【读书笔记】架构整洁之道 P2~3 编程范式设计原则
英文原书:https://agorism.dev/book/software-architecture/%28Robert%20C.%20Martin%20Series%29%20Robert%20C.%20Martin%20-%20Clean%20Architecture_%20A%20Craftsman%E2%80%99s%20Guide%20to%20Software%20Structure%20and%20Design-Prentice%20Hall%20%282017%29.pdf
推荐序
Bob大叔举了一个相当有趣的例子,如果又要保证操作原子性又要能精确还原各时刻的状态,有个办法是这样的:只提供CR操作,而不提供完整的CRUD操作(就像MySQL的binlog那样)。平时只要追加操作记录即可,各时刻的状态永远通过重放之前的操作记录得出,这样就彻底避免了状态的错乱。这个办法看起来古怪,但我真的在之前的开发中用过(当然是在程序生命周期有限的场景下),而且真的从没出过错。
第2部分 从基础构件开始:编程范式
直到今天,我们也一共只有三个编程范式,而且未来几乎不可能再出现新的
第3章 编程范式总览
它们分别是结构化编程(structured programming)、面向对象编程(object-oriented programming)以及函数式编程(functional programming)
- 结构化编程:我们可以将结构化编程范式归结为一句话:结构化编程对程序控制权的直接转移进行了限制和规范。
- 面向对象编程
- 事实上,这个编程范式的提出比结构化编程还早了两年,是在1966年由Ole Johan Dahl和Kriste Nygaard在论文中总结归纳出来的。这两个程序员注意到在ALGOL语言中,函数调用堆栈(call stack frame)可以被挪到堆内存区域里,这样函数定义的本地变量就可以在函数返回之后继续存在。这个函数就成为了一个类(class)的构造函数,而它所定义的本地变量就是类的成员变量,构造函数定义的嵌套函数就成为了成员方法(method)。这样一来,我们就可以利用多态(polymorphism)来限制用户对函数指针的使用。
- 我们也可以用一句话来总结面向对象编程:面向对象编程对程序控制权的间接转移进行了限制和规范。
- 函数式编程
- 从理论上来说,函数式编程语言中应该是没有赋值语句的。大部分函数式编程语言只允许在非常严格的限制条件下,才可以更改某个变量的值。
- 这里可以将函数式编程范式总结为下面这句话:函数式编程对程序中的赋值进行了限制和规范。
每个编程范式的目的都是设置限制。这些范式主要是为了告诉我们不能做什么,而不是可以做什么。这三个编程范式分别限制了goto语句、函数指针和赋值语句的使用。
这些编程范式的历史知识与软件架构有关系吗?当然有,而且关系相当密切。譬如说:
- 多态是我们跨越架构边界的手段
- 函数式编程是我们规范和限制数据存放位置与访问权限的手段
- 结构化编程则是各模块的算法实现基础。
这和软件架构的三大关注重点不谋而合:功能性、组件独立性以及数据管理。
第4章 结构化编程
可推导性
Dijkstra认为程序员可以像数学家一样对自己的程序进行推理证明。换句话说,程序员可以用代码将一些已证明可用的结构串联起来,只要自行证明这些额外代码是正确的,就可以推导出整个程序的正确性。
Dijkstra在研究过程中发现了一个问题:goto语句的某些用法会导致某个模块无法被递归拆分成更小的、可证明的单元,这会导致无法采用分解法来将大型问题进一步拆分成更小的、可证明的部分。
goto语句的其他用法虽然不会导致这种问题,但是Dijkstra意识到它们的实际效果其实和更简单的分支结构if-then-else以及循环结构do-while是一致的。如果代码中只采用了这两类控制结构,则一定可以将程序分解成更小的、可证明的单元。
测试
结构化编程范式促使我们先将一段程序递归降解为一系列可证明的小函数,然后再编写相关的测试来试图证明这些函数是错误的。如果这些测试无法证伪这些函数,那么我们就可以认为这些函数是足够正确的,进而推导整个程序是正确的。
第5章 面向对象编程
究竟什么是面向对象?
对于这个问题,一种常见的回答是“数据与函数的组合”。这种说法虽然被广为引用,但总显得并不是那么贴切,因为它似乎暗示了o.f()与f(o)之间是有区别的,这显然不是事实。面向对象理论是在1966年提出的,当时Dahl和Nygaard主要是将函数调用栈迁移到了堆区域中。数据结构被用作函数的调用参数这件事情远比这发生的时间更早。
还有些人在回答这个问题的时候,往往会搬出一些神秘的词语,譬如封装(encapsulation)、继承(inheritance)、多态(polymorphism)。其隐含意思就是说面向对象编程是这三项的有机组合,或者任何一种支持面向对象的编程语言必须支持这三个特性。
封装
通过采用封装特性,我们可以把一组相关联的数据和函数圈起来,使圈外面的代码只能看见部分函数,数据则完全不可见。譬如,在实际应用中,类(class)中的公共函数和私有成员变量就是这样。
然而,这个特性其实并不是面向对象编程所独有的。其实,C语言也支持完整的封装

显然,使用point.h的程序是没有Point结构体成员的访问权限的。它们只能调用makePoint()函数和distance()函数,但对它们来说,Point这个数据结构体的内部细节,以及函数的具体实现方式都是不可见的。
这正是完美封装
而C++作为一种面向对象编程语言,反而破坏了C的完美封装性。
由于一些技术原因[2](C++编译器必须要知道每个类实例的大小),C++编译器要求类的成员变量必须在该类的头文件中声明。这样一来,我们的point.h程序随之就改成了这样:

好了,point.h文件的使用者现在知道了成员变量x和y的存在!虽然编译器会禁止对这两个变量的直接访问,但是使用者仍然知道了它们的存在。而且,如果x和y变量名称被改变了,point.cc也必须重新编译才行!这样的封装性显然是不完美的。
当然,C++通过在编程语言层面引入public、private、protected这些关键词,部分维护了封装性。但所有这些都是为了解决编译器自身的技术实现问题而引入的hack——编译器由于技术实现原因必须在头文件中看到成员变量的定义。
而Java和C#则彻底抛弃了头文件与实现文件分离的编程方式,这其实进一步削弱了封装性。因为在这些语言中,我们是无法区分一个类的声明和定义的。
由于上述原因,我们很难说强封装是面向对象编程的必要条件。而事实上,有很多面向对象编程语言[3]对封装性并没有强制性的要求。
继承


请仔细观察main函数,这里NamedPoint数据结构是被当作Point数据结构的一个衍生体来使用的。之所以可以这样做,是因为NamedPoint结构体的前两个成员的顺序与Point结构体的完全一致。简单来说,NamedPoint之所以可以被伪装成Point来使用,是因为NamedPoint是Point结构体的一个超集,同时两者共同成员的顺序也是一样的。
上面这种编程方式虽然看上去有些投机取巧,但是在面向对象理论被提出之前,这已经很常见了[5]。其实,C++内部就是这样实现单继承的。
同时应该注意的是,在main.c中,程序员必须强制将NamedPoint的参数类型转换为Point,而在真正的面向对象编程语言中,这种类型的向上转换通常应该是隐性的。
多态
在面向编程对象语言被发明之前,我们所使用的编程语言能支持多态吗?答案是肯定的,请注意看下面这段用C语言编写的copy程序
#include <stdio.h>
void copy(){int c;while ((c=getchar())!= EOF)putchar(c);
}在上述程序中,函数getchar()主要负责从STDIN中读取数据。但是STDIN究竟指代的是哪个设备呢?同样的道理,putchar()主要负责将数据写入STDOUT,而STDOUT又指代的是哪个设备呢?很显然,这类函数其实就具有多态性,因为它们的行为依赖于STDIN和STDOUT的具体类型。
这里的STDIN和STDOUT与Java中的接口类似,各种设备都有各自的实现。当然,这个C程序中是没有接口这个概念的,那么getchar()这个调用的动作是如何真正传递到设备驱动程序中,从而读取到具体内容的呢?
