自然语言处理项目之情感分析(下)
简介
在当今信息爆炸的时代,海量的文本数据如社交媒体评论、产品评价、新闻留言等不断涌现,这些文本中蕴含着人们丰富的情感态度,无论是对商品的喜爱、对政策的支持,还是对服务的不满。而自然语言处理(NLP)领域中的情感分析技术,正是挖掘这些情感信息的关键工具。情感分析,也常被称为意见挖掘,它通过运用计算机技术对文本数据进行处理、分析和理解,自动识别和提取文本中所包含的情感倾向,如积极、消极、中性,甚至还能进一步细分为喜悦、愤怒、悲伤、惊讶等具体的情感类别,为企业决策、公共舆情监测、个人服务等诸多领域提供有力的支持。
继上一篇我们对数据进行了预处理,今天我们继续来完成项目的后半部分
自然语言处理项目之情感分析(上)
一、项目介绍
1.项目任务
对微博评论信息的情感分析,建立模型,自动识别评论信息的情绪状态。
评论信息内容
2.问题处理
1)目标
将每条评论内容转换为词向量。
2)输入字词格式
每个词/字转换为词向量长度(维度)200,使用腾讯训练好的词向量模型有4960个维度,需要这个模型或者文件可私信发送。
3)每一次传入的词/字的个数是否就是评论的长度
应该是固定长度,如何固定长度接着看,固定长度每次传入数据与图像相似,例如输入评论长度为32,那么传入的数据为32*200的矩阵,表示这一批词的独热编码,200表示维度
4)一条评论如果超过32个词/字怎么处理?
超出的直接删除后面的内容
5)一条评论如果没有32个词/字怎么处理?
缺少的内容,统一使用一个数字(非词/字的数字)替代,项目中使用<PAD>填充
6)如果语料库中的词/字太多是否可以压缩?
可以,某些词/字出现的频率比较低,可能训练不出特征。因此可以选择频率比较高的词来训练,项目中选择4760个。
7)被压缩的词/字如何处理?
可以统一使用一个数字(非词/字的数字)替代,即选择了评论固定长度的文字后,这段文字内可能有频率低的字,将其用一个数字替代,项目内使用<UNK>替代
二、代码实现
1.定义模型,前向传播函数
将下列代码写入新创建的文件TextRNN.py。定义了我们的模型结构。
import torch.nn as nnclass Model(nn.Module): # 定义一个类,继承神经网络的基类,参数管理、模型保存加载...def __init__(self, embedding_pretrained, n_vocab, embed,num_classes): # 传入参数表示为:预训练的词向量(当前项目导入腾讯训练好的词向量)、词汇表的长度、词向量维度、分类标签的数量super(Model, self).__init__()if embedding_pretrained is not None: # 如果有预训练模型# 创建一个词嵌入层,用与接收预训练的嵌入层权重作为输入,指定填充词在词汇表中的索引为n_vocab-1,freeze:指定是否冻结embedinq层的权重,False表示可以更新预训练模型的权重参数self.embedding = nn.Embedding.from_pretrained(embedding_pretrained, padding_idx=n_vocab - 1, freeze=False)else: # 如果没有预训练模型,则初始化一个随机嵌入层,维度为n_vocab*embed 项目内是4762*200self.embedding = nn.Embedding(n_vocab, embed, padding_idx=n_vocab - 1)# 建立LSTM网络层,输入维度为embed,有128个隐藏单元共三层,bidirectional=True表示双向LSTM,所以输出为128*2,batch_first=True表示输入张量第一个维度是批次数,dropout = 0.3表示LSTM层使用的dropout比例self.lstm = nn.LSTM(embed, 128, 3, bidirectional=True, batch_first=True, dropout=0.3)# 128为每一层中每个隐状态中的U、W、V的神经元个数,# 3为隐藏层的层数,batch_first=True表示输入和输出张量将以(batch,seq,feature)而不是(seq,betch,featur)。# bidirectiongl = True: 指定LSTM是双向的。网络会同时从前向后和从后向前处理输入序列,两个方向的# dropout = 0.3: 这指定了在LSTM层中使用的dropout比例。Dropout是一种正则化技术,用于防止网络在训练过程中过拟?self.fc = nn.Linear(128 * 2, num_classes) # 设置全连接层,在每个时间步的最后一个状态的输出映射到类别数上def forward(self, x): # 定义前向传播函数,输入的参数x为batch_size批次数以及sequence_length单词样本数x, _ = x # 返回新的x值为批次数out = self.embedding(x) # 将批次数传入词嵌入层,将整数索引转换为连续的、密集的词向量out, _ = self.lstm(out) # 将词向量传入LSTM网络层out = self.fc(out[:, -1, :]) # 只选择LSTM输出序列的最后一个时间步的隐藏状态传递给self.fcreturn out2、定义训练、测试函数
