AI之EBT:《Energy-Based Transformers are Scalable Learners and Thinkers》的翻译与解读
AI之EBT:《Energy-Based Transformers are Scalable Learners and Thinkers》的翻译与解读
导读:这篇论文提出了一种名为“能量转换器”(EBTs)的创新模型范式,它通过将“思考”过程建模为在一个由模型自身学习的能量景观上的优化搜索,成功地让“系统二思考”能力从无监督学习中自然涌现。EBTs的核心是训练一个能够评估任何“输入-预测”对合理性的验证器,并在推理时通过迭代梯度下降来寻找最合理的预测。实验结果有力地证明,EBTs在学习效率(预训练扩展性)和思考能力(推理时性能提升)上均超越了现有的主流架构,并展现出卓越的分布外泛化能力。总而言之,EBTs通过统一学习与思考,为构建更强大、更通用、更具泛化能力的下一代基础模型开辟了一条极具前景的新道路。
>> 背景痛点
● 现有模型的“思考”局限: 当前的AI模型(如标准Transformer、RNN)擅长快速、直觉式的“系统一”任务,但在需要慢速、审慎、分析性推理的“系统二”任务(如复杂数学、多步推理)上表现不佳。它们每个预测步骤的计算量是固定的,无法在难题上“投入更多思考”。
● 特定领域解决方案的泛化难题: 近期一些“推理模型”通过强化学习等方法提升了在数学、编程等领域的表现,但这些方法通常依赖于易于验证答案的特定领域(如存在明确规则的奖励函数),难以泛化到更广泛的问题(如写作),有时甚至会损害其他任务的性能。
● 主流架构的内在缺陷:
●● Transformer/RNN: 缺乏动态分配计算资源、在连续空间中可靠地建模不确定性、以及对自身预测进行显式验证这三项关键的“系统二”认知能力。
●● Diffusion Models (扩散模型): 虽然可以通过增加去噪步数来增加计算,但它们没有被训练为显式的验证器,通常需要外部模型来进一步提升性能,并且无法在思考过程的每一步给出预测的置信度(能量值)。
● 核心研究挑战: 论文旨在回答一个核心问题:“我们能否完全依赖无监督学习来发展出通用的‘系统二思考’能力?” 这将使模型能够在任何模态和任何问题上进行思考,而无需额外的人工、奖励或模型监督。
>> 具体的解决方案
● 核心模型:能量转换器 (EBTs): 论文提出了一种名为“能量转换器”(Energy-Based Transformers)的新型模型,它属于能量模型(EBMs)的一类。
● 模型功能定位:学习成为一个“验证器”: EBTs的核心功能是学习一个能量函数,该函数可以为任意“输入上下文”和“候选预测”的组合分配一个能量标量值。能量越低,代表该预测与上下文的兼容性越高(即可能性越大)。
● 两种架构变体:
●● 自回归EBT (Autoregressive EBT): 类似于GPT架构,用于语言建模、视频预测等序列生成任务。
●● 双向EBT (Bidirectional EBT): 类似于BERT和Diffusion Transformer (DiT),拥有双向注意力机制,适用于图像去噪、文本填充等任务。
>> 核心思路步骤
● 核心思想:将“思考”重构为优化过程: EBT范式将预测过程从“一次性生成”转变为“迭代优化”。模型不再直接输出答案,而是通过搜索其学习到的能量景观,找到能量最低(即最合理)的预测。
● 第一步:学习验证 (Learning to Verify): 在训练阶段,EBT被训练成一个验证器。其目标是学习一个能量景观,使得真实的“上下文-预测”对处于能量低谷,而错误的组合则处于能量高地。
● 第二步:通过能量最小化进行“思考”和预测 (Thinking and Prediction via Energy Minimization):
●● 初始化: 预测从一个随机状态(如随机噪声向量)开始。
●● 迭代优化: 模型计算当前预测的能量值,然后通过能量对预测本身的梯度进行下降,从而逐步修正预测,使其向能量更低的方向移动。这个迭代优化的过程被诠释为模型的“思考”过程。
●● 收敛输出: 当预测的能量值收敛或达到预设的步数后,最终得到的低能量预测即为模型的输出。
● 关键技术:能量景观正则化 (Energy Landscape Regularization): 为了让模型学习到平滑且易于优化的能量景观,从而涌现出强大的思考能力,论文采用了三种关键的正则化技术:
●● 重放缓冲区 (Replay Buffer): 模拟更长的优化轨迹,帮助定义能量最低点附近的景观。
●● Langevin动力学 (Langevin Dynamics): 在优化步骤中加入少量随机噪声,鼓励模型探索能量景观,避免陷入局部最优。
●● 随机化优化路径: 通过随机化梯度下降的步长和步数,提升模型的泛化能力。
>> 优势
● 卓越的学习可扩展性 (Superior Learning Scalability): 实验表明,EBTs在预训练过程中的扩展速度(Scaling Rate)比主流的Transformer++配方高出最多35%,涵盖了数据量、批量大小、模型深度、参数量和计算量等多个维度。这表明EBTs具有更高的数据和计算效率。
● 强大的“系统二思考”能力 (Powerful System 2 Thinking): 在推理时,EBTs可以通过“思考更长时间”(增加优化步数)和“自我验证”(生成多个候选并选择能量最低的)来显著提升性能(语言任务提升高达29%),而标准Transformer不具备这种在单次预测上动态增加计算的能力。
● 更强的泛化能力 (Better Generalization): EBTs在分布外(OOD)数据上表现更佳。思考带来的性能增益随着数据分布差异的增大而增强。值得注意的是,即使在预训练指标稍差的情况下,EBTs在下游任务上的表现仍能超越Transformer++,证明其泛化能力更强。
