虹膜边缘预测函数
基础内容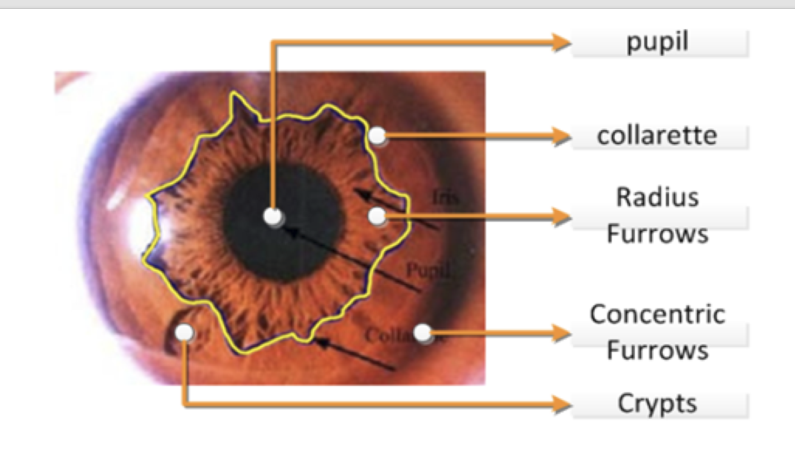
Collarette 是什么?虹膜卷缩轮
-
中文名:虹膜卷缩轮(或简称“卷缩轮”)。这个名字形象地描述了它的外观——像一圈褶皱、收缩的轮状边界。
-
位置:它位于虹膜的中间区域,大致上将虹膜分成了两个区域:
-
瞳孔区:Collarette 的内侧,最靠近瞳孔的部分。
-
睫状区:Collarette 的外侧,靠近眼睛白色部分(巩膜)的区域。
-
-
外观:它看起来像一个锯齿状、荷叶边或花边状的环。它是虹膜最厚的部分,也是虹膜表面起伏最大的地方。虹膜的小坑(隐窝)和辐射状的皱褶通常都以卷缩轮为起点或终点。
2. 虹膜是什么?
-
中文名:就是虹膜,也被称为“虹彩”。
-
位置:眼睛角膜之后、晶状体之前的一个圆形薄膜。我们所说的“眼睛的颜色”(如棕色、蓝色、绿色等)就是指虹膜的颜色。
-
功能:虹膜中央的圆孔就是瞳孔。虹膜内含有的肌肉可以控制瞳孔的大小,就像相机的光圈一样,调节进入眼睛的光线量。
生动的比喻
为了更好地理解,我们可以做一个比喻:
-
把整个虹膜想象成一个箭靶。
-
最中心的黑孔就是瞳孔。
-
而 Collarette(卷缩轮) 就是箭靶上那圈将靶心区域和外围区域分开的最明显的环线。
总结
| 术语 | 中文名 | 关系 | 功能 |
|---|---|---|---|
| Iris | 虹膜 | 整体 | 决定眼睛颜色,控制瞳孔大小 |
| Collarette | 虹膜卷缩轮 | 虹膜上的一个组成部分(一个环状隆起) | 是虹膜解剖结构上的重要分界线,在虹膜学中有特殊意义 |
所以,下次当您看到眼睛的特写照片时,可以仔细找找这个有趣的结构:在有色虹膜的中央区域,围绕着瞳孔的那一圈锯齿状的“衣领花边”,它就是 Collarette。
Pupil 的中文是 瞳孔。
它是位于眼睛虹膜(即眼珠有颜色的部分)正中央的一个圆形开口。
详细解释
您可以把它想象成相机的光圈:
-
结构:瞳孔本身不是一个实体结构,而是一个孔洞。它由周围的虹膜肌肉控制。
-
功能:瞳孔的主要功能是控制进入眼睛的光线量。
-
光线强时(例如在阳光下):虹膜内的瞳孔括约肌收缩,使瞳孔缩小(收缩),以减少进入眼睛的光线,保护视网膜不被强光伤害。
-
光线弱时(例如在黑暗处):虹膜内的瞳孔开大肌收缩,使瞳孔放大(扩张),以允许更多的光线进入眼睛,从而在昏暗环境下看得更清楚。
-
-
外观:我们看到的瞳孔通常是黑色的,这是因为光线通过瞳孔进入眼睛后,几乎全部被吸收,很少有光线反射出来。眼科医生用专门的灯光照射时,可以看到瞳孔后面视网膜发出的红光(即“红眼”照片的效果)。
与之前提到的 Collarette 和 Iris 的关系
这三个术语是紧密相关的眼部结构:
-
Iris (虹膜):是眼睛的有色部分(棕色、蓝色、绿色等),是一圈圆形的肌肉薄膜。
-
Pupil (瞳孔):是虹膜中央的黑色圆孔。
-
Collarette (卷缩轮):是虹膜表面的一个隆起环,它将虹膜分成了内侧的瞳孔区和外侧的睫状区。它围绕着瞳孔。
简单来说:瞳孔是虹膜中央的洞,而卷缩轮是虹膜上围绕这个洞的一个特殊环状结构。
总结
| 英文 | 中文 | 定义 |
|---|---|---|
| Pupil | 瞳孔 | 虹膜中央的圆形开口,根据光线强弱收缩或扩张,以控制进光量。 |
| Iris | 虹膜 | 眼睛的有颜色部分,通过肌肉运动控制瞳孔的大小。 |
| Collarette | 虹膜卷缩轮 | 虹膜表面的一个环状隆起,是虹膜解剖结构的分界线。 |
希望这次的解释也能帮到您!如果您还有其他关于眼睛结构的疑问,随时可以提出。
Iris 的中文是 虹膜。
它是眼睛中部,角膜(透明的外层)和晶状体(内部的聚焦结构)之间的圆形薄膜。我们平常所说的“眼睛的颜色”就是指虹膜的颜色。
详细解释
您可以将虹膜想象成相机中的可调节光圈:
-
结构:
-
虹膜是一个由平滑肌构成的环状薄膜。
-
它含有色素细胞,这些色素的种类和密度决定了眼睛的颜色(如棕色、蓝色、绿色、灰色等)。
-
虹膜中央的圆形开口就是瞳孔。
-
-
功能:
-
控制进光量:这是虹膜最主要的功能。它通过肌肉的收缩和舒张来改变瞳孔的大小,就像相机的光圈一样:
-
光线强时(如在阳光下):虹膜肌肉收缩,使瞳孔缩小,以减少进入眼睛的光线,保护视网膜。
-
光线弱时(如在黑暗处):虹膜肌肉舒张,使瞳孔放大,以允许更多光线进入,从而在暗处看得更清楚。
-
-
审美与识别:独特的虹膜纹理和颜色构成了每个人眼睛的独特外观,也是生物识别技术(如虹膜识别)的基础。
-
-
外观:
-
虹膜表面有复杂的纹理、辐射状的皱褶和环状的沟壑,这些特征每个人都是独一无二的。
-
我们之前讨论的 Collarette(卷缩轮)就是虹膜表面一个重要的环状隆起结构,它将虹膜分为内部的瞳孔区和外部的睫状区。
-
与其他结构的关系
这三个术语构成了眼睛的核心调节系统:
-
Iris (虹膜):是 “有颜色的阀门” ,本身会动。
-
Pupil (瞳孔):是虹膜中央的 “可大可小的孔” ,是光线进入的实际通道。
-
Collarette (卷缩轮):是虹膜表面的 “标志性纹理” ,是虹膜解剖上的一个重要分界线。
简单来说:虹膜是控制瞳孔大小的彩色肌肉环。
Radius Furrows 的中文是 (虹膜)沟。
它指的是虹膜表面那些凹陷的、线状的纹理或褶皱。您可以把它想象成皮肤上的皱纹,但这是虹膜上正常的生理结构。
详细解释
-
外观与类型:
-
Furrows 是虹膜上相对凹陷、颜色较深的线条。
-
它们主要有两种类型:
-
收缩沟:这是最常见的一种。它们通常呈现为从瞳孔向外周呈放射状、弯曲的弧线,像车轮的辐条一样。这些沟的深度和宽度会随着瞳孔的大小变化而改变。
-
结构沟:这类沟是更永久、更深的凹陷,其形态不随瞳孔收缩而变化。
-
-
-
功能:
-
增加弹性与适应性:虹膜是一个需要不断收缩和舒张的肌肉薄膜。这些沟壑(收缩沟)的存在,就像手风琴的风箱或布料上的褶皱一样,为虹膜的伸缩提供了额外的“余量”,使其能够更灵活、更大幅度地改变形状,从而精确控制瞳孔的大小。
-
增加表面积:沟壑结构增加了虹膜的表面积,可能有助于房水(眼内的液体)的交换和循环。
-
-
与 Collarette 的关系:
-
Collarette 是一个环状的隆起结构,它像一个边界,将虹膜分成内外两区。
-
Furrows 通常是放射状的凹陷线条,它们常常从 Collarette 附近开始,向虹膜外周延伸。
-
您可以这样理解:Collarette 是虹膜上“横向”的标志,而 Furrows 是“径向”的纹理。
-
生动的比喻
为了更好地理解,请想象一下:
-
把虹膜想象成一件丝绸长裙的裙摆。
-
Collarette 就像是裙子上一条明显的横向装饰束带。
-
Furrows 就像是裙摆上自然形成的纵向褶皱和裙褶。当裙子收缩(瞳孔变小)时,这些褶皱会变得更密集、更深;当裙子展开(瞳孔变大)时,褶皱会变浅、舒展开来。
