分布式 ID 生成方案实战指南:从选型到落地的全场景避坑手册(二)
三、方案 2:数据库分段 ID—— 分库分表场景的稳定选择
3.1 问题场景:电商订单分库分表
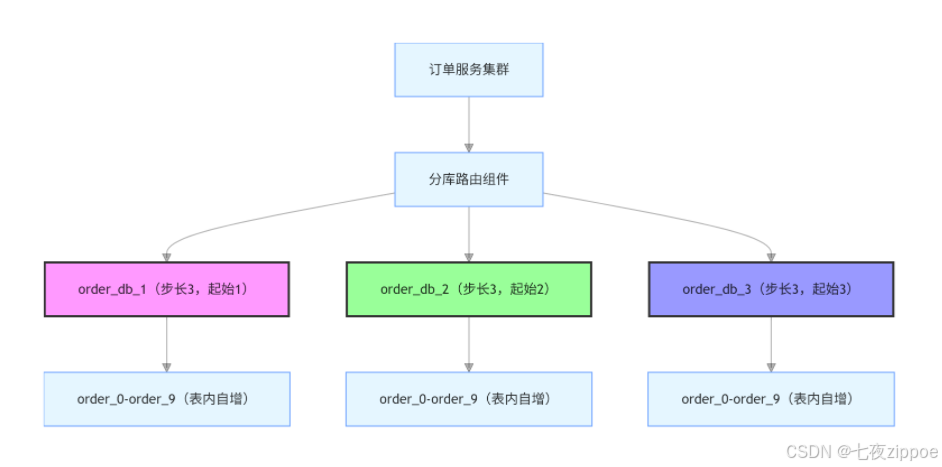
某电商订单系统,日均订单 100 万,分 3 个订单库(order_db_1、order_db_2、order_db_3),每个库分 10 个表(order_0-order_9)。需生成全局唯一的订单 ID,且支持按 ID 排序(查询用户最近订单)。
3.2 方案原理:从 “单库自增” 到 “分段自增”
数据库分段 ID 基于 “步长 + 偏移量” 实现,核心思路:
-
多个数据库实例(或表)共享自增 ID,但设置不同 “步长”(如 3 个库,步长 = 3);
-
每个库的 ID 起始值不同(偏移量),确保 ID 不重复;
-
例如:库 1 生成 ID=1、4、7…,库 2 生成 ID=2、5、8…,库 3 生成 ID=3、6、9…。
3.2.1 架构图:数据库分段 ID 生成架构
3.3 实战代码:数据库分段 ID 配置与实现
3.3.1 1. 数据库配置(MySQL 分库设置)
为 3 个订单库分别配置自增步长和起始值:
\-- order\_db\_1(库1):起始值1,步长3ALTER TABLE order\_0 MODIFY COLUMN id BIGINT AUTO\_INCREMENT PRIMARY KEY;ALTER TABLE order\_0 AUTO\_INCREMENT = 1;SET GLOBAL auto\_increment\_increment = 3; -- 全局步长(所有表生效)SET GLOBAL auto\_increment\_offset = 1; -- 全局起始偏移量\-- order\_db\_2(库2):起始值2,步长3ALTER TABLE order\_0 MODIFY COLUMN id BIGINT AUTO\_INCREMENT PRIMARY KEY;ALTER TABLE order\_0 AUTO\_INCREMENT = 2;SET GLOBAL auto\_increment\_increment = 3;SET GLOBAL auto\_increment\_offset = 2;\-- order\_db\_3(库3):起始值3,步长3ALTER TABLE order\_0 MODIFY COLUMN id BIGINT AUTO\_INCREMENT PRIMARY KEY;ALTER TABLE order\_0 AUTO\_INCREMENT = 3;SET GLOBAL auto\_increment\_increment = 3;SET GLOBAL auto\_increment\_offset = 3;
3.3.2 2. 分库路由实现(Java + MyBatis)
通过 MyBatis 的Interceptor实现订单按用户 ID 路由到对应库:
import org.apache.ibatis.executor.statement.StatementHandler;import org.apache.ibatis.plugin.\*;import java.sql.Connection;import java.util.Properties;// 分库路由插件:按用户ID取模路由到3个库@Intercepts({@Signature(type = StatementHandler.class, method = "prepare", args = {Connection.class, Integer.class})})public class OrderShardingPlugin implements Interceptor {@Overridepublic Object intercept(Invocation invocation) throws Throwable {// 1. 获取当前执行的SQL(如INSERT INTO order\_0 (user\_id, ...) VALUES (123, ...))StatementHandler statementHandler = (StatementHandler) invocation.getTarget();String sql = statementHandler.getBoundSql().getSql();// 2. 提取用户ID(假设SQL中user\_id是第1个参数)Long userId = (Long) statementHandler.getBoundSql().getParameterObject();// 3. 按用户ID取模3,确定路由库(0→db1,1→db2,2→db3)int dbIndex = (int) (userId % 3);String targetDb = "order\_db\_" + (dbIndex + 1);// 4. 修改数据库连接(切换到目标库)Connection connection = (Connection) invocation.getArgs()\[0];connection.setCatalog(targetDb); // 切换数据库// 5. 执行原SQL(此时会在目标库生成自增ID)return invocation.proceed();}@Overridepublic Object plugin(Object target) {return Plugin.wrap(target, this);}@Overridepublic void setProperties(Properties properties) {}}
