RAG全栈技术——文档切分
一. 通用文档切分策略
分块(Chunking),其实现形式上是将长文档拆分为较小的块的过程,目的是在检索时能够准确地找到最直接和最相关的段落。一个有效的分块策略,可以确保搜索结果精确地反映用户查询的实际需求。如果分块过小或过大,都可能导致搜索结果不准确或提取不到最相关的内容。理想的文本块应尽可能语义独立,即不过度依赖上下文,这样的文本是语言模型最易于理解的。因此,为文档确定最佳的块大小是确保搜索结果准确性和相关性的关键。这涉及多个决策因素,如块的大小;如果句子太短,模型可能难以理解其意义,且句子越短,包含的有效信息就越少。比较常用的有如下五种不同的方法来优化分块策略:
- 根据句子切分:这种方法按照自然句子边界进行切分,以保持语义完整性。
- 按照固定字符数来切分:这种策略根据特定的字符数量来划分文本,但可能会在不适当的位置切断句子。
- 按固定字符数来切分,结合重叠窗口(overlapping windows):此方法与按字符数切分相似,但通过重叠窗口技术避免切分关键内容,确保信息连贯性。
- 递归方法:通过递归方式动态确定切分点,这种方法可以根据文档的复杂性和内容密度来调整块的大小。
- 根据语义切割:这种高级策略依据文本的语义内容来划分块,旨在保持相关信息的集中和完整,适用于需要高度语义保持的应用场景。
-
1.1 按照句子切分
按照句子切分,其实就是通过标点符号来进行文本切分(分割),这可以直接使用Python的标准库来完成这个任务。一种简单的方法是使用 re 模块,它提供了正则表达式的支持,可以方便地根据标点符号来分割文本。如下示例中,展示了如何使用re.split()函数来根据中文和英文的标点符号进行文本切分。代码如下:
import redef split_text_by_punctuation(text):# 定义一个正则表达式,包括常见的中英文标点# pattern = r"[。!?。"#$%&'()*+,-/:;<=>@[\]^_`{|}~\s、]+"pattern = r"[。!?。]+"# 使用正则表达式进行分割segments = re.split(pattern, text)# 过滤掉空字符串return [segment for segment in segments if segment]# 文本
text = "春节的脚步越来越近,大街小巷都布满了节日的气氛。商店门口挂满了红灯笼和春联,家家户户都在忙着打扫卫生,准备迎接新的一年。\
小明回到家乡,感受到了浓浓的过年氛围。他在街上走着,看到小朋友们手持烟花棒,欢笑声此起彼伏。\
夜幕降临,整个城市亮起了五彩缤纷的灯光,映照着人们脸上的喜悦与期待。老人们聚在一起,回忆过去,展望未来。\
而年轻人则在夜市享受美食,放松心情。这是一个充满希望和喜悦的时刻,每个人都在以自己的方式庆祝这个特殊的节日。"# 调用函数进行分割
segments = split_text_by_punctuation(text)# 使用循环来打印每个chunk
