无需代码!用 Amazon Glue 实现 PostgreSQL 数据复制与 PII 脱敏
无需代码!用 Amazon Glue 实现 PostgreSQL 数据复制与 PII 脱敏
在企业数据管理中,将生产库数据同步到测试或分析环境时,如何兼顾效率与数据安全一直是难题。人工处理不仅耗时,还容易出现敏感信息泄露风险。而 Amazon Glue Studio 提供的低代码解决方案,能完美解决这一问题 —— 无需编写复杂脚本,通过可视化操作就能完成数据复制与个人身份信息(PII)脱敏。本文将详细介绍如何基于 Amazon Glue 构建这一流程,附关键配置步骤与验证方法。
一、方案背景与核心价值
1. 常见痛点
-
合规风险:生产数据库中的姓名、邮箱、手机号等 PII 数据若直接复制,会违反 GDPR、CCPA 等法规要求。
-
效率低下:人工脱敏需编写大量 SQL 或 Python 脚本,且跨账户、跨 VPC 的数据传输配置复杂。
-
运维负担:传统 ETL 工具需手动管理服务器、监控作业,占用过多运维资源。
2. Amazon Glue 解决方案优势
-
零代码 / 低代码:通过可视化编辑器拖拽组件,无需编写 ETL 脚本。
-
自动化运维:Amazon Glue 自动处理资源分配、作业监控与重试,无需管理底层基础设施。
-
跨账户支持:支持多亚马逊云科技账户间数据传输,符合企业资源隔离最佳实践。
-
灵活脱敏规则:内置 PII 检测功能,可自定义脱敏策略(如手机号替换、邮箱掩码)。
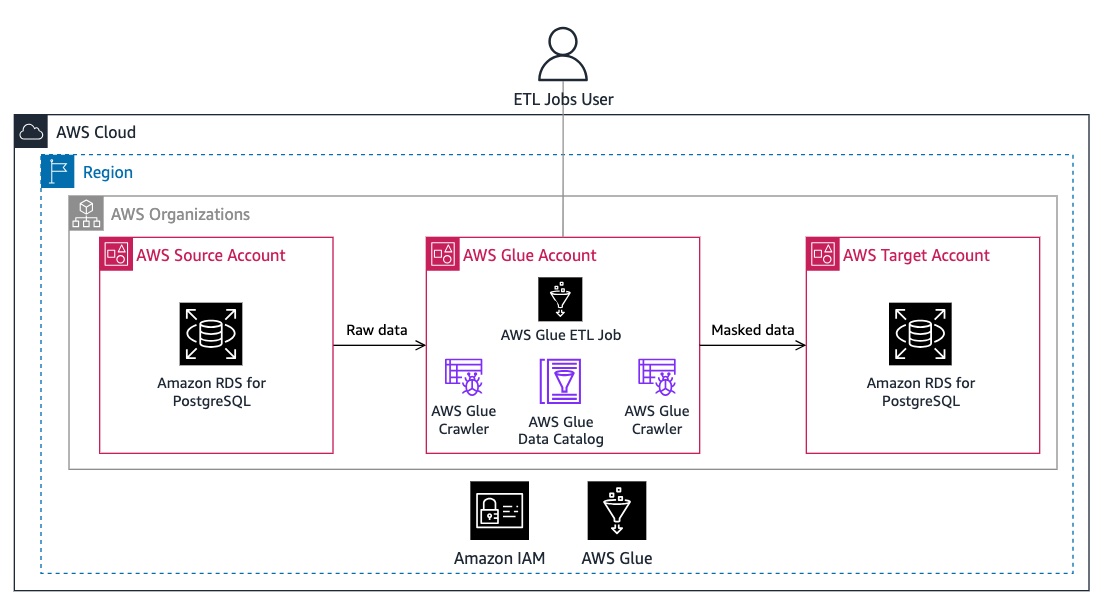
二、方案架构解析
本方案基于3个亚马逊云科技账户实现,分别承担不同角色,确保数据隔离与权限管控:
首先需要创建注册并登录亚马逊云科技账号:亚马逊云科技官网
亚马逊云科技近期推出了全新免费套餐(Free Tier 2.0),可以帮助开发者/企业用户更低成本、更轻松地上手云服务,新账户注册可领 $100 美元抵扣金,完成 5 个入门任务,每完成一项额外奖励 $20,最高再拿 $100,总抵扣金达 200 美元;
与旧版本对比,其优势如下,不过需要注意的是仅在海外区域可用哦(北京与宁夏为中国区域,其他为海外区域)
| Free Tier 2.0(现行) | Legacy Free Tier(旧版) | |