Concentric Furrows 的中文可以翻译为 同心(性)沟 或 同心圆沟。
它指的是虹膜上一种特殊的、呈环状或圆弧状的沟壑,这些沟壑与瞳孔边缘大致平行,像箭靶上的环线或树木的年轮。
详细解释与特点
与之前提到的常见的放射状沟纹不同,同心沟有其独特之处:
-
外观:
-
它们不是从瞳孔向外放射的,而是围绕着瞳孔的、一圈一圈的环状或半环状的凹槽。
-
它们可能是不完整的弧线,也可能形成完整的闭环。
-
通常颜色比周围虹膜组织更深,看起来像一道深深的褶皱。
-
-
位置:
-
最常见于睫状区,也就是卷缩轮(Collarette)以外的虹膜外周区域。
-
-
形成原因:
-
与主要为了适应瞳孔伸缩而形成的放射状收缩沟不同,同心沟通常被认为是一种相对永久性的结构沟。
-
它的形成可能与虹膜自身的结构张力、发育因素或长期的适应性变化有关。
-
同心沟 vs. 放射状收缩沟
这是一个重要的区别,可以通过下表清晰对比:
| 特征 | 同心沟 | 放射状收缩沟 |
|---|---|---|
| 走向 | 环状,与瞳孔边缘平行 | 放射状,从瞳孔向外周延伸 |
| 形状 | 像洋葱圈或树木年轮 | 像车轮的辐条或太阳的光芒 |
| 变化 | 相对固定,不随瞳孔大小剧烈变化 | 动态变化,随瞳孔收缩/舒张而变深/变浅 |
| 主要功能 | 更多是结构性的 | 功能性的,为虹膜伸缩提供弹性 |
在虹膜学中的解读(请注意区分)
在虹膜学(一种替代疗法,认为虹膜图案可以反映身体健康状况)中,同心沟有特定的解读,通常被称为 “焦虑圈”或“压力环” 。
-
解读:虹膜学家认为,密集的同心沟可能表示一个人长期处于神经紧张、焦虑、压力或痉挛性体质的状态。他们认为这种图案反映了身体对应部位的神经张力过高。
-
重要提示:虹膜学并非现代循证医学的一部分,其理论和有效性未被主流科学界所广泛接受。 在临床眼科中,医生更关注同心沟作为虹膜的一个解剖特征,而非其 purported 的诊断意义。
总结
-
Concentric Furrows 是虹膜上一种环状的、与瞳孔平行的沟壑。
-
它与更常见的放射状沟纹在走向和功能上都有明显区别。
-
它是虹膜的正常结构变异之一,但在替代疗法虹膜学中有其特殊的解读。
所以,如果您在虹膜上看到像细密年轮一样的环状线,那就是 同心沟。它和像车轮辐条一样的 放射状收缩沟 共同构成了虹膜复杂而独特的纹理。
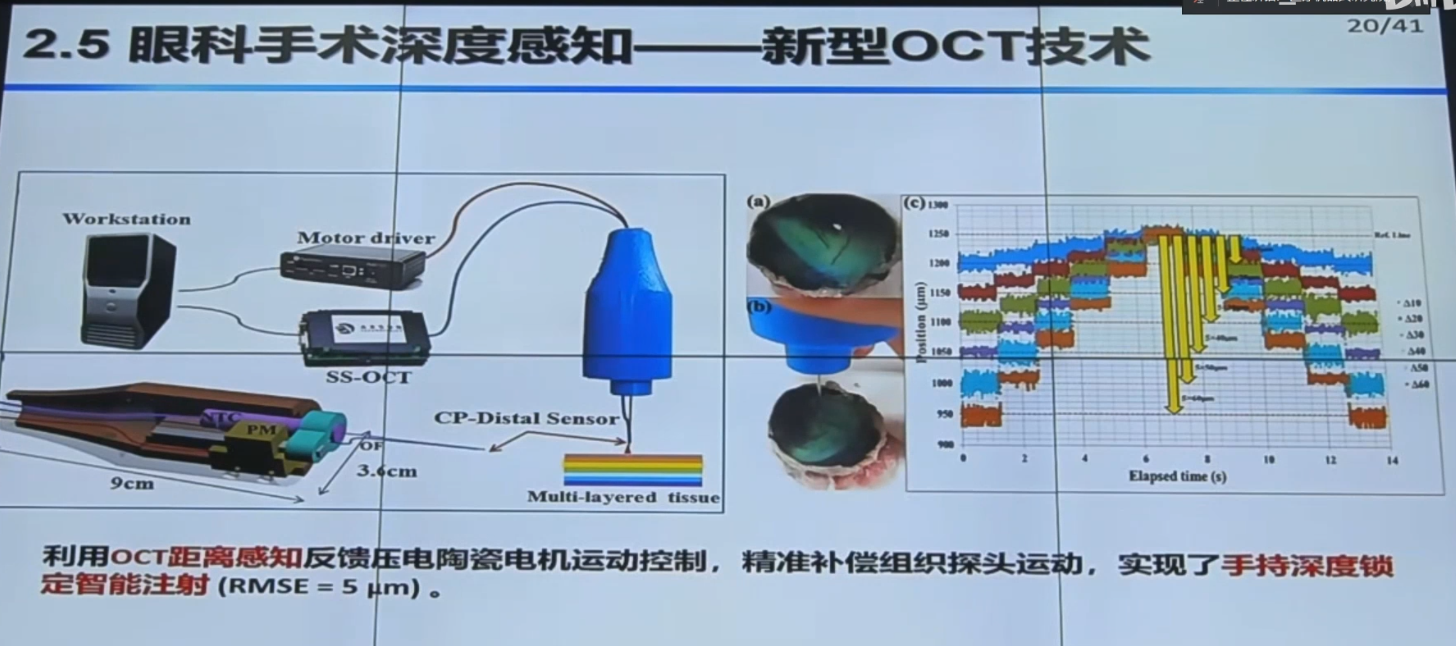
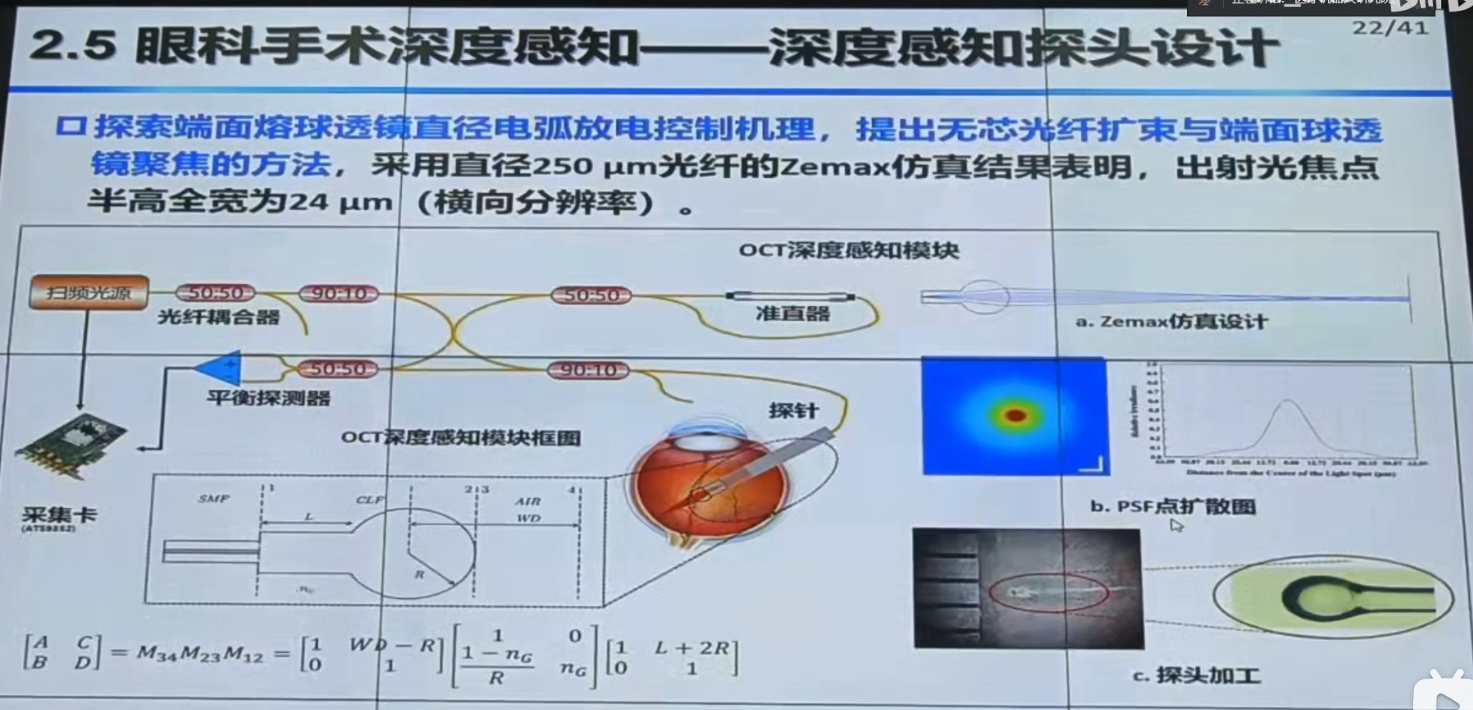
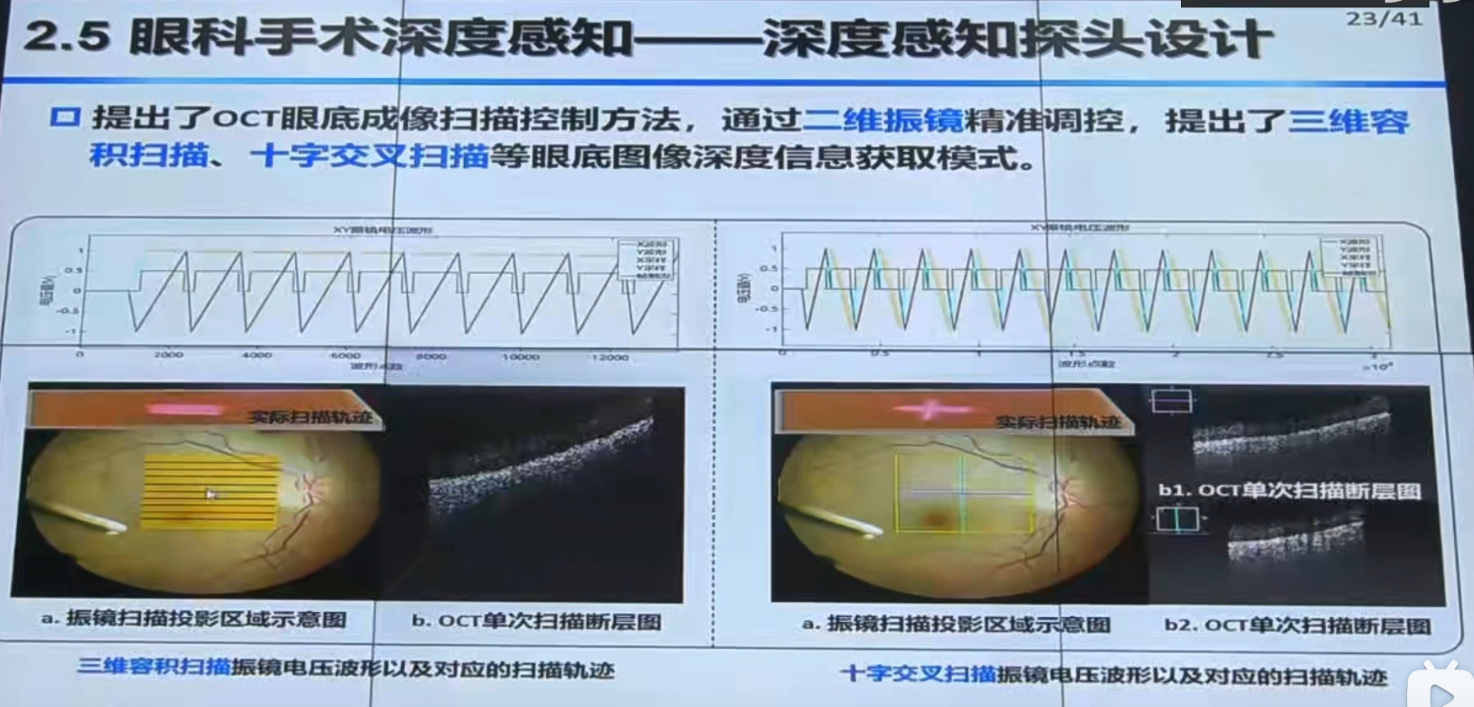
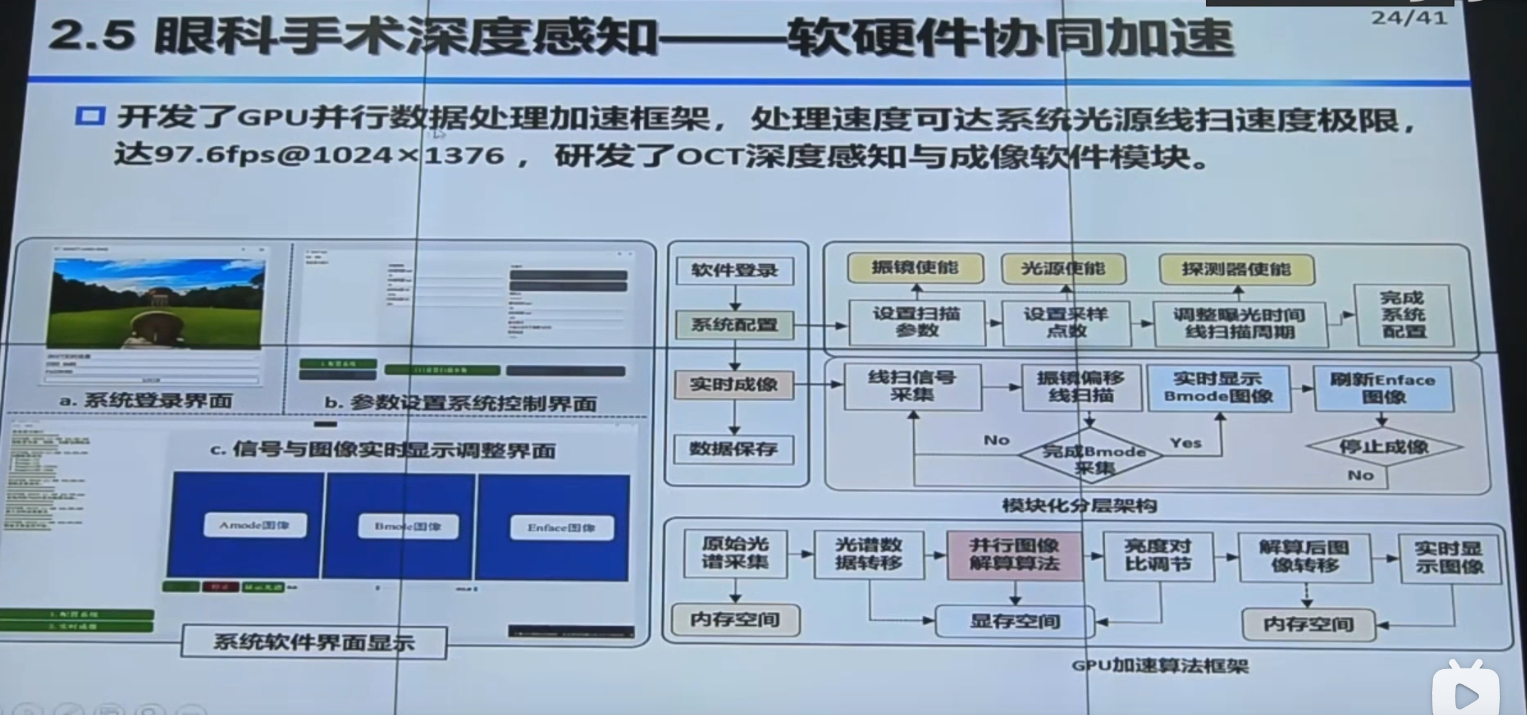
b站视频
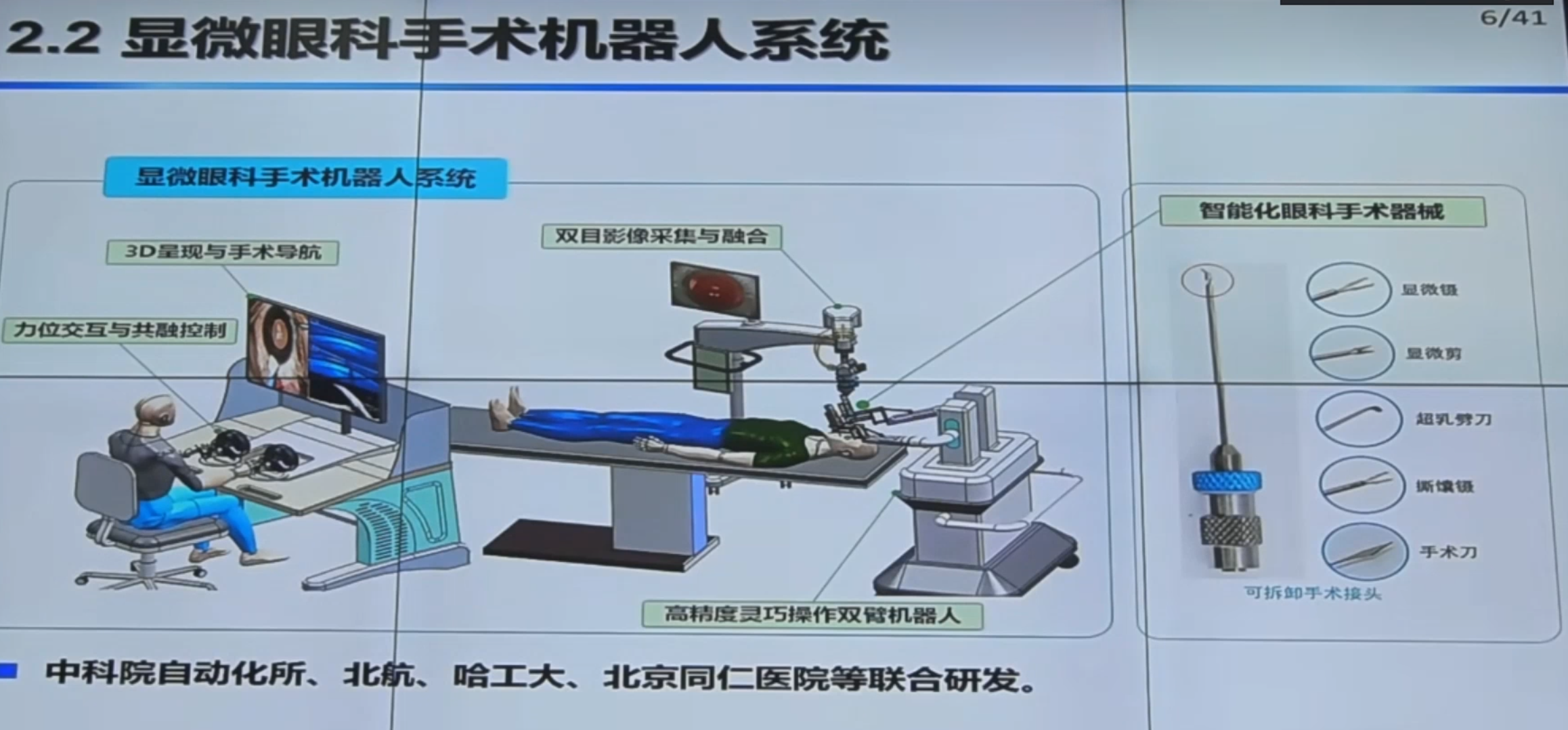
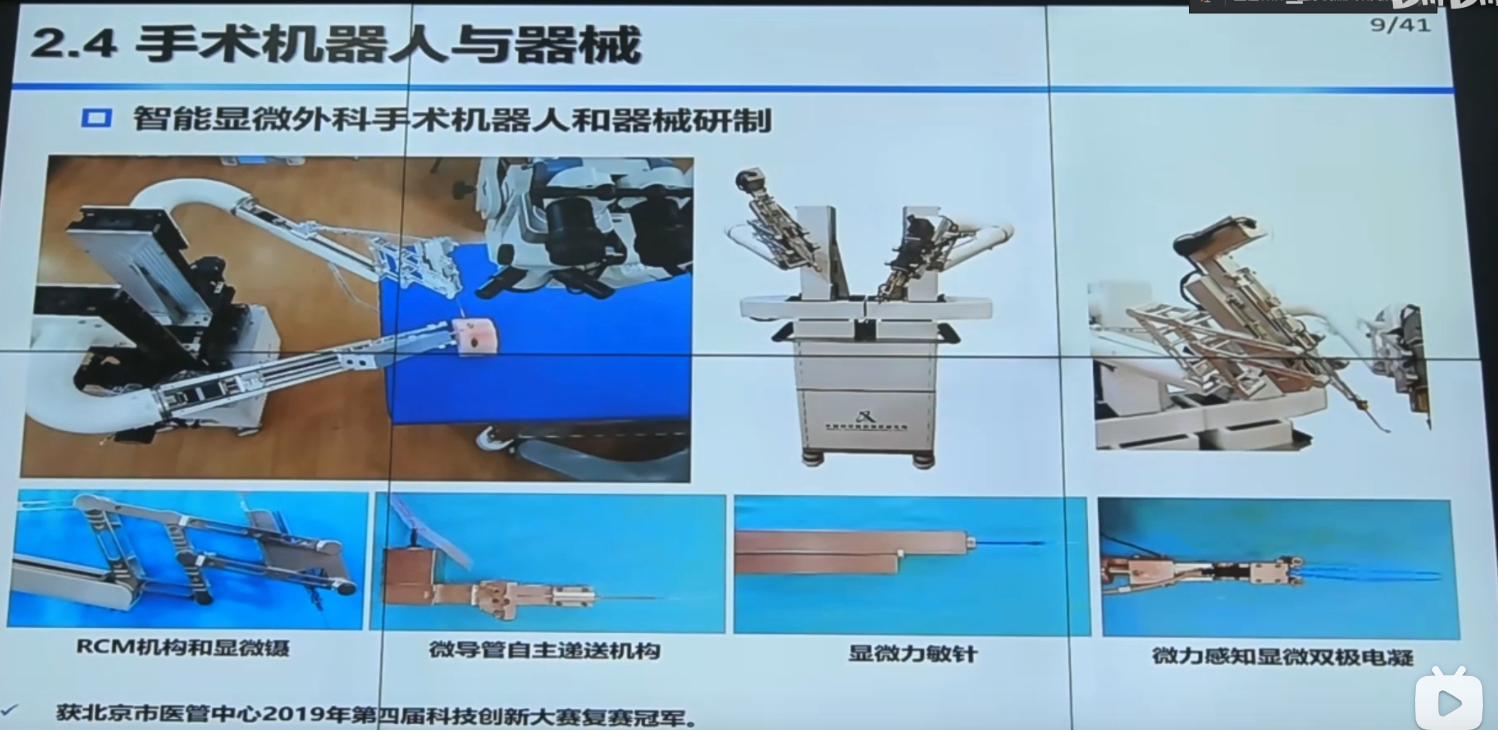
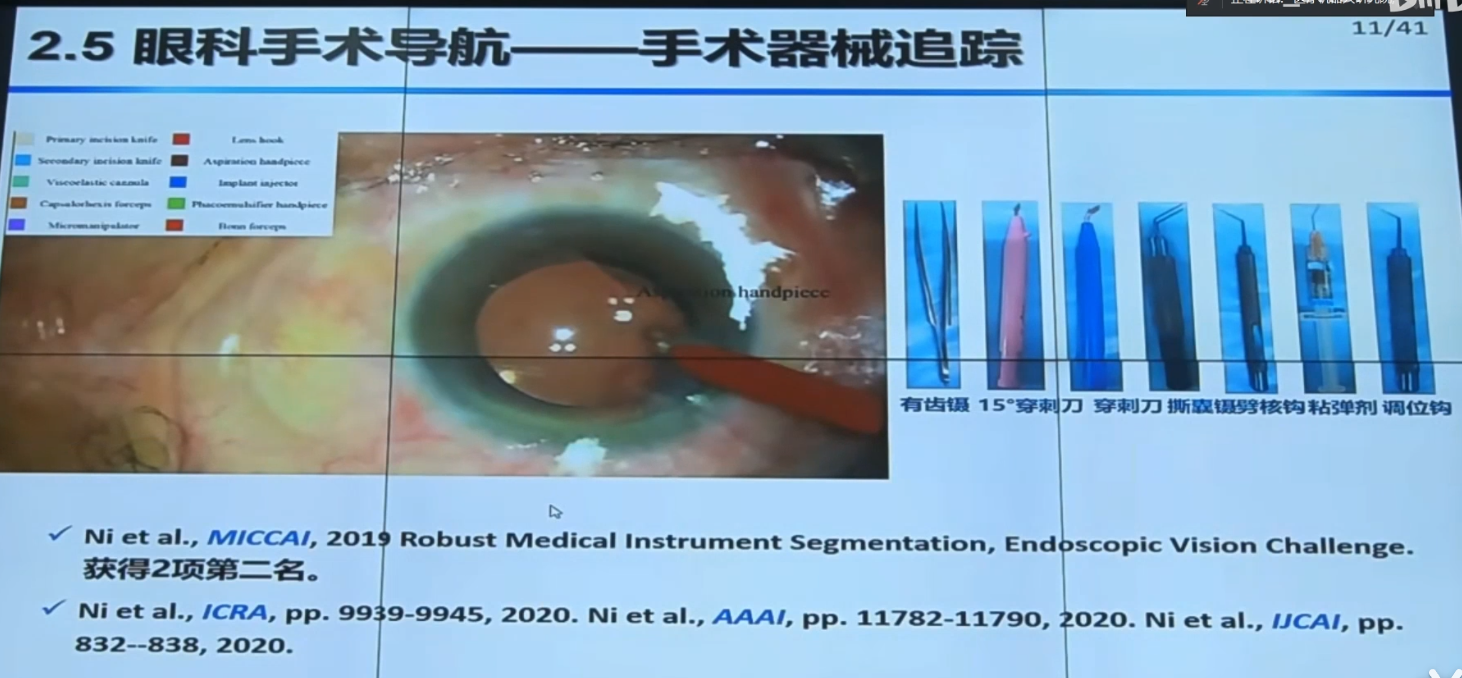
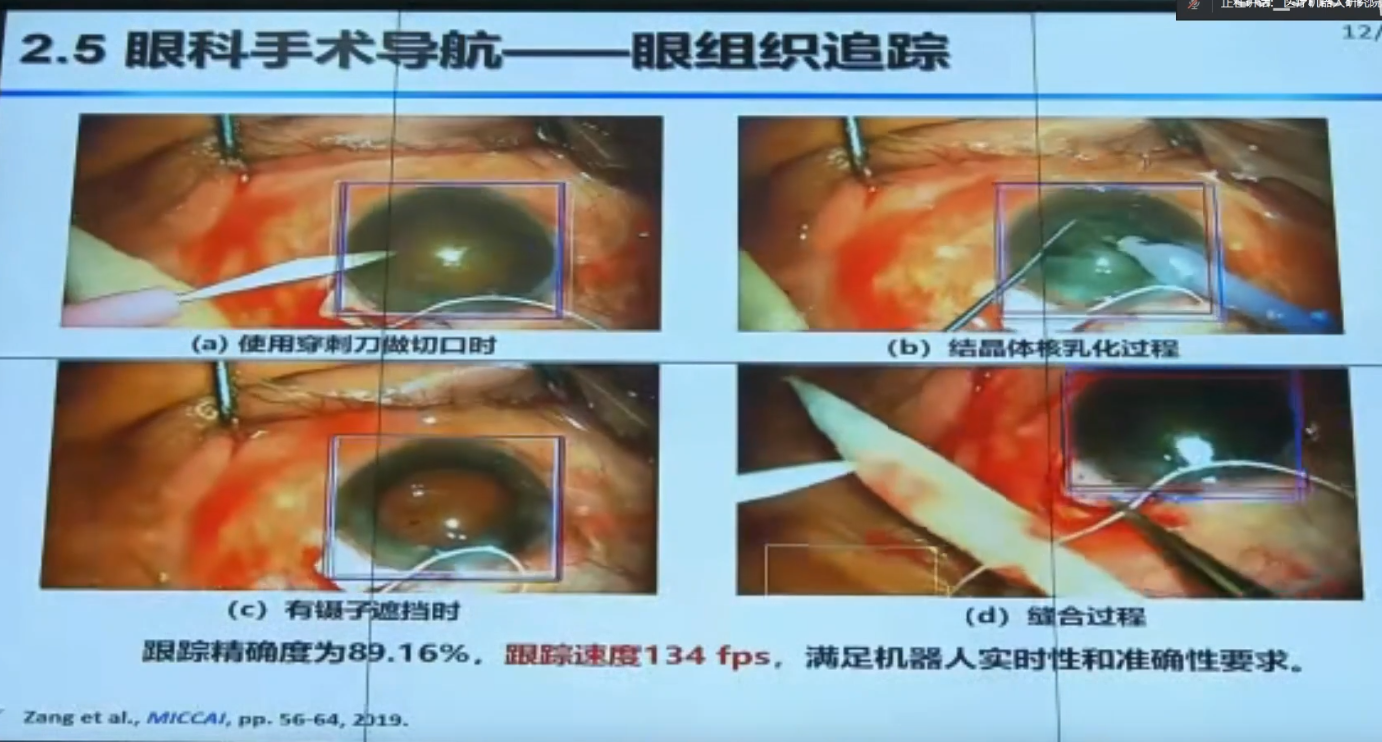
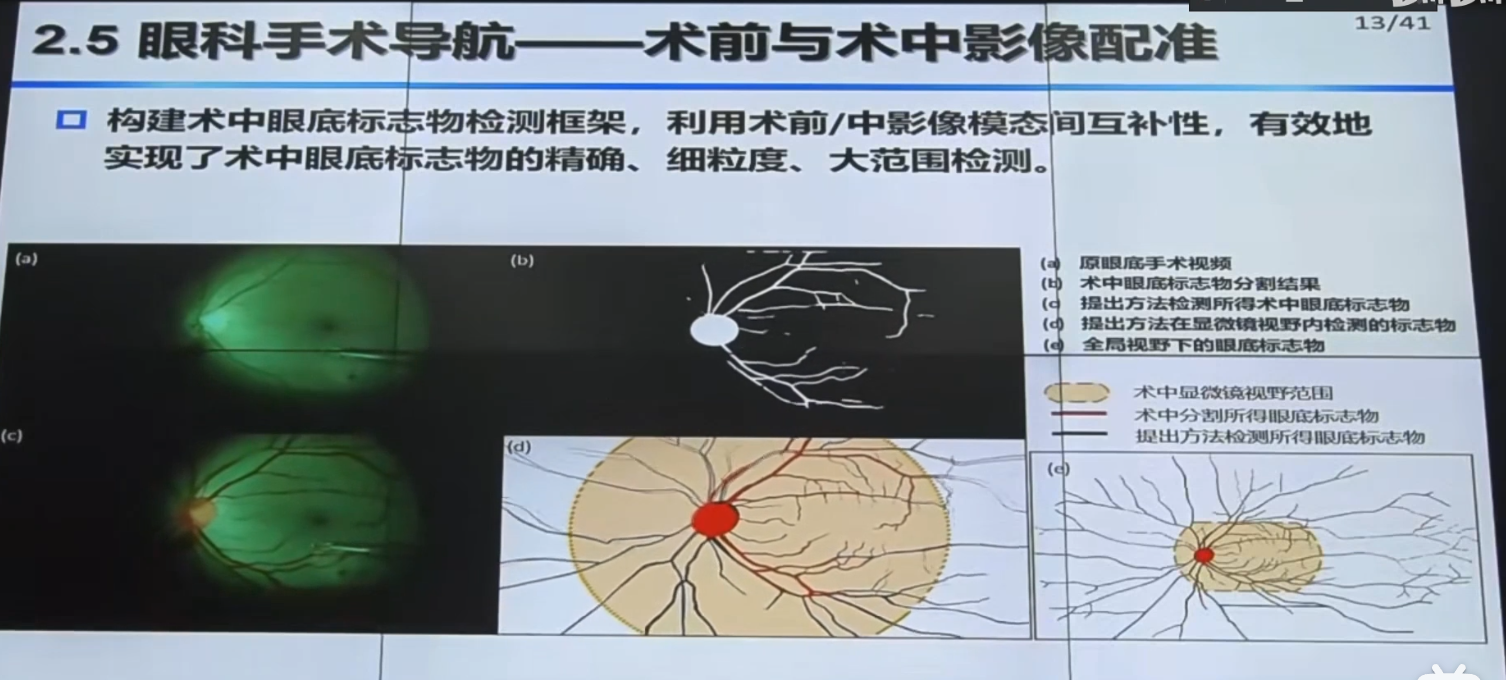
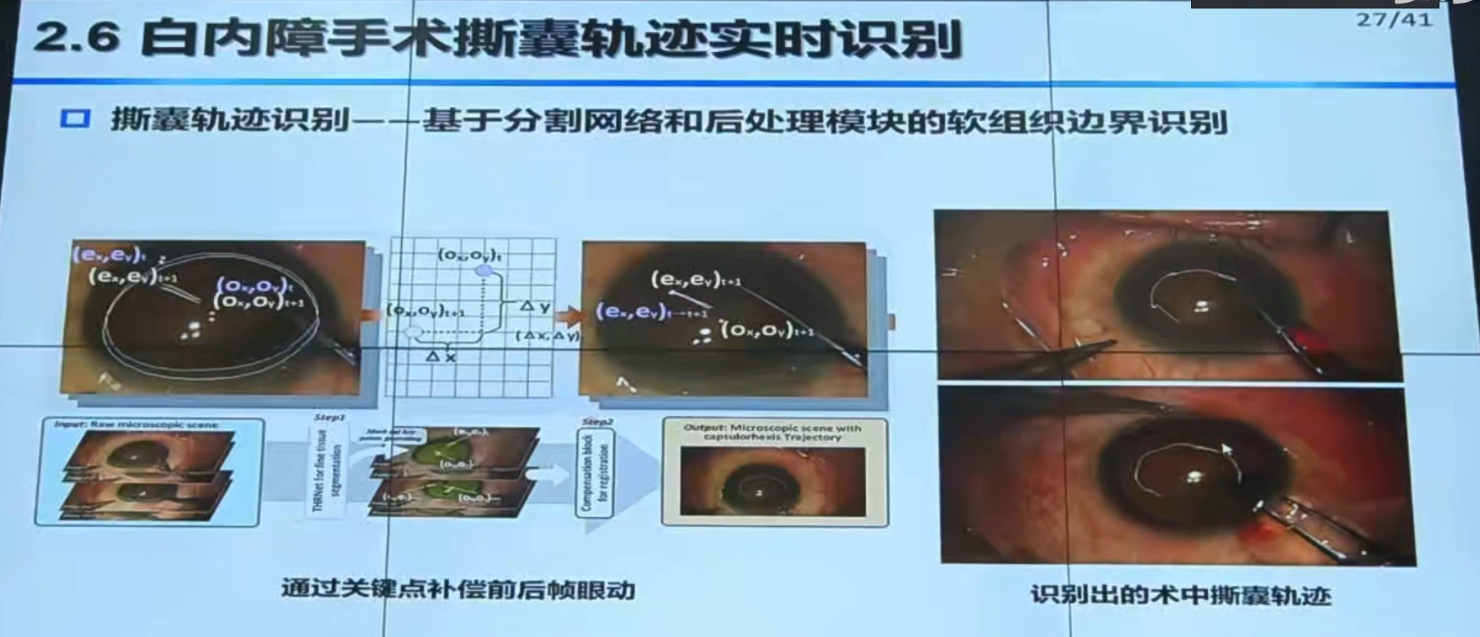
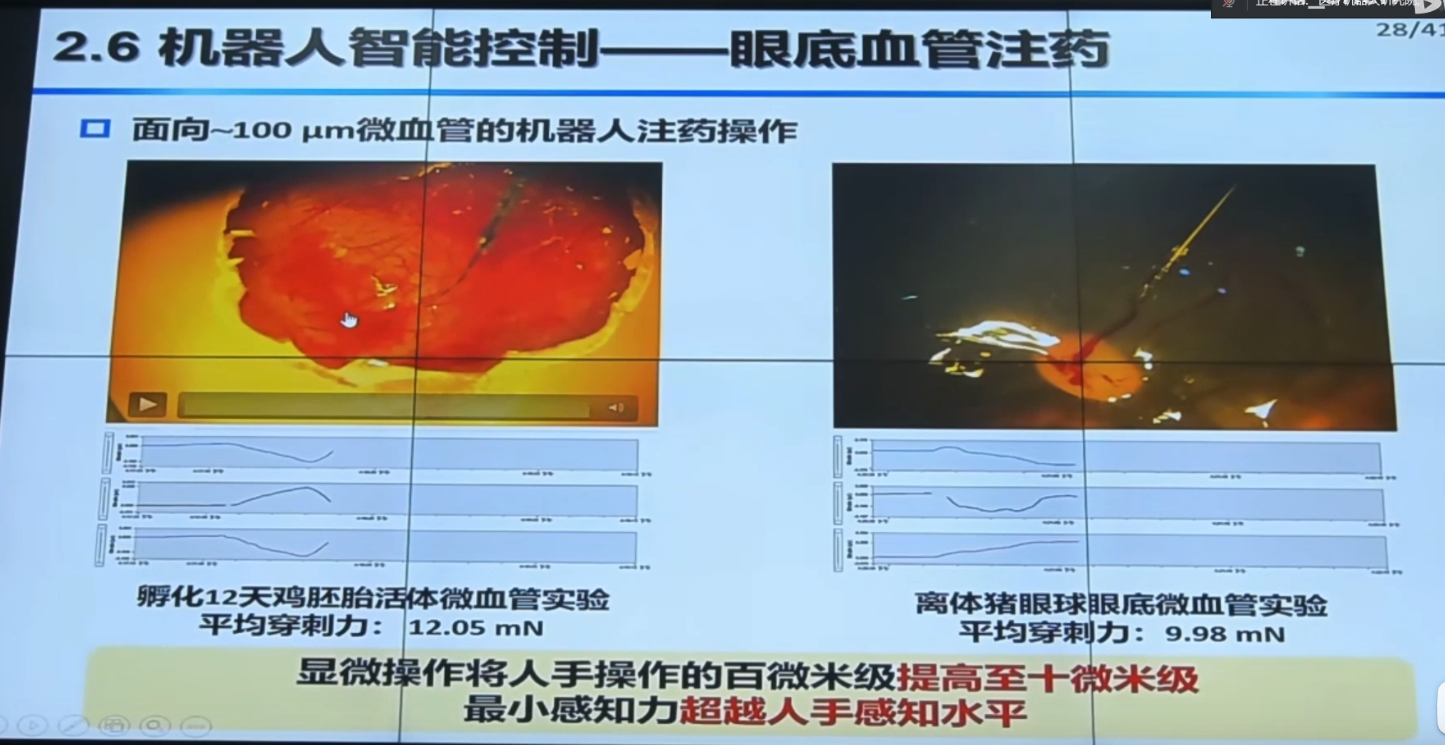
【手术机器人】中国科学院自动化研究所边桂彬:显微眼科手术机器人智能感知与控制_哔哩哔哩_bilibili

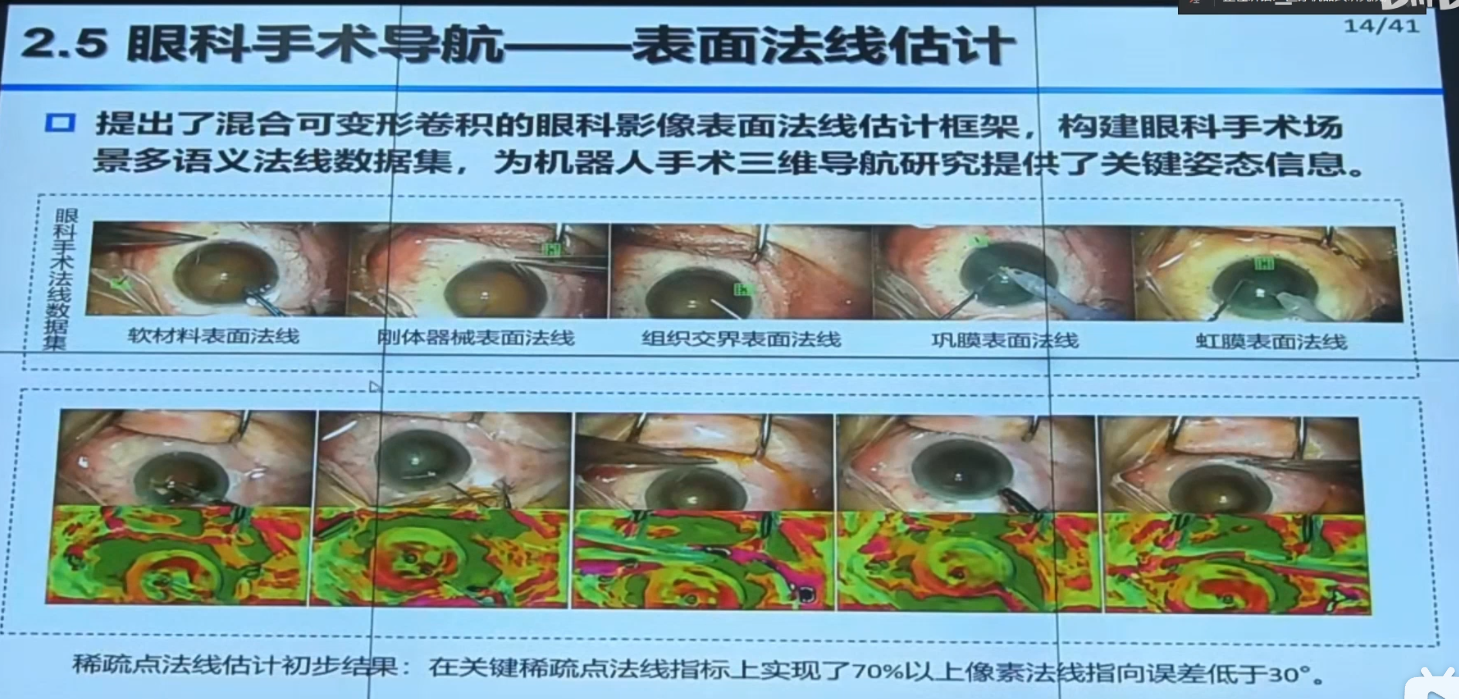
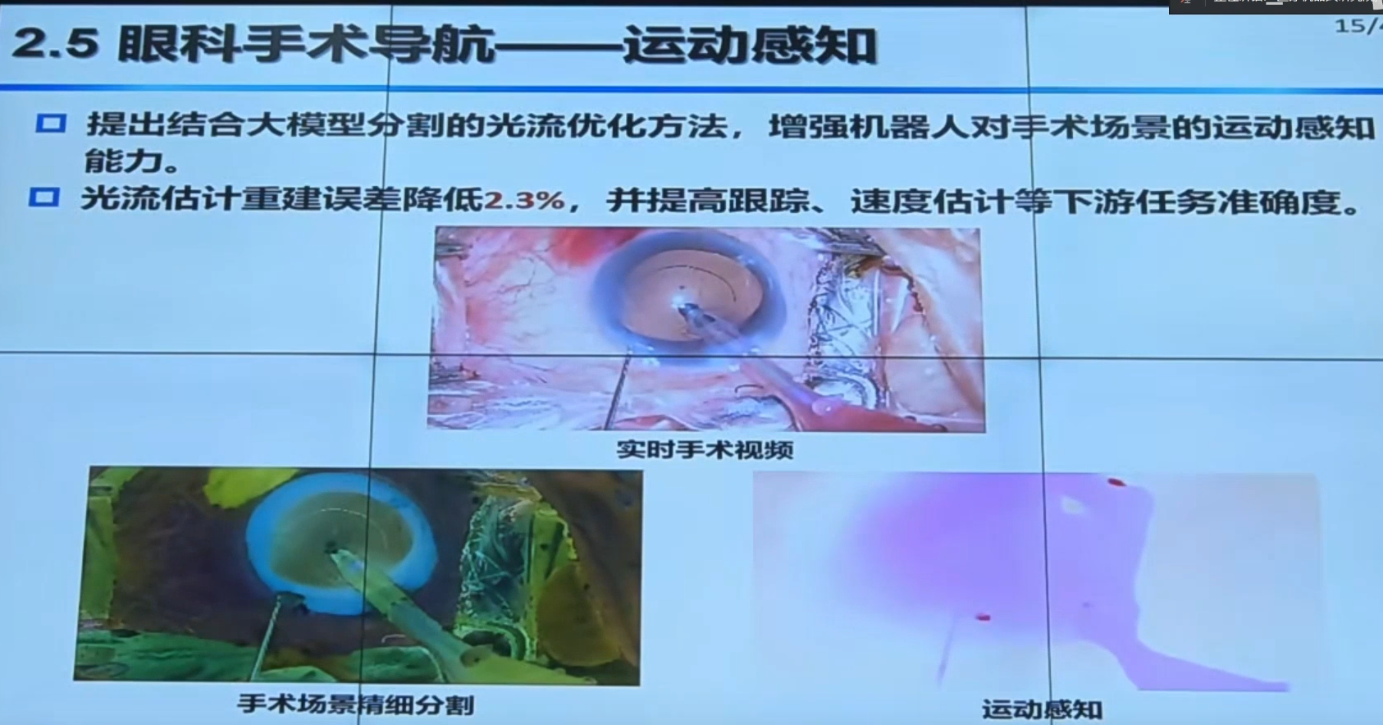
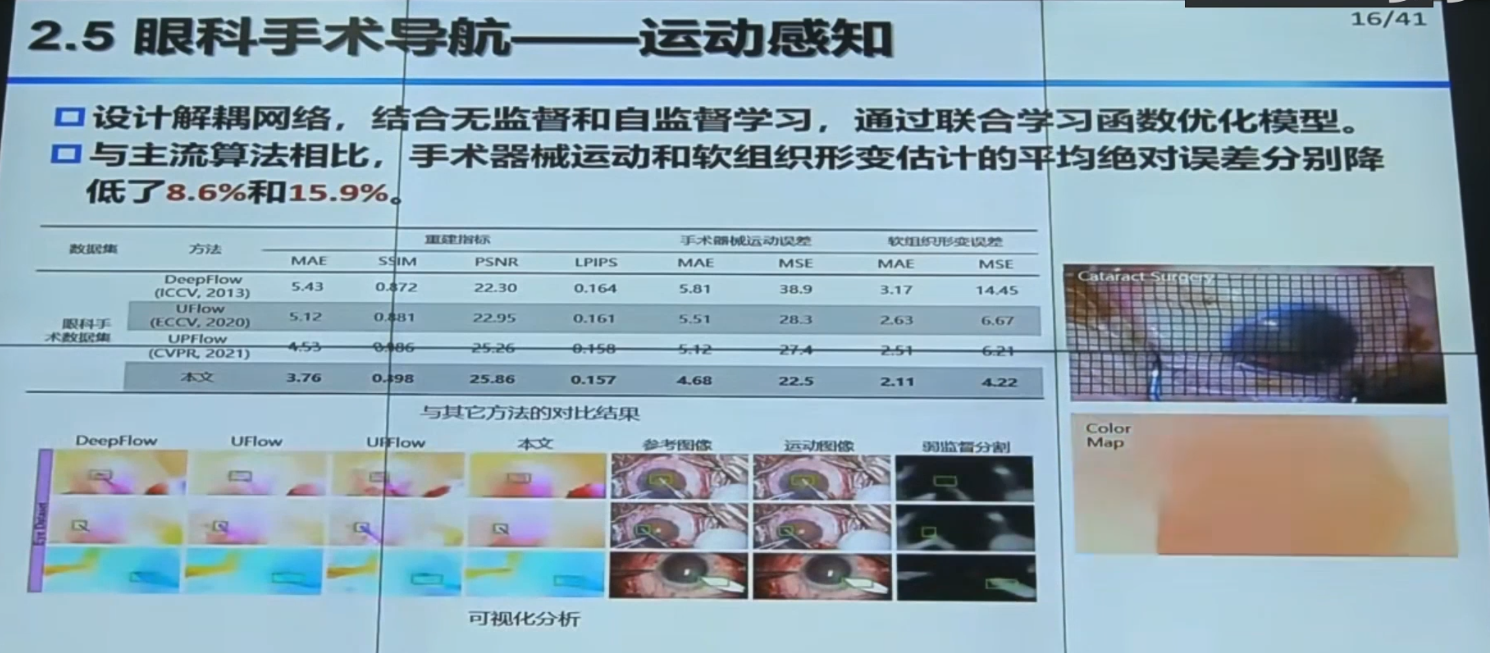




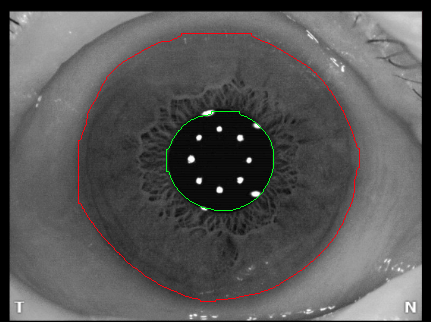
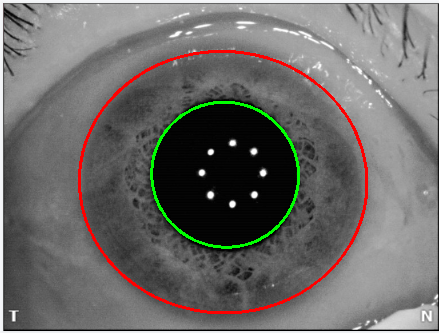
掩码本质上就是由大量点(或更准确地说,像素)组成的。
1. 掩码的本质:一个二维矩阵
想象一下一张Excel表格,每个格子代表图像上的一个像素。掩码就是一张这样的“表格”(二维矩阵),它的尺寸通常比原始图像小(例如可能是原图的1/4、1/8等,这是模型下采样的结果)。
-
表格中的每个值:代表其对应位置的像素“属于目标物体的概率”。
-
值的范围:通常是 0.0 到 1.0。
-
值 ≈ 1.0:这个像素点非常有可能是目标物体的一部分。
-
值 ≈ 0.0:这个像素点非常有可能属于背景。
-
值 around 0.5:模型不太确定。
-
在您的代码中,result.masks.data 获取到的就是这样一个二维概率矩阵(实际上是多个,每个检测到的对象都有一个)。
2. 从概率矩阵到二值图像
代码中关键的一步是将这个“概率矩阵”转换为“二值图像”:
mask_resized = cv2.resize(mask, (image.shape[1], image.shape[0]))
mask_binary = (mask_resized > 0.5).astype(np.uint8)-
cv2.resize: 首先将小尺寸的掩码矩阵放大到原始图像的精确尺寸(宽 x 高)。这样掩码矩阵中的每一个点(值)就与原始图像上的每一个像素一一对应了。 -
(mask_resized > 0.5).astype(np.uint8): 这是一个阈值化操作。它遍历放大后矩阵中的每一个点(值):-
如果值 > 0.5,则认为这个像素属于物体,将其设置为
1(白色)。 -
如果值 <= 0.5,则认为这个像素属于背景,将其设置为
0(黑色)。
-
-
最终得到的
mask_binary就是一个只由0和1组成的二维数组,这就是一个标准的二值图像,其中白色区域(值为1的点)就精确地定义了物体的形状。
3. 从二值图像到轮廓(点集)
得到了物体的精确形状(二值图)后,下一步就是找到它的轮廓,也就是勾勒出形状的边界线。
contours, _ = cv2.findContours(mask_binary, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)-
cv2.findContours()函数的工作就是在mask_binary这个由0和1组成的“点阵”中,寻找白色区域(值为1的点)的边界。 -
轮廓(Contour)是什么? 它正是由一系列点组成的集合。这些点按照顺序连接起来,就形成了一条封闭的、勾勒出物体外形的多边形曲线。
-
cv2.CHAIN_APPROX_SIMPLE:这个参数很重要,它会对轮廓进行压缩,只保留轮廓拐角处的关键点(例如,一条直线的轮廓只需要起点和终点两个点),从而大大减少组成轮廓的点的数量,节省内存。如果不压缩(cv2.CHAIN_APPROX_NONE),轮廓会包含边界上所有的像素点,数据量会非常大。
