联邦学习中的异质性问题
联邦学习中的异质性问题
- 数据异构性(Data heterogeneity)
- 分布偏移(Distribution Skew)
- 标签偏移(Label Skew)
- 特征偏移(Feature Skew)
- 质量偏移(Quality Skew)
- 数量偏移(Quantity Skew)
- 模型异构性(Model heterogeneity)
- 模型结构异质性(Model Structure Heterogeneity)
- 优化器异质性(Optimizer Heterogeneity)
- 任务异构性(Task heterogeneity)
- 标签空间异质性(Heterogeneous Class Labels)
- 任务类型异质性(Heterogeneous Task Types)
- 目标函数异质性(Heterogeneous Objectives)
- 通信异构性(Communication heterogeneity)
- 设备异构性(Device heterogeneity)
本文参考文章链接: Advances in Robust Federated Learning: A Survey With Heterogeneity Considerations
在人工智能飞速发展的今天,我们正站在一个前所未有的数据洪流时代。边缘设备每日产生海量数据,蕴藏着改变世界的智能潜力,但同时也面临着隐私保护与数据孤岛的双重挑战。联邦学习(Federated Learning, FL)作为一种颠覆性的分布式机器学习范式,应运而生,其核心思想——“数据不动模型动”——让我们看到了在保护隐私的前提下协同挖掘数据价值的曙光。
