C 内存布局
文章目录
- C 内存布局
- BSS段
- 一、bss 段的核心特点
- 二、为什么需要 bss 段?
- 堆和栈
- 一、核心区别
- 二、缓存命中率差异
- 三、优化堆缓存命中率的方法
- 函数栈帧
- 一、栈帧的核心作用
- 二、栈帧的结构与关键寄存器
- 三、函数调用与栈帧的生命周期
- 1. 调用前:准备参数并压栈
- 2. 调用时:创建新栈帧
- 3. 执行中:使用栈帧
- 4. 返回时:销毁栈帧并恢复
- ASLR(Address Space Layout Randomization,地址空间布局随机化)
- 一、ASLR 解决的安全问题
- 二、ASLR 的工作原理
- 32-bit OS和64 bit OS下内存布局
- objdump
- 一、核心作用:“解剖” 二进制文件
- 1. 查看文件头部与结构信息
- 2. 查看段 / 节(Section)详情
- 3. 反汇编:将机器码转为汇编指令
- 二、支持的文件格式
- 三、常见使用场景
- 四、其他工具
C 内存布局
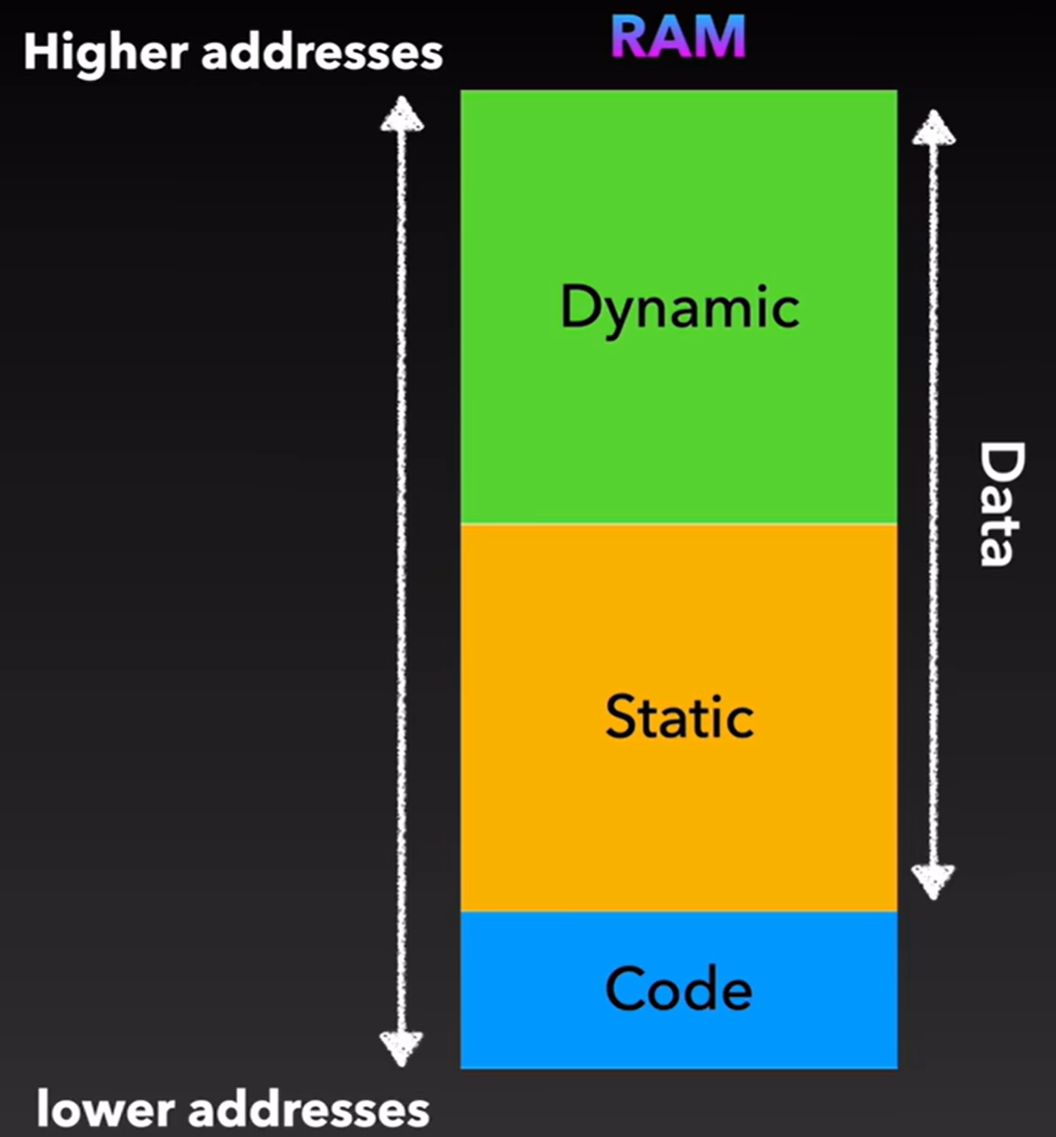