-
-
所以,
contours变量里存储的就是一个列表,列表中的每个元素都是一个轮廓,而每个轮廓本身又是一个由点坐标(x, y)组成的数组。
4. 绘制轮廓
最后,代码将这些点连接起来,画在图像上:
cv2.drawContours(result_image, contours, -1, color, line_thickness)这个函数读取 contours 中的那些点,按照顺序用指定颜色和粗细的线条将它们连接起来,最终形成您在输出图像上看到的平滑轮廓。
总结与类比
| 步骤 | 数据形式 | 描述 | 类比 |
|---|---|---|---|
| 1. 模型输出 | 概率矩阵 (小尺寸) | 由很多小数(0.0-1.0)组成的网格 | 一张模糊的、低分辨率的形状热力图 |
| 2. 调整尺寸 | 概率矩阵 (原图尺寸) | 放大网格,使其与原图像素对齐 | 将低分辨率热力图放大到原图大小,变得模糊 |
| 3. 二值化 | 二值图像 (原图尺寸) | 由0和1组成的网格,定义了物体区域 | 用剪刀沿着一个阈值把模糊的热力图剪成一个清晰的黑白剪影 |
| 4. 查找轮廓 | 轮廓点集 | 一系列有序的(x,y)坐标点 | 沿着黑白剪影的边缘贴上一条发光的灯带,灯带由许多灯泡(点)组成 |
| 5. 绘制轮廓 | 最终图像 | 将轮廓点用线连接起来 | 只看灯带勾勒出的形状,而不看剪影的内部 |
所以,您的理解完全正确:掩码最终被处理成了由一系列点组成的轮廓。这种方式比直接绘制整个填充的掩码计算效率更高、结果更清晰(只有一个漂亮的轮廓线)、并且生成的文件体积更小。
如果你有多个类别(例如虹膜和瞳孔),它们会以不同的颜色绘制轮廓。
 .
.
代码如下:
from ultralytics import YOLO
import os
import cv2
import numpy as np
from pathlib import Pathdef predict_images(model_path, source_dir, output_dir, conf_threshold=0.25, line_thickness=2, fit_ellipse=True):"""使用训练好的YOLOv8分割模型批量预测图像,可选择绘制分割轮廓或椭圆拟合参数:model_path: 训练好的模型路径 (.pt文件)source_dir: 包含待预测图像的文件夹路径output_dir: 保存预测结果的输出文件夹路径conf_threshold: 置信度阈值line_thickness: 轮廓线粗细fit_ellipse: 是否进行椭圆拟合 (True/False)"""# 加载训练好的模型model = YOLO(model_path)# 创建输出目录os.makedirs(output_dir, exist_ok=True)# 获取所有图像文件image_extensions = ['.jpg', '.jpeg', '.png', '.bmp', '.tiff']image_files = []for ext in image_extensions:image_files.extend(Path(source_dir).glob(f"*{ext}"))image_files.extend(Path(source_dir).glob(f"*{ext.upper()}"))print(f"找到 {len(image_files)} 张图像")# 批量预测for i, image_path in enumerate(image_files):print(f"处理图像 {i+1}/{len(image_files)}: {image_path.name}")# 读取原始图像image = cv2.imread(str(image_path))if image is None:print(f"无法读取图像: {image_path}")continue# 进行预测results = model.predict(source=image,conf=conf_threshold,save=False,verbose=False)# 创建结果图像的副本result_image = image.copy()# 处理每个预测结果for result in results:if result.masks is not None:# 获取所有掩码masks = result.masks.data.cpu().numpy()# 为每个类别定义颜色colors = [(0, 255, 0), # 绿色 - 类别0(0, 0, 255), # 红色 - 类别1(255, 0, 0), # 蓝色 - 类别2(255, 255, 0), # 青色 - 类别3(255, 0, 255), # 紫色 - 类别4(0, 255, 255), # 黄色 - 类别5]# 处理每个分割掩码for j, (mask, box) in enumerate(zip(masks, result.boxes)):class_id = int(box.cls[0])confidence = float(box.conf[0])# 选择颜色color = colors[class_id % len(colors)]# 将掩码转换为二值图像mask_resized = cv2.resize(mask, (image.shape[1], image.shape[0]))mask_binary = (mask_resized > 0.5).astype(np.uint8)# 找到轮廓contours, _ = cv2.findContours(mask_binary, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)# 打印检测信息class_name = model.names[class_id]print(f" 对象 {j+1}: {class_name} (置信度: {confidence:.2f})")# 对每个轮廓进行处理for contour in contours:# 椭圆拟合需要至少5个点if len(contour) >= 5 and fit_ellipse:try:# 拟合椭圆ellipse = cv2.fitEllipse(contour)# 绘制椭圆cv2.ellipse(result_image, ellipse, color, line_thickness)print(f" ✓ 已对 {class_name} 进行椭圆拟合")except Exception as e:print(f" ✗ 椭圆拟合失败: {e}")# 如果椭圆拟合失败,回退到绘制原始轮廓cv2.drawContours(result_image, [contour], -1, color, line_thickness)else:# 