达梦数据库中jdbc接口的大批量插入数据的写法推荐
1. 介绍
- 在应用开发中,当数据不大时使用 for循环一条一条的插入,这个方式比较简单直观灵活,但是这个对于大的数据集,使用for循环逐条插入数据可能会导致性能问题。
- 在网络延迟高或数据库负载大的情况下。使用for循环进行数据插入时,需要注意事务管理,确保数据的一致性和完整性。如果不适当地管理事务,可能会导致数据不一致或丢失。
- 每次循环迭代都需要建立和关闭数据库连接,这可能会导致额外的数据库连接开销,影响性能。
针对有大数据量批量插入语句的场景,此时有两种方案 1. 多条insert同时提交 ,2. insert…vaues (),()的语句形式批量提交。
在DM中推荐使用PreparedStatement预编译多条insert语句 然后executeBatch的操作也就是第一种方法
2. 使用PreparedStatement预编译
使用预处理的方式进行批量插入是一种常见的优化方法,它可以显著提高插入操作的性能。
优点:
- 性能提升: 预处理可以减少每次插入操作中的数据库通信次数,从而降低了网络通信的开销,提高了插入操作的效率和性能。
- 减少数据库负载: 将多条数据组合成批量插入的方式可以减少数据库服务器的负载,降低了数据库系统的压力,有助于提高整个系统的性能。
- 减少连接开销: 预处理可以减少每次循环迭代中建立和关闭数据库连接的开销,从而节省了系统资源,提高了连接的复用率。
- 事务管理:可以将多个插入操作放在一个事务中,以确保数据的一致性和完整性,并在发生错误时进行回滚,从而保证数据的安全性。
缺点:
- 内存消耗: 将多条数据组合成批量插入的方式可能会增加内存消耗,特别是在处理大量数据时。因此,需要注意内存的使用情况,以避免内存溢出或性能下降。
所以由此可见预编译方式性能较好,如果想避免内存问题的话,其实使用分批插入也可以解决这个问题。
