Week 2 - Algorithm efficiency + Searching/Sorting
一、Learning Outcomes
1. Polynomial time and exponential time algorithms
• 多项式时间算法(Polynomial time algorithms):这些算法的时间复杂度是以输入大小的多项式为度量的。例如,O(n^2)、O(n^3)等。这类算法的运行时间随着输入规模增大而增加,但通常增长速度较为缓慢,适合处理大规模数据。(冒泡排序、插入排序)
• 指数时间算法(Exponential time algorithms):这些算法的时间复杂度是以输入大小的指数为度量的,如O(2^n),O(n!)等。随着输入规模的增大,算法的运行时间呈指数增长,处理规模较大的问题时,可能会变得不可行。(穷举搜索、一些动态规划算法(在特定情况下))。
2. Asymptotic analysis of algorithms(算法的渐近分析)
渐进分析(Asymptotic Analysis) 是指分析算法性能(特别是时间和空间复杂度)随输入规模增长时的变化规律。它帮助我们理解算法在输入数据量增大时的表现,并确定其最坏情况、最好情况和平均情况的复杂度。
3. Searching/sorting algorithms and their time complexities
• 搜索算法(Searching algorithms):用于在数据结构中查找特定元素。
线性查找(Linear Search)、二分查找(Binary Search)
• 排序算法(Sorting algorithms):用于将数据结构中的元素按一定顺序排列。
冒泡排序(Bubble Sort)、选择排序(Selection Sort)、快速排序(Quick Sort)
二、 Linear Search
1. 问题描述
• 输入:一个包含 n 个数的序列 a0, a1, ..., an-1,以及一个目标数字 X。
• 输出:判断目标数字 X 是否在序列中。
2. Algorithm (Linear Search)
• 线性查找是一种简单的查找算法,适用于无序的数据结构(如数组、链表等)。
• 线性查找的工作原理是逐个检查序列中的每个元素,直到找到目标值或者检查完所有元素。

3. 时间复杂度分析
• 线性查找的时间复杂度是 O(n),其中 n 是序列中的元素个数。最坏情况下,可能需要检查序列中的每个元素,才能找到目标值或者确定目标值不存在。

三、Binary Search
• 输入:一个已经按升序排列的长度为 n 的数列 a0, a1, ..., an-1 和一个目标值 X。
• 二分查找要求输入的数列必须是有序的(升序排列 in ascending order)。如果数列是无序的,二分查找无法直接应用。the sequence of numbers is pre-sorted


+1 是为了处理在最后一步查找时,判断剩余元素是否为目标元素的情况。
在大 O 记法中,对数底数通常可以省略,因为对时间复杂度的分析关注的是增长的趋势,而不是具体的常数因子。实际上,任何以常数为底的对数都只相差一个常数倍,因此 它们的渐近增长是一样的。
”-time” 这个后缀通常是用来描述算法的时间复杂度的单位
四、Search for a pattern
1. String Matching
Given a string of n characters called the text and a string of m characters (m<=n) called the pattern.
We want to determine if the text contains a substring matching the pattern.