其实很简单,UNIX操作系统强制要求每个IO设备都要提供open、close、read、write和seek这5个标准函数。[6]也就是说,每个IO设备驱动程序对这5种函数的实现在函数调用上必须保持一致。
首先,FILE数据结构体中包含了相对应的5个函数指针,分别用于指向这些函数:
然后,譬如控制台设备的IO驱动程序就会提供这5个函数的实际定义,将FILE结构体的函数指针指向这些对应的实现函数:
换句话说,getchar()只是调用了STDIN所指向的FILE数据结构体中的read函数指针指向的函数。
这个简单的编程技巧正是面向对象编程中多态的基础。例如在C++中,类中的每个虚函数(virtual function)的地址都被记录在一个名叫vtable的数据结构里。我们对虚函数的每次调用都要先查询这个表,其衍生类的构造函数负责将该衍生类的虚函数地址加载到整个对象的vtable中。
归根结底,多态其实不过就是函数指针的一种应用。自从20世纪40年代末期冯·诺依曼架构诞生那天起,程序员们就一直在使用函数指针模拟多态了。也就是说,面向对象编程在多态方面没有提出任何新概念。
当然了,面向对象编程语言虽然在多态上并没有理论创新,但它们也确实让多态变得更安全、更便于使用了。
用函数指针显式实现多态的问题就在于函数指针的危险性。毕竟,函数指针的调用依赖于一系列需要人为遵守的约定。程序员必须严格按照固定约定来初始化函数指针,并同样严格地按照约定来调用这些指针。只要有一个程序员没有遵守这些约定,整个程序就会产生极其难以跟踪和消除的Bug。
面向对象编程语言为我们消除了人工遵守这些约定的必要,也就等于消除了这方面的危险性。采用面向对象编程语言让多态实现变得非常简单,让一个传统C程序员可以去做以前不敢想的事情。综上所述,我们认为面向对象编程其实是对程序间接控制权的转移进行了约束。
依赖反转
我们可以想象一下在安全和便利的多态支持出现之前,软件是什么样子的。下面有一个典型的调用树的例子。
显然,这样做就导致了我们在软件架构上别无选择。在这里,系统行为决定了控制流,而控制流则决定了源代码依赖关系。
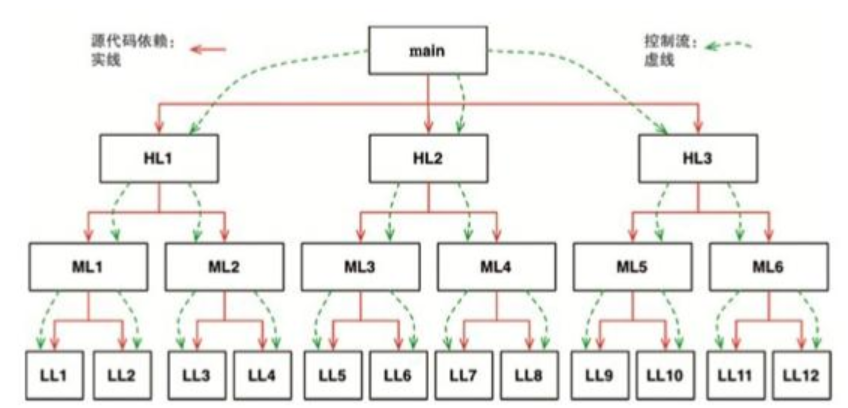
但一旦我们使用了多态,情况就不一样了(详见图5.2)。
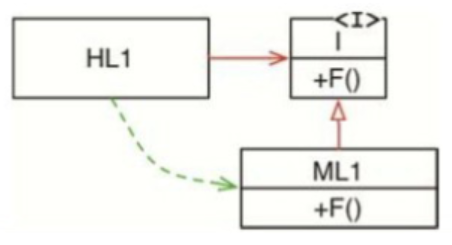
请注意模块ML1和接口I在源代码上的依赖关系(或者叫继承关系),该关系的方向和控制流正好是相反的,我们称之为****依赖反转。这种反转对软件架构设计的影响是非常大的。
事实上,通过利用面向编程语言所提供的这种安全便利的多态实现,无论我们面对怎样的源代码级别的依赖关系,都可以将其反转。
现在,我们可以再回头来看图5.1中的调用树,就会发现其中的众多源代码依赖关系都可以通过引入接口的方式来进行反转。
通过这种方法,软件架构师可以完全控制采用了面向对象这种编程方式的系统中所有的源代码依赖关系,而不再受到系统控制流的限制。不管哪个模块调用或者被调用,软件架构师都可以随意更改源代码依赖关系。
这就是面向对象编程的好处,同时也是面向对象编程这种范式的核心本质——至少对一个软件架构师来说是这样的。
这种能力有什么用呢?在下面的例子中,我们可以用它来让数据库模块和用户界面模块都依赖于业务逻辑模块(见图5.3),而非相反。
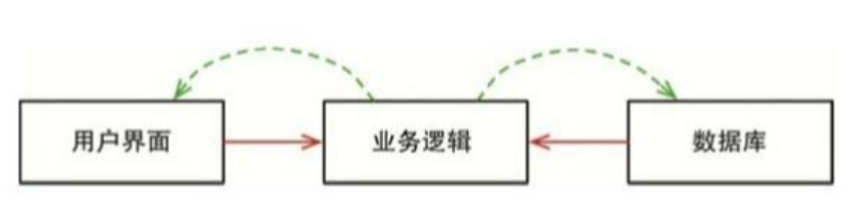
这意味着我们让用户界面和数据库都成为业务逻辑的插件。也就是说,业务逻辑模块的源代码不需要引入用户界面和数据库这两个模块。
这样一来,业务逻辑、用户界面以及数据库就可以被编译成三个独立的组件或者部署单元(例如jar文件、DLL文件、Gem文件等)了,这些组件或者部署单元的依赖关系与源代码的依赖关系是一致的,业务逻辑组件也不会依赖于用户界面和数据库这两个组件。
于是,业务逻辑组件就可以独立于用户界面和数据库来进行部署了,我们对用户界面或者数据库的修改将不会对业务逻辑产生任何影响,这些组件都可以被分别、独立地部署。
第6章 函数式编程
请看下面的这个例子:这段代码想要输出前25个整数的平方值。