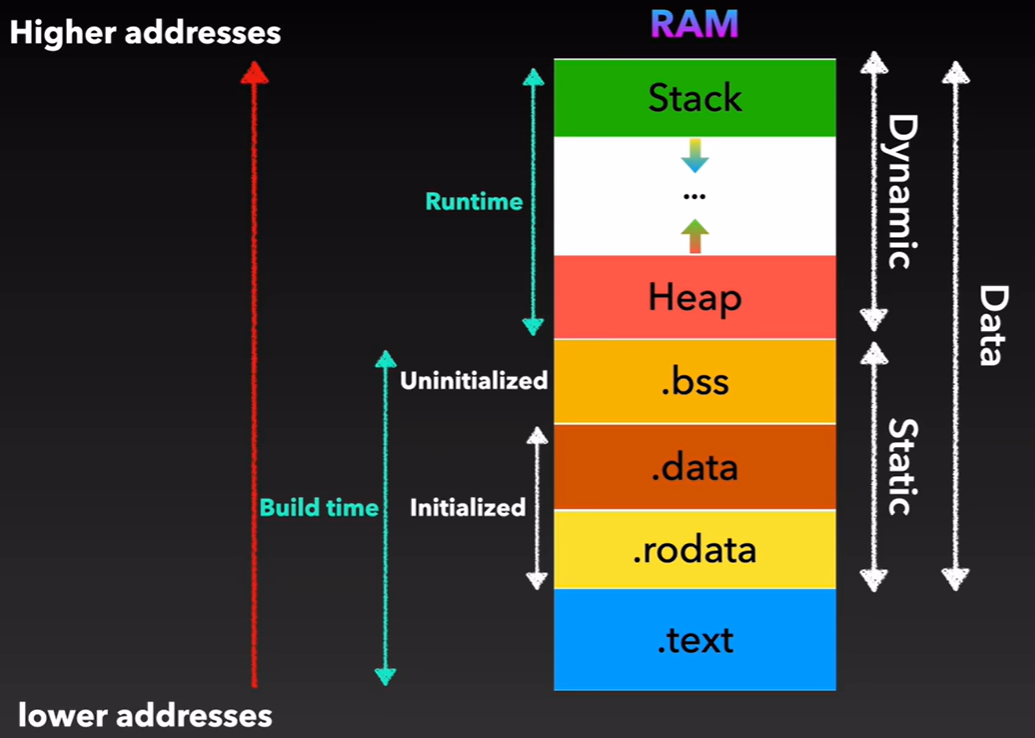
BSS段
一、bss 段的核心特点
- 存储内容
- 未初始化的全局变量:如
int global_var; - 未初始化的静态变量(包括全局静态和局部静态):如
static int static_var;或函数内的static int local_static; - 显式初始化为 0 的全局 / 静态变量:如
int zero_var = 0;(编译器通常会将其放入.bss而非.data)。
- 未初始化的全局变量:如
- 不占用磁盘空间,仅占用内存
.bss段在二进制文件中 不存储实际数据,只记录需要分配的内存大小(即变量总字节数)。- 程序加载到内存时,操作系统会根据
.bss段记录的大小,分配一块连续内存,并自动初始化为 0(或空指针)。 - 对比:
.data段存储已初始化且非 0 的变量,会占用磁盘空间(保存变量的初始值)。
- 内存属性
- 加载到内存后,
.bss段通常位于数据段(.data)之后,具有 可读写(RW) 属性(变量可以被修改)。
- 加载到内存后,
二、为什么需要 bss 段?