3.3.3 3. 进阶优化:号段模式(减少数据库访问)
数据库分段 ID 的痛点是 “每次生成 ID 都需访问数据库”,高并发下数据库压力大。优化方案:号段模式(预申请一段 ID 缓存到本地,用完再申请)。
号段模式原理:
-
从数据库申请一段 ID(如
start=1,end=1000),缓存到订单服务本地; -
服务生成 ID 时从本地缓存取,无需访问数据库;
-
当本地 ID 用到阈值(如 800)时,异步申请下一段 ID(
start=1001,end=2000),避免断流。
号段模式实战代码(Java + Spring Boot):
import org.springframework.beans.factory.annotation.Autowired;import org.springframework.stereotype.Service;import java.util.concurrent.atomic.AtomicLong;@Servicepublic class OrderIdGenerator {// 本地缓存的号段(start:起始ID,end:结束ID)private volatile long currentStart;private volatile long currentEnd;// 原子类:确保多线程下ID生成线程安全private AtomicLong currentId;// 阈值:当用到80%时申请下一段(避免断流)private static final double THRESHOLD = 0.8;@Autowiredprivate IdSegmentMapper idSegmentMapper; // MyBatis mapper,操作号段表// 初始化号段(服务启动时调用)public void initSegment() {// 从数据库申请第一段号段(假设order业务的segment\_type=1)IdSegment segment = idSegmentMapper.getNextSegment(1);currentStart = segment.getStart();currentEnd = segment.getEnd();currentId = new AtomicLong(currentStart);}// 生成订单ID(核心方法)public Long generateOrderId() {// 1. 原子递增获取当前IDlong id = currentId.getAndIncrement();// 2. 检查是否达到阈值,若达到则异步申请下一段if (id >= currentStart + (currentEnd - currentStart) \* THRESHOLD) {asyncApplyNextSegment();}// 3. 检查ID是否超出当前号段(异常情况,如申请下一段失败)if (id > currentEnd) {throw new RuntimeException("订单ID生成失败:号段耗尽");}return id;}// 异步申请下一段号段(避免阻塞ID生成)private void asyncApplyNextSegment() {// 用线程池异步执行(避免单线程阻塞)IdGeneratorThreadPool.execute(() -> {// 从数据库申请下一段(数据库通过乐观锁确保号段不重复)IdSegment nextSegment = idSegmentMapper.getNextSegment(1);// 更新本地号段currentStart = nextSegment.getStart();currentEnd = nextSegment.getEnd();// 重置currentId(从新start开始)currentId = new AtomicLong(currentStart);});}}
号段表结构(MySQL):
CREATE TABLE id\_segment (id BIGINT AUTO\_INCREMENT PRIMARY KEY,segment\_type INT NOT NULL COMMENT '业务类型(1=订单,2=物流)',start BIGINT NOT NULL COMMENT '号段起始ID',end BIGINT NOT NULL COMMENT '号段结束ID',version INT NOT NULL DEFAULT 0 COMMENT '乐观锁版本号',create\_time DATETIME NOT NULL DEFAULT CURRENT\_TIMESTAMP,UNIQUE KEY uk\_segment\_type (segment\_type)) COMMENT '号段表';\-- 初始化订单业务号段(start=1,end=1000)INSERT INTO id\_segment (segment\_type, start, end, version) VALUES (1, 1, 1000, 0);
