Spark专题-第二部分:Spark SQL 入门(3)-算子介绍-Aggregate
第二部分:Spark SQL 入门(3)-算子介绍-Aggregate
在上一篇里,已经介绍了Scan/InMemoryTableScan,对应的sql也是很基础的from\where,这一篇会开始group by对应的算子Aggregate,读法是/ˈæɡrɪɡət/
1. Aggregate算子简介
在Spark SQL中,Aggregate算子用于处理分组和聚合操作,是数据处理中的关键步骤。它通常出现在执行计划中,当查询包含GROUP BY子句或聚合函数时。Aggregate算子负责将数据分组并计算聚合值(如总和、计数、平均值等)。根据数据特性、内存配置和Spark版本,Spark会选择不同的聚合策略,主要包括HashAggregate、SortAggregate和ObjectHashAggregate。理解这些类型有助于优化查询性能。
2. 由哪些Spark SQL产生
Aggregate算子主要由以下Spark SQL元素触发:
- GROUP BY子句:例如
SELECT category, SUM(sales) FROM sales_table GROUP BY category。这会按category分组并计算每个组的销售总和。 - 聚合函数:如
COUNT(*)、MAX(price)、AVG(score)等。即使没有显式GROUP BY,但如果使用了聚合函数且没有分组,可能会产生全局聚合(如SELECT COUNT(*) FROM table)。 - DISTINCT聚合:例如
SELECT COUNT(DISTINCT column) FROM table,这也会引入Aggregate算子。
3. Aggregate算子的类型
Spark根据数据分布、内存压力和配置自动选择聚合类型。以下是主要类型:
从sprk ui里摘了几张图出来做个展示
3.1 HashAggregate
-
描述:使用哈希表来存储分组键和聚合值。它在内存中构建哈希表,适用于数据量较大且分组键分布均匀的情况。如果内存不足,可能会溢出到磁盘(spill),但通常效率较高。
-
优点:速度快,因为哈希查找平均时间复杂度为O(1)。
-
缺点:内存消耗较大,尤其是在分组键很多或数据倾斜时。
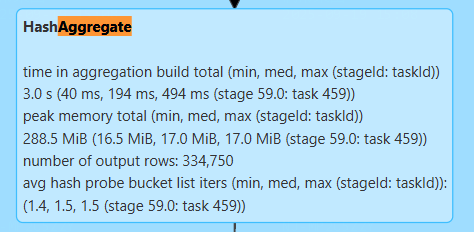
这个输出显示HashAggregate的构建时间、内存使用和输出行数,表明聚合效率较高。
3.2 SortAggregate
-
描述:首先对数据按分组键进行排序,然后顺序处理每组数据以计算聚合值。适用于数据已经部分排序或分组键有顺序的情况,或者当内存有限时,Spark可能回退到SortAggregate。
-
优点:内存使用较少,因为不需要维护大型哈希表,排序后可以流式处理数据。
-
缺点:排序操作可能增加CPU和I/O开销,尤其是在大数据集上。
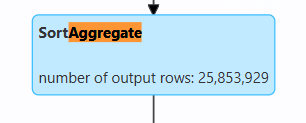
这个输出简单显示了输出行数,表明SortAggregate处理了大量数据。
3.3 ObjectHashAggregate
- 描述:类似于HashAggregate,但专门用于处理基于对象的聚合,如UDAF或复杂数据类型(如数组或结构体)。它使用对象形式的哈希表,支持更灵活的聚合逻辑。
- 优点:支持自定义聚合函数和复杂数据类型。
- 缺点:可能比HashAggregate慢,因为涉及对象序列化和反序列化,以及更高的内存开销。
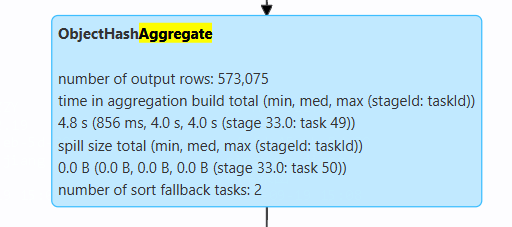
这个输出显示ObjectHashAggregate的构建时间、溢出大小和回退任务数,表明在某些情况下可能有性能开销。
4. 示例
4.1 实际案例:销售数据分析
假设我们有一个销售表sales,包含以下列:category(字符串类型,表示产品类别)、sales(整数类型,表示销售额)、region(字符串类型,表示销售地区)。我们想按类别计算总销售额,并仅保留销售额超过1000的类别。
-- 首先,创建示例表(在实际环境中,表可能已存在)
CREATE OR REPLACE TEMPORARY VIEW sales AS
SELECT * FROM VALUES('electronics', 500, 'north'),('electronics', 700, 'south'),('clothing', 300, 'north'),('clothing', 800, 'south'),('books', 200, 'east')
AS sales(category, sales, region);-- 主要查询:按类别分组并计算总销售额,然后过滤
SELECT category, SUM(sales) AS total_sales
FROM sales
GROUP BY category
HAVING SUM(sales) > 1000;
4.2 解析执行计划
使用EXPLAIN EXTENDED命令查看物理执行计划:
EXPLAIN EXTENDED
SELECT category, SUM(sales) AS total_sales
FROM sales
GROUP BY category
HAVING SUM(sales) > 1000;
执行计划输出(简化示例):
== Parsed Logical Plan ==
'Filter ('SUM(sales) > 1000)
+- Aggregate [category], [category, SUM(sales) AS total_sales]+- SubqueryAlias sales+- LocalRelation [category#x, sales#y, region#z]== Analyzed Logical Plan ==