核心目的是 优化二进制文件大小:
- 未初始化的变量默认值为 0,无需在文件中存储(否则会浪费磁盘空间,尤其是大量数组或结构体时)。
- 例如,定义
int arr[1000000];(未初始化),.bss只需记录 “需要 4MB 内存”,而如果初始化为非 0(如int arr[1000000] = {1};),则.data段会占用 4MB 磁盘空间存储初始值。
堆和栈
一、核心区别
| 特性 | 栈(Stack) | 堆(Heap) |
|---|---|---|
| 管理方式 | 编译器自动分配 / 释放 | 程序员手动 malloc/free 等管理 |
| 大小限制 | 较小(固定,如 8MB) | 较大(动态,受系统内存限制) |
| 内存连续性 | 连续内存块(栈帧) | 不连续(碎片化) |
| 访问速度 | 快(直接通过栈指针访问) | 慢(需指针间接访问,涉及内存管理) |
| 地址增长方向 | 从高地址到低地址 | 从低地址到高地址(通常) |
| 主要用途 | 局部变量、函数参数、返回地址 | 动态分配的变量、大型 / 长期存在的数据 |
| 常见问题 | 栈溢出(递归过深、大数组) | 内存泄漏、野指针、内存碎片 |
二、缓存命中率差异
| 特性 | 栈(Stack) | 堆(Heap) |
|---|---|---|
| 1. 内存分配模式 | 连续分配、紧凑布局:栈的内存是 “栈帧”(Stack Frame)的连续叠加,新数据紧邻旧数据分配。 | 离散分配、碎片化:堆的内存由分配器(如 ptmalloc、tcmalloc)管理,动态分配的块可能分散在内存各处,易产生碎片。 |
| 2. 空间局部性 | 极强:同一函数的局部变量、参数在栈帧中连续存储,访问 A 变量后,其相邻的 B/C 变量很大概率也在同一缓存行中,一次缓存加载即可覆盖多个数据。 | 极弱:动态分配的对象(如两个new创建的数组)可能相隔甚远,访问它们时需要多次加载不同的内存页到缓存,缓存利用率低。 |
| 3. 时间局部性 | 极强:函数调用期间,其栈帧中的局部变量会被反复访问(如循环中的计数器),符合 “近期访问的数据再次访问概率高” 的规律,缓存能长期保留这些数据。 | 较弱:动态分配的数据可能在创建后仅被少数几次访问,或被 GC 回收 / 手动释放,缓存中保留的 “有效数据” 时间短,易被新数据覆盖。 |
| 4. 内存预取优化 | 编译器和 CPU 可精准预取:栈的增长方向固定(通常从高地址到低地址),CPU 的预取器能预判下一个栈帧的位置,提前将数据加载到缓存。 | 预取难度大:堆的分配地址无规律,预取器无法准确预测下一个要访问的堆内存位置,难以有效预取。 |
三、优化堆缓存命中率的方法
