【仿生人形机器头】唇形同步
我现在在做视位素的归类,我会把口型相似的合并到一起。
其实只有嘴唇和下颚的事情。
其中下颚只有开关角度。
L0,L1,L2,L3 代表下颚张开的幅度,L0是下颚闭合,L1是小角度张开,L2是正常张开,L3是大幅度张开。
而唇部有上唇,下唇,两侧。其中两侧的舵机可以控制咧嘴,参与嘟嘴。
P0 是上下唇闭合,P1是上下唇小角度张开,P2是上下唇大角度张开,
C0是两侧舵机初始中间状态;
C1是两侧舵机小幅度夹,形成小幅度的轻嘟嘴;—— 轻幅度嘟嘴,“o”
C2是两侧舵机中幅度夹,形成中幅度的嘟嘴;—— 中幅度嘟嘴,“w”,“u”
C3是两侧舵机大幅度夹,形成大幅度的嘟嘴;—— 嘟嘴到闭嘴,“亲吻”
C9是两侧舵机反方向大幅度拉,形成大幅度的咧嘴;
特别的:在P的基础上加的偏移量
SXC0 代表轻升下唇,SXC1 代表中幅度升下唇,SXC2 代表大幅度升下唇
JXC0 代表轻降下唇,JXC1 代表中幅度降下唇,JXC2 代表大幅度降下唇
SSC0 代表轻升上唇,SSC1 代表中幅度升上唇,SSC2 代表大幅度升上唇
JSC0 代表轻降上唇,JSC1 代表中幅度降上唇,JSC2 代表大幅度降上唇
首先是声母:除了嘟嘴,全是咧嘴;除了双颚闭合,全是双颚张开
b,p,m;(双颚张开L1,嘴唇闭合P0 ,咧嘴C9)到(双颚张开L2,嘴唇小张P1 ,咧嘴C9 )
