31、GPT核心引擎完整手工构建:从算法原理到工程优化(Generative Pre-trained Transformer)
学习目标:完全从零实现GPT模型架构,深度理解每个组件的工程细节,掌握自回归语言模型的完整实现,建立大模型架构的核心技能。
在深度学习的技术演进历程中,GPT(Generative Pre-trained Transformer) 架构代表了自回归语言建模的巅峰实现。从GPT-1的1.17亿参数到GPT-4的万亿参数规模,这一架构体系不仅展现了Transformer解码器设计的优雅性,更体现了工程实现与理论创新的完美结合。当我们亲手实现GPT架构的每一个细节时,我们不仅是在编写代码,更是在深度理解现代AI系统的核心机制。
从学术突破到工程实践的技术演进反映了深度学习领域的发展规律。Transformer架构最初由Vaswani等人在"Attention Is All You Need"论文中提出,主要用于机器翻译任务。GPT系列模型的关键创新在于将Transformer的解码器部分单独提取出来,专门用于自回归语言建模任务。这种设计选择看似简单,实则蕴含着对语言本质的深刻理解:语言生成本质上是一个条件概率问题,每个词的出现都依赖于前面所有词的上下文信息。
架构设计的哲学思考体现了简洁性与强大性的统一。GPT架构的美妙之处在于其高度统一的设计理念:无论是注意力机制、前馈网络还是层归一化,都遵循着相同的设计模式。这种统一性不仅简化了实现复杂度,更重要的是为模型的可扩展性奠定了基础。当我们将模型从百万参数扩展到千亿参数时,核心架构保持不变,只是在深度和宽度上进行线性扩展。
数学原理与工程实现的深度融合是现代AI系统的显著特征。每一行代码背后都对应着严格的数学理论,每一个工程优化都源于对数学本质的深入理解。注意力机制的缩放因子、残差连接的梯度流动、层归一化的数值稳定性,这些看似技术性的细节实际上都承载着深厚的数学内涵。
从原型到生产的工程化挑战展现了理论到实践的复杂转化过程。学术论文中优雅的数学公式,在实际实现时需要考虑数值精度、内存效率、计算性能、并行策略等诸多工程问题。如何在保持数学正确性的前提下实现高效的工程实现,如何在有限的计算资源下训练更大的模型,这些都是我们在手工实现过程中需要深入思考的问题。
认知科学视角下的架构理解揭示了人工智能与人类智能的内在联系。自注意力机制在某种程度上模拟了人类阅读理解时的注意力分配过程,位置编码反映了序列信息在认知过程中的重要性,多层堆叠体现了从简单特征到复杂概念的抽象过程。虽然我们不能简单地将人工神经网络等同于生物神经系统,但这些设计选择确实体现了对智能本质的某种理解。
31.1 Transformer解码器基础:理解GPT的核心架构
> 解码器设计的理论基础
自回归建模的数学本质决定了GPT架构的基本形态。在语言建模任务中,我们的目标是学习条件概率分布P(x_t|x_1, x_2, …, x_{t-1}),即在给定前面所有token的条件下,预测下一个token的概率分布。这种建模方式天然地要求模型只能访问当前位置之前的信息,这就是因果性约束的来源。与编码器-解码器架构不同,纯解码器架构通过掩码机制在单一网络中实现了这种约束。
注意力机制的信息整合能力是Transformer架构优于传统RNN的关键优势。在RNN中,长距离依赖信息需要通过多步递归传播,容易出现梯度消失问题。而在自注意力机制中,任意两个位置之间都可以直接建立连接,理论上可以完美地处理任意长度的依赖关系。这种并行化的信息整合方式不仅提高了训练效率,更重要的是提供了更强的表达能力。
层次化特征提取的认知启发体现了深度学习的核心思想。GPT通过多层解码器的堆叠,实现了从底层字符模式到高层语义概念的逐步抽象。底层的解码器层主要关注局部的语法结构和词汇关系,中层开始捕捉句法结构和语义角色,顶层则能够理解复杂的语义关系和推理逻辑。这种层次化的设计与人类语言理解的认知过程存在着某种相似性。
残差连接的梯度流动优化解决了深度网络训练的根本性问题。在没有残差连接的深度网络中,梯度在反向传播过程中会逐层衰减,导致底层参数难以得到有效更新。残差连接通过提供直接的梯度传播路径,确保了深度网络的可训练性。在GPT架构中,每个子模块(注意力层和前馈网络)都采用了残差连接,形成了多条并行的梯度流动路径。
> 核心组件的实现细节
层归一化的数值稳定性考虑是深度网络训练成功的关键因素。与批归一化不同,层归一化在每个样本的特征维度上进行标准化,避免了对批大小的依赖。在实现时,我们需要特别注意数值稳定性:方差计算时添加小的epsilon项防止除零,使用更稳定的数值计算方法防止梯度爆炸或消失。LayerNorm的位置选择也很重要,现代实现通常采用Pre-LN(在注意力和前馈网络之前)而不是Post-LN(之后),以获得更好的训练稳定性。
解码器层的组合模式遵循着严格的设计原则。每个解码器层包含两个主要子模块:多头自注意力机制和位置感知的前馈网络。这两个模块都采用相同的结构模式:子模块 → 残差连接 → 层归一化。这种统一的设计模式不仅简化了实现,还提供了良好的可扩展性。模块间的信息流动遵循严格的顺序,确保因果性约束得到正确执行。
参数初始化策略的理论依据直接影响模型的训练效果。不同的初始化方法适用于不同的激活函数和网络结构。对于Transformer架构,通常采用正态分布初始化,标准差根据层的输入维度进行调整。位置编码采用预定义的正弦余弦函数或学习得到的嵌入向量。输出层的权重初始化需要特别小心,以避免初始预测过于极端。
> 基础实现框架

import torch
import torch.nn as nn
import torch.nn.functional as F
import math
from typing import Optional, Tuple
