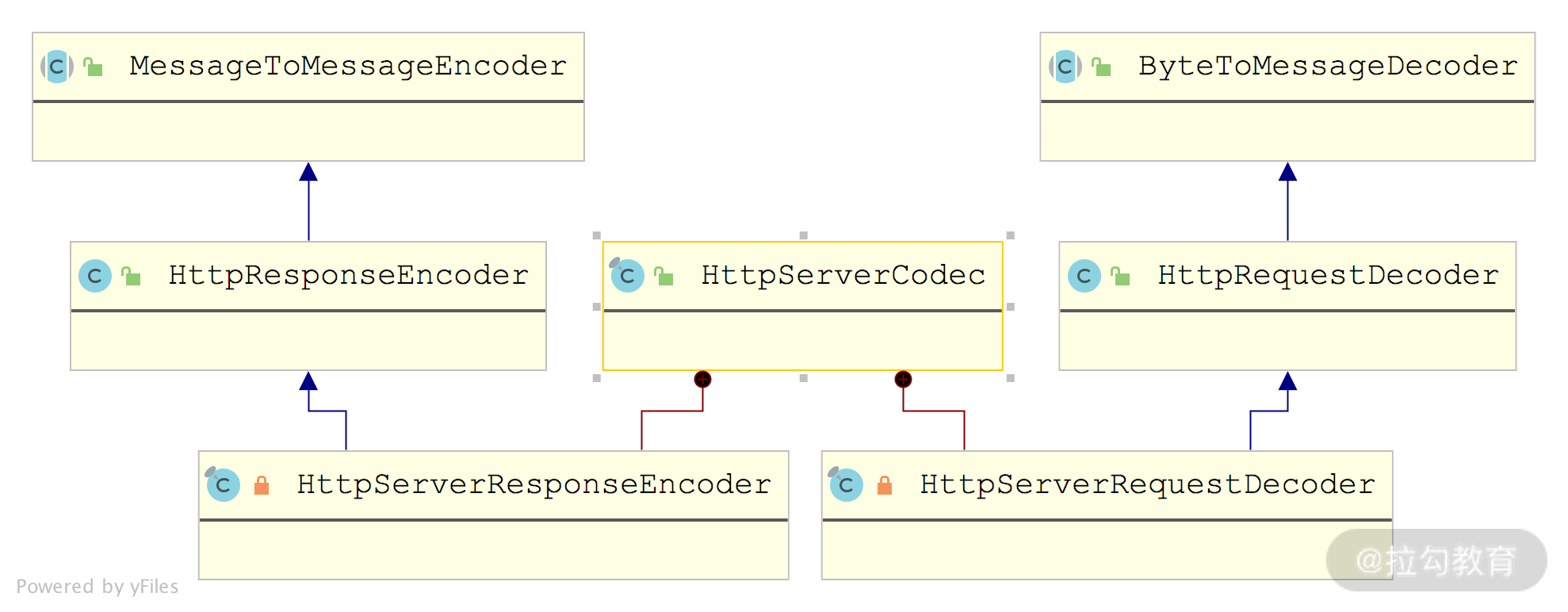
Netty 中 HTTP 协议的 Decoder 和 Encoder 实现
在简易版 RPC 框架中,我们的自定义请求暂时没有 HTTP 协议那么复杂,只要简单继承 ByteToMessageDecoder 和 MessageToMessageEncoder 即可。
首先来看 DemoRpcDecoder,它实现了 ByteBuf 到 Demo RPC Message 的转换,具体实现如下:
public class DemoRpcDecoder extends ByteToMessageDecoder {protected void decode(ChannelHandlerContext ctx,ByteBuf byteBuf, List<Object> out) throws Exception {if (byteBuf.readableBytes() < Constants.HEADER_SIZE) {return; // 不到16字节的话无法解析消息头,暂不读取}// 记录当前readIndex指针的位置,方便重置byteBuf.markReaderIndex();// 尝试读取消息头的魔数部分short magic = byteBuf.readShort();if (magic != Constants.MAGIC) { // 魔数不匹配会抛出异常byteBuf.resetReaderIndex(); // 重置readIndex指针throw new RuntimeException("magic number error:" + magic);}// 依次读取消息版本、附加信息、消息ID以及消息体长度四部分byte version = byteBuf.readByte();byte extraInfo = byteBuf.readByte();long messageId = byteBuf.readLong();int size = byteBuf.readInt();Object request = null;// 心跳消息是没有消息体的,无须读取if (!Constants.isHeartBeat(extraInfo)) {// 对于非心跳消息,没有积累到足够的数据是无法进行反序列化的if (byteBuf.readableBytes() < size) {byteBuf.resetReaderIndex();return;}// 读取消息体并进行反序列化byte[] payload = new byte[size];byteBuf.readBytes(payload);// 这里根据消息头中的extraInfo部分选择相应的序列化和压缩方式Serialization serialization = SerializationFactory.get(extraInfo);Compressor compressor = CompressorFactory.get(extraInfo);// 经过解压缩和反序列化得到消息体request = serialization.deserialize(compressor.unCompress(payload), Request.class);}// 将上面读取到的消息头和消息体拼装成完整的Message并向后传递Header header = new Header(magic, version, extraInfo, messageId, size);Message message = new Message(header, request);out.add(message);}
}
接下来看 DemoRpcEncoder,它实现了 Demo RPC Message 到 ByteBuf 的转换,具体实现如下:
class DemoRpcEncoder extends MessageToByteEncoder<Message>{@Overrideprotected void encode(ChannelHandlerContext channelHandlerContext,Message message, ByteBuf byteBuf) throws Exception {Header header = message.getHeader();// 依次序列化消息头中的魔数、版本、附加信息以及消息IDbyteBuf.writeShort(header.getMagic());byteBuf.writeByte(header.getVersion());byteBuf.writeByte(header.getExtraInfo());byteBuf.writeLong(header.getMessageId());Object content = message.getContent();if (Constants.isHeartBeat(header.getExtraInfo())) {byteBuf.writeInt(0); // 