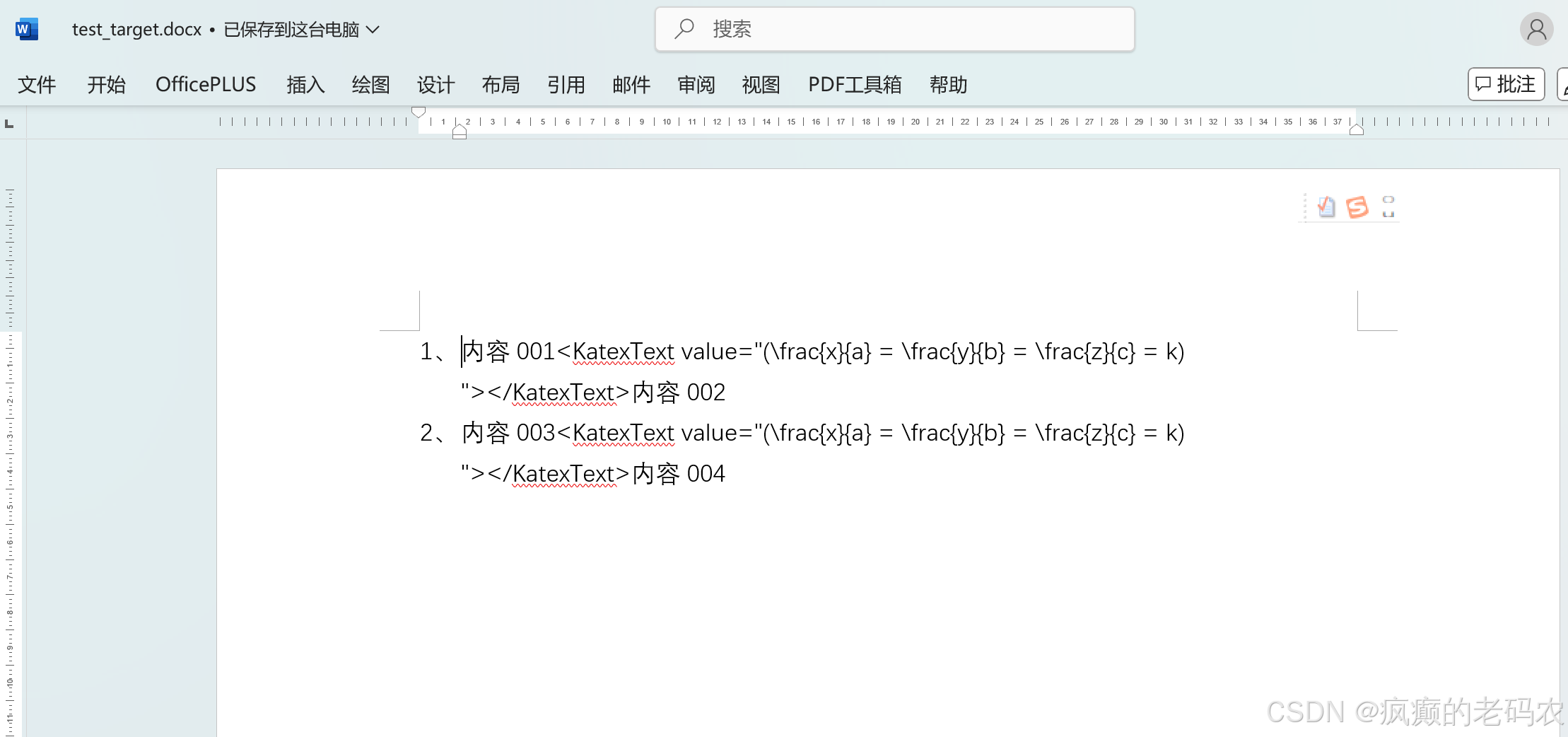
Java按顺序提取Word内容(文本+数学公式)
一、背景
因业务需求,目前正在实现一项需求,即将一份试卷的内容提取出来,由非结构化到结构化的转换。在试卷解析的时候在解析数学公式的时候花了一番功夫,当成功把word中的数学公式提出来并且转换为Latex之后已经大功告成了呢,突然发现从word读取到的公式转换成的Latex不能放到准确的位置,造成了顺序错乱的问题。本方案只是我本人实践的一种方法(不一定是最好的方法),于是写下来分享给大家。
二、概述
从一份word格式的试卷中读取内容,使用POI读取word文件,按照XWPFParagraph进行遍历,处理每一个XWPFParagraph,从XWPFParagraph获取xmlText;开始ParserXMLText内容(基于org.w3c.dom.Document);找到oMath节点后转换为Latex,将Latex替换掉oMath节点后产生新的xmlText,将新的xmlText设置到XWPFParagraph,将XWPFDocument持久化成新的word文档
三、正文
1、准备一份原始word文件
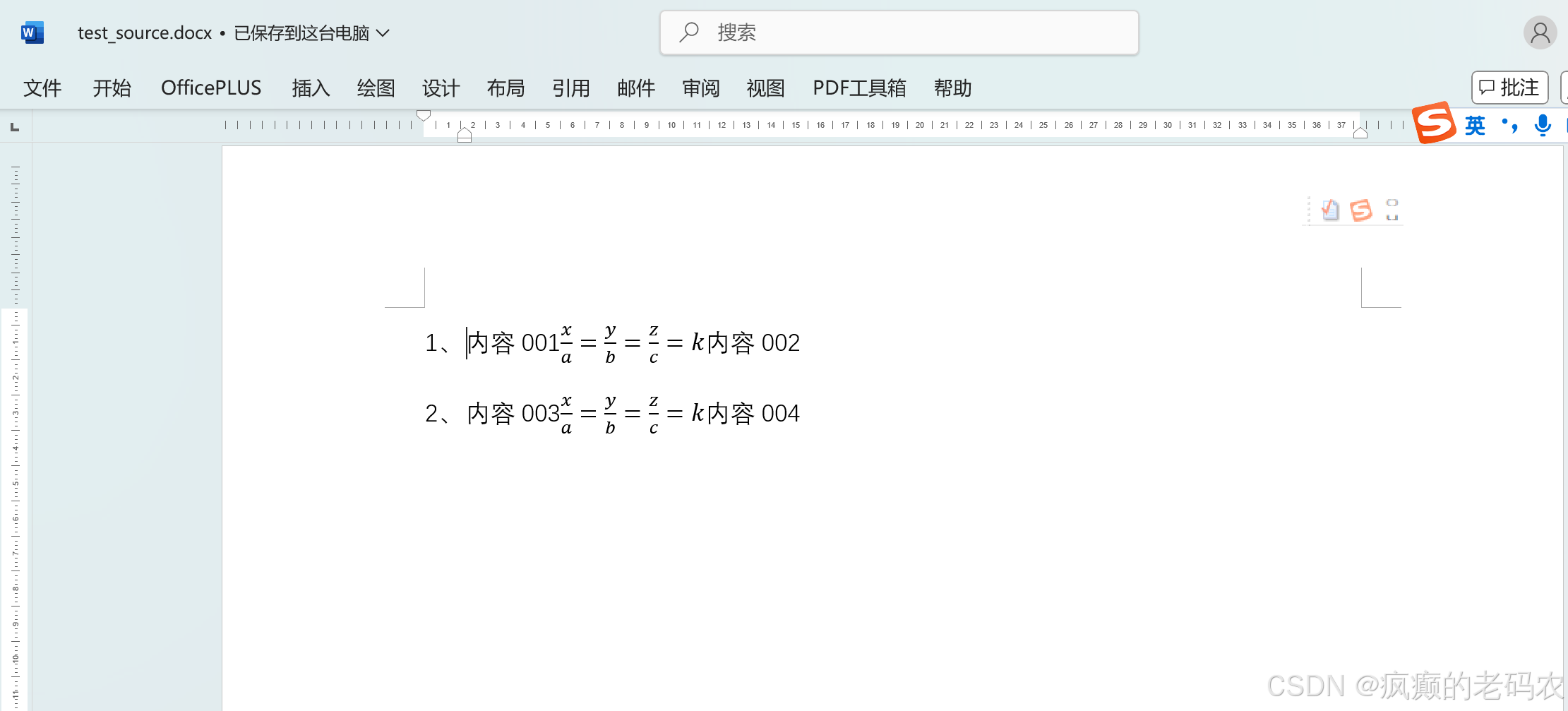
2、使用POI读取word文件,按照XWPFParagraph进行遍历
/*** 提取公式并替换为唯一标识符* @param fis 原始Word文档路径* @param outputPath 处理后Word文档路径* @return 公式与标识符的映射关系*/public Map<String, String> extractAndReplaceFormulas(InputStream fis, String outputPath) {Map<String, String> formulaMap = new HashMap<>();try {try (XWPFDocument document = new XWPFDocument(fis)) {// 遍历所有段落for (XWPFParagraph paragraph : document.getParagraphs()) {processParagraphViaXML(paragraph, formulaMap);}// 保存处理后的文档try (FileOutputStream fos = new FileOutputStream(outputPath)) {document.write(fos);}}} catch (Exception e) {log.error("extractAndReplace Formulas: {0}", e);}return formulaMap;}3、处理每一个XWPFParagraph,从XWPFParagraph获取xmlText