f;(不嘟嘴,有上牙咬下唇的感觉)双颚张开L1,嘴唇小张P1 + 升下唇SXC0,咧嘴C9
d,t,n,l,g,k,h;(微张嘴,不嘟嘴,且下唇比较靠下 )双颚张开L1,嘴唇小张P1,咧嘴C9
j,q,x,z,c,s;(张口,咧嘴)双颚张开L1,嘴唇小张P1,咧嘴C9
zh,ch,sh,r;(上下唇张开呈圆形,上唇往上,下唇往下,露出牙齿,轻嘟嘴,闭嘴,上下颚牙齿闭合)双颚闭合L0 ,嘴唇大张P2,嘟嘴C1
y;(双颚张开L1,嘴唇小张P1,咧嘴C9)
w;(双颚张开L2,嘴唇小张P1,嘟嘴C2)
然后是韵母:
a,e,ai,ei,er;(双颚张开L3,嘴唇大张P2,唇部C0)
o,ong;(双颚张开L3,嘴唇大张P2,嘟嘴C1)
u,ü;(双颚张开L2,嘴唇小张P1,嘟嘴C2)
i,in,ing;(双颚张开L1,嘴唇小张P1,咧嘴C9)
ui(微);(双颚张开L1,嘴唇小张P1,咧嘴C9)
ao,ou;(双颚张开L3,嘴唇大张P2,嘟嘴C1)
iu(优);(双颚张开L2,嘴唇小张P1,嘟嘴C2)
ie(椰);(双颚张开L3,嘴唇大张P2,唇部C0)
ue;(双颚张开L3,嘴唇大张P2,唇部C0)
an,en;双颚张开L2,嘴唇大张P2,咧嘴C9
ang,eng;双颚张开L3,嘴唇大张P2,咧嘴C9
un,ün;(比较特殊,必须是个过程,就是嘟一下嘴,再复位)
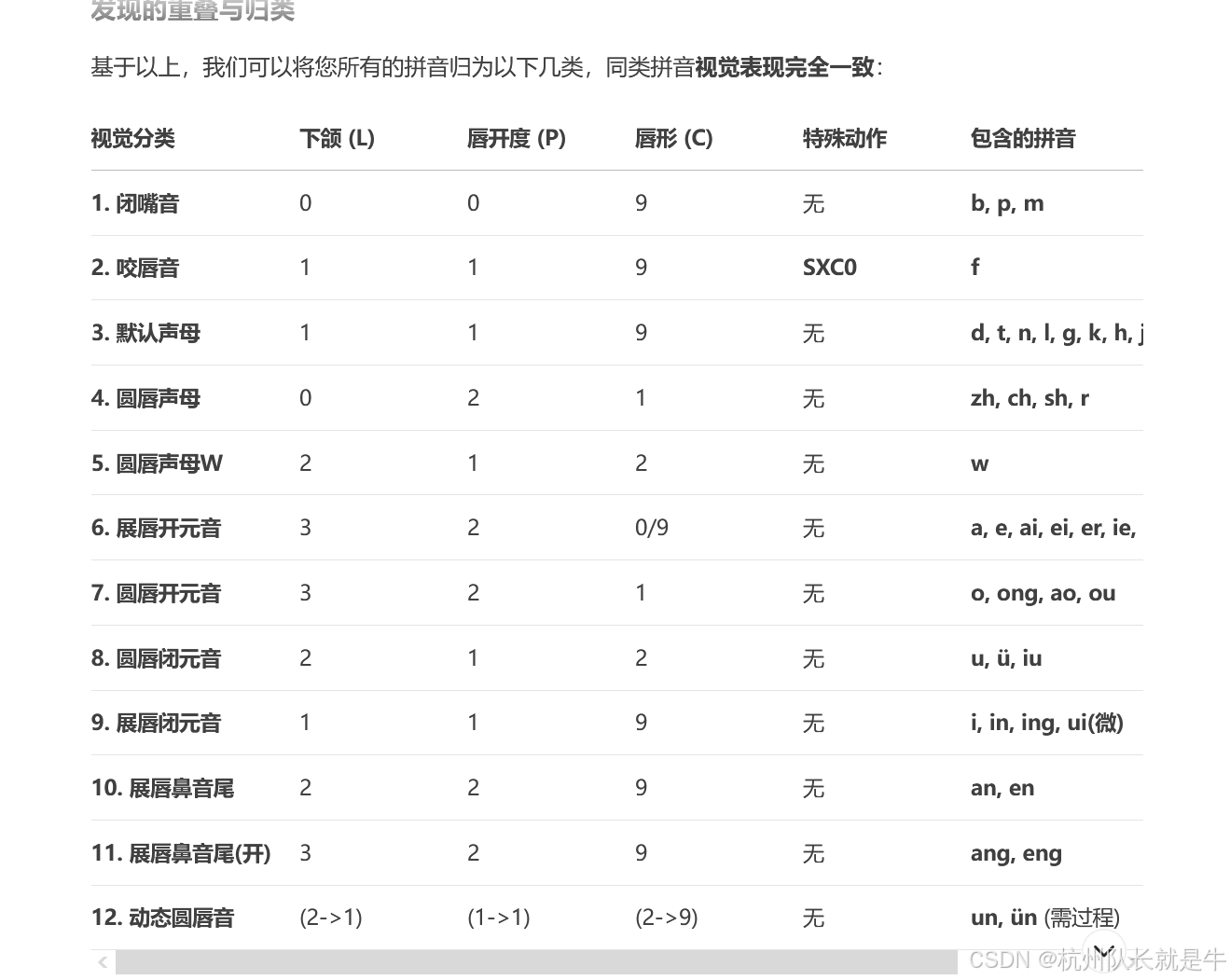

