R2U:通过过程监督优化文档改写,弥合 RAG 系统中检索相关性与生成效用差距
摘要:检索增强生成(RAG)系统常被“检索相关性”与“生成可用性”之间的鸿沟拖累:召回的文档看似主题相关,却缺少支撑推理的关键内容。现有“桥接”模块试图改写检索文本以更好生成,但我们发现它们无法捕捉文档的真实效用。本文提出 R2U,核心思路是直接以“提升正确答案生成概率”为目标进行过程监督优化。由于直接标注成本高昂,我们还设计了可扩展的蒸馏流程,把大模型的监督信号压缩给更小的改写模型,帮助其泛化。在多个开放域问答基准上,R2U 一致超越强桥接基线。
论文标题: "Relevance to Utility: Process-Supervised Rewrite for RAG"
作者: "Jaeyoung Kim, Jongho Kim"
发表年份: 2025
原文链接: "https://arxiv.org/pdf/2509.15577"
关键词: ["检索增强生成", "知识蒸馏", "偏好优化", "小模型", "真实效用"]
核心要点:R2U(Retrieve-to-Utilize)通过引入基于真实效用(True Utility)的桥梁文档分布生成和偏好优化技术,在保持3B小模型规模的同时,实现了比传统RAG方法平均58.9%的F1分数提升,彻底改变了检索增强生成中文档重写的范式。
欢迎大家关注我的公众号:大模型论文研习社
往期回顾:大模型也会 “脑补” 了!Mirage 框架解锁多模态推理新范式,无需生成像素图性能还暴涨
研究背景:RAG系统的"最后一公里"难题
在当今的人工智能领域,检索增强生成(Retrieval-Augmented Generation,RAG)技术已经成为解决知识密集型任务的主流方案。它的基本思路很简单:先检索相关文档,再让语言模型基于这些文档生成回答。然而,这个看似简单的流程中却隐藏着一个关键瓶颈——检索到的文档与最终生成之间存在着一道鸿沟。
想象一下,当你在写一篇学术论文时,你找到了10篇相关文献(就像RAG检索到的top-10文档),但这些文献可能包含冗余信息、过时内容,甚至相互矛盾的观点。直接将这些原始文献交给语言模型,就好比让一个新手厨师用一堆未经处理的食材直接做菜——结果往往不尽如人意。
