从零构建短视频推荐系统:双塔算法架构解析与代码实现
刷短视频本来只想看几分钟,不知不觉一个多小时就没了。每条视频都恰好戳中你的兴趣点,这种精准推送背后其实是一套相当复杂的工程架构。
这种"读心术"般的推荐效果并非偶然。驱动这种短视频页面的核心引擎,正是业内广泛采用的双塔推荐系统(Two-Tower Recommendation System)。
本文将从技术角度剖析:双塔架构的工作原理、为何在短视频场景下表现卓越,以及如何构建一套类似的推荐系统。
推荐系统:注意力经济的核心武器
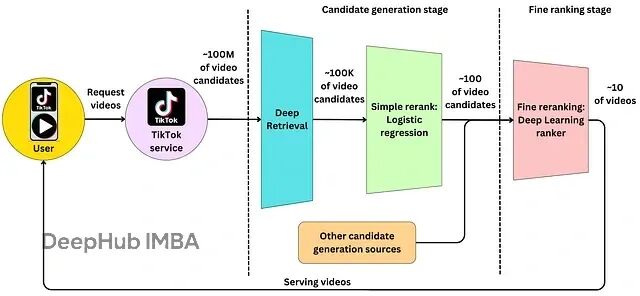
注意力经济时代,个性化推荐已经成为平台的基本能力。传统的"热门榜单"模式早已过时——因为用户很快就会感到内容乏味,并且推荐内容单一,无法吸引用户最终流失。
而短视频的成功在于能够预判用户需求,这也就是说为什么推荐系统成为当今最具商业价值的 AI 应用之一:
Netflix 通过推荐决定你下一部追的剧,YouTube 用算法填满你的首页和 Shorts 流,Amazon 靠推荐驱动购买决策,Spotify 的 Discover Weekly 帮你发现新音乐。
但论推荐效果,TikTok/抖音应该说是做到了极致。除了响应速度极快,个性化程度还极高。
双塔架构:两个"大脑"的协作机制
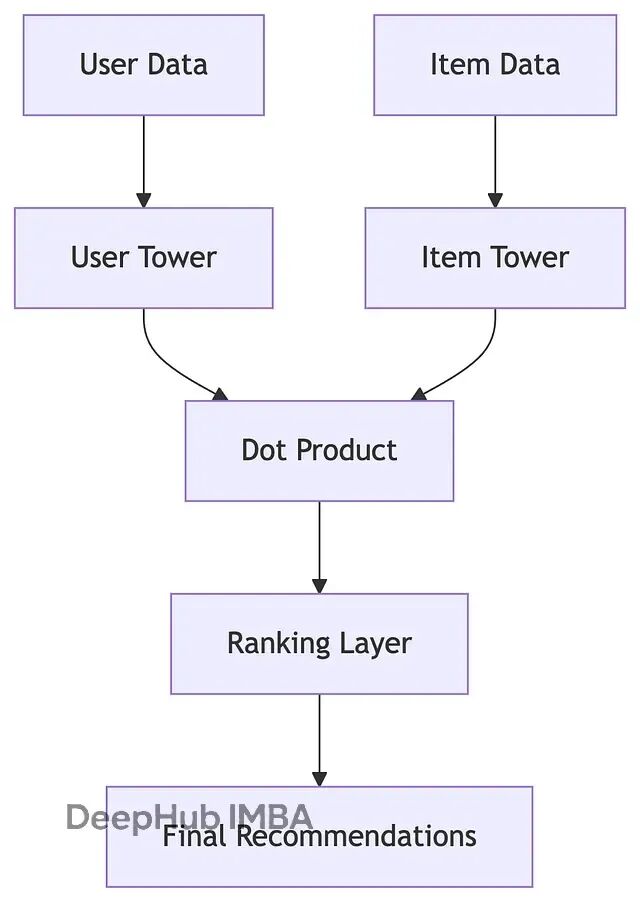
双塔系统本质上是两个独立但协调的神经网络模块:
**用户塔(User Tower)**专门建模用户特征——偏好习惯、行为模式、上下文信息等等。**物品塔(Item Tower)**则负责理解内容特征——视频属性、创作者风格、话题标签等。
这种设计的巧妙之处在于将复杂的用户-内容匹配问题,转化为两个向量空间的相似度计算。
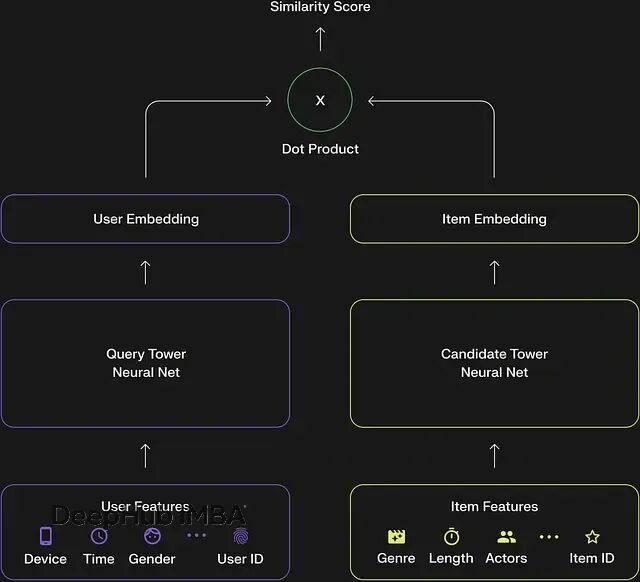
技术实现细节拆解
用户塔的特征工程
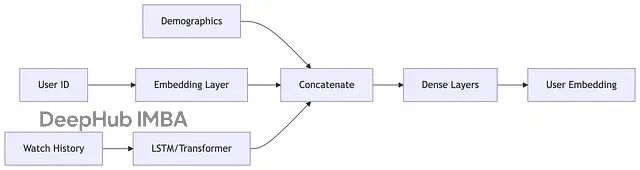
用户塔的任务是将用户的所有行为数据压缩成一个稠密向量表示,这个向量可以理解为用户的"数字指纹"。
输入特征通常包括:历史观看记录及停留时长、互动行为(点赞、分享、评论、关注),时间和地理位置等上下文信息,以及用户基础属性(年龄、性别等,如果可获取)。
这些原始特征经过 embedding 层和多层神经网络处理,最终输出一个固定维度的向量。这个向量在某种程度上"记住"了用户的兴趣偏好。
物品塔的内容理解
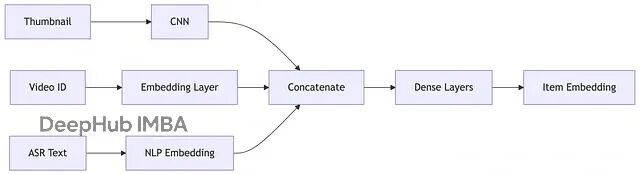
物品塔负责将每条物品转换为相应的向量表示。
以视频为例视频特征相对更加多元化:基础 ID 信息(视频 ID、创作者 ID),内容标签和话题分类,音频特征(BGM、音效等),文本信息(标题、字幕、ASR 转录文本),视觉特征(通常使用预训练的 CNN 模型提取关键帧或缩略图的特征向量)。
同样经过神经网络处理后,每条视频都得到一个与用户向量处于同一语义空间的表示向量。
向量匹配与相似度计算
两个塔产生的向量如何进行匹配?最直接的方法是计算向量间的点积或余弦相似度。相似度越高,表明用户对该视频的潜在兴趣越大。
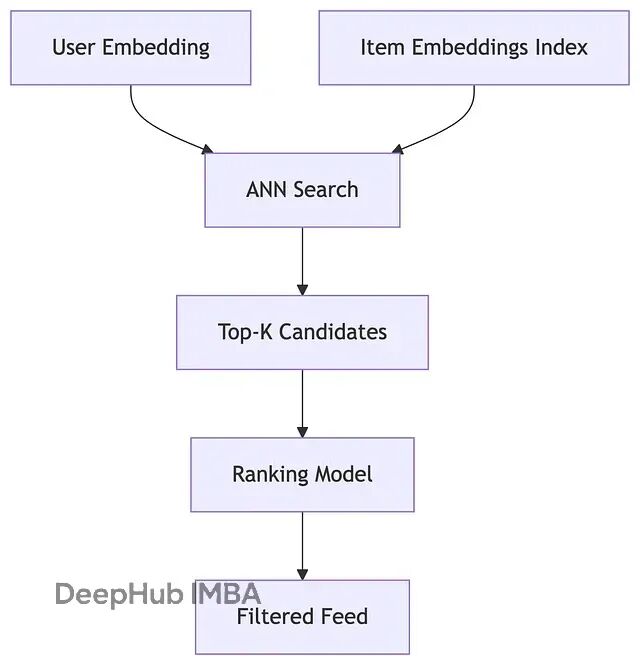
