(Arxiv-2025)OmniInsert:无遮罩视频插入任意参考通过扩散 Transformer 模型
OmniInsert:无遮罩视频插入任意参考通过扩散 Transformer 模型
paper title:OmniInsert: Mask-Free Video Insertion of Any Reference via Diffusion Transformer Models
paper是字节跳动发布在Arxiv 2025的工作
Code:链接
Abstract
基于扩散模型的视频插入在近期取得了显著进展。然而,现有方法依赖复杂的控制信号,但在主体一致性方面存在不足,限制了其实际应用价值。本文聚焦于无遮罩视频插入任务,旨在解决三个关键挑战:数据稀缺、主体–场景平衡以及插入协调。为了解决数据稀缺问题,我们提出了一种新的数据管道 InsertPipe,能够自动构建多样化的跨对数据。在此数据管道的基础上,我们开发了 OmniInsert,一个新颖的统一框架,可以在无遮罩条件下实现基于单一或多个主体参考的视频插入。具体而言,为了保持主体–场景的平衡,我们引入了一种简单而有效的条件特定特征注入机制(Condition-Specific Feature Injection),以区分性地注入多源条件,并提出了一种新颖的渐进式训练策略(Progressive Training),使模型能够在主体与源视频的特征注入之间取得平衡。同时,我们设计了主体聚焦损失(Subject-Focused Loss),以提升主体的细节外观。为进一步增强插入协调性,我们提出了插入式偏好优化(Insertive Preference Optimization)方法,通过模拟人类偏好来优化模型,并在参考过程中引入上下文感知重释模块(Context-Aware Rephraser),以实现主体与原始场景的无缝融合。针对该领域缺乏基准的问题,我们提出了 InsertBench,一个涵盖多样场景并精心挑选主体的综合性基准。在 InsertBench 上的评估表明,OmniInsert 超越了最先进的闭源商业解决方案。代码将会开源。
1 Introduction
扩散模型 [11, 38] 的出现极大推动了视频生成领域的发展。近年来,大量开源和商业视频生成模型被提出 [8, 13, 46],为视频内容创作提供了强有力的工具。除了生成之外,视频编辑自然成为扩展方向,重点在于通过细粒度的控制信号(如深度 [6, 29]、姿态 [15, 20, 35, 51]、运动 [7, 18, 27, 30] 和点 [5, 44])重新生成参考视频。在各种编辑技术中,基于参考图像的编辑 [19, 23] 起到了关键作用,它通过显式的视觉线索来指导编辑过程。尤其是视频插入(Video Insertion, VI)任务,即将参考主体插入到源视频中,因其在影视制作、广告和艺术设计中的巨大应用潜力而引起了广泛研究兴趣。