for i, segment in enumerate(segments):print("Chunk {}: {}".format(i + 1, segment))Chunk 1: 春节的脚步越来越近,大街小巷都布满了节日的气氛
Chunk 2: 商店门口挂满了红灯笼和春联,家家户户都在忙着打扫卫生,准备迎接新的一年
Chunk 3: 小明回到家乡,感受到了浓浓的过年氛围
Chunk 4: 他在街上走着,看到小朋友们手持烟花棒,欢笑声此起彼伏
Chunk 5: 夜幕降临,整个城市亮起了五彩缤纷的灯光,映照着人们脸上的喜悦与期待
Chunk 6: 老人们聚在一起,回忆过去,展望未来
Chunk 7: 而年轻人则在夜市享受美食,放松心情
Chunk 8: 这是一个充满希望和喜悦的时刻,每个人都在以自己的方式庆祝这个特殊的节日
如上所示,一整段text会根据设定的标点符号被分割为多个chunks,当然如果有特定的分割需求(比如保留某些特定的标点符号),可以调整正则表达式来灵活的调整。
-
1.2 按照固定字符数切分
如果想按照固定字符数来切分文本,这种方法就不再依赖于标点符号,而是简单地按照给定的字符数来切分文本。我们可以编写一个函数,用来将文本分割成指定长度的片段。代码如下:
# 固定字符数切分
def split_text_by_fixed_length(text, length):# 使用列表推导式按固定长度切分文本return [text[i:i + length] for i in range(0, len(text), length)]# 文本
text = "春节的脚步越来越近,大街小巷都布满了节日的气氛。商店门口挂满了红灯笼和春联,家家户户都在忙着打扫卫生,准备迎接新的一年。\
小明回到家乡,感受到了浓浓的过年氛围。他在街上走着,看到小朋友们手持烟花棒,欢笑声此起彼伏。\
夜幕降临,整个城市亮起了五彩缤纷的灯光,映照着人们脸上的喜悦与期待。老人们聚在一起,回忆过去,展望未来。\
而年轻人则在夜市享受美食,放松心情。这是一个充满希望和喜悦的时刻,每个人都在以自己的方式庆祝这个特殊的节日。"# 定义每个片段的长度
chunk_length = 100# 调用函数进行分割
result = split_text_by_fixed_length(text, chunk_length)# 打印结果
for i, segment in enumerate(result):print(f"Chunk {i+1}: {segment}")Chunk 1: 春节的脚步越来越近,大街小巷都布满了节日的气氛。商店门口挂满了红灯笼和春联,家家户户都在忙着打扫卫生,准备迎接新的一年。小明回到家乡,感受到了浓浓的过年氛围。他在街上走着,看到小朋友们手持烟花棒,欢笑
Chunk 2: 声此起彼伏。夜幕降临,整个城市亮起了五彩缤纷的灯光,映照着人们脸上的喜悦与期待。老人们聚在一起,回忆过去,展望未来。而年轻人则在夜市享受美食,放松心情。这是一个充满希望和喜悦的时刻,每个人都在以自己的