import warningsclass GPTConfig:"""GPT模型配置类"""def __init__(self,vocab_size: int = 50257,max_seq_len: int = 1024, n_layers: int = 12,n_heads: int = 12,n_embd: int = 768,dropout: float = 0.1,bias: bool = True,):self.vocab_size = vocab_sizeself.max_seq_len = max_seq_lenself.n_layers = n_layersself.n_heads = n_headsself.n_embd = n_embdself.dropout = dropoutself.bias = bias# 验证配置合理性assert n_embd % n_heads == 0, "n_embd必须能被n_heads整除"class LayerNorm(nn.Module):"""手工实现层归一化,支持可选的偏置项"""def __init__(self, ndim: int, bias: bool = True, eps: float = 1e-5):super().__init__()self.eps = epsself.weight = nn.Parameter(torch.ones(ndim))self.bias = nn.Parameter(torch.zeros(ndim)) if bias else Nonedef forward(self, x: torch.Tensor) -> torch.Tensor:# 计算最后一个维度的均值和方差mean = x.mean(dim=-1, keepdim=True)var = x.var(dim=-1, keepdim=True, unbiased=False)# 标准化x_norm = (x - mean) / torch.sqrt(var + self.eps)# 应用缩放和偏移x_norm = self.weight * x_normif self.bias is not None:x_norm = x_norm + self.biasreturn x_normclass MLP(nn.Module):"""前馈网络,实现位置级别的非线性变换"""def __init__(self, config: GPTConfig):super().__init__()# 通常中间层维度是嵌入维度的4倍hidden_dim = 4 * config.n_embdself.c_fc = nn.Linear(config.n_embd, hidden_dim, bias=config.bias)self.c_proj = nn.Linear(hidden_dim, config.n_embd, bias=config.bias)self.dropout = nn.Dropout(config.dropout)def forward(self, x: torch.Tensor) -> torch.Tensor:x = self.c_fc(x)x = F.gelu(x) # 使用GELU激活函数x = self.c_proj(x)x = self.dropout(x)return xclass Block(nn.Module):"""GPT解码器块"""def __init__(self, config: GPTConfig):super().__init__()self.ln_1 = LayerNorm(config.n_embd, bias=config.bias)self.attn = None # 将在下一节实现self.ln_2 = LayerNorm(config.n_embd, bias=config.bias) self.mlp = MLP(config)def forward(self, x: torch.Tensor) -> torch.Tensor:# Pre-LN架构:先归一化,再应用变换# 注意力分支x = x + self.attn(self.ln_1(x))# 前馈网络分支 x = x + self.mlp(self.ln_2(x))return x# 基础测试
def test_basic_components():"""测试基础组件"""print("=== 测试GPT基础组件 ===")config = GPTConfig(n_embd=256, n_layers=4, n_heads=8)batch_size, seq_len = 2, 10# 测试LayerNormln = LayerNorm(config.n_embd)x = torch.randn(batch_size, seq_len, config.n_embd)x_norm = ln(x)print(f"输入形状: {x.shape}")print(f"LayerNorm输出形状: {x_norm.shape}")print(f"归一化后均值: {x_norm.mean(-1).abs().max():.6f}")print(f"归一化后方差: {x_norm.var(-1, unbiased=False).mean():.6f}")# 测试MLPmlp = MLP(config)mlp_out = mlp(x_norm)print(f"MLP输出形状: {mlp_out.shape}")print("基础组件测试完成✓")if __name__ == "__main__":test_basic_components()
31.2 多头自注意力机制:GPT的核心计算引擎
> 注意力机制的数学本质
注意力权重的计算逻辑体现了相关性度量的数学原理。在自注意力机制中,我们通过计算查询(Query)和键(Key)之间的相似度来确定注意力权重。这种相似度计算采用了点积(dot-product)方法,因为点积天然地度量了两个向量在高维空间中的相关性。当两个向量指向相同方向时,点积值较大,表示强相关性;当向量正交时,点积值接近零,表示弱相关性。这种几何直觉为注意力机制提供了坚实的数学基础。
缩放因子的数值稳定性作用是实现细节中的关键考虑。原始点积注意力在向量维度较高时容易产生极大的数值,导致softmax函数进入饱和区域,产生极其尖锐的注意力分布。通过除以√d_k(键的维度平方根)进行缩放,我们可以控制点积值的数量级,使其保持在合理范围内。这个看似简单的缩放操作实际上对模型的训练稳定性和最终性能都有重要影响。