public class Squint {public static void main(String args[]){for (int i=0; i<25; i++)System.out.println(i*i);}
}下面我们改用Clojure语言来写这个程序,Clojure是LISP语言的一种衍生体,属于函数式编程语言。其代码如下:
(println(take 25(map(fn[x](* x x))(range))))
现在让我们回过头来再看一下这整句代码,从最内侧的函数调用开始:
- range函数会返回一个从0开始的整数无穷列表。
- 然后该列表会被传入map函数,并针对列表中的每个元素,调用求平方值的匿名函数,产生了一个无穷多的、包含平方值的列表。
- 接着再将这个列表传入take函数,后者会返回一个仅包含前25个元素的新列表。
- println函数将它的参数输出,该参数就是上面这个包含了25个平方值的列表。
读者不用担心上面提到的无穷列表。因为这些列表中的元素只有在被访问时才会被创建,所以实际上只有前25个元素是真正被创建了的。
我们讨论它的主要目标是要突显出Clojure和Java这两种语言之间的巨大区别。在Java程序中,我们使用的是可变量,即变量i,该变量的值会随着程序执行的过程而改变,故被称为循环控制变量。而Clojure程序中是不存在这种变量的,变量x一旦被初始化之后,就不会再被更改了。
这句话有点出人意料:函数式编程语言中的变量(Variable)是不可变(Vary)的。
不可变性与软件架构
为什么不可变性是软件架构设计需要考虑的重点呢?为什么软件架构师要操心变量的可变性呢?答案显而易见:所有的竞争问题、死锁问题、并发更新问题都是由可变变量导致的。如果变量永远不会被更改,那就不可能产生竞争或者并发更新问题。如果锁状态是不可变的,那就永远不会产生死锁问题。
不可变性是否实际可行?——如果我们能忽略存储器与处理器在速度上的限制,那么答案是肯定的。否则的话,不可变性只有在一定情况下是可行的。
可变性的隔离
一种常见方式是将应用程序,或者是应用程序的内部服务进行切分,划分为可变的和不可变的两种组件。不可变组件用纯函数的方式来执行任务,期间不更改任何状态。这些不可变的组件将通过与一个或多个非函数式组件通信的方式来修改变量状态(参见图6.1)。
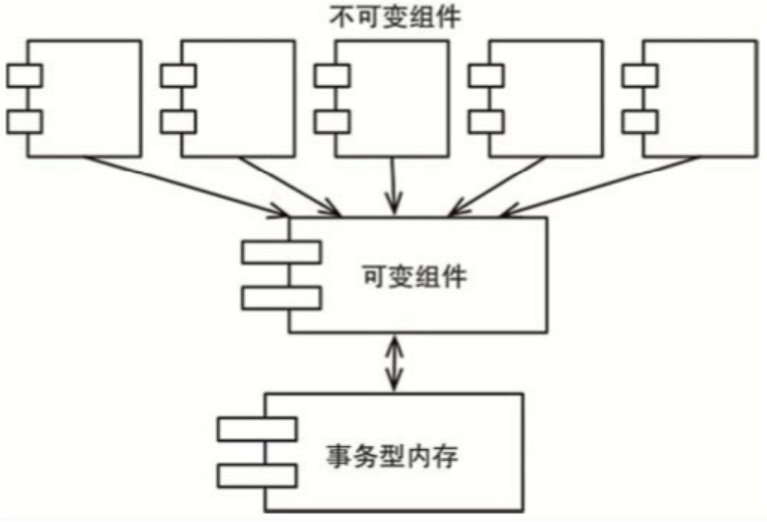
一个架构设计良好的应用程序应该将状态修改的部分和不需要修改状态的部分隔离成单独的组件,然后用合适的机制来保护可变量。
软件架构师应该着力于将大部分处理逻辑都归于不可变组件中,可变状态组件的逻辑应该越少越好。
事件溯源
举个简单的例子,假设某个银行应用程序需要维护客户账户余额信息,当它执行存取款事务时,就要同时负责修改余额记录。
如果我们不保存具体账户余额,仅仅保存事务日志,那么当有人想查询账户余额时,我们就将全部交易记录取出,并且每次都得从最开始到当下进行累计。当然,这样的设计就不需要维护任何可变变量了。
这就是事件溯源[10],在这种体系下,我们只存储事务记录,不存储具体状态。当需要具体状态时,我们只要从头开始计算所有的事务即可。
这种数据存储模式中不存在删除和更新的情况,我们的应用程序不是CRUD,而是CR。因为更新和删除这两种操作都不存在了,自然也就不存在并发问题。
第3部分 设计原则
通常来说,要想构建一个好的软件系统,应该从写整洁的代码开始做起。毕竟,如果建筑所使用的砖头质量不佳,那么架构所能起到的作用也会很有限。反之亦然,如果建筑的架构设计不佳,那么其所用的砖头质量再好也没有用。这就是SOLID设计原则所要解决的问题。
SOLID原则的主要作用就是告诉我们如何将数据和函数组织成为类,以及如何将这些类链接起来成为程序。请注意,这里虽然用到了“类”这个词,但是并不意味着我们将要讨论的这些设计原则仅仅适用于面向对象编程。这里的类仅仅代表了一种数据和函数的分组
一般情况下,我们为软件构建中层结构的主要目标如下:
- 使软件可容忍被改动。
- 使软件更容易被理解。
- 构建可在多个软件系统中复用的组件。
我们在这里之所以会使用“中层”这个词,是因为这些设计原则主要适用于那些进行模块级编程的程序员。SOLID原则应该直接紧贴于具体的代码逻辑之上,这些原则是用来帮助我们定义软件架构中的组件和模块的。