Chunk 3: 方式庆祝这个特殊的节日。
然而,这种方法的一个明显缺点是由于仅依据长度进行切分,切分后的片段可能无法保持完整的语义。但并不意味着它不适用于文本切分任务。例如,这种方法非常适合于处理日志文件或代码块,其中文本通常以固定长度或格式出现,或者在处理来自传感器或其他实时数据源的流数据时,固定长度切分可以确保数据被均匀地处理和分析。这些应用场景中,数据的结构和形式通常是预定和规范的,因此即便是按固定长度进行切分,反而会更有利于对数据的理解和使用。
-
1.3 结合重叠窗口的固定字符数切分
重复窗口的意义是:块之间保持一些重叠,以确保语义上下文不会在块之间丢失。在文本处理和其他数据分析领域,"重叠"(overlap)指的是连续数据块之间共享的部分。这种方法特别常见于信号处理、语音分析、自然语言处理等领域,其中数据的连续性和上下文信息非常重要。比如下述代码所示:
# 结合重叠窗口的固定字符数切分
def split_text_by_fixed_length_with_overlap(text, length, overlap):# 使用列表推导式按固定长度切分文本,同时考虑重叠窗口return [text[i:i + length] for i in range(0, len(text) - overlap, length - overlap)]# 文本
text = "春节的脚步越来越近,大街小巷都布满了节日的气氛。商店门口挂满了红灯笼和春联,家家户户都在忙着打扫卫生,准备迎接新的一年。\
小明回到家乡,感受到了浓浓的过年氛围。他在街上走着,看到小朋友们手持烟花棒,欢笑声此起彼伏。\
夜幕降临,整个城市亮起了五彩缤纷的灯光,映照着人们脸上的喜悦与期待。老人们聚在一起,回忆过去,展望未来。\
而年轻人则在夜市享受美食,放松心情。这是一个充满希望和喜悦的时刻,每个人都在以自己的方式庆祝这个特殊的节日。"# 定义每个片段的长度和重叠长度
chunk_length = 100
overlap_length = 30# 调用函数进行分割
result = split_text_by_fixed_length_with_overlap(text, chunk_length, overlap_length)# 打印结果
for i, segment in enumerate(result):print(f"Chunk {i+1}: {segment}")Chunk 1: 春节的脚步越来越近,大街小巷都布满了节日的气氛。商店门口挂满了红灯笼和春联,家家户户都在忙着打扫卫生,准备迎接新的一年。小明回到家乡,感受到了浓浓的过年氛围。他在街上走着,看到小朋友们手持烟花棒,欢笑
Chunk 2: 了浓浓的过年氛围。他在街上走着,看到小朋友们手持烟花棒,欢笑声此起彼伏。夜幕降临,整个城市亮起了五彩缤纷的灯光,映照着人们脸上的喜悦与期待。老人们聚在一起,回忆过去,展望未来。而年轻人则在夜市享受美食