多头机制的表示能力增强源于子空间分解的数学洞察。单个注意力头只能捕捉一种类型的相关性模式,而多头注意力通过将输入投影到不同的子空间,允许模型同时关注多种不同类型的依赖关系。例如,某些头可能专注于句法关系,某些头关注语义相似性,还有些头处理长距离依赖。这种分工机制大大增强了模型的表达能力。
因果掩码的实现细节确保了自回归模型的正确性。在训练和推理过程中,模型不能访问当前位置之后的信息,这通过下三角掩码矩阵来实现。将未来位置的注意力得分设置为负无穷,经过softmax后这些位置的权重会变为零。这种硬约束确保了模型严格遵循因果性原则,是自回归生成的基础。
> 高效实现的工程考虑
内存布局优化的重要性在大规模模型中尤为突出。注意力矩阵的计算涉及大量的矩阵乘法操作,不合理的内存布局会导致频繁的缓存未命中,严重影响计算效率。通过合理安排tensor的维度顺序,利用现代GPU的内存层次结构,可以显著提高计算性能。同时,注意力矩阵通常具有稀疏性,在某些情况下可以利用这一特性进行进一步优化。
梯度累积的数值精度考虑关系到模型训练的稳定性。在反向传播过程中,注意力权重的梯度计算涉及复杂的链式法则应用。特别是在使用混合精度训练时,需要carefully处理不同数值精度间的转换,防止梯度消失或爆炸。适当的梯度裁剪和数值检查是必要的安全措施。
并行化策略的设计权衡平衡了计算效率与实现复杂度。多头注意力天然具有并行性,不同的头可以并行计算。但在实际实现中,我们通常将多头计算合并为大矩阵乘法,利用高度优化的BLAS库来获得最佳性能。这种实现方式在保持数学等价性的同时,充分利用了现代硬件的并行计算能力。
> 核心实现代码

class CausalSelfAttention(nn.Module):"""因果自注意力机制实现"""def __init__(self, config: GPTConfig):super().__init__()assert config.n_embd % config.n_heads == 0self.n_heads = config.n_headsself.n_embd = config.n_embdself.head_dim = config.n_embd // config.n_heads# 合并的QKV投影,提高效率self.c_attn = nn.Linear(config.n_embd, 3 * config.n_embd, bias=config.bias)self.c_proj = nn.Linear(config.n_embd, config.n_embd, bias=config.bias)# 注意力和残差dropoutself.attn_dropout = nn.Dropout(config.dropout)self.resid_dropout = nn.Dropout(config.dropout)# 因果掩码(下三角矩阵)self.register_buffer("bias", torch.tril(torch.ones(config.max_seq_len, config.max_seq_len)).view(1, 1, config.max_seq_len, config.max_seq_len))def forward(self, x: torch.Tensor) -> torch.Tensor:B, T, C = x.size() # batch_size, seq_len, embedding_dim# 计算查询、键、值qkv = self.c_attn(x)q, k, v = qkv.split(self.n_embd, dim=2)# 重塑为多头形式 (B, T, C) -> (B, nh, T, hs)q = q.view(B, T, self.n_heads, self.head_dim).transpose(1, 2)k = k.view(B, T, self.n_heads, self.head_dim).transpose(1, 2) v = v.view(B, T, self.n_heads, self.head_dim).transpose(1, 2)# 计算注意力权重 (B, nh, T, hs) @ (B, nh, hs, T) -> (B, nh, T, T)att = (q @ k.transpose(-2, -1)) * (1.0 / math.sqrt(self.head_dim))# 应用因果掩码att = att.masked_fill(self.bias[:, :, :T, :T] == 0, float('-inf'))att = F.softmax(att, dim=-1)att = self.attn_dropout(att)# 应用注意力权重到值 (B, nh, T, T) @ (B, nh, T, hs) -> (B, nh, T, hs)y = att @ v# 重新组装头 (B, nh, T, hs) -> (B, T, C)y = y.transpose(1, 2).contiguous().view(B, T, C)# 最终投影y = self.resid_dropout(self.c_proj(y))return y# 更新Block类,加入注意力层