| SRP:单一职责原则 | 该设计原则是基于康威定律(Conway’s Law)[1]的一个推论——一个软件系统的最佳结构高度依赖于开发这个系统的组织的内部结构。这样,每个软件模块都有且只有一个需要被改变的理由。 |
|---|---|
| OCP:开闭原则 | 如果软件系统想要更容易被改变,那么其设计就必须允许新增代码来修改系统行为,而非只能靠修改原来的代码 |
| LSP:里氏替换原则 | 如果想用可替换的组件来构建软件系统,那么这些组件就必须遵守同一个约定,以便让这些组件可以相互替换 |
| ISP:接口隔离原则 | 软件设计师应该在设计中避免不必要的依赖 |
| DIP:依赖反转原则 | 高层策略性的代码不应该依赖实现底层细节的代码,恰恰相反,那些实现底层细节的代码应该依赖高层策略性的代码 |
康威定律(Conway’s Law)——Melvin Conway于20世纪60年代后期提出,任意一个软件都能反映出其制作团队的组织结构,这是因为人们会以反映他们组织形式的方式工作。换句话说,分散的团队可能用分散的架构生成系统。项目团队的组织结构中的优点和弱点都将不可避免地反映在他们生成的结果系统中。
http://butunclebob.com/ArticleS.UncleBob.PrinciplesOfOod
The next six principles are about packages. In this context a package is a binary deliverable like a .jar file, or a dll as opposed to a namespace like a java package or a C++ namespace.
The first three package principles are about package cohesion, they tell us what to put inside packages:
| REP | The Release Reuse Equivalency Principle发布/重用等价原则 | The granule of reuse is the granule of release. 创建一个包是为了方便别人重用。 |
|---|---|---|
| CCP | The Common Closure Principle 公共闭合原则 | Classes that change together are packaged together. 按预期的修改将类分组,使因为同一原因而被修改的类被放在同一个包中。参照:SRP原则。 |
| CRP | The Common Reuse Principle 公共重用原则 | Classes that are used together are packaged together. 尽可能将被一个客户使用的包和被多个客户使用的包分开。参照:ISP原则。 |
The last three principles are about the couplings between packages, and talk about metrics that evaluate the package structure of a system.
| ADP | The Acyclic Dependencies Principle 非循环依赖原则 | The dependency graph of packages must have no cycles. 包与包之间不要循环依赖,可以使用JDepend工具处理. |
|---|---|---|
| SDP | The Stable Dependencies Principle 稳定依赖原则 | Depend in the direction of stability 包不能依赖于不稳定的包. |
| SAP | The Stable Abstractions Principle 稳定抽象原则 | Abstractness increases with stability. 稳定的包应该是抽象的.保证稳定的包易于被控制。 |
