Flink 有状态流处理State、Keyed State、Checkpoint、对齐/不对齐与生产实践
1. 为什么要在流里“记住”?——State 的意义
在实际业务里,你很难“看一条算一条”。典型需求包括:
- 模式识别:需要记住到目前为止的事件序列
- 窗口聚合:分钟/小时/天的未完成聚合
- 在线学习:模型参数的最新版本
- 历史管理:高效访问过去的事件
这都需要 状态(State)。Flink 在运行时感知状态,借助 Checkpoints/Savepoints 保障容错,并支持弹性伸缩时的状态再分布。
2. Keyed State 与分区:让状态“本地化”
Keyed State 可以理解为嵌入式 Key/Value 存储:
只有在 Keyed 流(即经过 keyBy/分区)上才能访问状态,并且仅限当前事件的 Key。这保证了:
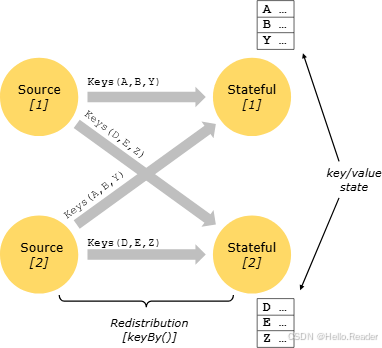
- 状态更新是本地操作 → 一致性无需额外事务开销
- 对齐键与状态 → 透明地重新分配状态与调整分区
进一步地,Keyed State 被组织为 Key Groups(数量 = 最大并行度)。执行时,每个并行子任务处理一个或多个 Key Group,实现最小原子粒度的再分配。
3. 状态持久化与恢复:Checkpoint 是如何工作的?
Flink 的 Exactly-Once 容错由 流回放 + Checkpointing 实现:
- Checkpoint 记录:每个输入流的位置 + 每个算子的状态快照
- 故障恢复:选择最近完成的检查点 k,恢复算子状态,源从 Sₖ 位置继续(Kafka 即 offset Sₖ)
- Checkpoint 间隔 = 容错开销 ↔ 恢复时间 的权衡
- 小状态场景下,快照足够轻量、可高频拍摄
- 状态应存放于可靠分布式存储(生产别放 JobManager 内存)
启用 Checkpoint(默认关闭) 的基本配置示例(DataStream API,Java):
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 每 10 秒做一次检查点
env.enableCheckpointing(10_000);// Exactly-Once 语义(默认),常与 Kafka 事务 Sink 配合
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);// 允许的最大并发检查点数(通常 1~2)
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);// 状态后端与存储
// 1) RocksDB(大状态推荐)
// env.setStateBackend(new EmbeddedRocksDBStateBackend());
// 2) HashMap(小状态内存)
// env.setStateBackend(new HashMapStateBackend());// Checkpoint 存储位置(必须是可靠持久化存储,如 HDFS/S3)
env.getCheckpointConfig().setCheckpointStorage("hdfs://nameservice1/flink/ckpt");
4. 屏障与对齐:一致性快照的关键细节
屏障(Barrier) 注入于 Source,携带快照 ID,与记录严格按序前进,不会超车。
当 中间算子从所有输入收到同一快照的屏障后,才向所有输出发出该屏障;当 Sink 从所有输入收到屏障并确认后,快照完成。
多输入时为何要“对齐”?
如果一个输入先到了 n 号屏障,而其他输入还没到,此时继续处理该输入会把 属于快照 n 的记录与 属于 n+1 的记录混在一起。
对齐做的就是:暂停先到达屏障的那路输入,等待其余输入也到达 n,再统一快照并继续处理。
5. 不对齐检查点(Unaligned):为“慢路径”兜底
从 Flink 1.11 起,检查点可 不对齐:
-
允许检查点超越在途数据,只要这些在途数据被写入算子状态
-
算子对输入缓冲区中第一个出现的屏障立即反应:
- 立刻把屏障加入输出缓冲
- 标记被超越的记录进行异步持久化
- 创建自身状态快照
-
优点:屏障能尽快到达 Sink,适合至少一路数据很慢、对齐耗时很长的场景
-
限制:会增加I/O 压力;如果瓶颈在状态后端 I/O,不一定有效
-
Savepoint 永远是对齐的
开启 Unaligned Checkpoints(示例):
env.getCheckpointConfig().enableUnalignedCheckpoints(true);
// 也可配置对齐超时,超时后自动退化为不对齐
// env.getCheckpointConfig().setAlignedCheckpointTimeout(Duration.ofSeconds(30));
6. 算子状态快照:何时拍、拍到哪?