心跳消息,没有消息体,这里写入0return;}// 按照extraInfo部分指定的序列化方式和压缩方式进行处理Serialization serialization = SerializationFactory.get(header.getExtraInfo());Compressor compressor = CompressorFactory.get(header.getExtraInfo());byte[] payload = compressor.compress(serialization.serialize(content));byteBuf.writeInt(payload.length); // 写入消息体长度byteBuf.writeBytes(payload); // 写入消息体}
}
总结
本课时我们首先介绍了简易 RPC 框架的基础架构以及其处理一次远程调用的基本流程,并对整个简易 RPC 框架项目的结构进行了简单介绍。接下来,我们讲解了简易 RPC 框架使用的自定义协议格式、序列化/反序列化方式以及压缩方式,这些都是远程数据传输不可或缺的基础。然后,我们又介绍了 Netty 中的编解码体系,以及 HTTP 协议相关的编解码器实现。最后,我们还分析了简易 RPC 协议对应的编解码器,即 DemoRpcEncoder 和 DemoRpcDecoder。
在下一课时,我们将自底向上,继续介绍简易 RPC 框架的剩余部分实现。
简易版 RPC 框架 Demo 的链接:https://github.com/xxxlxy2008/demo-prc 。
12 简易版RPC 框架实现(下)
在上一课时中,我们介绍了整个简易 RPC 框架项目的结构和工作原理,并且介绍了简易 RPC 框架底层的协议结构、序列化/反序列化实现、压缩实现以及编解码器的具体实现。本课时我们将继续自底向上,介绍简易 RPC 框架的剩余部分实现。
transport 相关实现
正如前文介绍 Netty 线程模型的时候提到,我们不能在 Netty 的 I/O 线程中执行耗时的业务逻辑。在 Demo RPC 框架的 Server 端接收到请求时,首先会通过上面介绍的 DemoRpcDecoder 反序列化得到请求消息,之后我们会通过一个自定义的 ChannelHandler(DemoRpcServerHandler)将请求提交给业务线程池进行处理。
在 Demo RPC 框架的 Client 端接收到响应消息的时候,也是先通过 DemoRpcDecoder 反序列化得到响应消息,之后通过一个自定义的 ChannelHandler(DemoRpcClientHandler)将响应返回给上层业务。
DemoRpcServerHandler 和 DemoRpcClientHandler 都继承自 SimpleChannelInboundHandler,如下图所示:
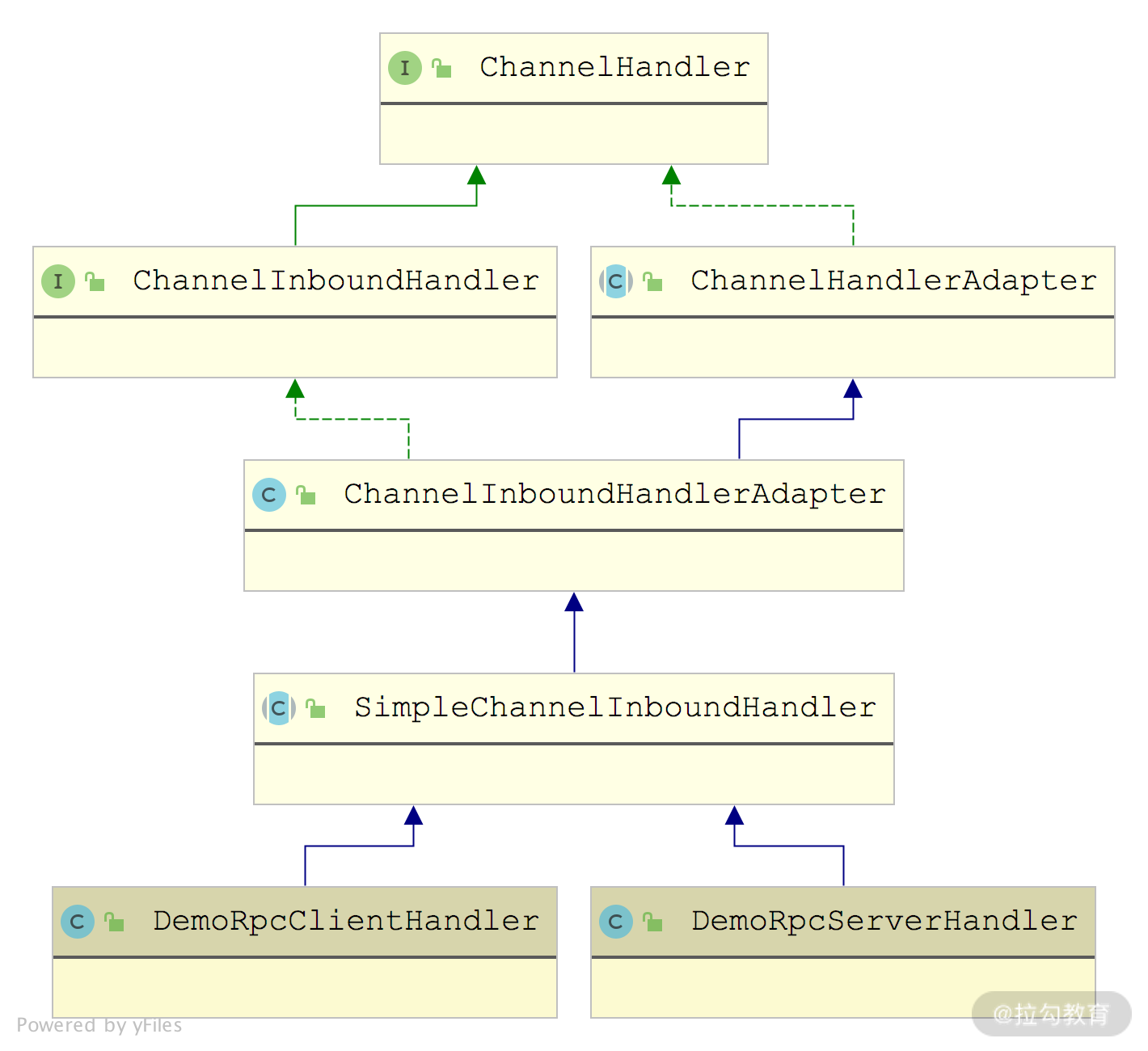
DemoRpcClientHandler 和 DemoRpcServerHandler 的继承关系图
下面我们就来看一下这两个自定义的 ChannelHandler 实现:
public class DemoRpcServerHandler extends SimpleChannelInboundHandler<Message<Request>> {// 业务线程池static Executor executor = Executors.newCachedThreadPool();protected void channelRead0(final ChannelHandlerContext ctx, Message<Request> message) throws Exception {byte extraInfo = message.getHeader().getExtraInfo();if (Constants.isHeartBeat(extraInfo)) { // 心跳消息,直接返回即可channelHandlerContext.writeAndFlush(message);return;}// 非心跳消息,直接封装成Runnable提交到业务线程executor.execute(new InvokeRunnable(message, cxt));}