第7章 SRP:单一职责原则
很多程序员根据SRP这个名字想当然地认为这个原则就是指:每个模块都应该只做一件事。但这只是一个面向底层实现细节的设计原则,并不是SRP的全部
在历史上,我们曾经这样描述SRP这一设计原则:任何一个软件模块都应该有且仅有一个被修改的原因。
在现实环境中,软件系统为了满足用户和所有者的要求,必然要经常做出这样那样的修改。而该系统的用户或者所有者就是该设计原则中所指的“被修改的原因”。我们也可以这样描述SRP:任何一个软件模块都应该只对一个用户(User)或系统利益相关者(Stakeholder)负责。
不过,这里的“用户”和“系统利益相关者”在用词上也并不完全准确,它们很有可能指的是一个或多个用户和利益相关者,只要这些人希望对系统进行的变更是相似的,就可以归为一类——一个或多个有共同需求的人。在这里,我们将其称为行为者(actor)。所以,对于SRP的最终描述就变成了:任何一个软件模块都应该只对某一类行为者负责。
反面案例1:重复的假象
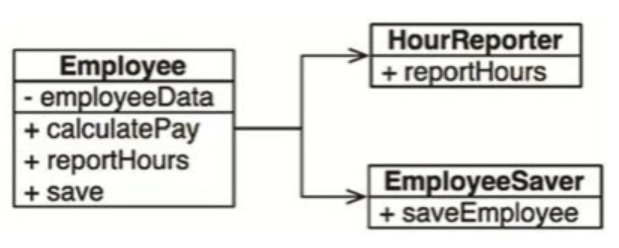
这是我最喜欢举的一个例子:某个工资管理程序中的Employee类有三个函数calculatePay()、reportHours()和save()(见图7.1)。
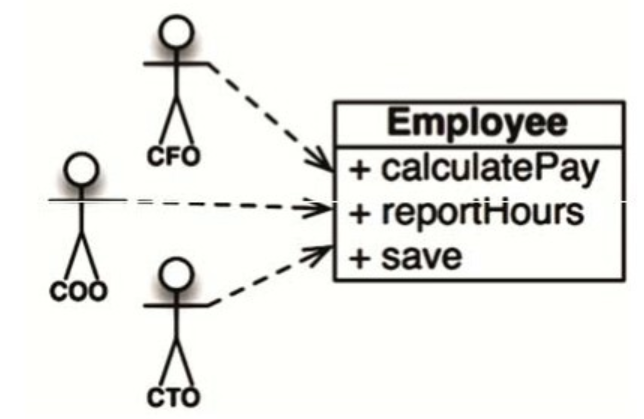
如你所见,这个类的三个函数分别对应的是三类非常不同的行为者,违反了SRP设计原则。
- calculatePay()函数是由财务部门制定的,他们负责向CFO汇报。
- reportHours()函数是由人力资源部门制定并使用的,他们负责向COO汇报。
- save()函数是由DBA制定的,他们负责向CTO汇报。
这三个函数被放在同一个源代码文件,即同一个Employee类中,程序员这样做实际上就等于使三类行为者的行为耦合在了一起,这有可能会导致CFO团队的命令影响到COO团队所依赖的功能。
例如,calculatePay()函数和reportHours()函数使用同样的逻辑来计算正常工作时数。程序员为了避免重复编码,通常会将该算法单独实现为一个名为regularHours()的函数(见图7.2)。接下来,假设CFO团队需要修改正常工作时数的计算方法,而COO带领的HR团队不需要这个修改,因为他们对数据的用法是不同的。
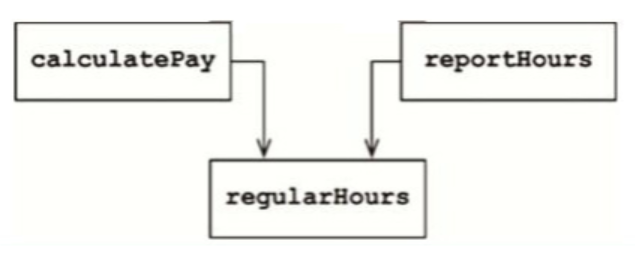
与此类似的事情我们肯定多多少少都经历过。这类问题发生的根源就是因为我们将不同行为者所依赖的代码强凑到了一起。对此,SRP强调这类代码一定要被分开。
反面案例2:代码合并
一个拥有很多函数的源代码文件必然会经历很多次代码合并,该文件中的这些函数分别服务不同行为者的情况就更常见了。
例如,CTO团队的DBA决定要对Employee数据库表结构进行简单修改。与此同时,COO团队的HR需要修改工作时数报表的格式。
解决方案
最简单直接的办法是将数据与函数分离,设计三个类共同使用一个不包括函数的、十分简单的EmployeeData类(见图7.3),每个类只包含与之相关的函数代码,互相不可见,这样就不存在互相依赖的情况了。
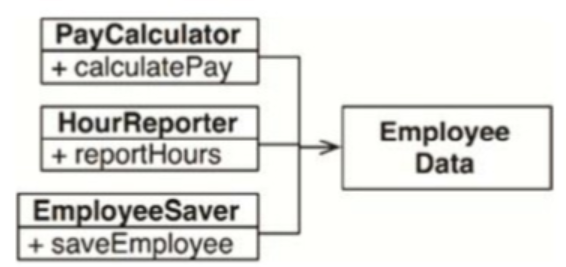
这种解决方案的坏处在于:程序员现在需要在程序里处理三个类。另一种解决办法是使用Facade设计模式(见图7.4)。
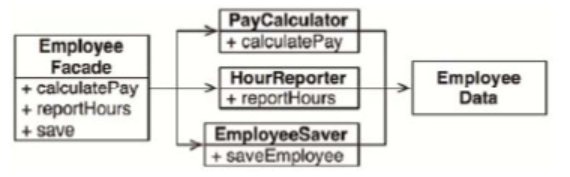
这样一来,EmployeeFacade类所需要的代码量就很少了,它仅仅包含了初始化和调用三个具体实现类的函数。
当然,也有些程序员更倾向于把最重要的业务逻辑与数据放在一起,那么我们也可以选择将最重要的函数保留在Employee类中,同时用这个类来调用其他没那么重要的函数(见图7.5)。
单一职责原则主要讨论的是函数和类之间的关系——但是它在两个讨论层面上会以不同的形式出现。在组件层面,我们可以将其称为共同闭包原则(Common Closure Principle),在软件架构层面,它则是用于奠定架构边界的变更轴心(Axis of Change)。我们在接下来的章节中会深入学习这些原则。
