不同地区(语言)windows系统的字符串乱码问题
如以下场景:
在简体中文的win系统,记事本创建一个txt,输入
我是谁?
Who am I?
保存txt后,拷贝到日文系统中打开是这样的
ホメハヌヒュ」ソ
Who am I?
原因是系统的字符编码不同,不同编码的解析方法是不同的,按照错误的编码来解析就产生错误的结果了,比如常见的乱码
像上面的txt文件,二进制显示如下:
ce d2 ca c7 cb ad a3 bf 0d 0a 57 68 6f 20 61 6d 20 49 3f
这是GB2312编码的字符串,在日文系统中会按照Shift_JIS编码解析,导致错误
在记事本右下角可以看到编码方式是"ANSI",这个ANSI又是什么意思?见下文对代码页的详细说明
解决办法:
采用UTF-8编码,记事本中可以通过另存为选择编码
我是谁?
私は誰ですか?
Who am I?
二进制显示如下:
e6 88 91 e6 98 af e8 b0 81 ef bc 9f 0d 0a e7 a7 81 e3 81 af e8 aa b0 e3 81 a7 e3 81 99 e3 81 8b ef bc 9f 0d 0a 57 68 6f 20 61 6d 20 49 3f
不管在什么语言系统下显示都是按照UTF-8解析,可以正常显示字符串
代码页
通过命令行chcp可以查询系统当前的代码页,不同代码页对应不同的字符编码,比如日文系统是932,简体中文系统是936
但这里还要注意一点,命令行里查到的是OEM代码页,还有一个叫做ANSI代码页,区别如下
ANSI代码页用于Windows图形界面程序
OEM代码页用于命令行和控制台程序
有的语言这两会不一样,如俄文,OEM代码页是866,ANSI代码页是1251
常用字符编码和代码页的对应关系如下:
| 编码名称 | 代码页 | 别名 | 说明 |
|---|---|---|---|
| UTF-8 | 65001 | - | 8位Unicode转换格式,现代标准,跨平台通用 |
| UTF-16LE | 1200 | - | 16位Unicode小端序,Windows内部使用 |
| UTF-16BE | 1201 | - | 16位Unicode大端序,某些旧系统 |
| UTF-32LE | 12000 | - | 32位Unicode小端序,特殊用途 |
| UTF-32BE | 12001 | - | 32位Unicode大端序,特殊用途 |
| Windows-1252 | 1252 | ANSI Latin-1 | 英语、法语、德语、西班牙语等西欧语言 |
| ISO-8859-1 | 28591 | Latin-1 | 西欧语言(ISO标准) |
| IBM437 | 437 | OEM US | 原始IBM PC编码,早期美国 DOS 系统 |
| IBM850 | 850 | Multilingual Latin-1 | 多语言 DOS |
| GB2312 | 936 | GBK, CP936 | 简体中文(中国大陆) |
| GB18030 | 54936 | - | 简体中文国家标准 |
| Big5 | 950 | - | 繁体中文(台湾、香港、澳门) |
| EUC-CN | 51936 | - | 中文扩展Unix编码 |
| Shift_JIS | 932 | CP932, SJIS | 日语(Microsoft扩展) |
| ISO-2022-JP | 50220 | JIS | 日语(邮件标准) |
| EUC-JP | 51932 | - | 日语Unix编码 |
| EUC-KR | 949 | CP949, UHC | 韩语扩展编码 |
| ISO-2022-KR | 50225 | - | 韩语邮件标准 |
| Johab | 1361 | - | 韩语字符集 |
| Windows-1251 | 1251 | ANSI Cyrillic | 俄语、保加利亚语等 |
| IBM866 | 866 | OEM Russian | DOS俄语编码 |
| KOI8-R | 20866 | - | 俄语(Unix传统) |
| KOI8-U | 21866 | - | 乌克兰语 |
| Windows-1256 | 1256 | - | 阿拉伯语 |