3. spring中标准的单条提交写法(不推荐)
@Override
public void batchInsertGOOD(BRAND bRAND, SHELL sHELL) throws IOException {
String[] good_string = null;
Integer CATEGORY_ID = 1;
for (int i = 0; i < 100000; i++) {
GOOD good = new GOOD();
good.setBRAND_ID(bRAND.getID());
good.setBRAND_UUID(bRAND.getBRAND_ID());
good.setSELLER_ID(sHELL.getID());
good.setSELLER_UUID(sHELL.getSHELL_ID());
good.setGOOD_ID(CustomUtil.getUUID());
good.setNAME(i+good_string[2]);
good.setPRICE(new BigDecimal(good_string[1]));
good.setGOOD_DESC("这时商品介绍---"+i+"----"+good_string[2]);
good.setIS_DELETE(0);
gOODMapper.insert(good);
}
}
使用com.baomidou.mybatisplus.core.mapper.BaseMapper
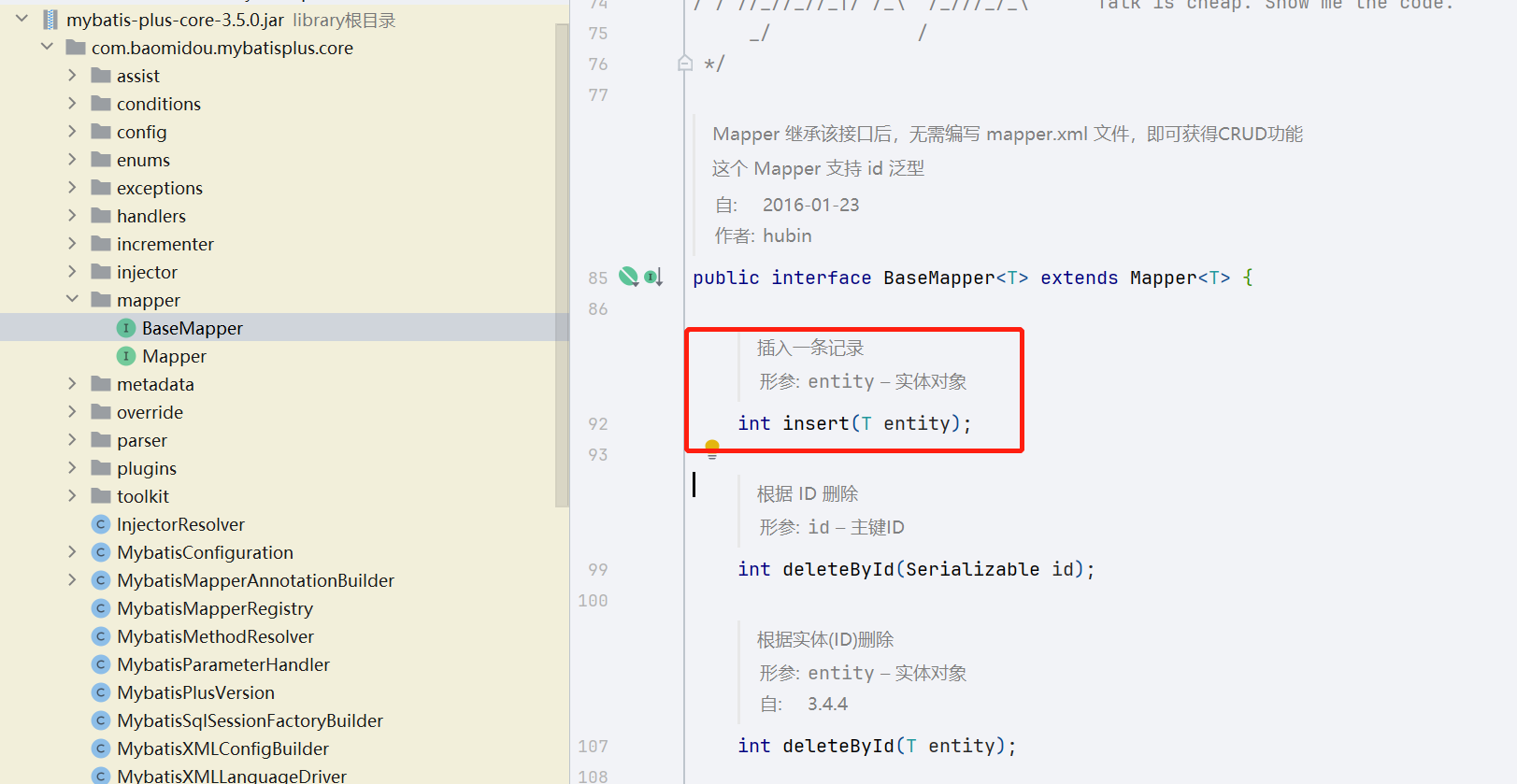
4. insert…vaues (),()的语句形式批量提交 (不推荐)
insert…vaues (),() 的语句形式批量提交。使用mysql数据库的话通常使用的这种写法。
这种写法会导致sql语句会非常大,不仅容易超出的sql长度限制,也会容易造成oom。