|---|---|---|
| 账户与支付 | 支持银联信用卡注册账户与人民币支付,无需外币信用卡。(2月份开始支持银联信用卡) | |
| 免费形态 | 账户分为两种计划:免费计划(确保 0 元,最长 6 个月或抵扣金用完)与付费计划(所有服务全量访问)。两种计划内均包括服务抵扣金,短期免费试用服务和永久免费服务。 | 三类优惠:Trials(短期试用)/ 12 个月免费 / 永久免费;到期或超额后按需计费。 |
| 金额机制 | 新用户最高 $200 AWS 抵扣金:注册 $100,完成 EC2/RDS/Lambda/Bedrock/Budgets 5个任务再得 $100。 | 以按服务配额为主(按月清零、不可跨服务挪用),没用到的配额会浪费。 |
| 误扣风险 | 免费计划不扣费(除非自愿升级),剩余抵扣金升级后在自注册起 12 个月内仍可用于合规服务。 | 容易因超出某服务配额而进入计费;新手对“超限”不敏感。 |
| 特点 | 专而深:抵扣金可集中投向你的刚需服务(示例:EC2 指定实例族、RDS、Lambda、Bedrock 等)。 | 广而浅:配额分布在很多服务,用不到的等于浪费,刚需服务的免费量相对有限。 |
核心流程:
-
源账户 RDS 数据库通过 VPC 对等连接向 Glue 账户开放访问。
-
Glue Crawler 自动爬取源库与目标库元数据,同步到 Data Catalog。
-
Glue ETL 作业提取源库数据,通过内置函数脱敏 PII 字段。
-
脱敏后的数据加载到目标账户 RDS 数据库。
-
验证目标库数据,确认脱敏效果。
| 账户类型 | 核心功能 | 关键资源 |
|---|---|---|
| 源账户(Source Account) | 存储生产数据 | Amazon RDS for PostgreSQL(含 PII 数据)、私有子网、安全组 |
| 目标账户(Target Account) | 接收脱敏后数据 | Amazon RDS for PostgreSQL(空表,结构与源库一致)、私有子网 |
| Glue 账户(Glue Account) | 执行 ETL 作业 | Amazon Glue Studio、Glue Crawler、Data Catalog、S3 端点 |