/*** 通过XML直接处理段落中的公式*/public void processParagraphViaXML(XWPFParagraph paragraph, Map<String, String> formulaMap) {try {CTP ctp = paragraph.getCTP();// 获取段落的XML内容String originalXml = ctp.xmlText();// 处理XML,替换公式String newXml = parserXML(originalXml, formulaMap);// 用新的XML替换原来的段落内容CTP newCtp = CTP.Factory.parse(newXml);paragraph.getCTP().set(newCtp);} catch (Exception e) {log.error("processParagraphViaXML Error: {0}", e);}}4、开始ParserXMLText内容(基于org.w3c.dom.Document)
private String parserXML(String originalXml, Map<String, String> formulaMap)throws IOException, SAXException, ParserConfigurationException, TransformerException {DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();factory.setNamespaceAware(true); // 启用命名空间支持DocumentBuilder builder = factory.newDocumentBuilder();org.w3c.dom.Document doc = builder.parse(new ByteArrayInputStream(originalXml.getBytes()));// 查找m:oMath节点(使用命名空间)NodeList oMathNodes = doc.getElementsByTagNameNS("http://schemas.openxmlformats.org/officeDocument/2006/math", "oMath");Map<Element,Node> map = new HashMap<>();for (int i = 0; i < oMathNodes.getLength(); i++) {Node oMathNode = oMathNodes.item(i);Element rElement = doHandleElement(oMathNode, doc);map.put(rElement, oMathNode);}map.forEach((rElement, oMathNode) -> oMathNode.getParentNode().replaceChild(rElement, oMathNode));return docmentToString(doc);}5、处理Node节点,并且找到oMath节点后转换为Latex,将Latex替换掉oMath节点后产生新的xmlText