号段获取 SQL(MyBatis Mapper):
\<update id="getNextSegment">UPDATE id\_segmentSET start = end + 1,end = end + 1000, -- 每次申请1000个ID(可根据并发调整)version = version + 1WHERE segment\_type = #{segmentType}AND version = #{version} -- 乐观锁:避免多服务节点重复申请\</update>
3.4 故障案例:号段模式 “ID 重复” 排查
3.4.1 问题背景
某支付系统用号段模式生成支付流水号,部署 3 个服务节点。大促期间发现 2 笔支付流水 ID 重复(ID=1567),导致下游对账系统报错。
3.4.2 根因分析
-
号段表的
version字段未加乐观锁,3 个服务节点同时申请号段时,均执行UPDATE id_segment SET start=end+1...; -
由于无版本控制,3 个节点均获取到相同号段(
start=1501,end=2500),导致生成重复 ID; -
服务节点本地缓存未设置 “防重复校验”,无法发现重复号段。
3.4.3 解决方案
-
在号段表
UPDATE语句中添加乐观锁(WHERE version = #{version}),确保同一时间只有一个节点能申请号段; -
服务节点申请号段后,记录本地号段的
start和end,并与其他节点通过配置中心(如 Nacos)同步,避免重复; -
生成 ID 时添加 “节点标识”(如在 ID 末尾加 1 位节点编号),即使号段重复,ID 也不会重复(如
1567-1、1567-2)。
3.5 避坑总结
✅ 适用场景:分库分表、中低并发(日均 100 万以内)、需强有序 ID 的场景(订单 / 物流);
❌ 不适用场景:超高并发(秒杀 10 万 QPS)、无数据库依赖的场景;
⚠️ 必避坑点:
-
分库步长需等于库数量(如 3 个库→步长 3),避免 ID 断层;
-
号段模式必须用乐观锁控制号段申请,防止重复;
-
号段大小需合理(并发高→号段大,如 1 万 / 段;并发低→号段小,如 1 千 / 段),避免内存浪费或频繁申请。
四、方案 3:雪花算法(Snowflake)—— 高并发场景的首选
4.1 问题场景:秒杀系统订单 ID 生成
某电商秒杀系统,峰值 QPS 达 5 万,需生成全局唯一、有序、高性能的订单 ID,且支持水平扩容(新增服务器节点)。此时雪花算法是最优选择。
4.2 方案原理:雪花算法的结构设计
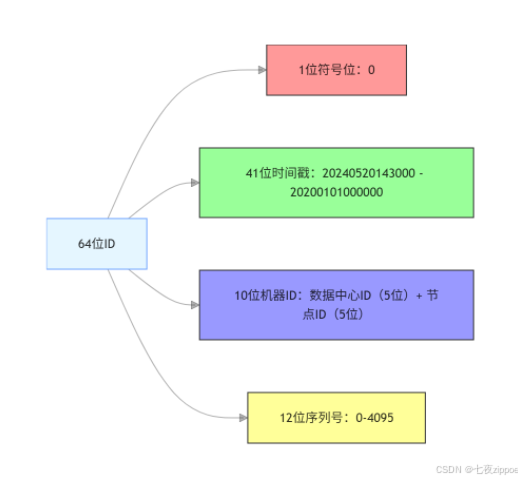
雪花算法生成 64 位 Long 类型 ID,结构如下(从高位到低位):
1位(符号位):固定为0(确保ID为正数)41位(时间戳):当前时间戳 - 起始时间戳(单位:毫秒),可支持约69年(2^41 / 365 / 24 / 3600 / 1000 ≈ 69)10位(机器ID):分为“数据中心ID(5位)+ 机器节点ID(5位)”,支持32个数据中心×32个节点=1024个节点12位(序列号):同一毫秒内的ID序号,支持每毫秒生成4096个ID(2^12=4096)
4.2.1 结构示意图:雪花算法 ID 组成
4.3 实战代码:雪花算法实现(含时钟回拨处理)
雪花算法的核心痛点是 “时钟回拨”(服务器时钟因同步导致时间倒退,生成重复 ID),以下代码包含时钟回拨解决方案。
4.3.1 雪花算法核心实现(Java)
import java.util.concurrent.atomic.AtomicInteger;public class SnowflakeIdGenerator {// 1. 常量配置private static final long SIGN\_BIT = 0L; // 符号位(固定0)private static final int TIMESTAMP\_BITS = 41; // 时间戳位数private static final int DATA\_CENTER\_BITS = 5; // 数据中心ID位数private static final int WORKER\_BITS = 5; // 机器节点ID位数private static final int SEQUENCE\_BITS = 12; // 序列号位数// 2. 位移量计算private static final long DATA\_CENTER\_SHIFT = SEQUENCE\_BITS + WORKER\_BITS;private static final long WORKER\_SHIFT = SEQUENCE\_BITS;private static final long TIMESTAMP\_SHIFT = SEQUENCE\_BITS + WORKER\_BITS + DATA\_CENTER\_BITS;// 3. 最大值限制(避免溢出)private static final long MAX\_DATA\_CENTER\_ID = (1L << DATA\_CENTER\_BITS) - 1; // 31private static final long MAX\_WORKER\_ID = (1L << WORKER\_BITS) - 1; // 31private static final long MAX\_SEQUENCE = (1L << SEQUENCE\_BITS) - 1; // 4095// 4. 