三、前置准备:环境配置
在开始构建 ETL 作业前,需完成以下基础配置,确保各账户间网络互通、权限合规。
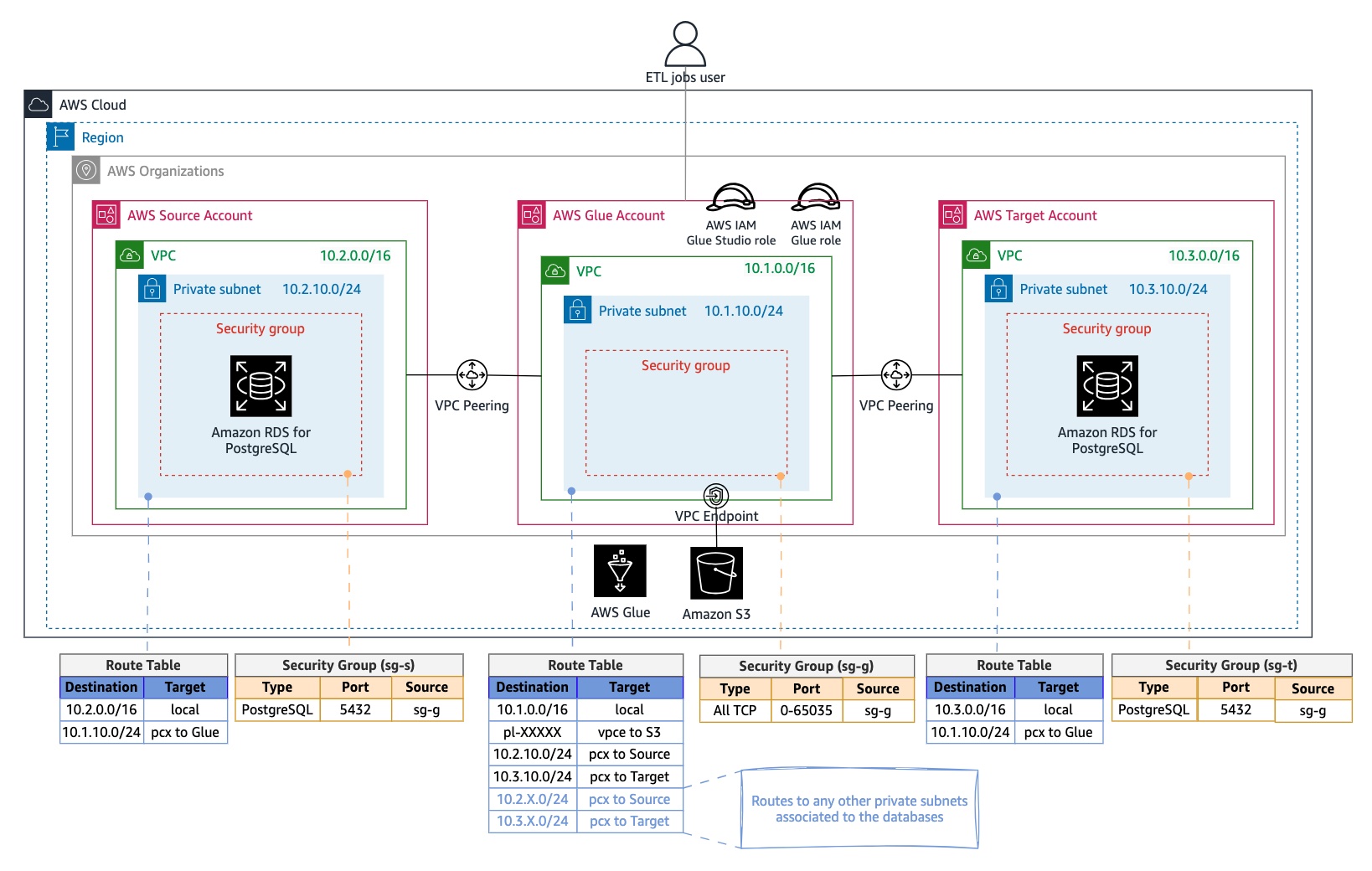
1. 账户与资源清单
| 资源类型 | 配置要求 | 示例值 |
|---|---|---|
| 源账户 RDS | PostgreSQL 13.14-R1,私有子网,表结构含 PII 字段(last_name、email 等) | VPC:10.1.0.0/16,子网:10.1.10.0/24 |
| 目标账户 RDS | 与源库表结构完全一致,初始为空 | VPC:10.2.0.0/16,子网:10.2.10.0/24 |
| Glue 账户 VPC | 含私有子网、自引用安全组(允许所有 TCP 端口入站) | VPC:10.3.0.0/16,安全组:sg-0f(自引用规则) |
| IAM 角色 | Glue 账户需具备 RDS 访问、S3 读写权限 | 角色名:AWSGlueServiceRole-DataSync |
| S3 端点 | Glue 账户 VPC 需创建 S3 端点,用于存储 ETL 脚本 | 端点类型:Gateway,关联 Glue 子网路由表 |
2. 关键 SQL:创建测试表与数据
在源账户 RDS中执行以下 SQL,创建含 PII 数据的客户表(目标账户 RDS 执行相同表结构,无需插入数据):
\-- 1. 创建模式(Schema)CREATE SCHEMA cx;\-- 2. 创建客户表(含PII字段)CREATE TABLE cx.customer (  id INT PRIMARY KEY,  first\_name VARCHAR(50),  last\_name VARCHAR(50), -- PII字段:姓氏  email VARCHAR(100), -- PII字段:邮箱  phone\_number VARCHAR(20), -- PII字段:手机号  address VARCHAR(200),  ssn VARCHAR(20), -- PII字段:社保号  notes TEXT -- PII字段:备注(可能含邮箱/手机号));\-- 3. 