然而,当我们从理想的实验室环境走向复杂的现实世界时,一个根本性的挑战赫然显现:异质性(Heterogeneity)。正如谷歌团队在2016年提出联邦学习概念时未曾充分预料的那样,现实世界中的联邦学习系统远非实验室中假设的"理想统一"状态,而是充满了各种形式的"现实多元性"。
本文提出五维异质性分类框架:将联邦学习中的异质性系统性地归纳为数据、模型、任务、通信、设备五个层面,建立了统一的分析框架。
数据异构性(Data heterogeneity)
数据异质性,也称为非独立同分布(Non-IID)数据问题,是指联邦学习系统中各个客户端设备持有的本地数据在统计特性上存在显著差异。这种差异不是随机的,而是系统性的,从根本上挑战了传统机器学习中的IID假设。
核心数学表达:
对于任意两个客户端 i和 j,其数据分布满足:

其中 Pi(x,y)是客户端 i的数据联合分布,x是特征,y是标签。
本文将数据异质性细分为五种基本类型
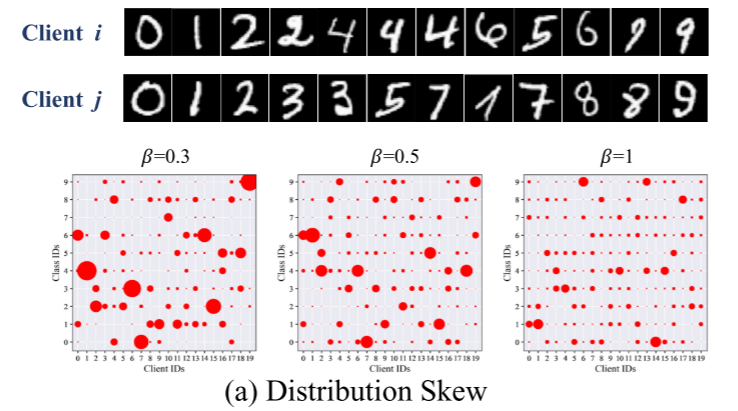
分布偏移(Distribution Skew)
-
定义:不同客户端的数据在特征-标签的联合分布 P(x,y)上存在差异。这是最广义和最复杂的Non-IID情况。
-
数学描述:

-
MNIST示例:
假设有10个客户端,每个客户端只包含两个数字类别的特定组合,且每个类别内的样本具有特定风格特征:客户端1:只包含数字"0"和"1",且所有"0"都是细体字,"1"都是粗体字客户端2:只包含数字"0"和"1",但所有"0"都是粗体字,"1"都是细体字客户端3:只包含数字"2"和"3",且"2"都是倾斜的,"3"都是直立的...以此类推 -
影响:这是最具挑战性的情况,因为特征和标签的联合分布完全不同,导致严重的客户端漂移问题。
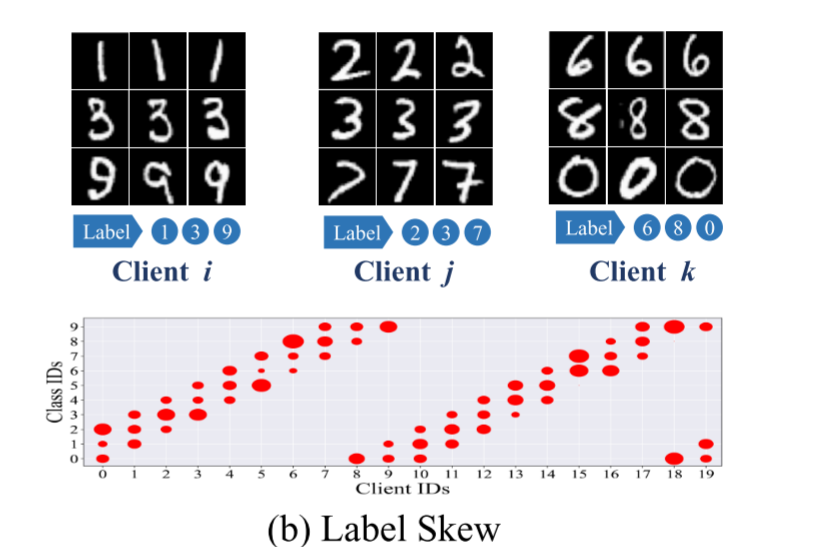
标签偏移(Label Skew)
-
定义:客户端间标签的边际分布 P(y)不同,但给定标签后的特征分布 P(x∣y)相似。
-
数学描述:

-
MNIST示例:
客户端1:包含所有10个数字,但80%是数字"0"和"1",其他数字各占2.5%客户端2:包含所有10个数字,但80%是数字"2"和"3",其他数字各占2.5%客户端3:包含所有10个数字,但80%是数字"8"和"9",其他数字各占2.5%
特征偏移(Feature Skew)
-
定义:客户端间特征的边际分布 P(x)不同,但标签与特征的关系 P(y∣x)相似。
-
数学描述:

-
MNIST示例:
客户端1:所有数字图像都是白底黑字(正常MNIST)客户端2:所有数字图像都是黑底白字(颜色反转)客户端3:所有数字图像都添加了高斯噪声客户端4:所有数字图像都进行了模糊处理

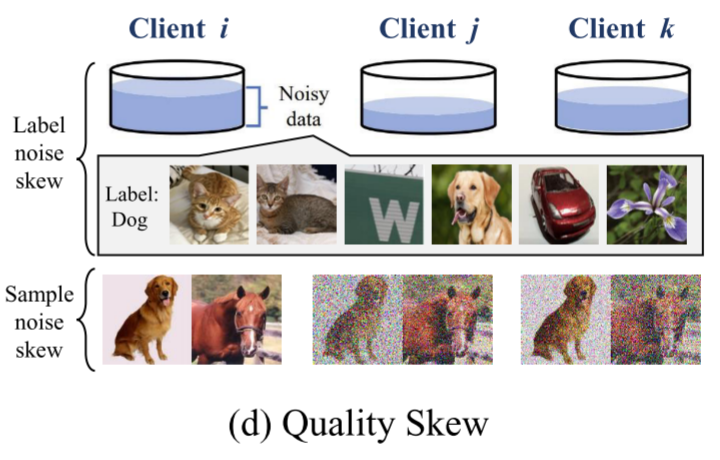