● 跨模态与问题的通用性 (Modality and Problem Agnostic): 该框架不局限于特定数据类型或任务,已成功应用于离散的文本模态和连续的视觉模态,以及自回归和双向两种任务范式。
● 无监督涌现思考能力 (Unsupervised Emergence of Thinking): 模型的思考能力完全从无监督的预训练中自然产生,无需依赖任何额外的监督信号(如奖励模型),使其应用范围更广。
>> 结论和观点
● EBT是更高效的学习者: 实验证明,EBT在预训练阶段比Transformer++扩展得更快,尤其是在数据效率上。这意味着在同等数据量下,EBT能学得更好,这在高质量数据日益稀缺的背景下极具价值。
● 思考能力可扩展且对OOD至关重要: EBT的思考能力会随着训练规模的增加而变强。并且,任务越偏离训练分布(OOD程度越高),系统二思考带来的性能提升就越显著,这为解决模型的泛化难题提供了有效途径。
● 验证比生成更易泛化: 论文的核心观点是,EBT之所以表现优越,是因为它学习的是“验证”而非直接“生成”。在计算理论中,验证一个解通常比从头生成一个解更容易,因此学习验证任务能带来更好的泛化性。
● EBT能更好地理解其生成内容: 在图像去噪任务中,双向EBT不仅效果优于强大的Diffusion Transformer(DiT),其学习到的图像表征在下游分类任务上的准确率更是高出近10倍。这表明EBT在生成的同时,对内容本身形成了更深刻的理解。
● 能量值可用于不确定性建模: EBT学习到的能量值与预测的不确定性高度相关。对于难预测的样本,模型会赋予更高的能量。这一特性使其能够在连续空间中自然地进行不确定性估计,为模型“知其不知”和自适应调整计算资源提供了基础。
● 采用能量景观正则化技术: 论文强调,为了在预训练中培养出强大的系统二思考能力,使用重放缓冲区、Langevin动力学(随机噪声)和随机化优化路径等正则化技术是至关重要的。
目录
《Energy-Based Transformers are Scalable Learners and Thinkers》的翻译与解读
Abstract
1、Introduction
Figure 1:Autoregressive Architecture Comparison. (a) Autoregressive (AR) Transformer is the most common, with (b) RNNs becoming more popular recently [22, 23]. (c) Diffusion Transformers [26] (which are often bidirectional but can also be autoregressive) are the most similar to EBT, being able to dynamically allocate computation during inference, but predict the noise rather than the energy [27, 28]. Consequently, diffusion models cannot give unnormalized likelihood estimates at each step of the thinking process, and are not trained as explicit verifiers, unlike EBTs.图 1:自回归架构比较。(a)自回归(AR)Transformer 是最常见的,(b)最近 RNN 变得更受欢迎[22, 23]。(c)扩散 Transformer [26](通常是双向的,但也可以是自回归的)与 EBT 最为相似,能够在推理过程中动态分配计算,但预测的是噪声而非能量[27, 28]。因此,扩散模型无法在思维过程的每一步给出未归一化的似然估计,也不像 EBT 那样作为显式验证器进行训练。
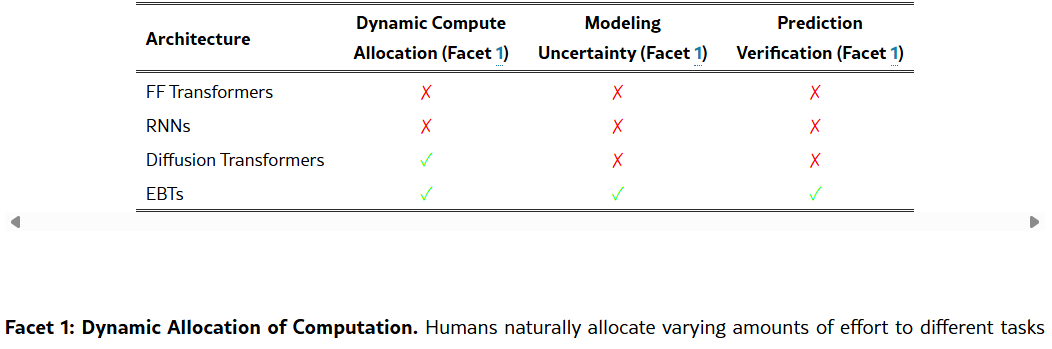
Table 1:Architectures and Cognitive Facets. For each prediction, Feed Forward (FF) Transformers and RNNs generally3 have a finite amount of computation. While diffusion models have potentially more computation during inference by increasing the number of denoising steps, they do not learn to explicitly verify or estimate uncertainty for predictions. EBMs can use a dynamic amount of computation during inference by iterating for any number of steps, and give an energy scalar that can be used to evaluate uncertainty and verify the strength of predictions.表 1:架构与认知方面。对于每个预测,前馈(FF)Transformer 和 RNN 通常具有有限的计算量。虽然扩散模型可以通过增加去噪步骤的数量在推理过程中拥有更多的计算量,但它们并未学习到明确验证或估计预测不确定性的方法。能量模型(EBM)在推理过程中可以通过迭代任意数量的步骤使用动态计算量,并给出一个能量标量,该标量可用于评估不确定性并验证预测的强度。