插入测试数据INSERT INTO cx.customer (id, first\_name, last\_name, email, phone\_number, address, ssn, notes)VALUES (1, 'Kwaku', 'Mensah', 'kwaku\_mensah@email.com', '646-555-0100', '123 Main St, Anytown, USA', '123-45-6789', 'Bought \$5K in products in 2021. Email: juan\_li@email.com'),(2, 'Jane', 'Doe', 'janedoe@email.com', '555-555-0101', '123 Oak Rd, Anytown, USA', '987-65-4321', 'Spent \$8K last 2 years. Call 555-555-0199 for offers');
3. 网络打通:VPC 对等连接配置
为实现 Glue 账户访问源 / 目标账户 RDS,需建立 VPC 对等连接,步骤如下:
-
创建对等连接:在 Glue 账户 VPC 控制台,分别创建与源账户、目标账户 VPC 的对等连接(请求方:Glue 账户,接受方:源 / 目标账户)。
-
启用 DNS 解析:在 Glue 账户对等连接设置中,勾选 “启用 DNS 解析”,确保 Glue 能解析 RDS 私有域名。
-
更新路由表:
-
Glue 账户路由表:添加源账户 VPC(10.1.0.0/16)和目标账户 VPC(10.2.0.0/16)的路由,下一跳为对等连接 ID。
-
源 / 目标账户路由表:添加 Glue 账户 VPC(10.3.0.0/16)的路由,下一跳为对等连接 ID。
- 安全组授权:在源 / 目标账户 RDS 安全组中,添加入站规则:类型 = PostgreSQL(端口 5432),源 = Glue 账户安全组 ID(如 sg-0f)。
四、核心步骤:构建 Glue ETL 作业
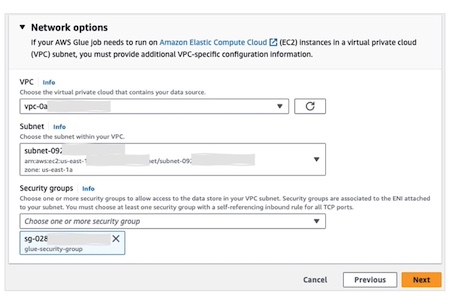
1. 步骤 1:创建 Glue 连接(打通 RDS 访问)
在Glue 账户控制台操作,为源库和目标库分别创建 JDBC 连接:

-
进入 Amazon Glue > 数据连接 > 创建连接。
-
选择 “JDBC” 作为数据源,配置如下:
-
源库连接:
-
名称:Source DB Connection-Postgresql
-
JDBC URL:
jdbc:postgresql://源RDS端点:5432/sourcedb(sourcedb 为源库名) -
用户名 / 密码:源 RDS 数据库 credentials
-
网络选项:选择 Glue 账户 VPC、私有子网、自引用安全组(sg-0f)
-
-
目标库连接:
-
名称:Target DB Connection-Postgresql
-
JDBC URL:
jdbc:postgresql://目标RDS端点:5432/targetdb(targetdb 为目标库名) -
其他配置与源库连接一致。
-
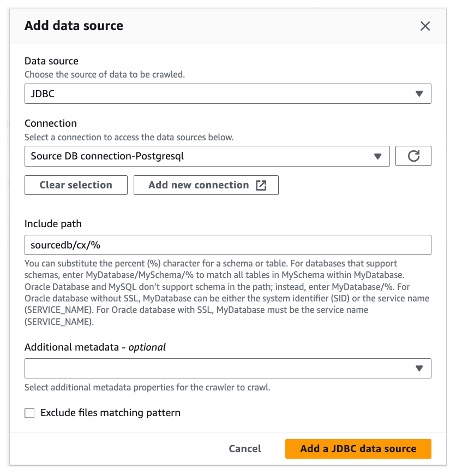
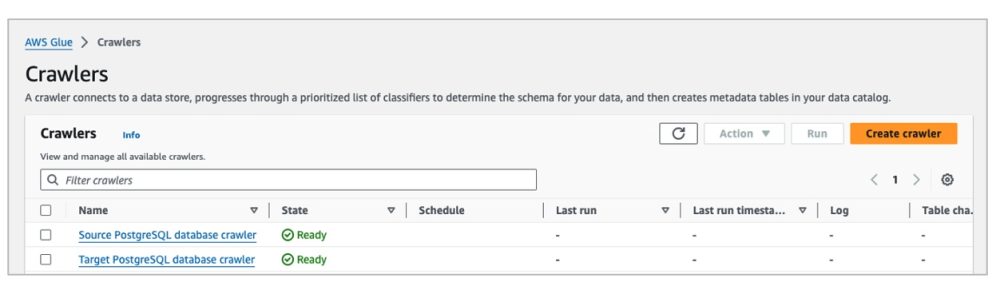
2. 步骤 2:创建 Glue Crawler(同步元数据)
Crawler 用于自动爬取 RDS 表结构,将元数据写入 Data Catalog,避免手动定义 Schema:
-
进入 Amazon Glue > 爬虫 > 创建爬虫。
-
源库爬虫配置:
-
名称:Source PostgreSQL database crawler
-
数据源:选择 “JDBC”,连接 = Source DB Connection-Postgresql,包含路径 =
sourcedb/cx/%(sourcedb = 源库名,cx = 模式名)。 -
IAM 角色:选择前置准备的 AWSGlueServiceRole-DataSync。
-
输出数据库:创建新数据库
sourcedb-postgresql(用于存储源库元数据)。
- 目标库爬虫配置:
-
名称:Target PostgreSQL database crawler
-
数据源:连接 = Target DB Connection-Postgresql,包含路径 =
targetdb/cx/%。 -
输出数据库:创建新数据库
targetdb-postgresql。