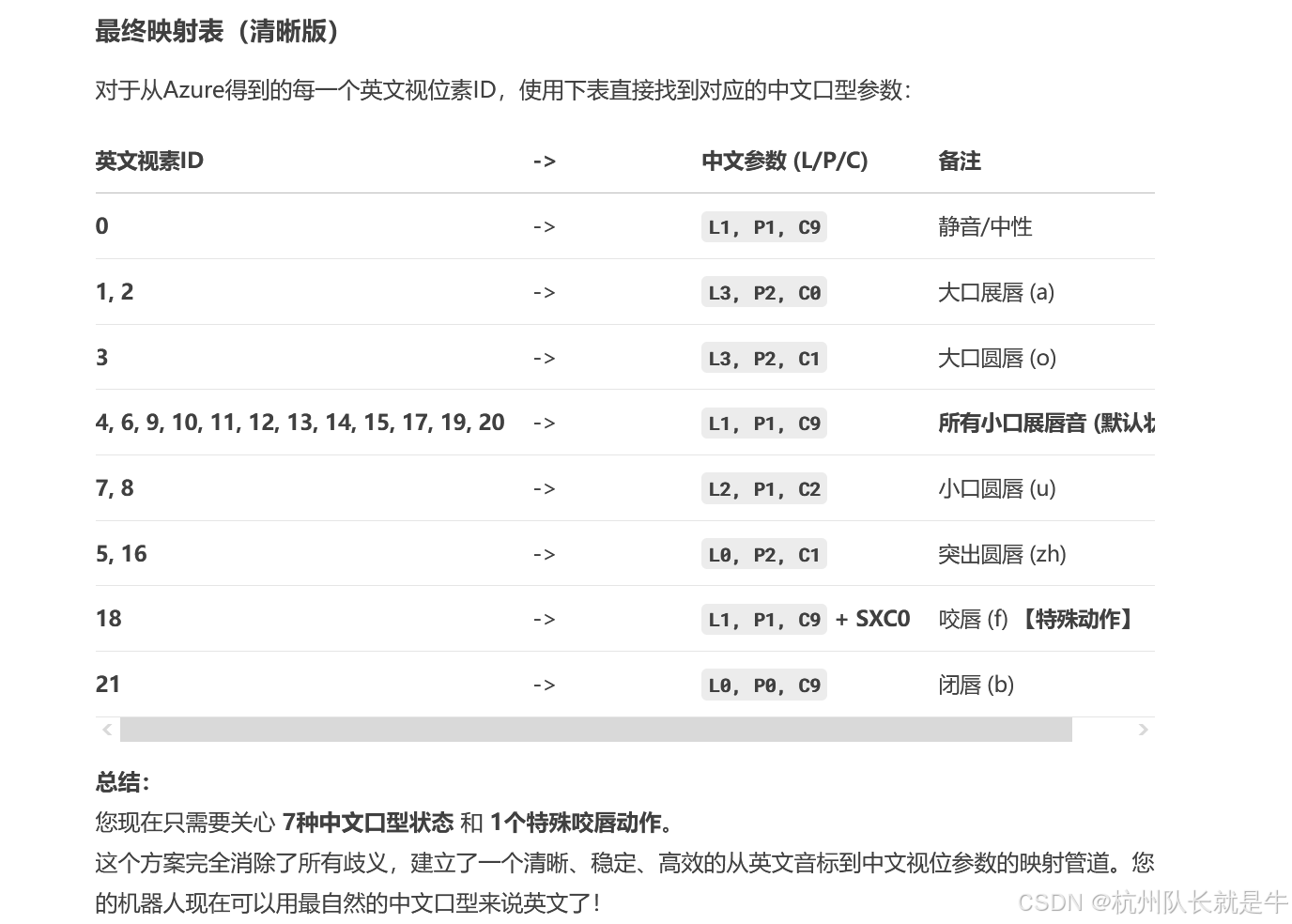
最终映射表(清晰版)
对于从Azure得到的每一个英文视位素ID,使用下表直接找到对应的中文口型参数:
| 英文视素ID | -> | 中文参数 (L/P/C) | 备注 |
|---|---|---|---|
| 0 | -> | L1, P1, C9 | 静音/中性 |
| 1, 2 | -> | L3, P2, C0 | 大口展唇 (a) |
| 3 | -> | L3, P2, C1 | 大口圆唇 (o) |
| 4, 6, 9, 10, 11, 12, 13, 14, 15, 17, 19, 20 | -> | L1, P1, C9 | 所有小口展唇音 (默认状态) |
| 7, 8 | -> | L2, P1, C2 | 小口圆唇 (u) |
| 5, 16 | -> | L0, P2, C1 | 突出圆唇 (zh) |
| 18 | -> | L1, P1, C9 + SXC0 | 咬唇 (f) 【特殊动作】 |
| 21 | -> | L0, P0, C9 | 闭唇 (b) |
总结:
您现在只需要关心 7种中文口型状态 和 1个特殊咬唇动作。
这个方案完全消除了所有歧义,建立了一个清晰、稳定、高效的从英文音标到中文视位参数的映射管道。您的机器人现在可以用最自然的中文口型来说英文了!