Conclusion
《Energy-Based Transformers are Scalable Learners and Thinkers》的翻译与解读
| 地址 | https://arxiv.org/abs/2507.02092 |
| 时间 | 2025年7月2日 |
| 作者 | UVA,UIUC,Amazon GenAI,Stanford University,Harvard University |
Abstract
| Inference-time computation techniques, analogous to human System 2 Thinking, have recently become popular for improving model performances. However, most existing approaches suffer from several limitations: they are modality-specific (e.g., working only in text), problem-specific (e.g., verifiable domains like math and coding), or require additional supervision/training on top of unsupervised pretraining (e.g., verifiers or verifiable rewards). In this paper, we ask the question "Is it possible to generalize these System 2 Thinking approaches, and develop models that learn to think solely from unsupervised learning?" Interestingly, we find the answer is yes, by learning to explicitly verify the compatibility between inputs and candidate-predictions, and then re-framing prediction problems as optimization with respect to this verifier. Specifically, we train Energy-Based Transformers (EBTs) -- a new class of Energy-Based Models (EBMs) -- to assign an energy value to every input and candidate-prediction pair, enabling predictions through gradient descent-based energy minimization until convergence. Across both discrete (text) and continuous (visual) modalities, we find EBTs scale faster than the dominant Transformer++ approach during training, achieving an up to 35% higher scaling rate with respect to data, batch size, parameters, FLOPs, and depth. During inference, EBTs improve performance with System 2 Thinking by 29% more than the Transformer++ on language tasks, and EBTs outperform Diffusion Transformers on image denoising while using fewer forward passes. Further, we find that EBTs achieve better results than existing models on most downstream tasks given the same or worse pretraining performance, suggesting that EBTs generalize better than existing approaches. Consequently, EBTs are a promising new paradigm for scaling both the learning and thinking capabilities of models. | 推理时间计算技术类似于人类的系统 2 思维,近来因其能提升模型性能而广受欢迎。然而,现有的大多数方法都存在一些局限性:它们要么针对特定模态(例如仅适用于文本),要么针对特定问题(例如数学和编程等可验证领域),要么需要在无监督预训练之上进行额外的监督/训练(例如验证器或可验证奖励)。在本文中,我们提出了一个问题:“是否有可能将这些系统 2 思维方法进行泛化,并开发出仅通过无监督学习就能学会思考的模型?”