- 运行爬虫:选择两个爬虫,点击 “运行”,完成后在 Data Catalog 中可查看同步的表(如 sourcedb_cx_customer、targetdb_cx_customer)。
3. 步骤 3:可视化构建 ETL 作业(核心环节)
进入 Amazon Glue Studio,通过拖拽组件完成数据提取、脱敏、加载,无需编写代码
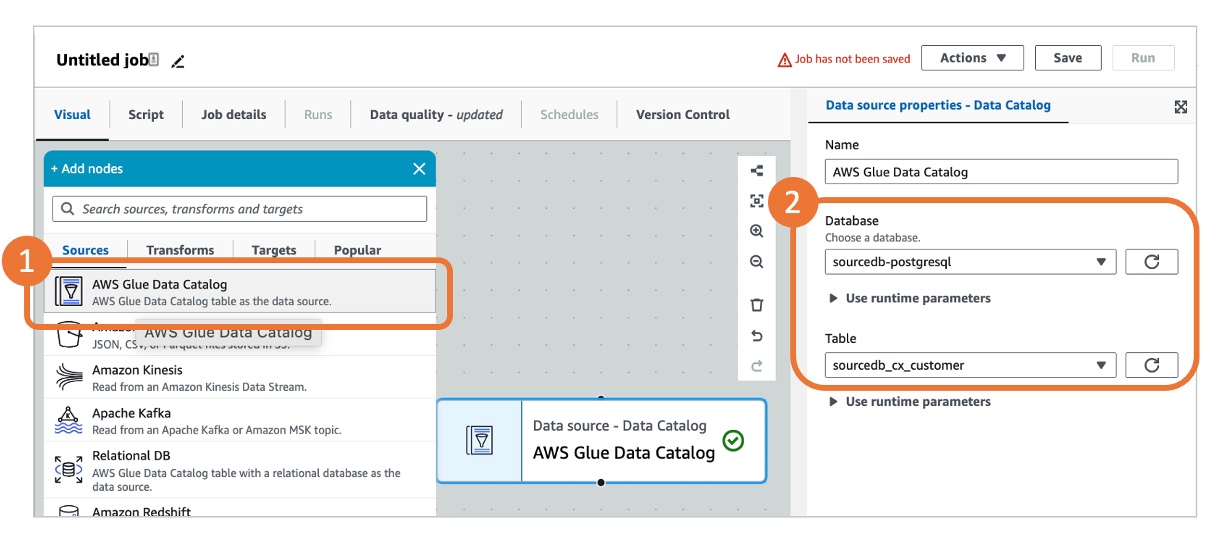
(1)添加数据源节点(提取源库数据)
-
在 Glue Studio 画布左侧 “Sources” 中,拖拽 “Amazon Glue Data Catalog” 到画布。
-
配置属性:
-
数据库:sourcedb-postgresql(源库元数据数据库)
-
表:sourcedb_cx_customer(源库客户表)
(2)添加 PII 脱敏节点(关键步骤)
-
在 “Transforms” 中,拖拽 “Detect Sensitive Data” 到画布,连接到数据源节点。
-
配置脱敏规则(细粒度控制,确保精准脱敏):
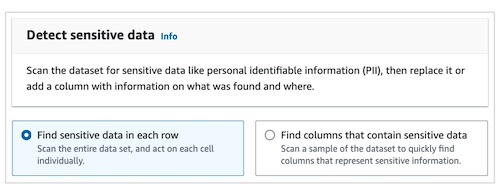
-
数据扫描方式:选择 “在每一行中查找敏感数据”(支持列级排除)。
-
敏感信息类型:勾选 “Person’s name”“Email Address”“US Phone”“Social Security Number (SSN)”。
-
全局操作:选择 “REDACT”(替换),编辑文本 =“***”。
-
细粒度覆盖(针对特定列自定义规则):
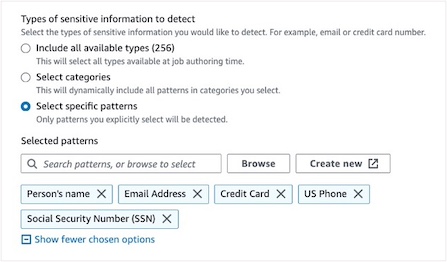
| 实体类型 | 列名 | 脱敏操作 | 编辑文本 |
|---|---|---|---|
| Email Address | email、notes | REDACT | ******@email.com |
| US Phone | phone_number、notes | REDACT | 555-555-5555 |
| Social Security Number (SSN) | ssn、notes | REDACT | 123-****** |
