计算机软件工程毕设项目——基于协同过滤算法的电影推荐系统(Python-Django-Vue-Mysql,基于用户的协同过滤余弦相似度计算推荐,B/S 架构)
基于协同过滤算法的电影推荐系统
前言介绍
1.1 研究背景
在数字化时代大背景之下,互联网技术呈现出快速发展的态势,促使海量信息数据出现爆炸式的增长,这样一来,用户在内容消费的过程当中,普遍遭遇到信息过载带来的困扰,而这种现象在个性化推荐系统领域表现得较为突出,电影内容作为大众娱乐消费的核心载体,在各类在线平台里占据着关键的推荐位置。基于此,怎样构建精准的电影推荐算法体系,已然成为当前学术界以及工业界共同关注的关键研究课题。
在电影推荐领域,随着推荐技术不断发展与优化,协同过滤算法已成为极具代表性的推荐算法之一,该算法依靠探寻用户群体间的相似性特征,根据用户历史评分数据预测其对未观看项目的偏好程度,有算法原理简单易懂的优势。从实现方式来讲,协同过滤算法主要分为基于用户相似性的协同过滤和基于物品相似性的协同过滤两种模式,这两种方法在实际应用场景中都呈现出良好的推荐性能。
在如今的推荐系统研究范畴当中,协同过滤算法始终占据着核心位置,这种情况在电影推荐场景里体现得颇为突出,基于协同过滤的电影推荐系统有十分突出的应用价值,还拥有广阔的学术研究空间。
1.2研究目的意义
本研究运用B/S架构开展系统开发工作,前端借助Vue框架搭建出有高度交互性的用户界面,切实提升了用户操作时的便捷程度与流畅状态,后端依据Django框架达成稳定可靠的服务支持,有力保障了系统运行效率以及数据传输性能,数据库层面选用MySQL来实现海量电影数据的存储,并借助Python强大的数据处理能力,让管理员可以对用户信息、电影分类、影片详情以及留言板等模块进行精细化管理控制。需要注意的是,系统借助协同过滤算法对用户观影记录、评分数据等行为特征展开深度剖析,精准识别用户偏好,为个体用户生成定制化的电影推荐方案,从用户体验角度来看,本系统可大幅减少用户筛选影片所消耗的时间,凭借精准匹配用户兴趣较大提高观影满意度,充分契合多元化的娱乐需求。
01开发环境
1.1、Python语言
1.2、MySQL 数据库
1.3、django 框架
1.4、B/S 架构
1.5、协同过滤算法
02系统功能亮点
亮点:协同过滤推荐算法
具体运用基于用户的协同过滤方法,借助解析用户收藏行为数据,辨别出和目标用户有着相似兴趣偏好的用户群体,再依照这些相似用户的观影历史记录为目标用户生成个性化的电影推荐列表。
协同过滤算法的核心机制是依靠量化用户之间的相似性程度达成个性化推荐,在这个过程中,余弦相似度作为经典的相似性度量办法,在该领域得到了广泛运用。
余弦相似度计算公式:
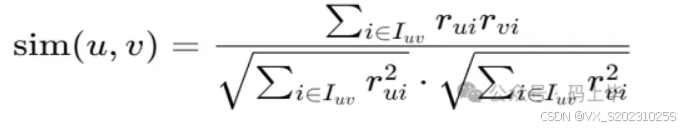
03图片展示










04 代码展示
#协同过滤推荐算法代码展示
#查找相似用户
def cosine_similarity(a, b):numerator = sum([a[key] * b[key] for key in a if key in b])denominator = math.sqrt(sum([a[key]**2 for key in a])) * math.sqrt(sum([b[key]**2 for key in b]))return numerator / denominator
#收藏协同算法
def dianyingxinxi_autoSort2(request):if request.method in ["POST", "GET"]:req_dict = request.session.get("req_dict")cursor = connection.cursor()sorted_recommended_goods=[]user_ratings={}try:cursor.execute("select * from storeup where type = 1 and tablename = 'dianyingxinxi' order by addtime desc")desc = cursor.descriptiondata_dict = [dict(zip([col[0] for col in desc], row)) for row in cursor.fetchall()]#用户-订单矩阵for item in data_dict:if user_ratings.__contains__(item["userid"]):ratings_dict = user_ratings[item["userid"]]if ratings_dict.__contains__(item["refid"]):ratings_dict[str(item["refid"])]+=1else:ratings_dict[str(item["refid"])] =1else:user_ratings[item["userid"]] = {str(item["refid"]):1}try:# 计算目标用户与其他用户的相似度similarities = {other_user: cosine_similarity(user_ratings[request.session.get("params").get("id")], user_ratings[other_user])for other_user in user_ratings if other_user != request.session.get("params").get("id")}# 找到与目标用户最相似的用户most_similar_user = sorted(similarities, key=similarities.get, reverse=True)[0]# 找到最相似但目标用户未购买过的商品recommended_goods = {goods: rating for goods, rating in user_ratings[most_similar_user].items() ifgoods not in user_ratings[request.session.get("params").get("id")]}# 按评分降序排列推荐sorted_recommended_goods = sorted(recommended_goods, key=recommended_goods.get, reverse=True)except:pass