第8章 OCP:开闭原则
设计良好的计算机软件应该易于扩展,同时抗拒修改。
思想实验
假设我们现在要设计一个在Web页面上展示财务数据的系统,页面上的数据要可以滚动显示,其中负值应显示为红色。接下来,该系统的所有者又要求同样的数据需要形成一个报表,该报表要能用黑白打印机打印,并且其报表格式要得到合理分页,每页都要包含页头、页尾及栏目名。同时,负值应该以括号表示。
一个好的软件架构设计师会努力将旧代码的修改需求量降至最小,甚至为0。
但该如何实现这一点呢?我们可以先将满足不同需求的代码分组(即SRP),然后再来调整这些分组之间的依赖关系(即DIP)。
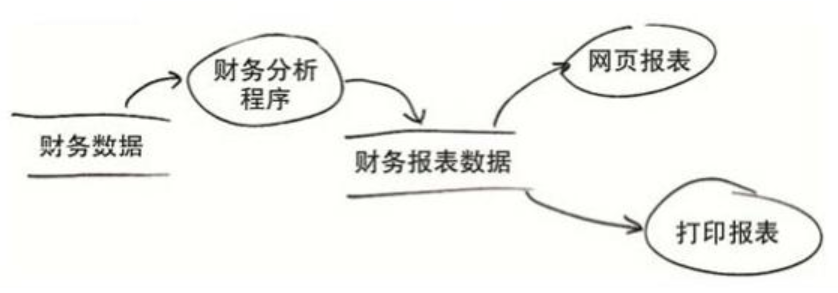
利用SRP,我们可以按图8.1中所展示的方式来处理数据流。即先用一段分析程序处理原始的财务数据,以形成报表的数据结构,最后再用两个不同的报表生成器来产生报表。
在具体实现上,我们会将整个程序进程划分成一系列的类,然后再将这些类分割成不同的组件。下面,我们用图8.2中的那些双线框来具体描述一下整个实现。在这个图中,左上角的组件是Controller,右上角是Interactor,右下角是Database,左下角则有四个组件分别用于代表不同的Presenter和View。
在图8.2中,用<I>标记的类代表接口,用<DS>标记的则代表数据结构;开放箭头指代的是使用关系,闭合箭头则指代了实现与继承关系。
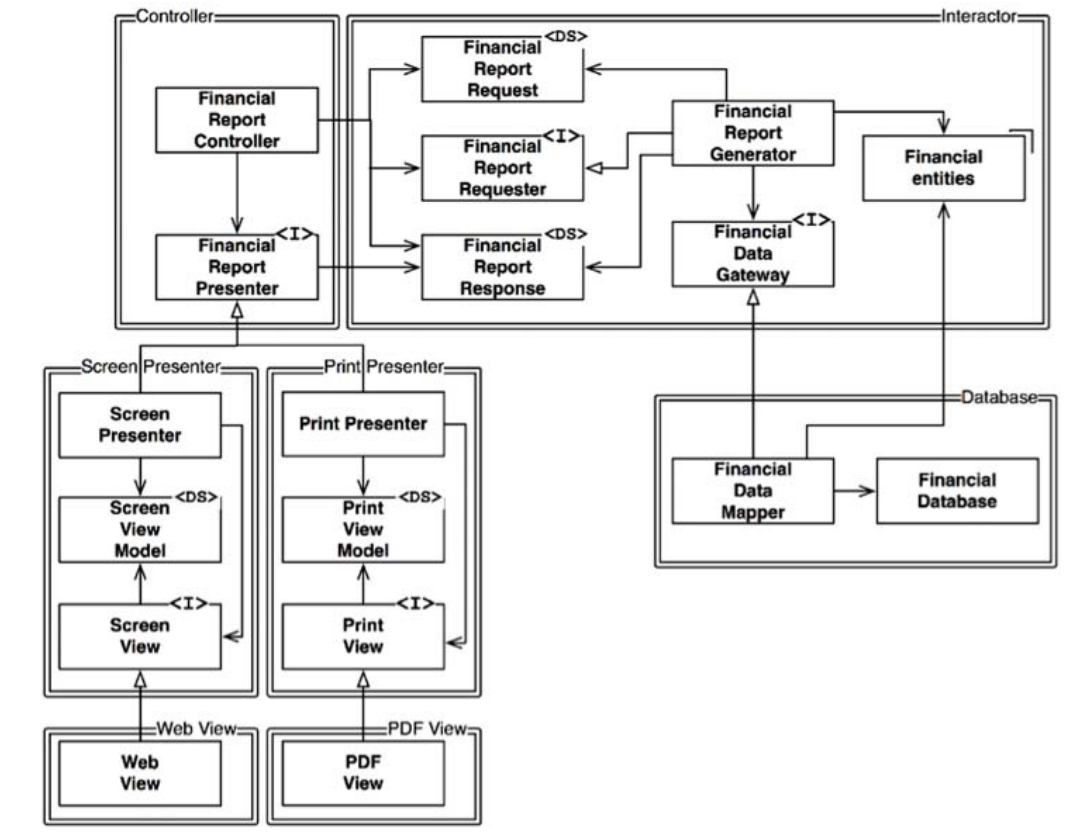
首先,我们在图8.2中看到的所有依赖关系都是其源代码中存在的依赖关系。这里,从类A指向类B的箭头意味着A的源代码中涉及了B,但是B的源代码中并不涉及A。因此在图8.2中,FinancialDataMapper在实现接口时需要知道FinancialDataGateway的实现,而FinancialDataGateway则完全不必知道FinancialDataMapper的实现。
其次,这里很重要的一点是这些双线框的边界都是单向跨越的。也就是说,上图中所有组件之间的关系都是单向依赖的,如图8.3所示,图中的**箭头都指向那些我们不想经常更改的组件**。
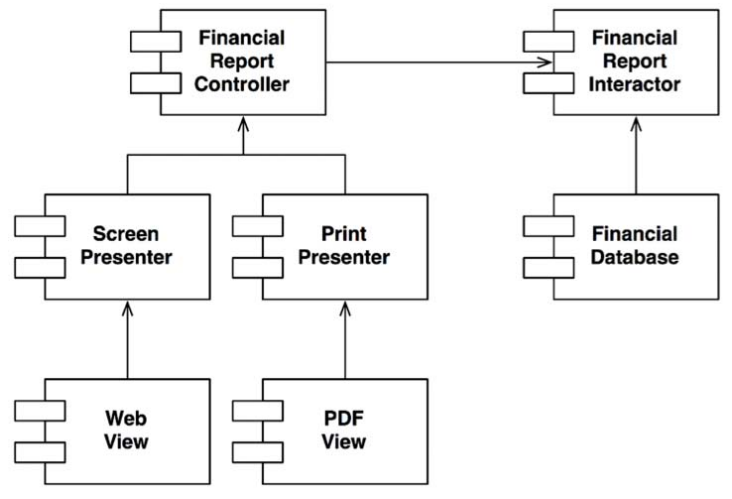
让我们再来复述一下这里的设计原则:如果A组件不想被B组件上发生的修改所影响,那么就应该让B组件依赖于A组件。
所以现在的情况是,我们不想让发生在Presenter上的修改影响到Controller,也不想让发生在View上的修改影响到Presenter。而最关键的是,我们不想让任何修改影响到Interactor。
其中,Interactor组件是整个系统中最符合OCP的。发生在Database、Controller、Presenter甚至View上的修改都不会影响到Interactor。
为什么Interactor会被放在这么重要的位置上呢?因为它是该程序的业务逻辑所在之处,Interactor中包含了其最高层次的应用策略。其他组件都只是负责处理周边的辅助逻辑,只有Interactor才是核心组件。
另外需要注意的是,这里利用“层级”这个概念创造了一系列不同的保护层级。譬如,Interactor是最高层的抽象,所以它被保护得最严密,而Presenter比View的层级高,但比Controller和Interactor的层级低。
依赖方向的控制
你刚刚在图表中所看到的复杂度是我们想要对组件之间的依赖方向进行控制而产生的。
例如,FinancialReportGenerator和FinancialDataMapper之间的FinancialDataGateway接口是为了反转Interactor与Database之间的依赖关系而产生的。同样的,FinancialReportPresenter接口与两个View接口之间也类似于这种情况。
信息隐藏
当然,FinancialReportRequester接口的作用则完全不同,它的作用是保护FinancialReportController不过度依赖于Interactor的内部细节。如果没有这个接口,则Controller将会传递性地依赖于FinancialEntities。