有趣的是,我们发现答案是肯定的,通过学习明确验证输入与候选预测之间的兼容性,然后将预测问题重新定义为针对此验证器的优化问题。具体而言,我们训练了能量基转换器(EBTs)——一种新的能量基模型(EBMs)——为每个输入和候选预测对分配一个能量值,通过基于梯度下降的能量最小化直至收敛来进行预测。无论是离散(文本)还是连续(视觉)模态,我们发现 EBT 在训练期间的扩展速度都比主流的 Transformer++ 方法更快,在数据、批处理大小、参数、浮点运算次数和深度方面,其扩展率最高可高出 35%。在推理过程中,EBT 通过系统 2 思维在语言任务上的性能比 Transformer++ 提升了 29%,并且在图像去噪方面,EBT 的表现优于扩散 Transformer,同时使用的前向传播次数更少。此外,我们发现,即使在预训练性能相同或更差的情况下,EBT 在大多数下游任务中的表现也优于现有模型,这表明 EBT 的泛化能力更强。因此,EBT 是一种有前景的新范式,能够扩展模型的学习和思考能力。 |
1、Introduction
| In psychology, human thinking is often classified into two different types: System 1 (thinking fast) and System 2 (thinking slow) [1, 2, 3, 4]. System 1 thinking is characterized by quick, intuitive and automatic responses, relying on previous experience to solve simple or familiar problems. Alternatively, System 2 Thinking is slow, deliberate and analytical, requiring conscious effort and logical reasoning to process more complex information. System 2 Thinking is essential for complex problems that go beyond automatic pattern recognition, such as in mathematics, programming, multistep reasoning, or novel out-of-distribution situations [5, 6], where precision and depth of understanding are important. Although current models perform well on tasks suitable for System 1 thinking [7], they continue to struggle with tasks that demand System 2 capabilities [8, 9, 10]. Consequently, the recent pursuance of System 2 Thinking capabilities has become a growing interest among AI researchers, leading to the rise of several foundation models such as O1 [11], R1 [12], Grok3 [13], and Claude 3.7 Sonnet [14]. These “reasoning models” excel on math and coding benchmarks, particularly by increasing the time models spend thinking. However, publicly available information on training methods, particularly from the open-source R1 model [12], suggests that the Reinforcement Learning (RL) based training approach for these models only works in domains where rule-based rewards can easily verify answers, such as math and coding. This limitation reduces applicability to a small range of problem types, and as a consequence, often deteriorates performance in other tasks such as writing [15, 16, 17]. Further, recent evidence suggests this RL-based approach may not induce new reasoning patterns, but rather just increase the probability of reasoning patterns already known to the base model [18], which limits performance on problems requiring exploration. | 在心理学中,人类思维通常被分为两种不同的类型:系统 1(快速思考)和系统 2(缓慢思考)[1, 2, 3, 4]。