Chunk 3: 老人们聚在一起,回忆过去,展望未来。而年轻人则在夜市享受美食,放松心情。这是一个充满希望和喜悦的时刻,每个人都在以自己的方式庆祝这个特殊的节日。
如上所示,每个文本片段长度为100个字符,并且每个片段与下一个片段有30个字符的重叠。这样,每个窗口实际上是在上一个窗口向前移动30个字符的基础上开始的。这种方法特别适用于需要数据重叠以保持上下文连续性的情况,能够较好的在某一个chunk中保存某个完整的语义信息,比如在第一个Chunk中的:'他在街上走着,看到小朋友们手持烟花棒,欢笑'被截断,但是完整的语义能够在Chunk2中被存储:'他在街上走着,看到小朋友们手持烟花棒,欢笑声此起彼伏。' 那么当这条语义信息是有关于Query的上下文,就可以在chunk2中被检索出来。
如上所示的前三种方法涉及的是对数据静态字符的切分,这些方法基本上只会将文本分割成固定数量字符的片段,而不考虑其内容或结构。这些是最基本且相对简单实现的文本切分方式。相比之下,递归方法的切分策略更为通用且常用,但实现上稍显复杂。为了简化实现过程,我们可以直接利用LangChain提供的封装类来进行实践。此外,LangChain也提供了相应的实现类来支持按照句子切分、固定字符数切分以及结合重叠窗口(overlap windows)的固定字符切分方法。
二. LangChain中的Text Splitters工具调用方法
LangChain框架构造了Data connection这一原生的数据处理流来统一管理RAG的处理流程。在这个架构中,文档切分的过程对应于Transformer环节,这一部分的任务是将整个Document对象转化(或“转换”)成多个小块(chunks)。这一转化步骤确立了文档从完整对象到细分片段的具体切分逻辑。
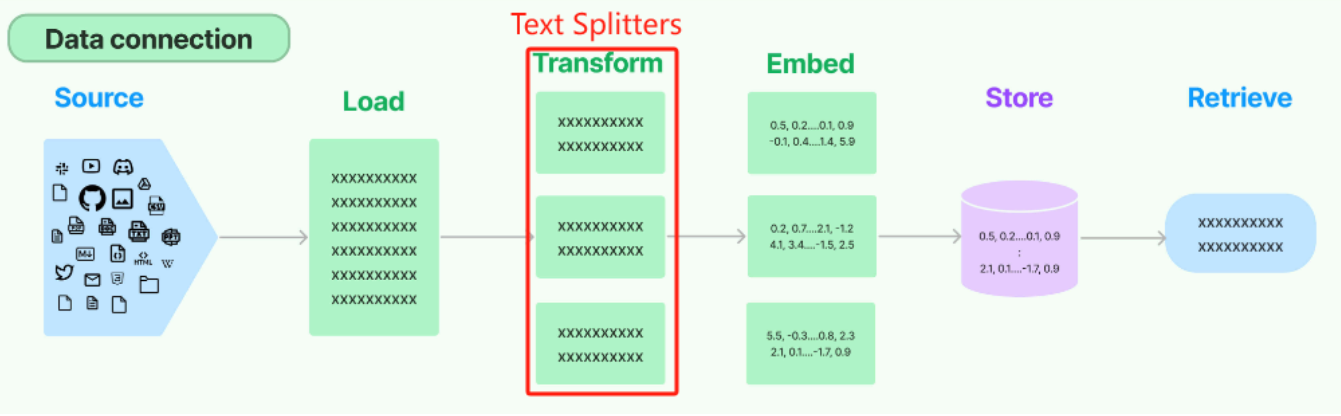
在Transform流程中,LangChain 有很多内置的文档转换器,可以轻松地拆分、组合、过滤和以其他方式操作文档,其类型和对应的说明文档位置如下:https://python.langchain.com/docs/how_to/#text-splitters
-
2.1 LangChain文档切分工具概览
在LangChain的内容处理体系中,Text Splitters是至关重要的组件,用于将长文本划分为可检索和可嵌入的小块(chunks),以适配检索增强生成(RAG)或其他下游任务。不同的分块方法可以根据输入内容的格式(如纯文本、HTML、代码或JSON)以及应用场景(例如语义分块或基于字符的固定分割)进行灵活选用。通过合理的Text Splitter配置,开发者可以在上下文保留和分块粒度之间取得平衡,从而显著提升问答系统的精确性和响应速度。下表汇总了LangChain官方文档中列出的主要分块方式及其适用场景:
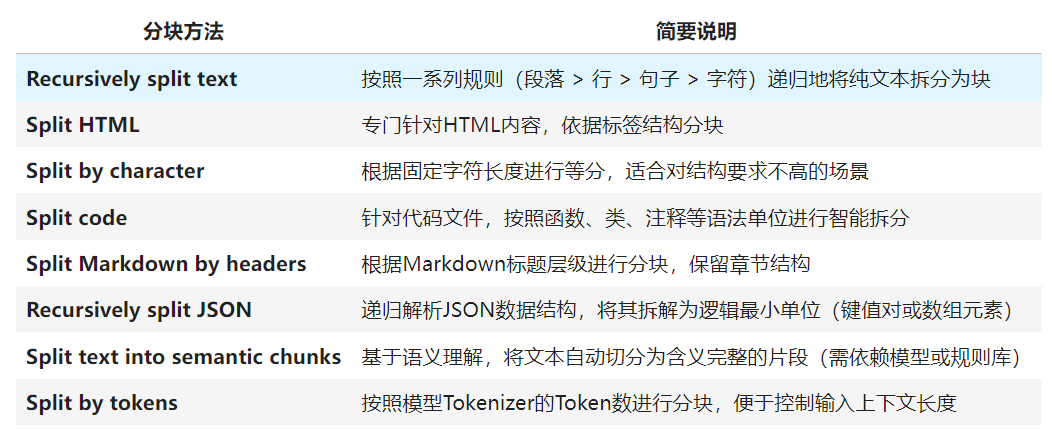