起始时间戳(自定义:2020-01-01 00:00:00)private static final long START\_TIMESTAMP = 1577836800000L;// 5. 实例变量(数据中心ID、机器ID、序列号、上次生成时间戳)private final long dataCenterId;private final long workerId;private final AtomicInteger sequence = new AtomicInteger(0);private volatile long lastTimestamp = -1L;// 6. 构造方法(校验数据中心ID和机器ID)public SnowflakeIdGenerator(long dataCenterId, long workerId) {if (dataCenterId < 0 || dataCenterId > MAX\_DATA\_CENTER\_ID) {throw new IllegalArgumentException("数据中心ID超出范围(0-31):" + dataCenterId);}if (workerId < 0 || workerId > MAX\_WORKER\_ID) {throw new IllegalArgumentException("机器节点ID超出范围(0-31):" + workerId);}this.dataCenterId = dataCenterId;this.workerId = workerId;}// 7. 生成ID(核心方法,线程安全)public synchronized long generateId() {// 7.1 获取当前时间戳(毫秒)long currentTimestamp = System.currentTimeMillis();// 7.2 处理时钟回拨(当前时间 < 上次时间)if (currentTimestamp < lastTimestamp) {// 方案1:等待时钟追赶(适合回拨时间短,如<10ms)long waitTime = lastTimestamp - currentTimestamp;if (waitTime <= 10) { // 回拨<10ms,等待try {Thread.sleep(waitTime);currentTimestamp = System.currentTimeMillis();} catch (InterruptedException e) {throw new RuntimeException("时钟回拨等待被中断", e);}} else {// 方案2:回拨时间长,抛出异常(避免重复ID)throw new RuntimeException("时钟回拨超出阈值(10ms):当前时间=" + currentTimestamp + ",上次时间=" + lastTimestamp);}}// 7.3 同一毫秒内:序列号递增if (currentTimestamp == lastTimestamp) {sequence.compareAndSet(MAX\_SEQUENCE, 0); // 序列号超出4095,重置为0int currentSequence = sequence.getAndIncrement();// 同一毫秒内序列号耗尽(理论上4096个/ms,高并发下可能发生)if (currentSequence > MAX\_SEQUENCE) {throw new RuntimeException("同一毫秒内ID生成超出上限(4096个)");}} else {// 7.4 不同毫秒:序列号重置为0sequence.set(0);}// 7.5 更新上次时间戳lastTimestamp = currentTimestamp;// 7.6 拼接ID(按位或运算)return SIGN\_BIT\| ((currentTimestamp - START\_TIMESTAMP) << TIMESTAMP\_SHIFT)\| (dataCenterId << DATA\_CENTER\_SHIFT)\| (workerId << WORKER\_SHIFT)\| sequence.get();}// 测试:生成10个IDpublic static void main(String\[] args) {SnowflakeIdGenerator generator = new SnowflakeIdGenerator(1, 2); // 数据中心1,机器2for (int i = 0; i < 10; i++) {System.out.println(generator.generateId());// 输出示例:1234567890123456789(64位Long,有序递增)}}}
4.3.2 机器 ID 分配方案(ZooKeeper 实现)
雪花算法的机器 ID(数据中心 ID + 节点 ID)需手动分配,避免重复。生产环境推荐用 ZooKeeper 自动分配:
-
服务启动时,向 ZooKeeper 的
/snowflake/worker节点下创建临时顺序节点(如/snowflake/worker/worker-0000000001); -