虽然堆的缓存天然劣势,但可通过编程技巧改善:
-
集中分配连续内存:用
malloc一次性分配大块连续内存(如数组),而非多次分配小块内存,利用空间局部性。int* arr = malloc(100 * sizeof(int)); // 连续堆内存,访问效率接近栈 -
减少随机访问:对堆数据采用顺序访问(如数组遍历),而非随机访问(如链表随机查找)。
-
利用数据结构优化:用数组替代链表(连续 vs 离散),或使用缓存友好的数据结构(如块状链表)。
-
内存池技术:预先分配大块内存,自行管理小块分配,减少内存碎片,使堆内存更集中。
函数栈帧
一、栈帧的核心作用
每次函数被调用时,操作系统会在栈上为其创建一个新的栈帧,主要负责:
- 存储函数的局部变量(如
int a = 10;) - 保存函数的参数(调用者传递给被调函数的值)
- 记录返回地址(函数执行完毕后,CPU 应回到调用者继续执行的位置)
- 维护栈帧之间的关系(通过栈基指针
ebp和栈顶指针esp定位)
二、栈帧的结构与关键寄存器
栈帧的布局由两个特殊寄存器定位(以 x86 架构为例):
ebp(基址指针):固定指向当前栈帧的底部(起始地址),用于定位栈帧内的参数和局部变量。esp(栈顶指针):指向当前栈帧的顶部,随着数据入栈 / 出栈动态移动。
一个典型的栈帧结构(从高地址到低地址)如下:
+---------------------+ <-- 上一个栈帧的ebp(由当前ebp指向)
| 上一个栈帧的ebp值 | (保存的基址指针,用于函数返回时恢复调用者栈帧)
+---------------------+ <-- 当前栈帧的ebp
| 返回地址(EIP) | (函数执行完后,CPU要跳转的地址)
+---------------------+
| 函数参数(从右到左)| (如func(a,b,c)中,c先入栈,再b,再a)
+---------------------+
| 局部变量(动态分配)| (如int x, char arr[10]等)
+---------------------+ <-- 当前栈帧的esp(栈顶)
三、函数调用与栈帧的生命周期
以func_b()调用func_a(1, 2)为例,栈帧的创建、使用、销毁过程如下:
1. 调用前:准备参数并压栈
- 调用者(
func_b)将参数从右到左压入栈:先压2,再压1(x86 架构的约定)。 - 压入返回地址(
func_b中调用func_a的下一条指令地址),确保func_a执行完后能回到正确位置。
2. 调用时:创建新栈帧
func_a被执行,首先将当前ebp的值(func_b的栈帧基址)压栈(保存调用者栈帧)。- 更新