在实际应用中,开发者可以灵活组合这些分块器,针对不同的内容类型采取最优的策略。例如,针对技术文档,可以先用Markdown Header Splitter保留章节层次,再使用Recursive Character Splitter对较长片段进行二次切分;而在代码检索场景,Code Splitter可以根据函数或类边界划分逻辑单元,从而提高查询的精准性和可读性。
-
2.2 CharacterTextSplitter
这是最简单的方法。其基于字符(默认为“”)进行分割,并通过字符数来测量块长度。要使用该方法,需要先进行导入:
# 如果未安装过该模块,需要先进行安装
# ! pip install -qU langchain-text-splitters
from langchain.text_splitter import CharacterTextSplitterwith open(r"test.txt", "r", encoding="utf-8") as f:text = f.read()print(text)我与父亲不相见已二年余了,我最不能忘记的是他的背影。那年冬天,祖母死了,父亲的差使也交卸了,正是祸不单行的日子。
我从北京到徐州,打算跟着父亲奔丧回家。到徐州见着父亲,看见满院狼藉的东西,又想起祖母,不禁簌簌地流下眼泪。
父亲说:“事已如此,不必难过,好在天无绝人之路!”回家,父亲还了亏空;又借钱办了丧事。这些日子,家中光景很是惨淡,一半为了丧事,一半为了父亲赋闲。
丧事完毕,父亲要到南京谋事,我也要回北京念书,我们便同行。到南京时,有朋友约去游逛,勾留了一日;第二日上午便须渡江到浦口,下午上车北去。
父亲因为事忙,本已说定不送我,叫旅馆里一个熟识的茶房陪我同去。他再三嘱咐茶房,甚是仔细。但他终于不放心,怕茶房不妥帖;颇踌躇了一会。
text_splitter = CharacterTextSplitter(separator='',chunk_size=20,chunk_overlap=5,
)print(type(text))
text_res = text_splitter.split_text(text)
print(text_res)
print(len(text_res))
print(text_res[0])
print(text_res[1])<class 'str'>
['我与父亲不相见已二年余了,我最不能忘记的', '不能忘记的是他的背影。那年冬天,祖母死了', ',祖母死了,父亲的差使也交卸了,正是祸不', ',正是祸不单行的日子。\n我从北京到徐州,', '京到徐州,打算跟着父亲奔丧回家。到徐州见', '。到徐州见着父亲,看见满院狼藉的东西,又', '的东西,又想起祖母,不禁簌簌地流下眼泪。', '流下眼泪。\n父亲说:“事已如此,不必难过', ' ,不必难过,好在天无绝人之路!”回家,父', '”回家,父亲还了亏空;又借钱办了丧事。这', '了丧事。