| 视素 ID | IPA | 嘴部位置 |
|---|---|---|
| 0 | 静音 |
|
| 1 | æ、ə、ʌ |
|
| 2 | ɑ |
|
| 3 | ɔ |
|
| 4 | ɛ、ʊ |
|
| 5 | ɝ |
|
| 6 | j、i、ɪ |
|
| 7 | w、u |
|
| 8 | o |
|
| 9 | aʊ |
|
| 10 | ɔɪ |
|
| 11 | aɪ |
|
| 12 | h |
|
| 13 | ɹ |
|
| 14 | l |
|
| 15 | s、z |
|
| 16 | ʃ、tʃ、dʒ、ʒ |
|
| 十七 | ð |
|
| 18 | f、v |
|
| 19 | d、t、n、θ |
|
| 20 | k、g、ŋ |
|
| 21 | p、b、m |
|






















下面给出一个分阶段实施规划(从“能打印正确口型序列”到“平滑驱动舵机”),以及最小可行代码骨架。你可以按阶段验证,失败点容易定位。
阶段 0:准备
- 确认:audio_offset = 毫秒;TTS 播放方式(扬声器播放 or 直接不播放只做口型)。
- 定义:servo_ids + neutral(各嘴相关舵机中值)。
- 决定抽象参数 L/P/C 与具体舵机映射规则(标出每个 L/P/C 数值对应哪几组舵机的相对偏移)。
阶段 1:数据压缩与映射
- 输入:原始 viseme 列表(可能 100+)。
- 操作:去掉连续重复 viseme;统计区间时长 = next.offset - cur.offset。
- 丢弃:区间 < 25ms(或合并到下一个)。
- 短 & 不是第一段 → 向前吸收
- 短 & 是第一段 & 后面还有 → 向后吸收(调整下一段起点)
- 短 & 只有它一个 → 时长扩展
- 不短 → 原样保留
我的逻辑是,首先有个被保护的几个id
- 输出:有效口型序列(~2×汉字数)。
- 验证:仅打印映射后的 L/P/C,不驱动舵机。
阶段 2:参数到舵机目标生成 (build_servo_targets)
- 输入:L/P/C(0/1/2/3 等级),special。
- 计算:jaw、左右上唇、左右下唇、左右嘴角(水平/垂直)偏移。
- Clamp:按 servo_safe_ranges。
- 输出:[(id,pos), ...]。
阶段 3:时序调度(独立口型播放引擎)
- 将每个压缩后的 viseme 区间转为 (targets, duration_ms)。
- duration_ms 再减去过渡时间 transition_ms(如 50ms),形成:
1) 过渡帧:从上一个口型到新口型(插值)
2) 保持帧:保持剩余时间(≥0 则生成一条保持动作)。
- 推入你的 action_queue(可以单独一个 lip_queue,消费时合并到全局串口写操作)。
阶段 4:与音频同步
- 如果音频实时播放:记录 start_time;队列调度时加一个 global_audio_latency_ms(测量得到)。
- 如果只做“假定同步”:直接按偏移依次排队即可。
- 可先忽略精确同步,验证视觉节奏。
阶段 5:平滑 & 优化
- 低通:对 jaw/lip_open 连续值做 3 点滑动平均。
- 帧率限制:强制 >= 40ms 一帧(25FPS);过短区间合并。
- 预热:播放前发送 neutral 口型,避免第一帧突变。
阶段 6:特殊动作扩展
- special == 'SXC0'(咬唇/上齿触下唇)触发附加舵机(或调低下唇)。
- 未来可加入表情叠加(微笑 + 口型),采用 additive blend:final = base_expression + viseme_delta(再 clamp)。
阶段 7:校准与参数表固化
- 交互脚本:输入 L/P/C 值 → 实时发送 → 人工微调 → 输出 JSON。
- 保存 mapping_config.json,运行时加载。
阶段 8:集成 UI
- UI 增加“播放 TTS + 口型测试”按钮:调用 TTS→viseme→构建队列。
- 日志区域显示:时间(ms) VisemeID L/P/C special clamp 信息。
--------------------------------------------------
核心代码骨架(新增 lip_sync.py)
````python
from dataclasses import dataclass
from typing import List, Dict, Tuple
# 完整映射
VISEME_TO_LPC = {
0:{'L':1,'P':1,'C':9,'special':None},
1:{'L':3,'P':2,'C':0,'special':None},
2:{'L':3,'P':2,'C':0,'special':None},
3:{'L':3,'P':2,'C':1,'special':None},
4:{'L':1,'P':1,'C':9,'special':None},
5:{'L':0,'P':2,'C':1,'special':None},
6:{'L':1,'P':1,'C':9,'special':None},
7:{'L':2,'P':1,'C':2,'special':None},
8:{'L':2,'P':1,'C':2,'special':None},
9:{'L':1,'P':1,'C':9,'special':None},
10:{'L':1,'P':1,'C':9,'special':None},
11:{'L':1,'P':1,'C':9,'special':None},
12:{'L':1,'P':1,'C':9,'special':None},
13:{'L':1,'P':1,'C':9,'special':None},
14:{'L':1,'P':1,'C':9,'special':None},
15:{'L':1,'P':1,'C':9,'special':None},
16:{'L':0,'P':2,'C':1,'special':None},
17:{'L':1,'P':1,'C':9,'special':None},
18:{'L':1,'P':1,'C':9,'special':'SXC0'},
19:{'L':1,'P':1,'C':9,'special':None},
20:{'L':1,'P':1,'C':9,'special':None},
21:{'L':0,'P':0,'C':9,'special':None},
}
DEFAULT_LPC = {'L':1,'P':1,'C':9,'special':None}
@dataclass
class VisemeEvent:
viseme_id: int
offset_ms: float
def compress_visemes(raw: List[VisemeEvent], min_hold_ms=25) -> List[VisemeEvent]:
if not raw:
return []
out = [raw[0]]
for v in raw[1:]:
if v.viseme_id != out[-1].viseme_id:
out.append(v)
# 过滤太短区间(回看长度)
filtered = []
for i,v in enumerate(out):
end = out[i+1].offset_ms if i+1 < len(out) else v.offset_ms + 80
if (end - v.offset_ms) >= min_hold_ms:
filtered.append(v)
return filtered
def lpc_to_servo_targets(lpc: Dict, servo_ids: Dict, neutral: Dict) -> List[Tuple[int,int]]:
# 需要你定义的中值与步长
# 示例权重(占位):需实测调整
L = lpc['L']; P = lpc['P']; C = lpc['C']
# 下颌开度:映射 L (0~3) → jaw delta
jaw_delta_table = {0:-20,1:0,2:40,3:80}
jaw_base_left = neutral['jaw_left']
jaw_base_right = neutral['jaw_right']
jaw_left_pos = jaw_base_left + jaw_delta_table.get(L,0)
jaw_right_pos = jaw_base_right + int(jaw_delta_table.get(L,0)*0.9) # 轻微差异
# 圆唇/突出:P 控制嘴角水平收敛;C 控制唇形分类(此处简单用作竖直张开微调)
protrude_scale = {0:0,1:60,2:120} # 水平内收
open_delta_table = {0:0,1:8,2:16,9:0} # C 仅示例
mouth_w_in = protrude_scale.get(P,0)
open_delta = open_delta_table.get(C,0)
# 计算嘴角 / 上下唇(示例简化)
targets = [
(servo_ids['jaw_left'], jaw_left_pos),
(servo_ids['jaw_right'], jaw_right_pos),
(servo_ids['upper_lip_left'], neutral['upper_lip_left'] + open_delta),
(servo_ids['upper_lip_right'], neutral['upper_lip_right'] + open_delta),
(servo_ids['lower_lip_left'], neutral['lower_lip_left'] - open_delta),
(servo_ids['lower_lip_right'], neutral['lower_lip_right'] - open_delta),
(servo_ids['left_corner_upper'], neutral['left_corner_upper'] - mouth_w_in),
(servo_ids['right_corner_upper'], neutral['right_corner_upper'] + mouth_w_in),
]
# TODO: clamp by external servo_safe_ranges
return targets
def viseme_sequence_to_actions(raw: List[Dict], servo_ids: Dict, neutral: Dict,
transition_ms=50, min_frame_ms=40) -> List[Tuple[List[Tuple[int,int]], int]]:
raw_events = [VisemeEvent(v['viseme_id'], v['audio_offset']) for v in raw]
comp = compress_visemes(raw_events)
actions = []
prev_targets = None
for i, ev in enumerate(comp):
end = comp[i+1].offset_ms if i+1 < len(comp) else ev.offset_ms + 120
span = max(min_frame_ms, end - ev.offset_ms)
lpc = VISEME_TO_LPC.get(ev.viseme_id, DEFAULT_LPC)
cur_targets = lpc_to_servo_targets(lpc, servo_ids, neutral)
if prev_targets is None:
actions.append((cur_targets, int(span)))
else:
# 过渡:transition_ms
actions.append((cur_targets, int(span))) # 简化:可拆成过渡+保持
prev_targets = cur_targets
return actions
````
在 UI / 主控制里调用示例
````python
# 假设你已有 viseme_list, servo_ids, neutral, enqueue_actions()
from lip_sync import viseme_sequence_to_actions
lip_actions = viseme_sequence_to_actions(viseme_list, servo_ids, neutral)
enqueue_actions(lip_actions, clear_existing=False) # 或独立 lip 队列
````
下一步建议执行顺序
1. 实现 lip_sync.py 并仅打印 actions 长度与第一条 targets。
2. 手动填 neutral 与真实 servo_ids;调 lpc_to_servo_targets 里的 delta。
3. 打一段 2 秒短句,看口型是否跟随(慢放 / 拍视频)。
4. 调整 jaw_delta_table / protrude_scale / open_delta_table。
5. 引入 clamp + 平滑(滑动平均)。
6. 与其他表情叠加(策略:先表情后口型或加权混合)。
告知我:需要我进一步完善哪部分(A 数值标定脚本 B 叠加算法 C 实时音频同步回调)。直接回复选项即可。以上是chatgpt5.0对我们项目做出的规划,你觉得chatgpt5.0说的对吗?它的计划怎么样?你觉得好不好,是否需要改进?