ebp为当前esp的值(ebp指向新栈帧的底部)。 - 调整
esp向下(栈增长方向通常是高地址到低地址),为局部变量分配空间。
3. 执行中:使用栈帧
- 通过
ebp的偏移量访问参数(如ebp+8对应第一个参数1,ebp+12对应第二个参数2)。 - 局部变量存储在
ebp下方(如ebp-4对应第一个局部变量)。
4. 返回时:销毁栈帧并恢复
- 函数执行完毕,将返回值存入
eax寄存器(x86 约定)。 - 恢复
esp到ebp位置(释放局部变量空间)。 - 弹出栈中保存的
func_b的ebp值(恢复调用者的栈帧基址)。 - 弹出返回地址到
eip寄存器(CPU 跳回func_b继续执行)。
ASLR(Address Space Layout Randomization,地址空间布局随机化)
一、ASLR 解决的安全问题
在没有 ASLR 的系统中,程序的内存布局是固定的:
- 代码段(程序指令)、数据段(全局变量)、栈、堆的加载地址在每次运行时都相同。
- 攻击者可通过漏洞(如缓冲区溢出)覆盖返回地址,跳转到预设的恶意代码地址(如栈上的 shellcode)。
ASLR 通过随机化地址,打破这种可预测性,让攻击者无法提前知道关键内存区域的位置,从而阻止或延缓攻击。
二、ASLR 的工作原理
ASLR 在程序加载或系统启动时,对以下内存区域的基地址进行随机化:
- 代码段(Text Segment):程序执行指令的存储区域,包括函数、库函数(如
libc)等。 - 数据段(Data Segment):全局变量、静态变量等。
- 栈(Stack):函数栈帧、局部变量、返回地址等。
- 堆(Heap):动态分配的内存(如
malloc/new分配的空间)。 - 共享库(Shared Libraries):如
libc.so、ld.so等系统库。
随机化的实现方式是在固定基地址上添加一个随机偏移量( Offset ),每次程序运行或系统重启时,偏移量都会重新生成,导致实际地址不可预测。
32-bit OS和64 bit OS下内存布局
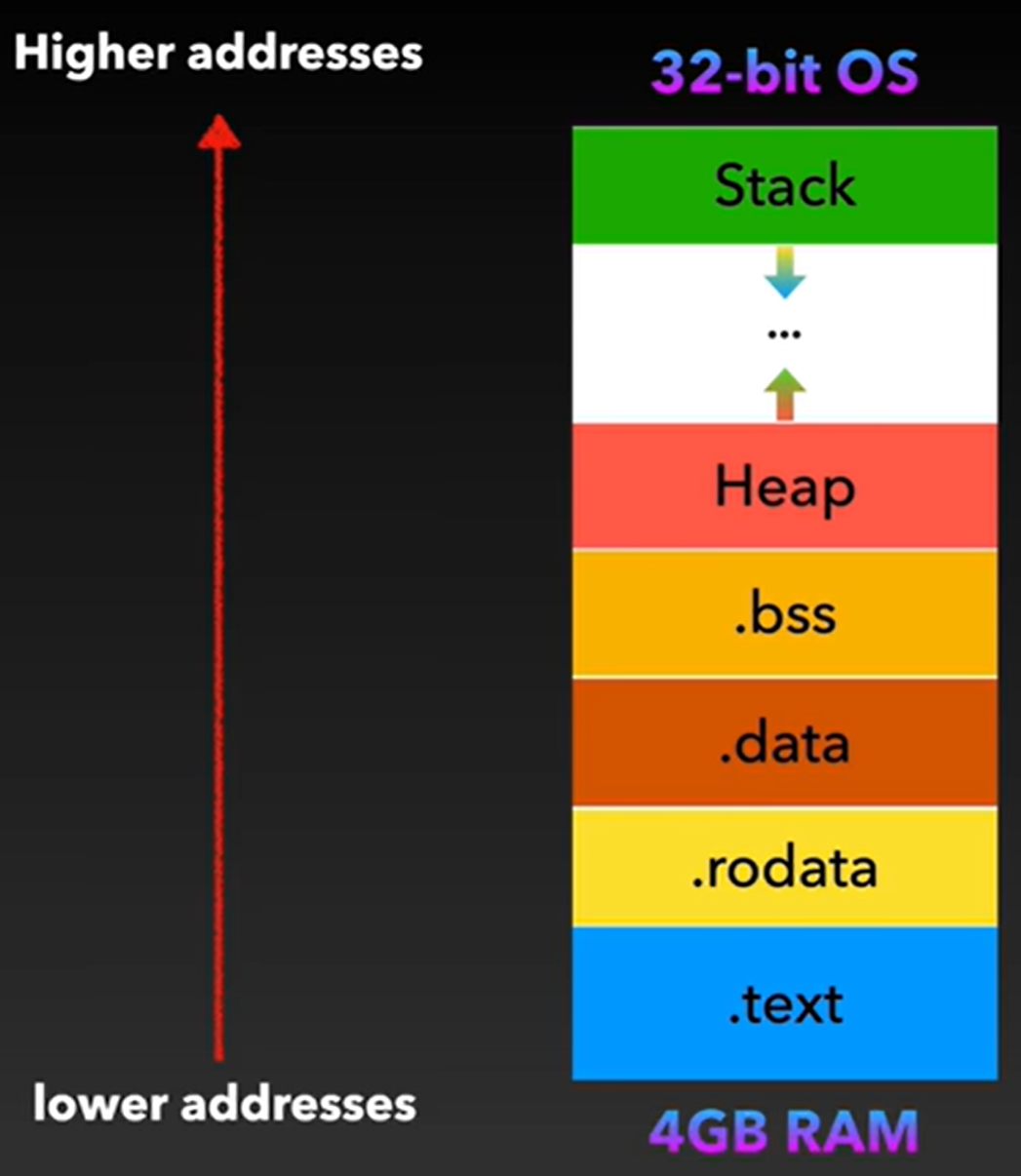
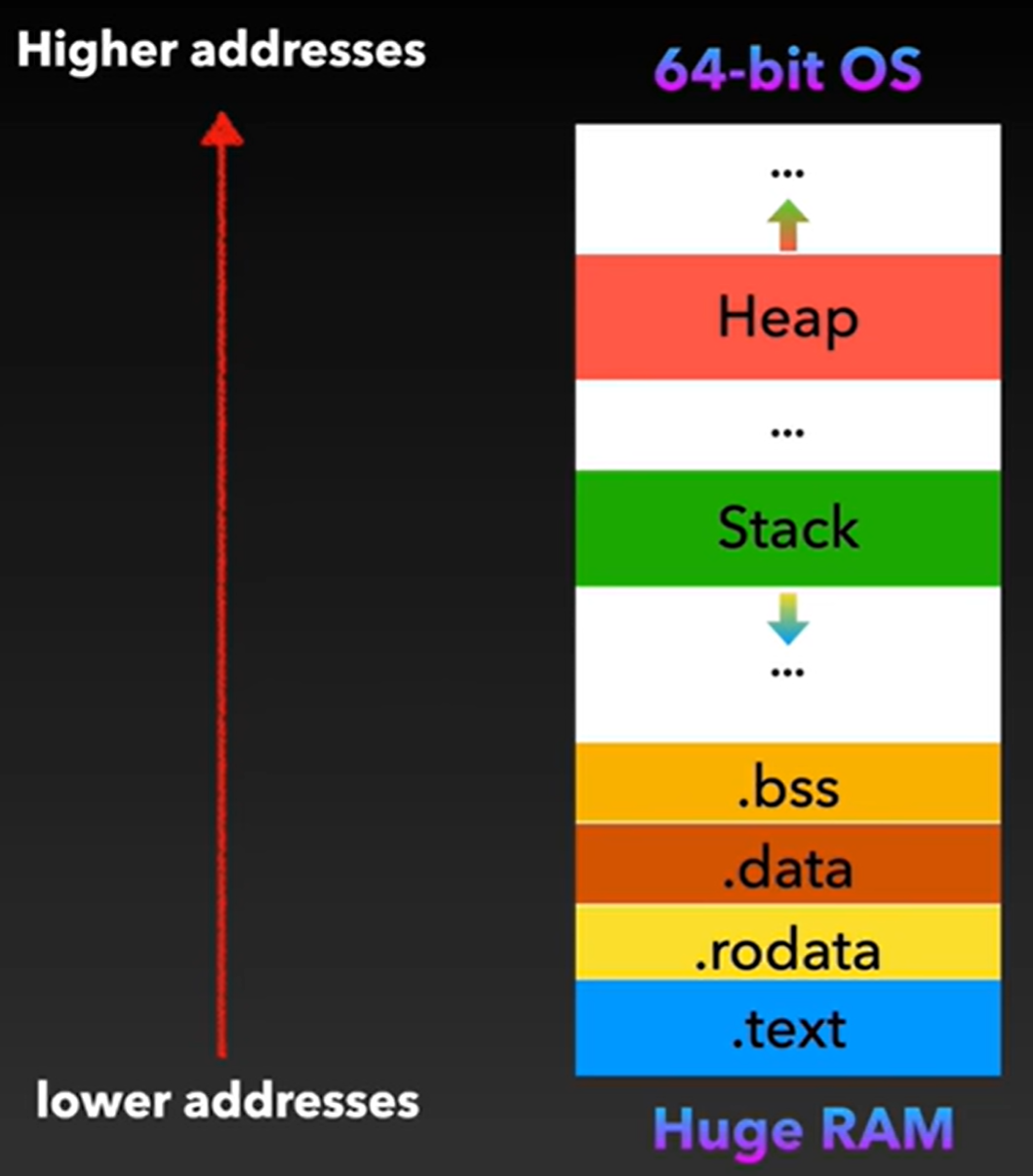
objdump
一、核心作用:“解剖” 二进制文件
二进制文件(如 .exe、.o、.so、.a)的内容对人类不直观,objdump 能将其 “翻译” 为可读信息,核心功能可分为三大类:
1. 查看文件头部与结构信息
二进制文件(尤其是 ELF 格式,Linux 下主流)都有固定的头部结构(记录文件类型、架构、入口地址等)和段 / 节表(记录代码段、数据段、符号表等位置)。objdump 可直接解析并展示这些元数据。
