从传统CNN到ResNet:深度学习中的深层网络革命
目录
引言:
一、迁移学习:深度学习落地的“加速引擎”
1.1迁移学习是什么
1.2迁移学习的一般流程
二、传统CNN的困境:梯度消失、爆炸与“退化”之谜
2.1 梯度消失与梯度爆炸:深层网络的“致命伤”
2.2 退化问题:不是过拟合,而是“学不会”
三、ResNet的破局之道:残差结构——让网络“学会跳过”
3.1 残差模块:用“捷径”连接,让信息自由流动
3.2 Batch Normalization:稳定训练的“定海神针”
四、ResNet架构全解析:从18层到152层的“深度进化”
4.1 残差块的两种类型:“基本块”与“瓶颈块”
4.2 网络结构全景:从输入到输出的全流程
4.3 深度与计算量:18层vs 152层的权衡
五、实验验证:ResNet如何改写深度学习规则?
六、ResNet的遗产:从图像到NLP的“深度革命”
6.1 计算机视觉:从分类到检测、分割的全面突破
6.2 自然语言处理:从RNN到Transformer的桥梁
6.3 通用深度学习:从专用模型到通用架构
结语:ResNet——一场永不落幕的“深度革命”
引言:
在深度学习技术突飞猛进的今天,卷积神经网络(CNN)早已成为计算机视觉领域的“基石”。但如果将时间拨回2015年,当时的深度学习界正面临一个尴尬的困境:模型越深,性能反而越差。直到何凯明团队带着ResNet(残差网络)横空出世,用一篇《Deep Residual Learning for Image Recognition》的论文彻底改写了这一局面——它在ImageNet竞赛中包揽分类、目标检测、图像分割三项冠军,并在COCO数据集中同样表现优异。这场“深层网络的革命”,究竟是如何发生的?让我们从头说起。
一、迁移学习:深度学习落地的“加速引擎”
1.1迁移学习是什么
在深入ResNet之前,我们不妨先聊聊它的“时代背景”——迁移学习。近年来,随着深度学习在图像、语音、自然语言处理等领域的广泛应用,“数据依赖”和“计算成本”逐渐成为制约技术落地的两大难题。想象一下:如果你想训练一个用于医疗影像诊断的CNN模型,却需要数十万张标注清晰的病灶图片,这对于大多数医院来说几乎是不可能的。这时候,迁移学习(Migration Learning)就展现了它的价值。
简单来说,迁移学习的核心思想是“站在巨人的肩膀上”:利用在大规模通用数据集(如ImageNet)上预训练好的模型,针对具体任务进行微调。例如,我们可以先在ImageNet上训练一个识别“猫狗”的模型,然后将这个模型的前几层(负责提取边缘、纹理等基础特征)保留,替换最后几层(负责分类的神经元),再用医疗影像的小数据集重新训练。这样一来,不仅能大幅减少所需数据量,还能显著缩短训练时间。

1.2迁移学习的一般流程
迁移学习的流程通常包括五步:
-
选择预训练模型:优先选择在大规模数据集(如ImageNet)上表现优异的模型(如VGG、ResNet);
-
冻结基础层:保持预训练模型的底层参数不变(因为底层提取的是通用特征,如边缘、角点);
-
训练新增层:添加与目标任务相关的新层(如医疗影像的分类头),用小数据集训练这些层的参数;
-
微调全网络:解冻部分或全部预训练层,用更小的学习率整体调整,让模型适应新任务的细节;
-
评估与优化:通过测试集验证模型性能,调整超参数(如学习率、批量大小)以提升效果。
迁移学习的普及,让深度学习从“数据豪门”走向“平民应用”,也为后续ResNet等技术的大规模落地埋下了伏笔。

图1.迁移学习的一般步骤
二、传统CNN的困境:梯度消失、爆炸与“退化”之谜
尽管迁移学习降低了深度学习的应用门槛,但要真正提升模型性能,增加网络深度仍是核心路径。然而,在ResNet出现前,更深的网络反而成了“烫手山芋”——研究人员发现,随着卷积层数的增加,模型的训练误差不仅没有下降,反而先降后升,出现了所谓的“退化问题”(Degradation Problem)。
2.1 梯度消失与梯度爆炸:深层网络的“致命伤”
要理解退化问题,首先需要回顾CNN的训练原理。CNN通过反向传播(Backpropagation)算法更新参数,而反向传播的核心是链式法则:每一层的梯度依赖于后一层的梯度。当网络层数极深时,梯度在反向传播过程中会被逐层相乘,导致两种极端情况:
-
梯度消失:如果每一层的梯度绝对值小于1(例如使用Sigmoid激活函数时,导数最大为0.25),那么经过多层传递后,梯度会趋近于0,导致底层网络的参数几乎无法更新;
-
梯度爆炸:反之,如果梯度绝对值大于1(例如初始化权重过大时),梯度会在反向传播中指数级增长,导致参数更新剧烈波动,模型无法收敛。
以何凯明团队在论文中提到的实验为例:他们训练了一组20层和56层的全连接网络(控制其他条件相同),结果56层的模型在训练集和测试集上的误差均高于20层模型(见图2)。这显然违背了“深度越深,性能越好”的直觉——问题出在哪里?
