Transformer 的革命之路
在 AI 技术迭代的浪潮中,很少有架构能像 Transformer 这样,用短短数年时间重塑整个人工智能的发展轨迹。
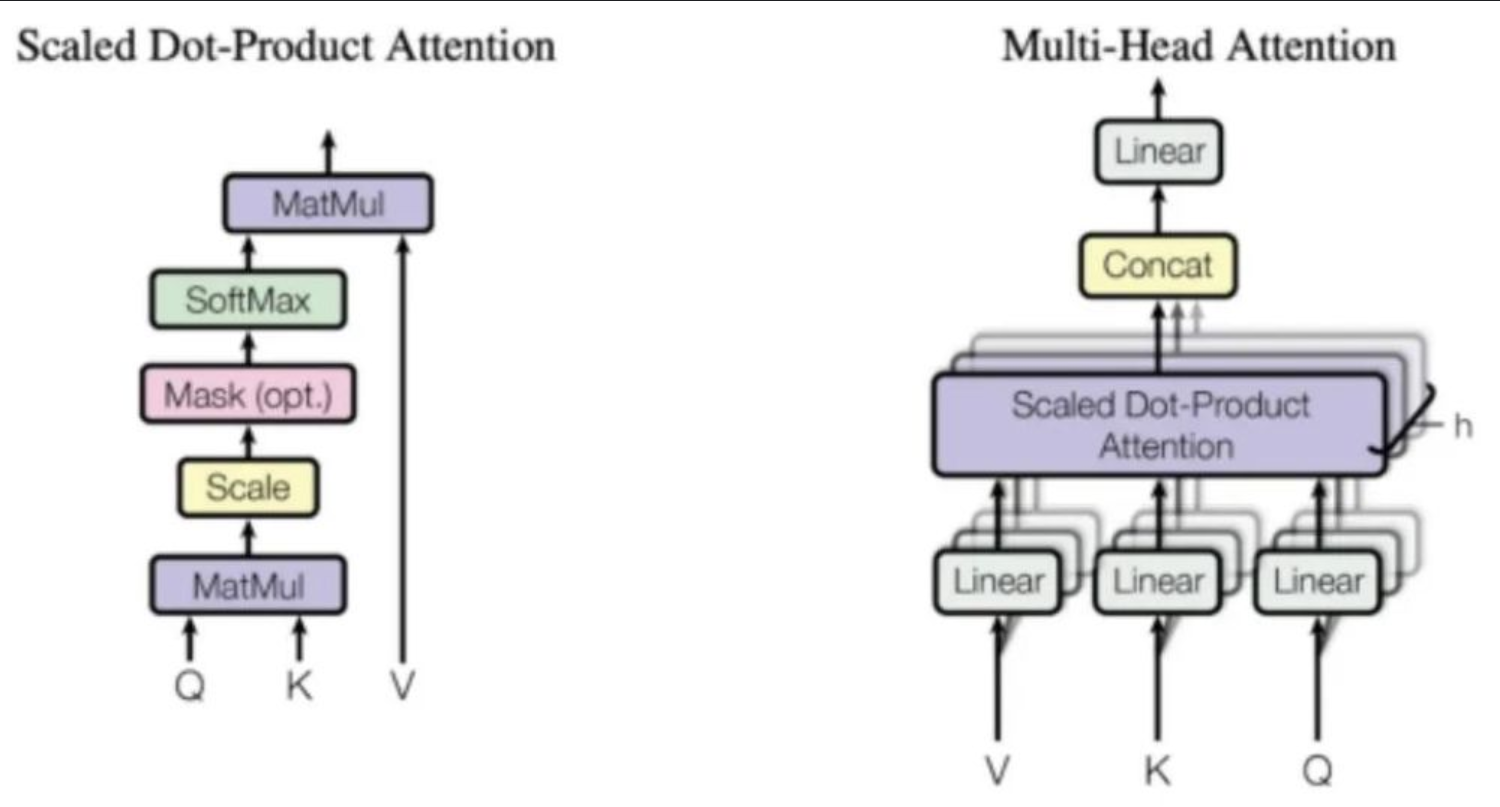
从自然语言处理的范式颠覆到跨领域的技术辐射,它的出现不仅解决了序列建模的长期痛点,更开启了通用人工智能的全新可能。要理解这场技术革命的深远意义,我们需要回溯它诞生的前夜、突破的瞬间与扩散的轨迹。
目录
- 一、前夜:RNN/LSTM 筑起的 “玻璃天花板”
- 二、破晓:2017 年的 “注意力革命”
- 三、辐射:从 NLP 到全领域的范式迁移
一、前夜:RNN/LSTM 筑起的 “玻璃天花板”
在 2017 年之前,循环神经网络(RNN)及其变体长短期记忆网络(LSTM)一直是序列数据建模的绝对主角。1990 年 SimpleRNN 的提出,首次赋予神经网络处理时序信息的能力 —— 通过隐藏层的跨时间步自连接,让模型能捕捉数据中的序列依赖关系。但这种架构天生存在致命缺陷:当序列长度增加时,沿时间反向传播(BPTT)过程中的梯度会急剧衰减或爆炸,导致模型无法记住长距离的关键信息,就像人无法回忆起数月前对话中的细节。
1997 年 Sepp Hochreiter 和 Jurgen Schmidhuber 提出的 LSTM,试图通过遗忘门、输入门和输出门的复杂门控机制打破这一局限。它引入的 “恒定误差传送带”(CEC)能让梯度更稳定地传递,在机器翻译、语音识别等任务中展现出远超 SimpleRNN 的性能,2016 年甚至成为 Google 翻译的核心引擎,支撑着 Facebook 每周 300 亿次的翻译请求。但 LSTM 的改进仍是 “修修补补”:门控机制的复杂性导致模型训练速度缓慢,且本质上仍依赖时序递进的计算模式 —— 必须等待前一个时间步处理完成才能开始下一个,完全无法利用 GPU 的并行计算能力。当面对书籍、论文等超长文本时,LSTM 依然会出现信息丢失,长距离依赖建模的精度随序列长度增加而显著下降。
此时的序列建模领域,正陷入 “精度与效率不可兼得” 的困境:想要捕捉长距离依赖,就必须接受复杂的门控结构和串行计算;想要提升速度,又会牺牲模型的记忆能力。整个 AI 界都在等待一种能打破这种平衡的全新架构。
二、破晓:2017 年的 “注意力革命”
2017 年,Google Brain 和多伦多大学的团队联合发表了一篇题为《Attention Is All You Need》的论文,如同惊雷划破技术迷雾。这篇后来被奉为 “圣经” 的文献,提出了一个颠覆性观点:完全舍弃循环结构,仅依靠注意力机制就能实现更优的序列建模。这一被命名为 “Transformer” 的架构,彻底改写了神经网络的设计逻辑。
Transformer 的核心突破在于三点。首先是纯注意力机制的架构革新:它用多头自注意力模块替代了 RNN/LSTM 的循环单元,通过 Query-Keys-Values 的映射逻辑,让序列中每个元素能直接与其他所有元素建立关联,实现全局依赖的并行计算。这种 “全局视野” 从根本上解决了长距离依赖问题,无需再依赖时序传递的记忆积累。其次是极简设计的工程价值:论文整合了位置编码、残差连接、层归一化等关键组件,既弥补了注意力机制缺乏时序信息的缺陷,又保障了深度网络的训练稳定性。正如谷歌科学家 Peyman Milanfar 所言,这种对 “数据依赖加权平均” 的极致运用,恰好契合了 GPU 算力提升带来的技术红利。