系统 1 思维的特点是快速、直觉且自动的反应,依靠先前的经验来解决简单或熟悉的问题。相反,系统 2 思维则缓慢、审慎且具有分析性,需要有意识的努力和逻辑推理来处理更复杂的信息。系统 2 思维对于超出自动模式识别的复杂问题至关重要,例如数学、编程、多步骤推理或新颖的分布外情况[5, 6],这些情况需要精确性和深度理解。尽管当前的模型在适合系统 1 思维的任务上表现出色[7],但在需要系统 2 能力的任务上仍面临挑战[8, 9, 10]。 因此,近来对系统 2 思维能力的追求已成为人工智能研究人员日益增长的兴趣所在,这促使了诸如 O1 [11]、R1 [12]、Grok3 [13] 和 Claude 3.7 Sonnet [14] 等几个基础模型的兴起。这些“推理模型”在数学和编程基准测试中表现出色,尤其是通过增加模型的思考时间来实现。然而,从开源的 R1 模型[12]等公开的训练方法信息来看,这些模型所采用的基于强化学习(RL)的训练方法仅在规则奖励能够轻松验证答案的领域(如数学和编程)有效。这种局限性使得其适用范围仅限于少数问题类型,因此在诸如写作等其他任务中的表现往往不佳[15, 16, 17]。此外,近期的证据表明,这种基于强化学习的方法可能不会诱导出新的推理模式,而只是增加了基础模型已知推理模式出现的概率[18],这限制了其在需要探索的问题上的表现。 |
| Along similar lines, there has been strong interest in achieving System 2 Thinking in both diffusion models and Recurrent Neural Networks (RNNs). Diffusion models support iterative inference through denoising steps, where increasing denoising steps can improve performance. However, they typically fail to benefit from denoising steps beyond what they were trained on [19], and aside from increasing denoising steps, diffusion models require an external verifier to improve System 2 Thinking capabilities [19, 20, 21]. RNNs also offer iterative computation via recurrent state updates [22, 23, 24], however, most modern RNNs only update their internal state with new information, meaning they cannot be used for thinking longer. Additionally, RNNs that do support recurrent depth still lack mechanisms for explicit verification [25], resulting in limited adoption for System 2 Thinking. As one of the primary goals of AI is to figure out how we can create systems that learn to think on their own on any type of problem, these approaches ultimately bring about the following core research question: “Can we rely entirely on unsupervised learning to develop System 2 Thinking?” Such a capability would enable generalization of current System 2 Thinking approaches to any problem, any modality, and avoid the reliance on external human, reward, or model supervision. In this work, we argue and demonstrate empirically that the answer to this core research question is yes, but that there are several limitations in existing model architectures that prevent this type of unsupervised System 2 Thinking from emerging. Particularly, when comparing the qualities of human System 2 Thinking with the current modeling paradigms (Figure 1, Table 1), we observe several key differences, outlined below as three key Facets of System 2 Thinking1: | 同样地,人们对于在扩散模型和循环神经网络(RNN)中实现系统 2 思维也表现出浓厚的兴趣。