这种传递性依赖违反了“软件系统不应该依赖其不直接使用的组件”这一基本原则。之后,我们会在讨论接口隔离原则和共同复用原则的时候再次提到这一点。
所以,虽然我们的首要目的是为了让Interactor屏蔽掉发生在Controller上的修改,但也需要通过隐藏Interactor内部细节的方法来让其屏蔽掉来自Controller的依赖。
第9章 LSP:里氏替换原则
1988年,Barbara Liskov在描述如何定义子类型时写下了这样一段话:这里需要的是一种可替换性:如果对于每个类型是S的对象o1都存在一个类型为T的对象o2,能使操作T类型的程序P在用o2替换o1时行为保持不变,我们就可以将S称为T的子类型。[4]
继承的使用指导
假设我们有一个License类,其结构如图9.1所示。该类中有一个名为calcFee()的方法,该方法将由Billing应用程序来调用。而License类有两个“子类型”:PersonalLicense与BusinessLicense,这两个类会用不同的算法来计算授权费用。
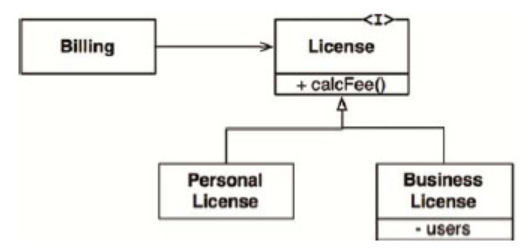
上述设计是符合LSP原则的,因为Billing应用程序的行为并不依赖于其使用的任何一个衍生类。也就是说,这两个衍生类的对象都是可以用来替换License类对象的。
正方形/长方形问题
正方形/长方形问题是一个著名(或者说臭名远扬)的违反LSP的设计案例(该问题的结构如图9.2所示)。
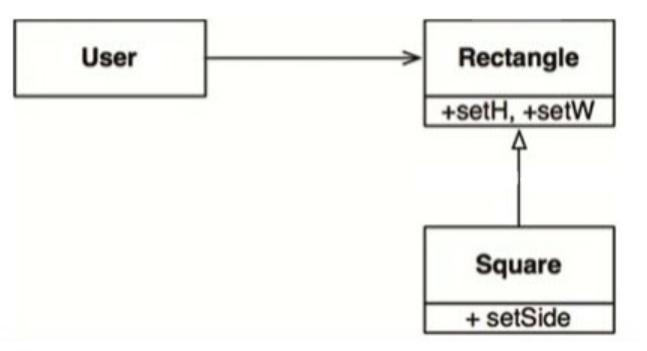
在这个案例中,Square类并不是Rectangle类的子类型,因为Rectangle类的高和宽可以分别修改,而Square类的高和宽则必须一同修改。由于User类始终认为自己在操作Rectangle类,因此会带来一些混淆。
如果想要防范这种违反LSP的行为,唯一的办法就是在User类中增加用于区分Rectangle和Square的检测逻辑(例如增加if语句)。但这样一来,User类的行为又将依赖于它所使用的类,这两个类就不能互相替换了。
LSP与软件架构
随着时间的推移,LSP逐渐演变成了一种更广泛的、指导接口与其实现方式的设计原则。
第10章 ISP:接口隔离原则
“接口隔离原则(ISP)”这个名字来自图10.1所示的这种软件结构。
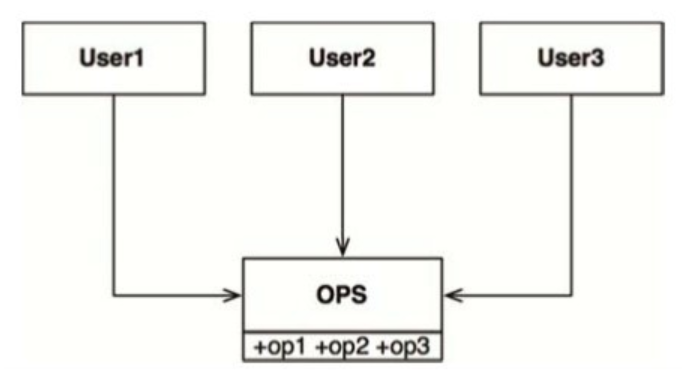
在图10.1所描绘的应用中,有多个用户需要操作OPS类。现在,我们假设这里的User1只需要使用op1,User2只需要使用op2,User3只需要使用op3。
在这种情况下,如果OPS类是用Java编程语言编写的,那么很明显,User1虽然不需要调用op2、op3,但在源代码层次上也与它们形成依赖关系。这种依赖意味着我们对OPS代码中op2所做的任何修改,即使不会影响到User1的功能,也会导致它需要被重新编译和部署。
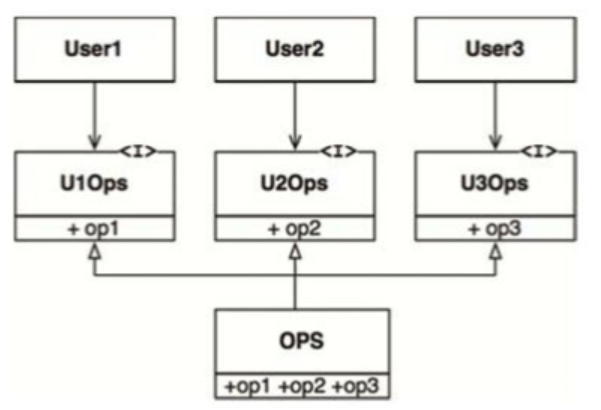
这个问题可以通过将不同的操作隔离成接口来解决,具体如图10.2所示。
ISP与编程语言
对于Java这样的静态类型语言来说,它们需要程序员显式地import、use或者include其实现功能所需要的源代码。而正是这些语句带来了源代码之间的依赖关系,这也就导致了某些模块需要被重新编译和重新部署。
而对于Ruby和Python这样的动态类型语言来说,源代码中就不存在这样的声明,它们所用对象的类型会在运行时被推演出来,所以也就不存在强制重新编译和重新部署的必要性。这就是动态类型语言要比静态类型语言更灵活、耦合度更松的原因。
ISP与软件架构
回顾一下ISP最初的成因:在一般情况下,任何层次的软件设计如果依赖于不需要的东西,都会是有害的。从源代码层次来说,这样的依赖关系会导致不必要的重新编译和重新部署,对更高层次的软件架构设计来说,问题也是类似的。
例如,我们假设某位软件架构师在设计系统S时,想要在该系统中引入某个框架F。这时候,假设框架F的作者又将其捆绑在一个特定的数据库D上,那么就形成了S依赖于F,F又依赖于D的关系(参见图10.3)。