已有方法 [23, 54] 使用 DDIM 反演进行噪声初始化,以保持参考视频的主要结构,并在去噪步骤中注入主体特征。然而,这些方法引入了额外的推理阶段,使计算时间增加一倍,并且常常导致插入主体的连续性和自然性不足。最近,VideoAnyDoor [45] 和 GetInVideo [55] 提出了端到端的视频插入框架,可以同时处理参考图像和条件视频。然而,它们依赖复杂的控制信号(如掩码或点)来引导插入位置和运动,并在主体一致性方面表现不佳。近期,一些统一的视频编辑工作 [28, 53] 支持基于指令的视频插入。然而,它们仍然存在主体不一致和交互不自然的问题,限制了实际应用。
在本文中,我们专注于无遮罩视频插入(Mask-free Video Insertion, MVI)任务,即根据用户自定义的提示,将用户定义的人物插入到参考视频中。该任务面临若干挑战,包括:1)数据稀缺:缺乏插入前后配对视频及其对应的主体参考;2)主体–场景平衡:在保持插入主体一致性的同时,确保参考视频未编辑区域的不变性;3)插入协调:实现插入主体合理的位置和运动,以保证自然交互。
为解决数据稀缺问题,我们提出了新的数据管道 InsertPipe,用于生成包含参考主体、相应编辑视频及文本提示的训练数据。具体而言,我们引入了三种数据构建管道:RealCapture Pipe、SynthGen Pipe 和 SimInteract Pipe,以增强数据多样性,从而提升模型在复杂场景下的鲁棒性。RealCapture Pipe 利用现有真实视频,通过检测、跟踪和视频擦除工具构建配对视频。不同于以往方法 [3, 16] 从视频中提取关键帧作为参考主体,我们着重于构建跨视频的主体对,以避免复制粘贴问题。为确保场景多样性,SynthGen Pipe 使用大语言模型(LLM)[37] 生成多样化提示,并结合图像生成、图像编辑、视频生成和主体移除等技术,自动构建大规模跨对数据集。针对复杂场景交互数据的稀缺,SimInteract Pipe 基于渲染引擎生成定制数据。
在数据管道的基础上,我们提出了 OmniInsert,一个新颖的统一框架,用于无遮罩视频插入,支持基于单主体和多主体参考的视频插入,并结合自定义提示。为保持主体–场景平衡,我们在模型架构、训练策略和监督上提出了三项改进。首先,我们引入了一种简单而有效的条件特定特征注入机制(Condition-Specific Feature Injection, CFI),在保持效率的同时,区别性地注入源视频和参考主体的条件,仅需对视频基础模型做最小调整。其次,我们提出了一种新颖的渐进式训练策略(Progressive Training, PT),通过多阶段优化,使模型能够平衡多条件的注入。第三,我们设计了主体聚焦损失(Subject-Focused Loss, SL),帮助模型更好地捕捉主体的细节外观。
为在复杂视觉场景中提升插入协调性,我们提出了两种互补技术。首先,插入式偏好优化(Insertive Preference Optimization, IPO)通过精心构建的一组配对视频,引导模型学习符合人类偏好的上下文感知插入策略。其次,上下文感知重释器(Context-Aware Rephraser, CAR)在推理时丰富用户提示,通过注入细粒度场景细节(如物体纹理、空间布局和交互线索),使插入内容更好地契合场景的语义与视觉结构。