扩散模型通过去噪步骤支持迭代推理,增加去噪步骤可以提高性能。然而,它们通常无法从超出其训练范围的去噪步骤中获益[19],而且除了增加去噪步骤之外,扩散模型还需要外部验证器来提高系统 2 思维能力[19, 20, 21]。循环神经网络(RNN)也通过循环状态更新提供迭代计算[22, 23, 24],然而,大多数现代 RNN 只是用新信息更新其内部状态,这意味着它们无法用于更长时间的思考。此外,支持循环深度的 RNN 仍然缺乏明确验证的机制[25],导致其在系统 2 思维方面的应用有限。 作为人工智能的主要目标之一,就是要弄清楚如何创建能够在任何类型的问题上自主思考的系统,这些方法最终引出了以下核心研究问题:“我们能否完全依靠无监督学习来开发系统 2 思维?”这种能力将使当前的系统 2 思维方法能够推广到任何问题、任何模式,并避免依赖外部的人类、奖励或模型监督。 在本研究中,我们从理论上论证并实证表明,对于这个核心研究问题的答案是肯定的,但现有模型架构存在若干限制,阻碍了这种无监督的系统 2 思维的出现。特别是,当将人类系统 2 思维的特质与当前的建模范式进行比较时(图 1、表 1),我们观察到几个关键差异,概述如下,作为系统 2 思维的三个关键方面 1: |
Figure 1:Autoregressive Architecture Comparison. (a) Autoregressive (AR) Transformer is the most common, with (b) RNNs becoming more popular recently [22, 23]. (c) Diffusion Transformers [26] (which are often bidirectional but can also be autoregressive) are the most similar to EBT, being able to dynamically allocate computation during inference, but predict the noise rather than the energy [27, 28]. Consequently, diffusion models cannot give unnormalized likelihood estimates at each step of the thinking process, and are not trained as explicit verifiers, unlike EBTs.图 1:自回归架构比较。(a)自回归(AR)Transformer 是最常见的,(b)最近 RNN 变得更受欢迎[22, 23]。(c)扩散 Transformer [26](通常是双向的,但也可以是自回归的)与 EBT 最为相似,能够在推理过程中动态分配计算,但预测的是噪声而非能量[27, 28]。因此,扩散模型无法在思维过程的每一步给出未归一化的似然估计,也不像 EBT 那样作为显式验证器进行训练。
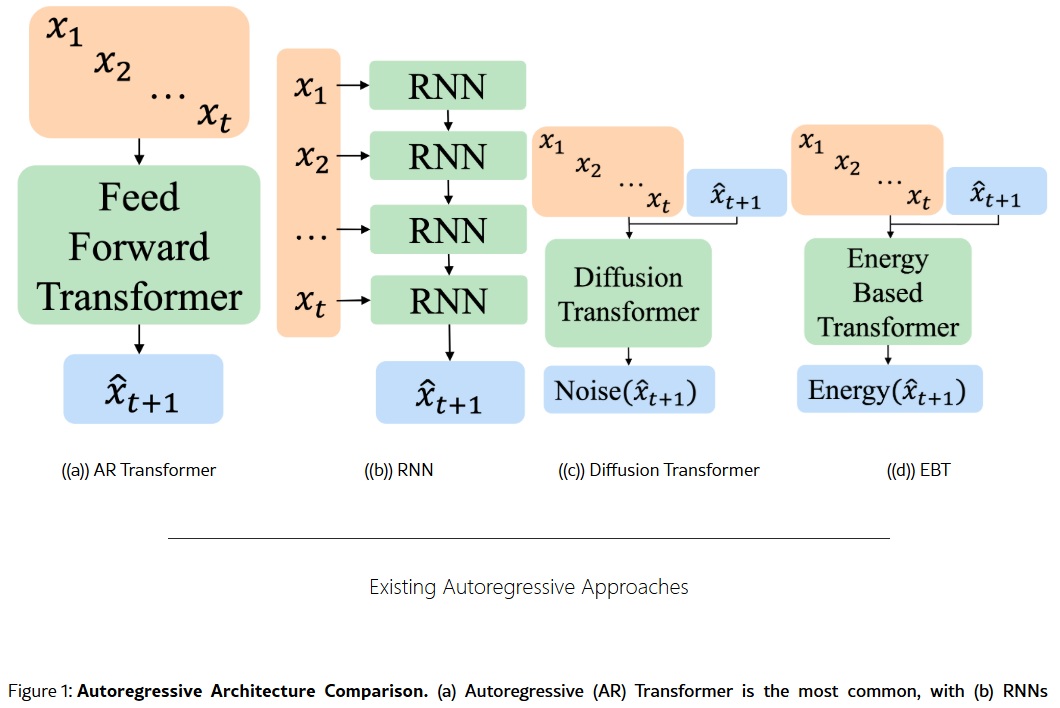
Table 1:Architectures and Cognitive Facets. For each prediction, Feed Forward (FF) Transformers and RNNs generally3 have a finite amount of computation. While diffusion models have potentially more computation during inference by increasing the number of denoising steps, they do not learn to explicitly verify or estimate uncertainty for predictions. EBMs can use a dynamic amount of computation during inference by iterating for any number of steps, and give an energy scalar that can be used to evaluate uncertainty and verify the strength of predictions.表 1:架构与认知方面。对于每个预测,前馈(FF)Transformer 和 RNN 通常具有有限的计算量。虽然扩散模型可以通过增加去噪步骤的数量在推理过程中拥有更多的计算量,但它们并未学习到明确验证或估计预测不确定性的方法。能量模型(EBM)在推理过程中可以通过迭代任意数量的步骤使用动态计算量,并给出一个能量标量,该标量可用于评估不确定性并验证预测的强度。
Conclusion