}public class DemoRpcClientHandler extends SimpleChannelInboundHandler<Message<Response>> {protected void channelRead0(ChannelHandlerContext ctx, Message<Response> message) throws Exception {NettyResponseFuture responseFuture = Connection.IN_FLIGHT_REQUEST_MAP.remove(message.getHeader().getMessageId());Response response = message.getContent();// 心跳消息特殊处理if (response == null && Constants.isHeartBeat(message.getHeader().getExtraInfo())) {response = new Response();response.setCode(Constants.HEARTBEAT_CODE);}responseFuture.getPromise().setSuccess(response);}
}
注意,这里有两个点需要特别说明一下。一个点是 Server 端的 InvokeRunnable,在这个 Runnable 任务中会根据请求的 serviceName、methodName 以及参数信息,调用相应的方法:
class InvokeRunnable implements Runnable {private ChannelHandlerContext ctx;private Message<Request> message;public void run() {Response response = new Response();Object result = null;try {Request request = message.getContent();String serviceName = request.getServiceName();// 这里提供BeanManager对所有业务Bean进行管理,其底层在内存中维护了// 一个业务Bean实例的集合。感兴趣的同学可以尝试接入Spring等容器管// 理业务BeanObject bean = BeanManager.getBean(serviceName);// 下面通过反射调用Bean中的相应方法Method method = bean.getClass().getMethod(request.getMethodName(), request.getArgTypes());result = method.invoke(bean, request.getArgs());} catch (Exception e) { // 省略异常处理} finally {}response.setResult(result); // 设置响应结果// 将响应消息返回给客户端ctx.writeAndFlush(new Message(message.getHeader(), response));}
}
另一个点是 Client 端的 Connection,它是用来暂存已发送出去但未得到响应的请求,这样,在响应返回时,就可以查找到相应的请求以及 Future,从而将响应结果返回给上层业务逻辑,具体实现如下:
public class Connection implements Closeable {private static AtomicLong ID_GENERATOR = new AtomicLong(0);public static Map<Long, NettyResponseFuture<Response>> IN_FLIGHT_REQUEST_MAP = new ConcurrentHashMap<>();private ChannelFuture future;private AtomicBoolean isConnected = new AtomicBoolean();public Connection(ChannelFuture future, boolean isConnected) {this.future = future;this.isConnected.set(isConnected);}public NettyResponseFuture<Response> request(Message<Request> message, long timeOut) {// 生成并设置消息IDlong messageId = ID_GENERATOR.incrementAndGet();message.getHeader().setMessageId(messageId);// 创建消息关联的FutureNettyResponseFuture responseFuture = new NettyResponseFuture(System.currentTimeMillis(),timeOut, message, future.channel(), new DefaultPromise(new DefaultEventLoop()));// 将消息ID和关联的Future记录到IN_FLIGHT_REQUEST_MAP集合中IN_FLIGHT_REQUEST_MAP.put(messageId, responseFuture);try {future.channel().writeAndFlush(message); // 发送请求} catch (Exception e) {// 发送请求异常时,删除对应的FutureIN_FLIGHT_REQUEST_MAP.remove(messageId);throw e;}return responseFuture;}// 省略getter/setter以及close()方法
