NeurIPS 2025 | 时序方向硬核总结,又一顶会新方向!

NeurIPS 2025将在2025年11月30日到12月2日于美国圣地亚哥( San Diego,USA)举行。其中小编精选了近70篇时序主题论文,希望能帮到你~本文放出部分精彩文章!
原文、时序相关 姿.料 在这里哦~

【论文1】TimeSeriesGym: A Scalable Benchmark for (Time Series) Machine Learning Engineering Agents
1.研究方法
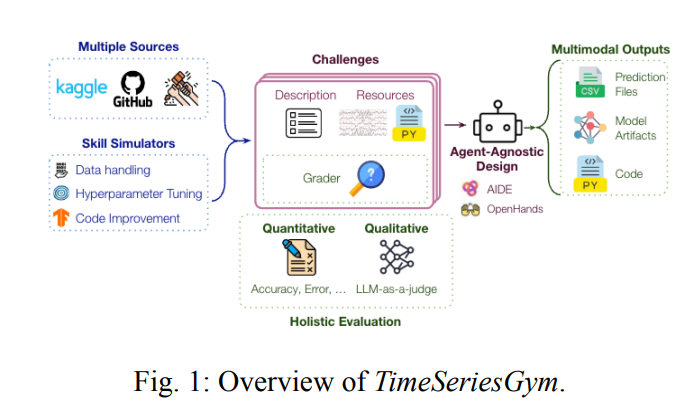
论文提出TimeSeriesGym,一款可扩展、与智能体无关的基准框架,用于评估LLM智能体的时序ML工程任务能力。含34个挑战(23数据源、8问题类型等)及精简版TimeSeriesGym-Lite,提供多模态、技能导向评估,还能通过工具生成新挑战,经实验对比不同框架、模型等性能。
2.论文创新点
- 针对现有基准局限,聚焦时间序列这一高频ML数据模态,构建覆盖8类问题、15+领域、34个挑战的TimeSeriesGym基准框架,更贴合真实ML工程复杂度。
- 设计可扩展挑战生成机制,提供文档与专用工具(如缺失数据模拟),解决传统基准手动筛选任务的scalability难题。
- 提出多模态、技能导向的全面评估体系,分离测试特定ML工程技能(数据处理、建模等),结合定量/程序/定性评估,反馈更精准。
- 推出轻量子集TimeSeriesGym-Lite,6个挑战高效评估核心技能,兼顾领域与问题多样性,降低使用门槛。
链接:https://openreview.net/pdf?id=8M3qAX6e5M
【论文2】Conformal Prediction for Time-series Forecasting with Change Points