通过上述改进,我们的方法实现了将自定义主体有效插入到参考视频中的目标,如图 1 和图 2 所示。为解决 MVI 缺乏基准的问题,我们提出了综合性基准 InsertBench,其包含 120 段视频及精心挑选的主体(适合插入对应视频)及相应提示。基于该基准,我们进行了广泛评估,结果表明 OmniInsert 在定量和定性上均明显优于最先进的商业解决方案。总体而言,我们的贡献总结如下:
技术方面:1)我们开发了 InsertPipe,一个系统化数据构建框架,包含多个数据管道,可自动生成高质量且多样化的数据;2)我们提出了 OmniInsert,一个统一的无遮罩架构,能够无缝插入单主体或多主体参考;3)我们引入了 InsertBench,一个专为 MVI 任务设计的综合性基准。
意义方面:1)OmniInsert 展现了卓越的生成质量,弥合了学术研究与商业级应用之间的差距;2)我们全面研究了 MVI 任务,包括数据、模型与基准,并将公开发布以支持未来的研究与开发。

图 1 OmniInsert 在真实场景中的展示。

图 2 OmniInsert 在现实-虚拟混合及多目标场景中的展示。
2 Related Work
视频基础模型。扩散模型 [11] 的发展极大推动了视频基础模型的研究。早期模型 [2, 9] 通过增加时间模块,将预训练的文本生成图像(Text-to-Image, T2I)模型扩展为连续视频生成。VDM [12] 将二维 U-Net 扩展到三维,而 AnimateDiff [9] 将一维时间注意力融入二维空间块中以提高效率。这些策略使其能够利用强大的图像先验,但其能力仍受限于原始以图像为中心的架构。近期,基于扩散 Transformer(Diffusion Transformer, DiT)[38] 的视频生成方法在质量和一致性方面表现出更优性能。这类方法将视频视为时空 patch 序列,并利用 Transformer 统一处理。强大的可扩展 Transformer [8, 22, 33, 34, 46, 52] 使得生成更长、更高质量的视频成为可能,为多种下游视频生成任务铺平了道路。
视频插入。视频插入(Video Insertion, VI)的目标是在保持未编辑区域一致性的前提下,将用户提供的参考主体插入源视频。已有方法 [23, 54] 使用 DDIM 反演来基于参考视频初始化生成噪声,并在去噪步骤中注入主体特征。由于它们本质上需要额外的反演阶段,因此计算开销和推理成本显著增加。VideoAnyDoor [45] 提出了一个端到端框架,可以根据用户指定的掩码和点条件精确修改内容和运动。GetInVideo [55] 采用三维全注意力扩散 Transformer 架构,同时处理参考图像、条件视频和掩码,以保持时间一致性。然而,这些方法依赖复杂的控制信号,但在主体一致性上表现不足。近期,一些统一的视频编辑工作 [28, 53] 支持无遮罩视频插入,但在复杂场景中仍会遇到主体不真实和交互不连贯的问题。考虑到商业软件 [21, 39] 目前在 MVI 能力上保持最先进水平,弥合学术研究与商业化之间的差距显得尤为关键。
3 Preliminary