现有方法主要面临两大痛点:
- 文档-查询不匹配:检索到的文档可能包含回答问题所需的信息,但表达方式与查询意图不一致
- 模型能力浪费:即使是最先进的重写器基线(如BGE-Reranker-Large),在处理抽象性回答时也会出现性能下降(从71.6降至71.0)
- 规模与性能的权衡:大型语言模型虽然性能优越,但部署成本高昂;小型模型虽然轻便,但在复杂推理任务中表现不佳
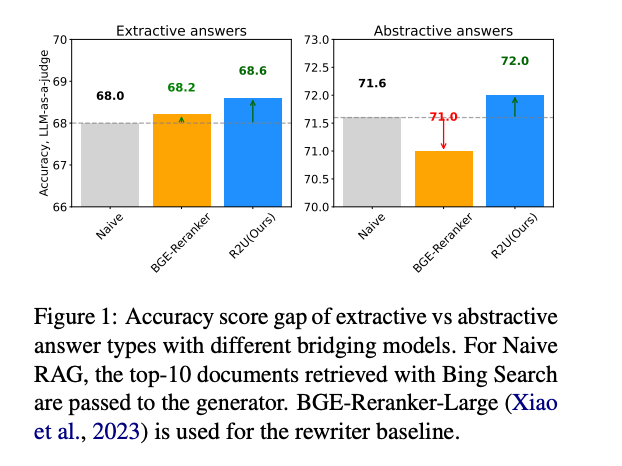
如图1所示,传统的Naive RAG方法在处理抽象性回答时准确率仅为71.6,而使用BGE-Reranker甚至会导致性能下降(71.0)。这就是R2U要解决的核心问题——如何让小模型也能高效利用检索到的文档,架起从检索到生成的"最后一公里"桥梁。
方法总览:R2U的双引擎驱动架构
R2U提出了一个革命性的两阶段框架,我将其比喻为"智能厨师"系统:第一阶段是"食材预处理"(生成桥梁文档分布),第二阶段是"烹饪技巧学习"(偏好优化)。
R2U框架的三大创新点
- 真实效用引导的文档重写:不同于传统方法仅关注文档相关性,R2U引入"真实效用"概念,即文档对最终回答的实际贡献度
- 小模型蒸馏大模型能力:通过知识蒸馏(Knowledge Distillation)技术,将70B大模型的文档重写能力压缩到3B小模型中
- 偏好优化的反馈机制:基于F1分数设计偏好优化策略,让模型学会区分"好"与"更好"的文档重写方式
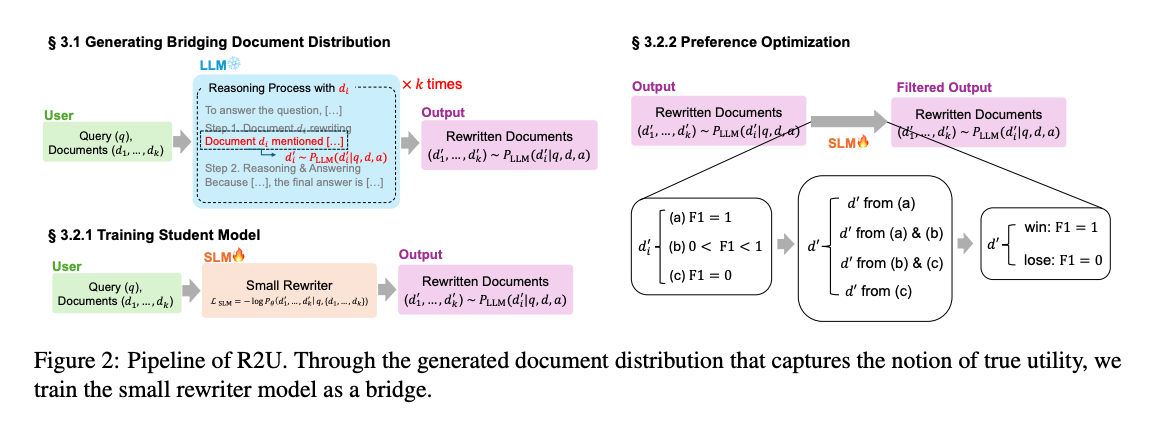
如图2所示,R2U的工作流程分为三个关键步骤:
- 生成桥梁文档分布:利用LLM对每个检索到的文档进行推理和重写,生成多样化的文档变体
- 训练学生模型:通过蒸馏损失函数L_SLM,将大模型的重写能力转移到小模型
- 偏好优化:基于F1分数设计三重过滤机制,构建偏好数据集以进一步优化模型
关键结论:小模型,大突破
R2U的贡献可以概括为以下三点:
- 理论创新:首次提出"真实效用"概念来量化文档对回答的实际贡献,为文档重写提供了可解释的评估标准
