自己怎么开发网站网站设置反爬虫的主要原因
Impala,它是 Cloudera 开发的开源 实时 SQL 查询引擎,专为 Hadoop 设计。与 Presto 类似,Impala 用于交互式分析,但架构和设计理念有所不同。以下是 Impala 的核心特点和工作原理:
一、Impala 核心架构
1. 组件组成
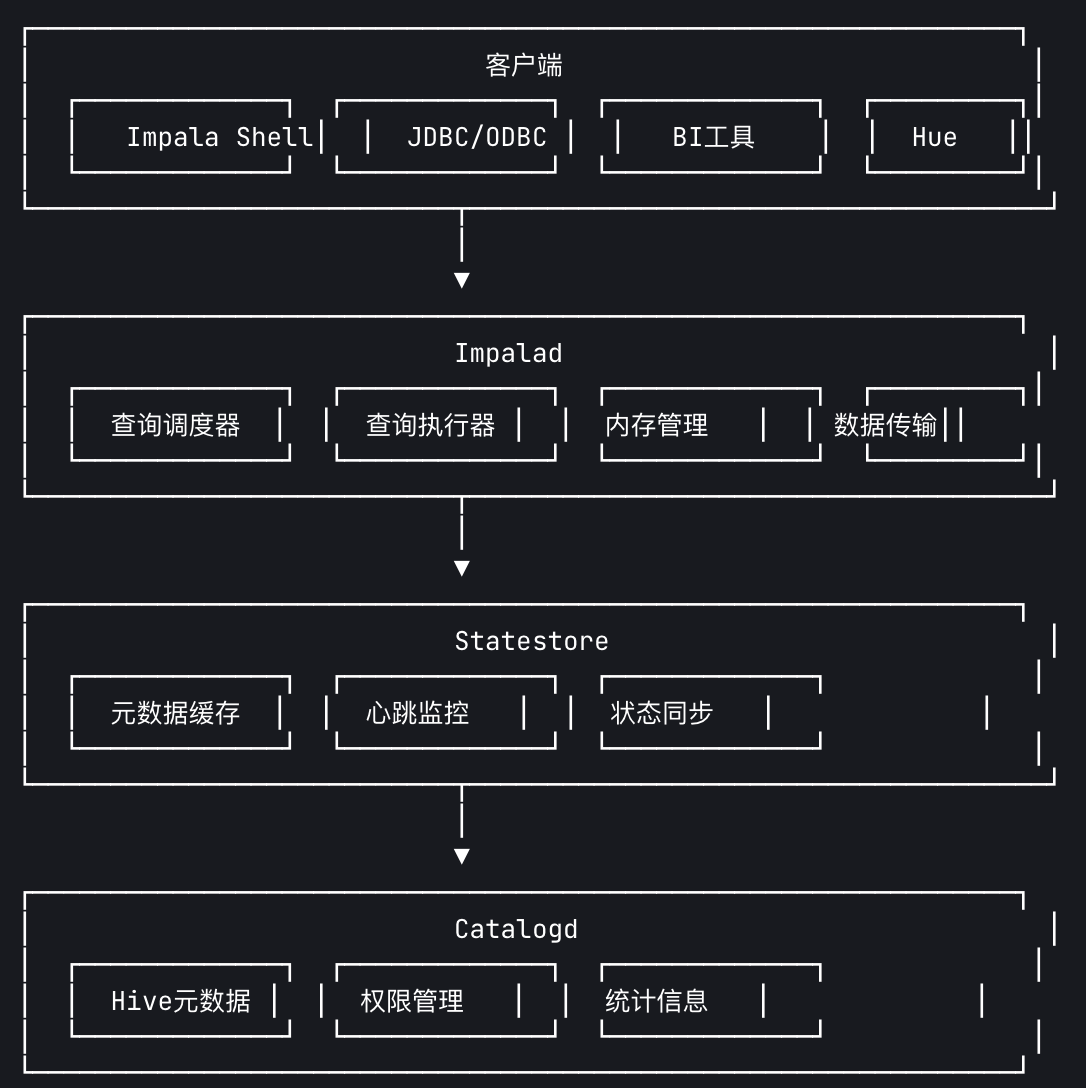
2. 关键组件
- Coordinator:
- 接收客户端查询请求,解析 SQL,生成查询计划。
- 调度查询任务到 Worker 节点执行。
- 聚合查询结果并返回给客户端。
- Worker:
- 执行 Coordinator 分配的任务,处理数据分片。
- 通过 Exchange Service 进行节点间数据传输。
- Connector:
- 插件式数据源连接器,支持 Hive、MySQL、Kafka、S3 等。
- 负责与数据源交互,提供元数据和数据访问接口。
二、Presto 的工作流程
- 客户端发送查询:
-
SELECT user_id, COUNT(*) FROM hive.orders JOIN mysql.users USING (user_id) WHERE order_date > '2023-01-01' GROUP BY user_id;
- Coordinator 处理查询:
- 解析 SQL:将 SQL 转换为逻辑查询计划。
- 优化计划:应用查询优化规则(如谓词下推、聚合提前)。
- 生成物理计划:将逻辑计划转换为可执行的任务图。
- Worker 执行任务:
- 读取数据源(如 Hive 表、MySQL 表)。
- 执行过滤、连接、聚合等操作。
- 通过 Exchange Service 交换中间结果。
- 结果返回:
- Coordinator 聚合所有 Worker 的结果并返回给客户端。
三、数据模型与 SQL 支持
1. 数据模型
- Catalog:对应一个数据源(如 hive、mysql)。
- Schema:类似数据库,组织表和视图。
- Table:物理表或外部表。
- View:逻辑视图,不存储数据。
2. SQL 支持
- 标准 SQL:支持大部分 ANSI SQL 语法。
- 高级功能:窗口函数、JSON 处理、正则表达式、JOIN 优化。
- 扩展函数:数学函数、字符串函数、日期函数、聚合函数等。
四、部署与配置
1. 单机部署(测试环境)
# 下载Presto
wget https://repo1.maven.org/maven2/io/prestosql/presto-server/350/presto-server-350.tar.gz
tar -zxvf presto-server-350.tar.gz
cd presto-server-350# 创建配置目录
mkdir etc# 配置jvm.config(示例)
cat > etc/jvm.config <<EOF
-server
-Xmx16G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
EOF# 配置config.properties(Coordinator和Worker共用)
cat > etc/config.properties <<EOF
coordinator=true
node-scheduler.include-coordinator=true
http-server.http.port=8080
query.max-memory=50GB
query.max-memory-per-node=1GB
discovery-server.enabled=true
discovery.uri=http://localhost:8080
EOF# 配置catalog(以Hive为例)
mkdir etc/catalog
cat > etc/catalog/hive.properties <<EOF
connector.name=hive-hadoop2
hive.metastore.uri=thrift://hive-metastore:9083
EOF# 启动Presto
bin/launcher start2. 集群部署(生产环境)
- Coordinator 节点:1-3 个(高可用)。