| Windows-1255 | 1255 | - | 希伯来语 |
| ISO-8859-6 | 28596 | - | 阿拉伯语 |
| ISO-8859-8 | 28598 | - | 希伯来语 |
| Windows-1250 | 1250 | - | 波兰语、捷克语、匈牙利语等 |
| ISO-8859-2 | 28592 | - | 中欧语言 |
| Windows-1254 | 1254 | - | 土耳其语 |
| ISO-8859-9 | 28599 | - | 土耳其语 |
| Windows-1257 | 1257 | - | 爱沙尼亚语、拉脱维亚语、立陶宛语 |
| ISO-8859-4 | 28594 | - | 波罗的海语言 |
“系统区域设置”决定代码页。windows系统在安装时会根据不同国家/地区修改系统区域设置,我们可以自行修改为其它语言(代码页)
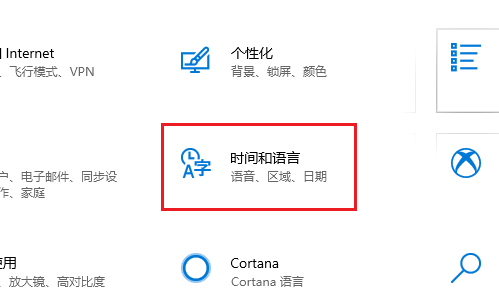
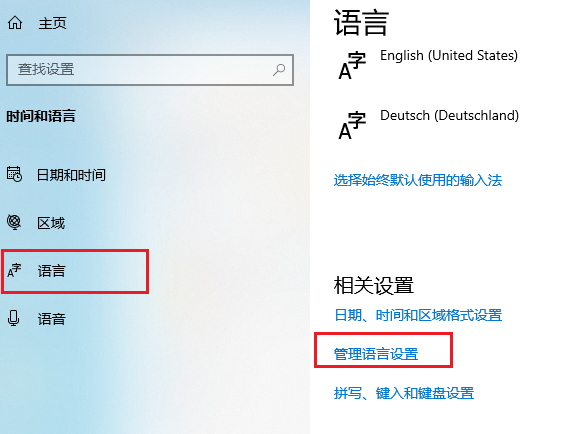
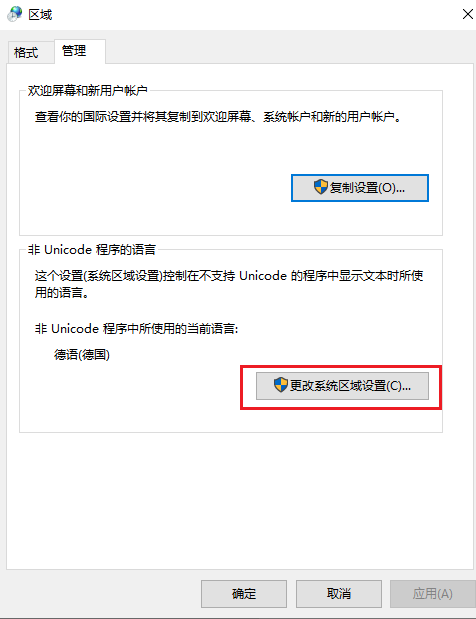
编程
对于编程,这个问题会更复杂一些。我们可以发现有一些程序只支持英文路径,其原因就是程序对字符串的处理没有考虑字符编码的问题,不同语言的字符需要特定字符编码才能表示,而英文字符在ASCII中规定,单字节的字符编码(如GBK、UTF-8)都兼容ASCII,而多字节编码(如UTF-16、UTF-32)则不兼容 ASCII
下面讨论一些编码造成的典型问题
1、字符串字面量
源代码(.h、.cpp)文件的字符编码会决定字面量的编码,如
const char* str = "我是谁";printf("%s", str);printf("\n");for (int i = 0; i < strlen(str); i++) {printf("%02X ", (unsigned char)str[i]);}printf("\n");
用记事本或其它工具打开源码文件,右下角查看字符编码,正常应该是ANSI(此处为简体中文系统,代码页936,对应GB2312)。打印结果如下
我是谁
CE D2 CA C7 CB AD
字符串显示正常
通过记事本把源码文件的编码改为UTF-8,VS-“配置属性”-“C/C++”>“命令行”属性页>“其它选项”填/utf-8 (必须VS 2019以上才支持该命令),重新编译,打印结果如下
鎴戞槸璋
E6 88 91 E6 98 AF E8 B0 81
字符串显示乱码,此时通过勾选"系统区域设置"-"Beta版:使用Unicode UTF-8 提供全球语言支持"可以使printf打印正常的字符
VS默认是按照ANSI保存源代码文件及编译,所以字面量支持本地代码页的字符,如代码页936就可以直接表示中文字符。但如果程序运行在其它代码页的系统时,str的内存打印结果如下
CE D2 CA C7 CB AD
可见,程序依然按照编译时的代码页936来解析字符串
如果希望用字面量表示字符能够在不同的代码页系统中保持一致,有两种思路:
一是使用宽字符,对于windows就是UTF-16 LE编码
以下代码在不同代码页下都能够获得正确的输出
//(这段代码可以忽略)初始化控制台,为了在不同代码页环境下正确显示中文HANDLE hConsole = GetStdHandle(STD_OUTPUT_HANDLE);DWORD charsWritten;CONSOLE_FONT_INFOEX fontInfo;fontInfo.cbSize = sizeof(fontInfo);GetCurrentConsoleFontEx(hConsole, FALSE, &fontInfo);wcscpy_s(fontInfo.FaceName, L"NSimSun"); //设置控制台字体为新宋体,确保正确显示中文SetCurrentConsoleFontEx(hConsole, FALSE, &fontInfo);//核心代码const wchar_t* str_w = L"我是谁";WriteConsoleW(hConsole, str_w, wcslen(str_w), &charsWritten, NULL); //通过WriteConsoleW来正确输出宽字符,避免使用wprintfWriteConsoleW(hConsole, L"\n", 1, &charsWritten, NULL);for (int i = 0; i < wcslen(str_w); i++) {for (int j = 0; j < sizeof(wchar_t); j++) {printf("%02X ", ((unsigned char*)str_w)[i * sizeof(wchar_t) + j]);}}printf("\n");
二是先把字面量(编译时的字符编码)转换为UTF-8编码后再处理,避免使用ANSI编码。这样就可以仍然用窄字符表示字符串
以下代码在不同代码页下都能够获得一致的输出
//(这段代码可以忽略)初始化控制台,让其支持打印UTF-8字符SetConsoleOutputCP(65001);SetConsoleCP(65001);HANDLE hConsole = GetStdHandle(STD_OUTPUT_HANDLE);DWORD charsWritten;CONSOLE_FONT_INFOEX fontInfo;fontInfo.cbSize = sizeof(fontInfo);GetCurrentConsoleFontEx(hConsole, FALSE, &fontInfo);wcscpy_s(fontInfo.FaceName, L"NSimSun"); //设置控制台字体为新宋体,确保正确显示中文SetCurrentConsoleFontEx(hConsole, FALSE, &fontInfo);//核心代码const char* str = "我是谁"; //编译时的字符编码为GB2312auto GbkToUtf16 = [=](const std::string& str) {std::wstring ret;if (str.empty()) return ret;int wide_len = MultiByteToWideChar(936, 0, str.c_str(), -1, nullptr, 0);if (wide_len == 0) return ret;std::vector<wchar_t> buffer(wide_len);MultiByteToWideChar(936, 0, str.c_str(), -1, buffer.data(), wide_len);return std::wstring(buffer.data());};auto Utf16ToUtf8 = [](const std::wstring& str) {std::string ret;if (str.empty()) return ret;int utf8_len = WideCharToMultiByte(CP_UTF8, 0, str.c_str(), -1, nullptr, 0, nullptr, nullptr);if (utf8_len == 0) return ret;std::vector<char> buffer(utf8_len);WideCharToMultiByte(CP_UTF8, 0, str.c_str(), -1, buffer.data(), utf8_len, nullptr, nullptr);return std::string(buffer.data());};std::string str_utf8 = Utf16ToUtf8(GbkToUtf16(str)); //GB2312转换为UTF-8printf("%s", str_utf8.c_str());printf("\n");for (int i = 0; i < str_utf8.size(); i++) {printf("%02X ", (unsigned char)str_utf8[i]);}printf("\n");
2、windows api的字符编码