但是面对百万级别的视频库,逐一计算显然不现实。所以就需要用到近似最近邻搜索(ANN)技术,比如 Facebook 开源的 Faiss 或者 Google 的 ScaNN。这些工具能够在毫秒级时间内从海量向量中找出最相似的候选集合。
从启动到推荐:完整的数据流

当用户打开 短视频时,后台的推荐流程大致如下:
首先实时计算或获取用户的最新特征向量。接着通过 ANN 检索从全量视频库中召回几千个潜在候选。然后使用更复杂的排序模型对候选视频进行精排,考虑预期观看时长、互动概率等多个目标。
在内容输出前还会应用各种业务规则:内容去重避免相似视频连续出现,新内容扶持保证流量分配的公平性,安全审核过滤违规内容。最后将排序好的视频推送到用户端,整个过程只需要几十毫秒以内就可以完成。
双塔模型的代码实现
想要实现一个简化版的双塔模型,可以参考以下代码框架。
数据准备阶段
# Example log data (user_id, video_id, watch_time, liked) logs = [ ("user1", "video123", 5.2, True), ("user1", "video456", 1.1, False), ("user2", "video789", 8.5, True), ]
特征存储系统
实际生产环境中需要构建实时特征存储系统。用户特征可能包括不同类别内容的观看统计、活跃时段分布等。视频特征则涵盖分类标签、互动指标聚合值等。
特征存储的核心是保证训练和推理阶段特征的一致性,同时满足低延迟的在线服务需求。
模型训练
双塔模型采用对比学习的训练方式。正样本来自真实的用户-视频交互记录,负样本则通过随机采样生成。训练目标是让正样本对应的用户向量和视频向量尽可能接近,负样本对应的向量尽可能远离。
常用的损失函数包括 InfoNCE,配合 in-batch negatives 策略能够有效提升训练效率。
import tensorflow as tf
from tensorflow.keras.layers import Input, Dense, Embedding, Dot # User Tower
user_input = Input(shape=(1,), name="user_id")
user_embedding = Embedding(num_users, 64)(user_input)
user_vec = Dense(32, activation="relu")(user_embedding) # Item Tower
item_input = Input(shape=(1,), name="item_id")
item_embedding = Embedding(num_items, 64)(item_input)
item_vec = Dense(32, activation="relu")(item_embedding) # Dot Product (Interaction)
dot_product = Dot(axes=1)([user_vec, item_vec]) model = tf.keras.Model(inputs=[user_input, item_input], outputs=dot_product)