扩散 Transformer(DiT)[38] 模型采用 Transformer 作为去噪网络来优化扩散潜变量。我们的方法继承了使用流匹配(Flow Matching)[31] 训练的视频扩散 Transformer,该方法通过在噪声和数据之间进行线性插值来执行前向过程。在时间步 ttt,潜变量 ztz_tzt 定义为:
zt=(1−t)z0+tϵ,z_t = (1 - t)z_0 + t\epsilon, zt=(1−t)z0+tϵ,
其中 z0z_0z0 是干净视频,ϵ∼N(0,1)\epsilon \sim \mathcal{N}(0,1)ϵ∼N(0,1) 是高斯噪声。模型被训练以直接回归目标速度:
LFM=E[∥(z0−ϵ)−vθ(zt,t,y)∥2],\mathcal{L}_{FM} = \mathbb{E}\big[\| (z_0 - \epsilon) - v_\theta(z_t, t, y) \|^2 \big], LFM=E[∥(z0−ϵ)−vθ(zt,t,y)∥2],
其中 vθv_\thetavθ 表示扩散模型的输出,yyy 表示条件。我们的扩散模型由堆叠的 DiT 模块组成,这些模块执行二维自注意力用于空间建模,以及三维自注意力用于时空融合。
4 Methodology
给定参考主体和源视频,我们的目标是生成一个新的视频合成结果,展示插入内容与原始场景之间的自然交互。我们首先提出一个新的数据管道 InsertPipe,用于构建多样化的配对数据(第 4.1 节)。在此数据管道的基础上,我们开发了一个新颖的框架 OmniInsert,其核心为条件特定特征注入(Condition-Specific Feature Injection, CFI)模块,用于无遮罩视频插入(第 4.2 节)。为了进一步提升插入的稳定性和质量,我们在训练过程中设计了渐进式训练(Progressive Training, PT)策略,并结合主体聚焦损失(Subject-Focused Loss, SL)和插入式偏好优化(Insertive Preference Optimization, IPO)(第 4.3 节)。此外,我们在推理阶段提出了上下文感知重释(Context-Aware Rephraser, CAR)模块,以增强插入的协调性(第 4.4 节)。
4.1 InsertPipe
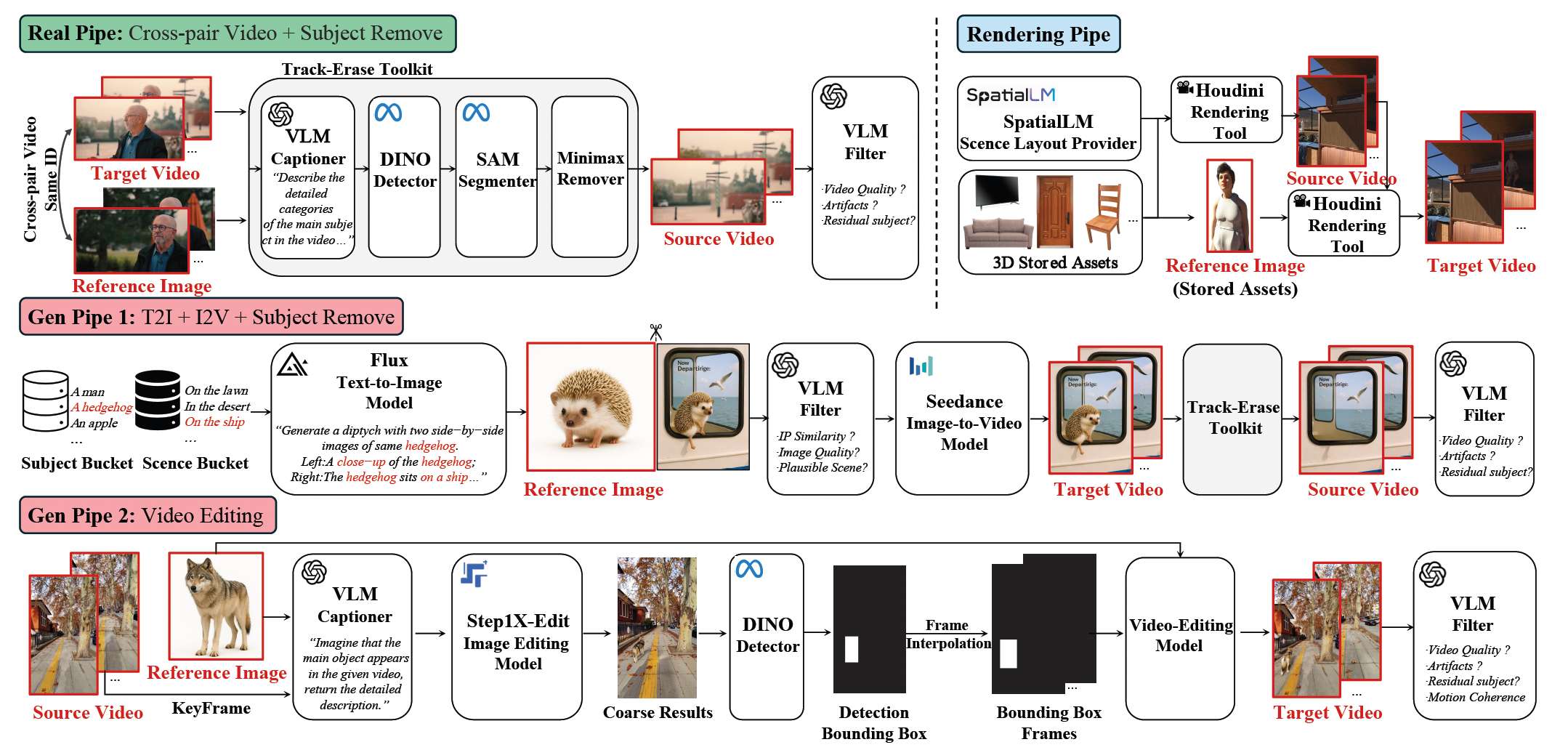
图 3 InsertPipe 概览。它由三条数据构建管道组成:Real Pipe、Rendering Pipe 和 Gen Pipe。
为解决数据稀缺这一挑战,我们提出了一个完整的数据管道 InsertPipe,用于为 MVI 任务生成多样化数据,涵盖 RealCapture Pipe、SynthGen Pipe 和 SimInteract Pipe,如图 3 所示。最终的训练样本格式为 {prompt,reference images,source video,target video}。
