深度学习Pytorch入门(2):手撕MNIST 手写数字分类
上一节熟悉了CIFAR 10分类,这一节熟悉一下手写数字识别,主要目的是为了熟悉代码的写法,全部默写一遍,加深记忆,和上节一模一样,本节不会写的很赘述,可以参考【深度学习Pytorch入门(1):手撕CIFAR 10影像分类】
数据介绍
MNIST数据集是282810 十分类的数据集,训练集60000张,测试集10000张
https://en.wikipedia.org/wiki/MNIST_database
网络介绍和实现
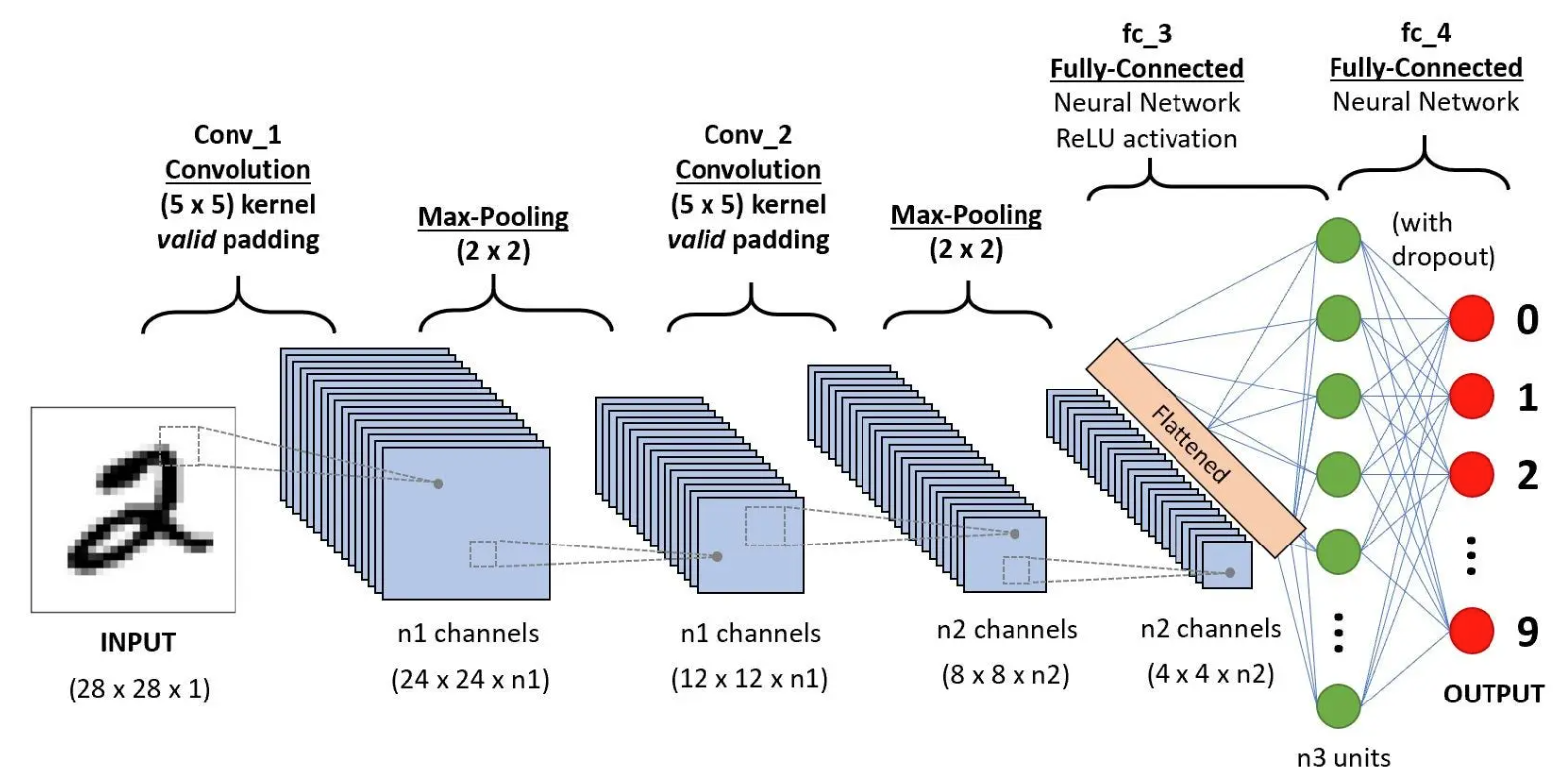
CNN卷积神经网络
n1 n2 n3 我这边取10 20 50
很简单,就是卷积+激活+池化
写出来如下,不在赘述,可以看上节内容:
import torch
import torch.nn as nn#定义一个CNN模型,用于手写数字分类
class lixiao_Model(nn.Module):def __init__(self):super(lixiao_Model, self).__init__()self.model1 = nn.Sequential(#开始定义网络#卷积1nn.Conv2d(in_channels=1,out_channels=10,kernel_size=5,stride=1,padding=0),#激活1nn.ReLU(),#池化1nn.MaxPool2d(kernel_size=2),# 卷积2nn.Conv2d(in_channels=10, out_channels=20, kernel_size=5, stride=1, padding=0),# 激活2nn.ReLU(),# 池化2nn.MaxPool2d(kernel_size=2),# 拉平nn.Flatten(),# 线性全连接层1nn.Linear(in_features=320,out_features=50),# 线性全连接层2nn.Linear(in_features=50, out_features=10))def forward(self,x):output = self.model1(x)return outputif __name__ == "__main__":lixiao = lixiao_Model()input = torch.ones((1,1,28,28))output = lixiao(input)print(output)训练