这些日子,家中光景很是惨淡,一半', '惨淡,一半为了丧事,一半为了父亲赋闲。', '亲赋 闲。\n丧事完毕,父亲要到南京谋事,我', '京谋事,我也要回北京念书,我们便同行。到', '便同行。到南京时,有朋友约去游逛,勾留了', '逛,勾留了一日;第二日上午便须渡江到浦口', '渡江 到浦口,下午上车北去。\n父亲因为事忙', '亲因为事忙,本已说定不送我,叫旅馆里一个', '旅馆里一个熟识的茶房陪我同去。他再三嘱咐', '他再三嘱咐茶房,甚是仔细。但他终于不放心', '终于 不放心,怕茶房不妥帖;颇踌躇了一会。', '躇了一会。']22
我与父亲不相见已二年余了,我最不能忘记的
不能忘记的是他的背影。那年冬天,祖母死了
从输出上看,该文本分割器将langchain_desc分成了22个chunks,每个chunks的长度不超过20个字符。此外,如果是此前借助loader读取进来的文本,也可以使用split_documents方法。它接收的是一个Document对话,需要是列表形式。
如上就是CharacterTextSplitter文档分割器的基本使用方法,不用的数据形式,需要采用不同的方法来执行文本切割,使用哪种方法,是完全取决于大家在前一步数据加载过程中执行的操作是怎样的,这是需要明确的第一点。除此之外:在 TextSplitter 类(基类)的初始化函数中,有一个检查是确保 chunk_overlap 必须小于 chunk_size。这是为了确保文本分块的逻辑正常运行,因为重叠区域不能大于整个块的大小。这样的设计是为了确保每个块之间有足够的内容重叠,但又不会导致块之间的界限不明确或重叠区域过大。不难发现,LangChain通过巧妙的设计通过CharacterTextSplitter这一文档分割器就可以通过separator、chunk_size、chunk_overlap参数的灵活组合,实现了我们在如何将文本切分成Chunks中手动编写的三种切分方式。
-
2.3 RecursiveCharacterTextSplitter
在上一小节的三种切分方法下,虽然简单且更容易理解,但其存在的核心问题是:完全忽视了文档的结构,只是单纯按固定字符数量进行切分。所以难免要更进一步地去做优化,那么一个更进阶的文本分割器应该具备的是:
- 能够将文本分成小的、具有语义意义的块(通常是句子)。
- 可以通过某些测量方法,将这些小块组合成一个更大的块,直到达到一定的大小。
- 一旦达到该大小,请将该块设为自己的文本片段,然后创建具有一些重叠的新文本块,以保持块之间的上下文。
根据上述需求,衍生出来的就是递归字符文本切分器,在langChain中的抽象类为:RecursiveCharacterTextSplitter,同时它也是Langchain的默认文本分割器,在Baseloader类中,我们可以用LangChain提供的文本切分可视化小工具进行直观的理解:https://langchain-text-splitter.streamlit.app/