}
我们可以看到,Connection 中没有定时清理 IN_FLIGHT_REQUEST_MAP 集合的操作,在无法正常获取响应的时候,就会导致 IN_FLIGHT_REQUEST_MAP 不断膨胀,最终 OOM。你也可以添加一个时间轮定时器,定时清理过期的请求消息,这里我们就不再展开讲述了。
完成自定义 ChannelHandler 的编写之后,我们需要再定义两个类—— DemoRpcClient 和 DemoRpcServer,分别作为 Client 和 Server 的启动入口。DemoRpcClient 的实现如下:
public class DemoRpcClient implements Closeable {protected Bootstrap clientBootstrap;protected EventLoopGroup group;private String host;private int port;public DemoRpcClient(String host, int port) throws Exception {this.host = host;this.port = port;clientBootstrap = new Bootstrap();// 创建并配置客户端Bootstrapgroup = NettyEventLoopFactory.eventLoopGroup(Constants.DEFAULT_IO_THREADS, "NettyClientWorker");clientBootstrap.group(group).option(ChannelOption.TCP_NODELAY, true).option(ChannelOption.SO_KEEPALIVE, true).channel(NioSocketChannel.class)// 指定ChannelHandler的顺序.handler(new ChannelInitializer<SocketChannel>() {protected void initChannel(SocketChannel ch) {ch.pipeline().addLast("demo-rpc-encoder", new DemoRpcEncoder());ch.pipeline().addLast("demo-rpc-decoder", new DemoRpcDecoder());ch.pipeline().addLast("client-handler", new DemoRpcClientHandler());}});}public ChannelFuture connect() { // 连接指定的地址和端口ChannelFuture connect = clientBootstrap.connect(host, port);connect.awaitUninterruptibly();return connect;}public void close() {group.shutdownGracefully();}
}
通过 DemoRpcClient 的代码我们可以看到其 ChannelHandler 的执行顺序如下:
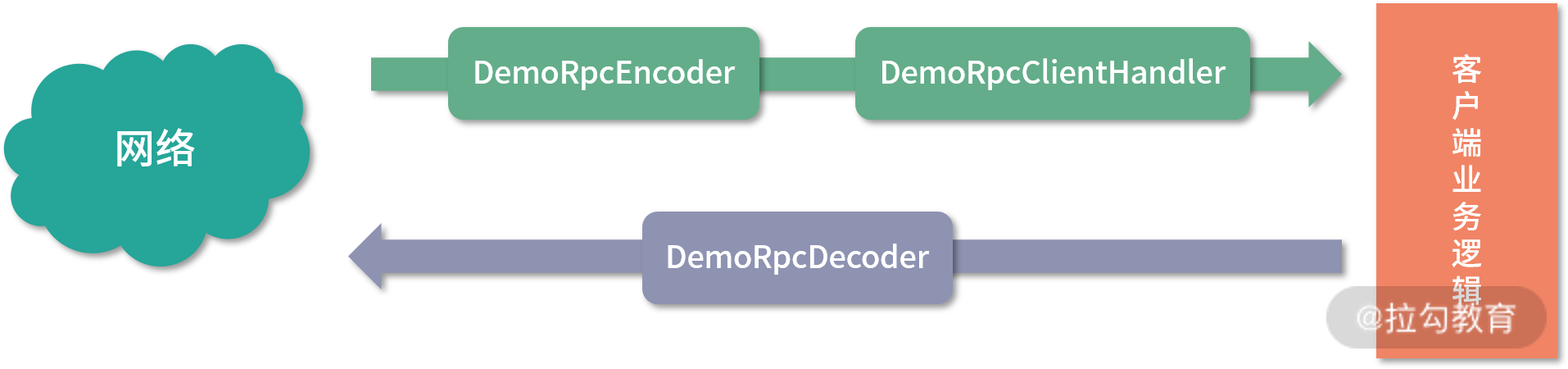
客户端 ChannelHandler 结构图
另外,在创建EventLoopGroup时并没有直接使用NioEventLoopGroup,而是在 NettyEventLoopFactory 中根据当前操作系统进行选择,对于 Linux 系统,会使用 EpollEventLoopGroup,其他系统则使用 NioEventLoopGroup。
接下来我们再看DemoRpcServer 的具体实现:
public class DemoRpcServer {private EventLoopGroup bossGroup;private EventLoopGroup workerGroup;private ServerBootstrap serverBootstrap;private Channel channel;protected int port;public DemoRpcServer(int port) throws InterruptedException {this.port = port;// 创建boss和worker两个EventLoopGroup,注意一些小细节, // workerGroup 是按照中的线程数是按照 