class Block(nn.Module):"""GPT解码器块(完整版本)"""def __init__(self, config: GPTConfig):super().__init__()self.ln_1 = LayerNorm(config.n_embd, bias=config.bias)self.attn = CausalSelfAttention(config)self.ln_2 = LayerNorm(config.n_embd, bias=config.bias) self.mlp = MLP(config)def forward(self, x: torch.Tensor) -> torch.Tensor:# Pre-LN架构x = x + self.attn(self.ln_1(x)) # 注意力分支x = x + self.mlp(self.ln_2(x)) # 前馈网络分支 return xdef test_attention_mechanism():"""测试注意力机制"""print("\n=== 测试多头自注意力机制 ===")config = GPTConfig(vocab_size=1000,max_seq_len=64,n_layers=2, n_heads=4,n_embd=128,dropout=0.1)batch_size, seq_len = 2, 16x = torch.randn(batch_size, seq_len, config.n_embd)# 测试注意力层attn = CausalSelfAttention(config)attn_out = attn(x)print(f"输入形状: {x.shape}")print(f"注意力输出形状: {attn_out.shape}")# 测试完整的解码器块block = Block(config)block_out = block(x)print(f"解码器块输出形状: {block_out.shape}")# 检查因果掩码是否工作with torch.no_grad():# 创建一个简单的测试用例test_input = torch.zeros(1, 4, config.n_embd)test_input[0, 0, :] = 1.0 # 只在第一个位置有非零值# 获取注意力权重(需要修改forward函数来返回权重)print("因果掩码测试:模型只能关注当前和之前的位置")print("注意力机制测试完成✓")if __name__ == "__main__":test_attention_mechanism()
这个实现的关键特点包括:
- 高效的QKV计算:使用单个线性层计算查询、键、值,减少参数和计算量
- 正确的因果掩码:确保模型只能看到当前位置之前的信息
- 稳定的数值计算:包含适当的缩放因子和dropout
- 内存友好的实现:合理的tensor重塑和转置操作
- 清晰的维度处理:详细的注释说明每步的张量形状变化
31.3 位置编码设计:序列顺序信息的数学表示
> 位置编码的理论基础与设计哲学
序列顺序信息的重要性在语言理解中具有根本性地位。人类语言本质上是一个有序序列,词汇的相对位置承载着重要的语法和语义信息。"狗咬人"和"人咬狗"使用了完全相同的词汇,但由于词序不同而表达截然相反的含义。然而,标准的注意力机制本质上是置换不变的(permutation invariant),即改变输入序列的顺序不会影响计算结果。为了让模型理解序列的顺序结构,我们必须显式地注入位置信息。
绝对位置编码的数学设计体现了函数分析中的正交基分解思想。Transformer原论文中提出的正弦余弦位置编码利用了三角函数的正交性和周期性质,为每个位置生成独特而稳定的编码向量。这种设计的优美之处在于:不同频率的正弦和余弦函数构成了一个完备的正交基,可以表示任意复杂的位置模式。同时,三角函数的平移不变性使得模型能够处理训练时未见过的序列长度。
学习式位置编码的适应性优势体现了端到端学习的威力。与预定义的数学函数不同,可学习的位置嵌入向量能够根据具体任务和数据特点进行自适应调整。在实践中,学习式位置编码往往能够获得更好的性能,特别是在特定领域或特殊任务中。这种方法的灵活性允许模型发现任务相关的位置模式,而不是受限于预定义的数学结构。
相对位置编码的归纳偏置反映了语言学中局部性原理的重要性。在自然语言中,词汇之间的关系往往更多地取决于它们的相对位置而非绝对位置。“在…之前”、"在…之后"这样的关系在不同绝对位置上都具有相似的语义含义。相对位置编码通过直接建模位置差异,为模型提供了更强的泛化能力,特别是在处理长序列时表现出明显优势。
> 多种位置编码方案的实现与对比
正弦余弦位置编码的工程实现需要careful处理数值精度和计算效率。原始公式使用不同频率的正弦和余弦函数来编码位置信息,其中偶数维度使用正弦函数,奇数维度使用余弦函数。频率的选择遵循几何级数递减,确保不同位置维度捕捉不同粒度的位置模式。在实现时,我们需要预先计算位置编码表并缓存,避免重复计算带来的性能开销。
可学习位置嵌入的参数效率体现了深度学习中参数化的权衡考虑。每个位置对应一个可学习的嵌入向量,这些向量在训练过程中根据任务需求进行优化。这种方法的优势在于灵活性和任务特化能力,但代价是增加了参数量,特别是在支持长序列时。合理的初始化策略和正则化技术对于防止过拟合至关重要。
旋转位置编码(RoPE)的几何直觉将位置信息编码为复平面上的旋转变换。RoPE通过将查询和键向量在复平面上按位置进行旋转,自然地将相对位置信息融入到注意力计算中。这种方法的数学优美性在于它保持了向量的模长,同时通过旋转角度来编码位置关系。RoPE在长序列建模中表现出色,已成为现代大型语言模型的标准配置。
和下一节代码一起实现。
31.4 前馈网络优化:非线性变换的高效实现
> 前馈网络的设计理念
维度扩展的表示能力增强体现了神经网络中宽度与深度的协同作用。GPT中的前馈网络采用了"扩展-收缩"的结构模式:首先将输入维度扩展到4倍(通常是768→3072),然后再收缩回原维度。这种设计背后的直觉是为每个位置提供更大的表示空间来进行复杂的非线性变换。更大的中间维度允许网络学习更丰富的特征组合,类似于在高维空间中进行特征映射。
激活函数的选择考虑直接影响模型的表达能力和训练动态。GELU(Gaussian Error Linear Unit)激活函数在现代Transformer中被广泛采用,它结合了ReLU的稀疏性和平滑性的优势。与ReLU的硬阈值不同,GELU提供了平滑的激活曲线,有利于梯度流动。其概率解释(基于高斯分布的激活概率)也为模型提供了更自然的随机性。