1.研究方法
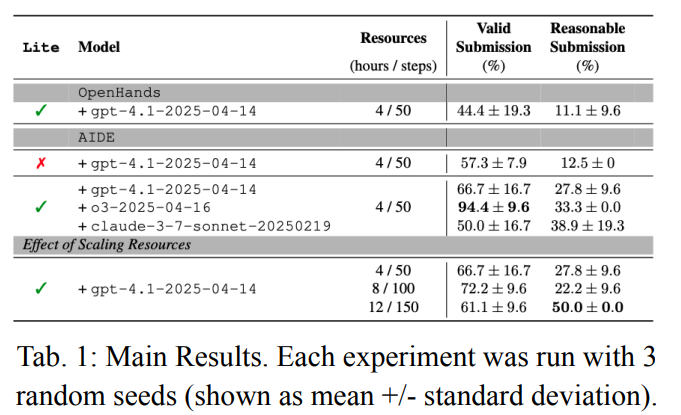
该研究提出CPTC算法,整合状态预测模型与在线保形预测,解决含变点时间序列的不确定性量化问题。依托SDS模型特性,整合多未来预测以自适应调整预测区间,无需每次重训模型。在3个合成与3个真实数据集验证,证明其渐近有效覆盖性,较基线提升覆盖稳健性,且计算高效、适配长序列。
2.论文创新点
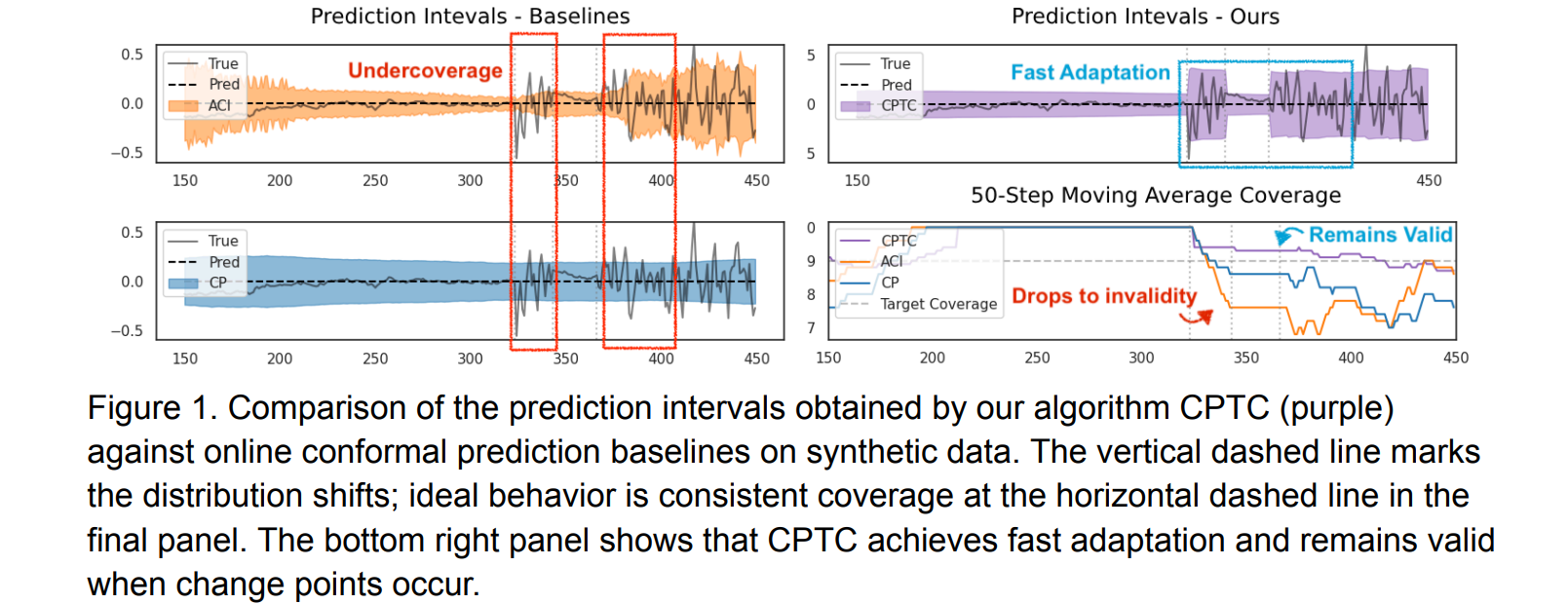
- 提出CPTC算法,整合状态预测模型与在线保形预测,专门解决含变点时间序列的不确定性量化难题,填补现有方法空白。
- 依托SDS模型特性,整合多未来预测自适应调整预测区间,无需每次重训模型,兼顾对已知与未知分布偏移的适配性。
- 证明算法渐近有效覆盖性,且无数据生成过程或状态转移模型准确性假设,理论基础扎实。
- 在多数据集验证,较基线提升覆盖稳健性,与残差回归基线比计算更高效,可适配长序列。
链接:https://openreview.net/pdf?id=9e8FoVcNFK
【论文3】BEDTime: A Unified Benchmark for Automatically Describing Time Series
1.研究方法

该研究提出BEDTime基准,为评估语言模型时间序列描述能力提供统一框架。其整合4类数据集形成10164组时序-描述对,设计识别、区分、生成3类基础任务,评估13种主流模型(LLM、VLM、TSLM),采用准确率、人工标注及自然语言推理评分等指标,还通过鲁棒性测试暴露模型短板,提供可扩展代码库。
2.论文创新点
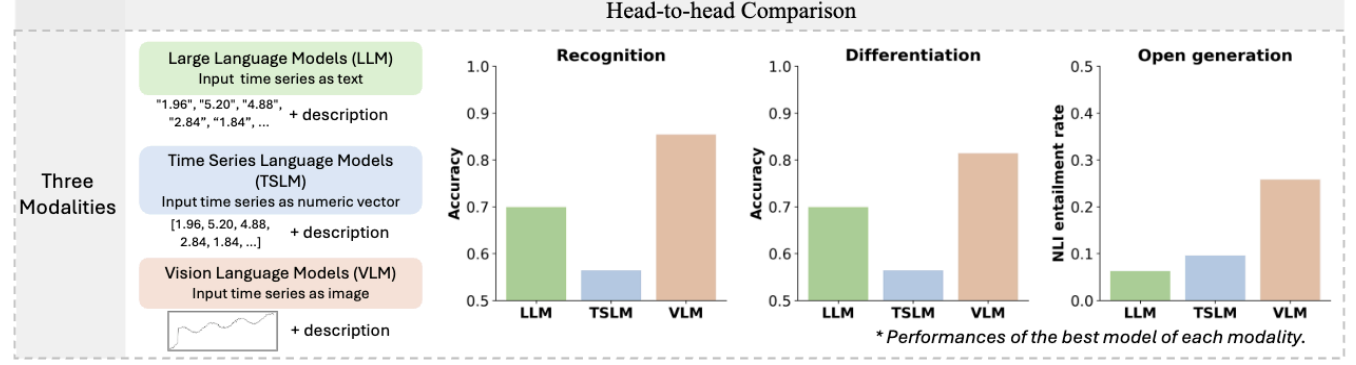