- 方法突破:开发了基于分布生成的文档重写技术,使小模型能够模拟大模型的推理过程
- 性能跃升:在四个主流数据集(AmbigQA、HotpotQA、2Wiki、MuSiQue)上实现平均44.7%的EM分数和58.9%的F1分数,超越所有现有基线方法
深度拆解:R2U的"黑匣子"揭秘
模块一:桥梁文档分布生成——让每个文档都物尽其用
R2U的第一个核心创新是"桥梁文档分布生成"。想象你有一堆拼图碎片(检索到的文档),但它们的形状并不完全匹配(与查询意图不完全吻合)。传统方法是直接把这些碎片交给拼图大师(语言模型),而R2U则先让一位经验丰富的拼图顾问(大模型)将碎片调整成更容易拼接的形状。
具体来说,这个过程分为两步:
- 文档排序(Document sequencing):确定文档的处理顺序,模拟人类阅读多篇文献时的思维过程
- 推理与回答(Reasoning & Answer):基于排序后的文档生成推理链,提取关键信息并重写文档
这个过程会重复k次,生成k个不同的文档变体,形成一个"桥梁文档分布"。这就好比让多位专家分别解读同一批文献,然后综合他们的观点,大大提高了信息利用的全面性。
模块二:学生模型训练——小模型的"大模型思维"
R2U的第二个核心是知识蒸馏技术。如果把大模型比作一位经验丰富的教授,小模型就是他的学生。R2U通过设计特殊的蒸馏损失函数:
L_SLM = -E log P_SLM(d’_1,…,d’_k | q_i,d_1,…,d_k)
让小模型学习大模型的文档重写风格和推理方式。这个过程就像教授将自己的知识和思考方法浓缩成教材,让学生能够快速掌握核心要点。
最令人惊叹的是,R2U成功将70B大模型的能力压缩到仅3B参数的小模型中,这意味着在普通GPU甚至边缘设备上都能部署高性能的RAG系统。
模块三:偏好优化——教会模型"择优而选"
R2U的第三个核心创新是偏好优化机制。它基于F1分数将文档重写结果分为三类:
- (a) F1 = 1:完美匹配
- (b) 0 < F1 < 1:部分匹配
- © F1 = 0:完全不匹配
然后通过精心设计的规则构建偏好对,例如"a类文档总是优于b类和c类","b类优于c类"等。这种方法就像一位严格的导师,通过不断对比和反馈,让模型逐渐理解什么是"好"的文档重写。