| Person’s name | last_name、notes | REDACT | ***** |
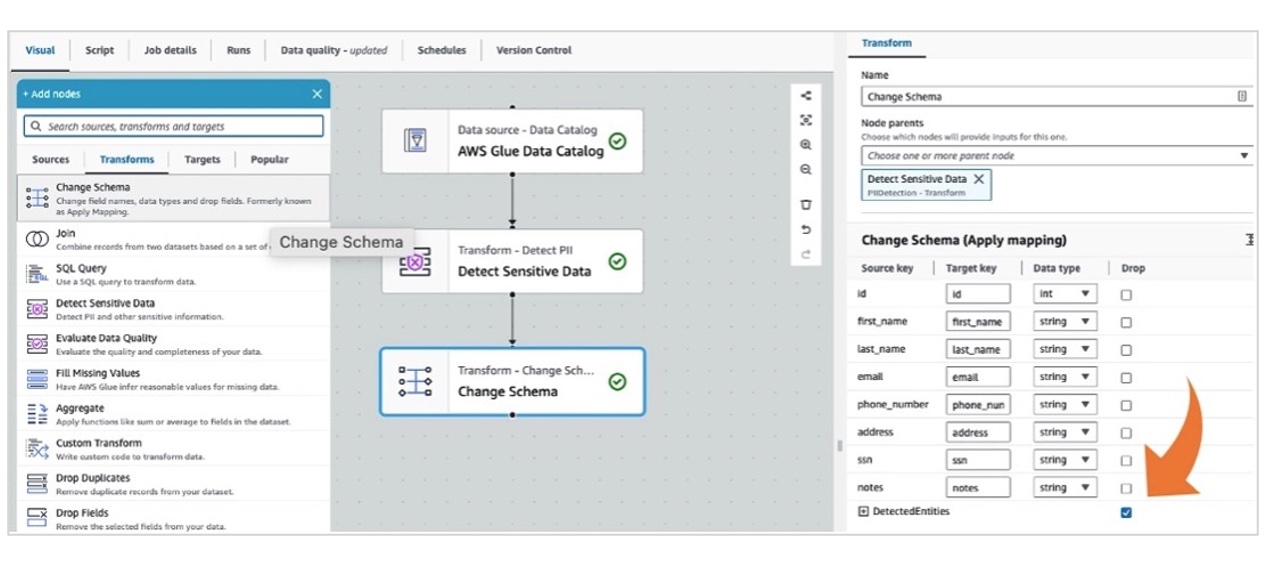
(3)添加数据转换节点(清理无用字段)
-
在 “Transforms” 中,拖拽 “Change Schema” 到画布,连接到 “Detect Sensitive Data” 节点。
-
配置字段映射:
-
保留需要的字段(id、first_name、last_name、email 等)。
-
删除 DetectedEntities 字段(脱敏过程中生成的元数据,无需写入目标库):勾选 “DetectedEntities” 后的 “Drop” 复选框。
-
类型修正:将 id 字段从字符串(脱敏后默认类型)改回 “int”。
(4)添加数据目标节点(加载到目标库)
- 在 “Targets” 中,拖拽 “Amazon Glue Data Catalog” 到画布,连接到 “Change Schema” 节点。
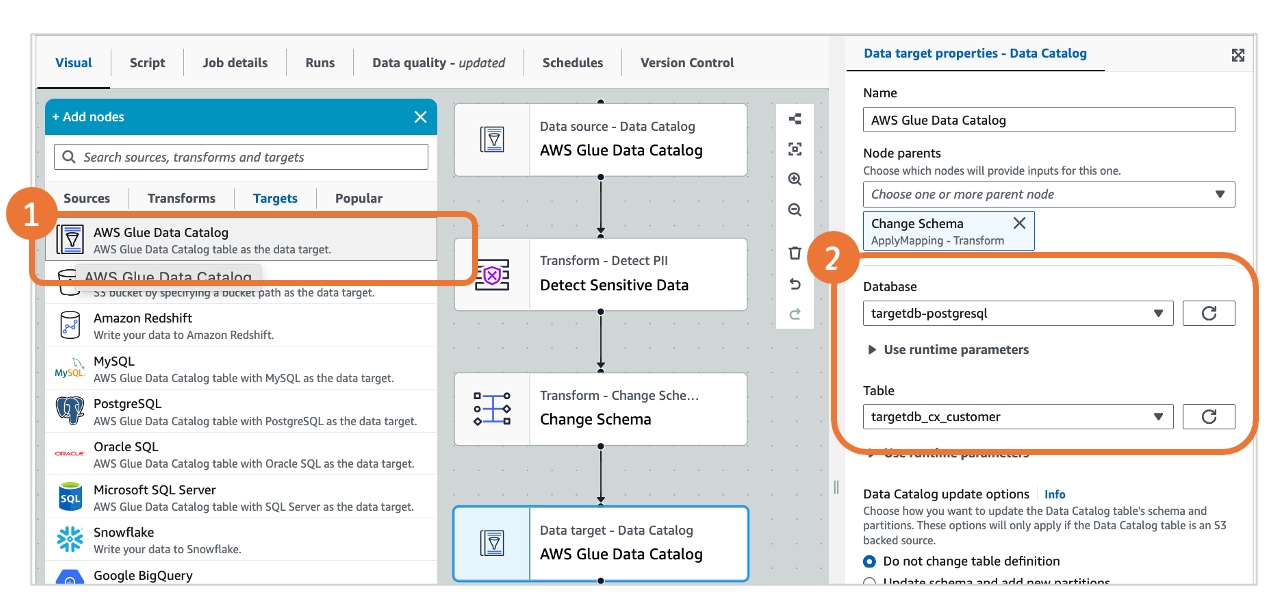
- 配置属性:
-
数据库:targetdb-postgresql(目标库元数据数据库)
-
表:targetdb_cx_customer(目标库客户表)
-
写入模式:选择 “追加”(首次同步也可选择 “覆盖”)。
(5)保存并运行作业
- 作业详情配置:
-
名称:ETL - Replicate customer data
-
IAM 角色:AWSGlueServiceRole-DataSync
-
其他参数默认(如 worker 类型 = G.1X,数量 = 2)。
- 点击 “保存”→“运行”,在 “Runs” 标签页查看进度,直至状态变为 “成功”。
五、验证结果:确认脱敏效果
登录目标账户 RDS,执行以下 SQL 查询,验证数据是否成功脱敏:
\-- 查询目标库客户表,查看PII字段脱敏效果SELECT id, first\_name, last\_name, email, phone\_number, ssn, notes FROM cx.customer LIMIT 5;
预期脱敏结果:
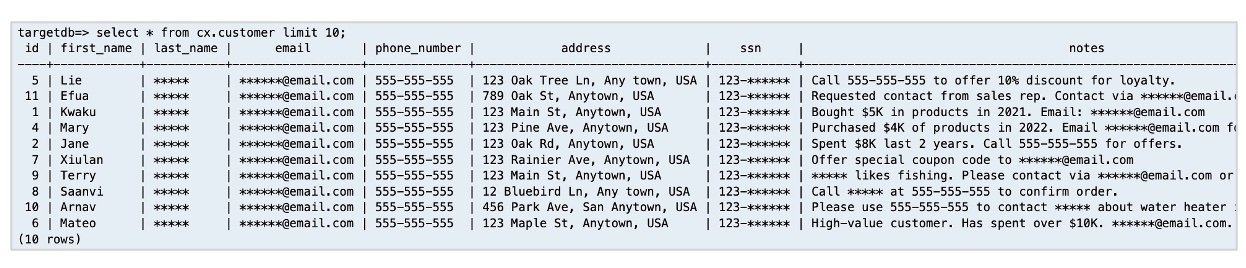