如果点数不足或不进行椭圆拟合,绘制原始轮廓cv2.drawContours(result_image, [contour], -1, color, line_thickness)if len(contour) < 5:print(f" ⓘ 轮廓点不足 ({len(contour)}个点),无法进行椭圆拟合")# 保存结果图像output_path = os.path.join(output_dir, f"pred_{image_path.name}")cv2.imwrite(output_path, result_image)print(f"所有图像处理完成,结果保存在: {output_dir}")if __name__ == "__main__":# 设置路径和参数model_path = R"D:\job\Iris\模型\best.pt" # 替换为你的模型路径source_dir = R"D:\job\Iris\图片" # 替换为你的图像文件夹路径output_dir = R"D:\job\Iris\检测结果" # 替换为你的输出文件夹路径conf_threshold = 0.9 # 置信度阈值,可以根据需要调整line_thickness = 2 # 轮廓线粗细fit_ellipse = True # 是否进行椭圆拟合# 运行预测predict_images(model_path, source_dir, output_dir, conf_threshold, line_thickness, fit_ellipse)1. 函数概述
这是一个使用 YOLOv8 分割模型进行批量图像预测的函数,特别针对眼睛的瞳孔和同心沟等近似椭圆形的对象,提供了椭圆拟合功能来平滑轮廓。
2. 函数参数详解
def predict_images(model_path, source_dir, output_dir, conf_threshold=0.25, line_thickness=2, fit_ellipse=True):-
model_path: 训练好的 YOLOv8 模型路径(.pt 文件)
-
source_dir: 包含待预测图像的文件夹路径
-
output_dir: 保存预测结果的输出文件夹路径
-
conf_threshold: 置信度阈值,默认 0.25(只保留置信度高于此值的预测)
-
line_thickness: 轮廓线粗细,默认 2 像素
-
fit_ellipse: 是否进行椭圆拟合,默认 True(针对瞳孔和同心沟等椭圆形对象特别有用)
3. 代码执行流程分析
3.1 初始化阶段
model = YOLO(model_path)
os.makedirs(output_dir, exist_ok=True)-
加载预训练的 YOLOv8 分割模型
-
创建输出目录(如果不存在)
3.2 图像文件收集
这段代码用于从指定目录中收集所有具有特定图像扩展名的文件。让我们详细分析它的工作原理和特点:
image_extensions = ['.jpg', '.jpeg', '.png', '.bmp', '.tiff']
image_files = []
for ext in image_extensions:image_files.extend(Path(source_dir).glob(f"*{ext}"))image_files.extend(Path(source_dir).glob(f"*{ext.upper()}"))-
支持多种常见图像格式
-
使用
Path.glob()方法收集所有匹配的图像文件 -
同时处理大小写扩展名,确保兼容性
1. 图像扩展名定义
image_extensions = ['.jpg', '.jpeg', '.png', '.bmp', '.tiff']-
定义了一个包含常见图像文件扩展名的列表
-
支持的格式:
-
.jpg和.jpeg: JPEG 格式(联合图像专家组) -
.png: PNG 格式(便携式网络图形) -
.bmp: BMP 格式(位图) -
.tiff: TIFF 格式(标记图像文件格式)
-
2. 文件收集循环
for ext in image_extensions:image_files.extend(Path(source_dir).glob(f"*{ext}"))image_files.extend(Path(source_dir).glob(f"*{ext.upper()}"))2.1 Path 对象的使用
-
Path(source_dir): 创建一个 Path 对象,表示源目录的路径 -
Path 对象是 Python 的
pathlib模块提供的,比传统的os.path更现代化和易用
2.2 glob 模式匹配
-
glob(f"*{ext}"): 使用通配符模式匹配文件-
*: 匹配任意数量的任意字符 -
{ext}: 插入 -
当前扩展名(小写)
-
例如:当
ext是.jpg时,模式为*.jpg
-
-
glob(f"*{ext.upper()}"): 同样匹配,但使用大写的扩展名-
ext.upper(): 将扩展名转换为大写 -
例如:当
ext是.jpg时,模式为*.JPG
-
2.3 extend 方法
-
image_files.extend(...): 将匹配到的文件列表添加到image_files中 -
使用
extend()而不是append()是因为glob()返回的是列表,我们需要将列表元素逐个添加,而不是将整个列表作为一个元素添加
3. 代码执行流程
-
初始化一个空列表
image_files来存储找到的图像文件 -
遍历
image_extensions列表中的每个扩展名 -
对于每个扩展名:
-
使用小写扩展名模式匹配文件(如
*.jpg) -
使用大写扩展名模式匹配文件(如
*.JPG) -
将匹配到的文件添加到
image_files列表中
-
-
循环结束后,
image_files包含所有匹配的图像文件
print(f"找到 {len(image_files)} 张图像")1. print() 函数
-
功能: Python 内置函数,用于将指定的消息输出到标准输出设备(通常是屏幕)
-
作用: 在程序执行过程中向用户提供反馈信息
-
重要性: 在没有图形界面的程序中,print 语句是主要的用户交互方式
2. f-string 格式化字符串
-
语法: 使用
f"..."前缀表示这是一个格式化字符串 -
优势:
-
比传统的
%格式化或.format()方法更简洁、更易读 -
直接在字符串中嵌入表达式,用大括号
{}包裹 -
在 Python 3.6+ 中可用
-
3. len(image_files) 表达式
-
功能: Python 内置函数,返回对象的长度或项目数
-
作用: 计算
image_files列表中的元素数量 -