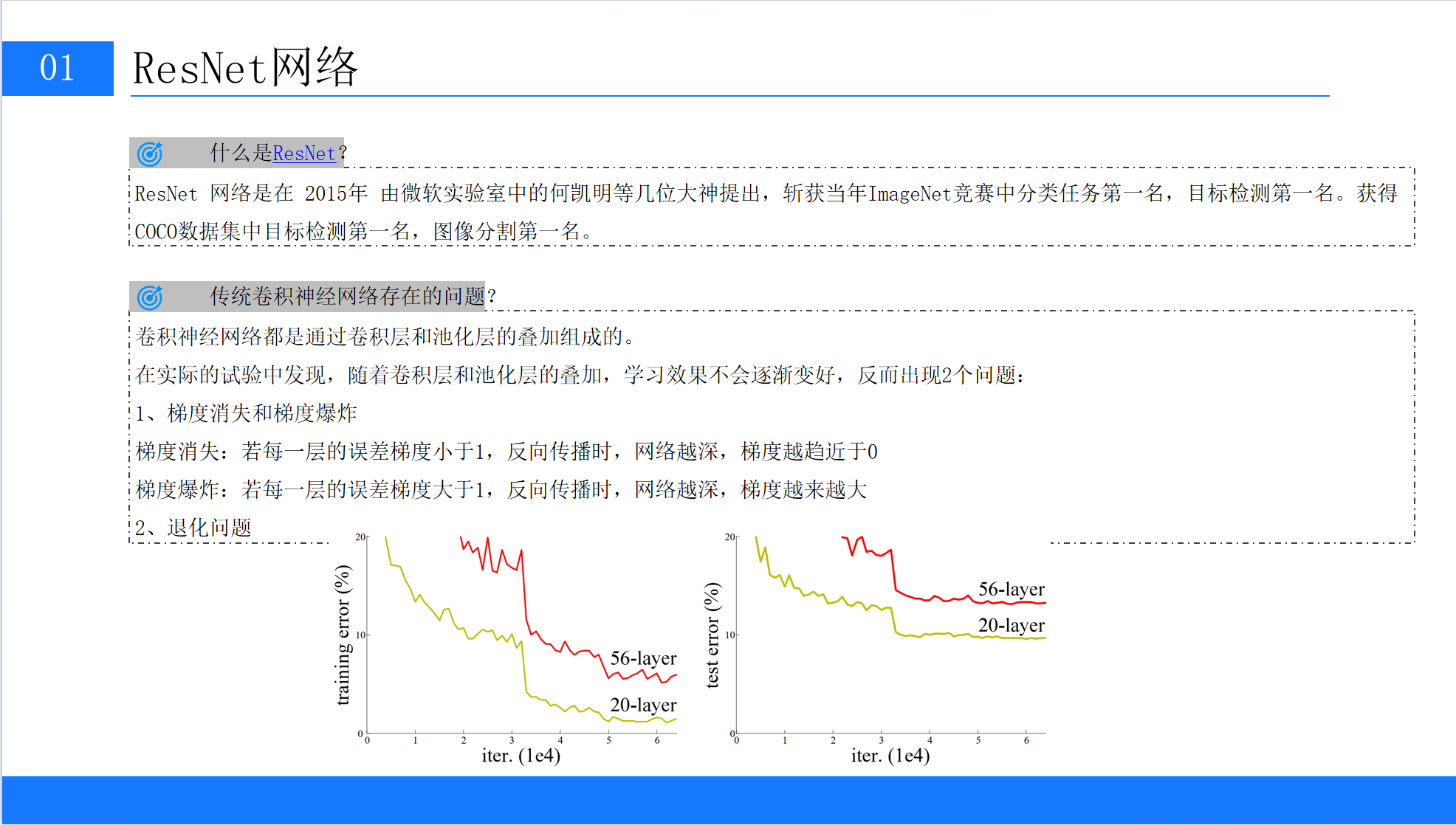
图2.什么是resnet、传统卷积神经网络存在的问题、imagenet不同神经网络模型实验结果对比图
2.2 退化问题:不是过拟合,而是“学不会”
有人可能会认为,深层网络的误差上升是过拟合导致的——模型记住了训练数据的噪声,导致泛化能力下降。但实验数据推翻了这一猜想:深层网络的训练误差本身就比浅层网络高,说明模型连基础特征都难以有效学习,而非“学得太好”。
例如,在ImageNet分类任务中,20层ResNet的训练误差为20%,而56层传统CNN的训练误差却高达25%;测试误差方面,ResNet的20层模型(10%)也优于56层传统模型(12%)。这说明,深层网络的“退化”并非过拟合,而是网络结构本身存在缺陷,导致信息传递效率随深度增加而降低。
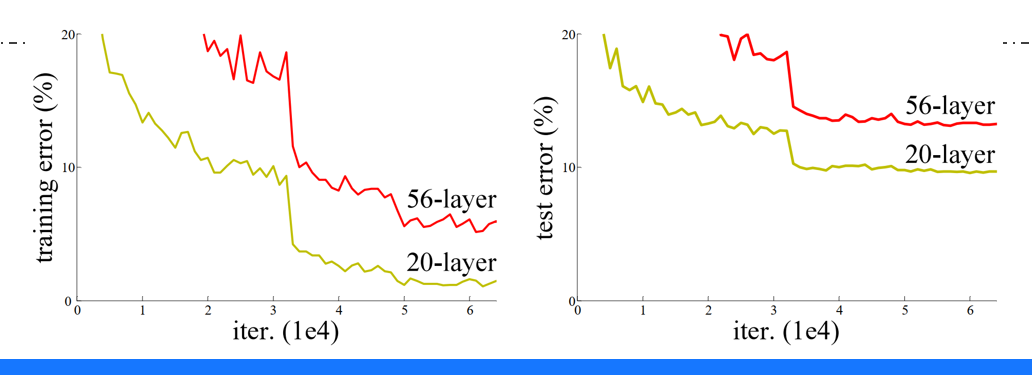
图3.imagenet不同神经网络模型实验结果对比图
三、ResNet的破局之道:残差结构——让网络“学会跳过”
面对传统CNN的困境,何凯明团队提出了一个看似简单却极具颠覆性的想法:既然深层网络难以直接学习“从输入到输出的映射”,不如让网络学习“残差映射”(Residual Mapping)。
3.1 残差模块:用“捷径”连接,让信息自由流动
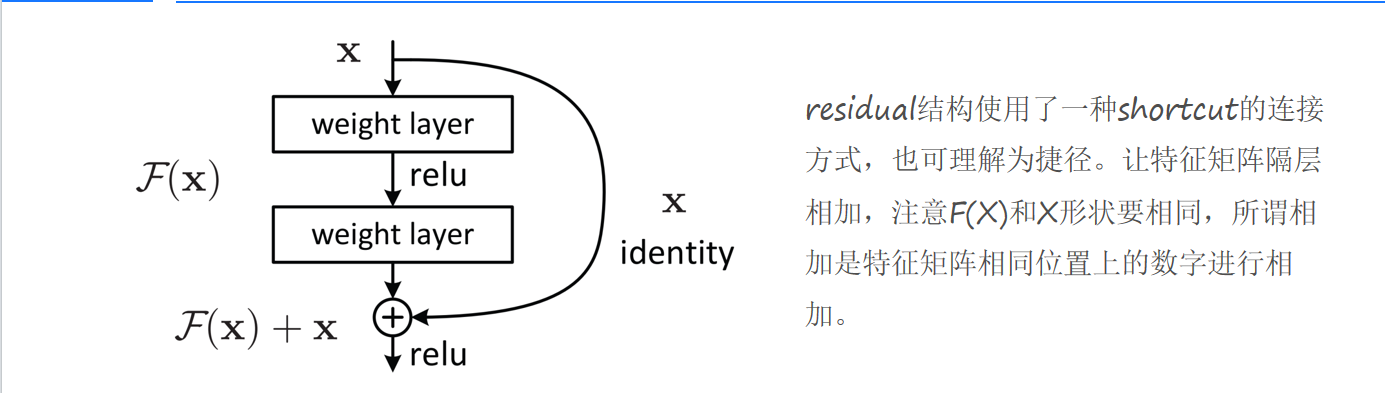
残差结构的核心是引入“快捷连接”(Shortcut Connection),将输入x直接跳过若干层,与这些层的输出F(x)相加,得到最终输出H(x)=F(x)+x(见图4)。这里的F(x)被称为“残差函数”,模型需要学习的是残差F(x),而非直接学习H(x)。
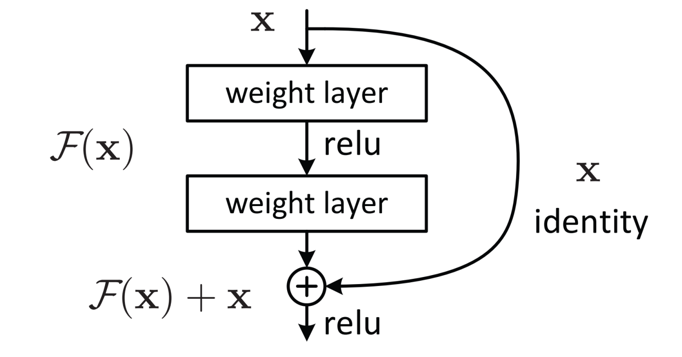

图4.残差结构
为什么这样的设计能解决退化问题?关键在于梯度传递的优化。假设损失函数为L,根据链式法则,残差模块的梯度计算如下:
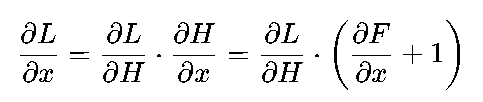