RealCapture Pipe。利用 [48] 中的长视频和自有数据,我们使用 AutoShot/PySceneDetect 将视频切分为单场景片段,作为 target video。随后,视觉-语言模型(VLM)[37] 为这些片段生成描述,细化主体外观、场景与交互。这些描述再由 LLM [37] 处理,提取主体类别/外观,作为检测/跟踪提示 [41],以生成掩码序列。此外,我们应用视频擦除技术 [56] 移除目标主体以得到 source video,并结合基于 VLM 的筛选机制以避免修复(inpainting)造成的视觉伪影。关于主体条件,我们构建跨视频的主体配对(避免使用同一视频关键帧 [3, 16]),以防止“复制-粘贴”问题。主体通过 CLIP [42] 与人脸特征 [4] 进行匹配,对于相似度过高(疑似复制粘贴)或过低(不一致)的配对予以剔除。
SynthGen Pipe。鉴于场景多样性有限,我们提出了由两条互补子流程组成的生成式数据管道。1)我们首先精心构建主体与场景库,分别包含 300 个类别与 1000 种设定。然后,将 LLM 生成的多样主体-场景配对与文本模板结合,借助 T2I 模型 [24, 25] 生成跨对参考。为确保一致性,进一步使用 VLM 对每对样本的外观一致性与细节保真度打分。随后,利用图生视频(I2V)基础模型 [8] 合成展现自然交互的 target video,而 source video 则通过跟踪-擦除工具链并结合 VLM 筛选策略获得。2)针对描绘空场景的视频,我们使用 VLM 判定适合插入的主体并生成相应提示;接着采样关键帧,采用基于指令的图像编辑方法 [32] 获得目标的粗位置;再通过时间插值与视频修复合成 target video,并用 VLM 筛选以保证时间一致性与主体一致性。
SimInteract Pipe。尽管多样性得到提升,复杂的主体—场景交互(例如:男子在缓缓开启的门后挥手)仍然稀缺。为此,我们基于 [14] 开发了一条渲染管线。具体而言,我们在渲染环境中构建了大规模的主体与场景资源库;随后使用 SpatialLM [36] 生成 350 个布局先验,用于驱动随机化的资源放置。借助带绑定骨骼的资源及其预定义运动,我们通过预设提示从动作库检索动画来合成交互。最后,我们通过策略性布置的相机渲染得到 target video,并在相同相机下通过主体移除生成配对的 source video。
4.2 OmniInsert Framework
无遮罩视频插入是一项具有挑战性的任务,它要求同时准确保留主体身份和背景一致性。一个直接的解决方案是沿时间维度注入参考的 VAE 特征,或在 patch 化后拼接参考视觉 token。然而,这类方法会带来较高的计算开销,并且未能考虑不同条件下的对齐需求差异:参考视频需要与潜在噪声逐帧对齐,而主体参考则需要完整的时间特征交互。为解决这些问题,我们提出了 OmniInsert,一个新颖的端到端无遮罩视频插入框架,支持使用单个或多个主体参考并结合文本提示进行引导,如图 4 所示。其核心是一种简单而高效的条件特定特征注入(Condition-Specific Feature Injection, CFI)机制,它能够以统一而高效的方式注入视频和主体特征,并根据各自的时间对齐需求进行定制化处理。