如上代码所展示的就是RecursiveCharacterTextSplitter类的核心逻辑。所谓的按字符递归分割,就是使用一组分隔符以分层和迭代的方式将输入文本分成更小的块。默认使用[“\n\n” ,"\n" ," ",""] 这四个特殊符号作为分割文本的标记,如果分割文本开始的时候没有产生所需大小或结构的块,那么这个方法会使用不同的分隔符或标准对生成的块递归调用,直到获得所需的块大小或结构。这意味着虽然这些块的大小并不完全相同,但它们仍然会逼近差不多的大小。其中的关键参数:
- separators:指定分割文本的分隔符
- chunk_size:被切割字符的最大长度
- chunk_overlap:如果仅仅使用chunk_size来切割时,前后两段字符串重叠的字符数量。
- length_function:如何计算块的长度。默认情况下,只计算字符数,也可以选择按照Token。
示例文本如下所示:
春节的脚步越来越近,大街小巷都布满了节日的气氛。商店门口挂满了红灯笼和春联,家家户户都在忙着打扫卫生,准备迎接新的一年。小明回到家乡,感受到了浓浓的过年氛围。他在街上走着,看到小朋友们手持烟花棒,欢笑声此起彼伏。夜幕降临,整个城市亮起了五彩缤纷的灯光,映照着人们脸上的喜悦与期待。老人们聚在一起,回忆过去,展望未来。而年轻人则在夜市享受美食,放松心情。这是一个充满希望和喜悦的时刻,每个人都在以自己的方式庆祝这个特殊的节日。同时调整Chunk Size,因为默认的是1000,很明显我们的测试文本长度低于1000,这里我们降低为100,同时将overlap设置为20:
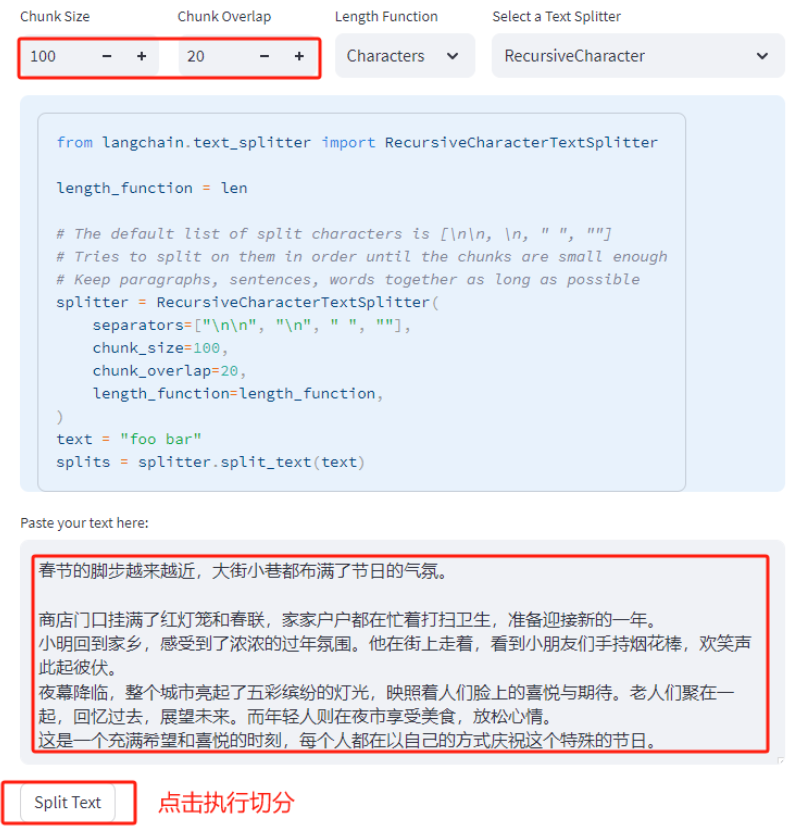
切分结果如下所示,会正常的切分为四个较为完整的chunks。
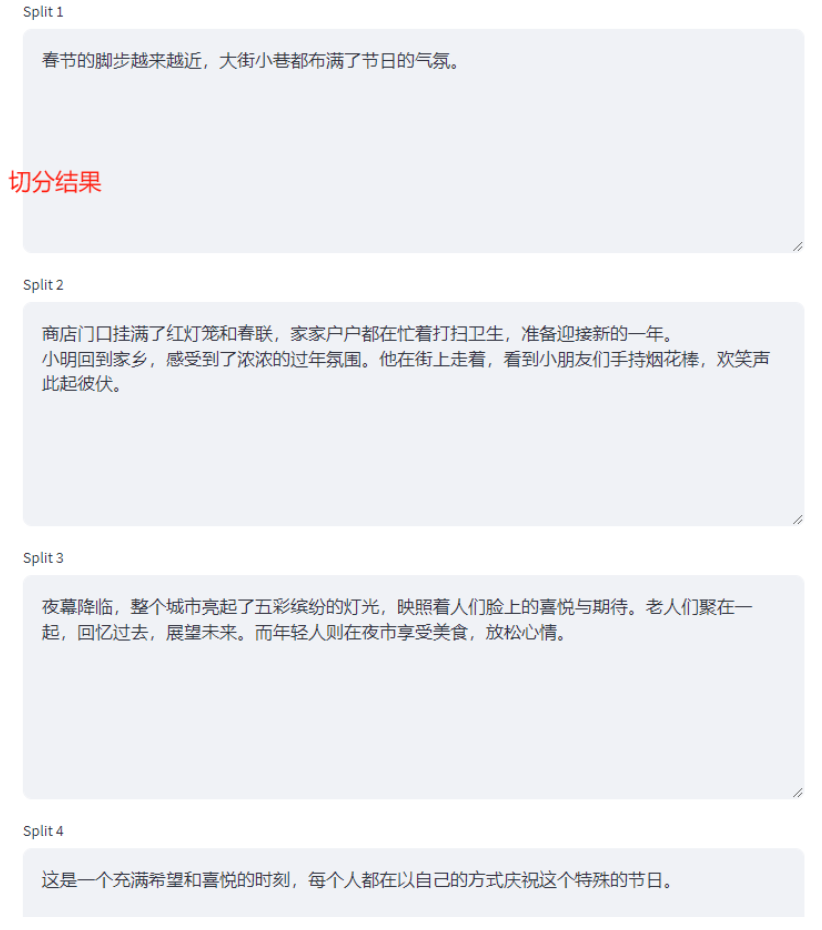
这里我们需要强调的两个关键点是:
- 切分的结果是由
length_function = len决定的,按照设置的切分规则,依次对文本进行分割; - 能不能进行分割,并不是由Chunk Size决定,超出Chunk Size只是触发条件,而真正会不会实际执行分割操作,取决于separator设置的关键词。
比如我们调低Chunk Size为50,再次执行。它会由原来的4个Chunk增加到8个Chunk,这里我们以chunk 3 和 chunk 4 举例说明:
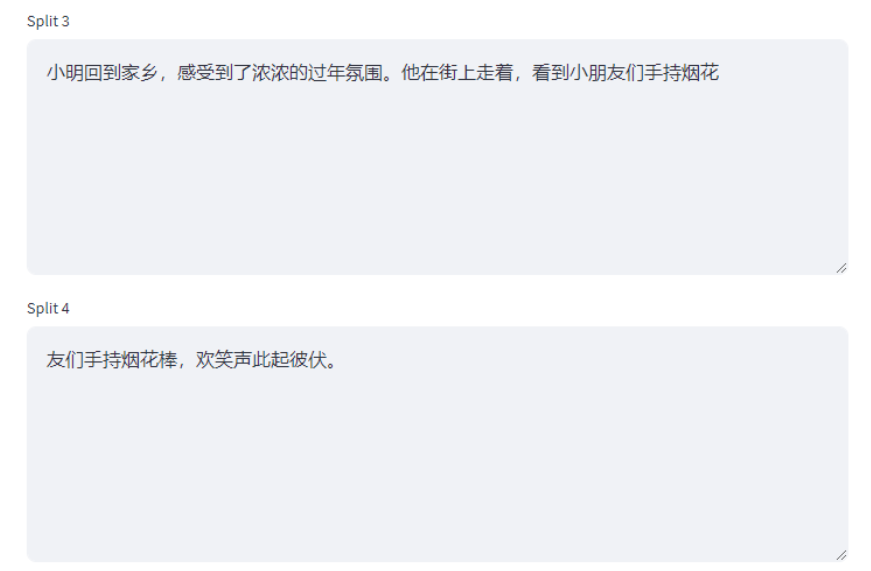
当Chunk Size设置为50时,第三行:“小明回到家乡,感受到了浓浓的过年氛围。他在街上走着,看到小朋友们手持烟花棒,欢笑声此起彼伏。”是超出50个字符,此时就会触发Chunk Overlap。也就说:当某一个片段溢出了Chunk Size设定的值,才会在下一个分片段中触发 Chunk Overlap,没有触发时,就不需要补充上下文,但当触发了以后,补充的上下文不能超过设定的Chunk Overlap.