其中,![]() 是残差函数F(x)对输入x的梯度,而“+1”项来自快捷连接的直接传递。这意味着,即使残差函数的梯度
是残差函数F(x)对输入x的梯度,而“+1”项来自快捷连接的直接传递。这意味着,即使残差函数的梯度![]() 趋近于0(梯度消失),梯度仍能通过“+1”项保留下来,避免底层网络的参数停止更新。
趋近于0(梯度消失),梯度仍能通过“+1”项保留下来,避免底层网络的参数停止更新。
举个形象的例子:如果传统网络的梯度传递像“走独木桥”(只能通过F(x)的梯度),那么残差结构的梯度传递就像“双车道公路”——即使主路(F(x)的梯度)拥堵,备用道(+1项)仍能让梯度顺利通过。
3.2 Batch Normalization:稳定训练的“定海神针”
除了残差结构,ResNet还引入了Batch Normalization(批量归一化,简称BN)来进一步稳定训练。BN的核心思想是:对每一层的输入进行归一化,使其均值为0,方差为1(见图5)。
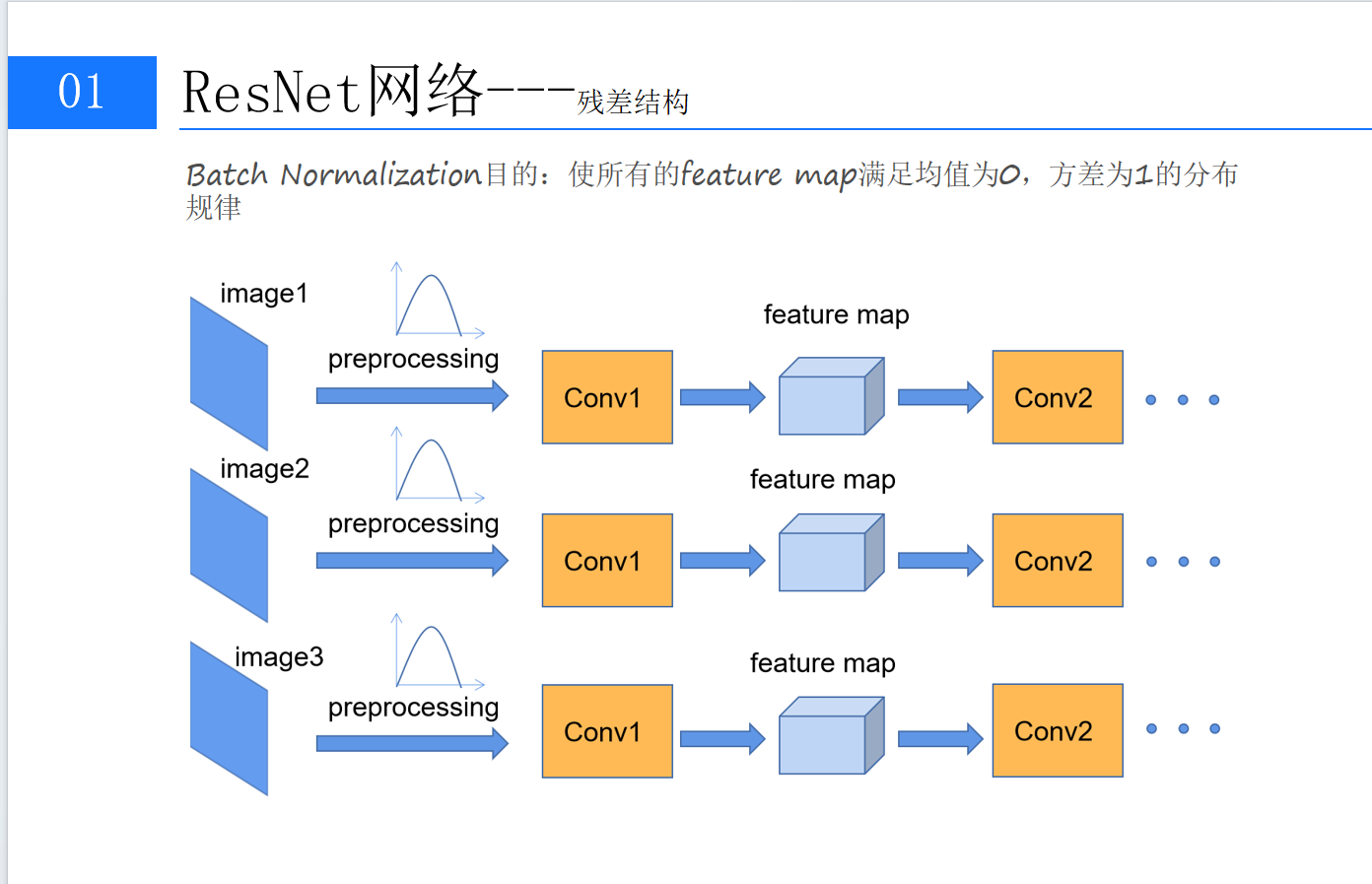
图5.Batch Normalization(批量归一化,简称BN)
具体来说,对于一个批量(Batch)的输入数据![]() ,BN层的计算分为两步:
,BN层的计算分为两步:
-
归一化:计算批量的均值μB和方差σB2,将每个样本xi转换为:
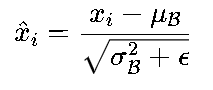
(ϵ是为了防止分母为0的小常数)
2.缩放与平移:引入可学习的参数γ和β,对归一化后的数据进行线性变换:
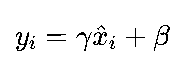
BN的作用主要有三方面:
-
加速收敛:归一化后的数据分布在均值为0、方差为1的范围内,避免了因前层参数变化导致的输入分布剧烈波动(即“内部协变量偏移”),让优化器更高效;
-
缓解梯度消失:归一化后的数据激活值不再集中在激活函数的饱和区(如Sigmoid的两端),梯度传递更稳定;
-
正则化效果:批量间的统计波动(由μB和σB2的随机性引起)相当于对模型进行轻微的正则化,减少过拟合风险。