常用选项:
-f(--file-headers):查看文件头部信息(最常用),包括:- 文件类型(如
executable可执行文件、relocatable目标文件、shared object共享库); - 架构(如
i386:x86-64、ARM aarch64); - 入口地址(程序开始执行的内存地址);
- 目标操作系统(如
GNU/Linux)。
- 文件类型(如
示例:查看 a.out(默认编译输出的可执行文件)的头部:
objdump -f a.out
输出片段:
a.out: file format elf64-x86-64
architecture: i386:x86-64, flags 0x00000150:
HAS_SYMS, DYNAMIC, D_PAGED
start address 0x0000000000400430 # 程序入口地址
2. 查看段 / 节(Section)详情
二进制文件内部按 “段(Segment)” 或 “节(Section)” 划分功能(如代码放在 .text 节、全局变量放在 .data 节、未初始化变量放在 .bss 节)。objdump 可列出所有节的信息,包括地址、大小、属性(如 “可执行”“可写”)。
常用选项:
-h(--headers):列出所有节的头部信息;-x(--all-headers):比-h更详细,包含符号表、动态段等额外信息。
示例:查看 a.out 的节信息:
objdump -h a.out
输出片段(关键节说明):
| 节名(Name) | 大小(Size) | VMA 地址 | 属性(Flg) | 功能说明 |
|---|---|---|---|---|
.text | 0x00000123 | 0x400430 | AX | 代码段(可执行、可读取) |
.data | 0x00000045 | 0x601000 | WA | 数据段(已初始化全局变量,可写、可读取) |
.bss | 0x00000080 | 0x601045 | WA | 未初始化数据段(运行时分配内存,可写) |
.rodata | 0x00000020 | 0x400553 | A | 只读数据段(如字符串常量) |
3. 反汇编:将机器码转为汇编指令
这是 objdump 最核心、最常用的功能 —— 将二进制文件中的 机器码(01 序列)反向翻译为汇编语言指令,帮助开发者理解程序的底层执行逻辑(如调试崩溃、分析第三方库、逆向工程)。
常用选项:
-d(--disassemble):反汇编 可执行节(如.text) 的内容(只反汇编有代码的部分);-D(--disassemble-all):反汇编 所有节(包括数据段,可能包含无效指令,慎用);-S(--source):结合源代码反汇编(需编译时加-g生成调试信息-ggdb),将汇编指令与对应的 C/C++ 代码逐行对应,调试时极其有用;-M(--disassembler-options):指定汇编语法(如-M intel用 Intel 语法,默认是 AT&T 语法,后者对新手不友好)。
示例 1:反汇编 a.out 的代码段(Intel 语法):
objdump -d -M intel a.out
输出片段(main 函数的汇编):
0000000000400526 <main>:400526: 55 push rbp ; 函数栈帧初始化400527: 48 89 e5 mov rbp,rsp40052a: 48 83 ec 10 sub rsp,0x10 ; 分配16字节栈空间40052e: c7 45 fc 0a 00 00 00 mov DWORD PTR [rbp-0x4],0xa ; 局部变量 = 10400535: b8 00 00 00 00 mov eax,0x0 ; 返回值设为040053a: c9 leave40053b: c3 ret ; 函数返回
示例 2:结合源代码反汇编(需先编译时加 -g):
# 1. 带调试信息编译:gcc -g test.c -o test
# 2. 结合源码反汇编:
objdump -S -M intel test
输出片段(代码与汇编对应):
0000000000400526 <main>:
#include <stdio.h>
int main() {400526: 55 push rbp400527: 48 89 e5 mov rbp,rsp40052a: 48 83 ec 10 sub rsp,0x10int a = 10;40052e: c7 45 fc 0a 00 00 00 mov DWORD PTR [rbp-0x4],0xaprintf("a = %d\n", a);400535: 8b 45 fc mov eax,DWORD PTR [rbp-0x4]400538: 89 c6 mov esi,eax40053a: 48 8d 3d d1 00 00 00 lea rdi,[rip+0xd1] # 400612 <_IO_stdin_used+0x12>400541: b8 00 00 00 00 mov eax,0x0400546: e8 c5 fe ff ff call 400410 <printf@plt>return 0;40054b: b8 00 00 00 00 mov eax,0x0
}400550: c9 leave400551: c3 ret
二、支持的文件格式