参数初始化的数学基础关系到训练的收敛性和稳定性。前馈网络的权重初始化需要careful平衡:太小的初始值会导致信号衰减,太大的初始值会导致梯度爆炸。Xavier/Glorot初始化和He初始化提供了理论指导,但在实际应用中还需要根据激活函数和网络深度进行微调。输出层的零初始化有助于模型的稳定训练。
Dropout的正则化机制在防止过拟合中发挥关键作用。在前馈网络中,通常在激活函数之后和最终投影之前应用Dropout。这种随机失活机制强制网络学习更鲁棒的表示,防止对特定神经元的过度依赖。Dropout的比率选择需要在正则化强度和模型容量之间找到平衡。
> 高效实现与优化技术
内存访问模式的优化在大模型中变得至关重要。前馈网络涉及大量的矩阵乘法操作,合理的内存布局可以显著提高计算效率。通过将权重矩阵按列主序存储,利用现代GPU的coalesced memory access特性,可以减少内存带宽瓶颈。同时,适当的tensor fusion技术可以减少中间结果的存储开销。
激活重计算的内存权衡是训练大模型的重要技术。在内存受限的环境下,可以选择不保存前向传播的中间激活值,而在反向传播时重新计算。这种时间换空间的策略允许我们训练更大的模型,但会增加约30%的计算开销。gradient checkpointing技术提供了更细粒度的控制,可以在内存和计算之间找到最优平衡点。
权重共享与参数效率在某些场景下可以减少模型参数。虽然标准GPT不使用权重共享,但在资源受限的环境下,可以考虑在不同层之间共享前馈网络的权重。这种技术需要careful的设计,以确保不会显著损害模型性能。参数化技巧如低秩分解也可以用于减少参数量。

import torch
import torch.nn as nn
import torch.nn.functional as F
import math
from typing import Optional, Tuple
from dataclasses import dataclass@dataclass
class GPTConfig:"""GPT模型配置"""block_size: int = 1024vocab_size: int = 50304 # GPT-2 vocab_size of 50257, padded up to nearest multiple of 64 for efficiencyn_layer: int = 12n_head: int = 12n_embd: int = 768dropout: float = 0.0bias: bool = True # True: bias in Linears and LayerNorms, like GPT-2. False: a bit better and fasterclass LayerNorm(nn.Module):"""带可选偏置的LayerNorm"""def __init__(self, ndim: int, bias: bool):super().__init__()self.weight = nn.Parameter(torch.ones(ndim))self.bias = nn.Parameter(torch.zeros(ndim)) if bias else Nonedef forward(self, input):return F.layer_norm(input, self.weight.shape, self.weight, self.bias, 1e-5)class CausalSelfAttention(nn.Module):"""因果自注意力机制"""def __init__(self, config: GPTConfig):super().__init__()assert config.n_embd % config.n_head == 0# key, query, value projections for all heads, but in a batchself.c_attn = nn.Linear(config.n_embd, 3 * config.n_embd, bias=config.bias)# output projectionself.c_proj = nn.Linear(config.n_embd, config.n_embd, bias=config.bias)# regularizationself.attn_dropout = nn.Dropout(config.dropout)self.resid_dropout = nn.Dropout(config.dropout)self.n_head = config.n_headself.n_embd = config.n_embdself.dropout = config.dropoutdef forward(self, x):B, T, C = x.size() # batch size, sequence length, embedding dimensionality (n_embd)# calculate query, key, values for all heads in batch and move head forward to be the batch dimq, k, v = self.c_attn(x).split(self.n_embd, dim=2)k = k.view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)q = q.view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)v = v.view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)# causal self-attention; Self-attend: (B, nh, T, hs) x (B, nh, hs, T) -> (B, nh, T, T)att = (q @ k.transpose(-2, -1)) * (1.0 / math.sqrt(k.size(-1)))att = F.softmax(att, dim=-1)att = self.attn_dropout(att)y = att @ v # (B, nh, T, T) x (B, nh, T, hs) -> (B, nh, T, hs)y = y.transpose(1, 2).contiguous().view(B, T, C) # re-assemble all head outputs side by side# output projectiony = self.resid_dropout(self.c_proj(y))return yclass PositionalEncoding(nn.Module):"""多种位置编码方案的统一实现"""def __init__(self,d_model: int,max_len: int = 5000,encoding_type: str = "learned", # learned, sinusoidal, ropedropout: float = 0.1):super().__init__()self.d_model = d_modelself.max_len = max_lenself.encoding_type = encoding_typeself.dropout = nn.Dropout(dropout)if encoding_type == "learned":# 可学习的位置嵌入self.pos_emb = nn.Parameter(torch.randn(max_len, d_model) * 0.02)elif encoding_type == "sinusoidal":# 正弦余弦位置编码self.register_buffer('pos_encoding', self._create_sinusoidal_encoding())elif encoding_type == "rope":# 旋转位置编码的频率向量self.register_buffer('freqs', self._create_rope_frequencies())else:raise ValueError(f"Unknown encoding type: {encoding_type}")def _create_sinusoidal_encoding(self) -> torch.Tensor:"""创建正弦余弦位置编码"""pe = torch.zeros(self.max_len, self.d_model)position = torch.arange(0, self.max_len).unsqueeze(1).float()# 计算频率分母:10000^(2i/d_model)div_term = torch.exp(torch.arange(0, self.d_model, 2).float() * -(math.log(10000.0) / self.d_model))# 偶数维度使用sine,奇数维度使用cosinepe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)return pedef _create_rope_frequencies(self) -> torch.Tensor:"""创建RoPE的频率向量"""# RoPE频率计算freqs = 1.0 / (10000 ** (torch.arange(0, self.d_model, 2).float() / self.d_model))return freqsdef forward(self, x: torch.Tensor, seq_len: Optional[int] = None) -> torch.Tensor:"""应用位置编码"""if seq_len is None:seq_len = x.size(1)if self.encoding_type == "learned":# 直接加上可学习的位置嵌入pos_emb = self.pos_emb[:seq_len].unsqueeze(0)return self.dropout(x + pos_emb)elif self.encoding_type == "sinusoidal":# 加上预计算的正弦余弦编码pos_encoding = self.pos_encoding[:seq_len].unsqueeze(0)return self.dropout(x + pos_encoding)elif self.encoding_type == "rope":# RoPE不直接加到输入上,而是在注意力计算中应用return xdef apply_rope(self, q: torch.Tensor, k: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]:"""将RoPE应用到查询和键向量"""if self.encoding_type != "rope":return q, kbatch_size, n_heads, seq_len, head_dim = q.shape# 为每个头计算频率(使用head_dim而不是完整的d_model)freqs = 1.0 / (10000 ** (torch.arange(0, head_dim, 2, device=q.device).float() / head_dim))# 创建位置向量positions = torch.arange(seq_len, device=q.device, dtype=torch.float).unsqueeze(1)# 计算角度 [seq_len, head_dim//2]angles = positions * freqs.unsqueeze(0)# 创建cos和sin值cos_vals = torch.cos(angles) # [seq_len, head_dim//2]sin_vals = torch.sin(angles) # [seq_len, head_dim//2]# 应用旋转变换def rotate_tensor(t):# t shape: [batch_size, n_heads, seq_len, head_dim]# 重新排列为 [batch_size, n_heads, seq_len, head_dim//2, 2]t_complex = t.view(batch_size, n_heads, seq_len, head_dim//2, 2)t_real = t_complex[..., 0] # [batch_size, n_heads, seq_len, head_dim//2]t_imag = t_complex[..., 1] # [batch_size, n_heads, seq_len, head_dim//2]# 应用复数旋转rotated_real = t_real * cos_vals - t_imag * sin_valsrotated_imag = t_real * sin_vals + t_imag * cos_vals# 重新组合rotated = torch.stack([rotated_real, rotated_imag], dim=-1)return rotated.view(batch_size, n_heads, seq_len, head_dim)return rotate_tensor(q), rotate_tensor(k)def test_position_encodings():"""测试不同类型的位置编码"""print("=== 测试位置编码方案 ===")d_model, max_len = 128, 64batch_size, seq_len = 2, 16x = torch.randn(batch_size, seq_len, d_model)# 测试可学习位置编码pe_learned = PositionalEncoding(d_model, max_len, "learned")x_learned = pe_learned(x)print(f"可学习位置编码输出形状: {x_learned.shape}")# 测试正弦余弦位置编码pe_sinusoidal = PositionalEncoding(d_model, max_len, "sinusoidal")x_sin = pe_sinusoidal(x)print(f"正弦余弦位置编码输出形状: {x_sin.shape}")# 测试RoPE - 修复维度问题pe_rope = PositionalEncoding(d_model, max_len, "rope")n_heads = 8head_dim = d_model // n_heads # 16q = torch.randn(batch_size, n_heads, seq_len, head_dim) # [2, 8, 16, 16]k = torch.randn(batch_size, n_heads, seq_len, head_dim) # [2, 8, 16, 16]q_rope, k_rope = pe_rope.apply_rope(q, k)print(f"RoPE处理后Q形状: {q_rope.shape}")print(f"RoPE处理后K形状: {k_rope.shape}")# 比较不同编码的特点print(f"可学习编码参数量: {pe_learned.pos_emb.numel()}")print(f"正弦编码参数量: 0 (预定义)")print(f"RoPE频率向量大小: {pe_rope.freqs.numel()}")print("位置编码测试完成✓")class OptimizedMLP(nn.Module):"""优化版前馈网络实现"""def __init__(self, config: GPTConfig,use_glu: bool = False, # 是否使用Gated Linear Unitactivation_fn: str = "gelu"):super().__init__()self.use_glu = use_gluhidden_dim = 4 * config.n_embdif use_glu:# GLU变体:将输入分成两部分,一部分作为门控self.gate_proj = nn.Linear(config.n_embd, hidden_dim, bias=config.bias)self.up_proj = nn.Linear(config.n_embd, hidden_dim, bias=config.bias)self.down_proj = nn.Linear(hidden_dim, config.n_embd, bias=config.bias)else:# 标准MLPself.c_fc = nn.Linear(config.n_embd, hidden_dim, bias=config.bias)self.c_proj = nn.Linear(hidden_dim, config.n_embd, bias=config.bias)# 激活函数选择self.activation = self._get_activation_fn(activation_fn)# Dropoutself.dropout = nn.Dropout(config.dropout)# 初始化权重self._init_weights()def _get_activation_fn(self, activation_fn: str):"""获取激活函数"""if activation_fn == "gelu":return F.geluelif activation_fn == "relu":return F.relu elif activation_fn == "swish" or activation_fn == "silu":return F.siluelse:raise ValueError(f"Unknown