八股(9.26)
1.说说你了解的JVM内存模型
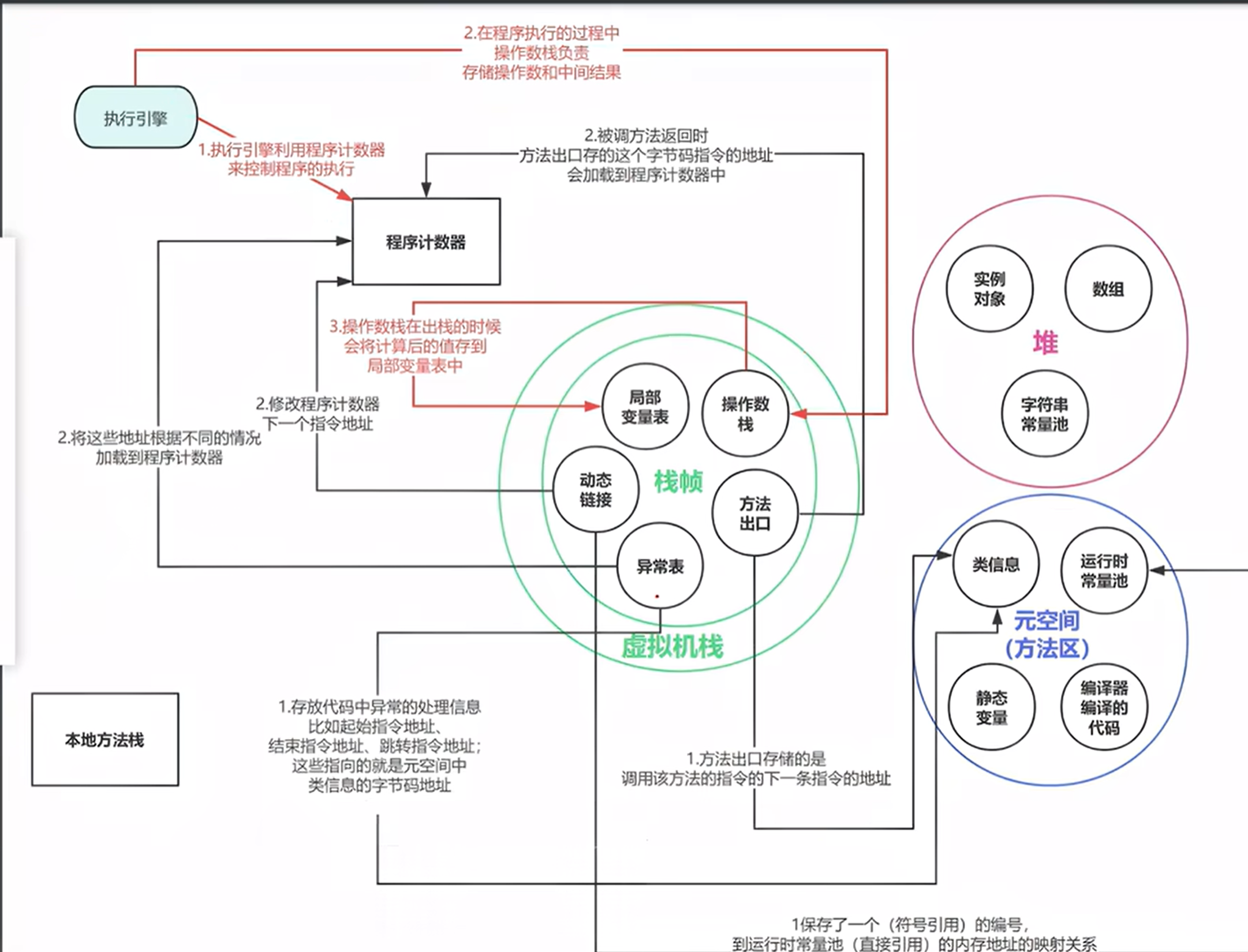
三部分:类加载子系统,执行引擎,运行时数据区
A.类加载子系统:根据全限定名称来载入类或接口
B.执行引擎:负责执行那些被包含在被载入类的方法中的指令
C.运行时数据区:用来存储字节码,对象,参数,返回值,局部变量及运行结果等
运行时数据区包括:
a.程序计数器:存储当前线程执行的字节码指令地址(行号),是线程私有区域
b.虚拟机栈:存储线程执行方法时的局部变量表,操作数栈,动态链接和方法出口等信息,线程私有。
c.本地方法栈:与虚拟机栈类似,但为Native方法(非Java实现的方法)提供服务,线程私有。
d.堆:存储对象实例和数组,是JVM中最大的区域,所有线程共享。
e.方法区:存储类信息(结构,字段,方法),常量,静态变量,即时编译后的代码等,线程共享。
f.运行时常量池:方法区的一部分,存储编译期生成的各种字面量和符号引用。
https://www.bilibili.com/video/BV1U7PMeMEME/?spm_id_from=333.337.search-card.all.click&vd_source=3abe3667e67749032f72d6f512b2a967
2.如何排查和优化慢SQL?
