Spark小说数据分析与推荐系统 Hadoop 机器学习 爬虫 协同过滤推荐算法 Hive 大数据 毕业设计(源码+文档)✅
博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅点击查看作者主页,了解更多项目!
🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
2、最全计算机专业毕业设计选题大全(建议收藏)✅
1、项目介绍
技术栈:
Python语言、Spark、Hive、Hadoop、Django框架、Echarts可视化
基于用户协同过滤推荐算法、机器学习、requests爬虫技术、MySQL数据库
https://b.faloo.com/ (飞卢小说网)
Spark小说数据分析与推荐系统 Hadoop 机器学习 爬虫 协同过滤推荐算法 Hive 大数据 毕业设计
2、项目界面
(1)数据大屏
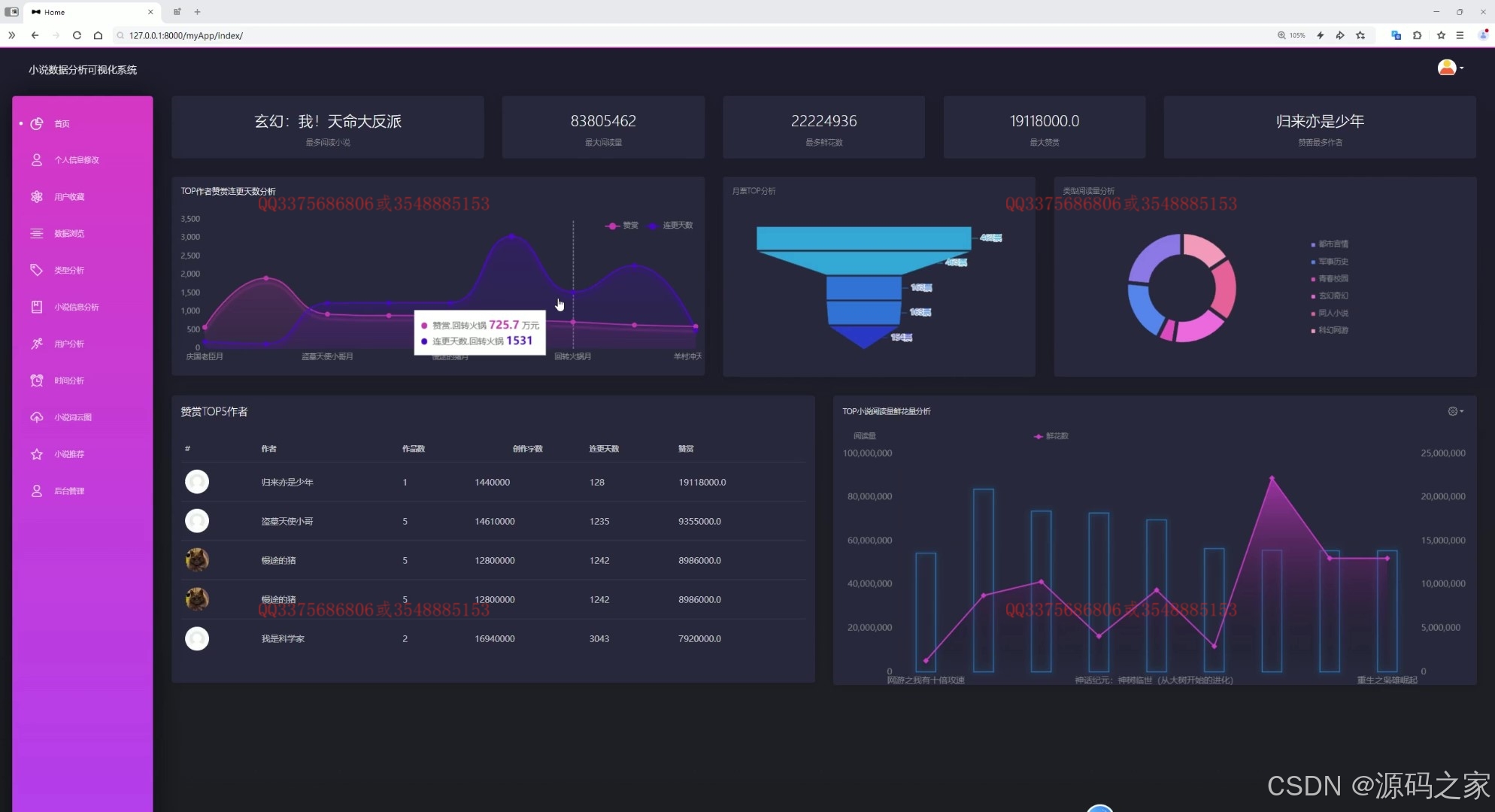
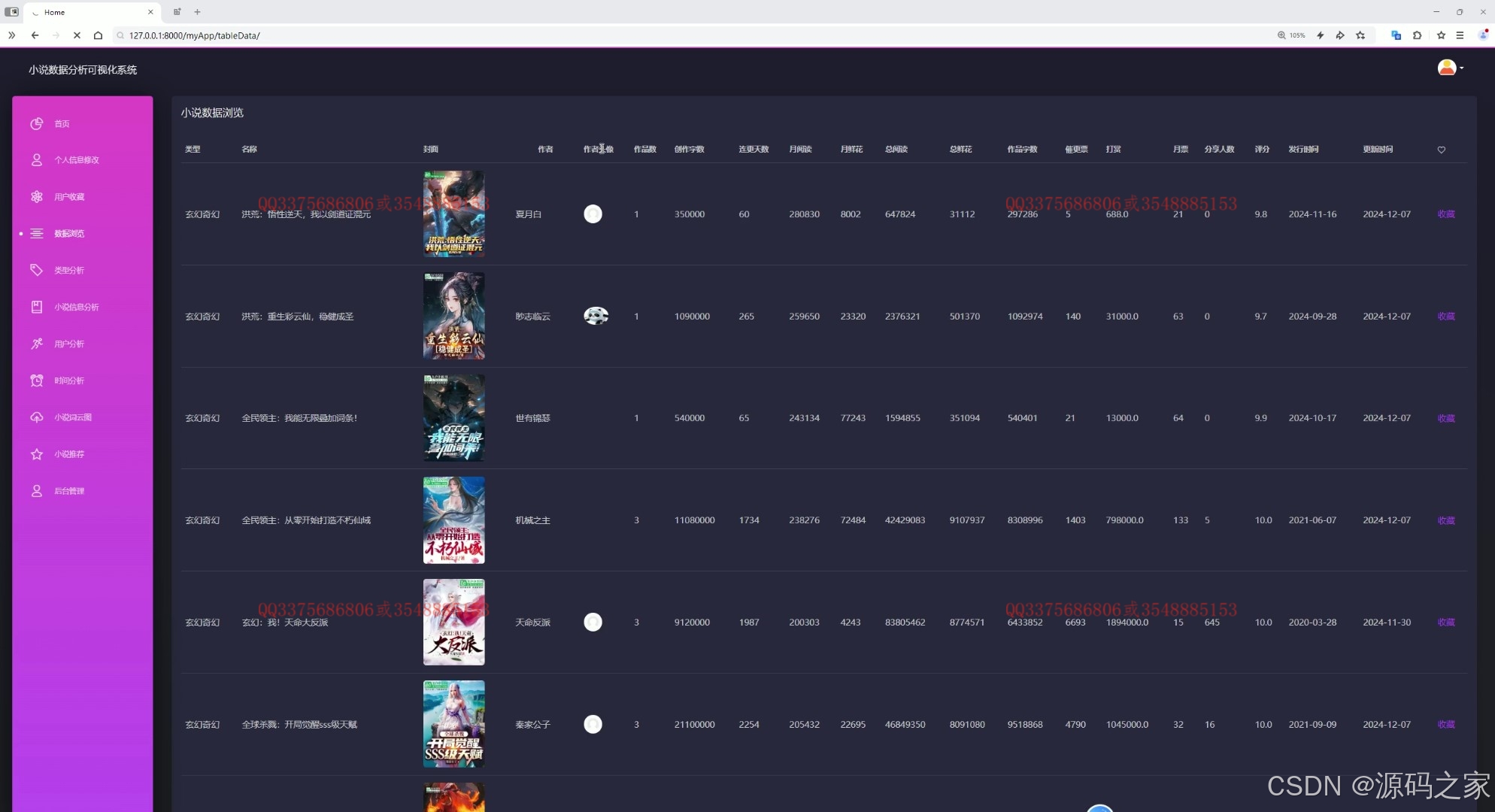
(2)数据中心
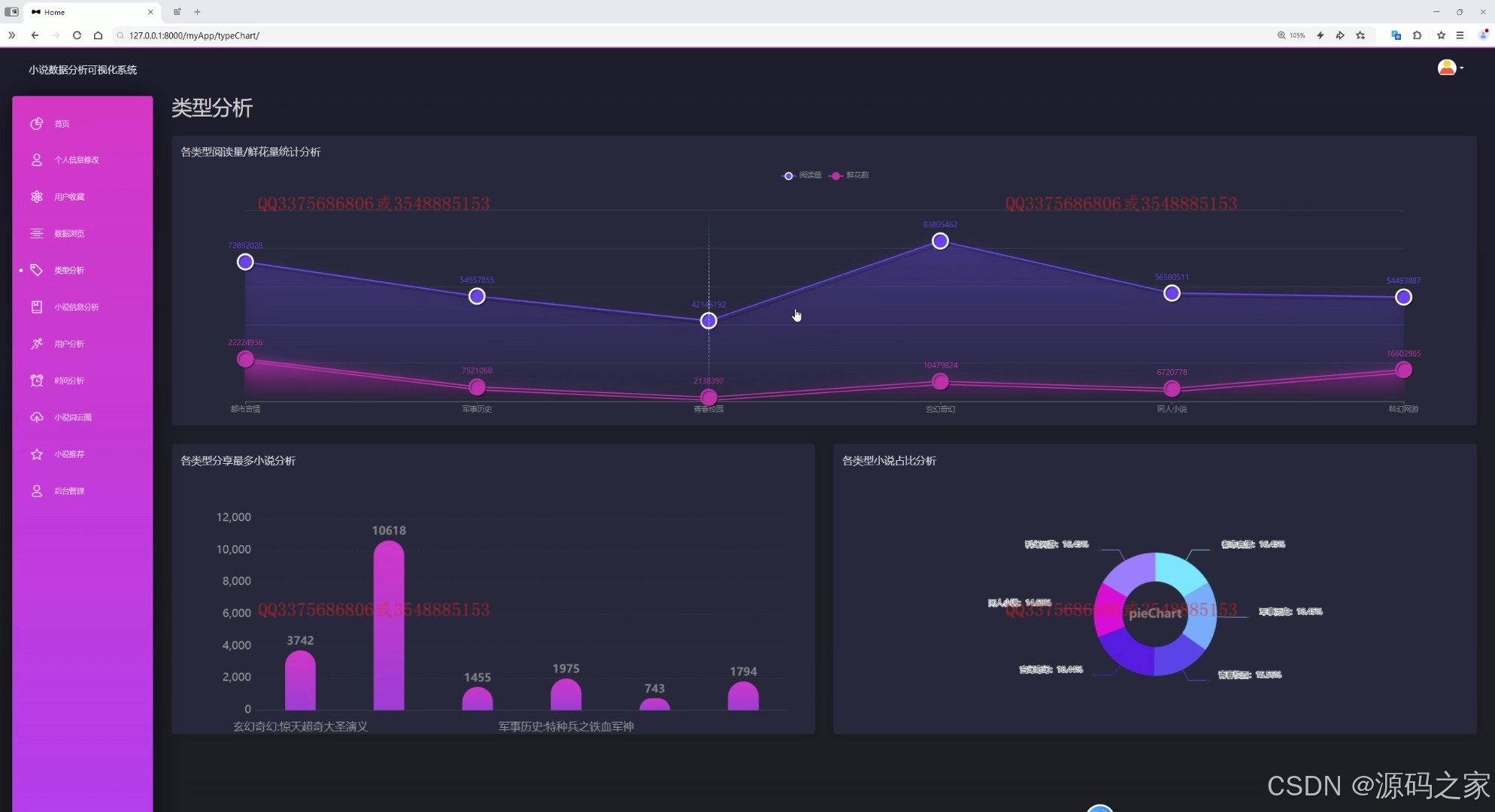
(3)小说数据类型分析
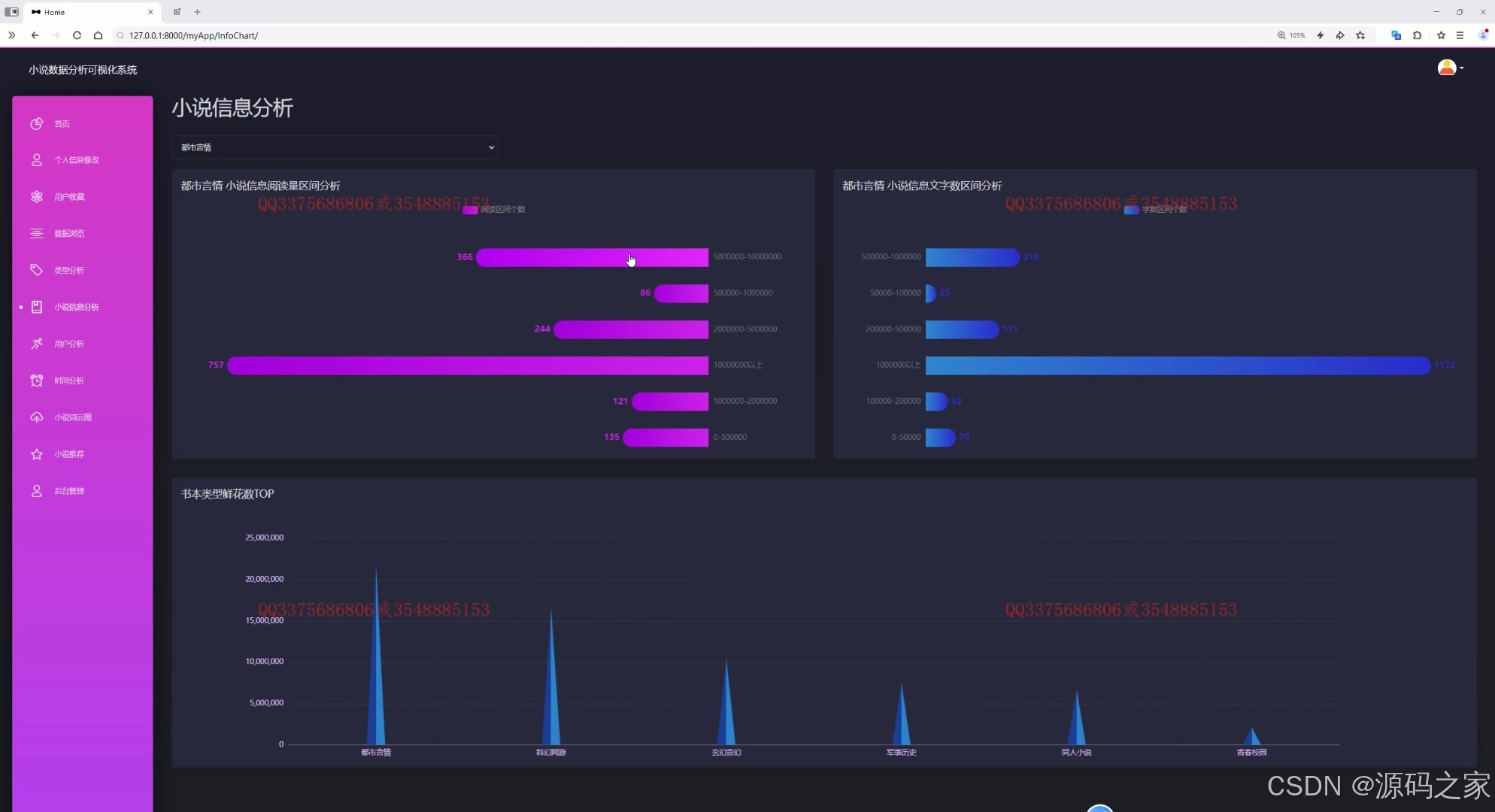
(4)小说数据分析
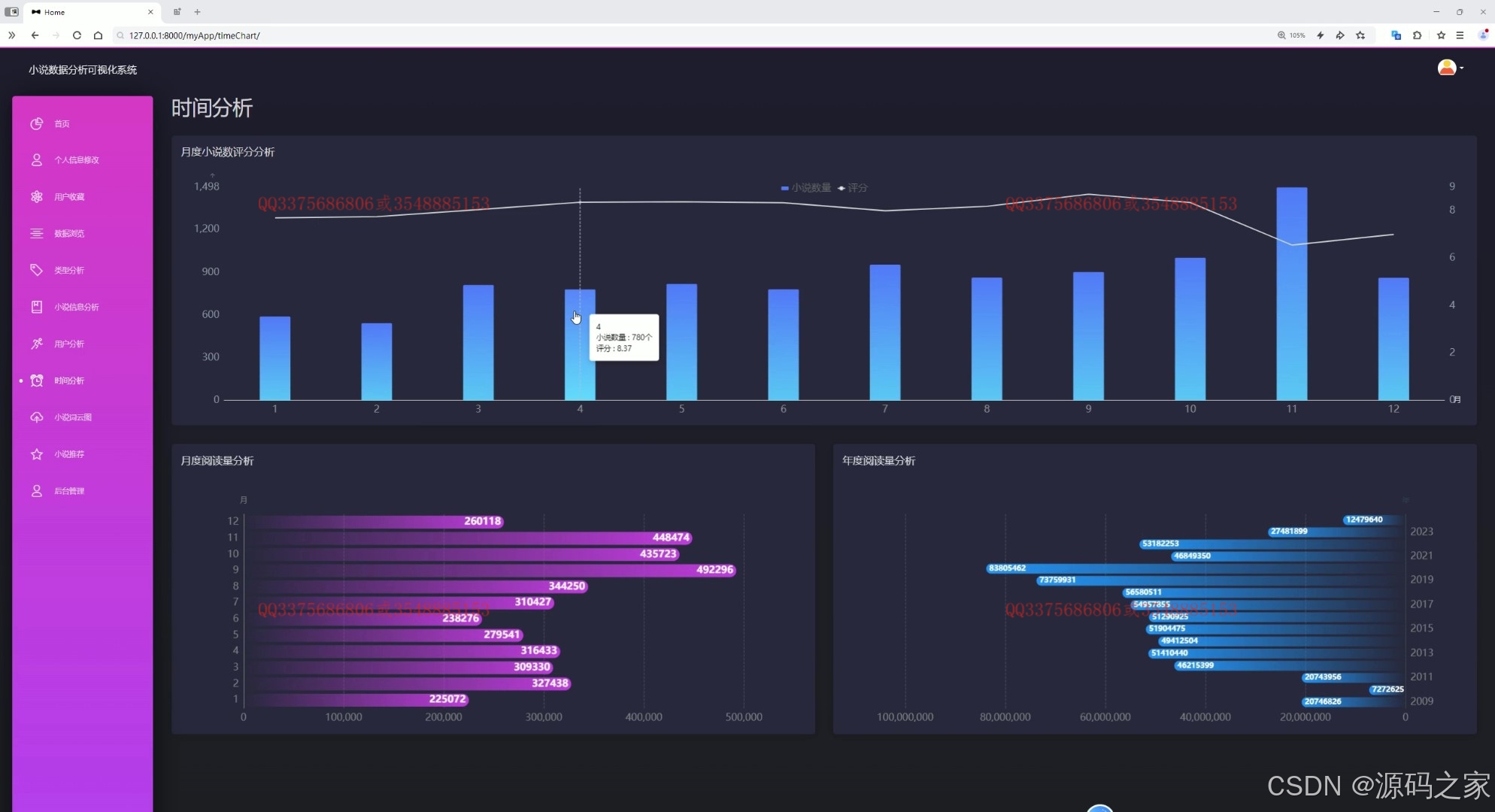
(5)小说数据时间分析
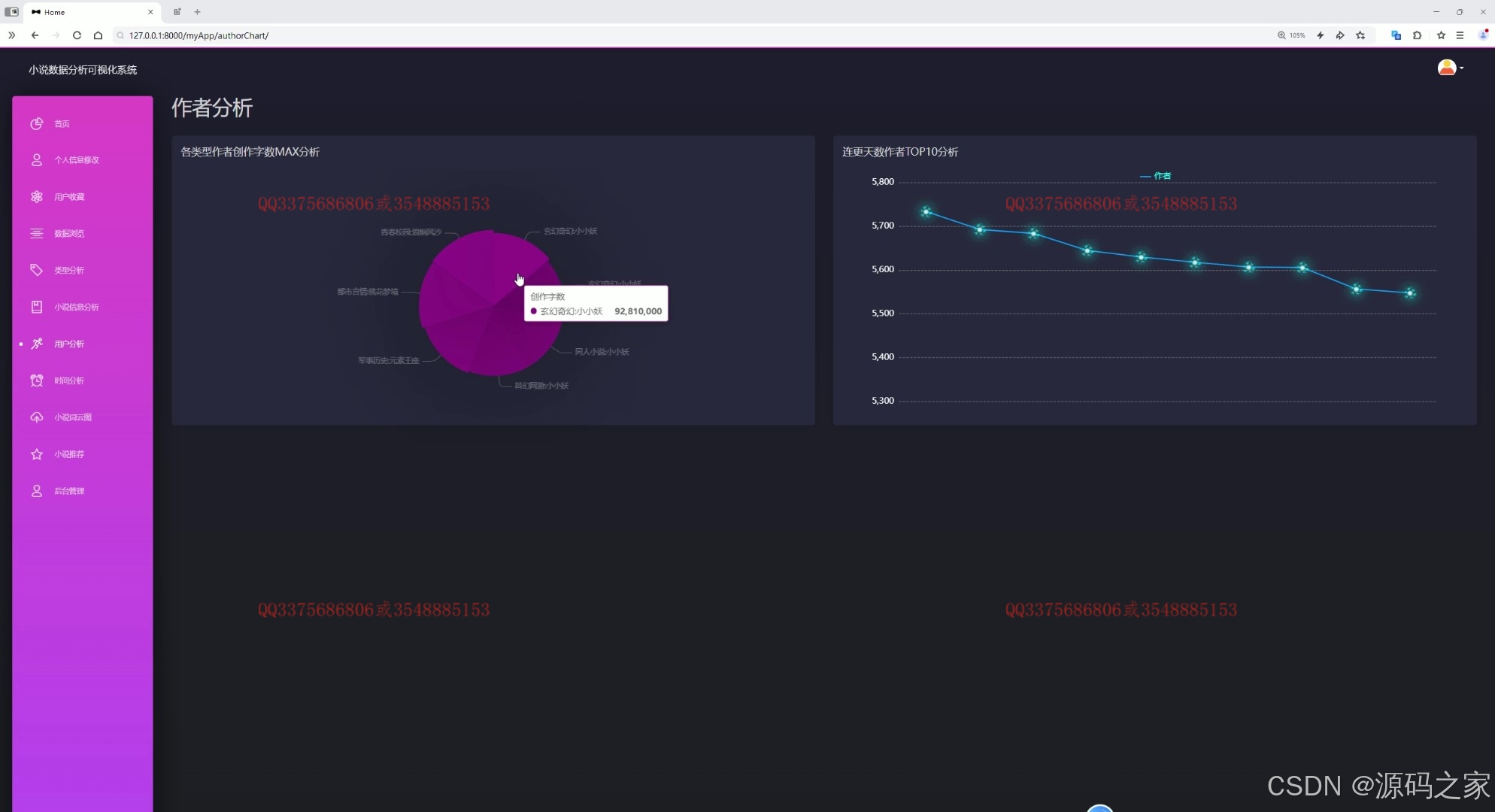
(6)小说数据作者分析
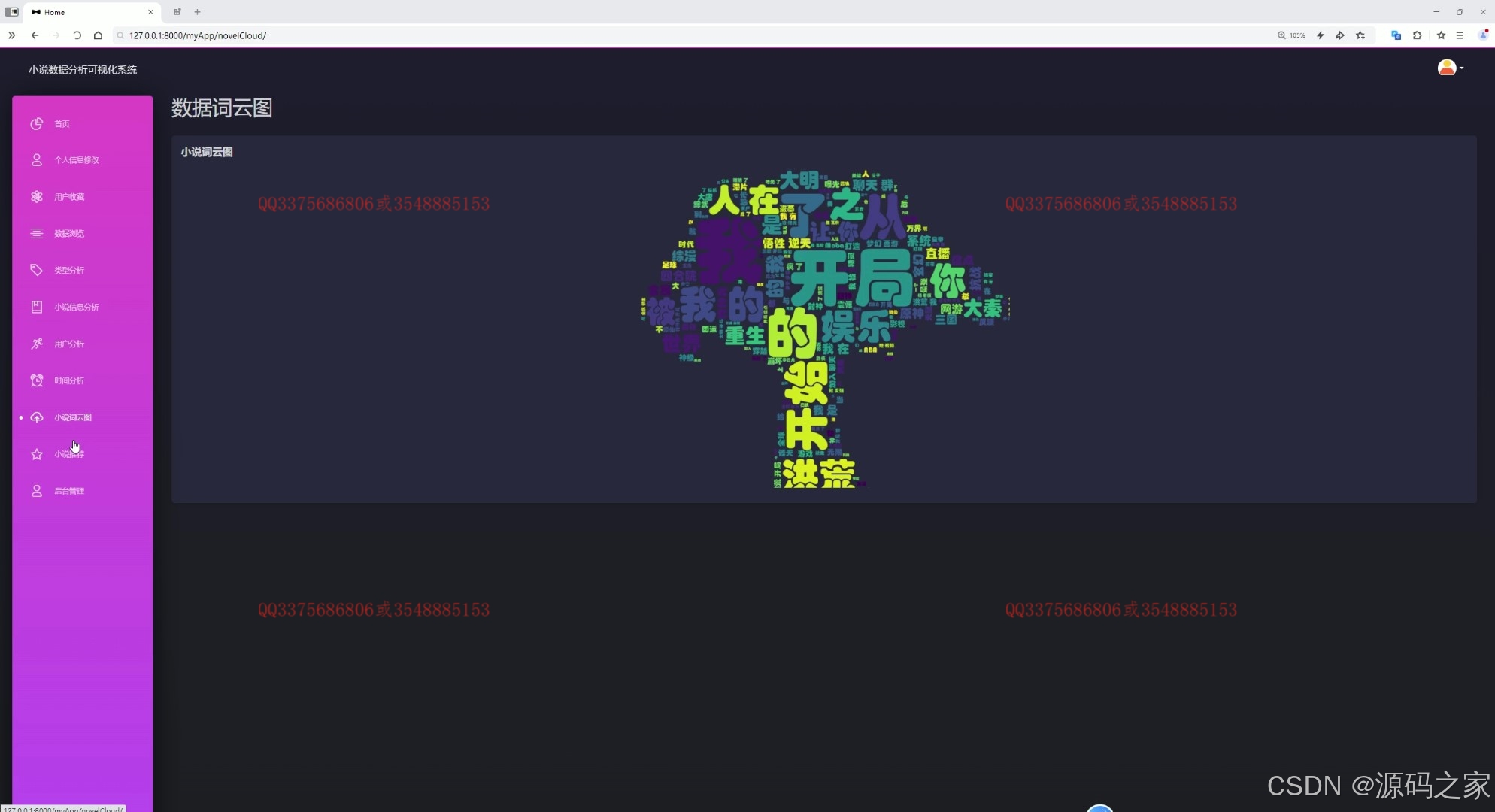
(7)小说数据词云图分析
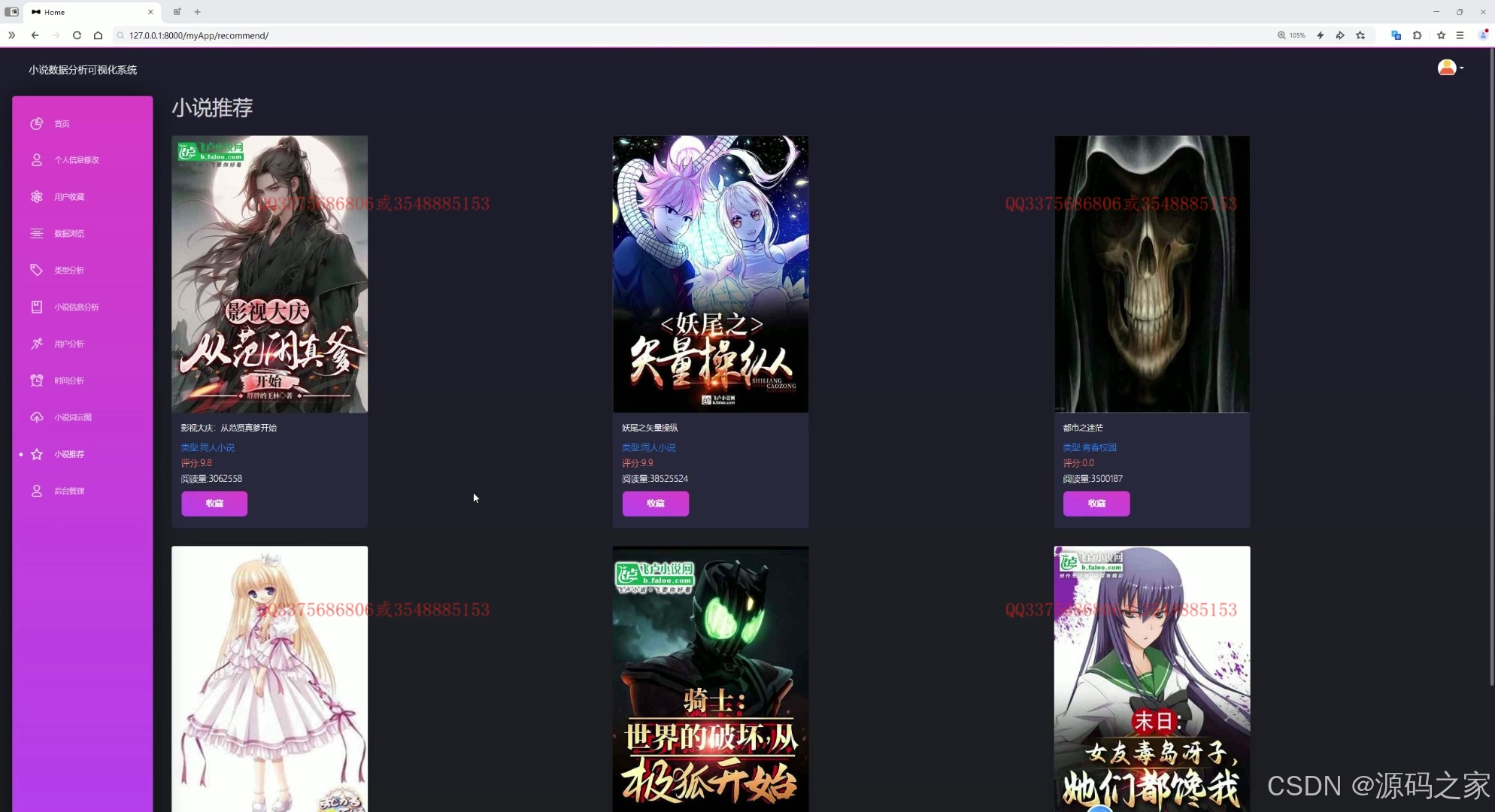
(8)小说推荐
(9)我的收藏
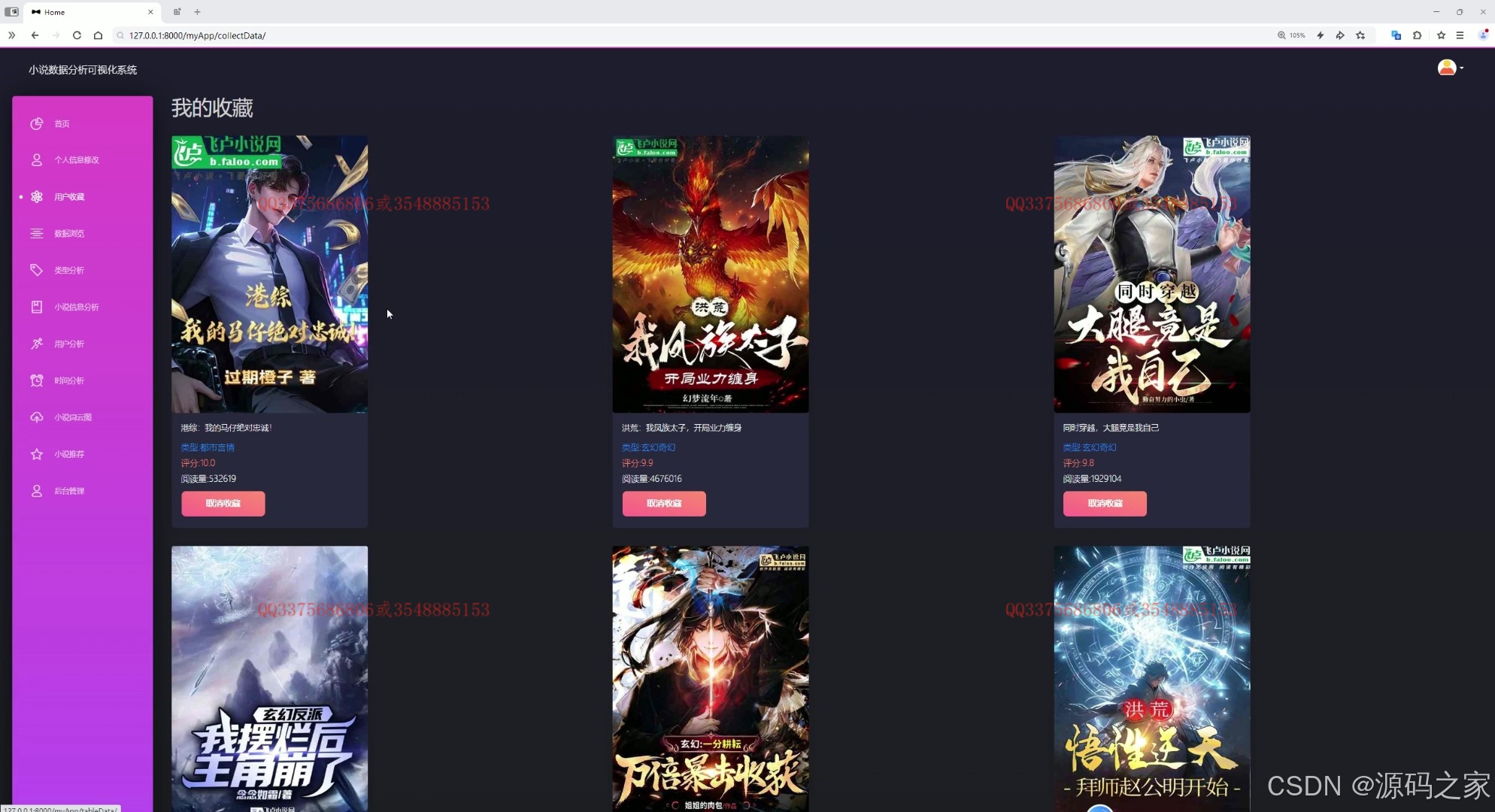
(10)我的收藏
(11)注册登录
(12)数据采集
(13)后台管理
3、项目说明
一、爬虫
requests爬虫技术
https://b.faloo.com/ 飞卢小说网
二、推荐 machine/index.py 机器学习
基于用户协同过滤的推荐,主要用于根据用户的历史行为(如点击次数)为用户推荐小说。
cosine_similarity 是 scikit-learn 库中用于计算余弦相似度的函数
具体步骤:
1、获取目标用户数据:从 user_ratings 中提取目标用户(user_name)的评分数据。
2、计算用户相似度:
将目标用户的评分数据转换为数组,遍历其他用户,计算每个用户与目标用户的相似度(使用余弦相似度 cosine_similarity),保存每个用户的相似度得分。
3、排序与选择相似用户:
按相似度得分对用户进行排序,选择相似度最高的前 top_n 个用户。
3、生成推荐列表:
获取这些相似用户评分过的项目(小说ID),过滤掉目标用户已经评分过的项目,生成最终的推荐列表。
4、输出推荐结果
基于 Spark 与协同过滤的小说数据分析与推荐系统
该项目是一款聚焦小说领域 “数据采集 - 分析 - 推荐” 全流程的大数据应用,作为毕业设计,以 Python 为开发基础,整合 Hadoop/Spark/Hive 的大数据处理能力、requests 爬虫技术与用户协同过滤推荐算法,依托 Django 搭建 Web 平台、Echarts 实现可视化,从飞卢小说网(https://b.faloo.com/)采集数据,为用户提供小说数据分析洞察与个性化推荐,兼具技术深度与实用场景。