| Across both discrete (text) and continuous (video) autoregressive models, the results show that EBTs scale at a faster rate than the standard Transformer++ approach during pretraining across all measured axes, including data, batch size, depth, parameters, FLOPs, and width. This is especially apparent with data and batch scaling for text, as well as width and parameter scaling for video, where the scaling rate was over 30% higher. These results are particularly important for two reasons: first, they suggest that at the scale of modern foundation models, EBTs would outperform the current Transformer++ approach even without their System 2 Thinking capabilities. Second, EBTs appear to be the first approach that has better data efficiency than the Transformer++. As data has become one of the major limiting factors in further scaling [123], this makes EBTs especially appealing. With System 2 Thinking, the EBT-Transformer++ performance gap would be expected to increase, as we found that System 2 Thinking could improve performance by as much as 29% for text (Figure 6(a)). Further, we found that the thinking capabilities of EBTs scale well, as they improve during pretraining (Figure 6(b)) and perform better for data that is more OOD (Figure 7). These findings imply that OOD generalization benefits from System 2 Thinking will further increase at larger scales, paving the way for principled generalization to OOD data. In addition, EBTs become increasingly robust to self-generated errors during verification (Figure 1(a)), indicating that their self-verification process scales reliably and sidesteps the adversarial instabilities reported in prior works [19, 124]. Figure 12:Image Denoising Thinking Scalability. A comparison between EBT and DiT on image denoising given a different number of forward passes. EBTs require only 1% of the forward passes used by DiT to achieve comparable or better PSNR. Further, the scaling rate of PSNR improvement given more forward passes is much higher for EBTs than it is for DiTs. These results suggest EBTs have superior thinking capabilities than DiTs on OOD data. | 无论是离散(文本)还是连续(视频)自回归模型,结果均表明,在预训练过程中,EBT 模型在所有测量维度(包括数据量、批处理大小、深度、参数数量、浮点运算次数和宽度)上的扩展速度都比标准的 Transformer++ 方法更快。在文本的数据和批处理扩展以及视频的宽度和参数扩展方面,这种差异尤为明显,其扩展速度高出 30% 以上。这些结果具有重要意义,原因有二:首先,这表明在现代基础模型的规模下,即使不考虑 EBT 的系统 2 思维能力,EBT 也会优于当前的 Transformer++ 方法。其次,EBT 似乎是首个在数据效率方面优于 Transformer++ 的方法。由于数据已成为进一步扩展的主要限制因素之一[123],这使得 EBT 更具吸引力。 加入系统 2 思维后,EBT 与 Transformer++ 之间的性能差距预计会进一步扩大,因为我们发现系统 2 思维能使文本性能提升高达 29%(图 6(a))。此外,我们发现 EBT 的思维能力具有良好的扩展性,因为它们在预训练期间有所提升(图 6(b)),并且对于更远离训练分布的数据表现更佳(图 7)。这些发现表明,得益于系统 2 思维的 OOD 泛化能力在更大规模下将进一步增强,为原则性地泛化到 OOD 数据铺平了道路。此外,EBT 在验证过程中对自生成错误的鲁棒性不断增强(图 1(a)),这表明其自验证过程可靠地扩展,并且避开了先前工作中报告的对抗性不稳定性 [19, 124]。 图 12:图像去噪思维扩展性。EBT 与 DiT 在给定不同前向传递次数的图像去噪任务上的比较。EBT 只需 DiT 所用前向传递次数的 1% 即可达到相当或更好的 PSNR。此外,给定更多前向传递次数时,EBT 的 PSNR 改善率远高于 DiT。这些结果表明 EBT 在 OOD 数据上的思维能力优于 DiT。 |