@Override
public void batchInsertGOOD_CUSTOM_T(BRAND bRAND, SHELL sHELL) throws IOException {
List<GOOD> goodLists = new ArrayList<>();
String[] good_string = null;
Integer CATEGORY_ID = 1;
for (int i = 0; i < 100000; i++) {
GOOD good = new GOOD();
good.setBRAND_ID(bRAND.getID());
good.setBRAND_UUID(bRAND.getBRAND_ID());
good.setSELLER_ID(sHELL.getID());
good.setSELLER_UUID(sHELL.getSHELL_ID());
good_string = CustomUtil.readTargetFileNum(RandomUtil.randomInt(1, 15),StrUtil.trim(bRAND.getBRAND_JC()));
//产品类型
good.setCATEGORY_ID(RandomUtil.randomInt(1, 10));
good.setGOOD_ID(CustomUtil.getUUID());
good.setNAME(i+good_string[2]);
good.setPRICE(new BigDecimal(good_string[1]));
good.setGOOD_DESC("这时商品介绍---"+i+"----"+good_string[2]);
good.setIS_DELETE(RandomUtil.randomInt(0, 1));
goodLists.add(good);
//每5000次 提交一次数据
if(i%5000==0&&i!=0){
gOODMapper.batchInsertList(goodLists);
goodLists.clear();
}
}
if(goodLists.size()!=0){
gOODMapper.batchInsertList(goodLists);
}
}
在Myabtis中xml文件的写法,使用foreach标签循环变量结果集
<insert id="batchInsertList" parameterType="java.util.List">
insert into "DM_GOODS"( "GOOD_ID", "NAME", "PRICE", "GOOD_DESC", "BRAND_ID", "BRAND_UUID", "CATEGORY_ID", "SELLER_ID", "SELLER_UUID", "IS_DELETE")
VALUES
<foreach collection="goodsList" item="good" separator=",">
(
#{good.GOOD_ID},#{good.NAME},#{good.PRICE},#{good.GOOD_DESC},
#{good.BRAND_ID},#{good.BRAND_UUID},#{good.CATEGORY_ID},
#{good.SELLER_ID},#{good.SELLER_UUID},#{good.IS_DELETE}
)
</foreach>
</insert>
在DM中如果拼接的?参数过多时,会报变量空间溢出这个问题,此时查看日志会发现有多条数据就要拼接多少次。

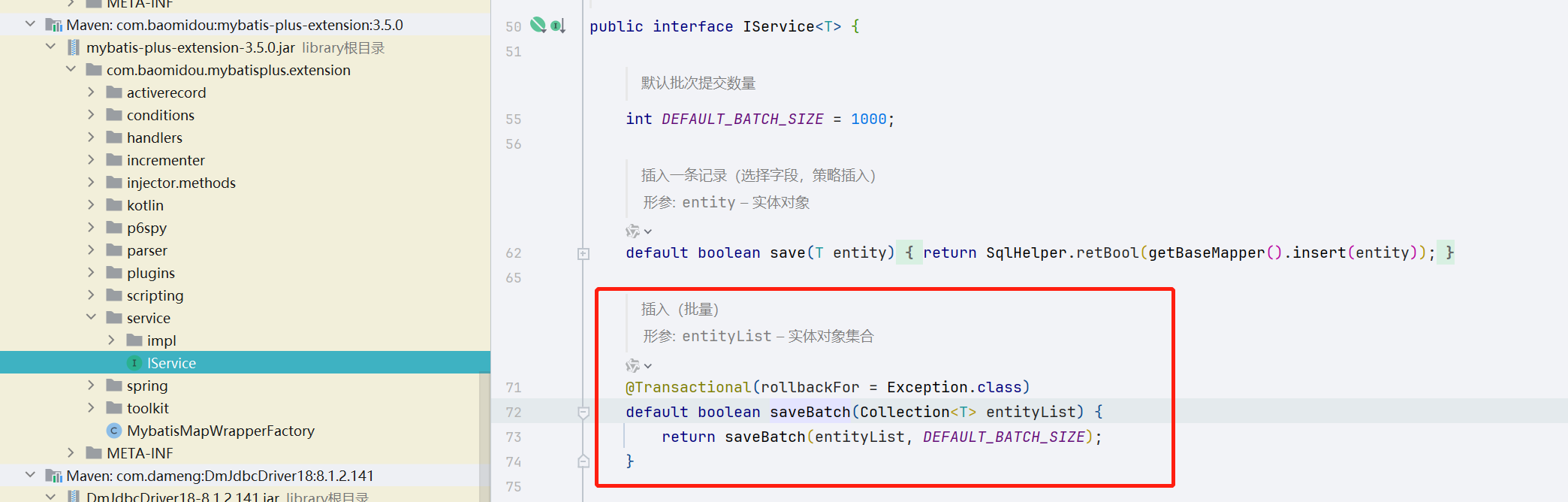
5. mybatis自带的savebatch方法(推荐)
@Service