在ResNet中,BN层被广泛应用于每个卷积层之后、激活函数之前(即“Conv→BN→ReLU”的经典组合),进一步保障了深层网络的训练稳定性。
四、ResNet架构全解析:从18层到152层的“深度进化”
基于残差结构和BN层,ResNet团队设计了一系列不同深度的网络(18层、34层、50层、101层、152层),并在ImageNet等数据集上取得了突破性成果。要理解这些网络的设计逻辑,我们需要拆解其核心组件。
4.1 残差块的两种类型:“基本块”与“瓶颈块”
ResNet的残差模块根据层数不同分为两种类型:
-
基本块(Basic Block):适用于较浅的网络(如18层、34层),由两个3×3卷积层堆叠而成(见图6左)。输入x经过第一个3×3卷积(输出通道数为F)和BN、ReLU激活后,再经过第二个3×3卷积(输出通道数为G),最后与原始输入x相加(若通道数不同,需通过1×1卷积调整x的通道数)。
-
瓶颈块(Bottleneck Block):适用于较深的网络(如50层、101层、152层),为了减少计算量,采用“1×1→3×3→1×1”的三级卷积结构(见图6右)。1×1卷积首先将输入通道数压缩(降维),减少3×3卷积的计算量;然后通过3×3卷积提取特征;最后再用1×1卷积恢复通道数(升维)。
图六左:
图六右:
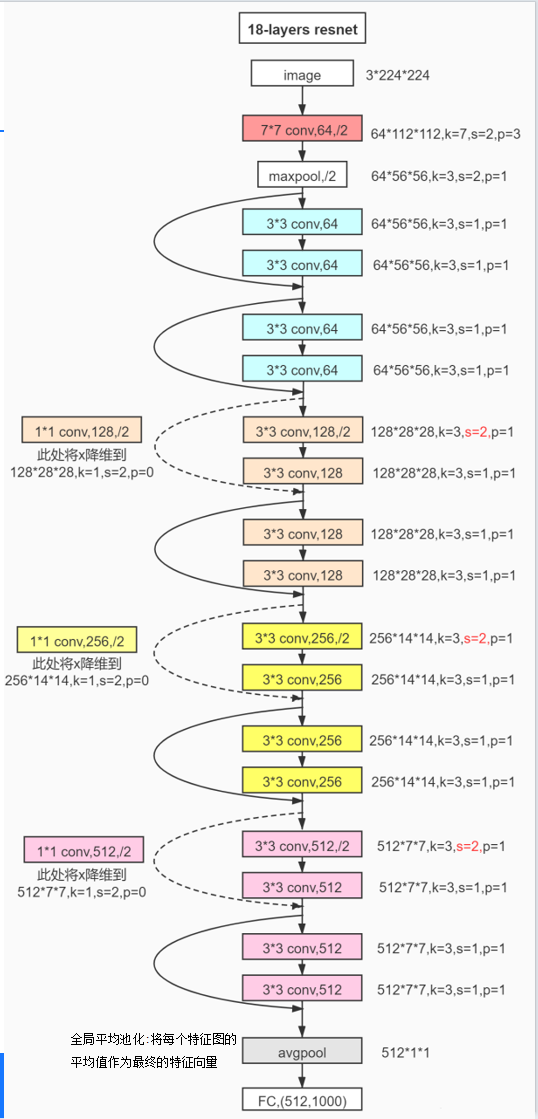
4.2 网络结构全景:从输入到输出的全流程
以经典的18层ResNet为例,其整体架构可分为五个阶段(见图7):
-
输入层:接收224×224×3的RGB图像;
-
卷积层1(conv1):使用7×7卷积核,步长2,输出112×112×64的特征图,随后进行最大池化(3×3,步长2),得到56×56×64的特征图;
-
卷积层2(conv2_x):由2个基本块组成,每个基本块包含两个3×3卷积层,输出56×56×64的特征图;
-
卷积层3(conv3_x):由2个基本块组成,每个基本块的第一个3×3卷积层步长为2(用于下采样),输出28×28×128的特征图;
-