质量偏移(Quality Skew)
-
定义:客户端数据的质量和可靠性存在差异,涉及数据可信度和准确性问题。
-
数学描述:难以用传统概率分布描述,主要体现在数据标注质量和信号质量上。
-
MNIST示例:
客户端1:精确标注的数字图像,由专业标注人员完成客户端2:噪声标注的数字图像,20%的标签被随机错误标注客户端3:低分辨率数字图像,图像被下采样后再上采样客户端4:遮挡数字图像,每个数字都有部分区域被随机遮挡
数量偏移(Quantity Skew)
-
定义:客户端持有的数据量存在巨大差异。
-
数学描述:

-
MNIST示例:
客户端1:拥有10,000个训练样本(大型机构)客户端2:拥有5,000个训练样本(中型机构)客户端3:拥有1,000个训练样本(小型机构)客户端4:只有100个训练样本(个人用户)

模型异构性(Model heterogeneity)
模型异质性是指参与联邦学习的各个客户端使用的模型结构或优化器不同。这与传统联邦学习(如FedAvg)中"所有客户端使用相同模型"的假设根本不同,是迈向现实应用的关键一步。
核心挑战:如何协调和聚合不同架构的模型更新?传统的参数平均法(如FedAvg)要求模型结构完全一致,当模型结构不同时,直接平均参数在数学上和物理上都是不可能的。
模型结构异质性(Model Structure Heterogeneity)
- 这是最显著的模型异质性形式,指客户端间使用的模型架构、层数、参数数量等存在差异。