public class GOODServiceImpl extends ServiceImpl<GOODMapper, GOOD> implements GOODService {
@Autowired
private GOODService gOODService;
@Override
public void batchInsertGood_Mys_SaveBatch(BRAND bRAND, SHELL sHELL) throws IOException {
List<GOOD> goodLists = new ArrayList<>();
String[] good_string = null;
Integer CATEGORY_ID = 1;
for (int i = 0; i < 100000; i++) {
GOOD good = new GOOD();
good.setBRAND_ID(bRAND.getID());
good.setBRAND_UUID(bRAND.getBRAND_ID());
good.setSELLER_ID(sHELL.getID());
good.setSELLER_UUID(sHELL.getSHELL_ID());
good_string = CustomUtil.readTargetFileNum(RandomUtil.randomInt(1, 15),StrUtil.trim(bRAND.getBRAND_JC()));
//产品类型
good.setCATEGORY_ID(RandomUtil.randomInt(1, 10));
good.setGOOD_ID(CustomUtil.getUUID());
good.setNAME(i+good_string[2]);
good.setPRICE(new BigDecimal(good_string[1]));
good.setGOOD_DESC("这时商品介绍---"+i+"----"+good_string[2]);
good.setIS_DELETE(RandomUtil.randomInt(0, 1));
goodLists.add(good);
//每5000次 提交一次数据
if(i%1000==0&&i!=0){
//ServiceImpl的saveBatch方法,默认batchsize是1000
gOODService.saveBatch(goodLists);
goodLists.clear();
}
}
if(goodLists.size()!=0){
gOODService.saveBatch(goodLists);
}
}
}
通过查看sqllog日志,发现saveBatch接口使用PreparedStatement预编译多条insert语句 然后executeBatch提交。
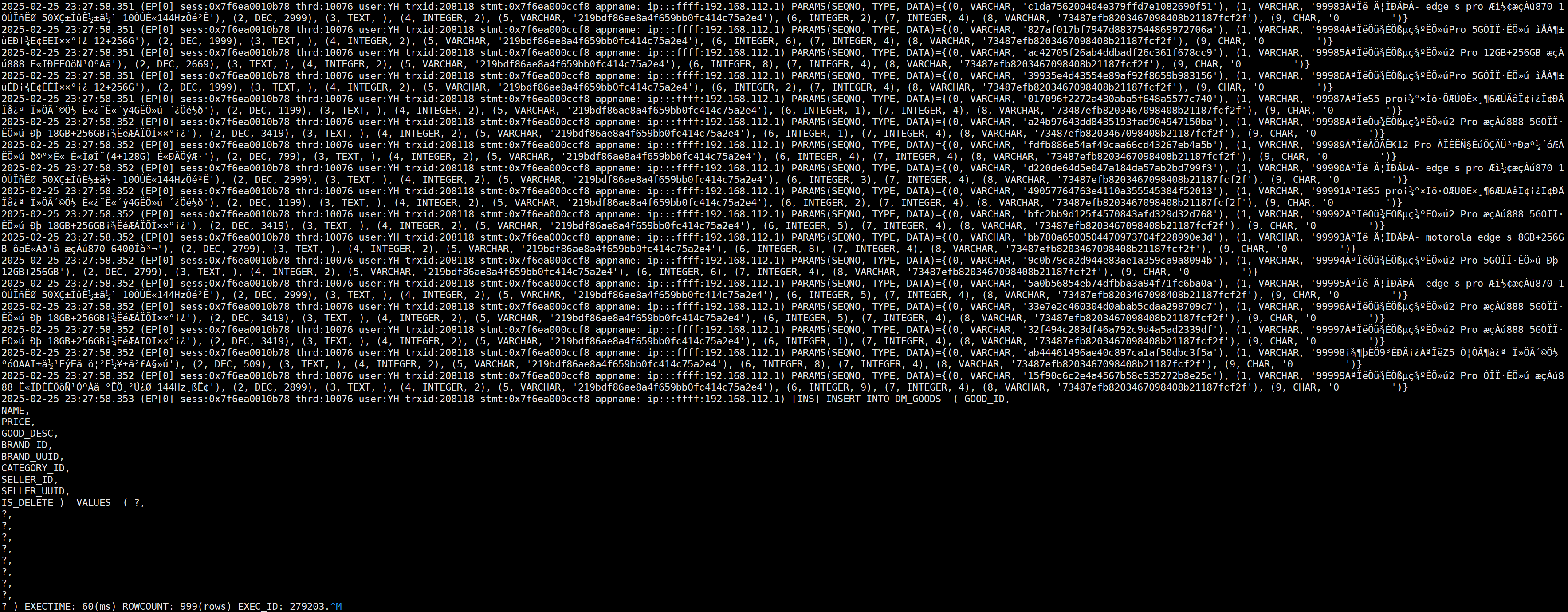
、
6. savebatch源码分析
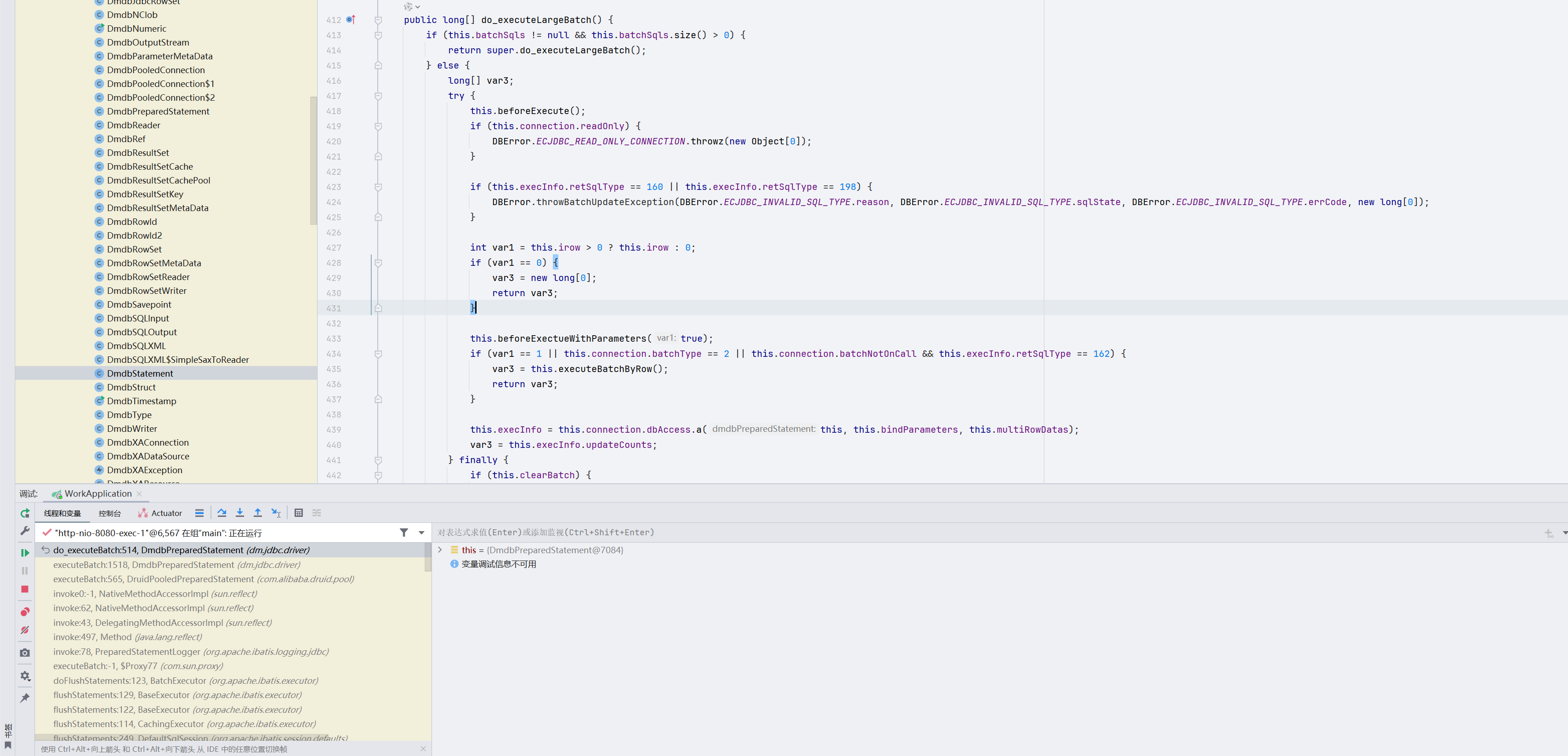
eg:在DM中没有rewriteBatchedStatements 参数,因为跟mysql的驱动内部的executeBatch()函数实现不同。
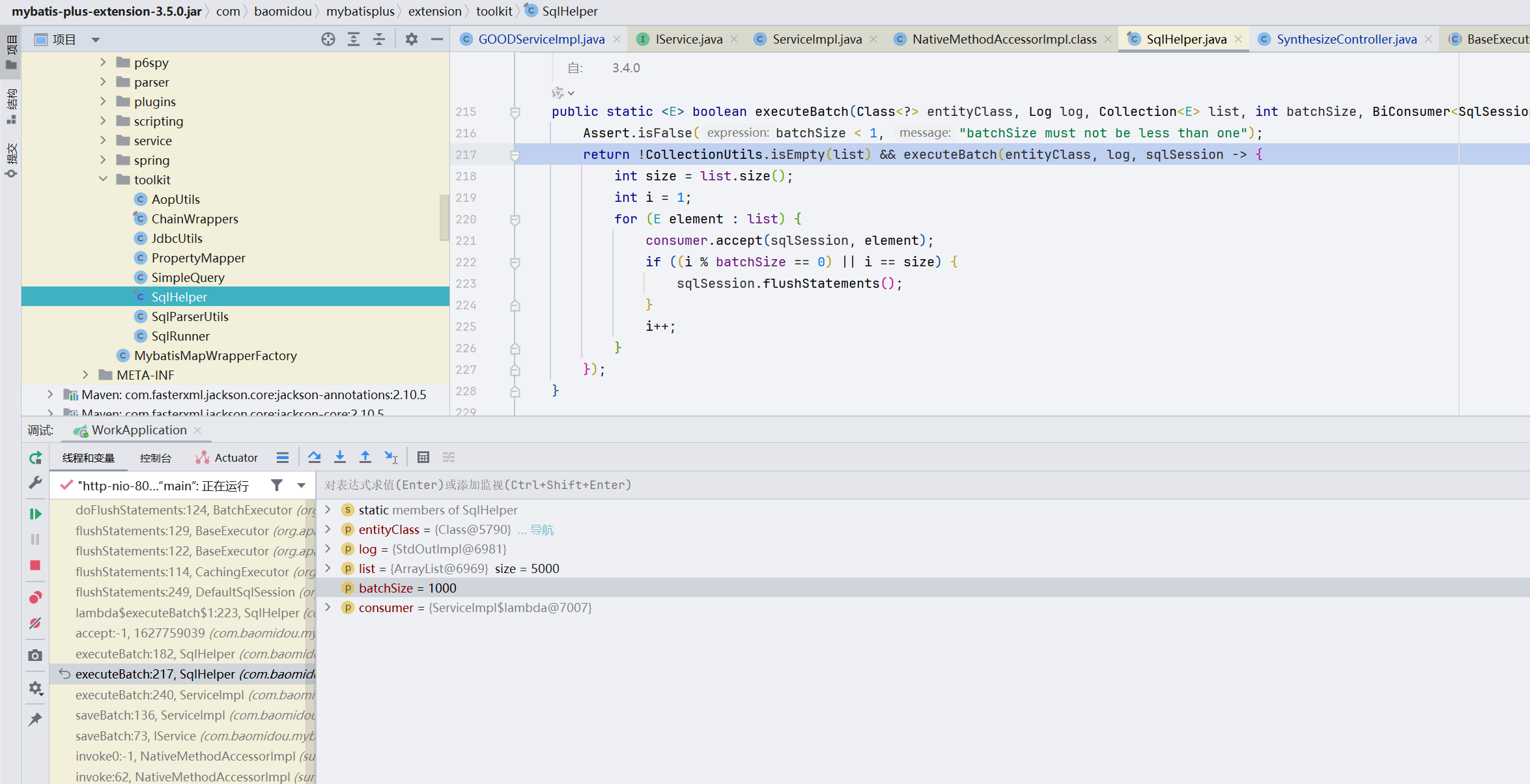
6.1 com.baomidou.mybatisplus.extension.toolkit.SqlHelper#executeBatch
executeBatch函数用于执行批量操作。主要功能如下:
- 检查批次大小是否合法。
- 如果数据集合不为空,则调用另一个 executeBatch 方法,逐个处理集合中的元素,并在达到批次大小或处理完所有元素时刷新语句。
- sqlSession.flushStatements将一个个单条插入的insert语句分批次进行提交,用的是同一个sqlSession。