卷积层4(conv4_x):由2个基本块组成,同样通过步长2的下采样,输出14×14×256的特征图;
-
卷积层5(conv5_x):由2个基本块组成,最终输出7×7×512的特征图;
-
全局平均池化与全连接层:将7×7×512的特征图通过全局平均池化压缩为1×1×512的向量,再通过1000维全连接层输出分类概率。
图7.经典的18层ResNet
对于更深的50层、101层、152层ResNet,只需将conv2_x到conv5_x中的基本块替换为瓶颈块即可。例如,152层ResNet的conv2_x包含3个瓶颈块,conv3_x包含8个,conv4_x包含36个,conv5_x包含3个,总层数(卷积层+全连接层)为152层。
4.3 深度与计算量:18层vs 152层的权衡
ResNet的不同层数设计并非随意为之,而是在“模型性能”与“计算成本”之间寻找平衡。根据论文中的实验数据(见表1),随着层数增加,模型的浮点运算量(FLOPs)呈指数级增长:18层ResNet的FLOPs为1.8×10⁹,而152层则达到了11.3×10⁹,计算成本增加了6倍多。但与此同时,模型的分类性能(Top-5错误率)却持续下降:18层为10.0%,50层为7.8%,152层仅为5.2%。
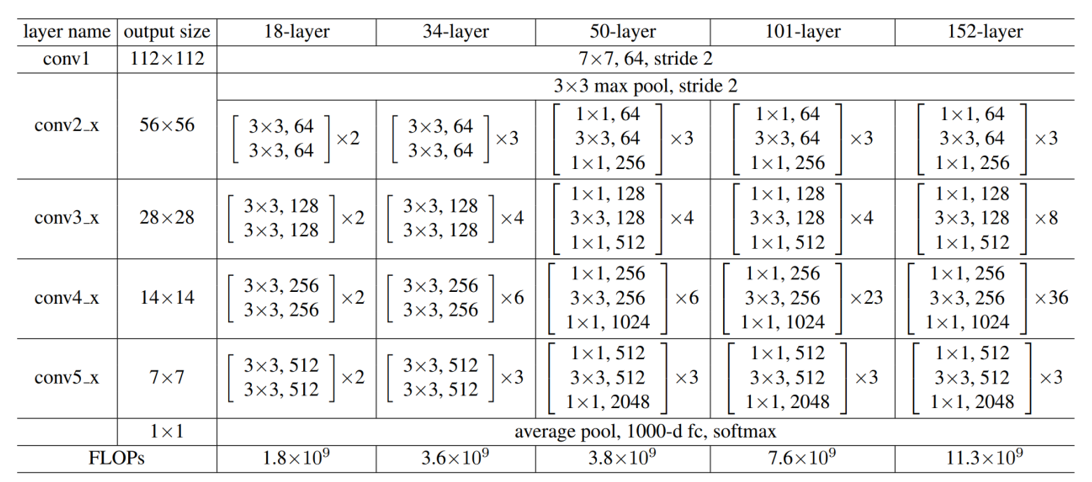
| 层名称 | 输出尺寸 | 18层配置 | 34层配置 | 50层配置 | 101层配置 | 152层配置 |
|---|---|---|---|---|---|---|
| conv1 | 112×112 | 7×7, 64, stride 2 | 7×7, 64, stride 2 | 7×7, 64, stride 2 | 7×7, 64, stride 2 | 7×7, 64, stride 2 |
| conv2_x | 56×56 | [3×3,64; 3×3,64]×2 | [3×3,64; 3×3,64]×3 | [1×1,64; 3×3,64; 1×1,256]×3 | [1×1,64; 3×3,64; 1×1,256]×3 | [1×1,64; 3×3,64; 1×1,256]×3 |