- 简单CNN示例:
假设一个手写数字识别(MNIST)任务,三个客户端因计算资源不同选择了不同的CNN结构:
客户端A(强大服务器):使用复杂CNN
结构:Input -> Conv32 -> Conv64 -> FC128 -> FC10
参数量:~250,000
客户端B(普通笔记本电脑):使用中等CNN
结构:Input -> Conv32 -> FC64 -> FC10
参数量:~80,000
客户端C(移动手机):使用轻量CNN
结构:Input -> Conv16 -> FC32 -> FC10
参数量:~20,000
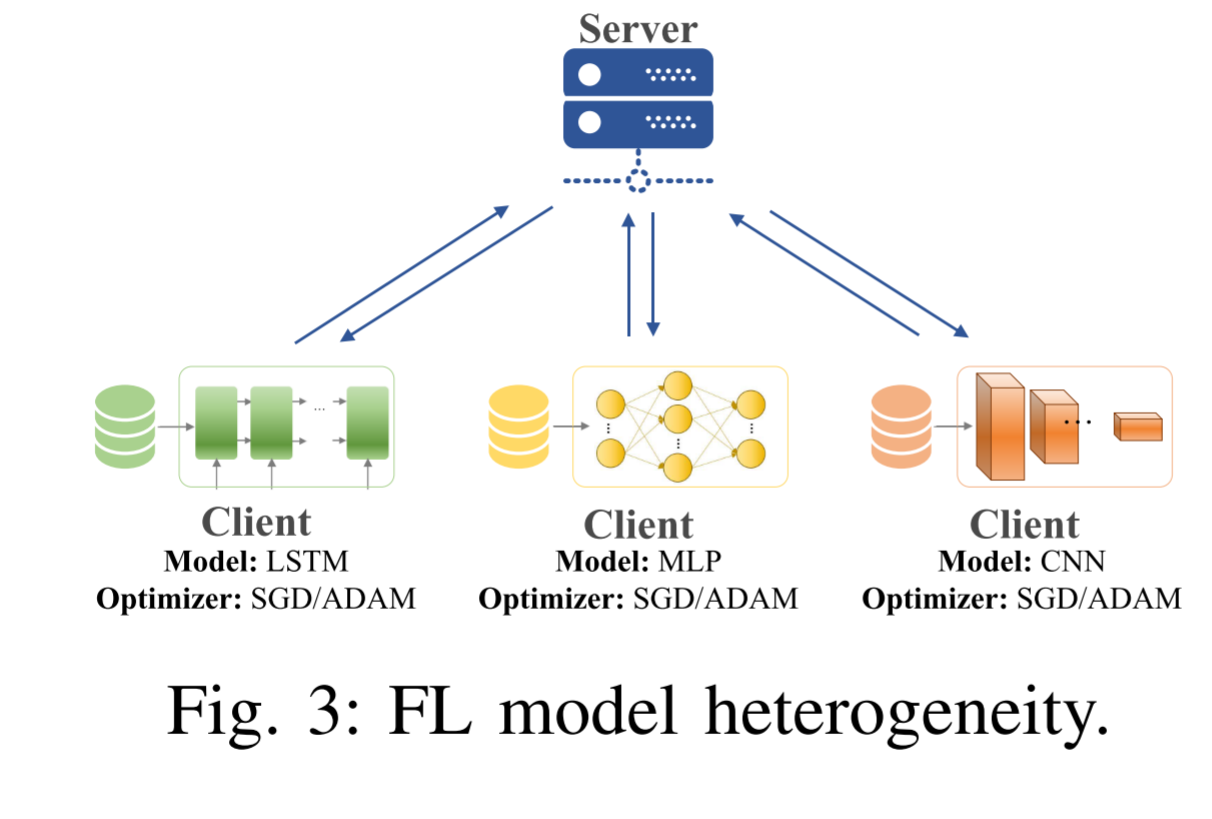
优化器异质性(Optimizer Heterogeneity)
-
指客户端使用不同的优化算法、学习率或其他超参数进行本地训练。
-
继续CNN示例:
即使使用相同的CNN架构,客户端也可能选择不同的优化策略:客户端A:使用Adam优化器,学习率0.001客户端B:使用SGD with Momentum,学习率0.01客户端C:使用RMSprop,学习率0.005 -
影响:不同的优化器会产生不同的梯度更新方向和幅度,即使对于相同的模型结构和数据,也会导致客户端模型以不同的方式收敛,增加聚合的复杂性。
任务异构性(Task heterogeneity)
任务异质性是指参与联邦学习的各个客户端需要解决的学习任务不同。这与传统联邦学习中"所有客户端共同优化单一全局目标"的假设根本不同,是联邦学习走向实用化的关键挑战。