技术栈围绕 “大数据流转” 形成闭环:Hadoop 负责海量小说数据的分布式存储,保障爬虫采集数据的稳定存储;Spark 凭借高效的分布式计算能力,支撑小说数据的多维度分析(如类型、时间、作者分析);Hive 构建数据仓库,规范数据结构,便于后续分析查询;requests 爬虫定向采集飞卢小说网数据,为系统提供数据源;用户协同过滤算法(基于 scikit-learn 的 cosine_similarity 余弦相似度)实现个性化推荐;Django 搭建 Web 交互平台,Echarts 将分析结果转化为数据大屏、词云图等可视化图表,MySQL 则存储用户信息、收藏记录等结构化数据,各技术模块精准支撑对应功能。
项目核心功能分三大模块,且与界面高度适配:其一为数据采集与处理,通过 requests 爬虫从飞卢小说网获取小说基础信息(对应 “数据采集” 界面 12),数据经清洗后存入 Hadoop,再通过 Hive 建模、Spark 计算,为后续分析与推荐提供数据支撑;其二为多维度数据分析,借助 Echarts 生成可视化图表 —— 数据大屏(界面 1)直观展示核心数据概览,数据中心(界面 2)呈现详细统计,小说类型分析(界面 3)、时间分析(界面 5)、作者分析(界面 6)分别从不同维度解析小说数据特征,词云图(界面 7)则可视化小说关键词分布(界面 4 为综合数据分析),让用户快速获取数据洞察;其三为个性化推荐与用户交互,基于用户协同过滤算法(machine/index.py 实现),通过 “获取用户数据→计算余弦相似度→选 Top N 相似用户→生成推荐列表” 步骤,为用户推荐未浏览过的小说(对应 “小说推荐” 界面 8);用户可通过注册登录(界面 11)管理 “我的收藏”(界面 9-10),管理员则通过 “后台管理”(界面 13)维护系统数据。
该项目的核心价值在于技术整合与场景落地:作为大数据方向毕业设计,它完整实现了从数据源采集到终端应用的大数据流程;同时,针对小说用户的 “发现新小说” 需求,通过协同过滤算法提升推荐精准度,多维度分析则为用户(或内容运营者)提供小说领域数据参考,是一款兼顾技术实践与用户需求的优秀毕业设计作品。
4、核心代码
#coding:utf8#导包
from pyspark.sql import SparkSession
from pyspark.sql.functions import monotonically_increasing_id
from pyspark.sql.types import StructField,StructType,StringType,IntegerType,FloatType
from pyspark.sql.functions import count,avg,regexp_extract,max,month,year