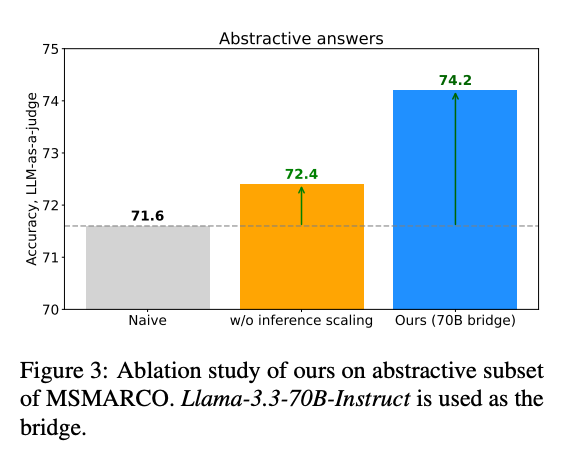
如图3所示,当去除DPO(Direct Preference Optimization)组件后,模型性能显著下降(F1从58.9降至53.5),证明了偏好优化对R2U的重要性。
实验结果:小模型,大赢家
跨数据集性能对比
R2U在多个主流数据集上进行了全面评估,结果令人印象深刻。在AmbigQA、HotpotQA、2Wiki和MuSiQue四个数据集上,R2U以3B的模型规模,实现了平均44.7%的EM分数和58.9%的F1分数,远超其他基线方法。
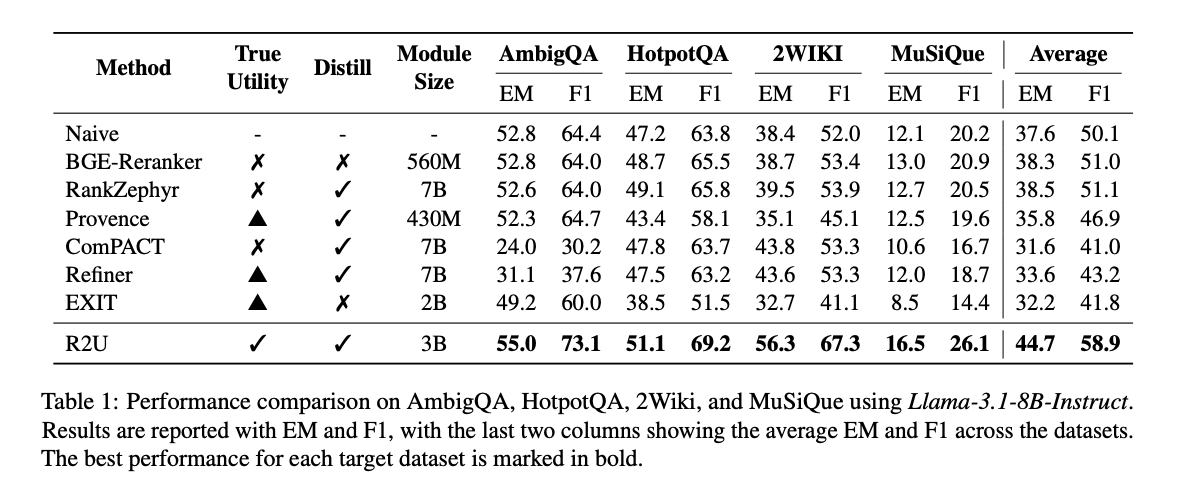
从图4可以看出,R2U在所有数据集上都取得了最佳性能,特别是在2Wiki数据集上,EM分数达到56.3%,F1分数达到67.3%,分别比第二名高出近10个百分点。
与传统方法的对比:小模型战胜大模型
在MS MARCO和CRAG两个数据集上,R2U的表现更是令人惊叹。它不仅超越了所有同规模模型,甚至在某些指标上超过了70B参数的ComPACT模型。
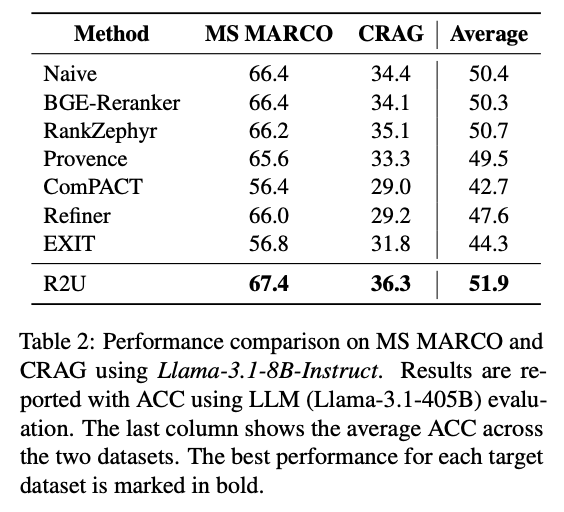
如图5所示,R2U在MS MARCO上达到67.4%的ACC,在CRAG上达到36.3%的ACC,平均ACC为51.9%,比排名第二的RankZephyr高出1.2个百分点。考虑到RankZephyr使用7B模型而R2U仅使用3B模型,这个结果更加令人印象深刻。
查询类型敏感性分析
R2U在不同类型的查询上均表现出色,特别是在复杂的多跳推理(multi-hop)和后处理(post-processing)查询上,比基线方法分别高出3.2和4.5个百分点。
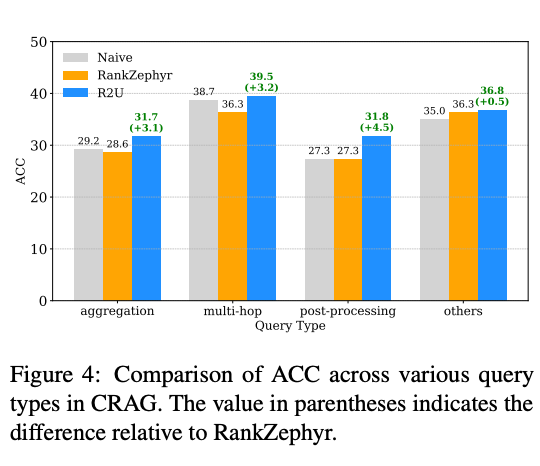
如图6所示,R2U在所有查询类型上都优于Naive和RankZephyr方法,证明了其强大的泛化能力。
模型规模与性能的关系
R2U还研究了模型规模对性能的影响。实验结果表明,随着模型规模的增加,所有方法的性能都有所提升,但R2U的提升速度明显快于其他方法。