常用的windows api一般分为两个版本,FunctionA和FunctionW,用于区分不同的字符串处理方式,如果写Function会根据宏UNICODE决定使用哪个版本。FunctionA对于输入参数中的字符串会按照ANSI(依赖代码页)编码来解析,后者则按照UTF-16(Unicode)编码。这里以INI文件的解析接口GetPrivateProfileInt 为例进行分析
#include <windows.h>
#include <iostream>void exampleUsage() {// 方法1:明确使用A版本(ANSI)UINT valueA = GetPrivateProfileIntA("Section", // ANSI字符串"Key", // ANSI字符串0, // 默认值"config.ini" // ANSI文件名);// 方法2:明确使用W版本(Unicode)UINT valueW = GetPrivateProfileIntW(L"Section", // Unicode字符串(L前缀)L"Key", // Unicode字符串0, // 默认值L"config.ini" // Unicode文件名);// 方法3:使用宏版本(推荐)UINT value = GetPrivateProfileInt(TEXT("Section"), // 使用TEXT宏TEXT("Key"), // 自动适配编码0, // 默认值TEXT("config.ini") // 自动适配编码);std::cout << "Value: " << value << std::endl;
}
头文件
// 在winnt.h中的定义
#ifdef UNICODE
typedef wchar_t TCHAR;
#define TEXT(quote) L##quote
#else
typedef char TCHAR;
#define TEXT(quote) quote
#endif// 函数声明
#ifdef UNICODE
#define GetPrivateProfileInt GetPrivateProfileIntW
#else
#define GetPrivateProfileInt GetPrivateProfileIntA
#endif
假设简体中文系统(代码页936),字符编码为ANSI的config.ini,内容如下
[我是谁]
我=1
调用GetPrivateProfileIntA可以读取key"我"的值
char section[] = {0xce, 0xd2,0xca, 0xc7,0xcb, 0xad,0x00}; //GB2312编码的“我是谁”char key[] = { 0xce, 0xd2, 0x00 }; //GB2312编码的“我”int value = GetPrivateProfileIntA(section, key, -1, "config.ini");
通过记事本将上面的config.ini保存为UTF-16 LE编码,config_utf16.ini,需要调用GetPrivateProfileIntW才可以读取key"我"的值
wchar_t section_w[] = {0x6211,0x662F, 0x8C01, 0x0000}; //UTF-16 LE编码的“我是谁”wchar_t key_w[] = { 0x6211, 0x0000 }; //UTF-16 LE编码的“我”int value = GetPrivateProfileIntW(section_w, key_w, -1, "config_utf16.ini");
对于字符编码为UTF-8的ini文件,不能直接用GetPrivateProfileInt来读取,只能自己写代码实现ini解析,或者勾选"系统区域设置"-"Beta版:使用Unicode UTF-8 提供全球语言支持"将代码页强制设置为65001即UTF-8,则可以调用GetPrivateProfileIntA读取成功
3、标准库的字符编码
一般会有窄字符和宽字符两个版本的函数或类,如ifstream和wifstream
windows平台窄字符对应ANSI编码,宽字符对应UTF-16 LE编码;Linux/macOS的窄字符对应UTF-8编码
对于windows,为了适配多语言(不同代码页)环境,需要使用宽字符。系统对于诸如文件名、目录名都是采用UTF-16编码保存的