和上一节完全一样,可以照搬,我这边变量名可能有些不一样,因为我默写的,加深记忆
import torch
import torchvision
from torch.utils.tensorboard import SummaryWriter
from torch.utils.data import DataLoader
import torch.nn as nn
from CNN_Model import *
from torch.optim.lr_scheduler import ReduceLROnPlateau
import timedevice = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")#定义训练集和测试集
train_data = torchvision.datasets.MNIST("./MNIST_Dataset",train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.MNIST("./MNIST_Dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)print("train size = {}".format(len(train_data)))
print("test size = {}".format(len(test_data)))#data loader
train_data_loader = DataLoader(train_data,batch_size=64)
test_data_loader = DataLoader(test_data,batch_size=64)# 模型实例化和加载
lixiao = lixiao_Model()
lixiao = lixiao.to(device)# 开始定义损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.to(device)# 开始定义优化器
lr_ration = 0.01
optimizer = torch.optim.SGD(lixiao.parameters(),lr_ration)# 开始定义学习率衰减
scheduler = ReduceLROnPlateau(optimizer=optimizer, mode='min', factor=0.1,patience=2, verbose=True, threshold=0.0001, threshold_mode='rel',cooldown=0, min_lr=0, eps=1e-08)#开始定义一些超参数
#迭代次数
epoch = 200
#学习率和超过5次不变就跳出训练
test_loss_threshold = 0.001
test_loss_num_threshold = 5
#训练集+测试集 计数器
total_train_step = 0
total_test_step = 0
#最低损失
best_loss = 99999999#中间 全局变量 记录上一次的损失和计数器
test_loss_last = 0
test_loss_stop_num = 0writer = SummaryWriter("./train_logs")# 开始训练
for i in range(epoch):start_time = time.time()#每次epochprint("----------epoch:{} 正在训练---------".format(i+1))lixiao.train()for data in train_data_loader:img,targets = dataimg = img.to(device)targets = targets.to(device)#训练output = lixiao(img)# 开始计算损失loss = loss_fn(output,targets)#优化器梯度归零optimizer.zero_grad()# 反向传播loss.backward()#更新梯度optimizer.step()#打印一下训练的损失看看total_train_step+=1if total_train_step % 100 == 0:print("训练次数:{},loss:{}".format(total_train_step,loss.item()))#绘制训练集损失和迭代的折线图writer.add_scalar("train_loss",loss.item(),total_train_step)#开始看测试集epoch_test_loss = 0total_accuacy = 0lixiao.eval()with torch.no_grad():for data in test_data_loader:img,targets = dataimg = img.to(device)targets = targets.to(device)#测试output = lixiao(img)#损失loss = loss_fn(output,targets)epoch_test_loss += loss#计算准确性accuacy = (output.argmax(1) == targets).sum() / len(test_data)total_accuacy += accuacy# 打印一下训练的损失看看total_test_step+=1if total_test_step % 10 == 0:#print("测试次数:{},loss:{}".format(total_train_step,loss.item()))#绘制训练集损失和迭代的折线图writer.add_scalar("test_loss",loss.item(),total_test_step)#一次epoch的时间end_time = time.time()print("epoch:{} time:{}".format(i+1,end_time-start_time))# 学习率衰减scheduler.step(epoch_test_loss)# 所有测试集 测试完后,开始统计以下信息#打印动态学习率t_lr = optimizer.param_groups[0]['lr']print("epoch:{} lr:{}".format(i+1,t_lr))#打印损失total_train_step += 1print("epoch:{},loss {}, accuacy {}".format(i+1,epoch_test_loss,total_accuacy))# 保存最佳模型,保存当前模型torch.save(lixiao, "./models/last.pt")if best_loss > epoch_test_loss:best_loss = epoch_test_losstorch.save(lixiao,"./models/best.pt")#判断跳出循环的条件loss_dis = abs(epoch_test_loss - test_loss_last)print("loss dis:{},curr:{},last:{},jsq:{}".format(loss_dis,test_loss_last,epoch_test_loss,test_loss_stop_num))test_loss_last = epoch_test_lossif loss_dis < test_loss_threshold:#损失比阈值小了,开始给计数器+1test_loss_stop_num += 1#如果计数器大于阈值if test_loss_stop_num > test_loss_num_threshold:print("损失已经超过{}不再下降,提前结束训练".format(test_loss_num_threshold))breakelse:#loss 损失比阈值大 说明我需要一直清零test_loss_stop_num = 0训练结果如下:
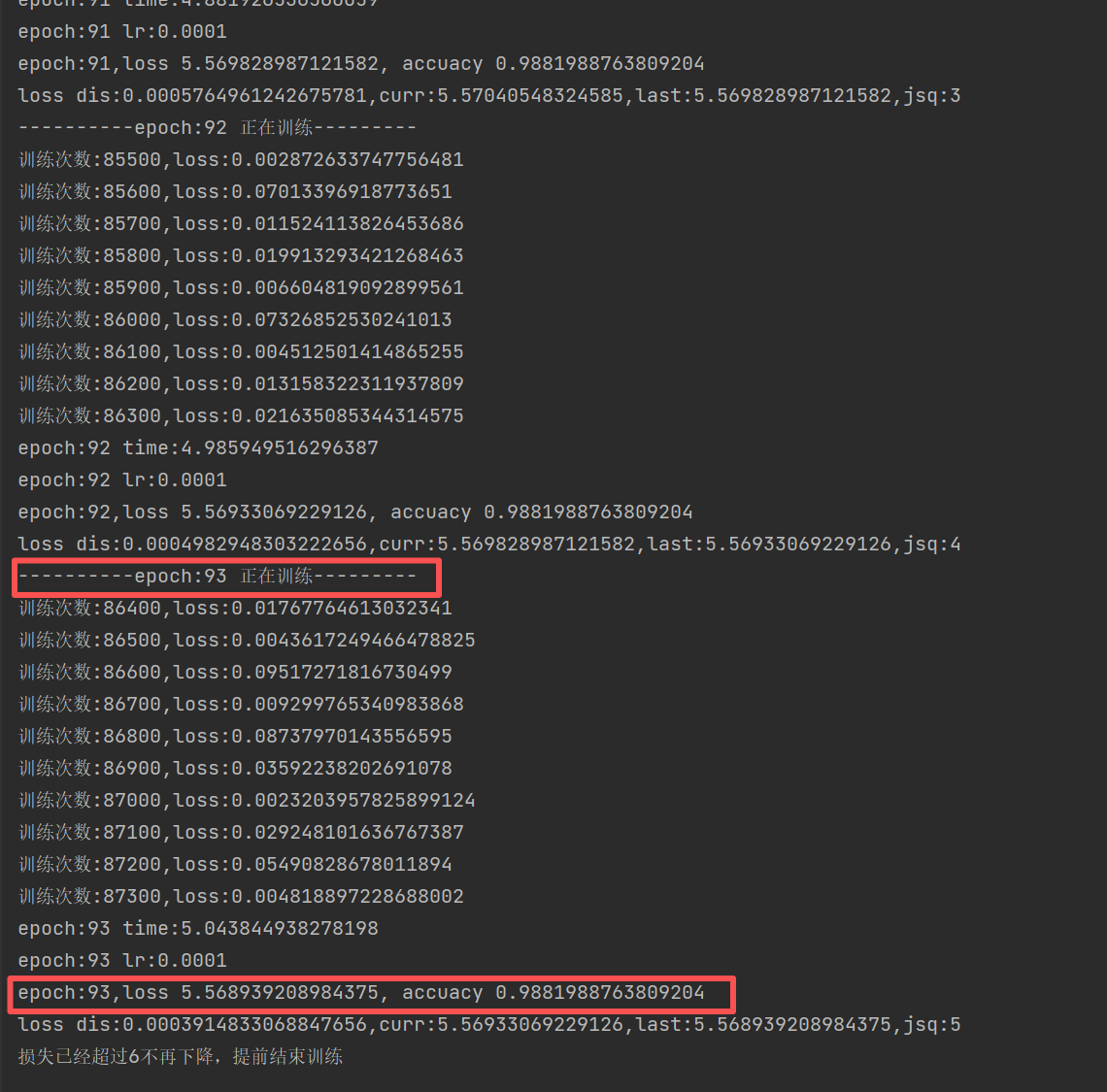
训练到93次,因为损失不发生变化,退出了
损失降到5.56,准确率98.82%
验证
验证部分主要是数据预处理部分
1.我是电脑上截屏手写保存的,所以,涉及到的操作有:
读取->转灰度->拉伸到0-255->取反(白底黑字)->转tensor->Resize->扩充batch size 维度(1,1,28,28)
2.如果是黑底白字,不需要取反操作
import cv2
import torch
import os
import torchvision
from torch.utils.tensorboard import SummaryWriter
import numpy as np
from CNN_Model import *# device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
device = torch.device("cuda:0")
# 先加载模型
lixiao = lixiao_Model()
lixiao = lixiao.to(device)
lixiao = torch.load("./models/best.pt")print(lixiao)
# 加载数据
filename = "C:/Users/lixia/Desktop/MNIST/aaaa/"
all_imgs = os.listdir(filename)
print(all_imgs)# transform 组合变换 先转tensor 再 resize
transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor(),torchvision.transforms.Resize((28,28))])