创建一个文件train_eval_test.py,将下列代码写入其中
import torch
import torch.nn.functional as F
import numpy as np
from sklearn import metrics
import timedef evaluate(class_list, model, data_iter, test=False): # 传入参数:种类名称列表、训练好的模型、验证集数据,test表示是否进行测试模式model.eval() # 模型开始测试loss_total = 0 # 初始化总损失值为0predict_all = np.array([], dtype=int) # 定义一个数组用于存放预测结果的标签labels_all = np.array([], dtype=int) # 存放所有样本的真实标签with torch.no_grad(): # 一个上下文管理器,关闭梯度计算for texts, labels in data_iter: # 遍历出来 每128条评价的包 的独热编码及长度 和标签outputs = model(texts) # 输出模型进行测试,返回每个包中每条评论的测试结果loss = F.cross_entropy(outputs, labels) # 计算交叉熵损失值loss_total += loss # 损失值叠加labels = labels.data.cpu().numpy() # 将真实标签转化为numpy数组predic = torch.max(outputs.data, 1)[1].cpu().numpy() # 计算预测值的标签并转化为numpy数组labels_all = np.append(labels_all, labels) # 将真实标签增加到labels_all数组predict_all = np.append(predict_all, predic)acc = metrics.accuracy_score(labels_all, predict_all) # 计算模型在所有样本上的准确率# 返回结果if test: #report = metrics.classification_report(labels_all, predict_all, target_names=class_list,digits=4) # 如果不是测试模式,那么打印分类报告,target_names用于识别每个类别的名称class_list,digits表示打印报告中浮点数的位数return acc, loss_total / len(data_iter), report # 返回准确率、平均损失值、分类报告return acc, loss_total / len(data_iter) # 返回准确率、平均损失值def test(model, test_iter, class_list):model.load_state_dict(torch.load('TextRNN.ckpt'))model.eval()start_time = time.time()test_acc, test_loss, test_report = evaluate(class_list, model, test_iter, test=True)msg = "Test Loss:{0:>5.2},Test Acc:{1:6.2%}"print(msg.format(test_loss, test_acc))print(test_report)def train(model, train_iter, dev_iter, test_iter, class_list): # 传入模型结构、训练集、验证集、测试集、标签类别model.train() # 开始训练optimizer = torch.optim.Adam(model.parameters(), lr=1e-3) # 优化器,用于更新模型权重,学习率为0.001total_batch = 0dev_best_loss = float('inf') # 初始化设置最大损失值为正无穷大last_improve = 0flag = Falseepochs = 10 # 设置训练次数for epoch in range(epochs):print('Epoch [{}/{}]'.format(epoch + 1, epochs)) # 第一轮[1/2],第二轮[2/2]for i, (trains, labels) in enumerate(train_iter): # 遍历训练集的索引和数据,数据存放的是 每128条评价的包 的字在词表中的索引信息、标签信息、评价长度# 经过DatasetIterater中的 to_tensor 返回的数据格式为:(x,seq_len),y,即独热编码、长度、标签outputs = model(trains) # 将数据放入模型进行训练,得到预测输出值,这里的forward没有展示,即传入模型进行前向传播,返回预测结果格式为128*4loss = F.cross_entropy(outputs, labels) # 将输出值与标签放入交叉熵损失计算损失值,多分类计算损失值model.zero_grad() # 对模型进行梯度清0,为下一轮训练做准备loss.backward() # 