取节点的顺序号(如 1)作为机器 ID,确保全局唯一;
-
服务下线时,临时节点自动删除,释放机器 ID。
ZooKeeper 机器 ID 分配代码(Java + Curator):
import org.apache.curator.framework.CuratorFramework;import org.apache.curator.framework.CuratorFrameworkFactory;import org.apache.curator.retry.ExponentialBackoffRetry;import org.apache.zookeeper.CreateMode;public class ZkWorkerIdAllocator {// ZooKeeper地址(集群用逗号分隔)private static final String ZK\_ADDRESS = "192.168.1.100:2181,192.168.1.101:2181";// 机器ID节点路径private static final String WORKER\_ID\_PATH = "/snowflake/worker/worker-";// 会话超时时间private static final int SESSION\_TIMEOUT = 5000;// 连接超时时间private static final int CONNECTION\_TIMEOUT = 3000;// 分配机器ID(返回0-31的ID)public static int allocateWorkerId() throws Exception {// 1. 创建ZooKeeper客户端CuratorFramework client = CuratorFrameworkFactory.builder().connectString(ZK\_ADDRESS).sessionTimeoutMs(SESSION\_TIMEOUT).connectionTimeoutMs(CONNECTION\_TIMEOUT).retryPolicy(new ExponentialBackoffRetry(1000, 3)) // 重试策略.build();client.start();// 2. 创建临时顺序节点(自动释放)String nodePath = client.create().creatingParentsIfNeeded() // 父节点不存在则创建.withMode(CreateMode.EPHEMERAL\_SEQUENTIAL) // 临时顺序节点.forPath(WORKER\_ID\_PATH);// 3. 提取机器ID(如nodePath=/snowflake/worker/worker-0000000001 → ID=1)String nodeName = nodePath.substring(WORKER\_ID\_PATH.length());int workerId = Integer.parseInt(nodeName);// 4. 校验机器ID范围(0-31)if (workerId < 0 || workerId > 31) {throw new RuntimeException("机器ID超出范围(0-31):" + workerId);}System.out.println("ZooKeeper分配机器ID成功:" + workerId);return workerId;}// 测试:分配机器IDpublic static void main(String\[] args) throws Exception {allocateWorkerId();}}
4.4 故障案例:雪花算法时钟回拨导致 ID 重复
4.4.1 问题背景
某支付系统用雪花算法生成支付流水号,部署 10 个服务节点。某天凌晨 2 点,由于服务器同步 NTP 时间,2 个节点的时钟回拨了 50ms,导致生成 100 + 个重复流水号,引发对账异常。
4.4.2 根因分析
-
雪花算法依赖服务器本地时间戳,时钟回拨后,
currentTimestamp < lastTimestamp; -
原代码未处理时钟回拨,直接用回拨后的时间戳生成 ID,导致与回拨前的 ID 重复;
-
2 个节点的机器 ID 相同(手动分配时配置错误),进一步加剧重复问题。
4.4.3 解决方案
-
在雪花算法中添加时钟回拨处理(如代码中 “等待时钟追赶” 或 “抛出异常”);
-
改用 ZooKeeper 自动分配机器 ID,避免手动配置错误;
-
服务启动时校验本地时间与 NTP 服务器时间差,若差 > 10ms 则拒绝启动;
-
生成 ID 后添加 “冗余校验”(如存入 Redis,检查 ID 是否已存在,避免重复)。
4.5 避坑总结
✅ 适用场景:高并发(秒杀 / 大促)、需有序 ID、水平扩容的场景(订单 / 支付 / 秒杀);
❌ 不适用场景:无 ZooKeeper / 配置中心、对时钟敏感的场景;
⚠️ 必避坑点:
-
必须处理时钟回拨(核心风险点),避免 ID 重复;
-
机器 ID 需全局唯一(推荐用 ZooKeeper/Nacos 分配);
-
起始时间戳需固定(避免不同服务节点起始时间不同导致 ID 重复);
-
高并发下需注意 “同一毫秒序列号耗尽”(可增大序列号位数或拆分业务)。