更值得玩味的是,注意力机制的思想并非首次出现 ——2014 年 Bengio 团队就将其用于机器翻译,Jürgen Schmidhuber 甚至宣称自己 1991 年提出的 “快速权重编程器” 已包含类似概念。但 Transformer 的真正贡献在于 “做减法”:它剥离了所有非必要模块,证明了注意力机制可以作为独立且完整的建模核心,这种极简主义设计使其既易于实现又便于扩展,迅速成为学界和工业界的首选架构。
三、辐射:从 NLP 到全领域的范式迁移
如果说 2017 年是 Transformer 的诞生元年,那么随后的几年便是它的 “征服之年”。这种架构从自然语言处理(NLP)出发,如同涟漪般扩散至计算机视觉(CV)、语音处理、科学计算等多个领域,完成了 AI 史上罕见的跨领域范式迁移。
在 NLP 领域,Transformer 迅速催生了两大技术分支:以 BERT 为代表的 “仅编码器” 架构和以 GPT 为代表的 “仅解码器” 架构。BERT 通过双向遮蔽语言模型(MLM)预训练,让模型能同时捕捉上下文信息,将情感分析、文本分类等任务的准确率提升 10%-20%;GPT 系列则凭借自回归生成能力,从基础文本补全演进到支持代码生成、逻辑推理的通用模型,参数规模从 117M 飙升至万亿级别。截至目前,超过 90% 的主流大模型都基于 Transformer 衍生而来,成为当之无愧的 “基础设施”。
2020 年,Transformer 在 CV 领域实现了历史性突破。谷歌团队提出的 Vision Transformer(ViT)彻底打破了 CNN 长达十余年的统治地位:它将图像拆分为 16×16 的像素块(Patch),如同处理文本 Token 般进行注意力建模,在 ImageNet 分类任务中准确率达到 88.5%,不仅超过 ResNet-50 约 3 个百分点,训练速度还提升了 2 倍。随后的 Swin Transformer 通过窗口注意力优化计算效率,ViT-22B 则将参数规模推向 220 亿,让视觉理解能力逼近人类水平。
在更广阔的前沿领域,Transformer 的影响力同样深远。OpenAI 的 Whisper 模型通过音频 - 文本跨模态注意力机制,实现了 99 种语言的高精度转录,即便在嘈杂环境下准确率仍达 85% 以上;DeepMind 的 AlphaFold2 基于 Transformer 预测蛋白质三维结构,将新药研发周期缩短 50%,彻底改变了结构生物学研究范式;自动驾驶领域,Transformer 能高效融合摄像头、激光雷达等多源传感器数据,为复杂路况决策提供实时支持。
从 RNN/LSTM 的 “线性困境” 到 Transformer 的 “并行革命”,这场技术变革不仅是架构的迭代,更是 AI 建模思想的升级 —— 它证明了 “注意力” 这种模拟人类认知的机制,能成为连接不同数据形态的通用桥梁。如今,Transformer 早已超越了单一架构的范畴,成为驱动 AI 从 “专用” 走向 “通用” 的核心引擎,而它的革命之路,才刚刚开启新的篇章。
Transformer 全景解析
想纵览本专栏所有文章脉络,快速把握 Transformer 技术体系全貌?点击下方链接,一键直达专栏大纲,轻松定位各核心章节,梳理技术演进路径。
点击查看专栏大纲