CPU 核数计算得到的,bossGroup = NettyEventLoopFactory.eventLoopGroup(1, "boos");workerGroup = NettyEventLoopFactory.eventLoopGroup( Math.min(Runtime.getRuntime().availableProcessors() + 1,32), "worker");serverBootstrap = new ServerBootstrap().group(bossGroup, workerGroup).channel(NioServerSocketChannel.class).option(ChannelOption.SO_REUSEADDR, Boolean.TRUE).childOption(ChannelOption.TCP_NODELAY, Boolean.TRUE).handler(new LoggingHandler(LogLevel.INFO)).childHandler(new ChannelInitializer<SocketChannel>(){ // 指定每个Channel上注册的ChannelHandler以及顺序protected void initChannel(SocketChannel ch) {ch.pipeline().addLast("demp-rpc-decoder", new DemoRpcDecoder());ch.pipeline().addLast("demo-rpc-encoder", new DemoRpcEncoder());ch.pipeline().addLast("server-handler", new DemoRpcServerHandler());}});}public ChannelFuture start() throws InterruptedException {ChannelFuture channelFuture = serverBootstrap.bind(port);channel = channelFuture.channel();channel.closeFuture();return channelFuture;}
}
通过对 DemoRpcServer 实现的分析,我们可以知道每个 Channel 上的 ChannelHandler 顺序如下:

服务端 ChannelHandler 结构图
registry 相关实现
介绍完客户端和服务端的通信之后,我们再来看简易 RPC 框架的另一个基础能力——服务注册与服务发现能力,对应 demo-rpc 项目源码中的 registry 包。
registry 包主要是依赖 Apache Curator 实现了一个简易版本的 ZooKeeper 客户端,并基于 ZooKeeper 实现了注册中心最基本的两个功能:Provider 注册以及 Consumer 订阅。
这里我们先定义一个 Registry 接口,其中提供了注册以及查询服务实例的方法,如下图所示:

ZooKeeperRegistry 是基于 curator-x-discovery 对 Registry 接口的实现类型,其中封装了之前课时介绍的 ServiceDiscovery,并在其上添加了 ServiceCache 缓存提高查询效率。ZooKeeperRegistry 的具体实现如下:
public class ZookeeperRegistry<T> implements Registry<T> {private InstanceSerializer serializer = new JsonInstanceSerializer<>(ServerInfo.class);private ServiceDiscovery<T> serviceDiscovery;private ServiceCache<T> serviceCache;private String address = "localhost:2181";public void start() throws Exception {String root = "/demo/rpc";// 初始化CuratorFrameworkCuratorFramework client = CuratorFrameworkFactory.newClient(address, new ExponentialBackoffRetry(1000, 3));client.start(); // 启动Curator客户端client.blockUntilConnected(); // 阻塞当前线程,等待连接成client.createContainers(root);// 初始化ServiceDiscoveryserviceDiscovery = ServiceDiscoveryBuilder.builder(ServerInfo.class).client(client).basePath(root).serializer(serializer).build();serviceDiscovery.start(); // 启动ServiceDiscovery// 创建ServiceCache,监Zookeeper相应节点的变化,也方便后续的读取serviceCache = serviceDiscovery.serviceCacheBuilder().name(root).build();serviceCache.start(); // 启动ServiceCache}@Overridepublic void registerService(ServiceInstance<T> service)throws Exception {serviceDiscovery.registerService(service);}@Overridepublic void unregisterService(ServiceInstance service) throws Exception {serviceDiscovery.unregisterService(service);}@Overridepublic List<ServiceInstance<T>> queryForInstances(String name) throws Exception {// 直接根据name进行过滤ServiceCache中的缓存数据 return serviceCache.getInstances().stream().filter(s -> s.getName().equals(name)).collect(Collectors.toList());}
}
通过对 ZooKeeperRegistry的分析可以得知,它是基于 Curator 中的 ServiceDiscovery 组件与 ZooKeeper 进行交互的,并且对 Registry 接口的实现也是通过直接调用 ServiceDiscovery 的相关方法实现的。在查询时,直接读取 ServiceCache 中的缓存数据,ServiceCache 底层在本地维护了一个 ConcurrentHashMap 缓存,通过 PathChildrenCache 监听 ZooKeeper 中各个子节点的变化,同步更新本地缓存。这里我们简单看一下 ServiceCache 的核心实现:
public class ServiceCacheImpl<T> implements ServiceCache<T>, PathChildrenCacheListener{//实现PathChildrenCacheListener接口// 关联的ServiceDiscovery实例private final ServiceDiscoveryImpl<T> discovery;// 底层的PathChildrenCache,用于监听子节点的变化private final PathChildrenCache cache; // 本地缓存private final ConcurrentMap<String, ServiceInstance<T>> instances = Maps.newConcurrentMap();public List<ServiceInstance<T>> getInstances(){ // 返回本地缓存内容return Lists.newArrayList(instances.values());}public void childEvent(CuratorFramework client, PathChildrenCacheEvent event) throws Exception{switch(event.getType()){case CHILD_ADDED:case CHILD_UPDATED:{addInstance(event.getData(), false); // 更新本地缓存notifyListeners = true;break;}case CHILD_REMOVED:{ // 更新本地缓存instances.remove(instanceIdFromData(event.getData()));notifyListeners = true;break;}}... // 通知ServiceCache上注册的监听器}
}
proxy 相关实现
在简易版 Demo RPC 框架中,Proxy 主要是为 Client 端创建一个代理,帮助客户端程序屏蔽底层的网络操作以及与注册中心之间的交互。
简易版 Demo RPC 使用 JDK 动态代理的方式生成代理,这里需要编写一个 InvocationHandler 接口的实现,即下面的 DemoRpcProxy。其中有两个核心方法:一个是 newInstance() 方法,用于生成代理对象;另一个是 invoke() 方法,当调用目标对象的时候,会执行 invoke() 方法中的代理逻辑。
