BERT 总结
自用
目录
1. 模型结构
2. 预训练任务
3. 使用方式
4. 应用场景(下游任务)
5. 特点 & 贡献
6. 局限性
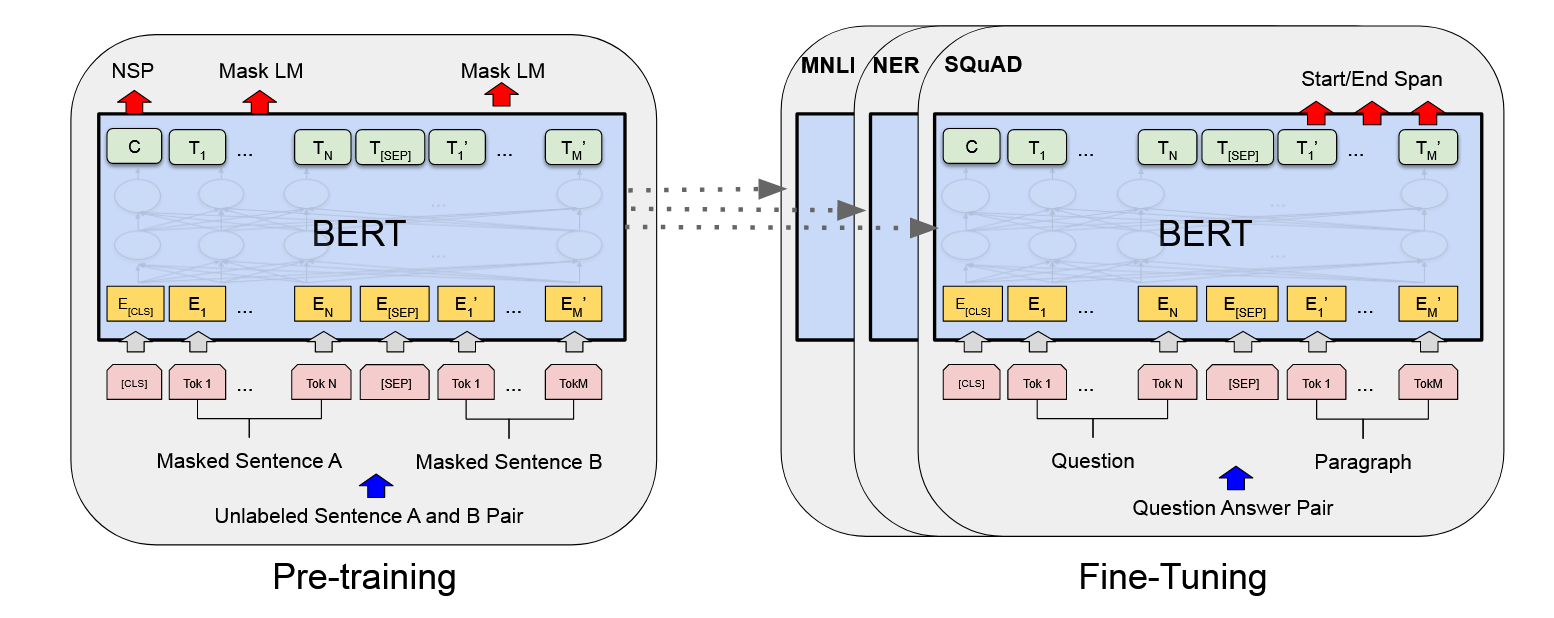
1. 模型结构
-
基于 Transformer Encoder(没有 Decoder)
-
主要参数
-
L:层数(BERT-Base 12 层,BERT-Large 24 层)
-
H:隐层维度(768 / 1024)
-
A:注意力头数(12 / 16)
-
-
输入嵌入 = 词嵌入 + 位置嵌入 + 句子嵌入
-
输出:对每个 token 的上下文向量表示
2. 预训练任务
BERT 用 无监督语料 训练,目标是学到通用语言表示:
-
MLM (Masked Language