public static <E> boolean executeBatch(Class<?> entityClass, Log log, Collection<E> list, int batchSize, BiConsumer<SqlSession, E> consumer) {
Assert.isFalse(batchSize < 1, "batchSize must not be less than one");
return !CollectionUtils.isEmpty(list) && executeBatch(entityClass, log, sqlSession -> {
int size = list.size();
int i = 1;
for (E element : list) {
consumer.accept(sqlSession, element);
if ((i % batchSize == 0) || i == size) {
sqlSession.flushStatements();
}
i++;
}
});
}
6.2 org.apache.ibatis.executor.BatchExecutor#doFlushStatements
doFlushStatements函数处理批量执行 SQL 语句并返回结果。主要功能如下:
- 如果是回滚操作,直接返回空列表。
- 遍历 statementList,对每个 Statement 执行批量更新,并处理生成的主键。
- 捕获批量更新异常,构建错误信息并抛出异常。
- 最后清理资源和状态。
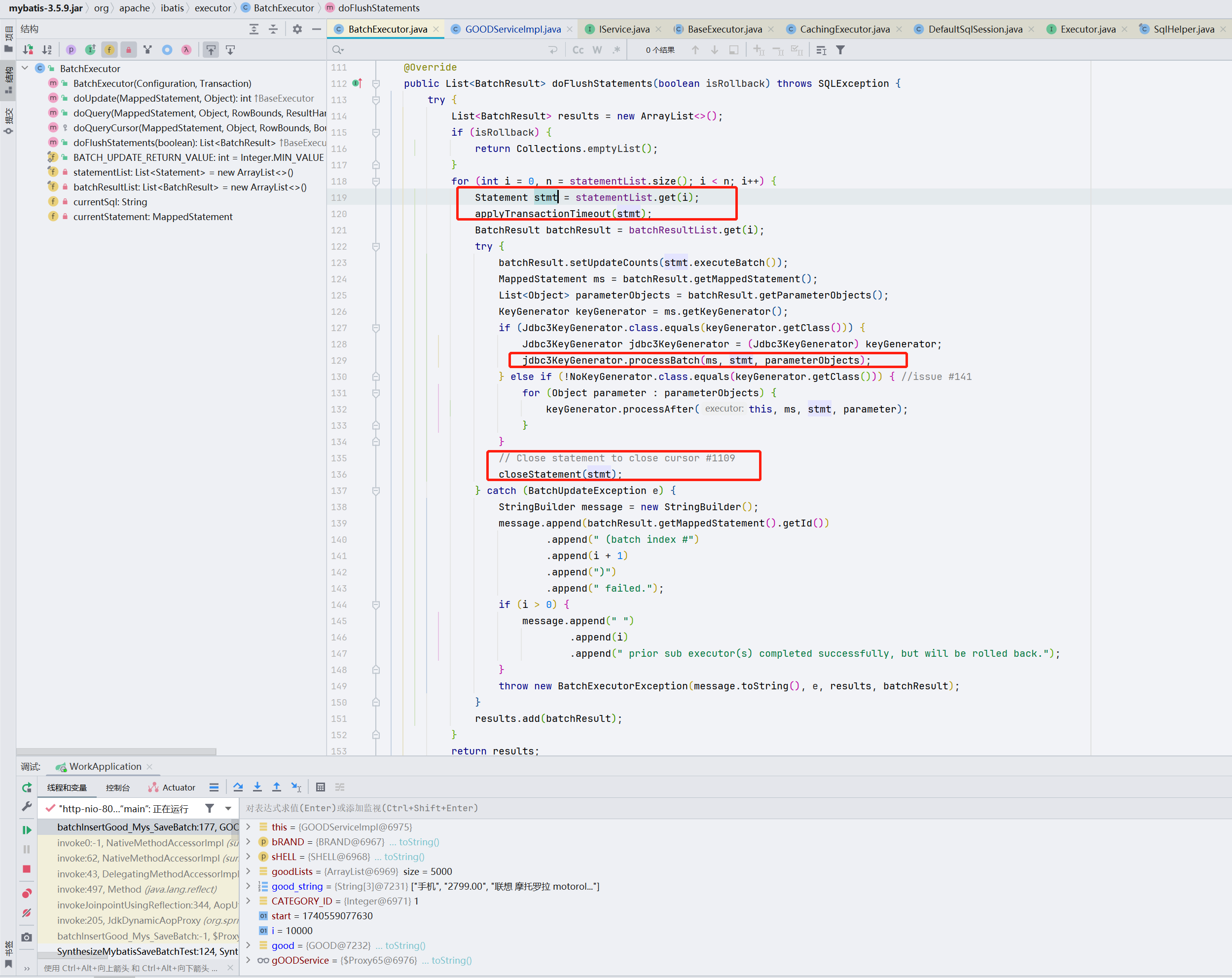
此处的stmt.executeBatch()函数,直接调的是DM的do_executeLargeBatch函数