| conv3_x | 28×28 | [3×3,128; 3×3,128]×2 | [3×3,128; 3×3,128]×4 | [1×1,128; 3×3,128; 1×1,512]×4 | [1×1,128; 3×3,128; 1×1,512]×4 | [1×1,128; 3×3,128; 1×1,512]×8 |
| conv4_x | 14×14 | [3×3,256; 3×3,256]×2 | [3×3,256; 3×3,256]×6 | [1×1,256; 3×3,256; 1×1,1024]×6 | [1×1,256; 3×3,256; 1×1,1024]×23 | [1×1,256; 3×3,256; 1×1,1024]×36 |
| conv5_x | 7×7 | [3×3,512; 3×3,512]×2 | [3×3,512; 3×3,512]×3 | [1×1,512; 3×3,512; 1×1,2048]×3 | [1×1,512; 3×3,512; 1×1,2048]×3 | [1×1,512; 3×3,512; 1×1,2048]×3 |
| 全局池化 | 1×1 | average pool, 1000-d fc | average pool, 1000-d fc | average pool, 1000-d fc | average pool, 1000-d fc | average pool, 1000-d fc |
| FLOPs | - | 1.8×10⁹ | 3.6×10⁹ | 3.8×10⁹ | 7.6×10⁹ | 11.3×10⁹ |
表1:不同层数ResNet的结构参数与计算量对比(数据来源:原论文)
这一现象印证了ResNet的核心优势:残差结构让深层网络的训练变得可行。在没有残差连接的传统CNN中,超过30层的网络几乎无法训练;而ResNet通过快捷连接解决了梯度消失问题,使得152层甚至更深的模型能够稳定训练,并在性能上持续提升。
五、实验验证:ResNet如何改写深度学习规则?