算子在从所有输入收到屏障、且向下游发出屏障之前拍摄状态快照。
为了避免阻塞,状态会异步写入配置的状态后端(如 HDFS/S3/RocksDB 增量)。
快照包含:
- 每个并行 Source 的流位置(offset/position)
- 每个算子状态对象的指针/句柄
7. Savepoints:升级迁移的“保险带”
- 手动触发的检查点,写入状态后端
- 不会因新检查点完成而自动过期
- 常用于程序/集群升级、拓扑变更、Job 重部署等场景
- 正确使用前务必理解 Checkpoints vs Savepoints 的差异(保存点的可移植性、格式与版本兼容性)
常用 CLI(示意):
# 触发保存点
flink savepoint <jobId> hdfs://.../savepoints/# 从保存点恢复
flink run -s hdfs://.../savepoints/savepoint-xxx/_metadata job.jar
8. Exactly-Once vs At-Least-Once:延迟与语义的取舍
-
对齐可能增加毫秒级延迟,但可给出 Exactly-Once
-
追求极致低延迟(极少数毫秒级)时,可跳过对齐:
- 算子在部分输入已到达 n 的屏障后仍继续处理所有输入
- 结果:在恢复时会出现重复记录(At-Least-Once)
-
仅在完全并行(map/flatMap/filter… 无 join/shuffle)的拓扑中,即使 At-Least-Once 模式也能实际达到 Exactly-Once(因为无对齐点)
配置语义示例:
// Exactly-Once(默认)
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);// At-Least-Once(更低延迟,但可能重复)
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.AT_LEAST_ONCE);
9. 状态后端选择:数据结构与快照实现
状态后端决定 Key/Value 索引的数据结构 与 快照实现:
- HashMapStateBackend:内存 HashMap,小状态、超低延迟
- RocksDB(EmbeddedRocksDBStateBackend):外部化 KV,大状态首选,支持增量快照
经验法则:
- 小状态、链路低延迟要求高 → HashMap
- 大状态、海量 Key、需容错稳定 → RocksDB 增量快照
- 无需改业务代码即可更换状态后端
10. 批模式下的状态与容错:不做 Checkpoint,直接“全量回放”
批作业是“有界流”的特例(BATCH ExecutionMode):
- 容错不使用 Checkpoint:故障时全量重放输入(输入是有限的)
- 平时处理更便宜(省去检查点开销),成本转移到恢复阶段
- 批模式下的状态后端使用简化的内存/外存结构,而不是在线 KV 索引
11. 代码与配置:从零到一的最小可用骨架
11.1 处理乱序 + 事件时间窗口(DataStream + Watermark)
WatermarkStrategy<Event> wm = WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ofMinutes(2)).withTimestampAssigner((e, ts) -> e.getEventTimeMillis());DataStream<Event> events = env.fromSource(kafkaSource, wm, "events");
11.2 手写 KeyedProcessFunction(对齐逻辑自定义)
events.keyBy(Event::getUserId).process(new KeyedProcessFunction<String, Event, Output>() {private transient ValueState<Long> cnt;private transient ValueState<Long> winEnd;@Override public void open(Configuration p) {cnt = getRuntimeContext().getState(new ValueStateDescriptor<>("cnt", Long.class));winEnd = getRuntimeContext().getState(new ValueStateDescriptor<>("end", Long.class));}@Override public void processElement(Event e, Context ctx, Collector<Output> out) throws Exception {cnt.update((cnt.value()==null?0:cnt.value()) + 1);long end = align10m(e.getEventTimeMillis());if (winEnd.value()==null || winEnd.value()!=end) {if (winEnd.value()!=null) ctx.timerService().deleteEventTimeTimer(winEnd.value()+1);ctx.timerService().registerEventTimeTimer(end+1);winEnd.update(end);}}@Override public void onTimer(long ts, OnTimerContext c, Collector<Output> out) throws Exception {if (winEnd.value()!=null && ts==winEnd.value()+1) {out.collect(new Output(c.getCurrentKey(), winEnd.value(), cnt.value()));cnt.clear(); winEnd.clear();}}private long align10m(long t){ long s=10*60*1000L; return t - (t%s) + s - 1; }});
11.3 Table/SQL 更快上手(带 Watermark 的动态表)
CREATE TABLE events (user_id STRING,event_time TIMESTAMP_LTZ(3),WATERMARK FOR event_time AS event_time - INTERVAL '2' MINUTE
) WITH (...);CREATE TABLE sink (...) WITH (...);INSERT INTO sink
SELECT user_id, WINDOW_END AS win_end, COUNT(*) AS cnt
FROM TABLE(TUMBLE(TABLE events, DESCRIPTOR(event_time), INTERVAL '10' MINUTES)
)
GROUP BY user_id, WINDOW_START, WINDOW_END;
12. 生产最佳实践清单(可当上线前自检表)
-
语义选择:默认 Exactly-Once;极端低延迟再考虑 At-Least-Once / Unaligned
-
Watermark:乱序容忍度保守设置,评估延迟与正确率
-
状态治理:
- 估算 Key/状态规模与 TTL(避免“永不清理”)
- RocksDB + 增量快照应对大状态;关注热点与倾斜
-
检查点可靠性:
- Checkpoint 落在可靠存储(HDFS/S3),限制并发与超时
- 定期 Savepoint 作为可回退版本
-
Connectors 语义:Kafka Source 可回退;Sink 用两阶段提交/事务保证端到端一致性
-
观测与告警:Backpressure、Busy Time、Checkpoint Duration/Alignment、Watermark Lag、State Size
-
演进与扩缩容:用 Savepoint 做算子并行度/拓扑变更;最大并行度与 Key Group 提前规划
-
批/流一体:批作业不做 Checkpoint,容错依赖全量回放,成本主要在恢复阶段
13. 结语
理解 状态 与 时间,是把 Flink 从“能跑”推进到“跑得稳、跑得准”的关键。
用 Keyed State 把业务上下文本地化;用 Checkpoints/Savepoints 守住一致性与可进化;根据链路特性在 对齐/不对齐 之间做正确取舍;结合 状态后端 管好规模与性能。
当这些拼图都对齐,你的实时系统就具备了在生产环境长期演进的基础能力。