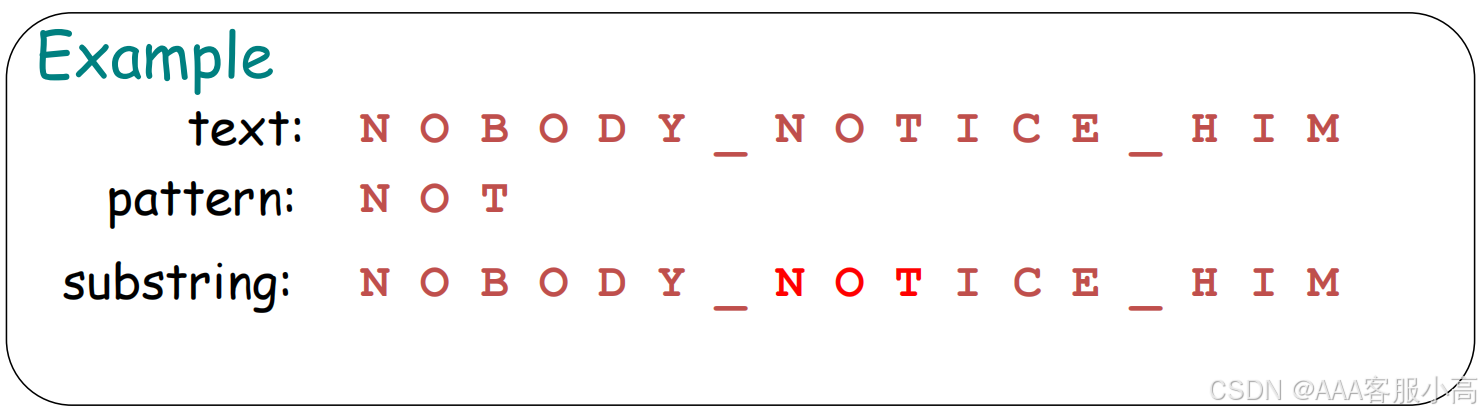
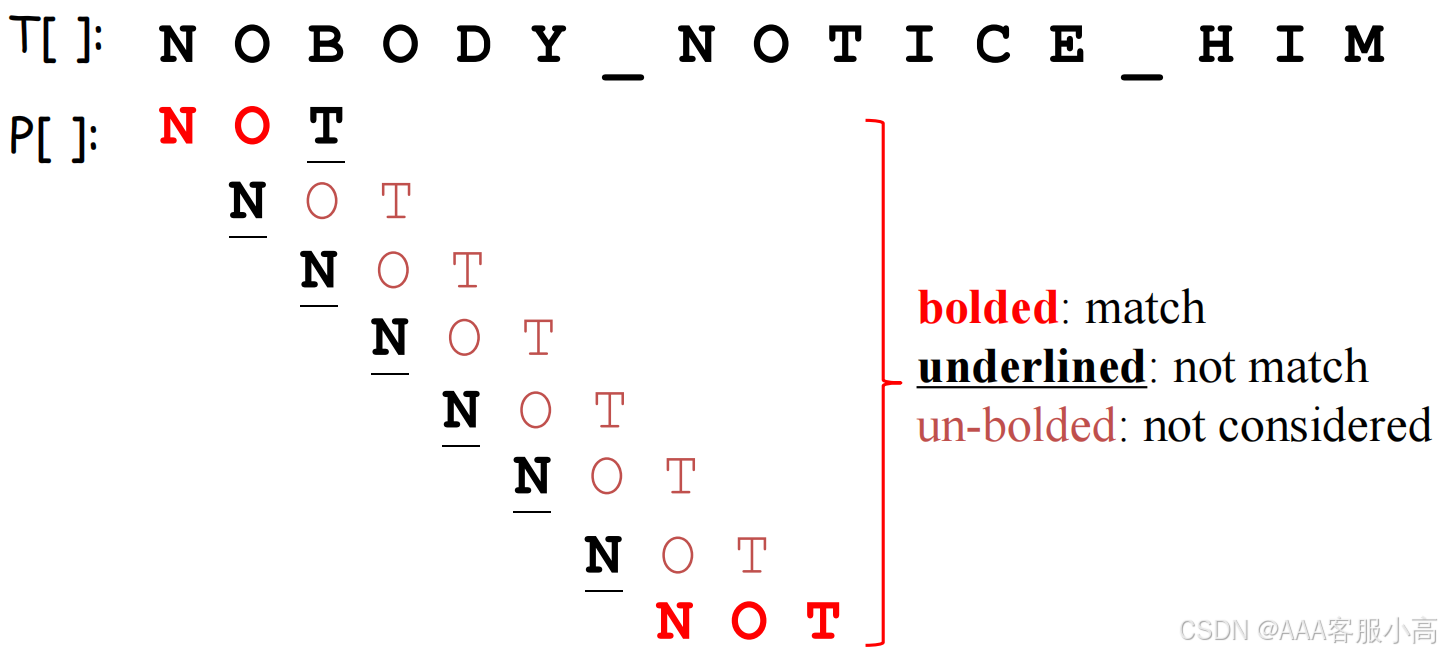
For each position i, it checks whether the pattern P[0..m-1] appears in T[i..i+m-1]

2. Match for all positions

3. Time Complexity

五、Sorting
Input: a sequence of n numbers a0 , a1 , …, an-1
Output: arrange the n numbers into ascending order
常见的排序算法:
插入排序、选择排序、冒泡排序、归并排序、快速排序。
insertion sort, selection sort, bubble sort, merge sort, quick sort