下面是 DemoRpcProxy 的具体实现:
public class DemoRpcProxy implements InvocationHandler {// 需要代理的服务(接口)名称private String serviceName;// 用于与Zookeeper交互,其中自带缓存private Registry<ServerInfo> registry;public DemoRpcProxy(String serviceName, Registry<ServerInfo> registry) throws Exception { // 初始化上述两个字段this.serviceName = serviceName;this.registry = registry;}public static <T> T newInstance(Class<T> clazz, Registry<ServerInfo> registry) throws Exception {// 创建代理对象return (T) Proxy.newProxyInstance(Thread.currentThread().getContextClassLoader(), new Class[]{clazz},new DemoRpcProxy(clazz.getName(), registry));}@Overridepublic Object invoke(Object proxy, Method method, Object[] args)throws Throwable {// 从Zookeeper缓存中获取可用的Server地址,并随机从中选择一个List<ServiceInstance<ServerInfo>> serviceInstances = registry.queryForInstances(serviceName);ServiceInstance<ServerInfo> serviceInstance = serviceInstances.get(ThreadLocalRandom.current().nextInt(serviceInstances.size()));// 创建请求消息,然后调用remoteCall()方法请求上面选定的Server端String methodName = method.getName();Header header =new Header(MAGIC, VERSION_1...);Message<Request> message = new Message(header, new Request(serviceName, methodName, args));return remoteCall(serviceInstance.getPayload(), message);}protected Object remoteCall(ServerInfo serverInfo, Message message) throws Exception {if (serverInfo == null) {throw new RuntimeException("get available server error");}// 创建DemoRpcClient连接指定的Server端DemoRpcClient demoRpcClient = new DemoRpcClient(serverInfo.getHost(), serverInfo.getPort());ChannelFuture channelFuture = demoRpcClient.connect().awaitUninterruptibly();// 创建对应的Connection对象,并发送请求Connection connection = new Connection(channelFuture, true);NettyResponseFuture responseFuture =connection.request(message, Constants.DEFAULT_TIMEOUT);// 等待请求对应的响应return responseFuture.getPromise().get(Constants.DEFAULT_TIMEOUT, TimeUnit.MILLISECONDS);}
}
从 DemoRpcProxy 的实现中我们可以看到,它依赖了 ServiceInstanceCache 获取ZooKeeper 中注册的 Server 端地址,同时依赖了 DemoRpcClient 与Server 端进行通信,上层调用方拿到这个代理对象后,就可以像调用本地方法一样进行调用,而不再关心底层网络通信和服务发现的细节。当然,这个简易版 DemoRpcProxy 的实现还有很多可以优化的地方,例如:
- 缓存 DemoRpcClient 客户端对象以及相应的 Connection 对象,不必每次进行创建。
- 可以添加失败重试机制,在请求出现超时的时候,进行重试。