结果: 一个整数值,表示找到的图像文件数量
4. 字符串内容分析
-
"找到 ": 中文前缀,说明后面数字的含义 -
{len(image_files)}: 动态插入的图像文件数量 -
" 张图像": 中文后缀,使用量词"张"来计量图像
5. 代码执行流程
-
计算
len(image_files)表达式的值 -
将该值转换为字符串
-
将转换后的字符串插入到格式化字符串中的指定位置
-
将完整的格式化字符串传递给
print()函数 -
print()函数将消息输出到控制台
for i, image_path in enumerate(image_files):1. for 循环
-
功能: Python 的控制流语句,用于遍历序列中的元素
-
作用: 对
image_files列表中的每个元素执行相同的操作 -
重要性: 这是处理批量数据的核心机制
2. enumerate() 函数
-
功能: Python 内置函数,返回一个枚举对象
-
作用: 为可迭代对象的每个元素添加索引,生成 (index, element) 元组
-
语法:
enumerate(iterable, start=0)-
iterable: 要枚举的可迭代对象(这里是image_files) -
start: 起始索引值,默认为 0
-
3. 元组解包
-
功能: Python 的特性,允许将元组的值分配给多个变量
-
作用: 将
enumerate()返回的 (index, element) 元组解包到变量i和image_path-
i: 接收索引值(从 0 开始) -
image_path: 接收对应的元素值(图像文件路径)
-
4. 代码执行流程
-
enumerate(image_files)创建一个枚举对象,生成 (0, image_files[0]), (1, image_files[1]), ... 序列 -
每次迭代,从枚举对象中获取下一个 (index, element) 元组
-
通过元组解包,将索引赋值给
i,将元素(图像路径)赋值给image_path -
执行循环体内的代码
-
重复步骤 2-4,直到处理完所有图像文件
image = cv2.imread(str(image_path))
if image is None:print(f"无法读取图像: {image_path}")continue1. cv2.imread() 函数
-
功能: OpenCV 库中的函数,用于从指定文件读取图像
-
语法:
cv2.imread(filename[, flags])-
filename: 要读取的图像文件路径 -
flags: 可选参数,指定读取图像的方式(如彩色、灰度等)
-
-
返回值:
-
成功时返回一个 NumPy 数组(图像数据)
-
失败时返回
None
-
1.1 路径转换
str(image_path)-
image_path是一个Path对象(来自pathlib模块)
-
str()将其转换为字符串,因为cv2.imread()期望字符串路径 -
这是必要的,因为 OpenCV 的 Python 绑定通常期望字符串路径而不是 Path 对象
1.2 默认读取方式
-
代码中没有指定
flags参数,因此使用默认值cv2.IMREAD_COLOR -
这意味着图像以彩色模式(BGR 格式)读取,忽略任何 alpha 通道
-
如果需要其他读取方式,可以使用:
-
cv2.IMREAD_GRAYSCALE: 以灰度模式读取 -
cv2.IMREAD_UNCHANGED: 读取所有通道,包括 alpha 通道
-
2. 错误检查
if image is None:-
检查
cv2.imread()是否成功读取图像 -
如果读取失败,
image将为None -
这是一个简单而有效的错误检查机制
3. 错误处理
print(f"无法读取图像: {image_path}")-
使用 f-string 格式化错误消息
-
明确指出无法读取哪个图像文件
-
这对于调试和用户反馈非常重要
3.2 流程控制
continue-
continue语句跳过当前循环的剩余代码,直接开始下一次迭代 -
这意味着如果图像读取失败,程序不会尝试处理该图像,而是继续处理下一个图像
-
这确保了批量处理不会因为单个文件的错误而中断
results = model.predict(source=image,conf=conf_threshold,save=False,verbose=False
)这段代码使用 Ultralytics YOLOv8 模型对输入图像进行预测,是整个图像处理流程的核心部分。让我们深入分析它的各个组成部分和功能。
1. model.predict() 方法
-
功能: YOLO 模型的主要推理方法,用于对输入数据进行预测
-
作用: 使用训练好的模型检测图像中的对象并生成预测结果
-
返回值: 返回一个
Results对象或Results对象列表,包含所有预测信息
2. 参数详解
2.1 source=image
-
类型: numpy 数组(图像数据)
-
作用: 指定预测的输入源,这里直接传递图像数据
-
替代选项:
-
可以是文件路径字符串
-
可以是包含多个路径的列表
-
可以是视频文件路径
-
可以是摄像头设备索引
-
可以是 URL 链接
-
2.2 conf=conf_threshold
-
类型: 浮点数(通常介于 0.0 和 1.0 之间)
-
作用: 置信度阈值,只保留置信度高于此值的预测结果
-
默认值: 在函数定义中设置为 0.25
-
重要性:
-
较高的值会减少误报,但可能漏掉一些真实对象
-
较低的值会检测更多对象,但可能增加误报
-
对于您的应用(瞳孔和同心沟检测),0.9 的高阈值是合适的,因为您希望只保留高置信度的预测
-
2.3 save=False
-
类型: 布尔值
-
作用: 控制是否自动保存带预测结果的可视化图像
-
设置为 False 的原因:
-
您希望在后续代码中自定义结果的可视化方式(如椭圆拟合)
-
避免生成重复的输出文件
-
提供更大的灵活性来处理和保存结果
-
2.4 verbose=False
-
类型: 布尔值
-
作用: 控制是否在控制台输出详细的预测信息
-
设置为 False 的原因:
-
您已经在代码中提供了自定义的进度和信息输出
-
避免控制台输出过于冗杂
-
保持输出信息的整洁和一致性
-
3. 预测结果的结构
results 是一个 Results 对象,包含以下重要属性:
3.1 results.boxes
-
包含检测到的边界框信息
-
属性包括:
-
xyxy: 边界框坐标 [x1, y1, x2, y2] -
conf: 置信度分数 -
cls: 类别 ID
-
3.2 results.masks
-
包含分割掩码信息(对于分割模型)
-
属性包括:
-
data: 掩码数据张量 -
xy: 掩码的多边形点
-
3.3 results.names