核心挑战:如何在一个联邦框架内同时支持多个相关但不相同的任务,既能实现知识共享,又能满足个性化需求?
数学表达:
对于客户端 i和 j,其学习目标函数不同

其中 Li是客户端 i的损失函数,θ是模型参数。
根据论文中的分类,任务异质性主要表现为以下三种形式:
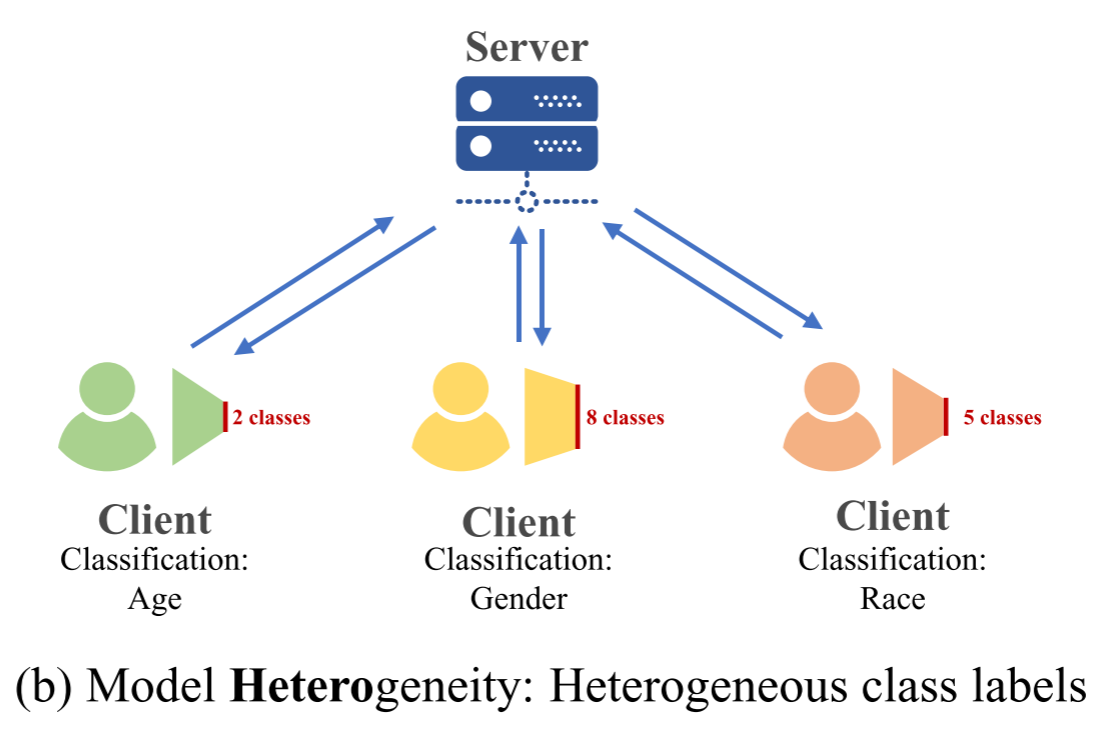
标签空间异质性(Heterogeneous Class Labels)
-
定义:客户端拥有相同类型的输入数据,但需要预测的类别集合不同。
-
CIFAR-10示例:
-
假设三个客户端都使用CIFAR-10图像数据,但关注不同的类别子集:
客户端1(动物识别):只识别"猫、狗、鸟、马"4类客户端2(交通工具识别):只识别"飞机、汽车、船、卡车"4类客户端3(混合识别):识别"猫、鸟、汽车、卡车"4类
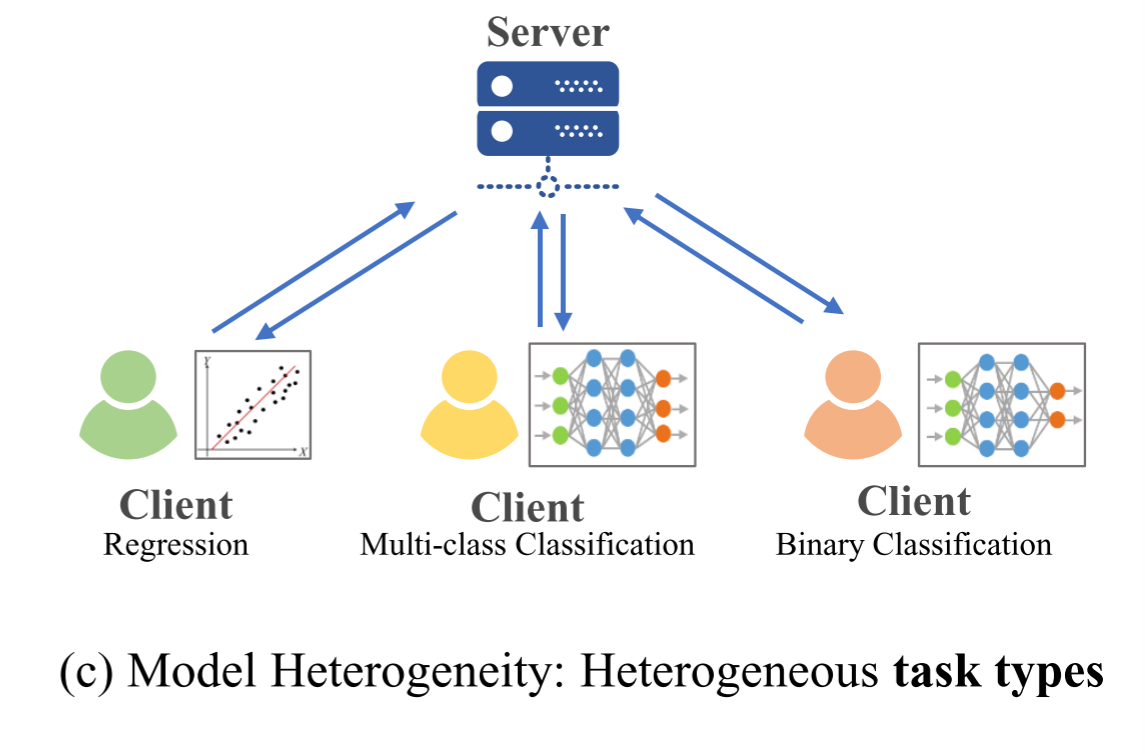
任务类型异质性(Heterogeneous Task Types)
-
定义:客户端需要解决完全不同类型的学习任务。
-
MNIST和CIFAR-10混合示例:
客户端1:MNIST手写数字分类(10分类问题)客户端2:CIFAR-10图像分类(10分类问题)客户端3:图像生成任务(如生成手写数字)
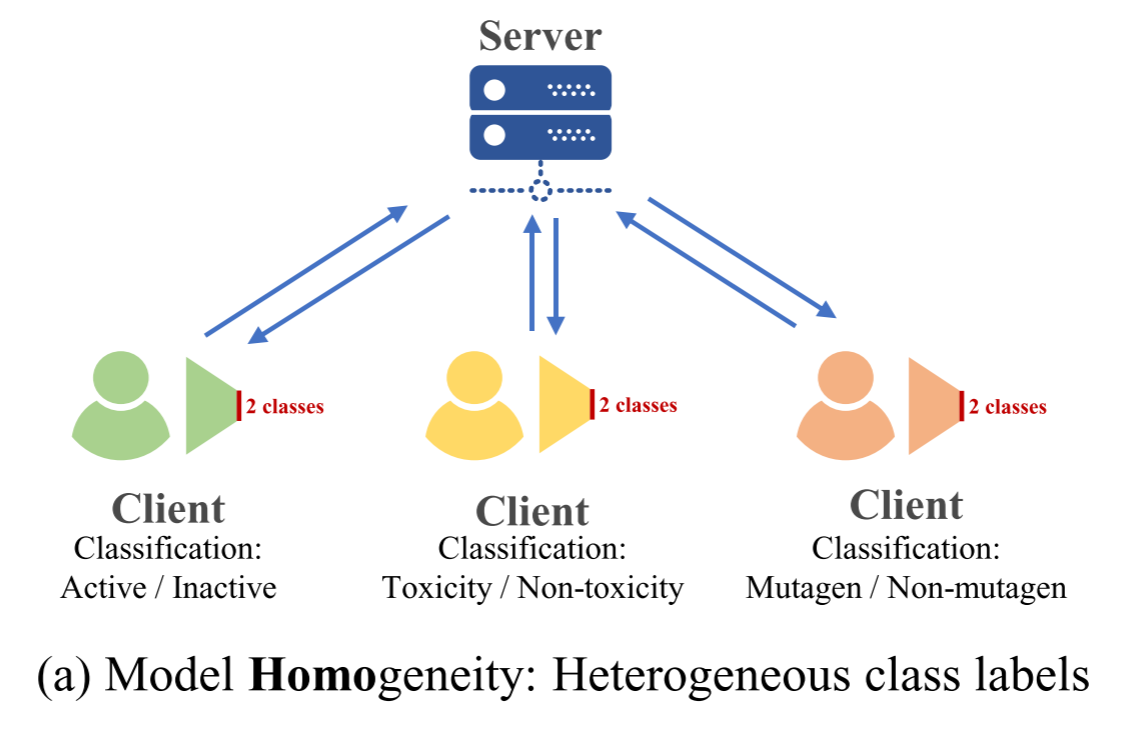