根据损失计算梯度optimizer.step() # 根据梯度更新模型参数if total_batch % 100 == 0: # 每100轮 输出 在训练集和验证集上的效果,每一百个批次的包打印出来一次predic = torch.max(outputs.data, 1)[1].cpu() # outputs.data为 每128条评价的包 的预测大小状态128*4,因为都在GPU中,所以为Tensor类型,torch.max返回第二个维度的最大值及索引,1表示第二个维度,[1]表示取索引的值当做预测结果,然后将预测结果传入cputrain_acc = metrics.accuracy_score(labels.data.cpu(), predic) # 将真实值的标签结果与预测结果输入函数计算准确率dev_acc, dev_loss = evaluate(class_list, model, dev_iter) # 将种类名、模型、验证集数据传入evaluate函数,获得验证结果,返回准确率和损失值if dev_loss < dev_best_loss: # 判断当前损失值是否小于历史损失值dev_best_loss = dev_loss # 如果损失值比前面的小,那么更新之前的损失值,然后保存这个模型的权重信息torch.save(model.state_dict(), 'TextRNN.ckpt') # 保存最优模型last_improve = total_batch # 保存最优模型的batch值,整数赋值给last_improve# 打印模型的轮数右对齐字符宽为6、训练集的损失值长度为5保留2个小数、训练集的准确率、验证集的损失值和准确率,其中的0,1,2,3,4表示序号第一个参数第二个参数...msg = 'Iter:{0:>6},Train Loss:{1:>5.2},Train Acc:{2:>6.2%},Val Loss:{3:>5.2},Val Acc:{4:>6.2%}'print(msg.format(total_batch, loss.item(), train_acc, dev_loss, dev_acc))model.train() # 因为上述使用了evaluate将模型设置了测试模式,所以此处再次设置为训练模式total_batch += 1 # 每运行一次训练了一个包的文件,对数值加1if total_batch - last_improve > 10000:print("No optimization for a long time,auto-stopping...")flag = Trueif flag:breaktest(model, test_iter, class_list) # 调用test函数进行测试3.定义主函数
创建一个文件命名为main.py,将下列代码写入文件
import torch
import numpy as np
import load_dataset
import TextRNN
from train_eval_test import traindevice = 'cuda' if torch.cuda.is_available() else 'mps' if torch.backends.mps.is_available() else 'cpu'
np.random.seed(1)
torch.manual_seed(1)
torch.cuda.manual_seed(1)
torch.backends.cudnn.deterministic = True
vocab, train_data, dev_data, test_data = load_dataset.load_dataset('simplifyweibo_4_moods.csv')
train_iter = load_dataset.DatasetIterater(train_data, 128, device)
dev_iter = load_dataset.DatasetIterater(dev_data, 128, device)
test_iter = load_dataset.DatasetIterater(test_data, 128, device)embedding_pretrained = torch.tensor(np.load("embedding_Tencent.npz")['embeddings'].astype('float32'))embed = embedding_pretrained.size(1) if embedding_pretrained is None else 200
class_list =['', ' ', '', '']
num_classes = len(class_list)
model = TextRNN.Model(embedding_pretrained, len(vocab), embed, num_classes).to(device)
train(model, train_iter, dev_iter, test_iter, class_list)4.代码文件
最后加上上篇博客的代码,一共有上图代码文件、加上腾讯的词库。
最后实现结果
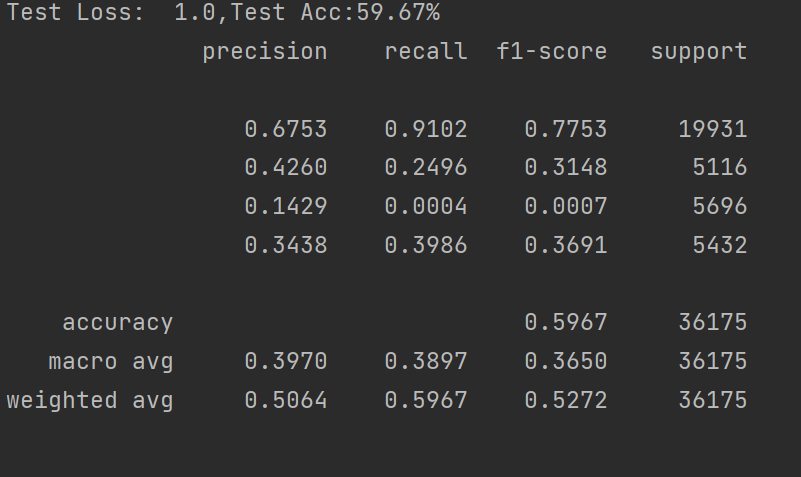
这样我们就实现了完整代码的训练以及测试。