-
类别名称的字典,将类别 ID 映射到类别名称
4. 代码执行流程
-
将图像数据传递给 YOLOv8 模型
-
模型对图像进行前向传播,生成预测结果
-
根据置信度阈值过滤低置信度的预测
-
返回包含所有满足条件的预测结果的
Results对象 -
由于
save=False和verbose=False,不会自动保存结果或输出详细信息
result_image = image.copy()1. 基本功能
-
作用: 创建原始图像的一个完全独立的副本
-
目的: 在副本上进行所有修改操作,保持原始图像不被改变
-
返回值: 返回一个新的 NumPy 数组,包含与原始图像相同的数据
2. 底层原理
2.1 NumPy 数组的复制机制
-
在 OpenCV 中,图像表示为 NumPy 多维数组
-
简单的赋值操作 (
result_image = image) 只会创建引用,而不是副本 -
copy()方法创建数据的深层副本,确保原始数据和副本完全独立
2.2 内存管理
-
copy()方法分配新的内存空间来存储图像数据 -
副本与原始图像在内存中是两个独立的对象
-
对副本的任何修改都不会影响原始图像
3. 为什么需要创建副本
3.1 保持原始数据完整性
# 如果没有创建副本,直接修改会改变原始图像
result_image = image # 这只是引用,不是副本
cv2.rectangle(result_image, (10, 10), (100, 100), (0, 255, 0), 2)
# 现在原始图像也被修改了!3.2 支持多次处理尝试
-
如果处理过程中出现错误,可以重新开始而不影响原始图像
-
可以尝试不同的处理参数,而不需要重新读取图像
3.3 便于比较和调试
-
可以同时保存原始图像和处理后的图像进行对比
-
便于调试算法,了解每个处理步骤的效果
if result.masks is not None:# 获取所有掩码masks = result.masks.data.cpu().numpy()1. if result.masks is not None:
1.1 result 对象
-
result是 YOLOv8 模型预测后返回的结果对象 -
对于分割任务,这个对象包含多个属性:
-
boxes: 检测到的边界框信息 -
masks: 分割掩码信息 -
probs: 分类概率(如果适用) -
names: 类别名称映射 -
orig_img: 原始图像 -
speed: 处理速度信息
-
1.2 result.masks
-
masks属性包含模型预测的分割掩码 -
如果没有检测到任何对象,或者模型不是分割模型,
masks可能为None -
这个检查确保只有当存在分割掩码时才继续处理,避免后续代码出错
1.3 条件判断的重要性
-
这是一个重要的错误预防机制
-
确保代码的健壮性,避免在没有任何检测结果时出现异常
-
在处理批量图像时特别重要,因为某些图像可能没有任何检测目标
2. masks = result.masks.data.cpu().numpy()
这行代码执行了三个关键操作,将掩码数据从模型输出格式转换为可处理的 NumPy 数组格式。
2.1 result.masks.data
-
result.masks是一个包含多个属性的对象 -
.data属性包含实际的掩码张量数据 -
这个张量通常位于 GPU 上(如果使用了 GPU 进行推理)
-
张量的形状通常是
[N, H, W],其中:-
N: 检测到的对象数量 -
H: 掩码高度(通常是原图的 1/4 或 1/8,取决于模型的下采样率) -
W: 掩码宽度
-
2.2 .cpu()
-
将张量从 GPU 内存移动到 CPU 内存
-
这是必要的步骤,因为:
-
NumPy 无法直接处理 GPU 上的张量
-
即使系统没有 GPU,这个方法也能正常工作(在这种情况下,张量已经在 CPU 上)
-
避免 GPU 内存占用过久,特别是在处理大量图像时
-
-
如果张量已经在 CPU 上,这个操作不会有任何效果
colors = [(0, 255, 0), # 绿色 - 类别0(0, 0, 255), # 红色 - 类别1(255, 0, 0), # 蓝色 - 类别2(255, 255, 0), # 青色 - 类别3(255, 0, 255), # 紫色 - 类别4(0, 255, 255), # 黄色 - 类别5
]这段代码定义了一个颜色列表,用于为不同的检测类别分配不同的颜色。
1. 颜色表示格式
1.1 BGR 颜色空间
-
这些颜色元组使用的是 BGR(蓝-绿-红) 格式,而不是常见的 RGB 格式
-
这是因为 OpenCV(cv2)默认使用 BGR 颜色空间
-
每个元组包含三个整数值,范围从 0 到 255,分别代表蓝色、绿色和红色的强度
1.2 颜色元组结构
-
每个颜色表示为
(B, G, R)三元组 -
例如:
(0, 255, 0)表示:-
蓝色分量: 0
-
绿色分量: 255
-
红色分量: 0
-
结果: 纯绿色
-
2. 具体颜色分析
2.1 类别0 - 绿色 (0, 255, 0)
-
纯绿色,常用于表示"正常"或"通过"状态
-
在您的应用中,可能表示瞳孔区域
2.2 类别1 - 红色 (0, 0, 255)
-
纯红色,常用于表示"警告"或"重要"区域
-
在您的应用中,可能表示同心沟或其他重要特征
2.3 类别2 - 蓝色 (255, 0, 0)
-
纯蓝色,常用于表示"信息"或"中性"区域
-
在您的应用中,可能表示其他眼部结构
2.4 类别3 - 青色 (255, 255, 0)
-
青色(蓝绿色),是蓝色和绿色的混合
-
在颜色轮上介于蓝色和绿色之间
2.5 类别4 - 紫色 (255, 0, 255)
-
紫色(洋红色),是蓝色和红色的混合
-
在颜色轮上介于蓝色和红色之间
2.6 类别5 - 黄色 (0, 255, 255)
-
黄色,是绿色和红色的混合
-
在颜色轮上介于绿色和红色之间
for j, (mask, box) in enumerate(zip(masks, result.boxes)):1.1 zip(masks, result.boxes)
-
zip()函数将两个或多个可迭代对象"压缩"在一起 -
它创建一个迭代器,生成元组,其中每个元组包含来自每个可迭代对象的对应元素
-
在这里,它将掩码数组
masks和边界框对象result.boxes配对 -
假设有 N 个检测到的对象,则
zip()会生成 N 个元组,每个元组包含一个掩码和对应的边界框
1.2 enumerate()
-
enumerate()函数为迭代中的每个元素添加一个计数器 -
它返回一个包含索引和值的元组
-
在这里,它为每个
(mask, box)对添加一个索引j -
索引
j从 0 开始,表示当前处理的是第几个检测到的对象
1.3 for j, (mask, box) in ...