private Element doHandleElement(Node oMathNode, org.w3c.dom.Document doc) throws TransformerException {// 保存原始公式内容(简化处理,实际可能需要更复杂的序列化)String formulaContent = nodeToString(oMathNode);if(questionMathReader==null){questionMathReader = new QuestionMathReader2();}log.debug("formulaContent:{}", formulaContent);String latexContent = questionMathReader.convertFromMmlToLatex(formulaContent);log.debug("LatexContent:{}", latexContent);// 创建新的文本节点Text textNode = doc.createTextNode("<KatexText value=\""+latexContent+"\"></KatexText>");// 创建新的w:r节点(Word中的文本需要包装在r中)Element rElement = doc.createElementNS("http://schemas.openxmlformats.org/wordprocessingml/2006/main", "w:r");Element tElement = doc.createElementNS("http://schemas.openxmlformats.org/wordprocessingml/2006/main", "w:t");tElement.appendChild(textNode);rElement.appendChild(tElement);return rElement;}
// 辅助方法:将 Node 转换为 XML 字符串private String nodeToString(Node node) throws TransformerException {TransformerFactory tf = TransformerFactory.newInstance();Transformer transformer = tf.newTransformer();transformer.setOutputProperty(OutputKeys.OMIT_XML_DECLARATION, "yes");StringWriter writer = new StringWriter();transformer.transform(new DOMSource(node), new StreamResult(writer));return writer.toString();}6、将org.w3c.dom.Document转换为字符串