| We hypothesize that the superior scaling of EBTs compared to the Transformer++ can be attributed to EBTs learning to verify (Facet 1) rather than solely learning to predict. As discussed in Section 2, verification often generalizes better than amortized generation, which we believe leads to improved learning efficiency. The results in our generalization experiments further support this idea of verification leading to improved generalization, as we found that given a slightly worse pretraining performance, EBTs still outperform the Transformer++ recipe on downstream tasks. Additionally, corresponding to Facet 1 regarding prediction uncertainty, we find that the energy values learned by EBTs correlate strongly with more challenging to predict data, as shown in Figures 8 and 11. This is a promising characteristic of EBTs, as it enables uncertainty estimation within continuous state spaces, which would allow for principled inference-time behavior adaptation (Facet 1) when models determine a problem is more challenging. Lastly, the results from our bidirectional experiments indicate that EBTs hold strong promise in bidirectional modeling. Particularly, we find that bidirectional EBTs outperform the DiT baseline in image denoising on both In and Out-of-Distribution performance, while using significantly fewer forward passes. This suggests that EBTs offer promise in tasks such as image generation or bidirectional text generation. Further, when evaluating the representations from DiTs and EBTs, we find that EBTs perform significantly better, achieving up to a 10× improvement in accuracy, suggesting EBTs offer promise in developing a better understanding of what is being generated when performing generative modeling. | 我们假设,与 Transformer++ 相比,EBTs 更出色的扩展性可归因于 EBTs 学会了验证(方面 1),而不仅仅是学习预测。正如第 2 节所讨论的,验证通常比近似生成具有更好的泛化能力,我们认为这会提高学习效率。我们在泛化实验中的结果进一步支持了验证能提高泛化的这一观点,因为我们发现,尽管预训练性能稍差,但 EBTs 在下游任务上仍优于 Transformer++ 配方。此外,对应于方面 1 中关于预测不确定性的内容,我们发现 EBTs 学习到的能量值与更难预测的数据有很强的相关性,如图 8 和图 11 所示。这是 EBTs 的一个很有前景的特性,因为它能够在连续状态空间中进行不确定性估计,这将允许模型在推理时根据问题的难度进行有原则的行为调整(方面 1)。最后,我们的双向实验结果表明,EBTs 在双向建模方面具有很大的潜力。特别是,我们发现双向 EBT 在图像去噪任务中,无论是对分布内还是分布外的数据,其性能都优于 DiT 基线,而且使用的前向传播次数显著减少。这表明 EBT 在诸如图像生成或双向文本生成等任务中具有潜力。此外,在评估 DiT 和 EBT 的表示时,我们发现 EBT 表现显著更优,准确率最高可提升 10 倍,这表明 EBT 在进行生成建模时,对于生成内容的理解方面具有潜力。 |