- Worker 节点:根据数据量和查询负载调整(通常 5-100 个)。
- 配置要点:
-
# Coordinator专用配置 coordinator=true node-scheduler.include-coordinator=false # 通常不参与计算# Worker专用配置 coordinator=false
五、性能优化
1. 资源调优
- 内存配置:
-
query.max-memory=100GB # 单个查询总内存限制 query.max-memory-per-node=10GB # 单节点内存限制 task.max-worker-threads=20 # 每个Worker的最大线程数
并行度调整:
node-scheduler.max-splits-per-node=1000 # 每个节点最大分片数2. 查询优化
- 谓词下推:确保过滤器尽可能早地应用。
- JOIN 优化:
-
-- 小表广播优化 SELECT /*+ BROADCAST(r) */ * FROM orders o JOIN region r ON o.region_id = r.id;
分区过滤:
SELECT * FROM orders WHERE order_date >= '2023-01-01';
-- 确保表按order_date分区,避免全表扫描六、与其他系统对比
| 特性 | Presto | Hive | Spark SQL |
|---|---|---|---|
| 查询类型 | 交互式分析 | 批处理 | 批处理 / 流处理 |
| 查询延迟 | 亚秒级到分钟级 | 分钟级到小时级 | 秒级到分钟级 |
| 数据量支持 | PB 级 | PB 级 | TB 级到 PB 级 |
| 数据源支持 | 多源混合查询 | 主要支持 Hive | 需通过连接器适配 |
| 架构设计 | 无共享架构 | MR/Tez/Spark 引擎 | 基于内存计算 |
| 适用场景 | 即席查询、BI 分析 | 离线 ETL | 复杂 ETL、机器学习 |
七、常见问题与解决方案
1. OutOfMemoryError
- 原因:查询内存超过限制。
- 解决:
- 增加
query.max-memory-per-node。 - 优化查询,减少数据传输(如添加过滤条件)。
- 增加
2. 查询性能差
- 分析工具:
-
EXPLAIN (TYPE DISTRIBUTED, FORMAT GRAPHVIZ) SELECT * FROM orders JOIN customers ON orders.customer_id = customers.id;
- 优化方向:
- 检查数据分布是否倾斜。
- 调整 JOIN 策略(如广播小表)。
3. 数据源连接失败
- 检查配置:
-
# 以Hive连接器为例 hive.metastore.uri=thrift://hive-metastore:9083 hive.config.resources=/etc/hadoop/conf/core-site.xml,/etc/hadoop/conf/hdfs-site.xml
测试连通性
telnet hive-metastore 9083八、最佳实践
- 资源分配:
- 为 Coordinator 和 Worker 分配专用节点,避免资源竞争。
- 监控节点资源使用,避免 CPU / 内存瓶颈。
- 数据分区:
- 对大表按时间或常用过滤字段分区。
- 使用分桶(Bucketing)提高 JOIN 性能。
- 定期维护:
- 清理过期数据,避免查询扫描无用数据。
- 统计信息收集:
ANALYZE table_name;
- 安全配置:
- 启用 LDAP 认证:
-
http-server.authentication.type=PASSWORD password.authenticator.name=ldap ldap.url=ldap://ldap.example.com ldap.user-base-dn=ou=people,dc=example,dc=com
细粒度权限控制:
GRANT SELECT ON hive.default.orders TO role analyst;通过以上配置和优化,Presto 可以高效处理 PB 级数据的交互式分析查询,成为企业数据湖的核心查询引擎。