import pyspark.sql.functions as Fif __name__ == '__main__':# 构建spark = SparkSession.builder.appName("sparkSQL").master("local[*]"). \config("spark.sql.shuffle.partitions", 2). \config("spark.sql.warehouse.dir", "hdfs://node1:8020/user/hive/warehouse"). \config("hive.metastore.uris", "thrift://node1:9083"). \enableHiveSupport(). \getOrCreate()#读取novelData = spark.read.table('novelData')#需求1result1 = novelData.orderBy("allRead",ascending=False).limit(10)result2 = novelData.orderBy("reward",ascending=False).limit(10)# sqlresult1.write.mode("overwrite"). \format("jdbc"). \option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"). \option("dbtable", "TopRead"). \option("user", "root"). \option("password", "root"). \option("encoding", "utf-8"). \save()result1.write.mode("overwrite").saveAsTable("TopRead", "parquet")spark.sql("select * from TopRead").show()result2.write.mode("overwrite"). \format("jdbc"). \option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"). \option("dbtable", "TopReward"). \option("user", "root"). \option("password", "root"). \option("encoding", "utf-8"). \save()result2.write.mode("overwrite").saveAsTable("TopReward", "parquet")spark.sql("select * from TopReward").show()#需求3result3 = novelData.groupby("type").agg(avg("allRead").alias("avg_allRead"))result3.write.mode("overwrite"). \format("jdbc"). \option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"). \option("dbtable", "typeAvgRead"). \option("user", "root"). \option("password", "root"). \option("encoding", "utf-8"). \save()result3.write.mode("overwrite").saveAsTable("typeAvgRead", "parquet")spark.sql("select * from typeAvgRead").show()#需求四result4 = novelData.select("monthTicker","title").orderBy("monthTicker",ascending=False).limit(10)result4.write.mode("overwrite"). \format("jdbc"). \option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"). \option("dbtable", "TopMTicket"). \option("user", "root"). \option("password", "root"). \option("encoding", "utf-8"). \save()result4.write.mode("overwrite").saveAsTable("TopMTicket", "parquet")spark.sql("select * from TopMTicket").show()#需求5result5 = novelData.groupby("type").agg(max("allRead").alias("max_allRead"),max("allFlower").alias("max_Flower"),)result5.write.mode("overwrite"). \format("jdbc"). \option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"). \option("dbtable", "novelTypeMRF"). \option("user", "root"). \option("password", "root"). \option("encoding", "utf-8"). \save()result5.write.mode("overwrite").saveAsTable("novelTypeMRF", "parquet")spark.sql("select * from novelTypeMRF").show()#需求6 类型推荐max_share_df = novelData.groupby("type").agg(F.max("shareNum").alias("max_share"))novelData_alias = novelData.alias("novel")max_shre_df_alias = max_share_df.alias("maxShare")result6 = novelData_alias.join(max_share_df,(novelData_alias.type == max_share_df.type) &(novelData_alias.shareNum == max_share_df.max_share),"inner")\.select(novelData_alias.type.alias("type"),novelData_alias.title.alias("title"),max_share_df.max_share.alias("maxShare"))result6.write.mode("overwrite"). \format("jdbc"). \option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"). \option("dbtable", "novelMaxShare"). \option("user", "root"). \option("password", "root"). \option("encoding", "utf-8"). \save()result6.write.mode("overwrite").saveAsTable("novelMaxShare", "parquet")spark.sql("select * from novelMaxShare").show()#需求7result7 = novelData.groupby("type").count()#result7.write.mode("overwrite"). \format("jdbc"). \option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"). \option("dbtable", "novelType"). \option("user", "root"). \option("password", "root"). \option("encoding", "utf-8"). \save()result7.write.mode("overwrite").saveAsTable("novelType", "parquet")spark.sql("select * from novelType").show()#需求8novelData_with_range = novelData.withColumn("read_range",F.when(novelData.allRead < 500000,"0-500000").when((novelData.allRead >= 500000) & (novelData.allRead < 1000000), "500000-1000000").when((novelData.allRead >= 1000000) & (novelData.allRead < 2000000), "1000000-2000000").when((novelData.allRead >= 2000000) & (novelData.allRead < 5000000), "2000000-5000000").when((novelData.allRead >= 5000000) & (novelData.allRead < 10000000), "5000000-10000000").otherwise("10000000以上"))result8 = novelData_with_range.groupby("type","read_range").count().orderBy("type","read_range")#result8.write.mode("overwrite"). \format("jdbc"). \option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"). \option("dbtable", "novelReadRange"). \option("user", "root"). \option("password", "root"). \option("encoding", "utf-8"). \save()result8.write.mode("overwrite").saveAsTable("novelReadRange", "parquet")spark.sql("select * from novelReadRange").show()#novelData_with_range2 = novelData.withColumn("wordNum_range",F.when(novelData.wordNum < 50000,"0-50000").when((novelData.wordNum >= 50000) & (novelData.wordNum < 100000), "50000-100000").when((novelData.wordNum >= 100000) & (novelData.wordNum < 200000), "100000-200000").when((novelData.wordNum >= 200000) & (novelData.wordNum < 500000), "200000-500000").when((novelData.wordNum >= 500000) & (novelData.wordNum < 1000000), "500000-1000000").otherwise("1000000以上"))result9 = novelData_with_range2.groupby("type", "wordNum_range").count().orderBy("type", "wordNum_range")#result9.write.mode("overwrite"). \format("jdbc"). \option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"). \option("dbtable", "novelWordNumRange"). \option("user", "root"). \option("password", "root"). \option("encoding", "utf-8"). \save()result9.write.mode("overwrite").saveAsTable("novelWordNumRange", "parquet")spark.sql("select * from novelWordNumRange").show()#需求十result10 = novelData.groupby("type").agg(F.max("allFlower").alias("max_allFlower"))result10 = result10.orderBy(F.desc("max_allFlower"))## result10.write.mode("overwrite").saveAsTable("novelReadRange", "parquet")# spark.sql("select * from novelReadRange").show()#result10.write.mode("overwrite"). \format("jdbc"). \option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"). \option("dbtable", "novelFlowerTop"). \option("user", "root"). \option("password", "root"). \option("encoding", "utf-8"). \save()result10.write.mode("overwrite").saveAsTable("novelFlowerTop", "parquet")spark.sql("select * from novelFlowerTop").show()#需求11result11 = novelData.select("author","authorDays")\.orderBy("authorDays",ascending=False)\.limit(10)#result11.write.mode("overwrite"). \format("jdbc"). \option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"). \option("dbtable", "authorDayTop"). \option("user", "root"). \option("password", "root"). \option("encoding", "utf-8"). \save()result11.write.mode("overwrite").saveAsTable("authorDayTop", "parquet")spark.sql("select * from authorDayTop").show()#需求十二max_authorWords_df = novelData.groupby("type").agg(F.max("authorWords").alias("max_Words"))novelData_alias = novelData.alias("novel")max_authorWords_df = max_authorWords_df.alias("maxWord")result12 = novelData_alias.join(max_authorWords_df,(novelData_alias.type == max_authorWords_df.type) &(novelData_alias.authorWords == max_authorWords_df.max_Words),"inner") \.select(novelData_alias.type.alias("type"),novelData_alias.author.alias("author"),max_authorWords_df.max_Words.alias("max_Words"))#result12.write.mode("overwrite"). \format("jdbc"). \option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"). \option("dbtable", "authorMaxWord"). \option("user", "root"). \option("password", "root"). \option("encoding", "utf-8"). \save()result12.write.mode("overwrite").saveAsTable("authorMaxWord", "parquet")spark.sql("select * from authorMaxWord").show()#需求13monthly_data = novelData.withColumn("month",month(novelData["startTime"]))result13 = monthly_data.groupby("month").agg(count('*').alias("data_count"),avg("rate").alias("avg_rate"))#result13.write.mode("overwrite"). \format("jdbc"). \option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"). \option("dbtable", "novelMonthCount"). \option("user", "root"). \option("password", "root"). \option("encoding", "utf-8"). \save()result13.write.mode("overwrite").saveAsTable("novelMonthCount", "parquet")spark.sql("select * from novelMonthCount").show()#需求14result14 = monthly_data.groupby("month").agg(max("monthRead").alias("max_monthRead"))#result14.write.mode("overwrite"). \format("jdbc"). \option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"). \option("dbtable", "novelMonthRead"). \option("user", "root"). \option("password", "root"). \option("encoding", "utf-8"). \save()result14.write.mode("overwrite").saveAsTable("novelMonthRead", "parquet")spark.sql("select * from novelMonthRead").show()#需求15yearly_data = novelData.withColumn("year",year(novelData["startTime"]))result15 = yearly_data.groupby("year").agg(max("allRead").alias("max_allRead"))#result15.write.mode("overwrite"). \format("jdbc"). \option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"). \option("dbtable", "novelYearRead"). \option("user", "root"). \option("password", "root"). \option("encoding", "utf-8"). \save()result15.write.mode("overwrite").saveAsTable("novelYearRead", "parquet")spark.sql("select * from novelYearRead").show()🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目编程以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