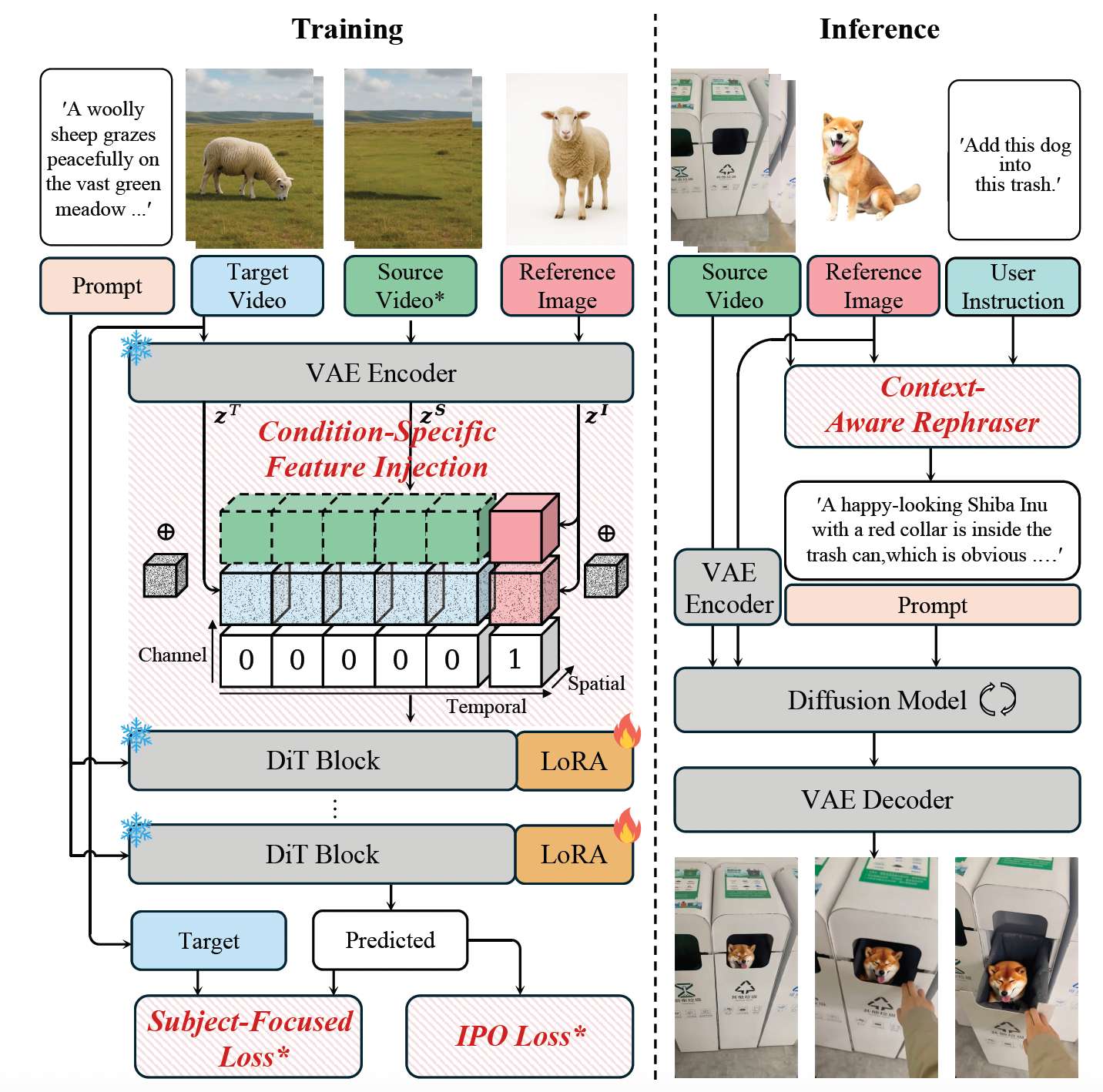
图 4 OmniInsert 概览。需要注意的是,带 * 标记的部分仅在特定阶段启用。
条件特定特征注入(Condition-Specific Feature Injection, CFI)。CFI 在注入机制和通道级标记上采用了有针对性的设计,以适应视频条件与物体条件的不同特性。具体来说,对于视频条件,源视频与潜在噪声在通道维度上进行拼接,并附带专用标记,形式化表达为:
ztVid=Concat([ztT,zS,fS],dim=1),z_t^{\text{Vid}} = \text{Concat}([z_t^T, z^S, f^S], \text{dim}=1), ztVid=Concat([ztT,zS,fS],dim=1),
其中,带噪的目标视频潜变量 ztT=(1−t)zT+tϵz_t^T = (1 - t)z^T + t\epsilonztT=(1−t)zT+tϵ,zT∈Rf×c×h×wz^T \in \mathbb{R}^{f \times c \times h \times w}zT∈Rf×c×h×w 表示干净的目标视频潜变量,zS∈Rf×c×h×wz^S \in \mathbb{R}^{f \times c \times h \times w}zS∈Rf×c×h×w 表示参考源视频潜变量,fS∈Rf×1×h×wf^S \in \mathbb{R}^{f \times 1 \times h \times w}fS∈Rf×1×h×w 是全零向量。通道维度的拼接方式与背景条件高度匹配,有助于实现有效的空间对齐。
相比之下,对于主体条件,潜变量在时间维度上拼接,以更好地捕捉帧间的动态变化。如图 4 所示,主体潜变量的构造为:
ztSub=Concat([ztI,zI,fI],dim=1),z_t^{\text{Sub}} = \text{Concat}([z_t^I, z^I, f^I], \text{dim}=1), ztSub=Concat([ztI,zI,fI],dim=1),
其中 zI,ztI∈Rn×c×h×wz^I, z_t^I \in \mathbb{R}^{n \times c \times h \times w}zI,ztI∈Rn×c×h×w 表示干净与带噪的主体潜变量,ztI=(1−t)zI+tϵz_t^I = (1 - t)z^I + t\epsilonztI=(1−t)zI+tϵ,nnn 表示插入主体的数量,fI∈R1×1×h×wf^I \in \mathbb{R}^{1 \times 1 \times h \times w}fI∈R1×1×h×w 是全一标记图。最终扩散输入通过在帧维度上拼接视频条件与主体条件潜变量构造为:
zt=Concat([ztVid,ztSub],dim=0).z_t = \text{Concat}([z_t^{\text{Vid}}, z_t^{\text{Sub}}], \text{dim}=0). zt=Concat([ztVid,ztSub],dim=0).