- 可以添加更加复杂和灵活的负载均衡机制,例如,根据 Hash 值散列进行负载均衡、根据节点 load 情况进行负载均衡等。
你若感兴趣的话可以尝试进行扩展,以实现一个更加完善的代理层。
使用方接入
介绍完 Demo RPC 的核心实现之后,下面我们讲解下Demo RPC 框架的使用方式。这里涉及Consumer、DemoServiceImp、Provider三个类以及 DemoService 业务接口。
使用接入的相关类
首先,我们定义DemoService 接口作为业务 Server 接口,具体定义如下:
public interface DemoService {String sayHello(String param);
}
DemoServiceImpl对 DemoService 接口的实现也非常简单,如下所示,将参数做简单修改后返回:
public class DemoServiceImpl implements DemoService {public String sayHello(String param) {return "hello:" + param;}
}
了解完相应的业务接口和实现之后,我们再来看Provider的实现,它的角色类似于 Dubbo 中的 Provider,其会创建 DemoServiceImpl 这个业务 Bean 并将自身的地址信息暴露出去,如下所示:
public class Provider {public static void main(String[] args) throws Exception {// 创建DemoServiceImpl,并注册到BeanManager中BeanManager.registerBean("demoService", new DemoServiceImpl());// 创建ZookeeperRegistry,并将Provider的地址信息封装成ServerInfo// 对象注册到ZookeeperZookeeperRegistry<ServerInfo> discovery = new ZookeeperRegistry<>();discovery.start();ServerInfo serverInfo = new ServerInfo("127.0.0.1", 20880);discovery.registerService(ServiceInstance.<ServerInfo>builder().name("demoService").payload(serverInfo).build());// 启动DemoRpcServer,等待Client的请求DemoRpcServer rpcServer = new DemoRpcServer(20880);rpcServer.start();}
}
最后是Consumer,它类似于 Dubbo 中的 Consumer,其会订阅 Provider 地址信息,然后根据这些信息选择一个 Provider 建立连接,发送请求并得到响应,这些过程在 Proxy 中都予以了封装,那Consumer 的实现就很简单了,可参考如下示例代码:
public class Consumer {public static void main(String[] args) throws Exception {// 创建ZookeeperRegistr对象ZookeeperRegistry<ServerInfo> discovery = new ZookeeperRegistry<>();// 创建代理对象,通过代理调用远端ServerDemoService demoService = DemoRpcProxy.newInstance(DemoService.class, discovery);// 调用sayHello()方法,并输出结果String result = demoService.sayHello("hello");System.out.println(result);}
}
总结
本课时我们首先介绍了简易 RPC 框架中的transport 包,它在上一课时介绍的编解码器基础之上,实现了服务端和客户端的通信能力。之后讲解了registry 包如何实现与 ZooKeeper 的交互,完善了简易 RPC 框架的服务注册与服务发现的能力。接下来又分析了proxy 包的实现,其中通过 JDK 动态代理的方式,帮接入方屏蔽了底层网络通信的复杂性。最后,我们编写了一个简单的 DemoService 业务接口,以及相应的 Provider 和 Consumer 接入简易 RPC 框架。
在本课时最后,留给你一个小问题:在 transport 中创建 EventLoopGroup 的时候,为什么针对 Linux 系统使用的 EventLoopGroup会有所不同呢?
简易版 RPC 框架 Demo 的链接:https://github.com/xxxlxy2008/demo-prc 。