| id | first_name | last_name | phone_number | ssn | notes | |
|---|---|---|---|---|---|---|
| 1 | Kwaku | ***** | ******@email.com | 555-555-5555 | 123-****** | Bought $5K in products in 2021. Email: ******@email.com |
| 2 | Jane | ***** | ******@email.com | 555-555-5555 | 123-****** | Spent $8K last 2 years. Call 555-555-5555 for offers |
可见,last_name、email、phone_number 等 PII 字段已被脱敏,原始敏感信息未泄露,符合合规要求。
六、资源清理(避免不必要开销)
作业验证完成后,删除临时资源:
-
Glue 资源:删除 ETL 作业、Crawler、Data Catalog 数据库、连接。
-
网络资源:删除 VPC 对等连接,移除路由表中的对等路由、安全组入站规则。
-
S3 资源:删除 Glue 账户中
aws-glue-assets-<账户ID>-<区域>存储桶下的 ETL 脚本文件。 -
RDS 资源:若无需保留测试数据,删除源 / 目标账户的 RDS 实例(或使用 CloudFormation 栈批量删除)。
七、总结与扩展
通过 Amazon Glue Studio,我们无需编写代码就实现了跨账户 PostgreSQL 数据复制与 PII 脱敏,既满足了合规要求,又降低了运维成本。企业可基于此方案扩展:
-
多数据源支持:除 PostgreSQL 外,可对接 MySQL、Oracle、S3 等,实现异构数据同步。
-
定时调度:在 ETL 作业中设置调度规则(如每日凌晨 3 点运行),替代人工触发。
-
自定义脱敏函数:通过 “Custom Transform” 节点编写 Python 代码,实现复杂脱敏逻辑(如身份证号部分掩码)。
如果你需要进一步优化性能(如增量同步)或扩展场景(如数据湖加载),可参考 Amazon Glue 官方文档,或基于本文的基础架构进行二次开发。