private static String docmentToString(org.w3c.dom.Document doc) throws TransformerException {// 将修改后的DOM转换回XML字符串TransformerFactory transformerFactory = TransformerFactory.newInstance();Transformer transformer = transformerFactory.newTransformer();transformer.setOutputProperty(OutputKeys.OMIT_XML_DECLARATION, "yes");transformer.setOutputProperty(OutputKeys.INDENT, "no");StringWriter writer = new StringWriter();transformer.transform(new DOMSource(doc), new StreamResult(writer));return writer.toString();}7、将新的xmlText设置到XWPFParagraph,将XWPFDocument持久化成新的word文档
// 处理XML,替换公式String newXml = parserXML(originalXml, formulaMap);// 用新的XML替换原来的段落内容CTP newCtp = CTP.Factory.parse(newXml);paragraph.getCTP().set(newCtp);8、还一个main函数也一起贴一下
public static void main(String[] args) throws IOException {QuestionMathReplace2 extractor = new QuestionMathReplace2();// 执行提取并替换公式Map<String, String> formulaMap = extractor.extractAndReplaceFormulas(Files.newInputStream(Paths.get("F://test_source.docx")),"F://test_target.docx");// 输出映射关系for (Map.Entry<String, String> entry : formulaMap.entrySet()) {System.out.println(entry.getKey() + " => " + entry.getValue());}}9、运行一下,看一下控制台
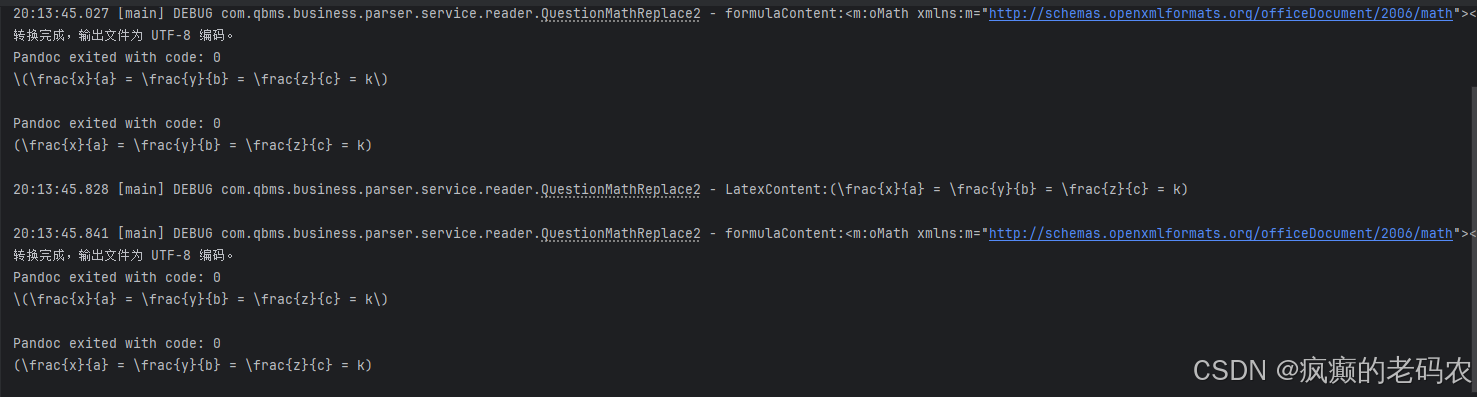
10、最后看一下生成的word文件