这种时间维度的拼接能够有效捕捉主体的运动与连续性。
得益于差异化的条件注入策略,CFI 能够在保持网络效率的同时,实现无缝的主体插入与背景保真。此外,我们将 LoRA 机制集成到 DiT 模块中,以避免代价高昂的全参数更新,从而保留模型原有的文本对齐能力与视觉保真度。
4.3 OmniInsert Training Pipeline
渐进式训练(Progressive Training)。训练视频插入模型的一个重大挑战在于学习难度的固有不平衡:保持源视频基本上是一个复制-粘贴任务,这远比动态主体插入中涉及的复杂时空建模要简单。因此,朴素的单阶段训练往往会使模型偏向于更简单的背景保持任务,从而导致对象插入失败,如图 7 所示。为缓解这些问题,我们提出了一种四阶段渐进式训练策略:

我们方法的消融结果。
阶段 1. 我们首先训练模型基于主体特征和文本提示注入参考主体,同时舍弃源视频条件。这样能够单独进行主体建模,帮助模型建立较强的主体表征与运动生成能力。
阶段 2. 基于阶段 1 的模型,我们引入源视频,并在完整数据集上对整个 MVI 任务进行预训练。这使得模型具备了初步的能力,将主体与视频背景对齐。然而,该阶段的模型常常表现出身份不一致,并且在复杂场景下性能有限。
阶段 3. 针对上述不足,我们引入精心挑选的数据集,其中包含高保真肖像与合成渲染图像,用于精修阶段。在此数据上进行短期微调,可显著提升身份保持能力,并增强模型在视觉复杂环境中的鲁棒性。
阶段 4. 为进一步减少物理不合理性(如不自然的姿态、模型穿插)和视觉伪影,我们提出了插入偏好优化(Insertion Preference Optimization, IPO),这是一个受到 [40] 启发的微调阶段。通过少量人工标注的偏好对,IPO 能够引导模型生成更加自然、符合物理规律的插入结果,从而在生成质量上实现显著提升。
通过渐进式优化,模型实现了来自主体与源视频的特征注入平衡,增强了插入的稳定性与保真度。值得注意的是,这一渐进策略的成功还依赖于精心设计的损失函数,相关内容将在下文描述。
主体聚焦损失(Subject-Focused Loss)。在阶段 1–3 中,流匹配损失(LFM\mathcal{L}_{FM}LFM)作为主要训练目标。然而,由于它对合成视频中的所有区域一视同仁,往往无法保证对占据相对较小空间区域的主体保持一致性。为了解决这一问题,我们提出了主体聚焦损失(Subject-Focused Loss, SL),它是 LFM\mathcal{L}_{FM}LFM 的一种改进形式,将模型的注意力更强地引导到主体区域。形式化定义如下:
LSL=E[∥M⋅((z0−ϵ)−Vθ(zt,t,y))∥2],\mathcal{L}_{SL} = \mathbb{E}\big[\| \mathcal{M} \cdot \big((z_0 - \epsilon) - \mathcal{V}_\theta(z_t, t, y)\big) \|^2 \big], LSL=E[∥M⋅((z0−ϵ)−Vθ(zt,t,y))∥2],
(4)
其中 M\mathcal{M}M 表示由跟踪得到的空间下采样掩码。因此,阶段 1–3 的总体损失 L\mathcal{L}L 为:
L=λ1LFM+λ2LSL.\mathcal{L} = \lambda_1 \mathcal{L}_{FM} + \lambda_2 \mathcal{L}_{SL}. L=λ1LFM+λ2LSL.