writer = SummaryWriter("./logs_test")
# 设置为评估模式
lixiao.eval()
step = 0
for i in all_imgs:# 拼接影像路径imgfilename = os.path.join(filename,i)print(imgfilename)#开始读取影像img = cv2.imread(imgfilename)#彩色转灰度img = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)# 将影像归一化,并拉伸到0-1之间,如果是白底黑字,还需要取反一下# 将像素值扩展到0-255范围# min_val = np.min(img)# max_val = np.max(img)# img = (img - min_val) * 255.0 / (max_val - min_val)# img = img.astype(np.float32) / 255.0# img = 1.0 - img # 黑白对调#转换 用的是一个变换组 先转tensor 结构,再resizeimg = transform(img)# 写图像到日志界面writer.add_image("test", img, step)step += 1# 扩展一个batch size 的维度img = torch.reshape(img, (-1, 1, 28, 28))# 开始预测with torch.no_grad():# tensor 搬到设备端img = img.to(device)# 模型预测output = lixiao(img)# 计算labelpred = output.argmax(dim=1).item()print(f"图像 {i} 的预测数字是: {pred}")
写到日志里面的折线图和图片,可以使用该命令查看

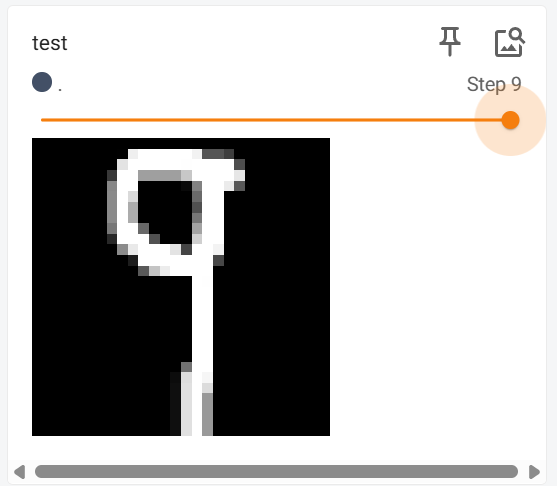
训练是98%的准确性了,但是我的数据集预测效果可不咋样,可能是我写的太规范了?和数据集差别较大?
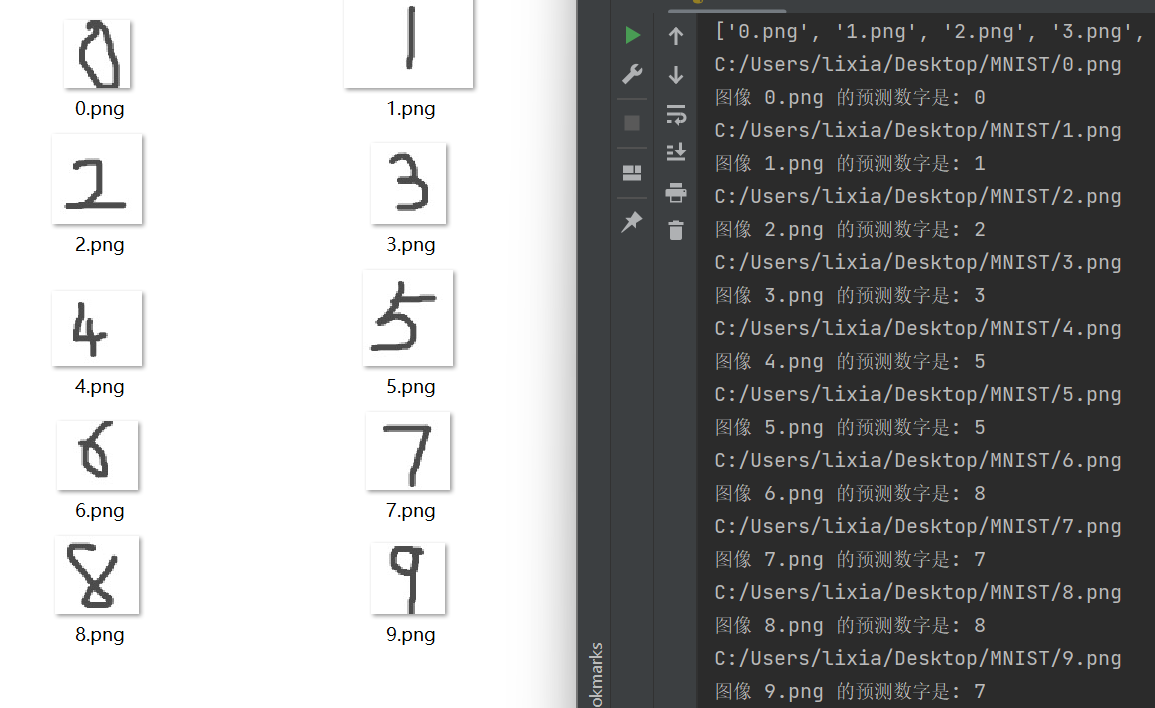
百度图片随便抓了一个图,扣了一些数字下来预测,还是挺准的
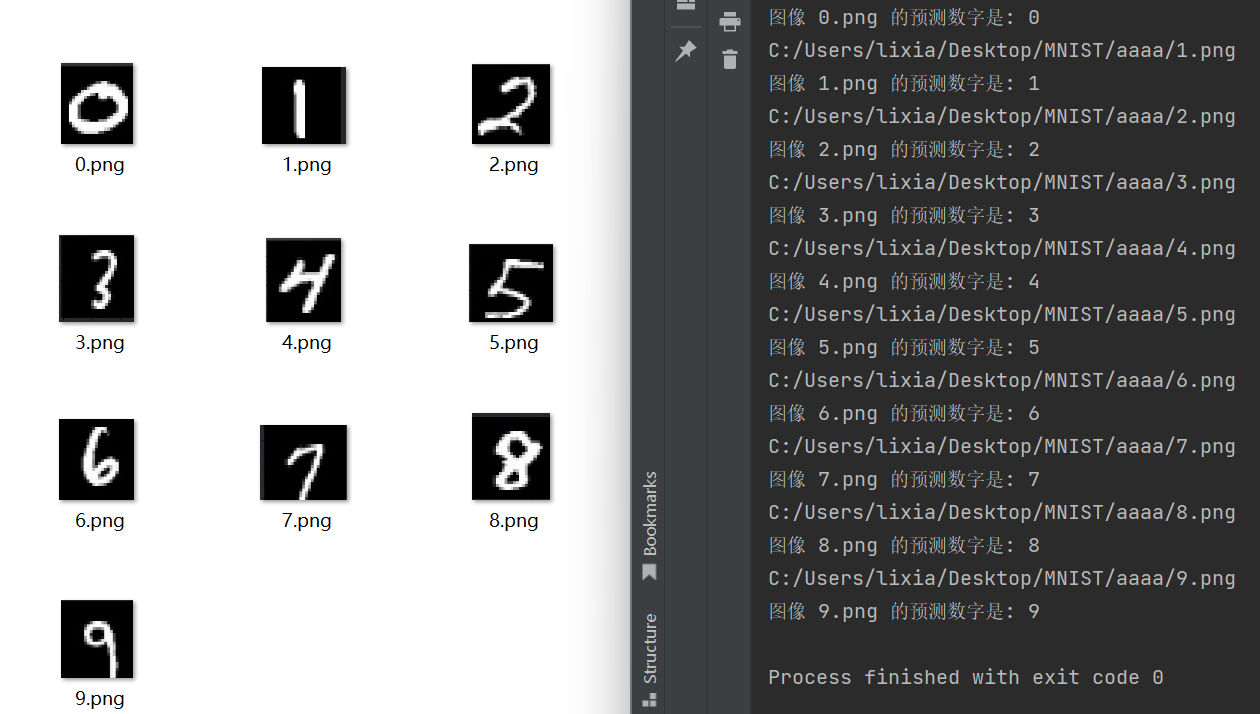
就这样吧,算是巩固了一下分类流程,后面再看看其他网络