在这种情况下虽然超出了 Chunk Size,但是按照separators=["\n\n", "\n", " ", ""]的规则,没有任何一条命中,所以不能分割。因此我们才说:超出Chunk Size只是触发条件,而能不能分割,取决于separator设置的关键词。
-
2.4 处理特定数据文档切分
在上面的介绍中,无论是手动实现还是借助于LangChain抽象好的文档加载器,均更倾向于处理普通的文本文件(如 .txt)。而当遇到更复杂的数据格式,如JSON、PDF等,之前的处理方式就并不再适用,此时考虑的应该是如何将文本分割的策略正确地匹配到具体的数据格式。
比如对于Markdown来说,其文档分割器为MarkdownTextSplitter。
from langchain.text_splitter import MarkdownTextSplittermarkdown_text = """
# 主题:技术探讨## 第一部分:前言这是前言部分,简短介绍文档主旨。## 第二部分:技术分析### Python编程### 解释1. **标题**:使用不同级别的标题(从`#`到`###`)来组织文档结构。
2. **代码块**:分别用Python和JavaScript代码块来示例如何在Markdown中嵌入代码。
3. **水平线**:使用`***`和`---`创建水平线,用于文档中不同部分之间的视觉分隔。
"""splitter = MarkdownTextSplitter(chunk_size=60, chunk_overlap=10)
markdown_split = splitter.create_documents([markdown_text])
print(markdown_split)
print(len(markdown_split))[Document(metadata={}, page_content='# 主题:技术探讨\n\n## 第一部分:前言\n\n这是前言部分,简短介绍文档主旨。\n\n## 第二部分:技术分析'),Document(metadata={}, page_content='### Python编程\n\n### 解释'),Document(metadata={}, page_content='1. **标题**:使用不同级别的标题(从`#`到`###`)来组织文档结构。'),Document(metadata={}, page_content='2. **代码块**:分别用Python和JavaScript代码块来示例如何在Markdown中嵌入代码。'),Document(metadata={}, page_content='3. **水平线**:使用`***`和`---`创建水平线,用于文档中不同部分之间的视觉分隔。')]5
同时,LangChain封装的MarkdownHeaderTextSplitter,它的切分逻辑是基于指定的标题来分割markdown文件。因为Markdown格式有特定的语法,一般整体内容由h1、h2、h3等多级标题组织,所以MarkdownHeaderTextSplitter的切分策略就是根据标题来分割文本内容。
from langchain_text_splitters import MarkdownHeaderTextSplitterheaders_to_split_on = [("#", "Header 1"),("##", "Header 2"),("###", "Header 3"),
]markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
md_header_splits = markdown_splitter.split_text(markdown_text)
print(md_header_splits)
print(len(md_header_splits))[Document(metadata={'Header 1': '主题:技术探讨', 'Header 2': '第一部分:前言'}, page_content='这是前言部分,简短介绍文档主旨。'), Document(metadata={'Header 1': '主题:技术探讨', 'Header 2': '第二部分:技术分析', 'Header 3': '解释'}, page_content='1. **标题**:使用不同级别的标题(从`#`到`###`)来组织文档结构。\n2. **代码块**:分别用Python和JavaScript代码块来示例如何在Markdown中嵌入代码。\n3. **水平线**:使用`***`和`---`创建水平线,用于文档中不同部分之间的视觉分隔。')]2
从输出上看,切分策略会根据指定标题(标题1, 标题2,标题3) ,且同一标题内的的数据被放置在同一个块内。
除此之外,还有一个CodeTextSplitter,可以按照代码进行分割,支持代码的语言包括['cpp', 'go', 'java', 'js', 'php', 'proto', 'python', 'rst', 'ruby', 'rust', 'scala', 'swift', 'markdown', 'latex', 'html', 'sol'],使用方法还是类似的,直接去实例化对应的文档分割器。
from langchain.text_splitter import (RecursiveCharacterTextSplitter,Language,
)md_splitter = RecursiveCharacterTextSplitter.from_language(language=Language.MARKDOWN, chunk_size=60, chunk_overlap=0
)
md_docs = md_splitter.create_documents([markdown_text])
print(md_docs) [Document(metadata={}, page_content='# 主题:技术探讨\n\n## 第一部分:前言\n\n这是前言部分,简短介绍文档主旨。\n\n## 第二部分:技术分析'),Document(metadata={}, page_content='### Python编程'),Document(metadata={}, page_content='### 解释'),Document(metadata={}, page_content='1. **标题**:使用不同级别的标题(从`#`到`###`)来组织文档结构。'),Document(metadata={}, page_content='2. **代码块**:分别用Python和JavaScript代码块来示例如何在Markdown中嵌入代码。'),Document(metadata={}, page_content='3. **水平线**:使用`***`和`---`创建水平线,用于文档中不同部分之间的视觉分隔。')]
从过程上看,其实现还是非常简单的,同样,对于JSON、代码等不同形式的解析并分割都可以按照相同的方式去操作。