(5)
IPO 损失。在阶段 4 中,我们提出了一种偏好优化机制,以提升视觉稳定性和物理合理性。具体来说,训练良好的阶段 3 模型作为参考模型 πref\pi_{\text{ref}}πref,而额外的 LoRA 模块被初始化为可训练的策略 πθ\pi_\thetaπθ。在偏好数据构建中,我们通过人工选择模型推理输出,整理成配对样本(偏好结果 ywy_wyw 和非偏好结果 yly_lyl)。类似于 [50],损失定义为:
LIPO=LDPO+λ⋅E[(−logπθ(yl∣x)−γ)2],\mathcal{L}_{IPO} = \mathcal{L}_{DPO} + \lambda \cdot \mathbb{E}\Big[ \big(- \log \pi_\theta(y_l|x) - \gamma \big)^2 \Big], LIPO=LDPO+λ⋅E[(−logπθ(yl∣x)−γ)2],
(6)
其中 LDPO\mathcal{L}_{DPO}LDPO 定义为:
LDPO=−E[logσ(βlogπθ(yw∣x)πref(yw∣x)−βlogπθ(yl∣x)πref(yl∣x))],\mathcal{L}_{DPO} = - \mathbb{E} \Bigg[ \log \sigma \Bigg( \beta \log \frac{\pi_\theta(y_w|x)}{\pi_{\text{ref}}(y_w|x)} - \beta \log \frac{\pi_\theta(y_l|x)}{\pi_{\text{ref}}(y_l|x)} \Bigg) \Bigg], LDPO=−E[logσ(βlogπref(yw∣x)πθ(yw∣x)−βlogπref(yl∣x)πθ(yl∣x))],
(7)
其中 xxx 表示模型输入(为简洁起见省略),σ\sigmaσ 表示标准 Sigmoid 函数。值得注意的是,仅包含 500 对偏好样本的小规模数据集即可在该阶段取得显著性能提升。需要强调的是,IPO 损失仅在阶段 4 中作为唯一目标函数使用。
4.4 OmniInsert Inference Pipeline
无分类器引导(Classifier-free guidance)[10] 通过联合条件与无条件训练,在扩散模型中平衡了样本质量与多样性。在推理过程中,我们设计了一种联合的无分类器引导,以平衡多重条件:
v^θ(zt,cp,ci,cv)=vθ(zt,∅,∅,∅)+S1⋅(vθ(zt,cp,∅,∅)−vθ(zt,∅,∅,∅))+S2⋅(vθ(zt,cp,ci,∅)−vθ(zt,cp,∅,∅))+S3⋅(vθ(zt,cp,ci,cv)−vθ(zt,cp,ci,∅)),\hat{v}_\theta(z_t, c_p, c_i, c_v) = v_\theta(z_t, \emptyset, \emptyset, \emptyset) + S_1 \cdot (v_\theta(z_t, c_p, \emptyset, \emptyset) - v_\theta(z_t, \emptyset, \emptyset, \emptyset))+ S_2 \cdot (v_\theta(z_t, c_p, c_i, \emptyset) - v_\theta(z_t, c_p, \emptyset, \emptyset)) \\+ S_3 \cdot (v_\theta(z_t, c_p, c_i, c_v) - v_\theta(z_t, c_p, c_i, \emptyset)),v^θ(zt,cp,ci,cv)=vθ(zt,∅,∅,∅)+S1⋅(vθ(zt,cp,∅,∅)−vθ(zt,∅,∅,∅))+S2⋅(vθ(zt,cp,ci,∅)−vθ(zt,cp,∅,∅))+S3⋅(vθ(zt,cp,ci,cv)−vθ(zt,cp,ci,∅)),
(8)
其中 cp,ci,cvc_p, c_i, c_vcp,ci,cv 分别表示提示条件、参考主体和源视频。S1,S2,S3S_1, S_2, S_3S1,S2,S3 为引导系数。
上下文感知重释器(Context-Aware Rephraser)。为提升复杂视觉场景下的主体插入一致性,我们在推理阶段引入了上下文感知重释器(CAR)模块,如图 4 所示。CAR 利用 VLM 生成详细的、具备上下文感知的提示,引导模型实现更无缝且合理的主体与源场景融合。具体来说,CAR 首先引导 VLM 生成细粒度描述,涵盖源环境与参考主体。随后,CAR 为 VLM 提供创意约束,例如保持原始视频设定、在想象性与连贯性之间平衡插入主体、在尺寸与位置上保持空间一致性等。最终,CAR 生成的提示能够更准确地反映用户的创作意图,尤其在视觉特效(VFX)方面,从而显著提升 OmniInsert 的插入真实感与和谐度。