- 首创BEDTime基准,构建首个统一框架评估语言模型的时间序列描述能力,解决现有评估碎片化问题,支持跨模态模型公平对比。
- 整合4类数据集生成10164组时序-描述对,覆盖多场景,设计识别、区分、生成3类基础任务,聚焦核心技能而非复杂推理。
- 采用多维度评估体系(准确率+人工标注+自然语言推理评分),结合鲁棒性测试,精准暴露模型在长序列、噪声等场景的脆弱性。
- 提供灵活代码库,支持集成新模型与适配新数据集,保障基准可扩展性,助力后续研究与模型优化。
论文链接:https://openreview.net/pdf?id=DonOgkqzyD
【论文4】Instruction-based Time Series Editing
1.研究方法
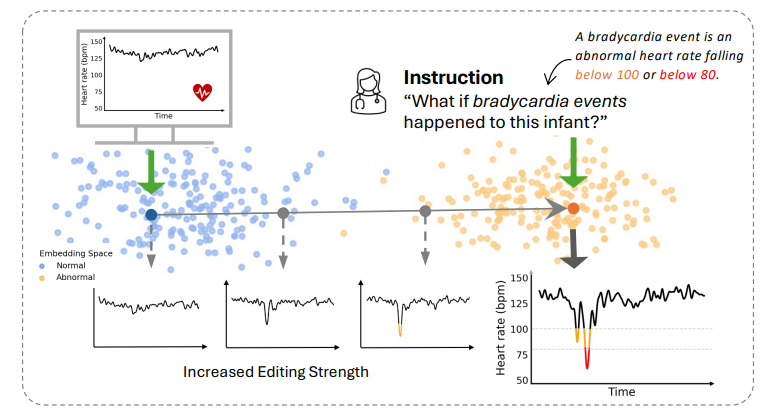
该研究提出InstructTime模型,用于基于指令的时间序列编辑(TSE)。其通过对比学习将时序数据与自然语言指令映射到共享多模态嵌入空间,结合多分辨率时序编码器捕捉全局趋势与局部模式,解码插值嵌入生成编辑后时序,支持可控编辑强度、多条件指令,在合成与真实数据集上表现优异。
2.论文创新点
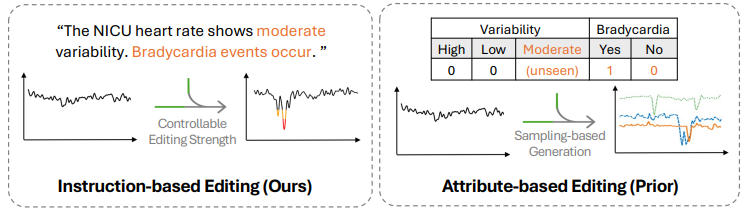
- 首创基于指令的时间序列编辑新范式,用自然语言指令替代预定义属性向量,解决传统TSE方法灵活性与可解释性不足的问题。
- 提出InstructTime模型,借对比学习构建时序与语言的共享多模态嵌入空间,支持可控编辑强度与多条件指令。
- 设计多分辨率时序编码器,捕捉全局趋势与局部模式,适配不同指令对应的 temporal 分辨率需求。
- 在合成与真实数据集验证,较SOTA扩散方法实现更好语义对齐,且非指令版本仍具竞争力,兼顾公平对比与性能优势。
链接:https://openreview.net/pdf?id=enr6tucBi6