目标函数异质性(Heterogeneous Objectives)
-
定义:客户端处理相似数据,但优化目标不同。
-
医疗影像示例:
-
假设三个医院都有胸部X光片数据:
医院1:肺炎检测(二分类:肺炎/正常)医院2:疾病严重程度分级(多分类:轻度/中度/重度)医院3:肺部分割(像素级分割任务)
通信异构性(Communication heterogeneity)
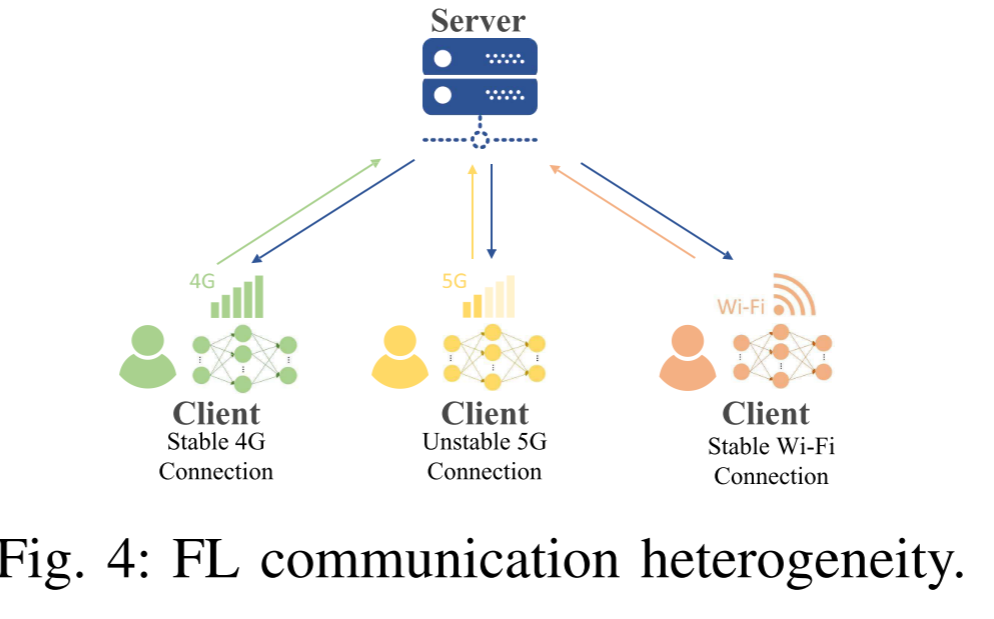
通信异质性是指参与联邦学习的各个客户端设备在网络连接能力上存在显著差异。这种差异不是偶然的,而是由设备所处的物理环境、网络基础设施和资源约束所系统性导致的。它直接挑战了传统联邦学习中“所有客户端具有稳定、高速且对称的网络连接”的理想化假设。
核心挑战:如何在一个网络能力分布极不均匀的系统中,协调大量设备的模型更新,确保学习过程的高效和稳定,同时避免系统被最慢或最不稳定的设备拖累?
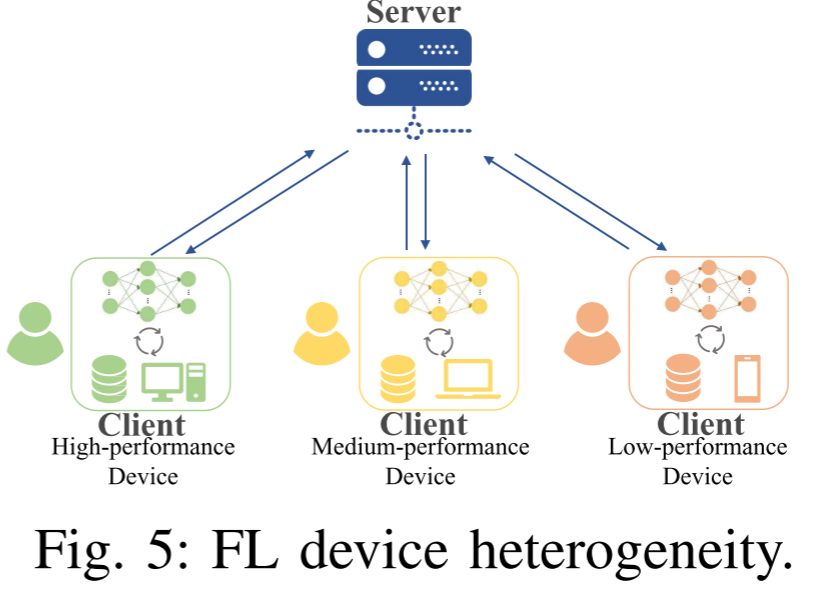
设备异构性(Device heterogeneity)
设备异质性是指参与联邦学习的各个客户端设备在硬件配置、计算能力、存储容量和能源供应等方面存在显著差异。这种差异源于设备类型、型号、使用年限和使用场景的多样性,是联邦学习在真实边缘计算环境中部署时面临的基础性挑战。
核心挑战:如何在一个计算能力分布极不均匀的系统中,协调从强大服务器到受限物联网设备的各类设备协同完成模型训练任务,同时保证效率、公平性和模型质量?