model.compile(optimizer="adam", loss="binary_crossentropy") model.fit([user_ids, item_ids], labels, epochs=10)
向量索引构建
模型训练完成后,需要为所有视频预计算向量表示,并构建 ANN 索引以支持快速检索。
import faiss # Store all item embeddings in Faiss for fast search
item_embeddings = model.get_layer("item_embedding").get_weights()[0]
index = faiss.IndexFlatIP(32) # Inner Product search
index.add(item_embeddings) # Get recommendations for a user
user_embedding = user_model.predict(["user123"]) _, recommended_ids = index.search(user_embedding, k=10) # Top 10 videos
线上服务部署
生产环境的推荐服务需要处理实时用户请求。系统接收用户特征后,调用用户塔计算向量表示,然后查询 ANN 索引获取候选集,最后经过排序模型输出最终推荐结果。
整个链路的延迟控制是关键指标,通常要求在 100 毫秒以内完成。
import tensorflow as tf # A simple two-tower model using user IDs and item IDs
class TwoTowerModel(tf.keras.Model): def __init__(self, user_vocab_size, item_vocab_size, embed_dim): super().__init__() # Embedding layers for users and items (learnable lookup tables) self.user_embedding = tf.keras.layers.Embedding(input_dim=user_vocab_size, output_dim=embed_dim) self.item_embedding = tf.keras.layers.Embedding(input_dim=item_vocab_size, output_dim=embed_dim) def call(self, inputs): user_id, item_id = inputs # expecting user and item IDs as inputs # Get embeddings for user and item user_vec = self.user_embedding(user_id) # shape: [batch_size, embed_dim] item_vec = self.item_embedding(item_id) # shape: [batch_size, embed_dim] # Compute dot product similarity (and squeeze to 1D) score = tf.reduce_sum(user_vec * item_vec, axis=1) return score # Example usage:
model = TwoTowerModel(user_vocab_size=10000, item_vocab_size=50000, embed_dim=32)
user_ids = tf.constant([123]) # a sample user ID
item_ids = tf.constant([456]) # a sample item ID
predicted_score = model((user_ids, item_ids)).numpy() print("Predicted score:", predicted_score)
工程实践中的核心挑战
冷启动问题是推荐系统的经典难题。新用户缺乏历史行为数据,新视频没有互动反馈,这时需要依赖内容特征和一些启发式规则来进行推荐。
流行度偏差同样需要重点关注。热门内容容易获得更多曝光,形成马太效应。平衡热门内容和长尾内容的分发比例,关系到内容生态的健康发展。
特征一致性在工程实践中经常被忽视。离线训练和在线推理使用的特征定义必须严格一致,否则会导致模型效果大幅下降。
效果评估体系
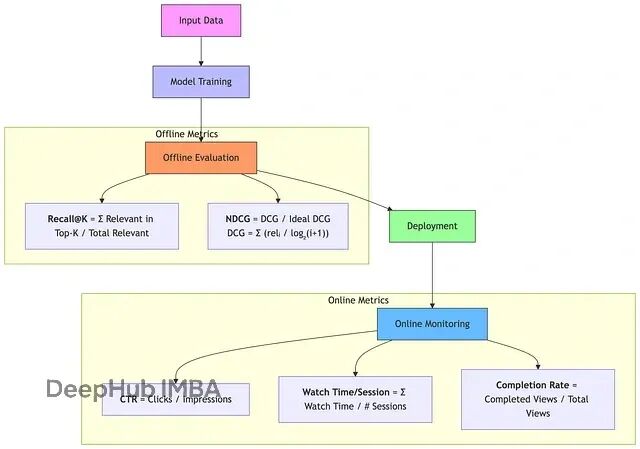
推荐系统的评估需要结合在线和离线指标。
在线指标主要关注用户实际行为:点击率(CTR)、观看时长、完播率、互动率等。这些指标直接反映推荐效果对用户体验的影响。
离线指标则用于模型开发阶段的快速评估:召回率@K 衡量候选召回的质量,NDCG 评估排序效果,AUC 反映分类性能等。

双塔架构的核心优势
短视频推荐对响应速度要求极高,用户不会为了等待推荐结果而忍受几秒钟的加载时间。
双塔架构在这方面表现出色:向量可以离线预计算,大幅减少在线计算开销;架构简单清晰,容易做水平扩展;能够自然地融合协同过滤和内容过滤的优势。
相比于复杂的深度模型,双塔系统在保证效果的同时更易于工程实现和维护。

短视频推荐效果看似神奇,实际上是大量工程优化和算法创新的结果。
整个系统的核心逻辑其实不复杂:把用户偏好和内容特征都编码成向量,然后在高维空间中进行相似度匹配。难点在于如何设计特征、如何训练模型、如何优化工程性能。
用户塔将观看历史、互动行为、时间上下文等信息压缩为 256 维向量,例如
[0.2, -0.7, ..., 0.4]
。
视频塔将内容元数据、音频特征、创作者信息等编码为同样维度的向量,例如
[-0.1, 0.5, ..., 0.3]
。
实时匹配通过余弦相似度计算用户向量和视频向量的匹配程度,使用 FAISS 等工具实现毫秒级的近似最近邻检索,找出最相关的 50 条候选视频。
最终的推荐列表还会根据时效性、多样性等业务规则进行调整,确保在 10 毫秒内完成整个推荐流程。
总结
我们上面这只是推荐系统的基础架构。真正的产品化还需要考虑更多细节:多目标优化、实时反馈、AB 测试、内容安全等等。但双塔模型为这些复杂需求提供了一个稳定可靠的技术基础。
完整代码:
https://avoid.overfit.cn/post/8a6c8f94d2764cc9bdf9e7fc781e09f5
作者:Prem Vishnoi