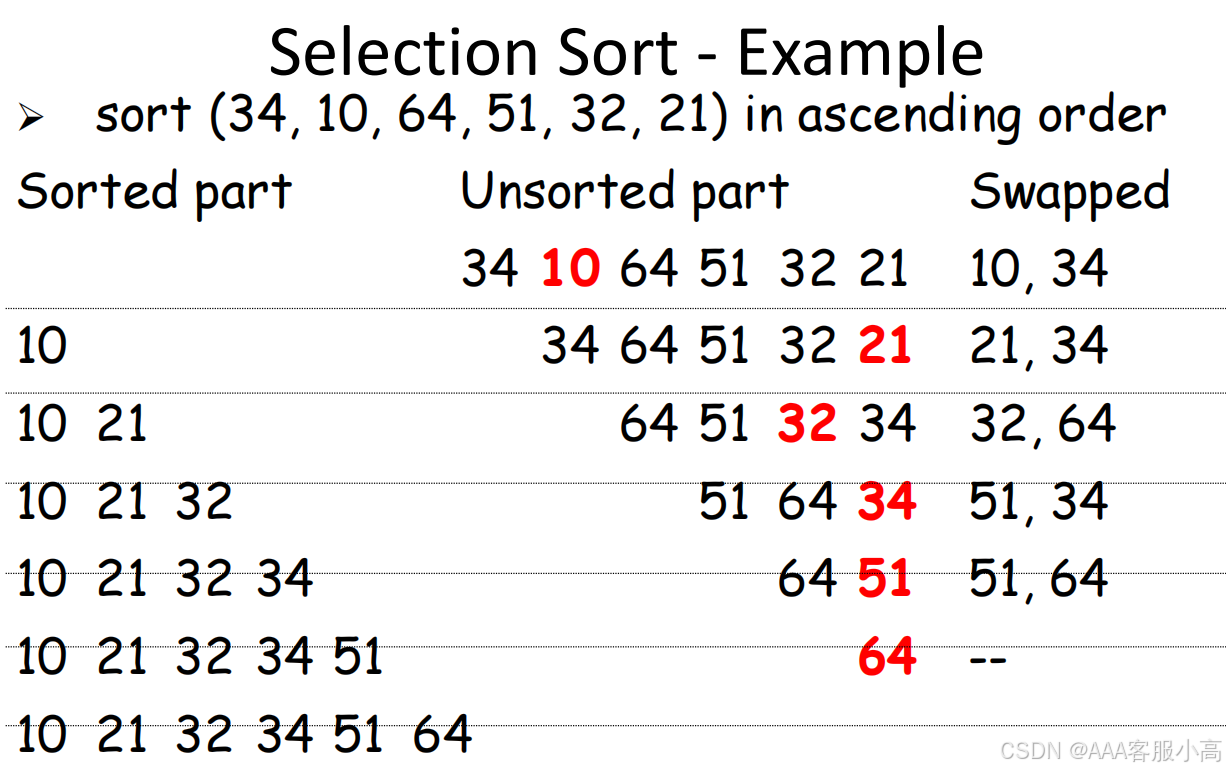
六、Selection Sort
1. 查找输入序列中的最小元素
2. 将最小元素从输入序列中删除
3. 将最小元素添加到结果序列中
4. 重复直到输入序列为空

七、Bubble Sort
1. 从最后一个元素开始,交换相邻元素
2. 当到达第一个元素时,第一个元素是最小的
• 在一次遍历(称为一轮冒泡)结束后,最大的元素会被交换到数组的最后一位,这样这一轮结束时,最大的元素已经在正确的位置。
3. 重复上述步骤,直到剩下的元素完全排序
八、Insertion Sort
• 插入排序的基本思想是:从第二个元素开始,依次将每个元素插入到已排序部分中的正确位置。


选择排序、冒泡排序和插入排序
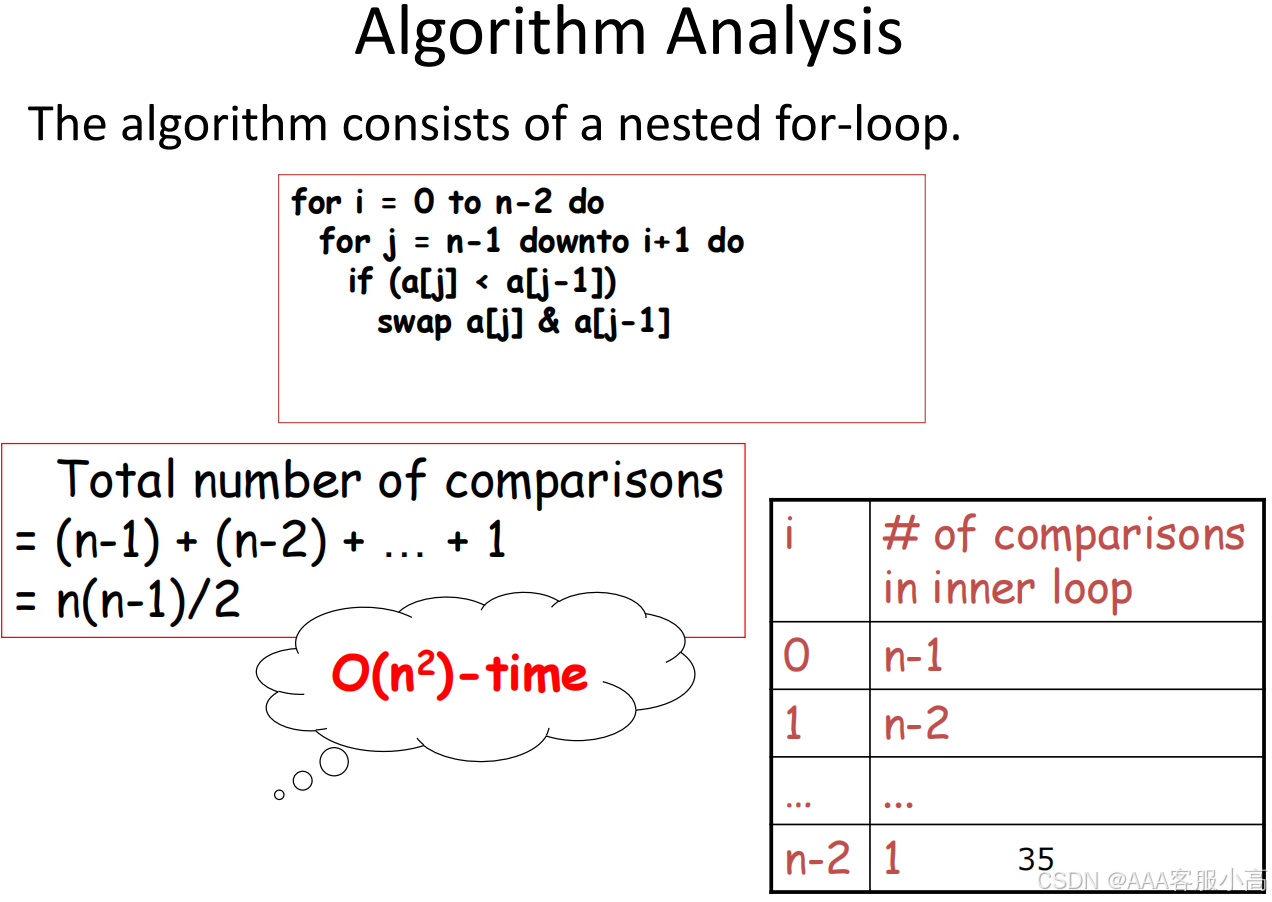
• 这三种排序算法在最坏情况下的时间复杂度都是 O(n²)。也就是说,在处理大规模数据时,这些算法的性能较差,尤其是当数据规模增大时,它们的运行时间会显著增加。