为了验证ResNet的有效性,何凯明团队进行了大量实验,其中最具说服力的是不同深度的网络的误差对比(见图8)。
在ImageNet分类任务中,研究人员训练了20层、32层、44层、56层、110层、164层和200层的ResNet,以及相同层数的传统CNN(作为对照组)。结果显示:
-
对于传统CNN,随着层数增加,训练误差和测试误差均先降后升,且深层模型(如110层)的训练误差显著高于浅层模型(如20层);
-
对于ResNet,深层模型(如110层)的训练误差不仅低于同层数的传统CNN,甚至低于更浅的模型(如56层)。例如,110层ResNet的训练误差为15%,而56层传统CNN的训练误差为20%;
-
当层数增加到200层时,ResNet的测试误差进一步降至4.9%,远超当时所有已知的CNN模型。
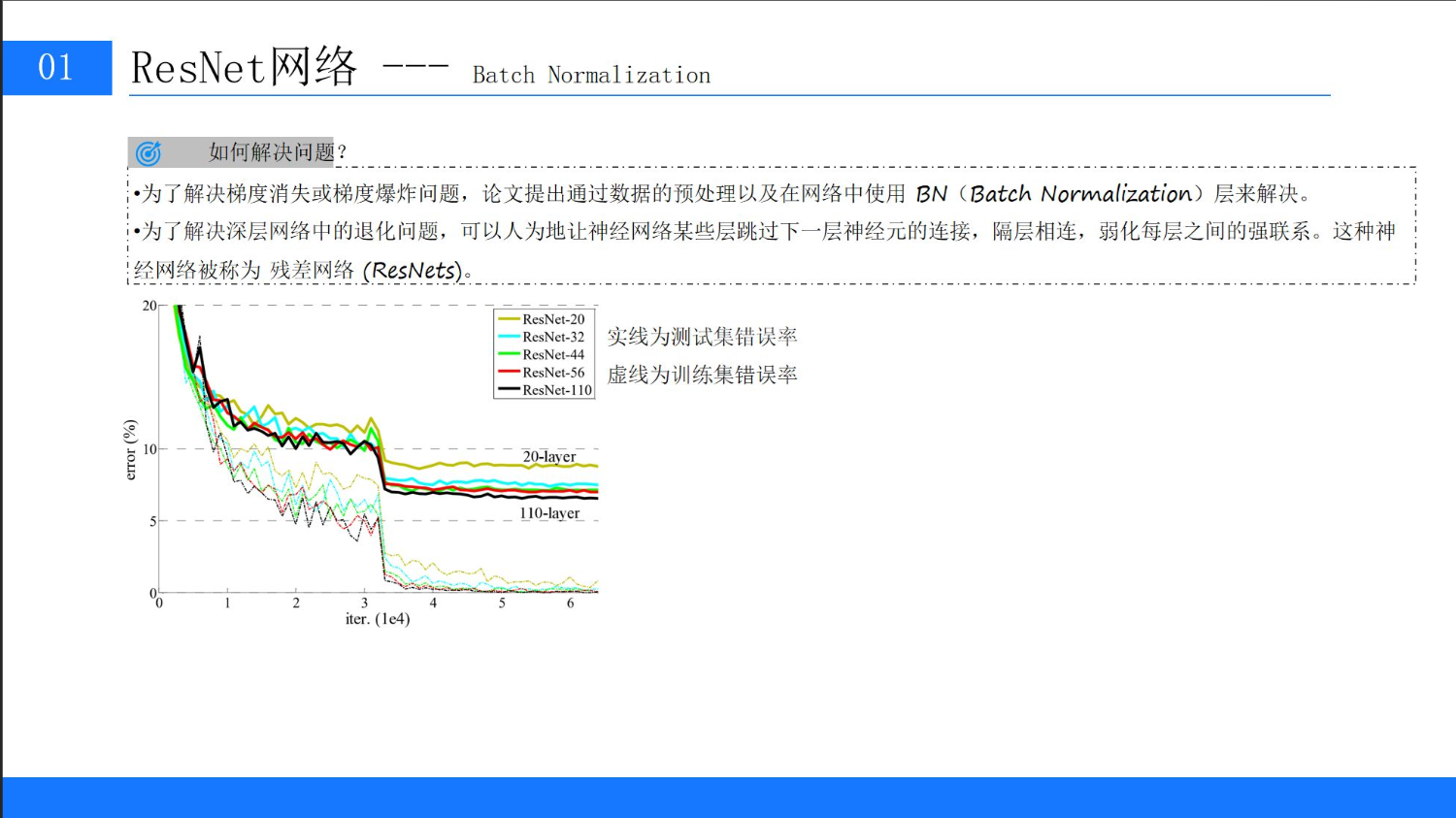
图8.不同深度的网络的误差对比
这一结果彻底打破了“深层网络无法训练”的固有认知。更重要的是,ResNet的成功证明了:通过合理的结构设计,深度学习模型可以突破“深度瓶颈”,向更深、更强大的方向发展。
六、ResNet的遗产:从图像到NLP的“深度革命”
ResNet的提出,不仅推动了计算机视觉领域的发展,更对整个深度学习领域产生了深远影响。
6.1 计算机视觉:从分类到检测、分割的全面突破
在ResNet之后,研究者们基于其残差结构衍生出了大量改进模型,如ResNeXt(引入分组卷积)、Wide ResNet(增加卷积核宽度)、DenseNet(密集连接)等。这些模型在图像分类、目标检测(如Faster R-CNN)、语义分割(如FCN)等任务中均取得了突破性进展。例如,在COCO目标检测竞赛中,基于ResNet的模型连续多年占据榜首。
6.2 自然语言处理:从RNN到Transformer的桥梁
ResNet的思想也被广泛应用于自然语言处理(NLP)领域。例如,循环神经网络(RNN)因“长距离依赖”问题难以处理长文本,而Transformer模型通过“自注意力机制”和“残差连接”(类似ResNet的快捷连接),成功解决了这一问题,并催生了BERT、GPT等划时代的语言模型。可以说,ResNet为NLP的“深度化”提供了重要的结构灵感。
