聊聊Bert模型输出的pooler_output与last_hidden_state
周末了, 今天来聊聊这个Bert模型的输出。
闲言少叙,开始~~
Bert模型一般会输出什么?
这里我以bert系列的经典模型‘bert-base-chinese’为示例
代码都很简单就不过多张贴了(算了还是看看吧~,也可以不用看 ^_^),
from transformers import BertModel, BertTokenizer
import warnings
import os
os.environ['TF_ENABLE_ONEDNN_OPTS']='0'
warnings.filterwarnings('ignore')# 加载模型和分词器
model = BertModel.from_pretrained(r'bert-base-chinese')
tokenizer = BertTokenizer.from_pretrained(r'bert-base-chinese')# 输入文本
inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
print(inputs)
# 模型前向传播
outputs = model(**inputs)
print(outputs)
# 获取两种输出
last_hidden_states = outputs.last_hidden_state
pooler_output = outputs.pooler_outputprint(f"last_hidden_state 的形状: {last_hidden_states.shape}")
# 输出: torch.Size([1, 9, 768])
# 解释: [1个句子, 9个tokens(包括[CLS]和[SEP]), 768维向量]print(f"pooler_output 的形状: {pooler_output.shape}")
# 输出: torch.Size([1, 768])
# 解释: [1个句子, 768维向量]# 验证 pooler_output 的来源
cls_vector_from_last_hidden = last_hidden_states[:, 0, :] # 取出 [CLS] 的向量
print(f"[CLS] 向量的形状: {cls_vector_from_last_hidden.shape}")
这里直接看看输出
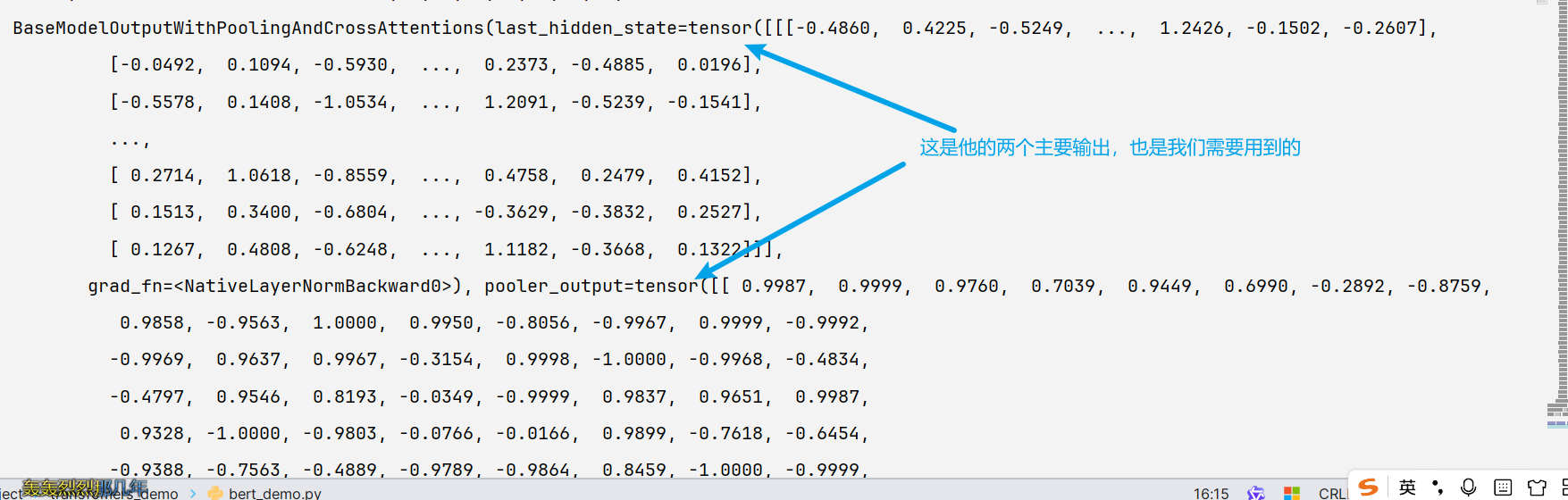
严谨的来说还可以有这些

我们在开发中用的比较多的是输出里面的last_hidden_state和pooler_output,这也今天话题的主角哦
这里我将这两哥们的形状输出打印一下吧

这里
last_hidden_state的形状对应是[batch_size,sequence_length,hidden_size]
pooler_output的形状对应是[batch_size,hidden_size]
last_hidden_state: 记录的是输入序列中每一个token位置在最后一层Transformer的输出,是token级别的上下文表示。(简单来说,整个序列中每一个时刻(每个词)的详细信息。)
pooler_output:句子级别的摘要表示,是为输入序列生成的单一向量表示(j简单来说就是,整个句子的语义表)
两者有什么关系?
看到他们的输出的形状,你可能会突发好奇 ,这~ 这个pooler_output是不是从last_hidden_state 里面取了一个Token的表示出来哦
对,但又不完全对
下面来揭晓谜底
他们的计算过程概述
last_hidden_state 的来源:
输入序列经过BERT的所有Transformer层。
最后一层Transformer为输入序列中的每一个token都输出一个高维向量(例如768维)。
所有这些向量的集合就是
last_hidden_state。
pooler_ouput的来源:
从
last_hidden_state中取出第一个向量,也就是[CLS]标记对应的向量(last_hidden_state[:, 0, :])。将这个向量通过一个小的全连接层(也叫池化层),公式为:
Tanh(W * [CLS]_vector + b)。这个全连接层的参数
W和b是在预训练(Next Sentence Prediction任务)和微调过程中学习到的。
总结:
看到这里,相信你也知道他们的关系:
形象一点来说呢:
last_hidden_state:就像一部电影的每一帧画面。它包含了整个序列中每一个时刻(每个词)的详细信息。
pooler_output:就像是这部电影的海报或剧情简介。它试图用一张图或几句话来概括整部电影的核心内容。
所以他们在开发中的使用时机和场景也不同:
小结:
1。last_hidden_state:Token级别的任务,如NER,分词,填空(MLM),序列标注等等
2. pooler_output: 句子级任务,如分类(情感分析),句子配对,下一句预测 , (相似性计算,自然语义推理,NLI)等等
note:
在 BERT 里,last_hidden_state 是整个输入序列里每个 token 的最终表示,形状是 [batch_size, seq_len, hidden_size]。
pooler_output 这个名字容易让人误解成池化所有 token,其实不是。它只是取了 [CLS] 位置的向量,再通过一层全连接层加 tanh,得到一个 [batch_size, hidden_size] 的向量。
可以理解为是一种“伪池化”:用 [CLS] 作为整句话的代表,经过变换后作为全局语义向量。这个结果常用于句子级别的任务,比如分类或句子对匹配。
如果任务是 token 级别的,比如命名实体识别或者填空预测,就直接用 last_hidden_state。