快速排序(Quick Sort)、归并排序(Merge Sort) 和 堆排序(Heap Sort),这些排序算法在最坏情况下的时间复杂度都为 O(n log n)
the time complexity of the fastest comparison-based sorting algorithm
九、exponential time algorithms
1. Traveling Salesman Problem
输入: 有 n 个城市。
输出: 从一个特定城市出发,找到一条最短路径,这条路径要求:
• 每个城市都访问一次且仅访问一次。
• 在访问完所有城市后,再返回到出发的城市。
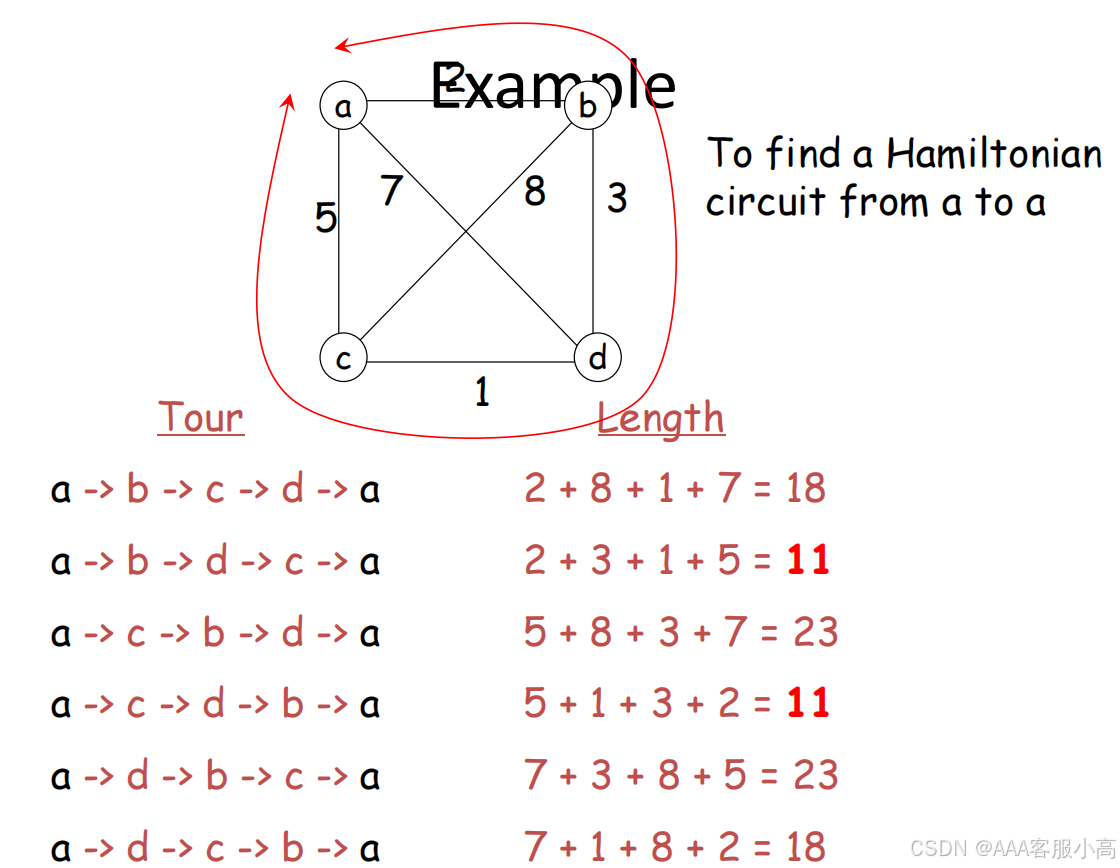
哈密顿回路(Hamiltonian Circuit):
• 哈密顿回路是图论中的一个经典问题,指的是在图中寻找一条回路,这条回路通过每个节点一次且仅一次,并最终回到起点。
• 对应到旅行商问题中,就是要求找到一个哈密顿回路,其中回路的总长度最短。
A Hamiltonian circuit can be represented by a sequence of n+1 cities v1 , v2 , …, vn , v1 , where the first and the last are the same, and all the others are distinct.
(n-1)! = (n-1)(n-2)…1
N.B.: (n-1)! is exponential in terms of n
Exhaustive search approach:(n-1)!
Find all tours in this form, compute the tour length and find the shortest among them.
