DKD论文阅读

2022.7
1.摘要
background
当前最先进的知识蒸馏(KD)方法主要集中于从中间层提取复杂的深度特征进行蒸馏,而基于模型最终输出(logits)的蒸馏方法的重要性被大大忽略了。
尽管基于Logits的蒸馏方法计算成本低,但其性能通常不如基于特征的方法。论文作者认为,这是因为传统知识蒸馏损失函数存在未知的内在限制,其潜力未被充分挖掘。
作者发现,经典的知识蒸馏损失(由Hinton提出)是一个高度耦合(Coupled)的公式,这种耦合性(1)抑制了非目标类别知识的有效传递;(2)限制了平衡不同知识成分的灵活性。
innovation
创新点1 (重构损失函数): 论文从一个全新的视角出发,将经典的KD损失函数在数学上等价地分解为两个独立的部分:
1.目标类知识蒸馏 (Target Class Knowledge Distillation, TCKD): 一个二元分类的蒸馏,关注模型对于“是目标类”还是“不是目标类”的判断。
2.非目标类知识蒸馏 (Non-target Class Knowledge Distillation, NCKD): 一个在所有非目标类别上的多分类蒸馏,关注模型在判断“错误”时的具体倾向性,即“暗知识 (dark knowledge)”。
创新点2 (发现耦合问题): 通过重构,论文揭示了经典KD损失的内在缺陷:经典KD = TCKD + (1 - p_t^T) * NCKD。其中 p_t^T 是教师模型对正确类别的置信度。这意味着,当教师模型对一个样本的预测非常自信时(p_t^T 趋近于1),NCKD项的权重 (1 - p_t^T) 会趋近于0,从而抑制了最有价值的“暗知识”的传递。
创新点3 (提出DKD): 为了解决上述问题,论文提出了解耦知识蒸馏 (Decoupled Knowledge Distillation, DKD)。其核心思想是解除TCKD和NCKD之间的耦合关系,使用两个独立的超参数α和β来分别加权这两个部分:DKD = α * TCKD + β * NCKD。
2. 方法 Method
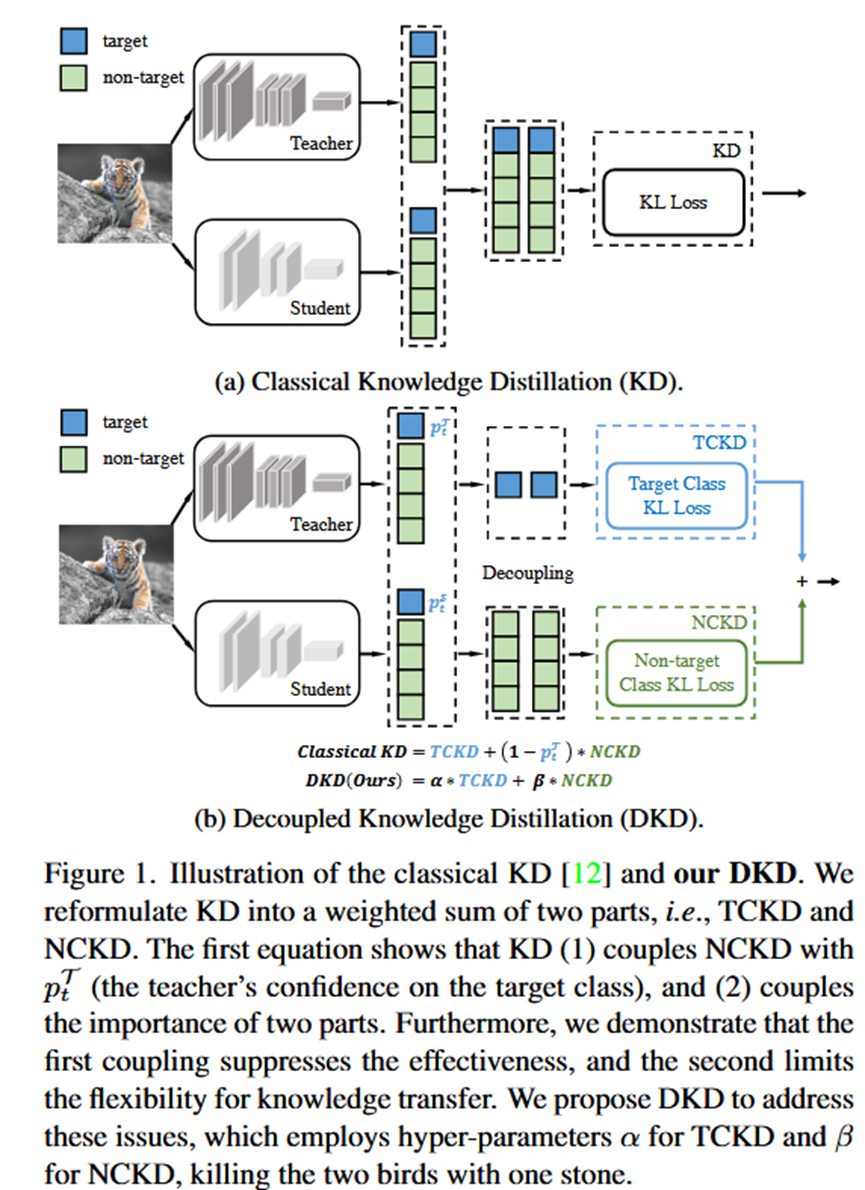
Pipeline总览:
第一步:重构经典KD损失。 将原始的KL散度损失函数,通过数学变换,分解为TCKD和NCKD两个部分的加权和。
第二步:分析重构后的公式。 识别出经典KD中存在的耦合问题,即NCKD的权重被教师模型对目标类的置信度所抑制。
第三步:提出DKD损失。 基于上述分析,提出一个新的、解耦的损失函数,用独立的超参数α和β取代原来的耦合项,从而更灵活地进行知识蒸馏。
各部分细节:
输入: 教师模型的Logits (l_tea) 和学生模型的Logits (l_stu)。
重构过程 (Reformulation):
1.TCKD的定义: 首先计算教师和学生模型对于“目标类 vs 非目标类”的二元概率分布。TCKD就是这两个二元分布之间的KL散度。它关注的是模型区分“对”与“错”的宏观能力。
2.NCKD的定义: 仅考虑所有非目标类别,将它们的Logits进行一次新的Softmax,得到一个在非目标类别上的概率分布。NCKD就是教师和学生在这个新分布上的KL散度。它关注的是模型在犯错时,认为“哪个错的更靠谱一些”的细粒度知识,即“暗知识”。
DKD损失函数:
将TCKD和NCKD通过超参数α和β进行线性组合,形成最终的DKD损失。
L_DKD = α * TCKD + β * NCKD
这个损失函数与标准的交叉熵损失一起,共同用于训练学生模型。
输出: 一个经过DKD方法训练好的、性能更强的学生模型。
3. 实验 Experimental Results
实验数据集:
图像分类: CIFAR-100, ImageNet
目标检测: MS-COCO
核心实验与结论:
1.实验目的:分析TCKD和NCKD的独立作用。
结论: 单独使用NCKD的效果就与经典KD相当甚至更好,证明了“暗知识”的重要性。单独使用TCKD在简单数据集上效果不佳甚至有害,但在困难的训练数据(如强数据增强、噪声标签、复杂数据集)上能带来显著增益。这验证了TCKD传递的是关于“样本难度”的知识。
2.实验目的:验证经典KD对NCKD的抑制作用。
结论: 实验证明,在教师最自信(最容易预测正确)的样本上传递的知识最有价值。而经典KD恰恰在这些样本上对NCKD的抑制最强。这揭示了其设计的根本缺陷。
3.实验目的:验证DKD的有效性。
结论: 在所有任务和数据集上,DKD都显著优于经典的KD方法。在图像分类任务上,DKD的性能可以媲美甚至超越许多复杂的基于特征的方法。在目标检测任务上,DKD也能提升性能,当与基于特征的方法结合时,可以取得新的SOTA结果。
4.实验目的:评估DKD的效率和扩展性。
结论: DKD的训练开销与经典KD几乎完全相同,远低于基于特征的方法。此外,DKD还有助于缓解“大模型老师不一定教出好学生”的问题,因为它避免了更自信的大模型对NCKD的过度抑制
4. 总结 Conclusion
经典知识蒸馏(KD)并非完美,其耦合的数学形式限制了其性能。知识可以被解耦为“目标类知识”(关于样本难度)和“非目标类知识”(暗知识),后者在经典KD中被严重压制。通过DKD这种简单、无额外成本的解耦方法,可以大幅释放Logits蒸馏的潜力,使其成为一种极具竞争力的SOTA方法。