-
这是一个元组解包操作
-
对于每次迭代,
j接收索引值 -
(mask, box)接收来自zip()的元组,并将其解包为两个变量:-
mask: 当前对象的掩码数据 -
box: 当前对象的边界框信息
-
2. 循环变量的详细分析
2.1 j - 对象索引
-
一个整数,表示当前处理的是第几个检测到的对象
-
从 0 开始计数
-
在循环体内用于标识对象(例如在打印信息时)
2.2 mask - 分割掩码
-
一个形状为
[H, W]的 NumPy 数组 -
包含浮点值,范围在 0 到 1 之间,表示每个像素属于目标对象的概率
-
这个掩码的尺寸通常比原始图像小(由于模型的下采样)
-
在后续代码中,这个掩码会被调整大小、二值化,并用于提取轮廓
2.3 box - 边界框信息
-
一个包含边界框信息的对象,通常有以下属性:
-
box.cls: 类别 ID(张量) -
box.conf: 置信度分数(张量) -
box.xyxy: 边界框坐标 [x1, y1, x2, y2](张量) -
box.xywh: 边界框坐标 [x, y, width, height](张量)
-
-
在循环体内,这些信息被提取并用于确定对象的类别和置信度
if result.masks is not None:masks = result.masks.data.cpu().numpy()1.1 result.masks
-
result是 YOLOv8 模型对图像进行预测后返回的结果对象 -
masks是result对象的一个属性,包含分割掩码信息 -
如果没有检测到任何对象,或者模型不是分割模型,
masks可能为None
1.2 is not None 检查
-
这是一个重要的条件检查,确保只有当存在分割掩码时才继续处理
-
避免在没有任何检测结果时出现异常或错误
-
在处理批量图像时特别重要,因为某些图像可能没有任何检测目标
1.3 result.masks.data
-
.data属性包含实际的掩码张量数据 -
这个张量通常位于 GPU 上(如果使用了 GPU 进行推理)
-
张量的形状通常是
[N, H, W],其中:-
N: 检测到的对象数量 -
H: 掩码高度(通常是原图的 1/4 或 1/8,取决于模型的下采样率) -
W: 掩码宽度
-
1.4 .cpu()
-
将张量从 GPU 内存移动到 CPU 内存
-
这是必要的步骤,因为:
-
NumPy 无法直接处理 GPU 上的张量
-
即使系统没有 GPU,这个方法也能正常工作(在这种情况下,张量已经在 CPU 上)
-
避免 GPU 内存占用过久,特别是在处理大量图像时
-
1.5 .numpy()
-
将 PyTorch 张量转换为 NumPy 数组
-
这样做的好处包括:
-
NumPy 数组与 OpenCV 等其他库兼容性更好
-
可以使用熟悉的 NumPy 语法和函数处理数据
-
便于可视化、保存和后续处理
-
class_id = int(box.cls[0])
confidence = float(box.conf[0])1.1 box 对象
-
box是 YOLOv8 检测结果中的一个边界框对象 -
它包含关于检测到的对象的各种信息,包括:
-
cls: 类别信息 -
conf: 置信度分数 -
xyxy: 边界框坐标 (x1, y1, x2, y2) -
xywh: 边界框坐标 (x, y, width, height)
-
1.2 box.cls 和 box.conf
-
box.cls: 包含类别信息的张量 -
box.conf: 包含置信度分数的张量 -
这些张量通常是单元素张量(只有一个值),因此使用
[0]来访问第一个(也是唯一一个)元素
1.3 [0] 索引操作
-
使用
[0]来访问张量中的第一个元素 -
这是因为对于每个检测到的对象,
box.cls和box.conf通常是单元素张量 -
这个操作从张量中提取出实际的数值
1.4 int() 和 float() 转换
-
int(box.cls[0]): 将类别值转换为整数 -
float(box.conf[0]): 将置信度值转换为浮点数 -
这些转换是必要的,因为原始值是 PyTorch 张量中的元素,需要转换为标准的 Python 数据类型以便后续使用
2. 提取的信息详解
2.1 class_id - 类别 ID
-
一个整数,表示检测到的对象的类别
-
这个 ID 对应于模型训练时定义的类别
-
例如,在您的瞳孔检测应用中:
-
0 可能表示瞳孔
-
1 可能表示同心沟
-
其他数字可能表示其他眼部结构
-
2.2 confidence - 置信度分数
-
一个浮点数,范围在 0 到 1 之间
-
表示模型对检测结果的置信程度
-
值越接近 1,表示模型越确定检测结果是正确的
-
这个值在预测时已经通过
conf_threshold参数进行了过滤,只有高于阈值的检测结果才会被保留
# 对每个轮廓进行处理
for contour in contours:# 椭圆拟合需要至少5个点if len(contour) >= 5 and fit_ellipse:try:# 拟合椭圆ellipse = cv2.fitEllipse(contour)# 绘制椭圆cv2.ellipse(result_image, ellipse, color, line_thickness)print(f" ✓ 已对 {class_name} 进行椭圆拟合")except Exception as e:print(f" ✗ 椭圆拟合失败: {e}")# 如果椭圆拟合失败,回退到绘制原始轮廓cv2.drawContours(result_image, [contour], -1, color, line_thickness)else:# 如果点数不足或不进行椭圆拟合,绘制原始轮廓cv2.drawContours(result_image, [contour], -1, color, line_thickness)if len(contour) < 5:print(f" ⓘ 轮廓点不足 ({len(contour)}个点),无法进行椭圆拟合")1. 代码结构解析
1.1 轮廓遍历
for contour in contours:-
遍历从二值掩码中提取的所有轮廓
-
每个
contour是一个由点组成的数组,表示一个封闭的轮廓
1.2 椭圆拟合条件检查
if len(contour) >= 5 and fit_ellipse:-
检查两个条件:
-
轮廓点数 ≥ 5(椭圆拟合的最小点数要求)
-
fit_ellipse参数为 True(用户选择进行椭圆拟合)
-
1.3 椭圆拟合尝试
try:# 拟合椭圆ellipse = cv2.fitEllipse(contour)# 绘制椭圆cv2.ellipse(result_image, ellipse, color, line_thickness)print(f" ✓ 已对 {class_name} 进行椭圆拟合")-
使用 OpenCV 的
fitEllipse函数拟合椭圆 -
如果成功,绘制拟合的椭圆并打印成功信息
1.4 异常处理
except Exception as e:print(f" ✗ 椭圆拟合失败: {e}")# 如果椭圆拟合失败,回退到绘制原始轮廓cv2.drawContours(result_image, [contour], -1, color, line_thickness)-
捕获椭圆拟合过程中可能出现的任何异常
-
打印错误信息并回退到绘制原始轮廓
1.5 备用方案
else:# 如果点数不足或不进行椭圆拟合,绘制原始轮廓cv2.drawContours(result_image, [contour], -1, color, line_thickness)if len(contour) < 5:print(f" ⓘ 轮廓点不足 ({len(contour)}个点),无法进行椭圆拟合")-
当不满足椭圆拟合条件时,绘制原始轮廓
-
如果是因为点数不足,打印提示信息
2. 椭圆拟合技术细节
2.1 cv2.fitEllipse() 函数
-
接受一个轮廓点集作为输入
-
使用最小二乘法拟合最佳椭圆
-
返回一个元组,包含:
-
椭圆中心坐标 (x, y)
-
主轴和次轴的长度 (width, height)
-
椭圆的旋转角度(度)
-
2.2 椭圆拟合的最小点数要求
-
椭圆拟合需要至少 5 个点
-
这是因为椭圆有 5 个自由度:
-
中心 x 坐标
-
中心 y 坐标
-
长轴长度
-
短轴长度
-
旋转角度
-
2.3 cv2.ellipse() 函数
-
接受椭圆参数和绘制参数
-
在图像上绘制椭圆
-
参数:
-
result_image: 要绘制椭圆的图像 -
ellipse: 从fitEllipse返回的椭圆参数 -
color: 椭圆颜色 -
line_thickness: 椭圆线宽
-
3. 在完整代码上下文中的作用
这段代码是图像分割后处理的关键部分,它将检测到的轮廓转换为更平滑、更符合实际形状的椭圆:
-
轮廓提取: 从二值掩码中提取轮廓点集
-
椭圆拟合: 对适合椭圆拟合的轮廓进行椭圆拟合
-
可视化: 绘制拟合的椭圆或原始轮廓
-
错误处理: 处理椭圆拟合可能出现的异常情况
-
信息反馈: 提供处理状态的详细反馈
4. 椭圆拟合的优势
在您的瞳孔和同心沟检测应用中,椭圆拟合提供了几个重要优势:
4.1 形状平滑化
-
消除原始轮廓的不规则锯齿和噪声
-
产生更平滑、更美观的轮廓
4.2 形状一致性
-
确保瞳孔和同心沟等对象保持椭圆形
-
符合这些眼部结构的实际形状特征
4.3 噪声鲁棒性
-
对分割结果中的小噪声不敏感
-
即使轮廓中有一些异常点,椭圆拟合也能产生合理的结果
4.4 参数化表示
-
椭圆拟合提供了参数化表示(中心、轴长、角度)
-
这些参数可以用于后续的测量和分析
代码
1. 导入必要的库
from ultralytics import YOLO
import os
import cv2
import numpy as np
from pathlib import Path-
YOLO: Ultralytics库的核心类,用于加载和运行YOLO模型 -
os: 操作系统接口,用于文件和目录操作 -
cv2: OpenCV库,用于图像处理和计算机视觉任务 -
numpy: 数值计算库,处理数组和矩阵运算 -
Path: 路径操作工具,简化文件路径处理
2. 主函数定义
-
功能: 使用训练好的YOLOv8分割模型批量预测图像,只绘制分割轮廓
def predict_images(model_path, source_dir, output_dir, conf_threshold=0.25, line_thickness=2):这是一个函数定义,接受以下参数:
-
model_path: 训练好的模型文件路径(.pt文件) -
source_dir: 包含待预测图像的文件夹路径 -
output_dir: 保存预测结果的输出文件夹路径 -
conf_threshold: 置信度阈值(默认0.25),低于此值的预测将被忽略 -
line_thickness: 轮廓线粗细(默认2像素)
3. 加载模型和准备输出目录
# 加载训练好的模型
model = YOLO(model_path)# 创建输出目录
os.makedirs(output_dir, exist_ok=True)-
YOLO(model_path): 加载预训练的YOLOv8分割模型 -
os.makedirs(output_dir, exist_ok=True): 创建输出目录,如果已存在则不会报错
4. 获取图像文件列表
# 获取所有图像文件
image_extensions = ['.jpg', '.jpeg', '.png', '.bmp', '.tiff']
image_files = []
for ext in image_extensions:image_files.extend(Path(source_dir).glob(f"*{ext}"))image_files.extend(Path(source_dir).glob(f"*{ext.upper()}"))-
定义支持的图像文件扩展名列表
-
使用
Path(source_dir).glob()方法查找所有匹配的文件 -
同时查找小写和大写扩展名的文件,确保不遗漏
for ext in image_extensions:-
这是一个循环语句,遍历
image_extensions列表中的每一个元素 -
image_extensions是一个包含常见图像文件扩展名的列表:['.jpg', '.jpeg', '.png', '.bmp', '.tiff'] -
每次循环,
ext变量会依次取列表中的一个扩展名
image_files.extend(Path(source_dir).glob(f"*{ext}"))-
Path(source_dir): 创建一个Path对象,表示源目录的路径 -
.glob(f"*{ext}"): 使用glob模式匹配查找文件-
*是通配符,匹配任意字符 -
{ext}是格式化字符串,会被替换为当前扩展名 -
例如,当
ext是.jpg时,模式变为*.jpg,匹配所有以.jpg结尾的文件
-
-
image_files.extend(...): 将匹配到的文件列表添加到image_files列表中-
extend()方法用于将另一个列表的所有元素添加到当前列表
-
image_files.extend(Path(source_dir).glob(f"*{ext.upper()}"))-
这一行与上一行类似,但搜索的是大写的扩展名
-
ext.upper(): 将扩展名转换为大写-
例如,
.jpg变为.JPG
-
-
这样做的原因是,不同操作系统或用户可能使用不同大小写的扩展名
-
例如,有些用户可能保存为
image.JPG而不是image.jpg
5. 批量处理图像
# 批量预测
for i, image_path in enumerate(image_files):print(f"处理图像 {i+1}/{len(image_files)}: {image_path.name}")# 读取原始图像image = cv2.imread(str(image_path))if image is None:print(f"无法读取图像: {image_path}")continue-
使用
enumerate遍历所有图像文件,同时获取索引和路径 -
cv2.imread()读取图像,如果读取失败则跳过该图像
6. 模型预测
# 进行预测
results = model.predict(source=image,conf=conf_threshold,save=False,verbose=False
)-
model.predict(): 使用模型进行预测 -
source=image: 输入图像 -
conf=conf_threshold: 设置置信度阈值 -
save=False: 不自动保存结果(我们将自定义保存) -
verbose=False: 减少控制台输出
7. 处理预测结果
# 创建结果图像的副本
result_image = image.copy()# 处理每个预测结果
for result in results:if result.masks is not None:# 获取所有掩码masks = result.masks.data.cpu().numpy()# 为每个类别定义颜色colors = [(0, 255, 0), # 绿色 - 类别0(0, 0, 255), # 红色 - 类别1(255, 0, 0), # 蓝色 - 类别2(255, 255, 0), # 青色 - 类别3(255, 0, 255), # 紫色 - 类别4(0, 255, 255), # 黄色 - 类别5]-
result_image = image.copy(): 创建原始图像的副本,用于绘制结果 -
result.masks: 包含分割掩码的结果 -
masks.data.cpu().numpy(): 将掩码数据从GPU转移到CPU并转换为NumPy数组 -
colors: 定义不同类别的颜色(BGR格式)
8. 处理每个检测到的对象