在这种情况下,如果D中包含了F不需要的功能,那么这些功能同样也会是S不需要的。而我们对D中这些功能的修改将会导致F需要被重新部署,后者又会导致S的重新部署。更糟糕的是,D中一个无关功能的错误也可能会导致F和S运行出错。
第11章 DIP:依赖反转原则
依赖反转原则(DIP)主要想告诉我们的是,如果想要设计一个灵活的系统,在源代码层次的依赖关系中就应该多引用抽象类型,而非具体实现。
也就是说,在Java这类静态类型的编程语言中,在使用use、import、include这些语句时应该只引用那些包含接口、抽象类或者其他抽象类型声明的源文件,不应该引用任何具体实现。
我们主要应该关注的是软件系统内部那些会经常变动的(volatile)具体实现模块,这些模块是不停开发的,也就会经常出现变更。
稳定的抽象层
| 应在代码中多使用抽象接口,尽量避免使用那些多变的具体实现类 | 这条守则适用于所有编程语言,无论静态类型语言还是动态类型语言。同时,对象的创建过程也应该受到严格限制,对此,我们通常会选择用抽象工厂(abstract factory)这个设计模式。 |
|---|---|
| 不要在具体实现类上创建衍生类 | 在静态类型的编程语言中,继承关系是所有一切源代码依赖关系中最强的、最难被修改的,所以我们对继承的使用应该格外小心。 |
| 不要覆盖(override)包含具体实现的函数 | 调用包含具体实现的函数通常就意味着引入了源代码级别的依赖。即使覆盖了这些函数,我们也无法消除这其中的依赖——这些函数继承了那些依赖关系。在这里,控制依赖关系的唯一办法,就是创建一个抽象函数,然后再为该函数提供多种具体实现。 |
| 应避免在代码中写入与任何具体实现相关的名字,或者是其他容易变动的事物的名字 | 这基本上是DIP原则的另外一个表达方式。 |
工厂模式
如果想要遵守上述编码守则,我们就必须要对那些易变对象的创建过程做一些特殊处理,这样的谨慎是很有必要的,因为基本在所有的编程语言中,创建对象的操作都免不了需要在源代码层次上依赖对象的具体实现。
在大部分面向对象编程语言中,人们都会选择用抽象工厂模式来解决这个源代码依赖的问题。
下面,我们通过图11.1来描述一下该设计模式的结构。如你所见,Application类是通过Service接口来使用ConcreteImpl类的。然而,Application类还是必须要构造ConcreteImpl类实例。于是,为了避免在源代码层次上引入对ConcreteImpl 类具体实现的依赖,我们现在让 Application 类去调用ServiceFactory接口的makeSvc方法。这个方法就由ServiceFactoryImpl类来具体提供,它是ServiceFactory的一个衍生类。该方法的具体实现就是初始化一个ConcreteImpl类的实例,并且将其以Service类型返回。
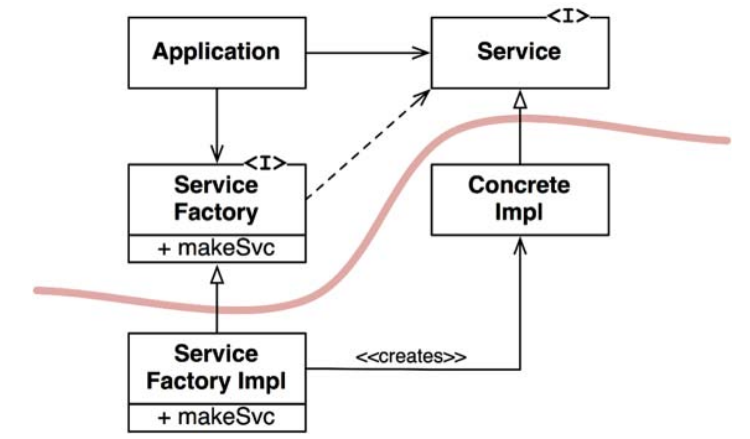
图11.1中间的那条曲线代表了软件架构中的抽象层与具体实现层的边界。在这里,所有跨越这条边界源代码级别的依赖关系都应该是单向的,即具体实现层依赖抽象层。
这条曲线将整个系统划分为两部分组件:抽象接口与其具体实现。抽象接口组件中包含了应用的所有高阶业务规则,而具体实现组件中则包括了所有这些业务规则所需要做的具体操作及其相关的细节信息。
请注意,这里的控制流跨越架构边界的方向与源代码依赖关系跨越该边界的方向正好相反,源代码依赖方向永远是控制流方向的反转——这就是DIP被称为依赖反转原则的原因。
具体实现组件
在图11.1中,具体实现组件的内部仅有一条依赖关系,这条关系其实是违反DIP的。这种情况很常见,我们在软件系统中并不可能完全消除违反DIP的情况。通常只需要把它们集中于少部分的具体实现组件中,将其与系统的其他部分隔离即可。
绝大部分系统中都至少存在一个具体实现组件——我们一般称之为main组件,因为它们通常是main函数[5](这里指代的是操作系统用来启动应用程序的那个函数。)
所在之处。在图11.1中,main函数应该负责创建ServiceFactoryImpl实例,并将其赋值给类型为ServiceFactory的全局变量,以便让Application类通过这个全局变量来进行相关调用。