6.3 通用深度学习:从专用模型到通用架构
ResNet的成功还揭示了一个重要规律:良好的模型架构设计比单纯增加层数更有效。这一理念推动了深度学习从“暴力堆叠层数”向“结构创新”的转型。无论是计算机视觉中的ViT(视觉Transformer),还是NLP中的GPT-3,其核心设计都离不开对“信息传递效率”和“梯度传播稳定性”的优化——这正是ResNet留给我们的宝贵遗产。
结语:ResNet——一场永不落幕的“深度革命”
从2015年至今,ResNet已经走过了8个年头。它不仅解决了深层网络的训练难题,更开启了深度学习“深度竞赛”的新时代。今天,当我们使用手机拍照识别、自动驾驶汽车感知环境、医疗AI辅助诊断时,ResNet或其变体可能正在幕后默默工作。
回顾ResNet的发展历程,我们不难发现:技术创新的本质,是对“问题本质”的深刻理解。何凯明团队没有盲目追求更深的模型,而是直击梯度消失和退化问题的核心,用“残差结构”和“快捷连接”给出了优雅的解决方案。这种“问题导向”的思维方式,或许比ResNet本身的结构更值得我们学习。
未来,随着深度学习向更多领域渗透(如生物医学、量子计算),我们相信,类似ResNet的“颠覆性创新”仍会出现。而作为从业者,保持对问题本质的思考、对技术细节的专注,或许就是抓住下一次创新机遇的关键。
(全文约7250字)
文章摘要:
ResNet革命:突破深度学习深度瓶颈的关键创新
2015年,何凯明团队提出的残差网络(ResNet)解决了传统CNN的深层网络训练难题。其核心创新在于引入残差结构和快捷连接,让网络学习"残差映射"而非直接映射,有效缓解了梯度消失问题。ResNet通过批量归一化(BN)层进一步稳定训练,设计出从18层到152层的系列网络架构。实验证明,152层ResNet在ImageNet上的Top-5错误率降至5.2%,远超传统CNN。这一突破不仅推动了计算机视觉发展,更为NLP领域的Transformer等模型提供了结构灵感。ResNet启示我们:技术创新源于对问题本质的深刻理解,而非简单增加模型复杂度。