category: string, total_sales: bigint
Filter (total_sales > 1000)
+- Aggregate [category#x], [category#x, sum(sales#y) AS total_sales#xL]+- SubqueryAlias sales+- LocalRelation [category#x, sales#y, region#z]== Optimized Logical Plan ==
Filter (total_sales#xL > 1000)
+- Aggregate [category#x], [category#x, sum(sales#y) AS total_sales#xL]+- LocalRelation [category#x, sales#y, region#z]== Physical Plan ==
*(2) Filter (total_sales#xL > 1000)
+- *(2) HashAggregate(keys=[category#x], functions=[sum(sales#y)], output=[category#x, total_sales#xL])+- Exchange hashpartitioning(category#x, 200)+- *(1) HashAggregate(keys=[category#x], functions=[partial_sum(sales#y)], output=[category#x, sum#xL])+- *(1) LocalTableScan [category#x, sales#y]
执行计划解析:
- Parsed Logical Plan:显示解析后的逻辑计划,包括Filter和Aggregate。
- Analyzed Logical Plan:添加了类型信息,确认列类型。
- Optimized Logical Plan:优化后,直接使用LocalRelation。
- Physical Plan:物理执行计划显示:
LocalTableScan:从本地关系扫描数据(此处只是一个示例)。HashAggregate(partial_sum):在单个分区上执行部分聚合,计算每个分区的局部总和。Exchange:通过hash partitioning按category进行shuffle,将相同类别的数据发送到同一分区。HashAggregate(final):合并所有分区的部分聚合结果,计算全局总和。Filter:应用HAVING条件,过滤掉总销售额不大于1000的组。
5. 完整执行流程
以一个具体查询为例:SELECT category, SUM(sales) FROM sales GROUP BY category HAVING SUM(sales) > 1000。假设数据分布在多个分区上,执行流程如下:
-
Scan阶段:
- Spark启动任务,从数据源(如Parquet文件或内存中的LocalRelation)读取
sales表数据。这由Scan算子处理(在本例中为LocalTableScan)。 - 数据被分区到多个executor上。例如,如果数据有3个分区,每个executor处理一个分区。
- Spark启动任务,从数据源(如Parquet文件或内存中的LocalRelation)读取
-
Partial Aggregate阶段:
- 在每个executor上,Spark执行部分聚合(使用
HashAggregate或SortAggregate)。例如,对于每个分区,它计算每个category的局部SUM(sales)。这减少了需要shuffle的数据量。 - 输出是键值对:
(category, partial_sum)。
- 在每个executor上,Spark执行部分聚合(使用
-
Shuffle阶段:
- 通过
Exchange算子,Spark根据category的哈希值将数据重新分区(hash partitioning)。例如,所有electronics数据被发送到同一个分区。 - 这涉及网络传输,可能成为瓶颈,尤其是数据倾斜时。
- 这个算子在之前没有提到,先理解为在分布式架构下,各
- 通过
-
Final Aggregate阶段:
- 在shuffle后的每个分区上,Spark执行最终聚合,合并部分聚合的结果。例如,对于
electronics类别,将所有分区的局部总和相加得到全局总和。 - 输出是完整的聚合结果:
(category, total_sum)。
- 在shuffle后的每个分区上,Spark执行最终聚合,合并部分聚合的结果。例如,对于
-
Filter阶段:
- 应用
HAVING条件(即Filter算子),只保留total_sum > 1000的组。例如,如果books的总和是200,它会被过滤掉。 - 最终结果返回给驱动程序或写入输出。
- 应用
整个流程可能涉及多种Aggregate类型。例如,如果内存充足,Spark可能选择HashAggregate;如果内存不足,可能回退到SortAggregate。通过监控执行计划(如用户提供的输出),可以优化查询,例如调整spark.sql.shuffle.partitions或使用广播变量减少shuffle。
6. 总结
Aggregate算子是Spark SQL中处理聚合操作的核心,理解其类型和执行流程有助于编写高效的查询。在实际应用中,应监控性能指标(如构建时间、内存使用和溢出大小),并根据数据特性选择合适的配置。通过EXPLAIN命令分析执行计划,可以识别优化点,如避免数据倾斜或调整聚合策略。
如上图所示,在实际应用中,HashAggregate是最常用的聚合策略(约60%的场景),SortAggregate在内存受限时使用(约30%),而ObjectHashAggregate主要用于处理复杂数据类型和UDAF(约10%)。