2. Knapsack Problem
输入:给定n个物品,其重量分别为w1, w2, …, wn,以及价值分别为v1, v2, …, vn,还有一个容量为W的背包。
输出:找到能够装入背包的最有价值的物品子集。
应用:一架运输机需要在不超过其容量的情况下,将最有价值的一组物品运送到一个偏远地点。
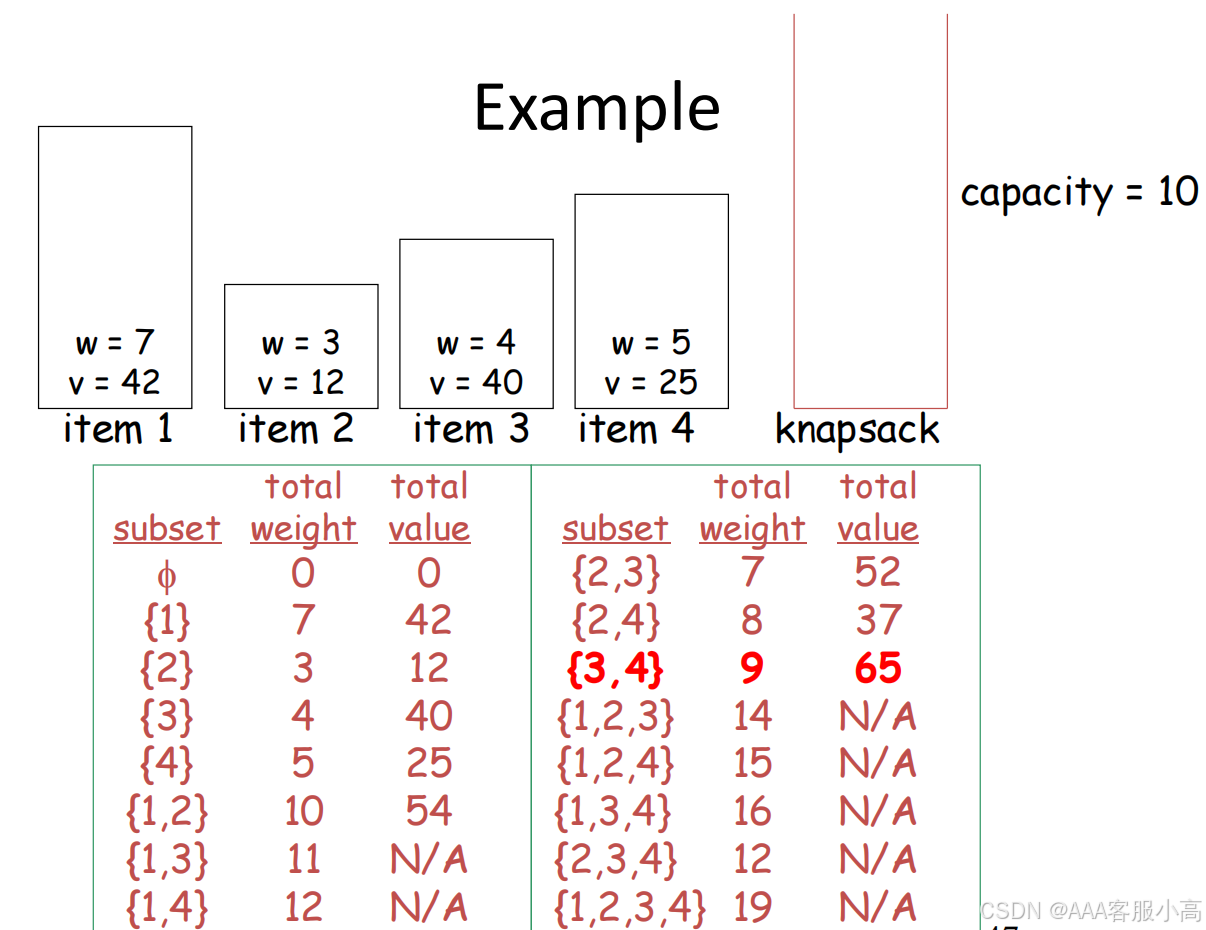
背包问题的暴力搜索法(Exhaustive Search Approach)
• 考虑所有可能的子集:给定 n 个物品,暴力搜索方法会尝试所有的子集。对于每个子集,计算该子集的总重量,并找出所有符合条件(即总重量不超过背包容量)的子集的总价值。
• 最后,选择那些满足背包容量限制的子集中价值最大的一个,作为解决方案。
所有物品的子集数目为 2^n。这是因为每个物品都有 2 种状态(在背包中或不在背包中),所以物品数量为 n时,所有可能的组合数是 2^n