objdump 并非只支持 Linux 下的 ELF 格式,而是跨平台、多格式兼容,常见支持的格式包括:
- ELF:Linux/Unix 下的主流格式(可执行文件、目标文件
.o、共享库.so、静态库.a); - PE/COFF:Windows 下的格式(
.exe、.dll,需在 Linux 下用objdump分析,或 Windows 下用 MinGW 版本); - Mach-O:macOS/iOS 下的格式(
.mach-o、.dylib); - a.out:早期 Unix 下的古老格式(现在很少用)。
三、常见使用场景
- 开发调试:定位程序崩溃原因(如反汇编查看崩溃地址对应的指令,结合
-S看源码上下文); - 底层学习:理解编译原理(如查看
gcc如何将 C 代码编译为汇编,分析优化效果); - 逆向工程:分析第三方闭源程序 / 库的逻辑(如查看函数调用关系、数据处理流程);
- 安全分析:检查二进制文件是否包含恶意代码(反汇编查看可疑指令,如系统调用、内存操作);
- 验证编译结果:确认编译选项是否生效(如查看是否包含调试信息、代码段是否为只读)。
四、其他工具
| 工具 | 核心优势 | 典型场景 |
|---|---|---|
objdump | 功能全面,支持反汇编、查看结构 | 反汇编分析代码逻辑、快速了解文件结构 |
readelf | 专注 ELF 格式,信息更详细 | 深入分析 ELF 节 / 段结构、动态链接信息 |
nm | 快速查看符号表(函数 / 变量) | 确认符号是否定义、查找未定义依赖 |
strings | 提取字符串,快速定位关键信息 | 分析程序功能、查找路径 / 提示信息 |
ldd | 查看共享库依赖 | 解决 “缺失库” 错误、确认库版本 |
addr2line | 地址转源码位置 | 调试段错误、定位崩溃行号 |
gdb | 交互式调试 + 静态分析 | 动态调试程序、结合源码单步分析汇编 |
量) | 确认符号是否定义、查找未定义依赖 |
| strings | 提取字符串,快速定位关键信息 | 分析程序功能、查找路径 / 提示信息 |
| ldd | 查看共享库依赖 | 解决 “缺失库” 错误、确认库版本 |
| addr2line | 地址转源码位置 | 调试段错误、定位崩溃行号 |
| gdb | 交互式调试 + 静态分析 | 动态调试程序、结合源码单步分析汇编 |
参考:https://www.bilibili.com/video/BV1Sepyz7ECL/?spm_id_from=333.1007.tianma.1-2-2.click&vd_source=421e907dca148d8cdae057950df04587