# 绘制每个分割掩码的轮廓
for j, (mask, box) in enumerate(zip(masks, result.boxes)):class_id = int(box.cls[0])confidence = float(box.conf[0])# 选择颜色color = colors[class_id % len(colors)]# 将掩码转换为二值图像mask_resized = cv2.resize(mask, (image.shape[1], image.shape[0]))mask_binary = (mask_resized > 0.5).astype(np.uint8)# 找到轮廓contours, _ = cv2.findContours(mask_binary, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)# 只绘制轮廓,不填充cv2.drawContours(result_image, contours, -1, color, line_thickness)# 打印检测信息(可选)class_name = model.names[class_id]print(f" 对象 {j+1}: {class_name} (置信度: {confidence:.2f})")-
zip(masks, result.boxes): 同时遍历掩码和边界框信息 -
class_id = int(box.cls[0]): 获取类别ID -
confidence = float(box.conf[0]): 获取置信度分数 -
color = colors[class_id % len(colors)]: 根据类别ID选择颜色 -
cv2.resize(): 调整掩码大小以匹配原始图像尺寸 -
(mask_resized > 0.5).astype(np.uint8): 将掩码转换为二值图像(0或1) -
cv2.findContours(): 找到二值图像中的轮廓 -
cv2.drawContours(): 在结果图像上绘制轮廓 -
打印每个检测到的对象信息
9. 保存结果图像
# 保存结果图像
output_path = os.path.join(output_dir, f"pred_{image_path.name}")
cv2.imwrite(output_path, result_image)-
使用
os.path.join()构建输出文件路径 -
文件名添加"pred_"前缀以区分原始图像
-
cv2.imwrite()保存处理后的图像
10. 主程序入口
if __name__ == "__main__":# 设置路径和参数model_path = "/home/bohan/yolov8/meter_seg_experiments/exp1_yolov8m_640/weights/best.pt"source_dir = "/home/bohan/yolov8/虹膜相关文件/虹膜标注/数据"output_dir = "/home/bohan/yolov8/虹膜相关文件/虹膜标注/数据/检测结果"conf_threshold = 0.9 # 置信度阈值,可以根据需要调整line_thickness = 1 # 轮廓线粗细# 运行预测predict_images(model_path, source_dir, output_dir, conf_threshold, line_thickness)-
if __name__ == "__main__":确保代码只在直接运行时执行,而不是被导入时执行 -
设置模型路径、输入目录、输出目录等参数
-
调用
predict_images函数开始处理
代码执行流程
-
加载训练好的YOLOv8分割模型
-
创建输出目录
-
获取输入目录中的所有图像文件
-
遍历每个图像文件:
-
读取图像
-
使用模型进行预测
-
处理预测结果,绘制分割轮廓
-
保存处理后的图像
-
-
处理完成后打印总结信息
python知识
extend() 方法
extend() 是 Python 列表(List)对象的一个内置方法,用于将一个可迭代对象(如列表、元组等)中的所有元素添加到当前列表的末尾。
基本语法
list.extend(iterable)-
list: 要扩展的列表对象 -
iterable: 任何可迭代对象(列表、元组、集合、字符串等) -
方法没有返回值,而是直接修改原列表
工作原理
extend() 方法会将传入的可迭代对象中的每个元素逐个添加到原列表的末尾。
与 append() 方法的区别
这是理解 extend() 的关键,让我通过例子来说明:
# 使用 append()
list1 = [1, 2, 3]
list2 = [4, 5, 6]
list1.append(list2)
print(list1) # 输出: [1, 2, 3, [4, 5, 6]]# 使用 extend()
list1 = [1, 2, 3]
list2 = [4, 5, 6]
list1.extend(list2)
print(list1) # 输出: [1, 2, 3, 4, 5, 6]-
append(): 将整个对象作为一个单个元素添加到列表末尾 -
extend(): 将对象中的每个元素逐个添加到列表末尾
在你的代码中的应用
for ext in image_extensions:image_files.extend(Path(source_dir).glob(f"*{ext}"))image_files.extend(Path(source_dir).glob(f"*{ext.upper()}"))让我们分解这段代码:
-
Path(source_dir).glob(f"*{ext}")返回一个包含所有匹配文件的列表 -
image_files.extend(...)将这个列表中的所有文件路径添加到image_files列表中 -
对每个扩展名(包括大写版本)重复这个过程
实际示例
假设:
-
image_extensions = ['.jpg', '.png'] -
目录中有:
['a.jpg', 'b.JPG', 'c.png', 'd.PNG']
代码执行过程:
# 初始状态
image_files = []# 第一次循环: ext = '.jpg'
matched_files = ['a.jpg'] # Path(source_dir).glob("*.jpg") 的结果
image_files.extend(matched_files) # image_files 变为 ['a.jpg']matched_files_upper = ['b.JPG'] # Path(source_dir).glob("*.JPG") 的结果
image_files.extend(matched_files_upper) # image_files 变为 ['a.jpg', 'b.JPG']# 第二次循环: ext = '.png'
matched_files = ['c.png'] # Path(source_dir).glob("*.png") 的结果
image_files.extend(matched_files) # image_files 变为 ['a.jpg', 'b.JPG', 'c.png']matched_files_upper = ['d.PNG'] # Path(source_dir).glob("*.PNG") 的结果
image_files.extend(matched_files_upper) # image_files 变为 ['a.jpg', 'b.JPG', 'c.png', 'd.PNG']其他使用场景
extend() 方法可以用于各种可迭代对象:
# 扩展元组
list1 = [1, 2, 3]
tuple1 = (4, 5)
list1.extend(tuple1) # [1, 2, 3, 4, 5]# 扩展字符串(字符串是可迭代的)
list1 = ['a', 'b']
list1.extend("cd") # ['a', 'b', 'c', 'd']# 扩展集合
list1 = [1, 2, 3]
set1 = {4, 5}
list1.extend(set1) # [1, 2, 3, 4, 5](注意:集合是无序的)# 扩展生成器
def number_generator():yield 4yield 5list1 = [1, 2, 3]
list1.extend(number_generator()) # [1, 2, 3, 4, 5]性能考虑
对于大量数据的合并,extend() 通常比使用 + 运算符更高效,因为它直接修改原列表,而不需要创建新列表:
# 效率较低(创建新列表)
list1 = list1 + list2# 效率较高(直接修改原列表)
list1.extend(list2)总结
-
extend()用于将一个可迭代对象的所有元素添加到列表末尾 -
与
append()不同,extend()是展开添加元素,而不是添加整个对象 -
在你的代码中,它用于收集所有匹配特定扩展名的文件路径
-
它是原地操作,直接修改原列表,不返回新列表
这个方法在处理需要合并多个列表或可迭代对象时非常有用,特别是在文件处理、数据收集等场景中。
.glob() 方法和 glob 模式匹配
.glob() 是 Python 中 pathlib.Path 对象的一个方法,用于基于 Unix shell 风格的通配符模式匹配文件路径。让我们详细解析这个功能。
基本语法
Path(directory_path).glob(pattern)-
Path(directory_path): 创建一个 Path 对象,表示要搜索的目录路径 -
.glob(pattern): 使用指定的模式在该目录中搜索文件 -
返回一个生成器,产生所有匹配指定模式的 Path 对象
在你的代码中的应用
Path(source_dir).glob(f"*{ext}")-
source_dir: 要搜索的目录路径 -
f"*{ext}": 使用 f-string 格式化字符串,生成模式 -
例如,如果
ext是.jpg,模式就是*.jpg
Glob 模式语法
Glob 模式使用特殊字符来匹配文件名:
1. * - 匹配任意数量的任意字符
-
*.txt: 匹配所有以.txt结尾的文件 -
file*: 匹配所有以file开头的文件 -
*data*: 匹配所有包含data的文件
2. ? - 匹配单个任意字符
-
file?.txt: 匹配file1.txt,fileA.txt等,但不匹配file10.txt -
image-?.jpg: 匹配image-1.jpg,image-A.jpg等
3. [] - 匹配括号内的任意一个字符
-
file[123].txt: 匹配file1.txt,file2.txt,file3.txt -
image-[abc].jpg: 匹配image-a.jpg,image-b.jpg,image-c.jpg -
[0-9]: 匹配任意数字 -
[a-z]: 匹配任意小写字母 -
[A-Z]: 匹配任意大写字母
4. ** - 递归匹配所有子目录
-
**/*.txt: 匹配当前目录及其所有子目录中的.txt文件 -
docs/**/*.md: 匹配docs目录及其所有子目录中的.md文件
实际示例
假设目录结构如下:
/home/user/documents/
├── report.pdf
├── image.jpg
├── photo.JPG
├── data.txt
├── backup.zip
└── projects/├── code.py├── notes.txt└── images/├── logo.png└── screenshot.jpg使用不同的 glob 模式:
from pathlib import Path# 匹配所有 .txt 文件
list(Path("/home/user/documents").glob("*.txt"))
# 结果: [PosixPath('/home/user/documents/data.txt')]# 匹配所有 .jpg 文件(不区分大小写需要两次匹配)
list(Path("/home/user/documents").glob("*.jpg")) + list(Path("/home/user/documents").glob("*.JPG"))
# 结果: [PosixPath('/home/user/documents/image.jpg'), PosixPath('/home/user/documents/photo.JPG')]# 匹配所有以 "i" 开头的文件
list(Path("/home/user/documents").glob("i*"))
# 结果: [PosixPath('/home/user/documents/image.jpg')]# 递归匹配所有目录中的 .txt 文件
list(Path("/home/user/documents").glob("**/*.txt"))
# 结果: [PosixPath('/home/user/documents/data.txt'),
# PosixPath('/home/user/documents/projects/notes.txt')]# 匹配单个字符的文件名
list(Path("/home/user/documents").glob("?.txt"))
# 结果: [] (没有匹配项)# 匹配包含 "a" 的文件
list(Path("/home/user/documents").glob("*a*"))
# 结果: [PosixPath('/home/user/documents/data.txt'),
# PosixPath('/home/user/documents/backup.zip')]在你的代码中的具体作用
for ext in image_extensions:image_files.extend(Path(source_dir).glob(f"*{ext}"))image_files.extend(Path(source_dir).glob(f"*{ext.upper()}"))这段代码的作用是:
-
遍历所有图像扩展名 (如
.jpg,.png等) -
对于每个扩展名,搜索目录中所有以该扩展名结尾的文件
-
同时搜索以大写扩展名结尾的文件(如
.JPG,.PNG) -
将所有找到的文件路径添加到
image_files列表中
与正则表达式的区别
虽然 glob 模式看起来有点像正则表达式,但它们有一些重要区别:
-
语法更简单:Glob 模式使用更简单的通配符,而正则表达式有更复杂的语法
-
用途不同:Glob 专门用于文件名匹配,正则表达式用于文本模式匹配
-
特殊字符:在 glob 中,
*,?,[]是特殊字符,其他字符都是字面值 -
性能:Glob 匹配通常比正则表达式匹配更快,特别是对于文件名匹配
替代方法
除了使用 Path.glob(),你也可以使用:
# 使用 os.listdir() 和过滤
import os
all_files = os.listdir(source_dir)
image_files = [f for f in all_files if f.lower().endswith(('.jpg', '.png', '.jpeg', '.bmp', '.tiff'))]# 使用 glob 模块(与 Path.glob() 类似)
import glob
image_files = glob.glob(os.path.join(source_dir, "*.jpg")) + glob.glob(os.path.join(source_dir, "*.JPG"))
但 Path.glob() 方法更加现代化和 Pythonic,特别是在处理路径时。
总结
-
.glob()方法是基于 Unix shell 风格的模式匹配文件的有效方式 -
它使用简单的通配符语法:
*匹配任意字符,?匹配单个字符,[]匹配字符范围 -
在你的代码中,它用于查找特定扩展名的图像文件
-
通过同时搜索小写和大写扩展名,确保了跨平台的兼容性
-
返回的是一个生成器,可以高效地处理大量文件
这种方法比手动遍历目录和检查每个文件更简洁、更高效,是处理文件搜索任务的推荐方式。