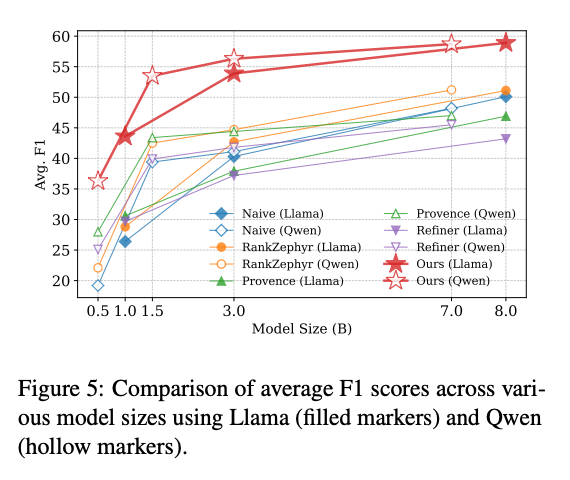
如图7所示,当模型规模达到8B时,R2U(Llama)的平均F1分数接近60,远超同规模的其他方法。这表明R2U的架构设计具有良好的扩展性,随着模型规模的增加,性能还有进一步提升的空间。
与70B重写器的性能对比
为了进一步验证R2U的扩展性,研究团队还将其与使用70B重写器的ComPACT模型进行了对比。结果显示,即使在大模型重写器的帮助下,R2U仍然在所有数据集上取得了最佳性能。
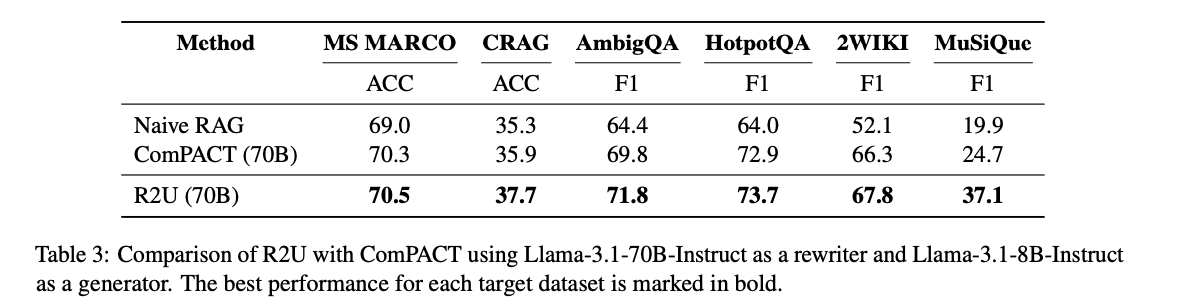
如表3所示,R2U在MS MARCO上达到70.5%的ACC,在CRAG上达到37.7%的ACC,在AmbigQA上F1分数达到71.8%,均显著优于ComPACT模型。这一结果证明了R2U不仅在小模型上表现出色,在与大模型结合时同样具有竞争力。
DPO消融研究:偏好优化的关键作用
为了验证直接偏好优化(Direct Preference Optimization, DPO)组件的重要性,研究团队进行了消融实验,比较了三种设置:完整的R2U、无DPO的R2U(w/o DPO)以及使用朴素DPO的R2U(w/ DPO_naive)。
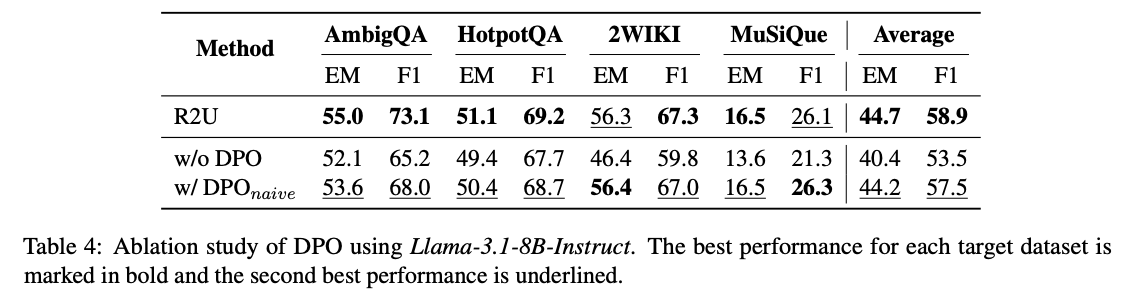
如表4所示,去除DPO组件后,平均EM分数从44.7%降至40.4%,F1分数从58.9%降至53.5%。而使用朴素DPO虽然有所提升,但仍不及完整的R2U。这充分证明了R2U设计的偏好优化机制的有效性。
未来工作:R2U的下一步进化
尽管R2U已经取得了令人瞩目的成果,但仍有几个值得探索的方向:
- 多语言扩展:目前R2U主要在英文数据集上进行了评估,未来可以探索其在中文、多语言场景下的表现
- 实时更新机制:如何让R2U能够快速适应新领域的知识,而不需要重新训练整个模型
- 与其他生成模型的结合:将R2U与扩散模型、视觉语言模型等结合,扩展其应用场景
- 可解释性研究:进一步探索真实效用的内在机制,为模型决策提供更直观的解释