A.慢SQL的排查
a.开启慢查询日志,定位慢SQL
开启方式:在MySQL中通过配置slow_query_log=1启用慢查询日志,设置long_query_time=N(如2秒)定义慢SQL阈值。
b.分析执行计划,定位瓶颈
对慢SQL执行EXPLAIN ANALYZE,重点关注以下字段:
type:访问类型,从优到差为system>const>eq_ref>ref>range>index>ALL,出现ALL(全表扫描)需优化
key:实际使用的索引,若为NULL表示未走索引
rows:预估扫描行数,数值越大效率越低
Extra:额外信息
B.慢SQL的优化
a.优化索引
新增合适的索引:针对WHERE,JOIN,ORDER BY,GROUPP BY后的字段建立索引(如联合索引须遵循“最左前缀原则”
删除冗余/低效索引:重复索引(如同一字段建立多个索引),从未使用的索引会增加写入开销
避免索引失效:不在索引行列上做计算;避免WHERE子句中使用!=,NOT IN,IS NULL(可能导致全局扫描);字符串不加引号会导致类型转换,使索引失效
b.优化SQL语句
避免全局扫描:明确查询条件,不写SELECT*(减少数据传输,便于利用覆盖索引)
优化子查询:将子查询改为JOIN(子查询可能导致多次扫描,JOIN效率更高)
控制返回行数:使用LIMIT限制结果集,避免一次性放回大量数据
优化排序/分组:排序字段尽量使用索引;达标分组时可先过滤数据
避免JOIN过多表:多表JOIN会增加关联成本,建议拆分查询或控制JOIN表数量
c.表结构优化
分库分表:水平分表:将大表按规则拆分(如按时间或用户ID哈希),降低单表数据量(建议单表行数控制在千万级以内);垂直分表:将大字段(如text,blob)拆分到子表,减少主表扫描开销
选择合适的数据类型:避免使用过大类型(如用INT代替BIGINT,VARCHAR(20)代替VARCHAR(255));用TIMESTAMP代替DATETIME(节省空间,带时区)
添加适量的冗余字段:减少JOIN操作(以空间换时间)
d.数据库配置优化
调整缓存参数:如innodb_buffer_pool_size(建议为服务器的50%-70%,提高缓存命中率)
优化排序存储:sort_buffer_size,join_buffer_size(避免过小导致磁盘临时文件)
开启查询缓存(MySQL8.0之前可用query_cache_type):适用于读多写少,结果稳定的场景
e.升级服务器硬件配置
f.使用分布式数据库
https://www.bilibili.com/video/BV1rVpSeoE2k/?spm_id_from=333.337.search-card.all.click&vd_source=3abe3667e67749032f72d6f512b2a967
3.为什么 MySQL 采用 B+ 树作为索引?
A.B+树的结构更适合磁盘存储
a.多路平衡查找树:它的每个节点可以存储多个关键字(索引值)和指针,大幅降低了树的高度。
b.减少磁盘I/O:数据库索引存储在磁盘上,树的高度直接决定了查询时的磁盘I/O次数。B+树的矮胖结构可以显著减少I/O操作,而磁盘的I/O是数据库性能的核心瓶颈。
B.所有数据集中在叶子节点,查询效率稳定
叶子节点有序且相连:B+树的非叶子节点仅作为索引目录(不存储实际数据),所有实际数据(或主键指针)都存储在叶子节点中,且叶子节点之间通过双向链表连接。
查询效率稳定:无论查询到哪个关键字,都必须遍历到叶子节点,因此所有的查询时间复杂度为O(logn),避免B树中“部分查询可能在非叶子节点就结束”导致的效率不稳定问题。
范围查询高效:由于叶子节点有序且链表相连,范围查询只需找到起始叶子节点,然后沿链表顺序扫描即可,无需回溯上层节点,效率远高于B树和哈希索引。
C.适合数据库的高频操作场景
a.支持模糊查询和排序:B+树的叶子节点按关键字有序排列,天然支持ORDER BY,GROUP BY等排序操作,以及LIKE'prefix%'这类前缀模糊查询(可利用索引的有序性定位排序)
b.索引复用性高:非叶子节点的关键字可被多个查询共享,提升索引利用率。
c.擦汗如删除效率高:B+树通过分裂和合并节点维持平衡性,相比二叉树(如红黑树),多路结构减少了节点调整次数,尤其在大数据量下更稳定。
D.与其他索引结构的对比
相比B树:B树的非叶子节点存储数据,导致相同节点能容纳的关键字更少,树更高,I/O更多;且范围查询需要回溯,效率低。
相比哈希索引:哈希索引仅支持等值查询(=),不支持范围查询,排序和模糊查询,无法满足数据库的复杂查询需求。
相比二叉搜索树:普通二叉树可能退化为链表(查询效率O(n)),即使是平衡二叉树(如AVL树,红黑树),其高度仍远高于B+树,磁盘I/O次数过多。
https://www.bilibili.com/video/BV1yM411s7WV/?spm_id_from=333.337.search-card.all.click&vd_source=3abe3667e67749032f72d6f512b2a967
https://www.bilibili.com/video/BV19K421b7PX/?spm_id_from=333.337.search-card.all.click&vd_source=3abe3667e67749032f72d6f512b2a967