activation: {activation_fn}")def _init_weights(self):"""初始化权重"""for module in self.modules():if isinstance(module, nn.Linear):# He初始化适用于ReLU类激活函数torch.nn.init.normal_(module.weight, mean=0.0, std=0.02)if module.bias is not None:torch.nn.init.zeros_(module.bias)def forward(self, x: torch.Tensor) -> torch.Tensor:if self.use_glu:# GLU: gate * activation(up_projection)gate = self.gate_proj(x)up = self.up_proj(x)hidden = gate * self.activation(up)output = self.down_proj(hidden)else:# 标准MLPhidden = self.c_fc(x)hidden = self.activation(hidden)hidden = self.dropout(hidden)output = self.c_proj(hidden)return self.dropout(output)class EfficientBlock(nn.Module):"""高效的GPT解码器块实现"""def __init__(self, config: GPTConfig, use_parallel_attention: bool = False):super().__init__()self.use_parallel_attention = use_parallel_attentionif use_parallel_attention:# PaLM风格:注意力和MLP并行计算self.ln = LayerNorm(config.n_embd, bias=config.bias)self.attn = CausalSelfAttention(config)self.mlp = OptimizedMLP(config)else:# 标准GPT风格:注意力和MLP串行计算 self.ln_1 = LayerNorm(config.n_embd, bias=config.bias)self.attn = CausalSelfAttention(config)self.ln_2 = LayerNorm(config.n_embd, bias=config.bias)self.mlp = OptimizedMLP(config)def forward(self, x: torch.Tensor) -> torch.Tensor:if self.use_parallel_attention:# 并行计算注意力和MLPx_norm = self.ln(x)attn_out = self.attn(x_norm)mlp_out = self.mlp(x_norm)return x + attn_out + mlp_outelse:# 串行计算x = x + self.attn(self.ln_1(x))x = x + self.mlp(self.ln_2(x))return xdef benchmark_mlp_variants():"""基准测试不同MLP变体的性能"""print("=== MLP变体性能测试 ===")config = GPTConfig(n_embd=768, dropout=0.1)batch_size, seq_len = 4, 512x = torch.randn(batch_size, seq_len, config.n_embd)variants = {"标准MLP": OptimizedMLP(config, use_glu=False, activation_fn="gelu"),"GLU变体": OptimizedMLP(config, use_glu=True, activation_fn="gelu"), "SiLU激活": OptimizedMLP(config, use_glu=False, activation_fn="silu")}for name, model in variants.items():model.eval()# 计算参数量params = sum(p.numel() for p in model.parameters())# 前向传播测试with torch.no_grad():output = model(x)print(f"{name}:")print(f" 参数量: {params:,}")print(f" 输出形状: {output.shape}")print(f" 输出范围: [{output.min():.4f}, {output.max():.4f}]")print()# 测试并行vs串行注意力块print("注意力块变体对比:")serial_block = EfficientBlock(config, use_parallel_attention=False)parallel_block = EfficientBlock(config, use_parallel_attention=True)with torch.no_grad():serial_out = serial_block(x)parallel_out = parallel_block(x)print(f"串行块输出形状: {serial_out.shape}")print(f"并行块输出形状: {parallel_out.shape}")print("MLP优化测试完成✓")if __name__ == "__main__":test_position_encodings()benchmark_mlp_variants()
31.5 内存管理策略:在有限资源下训练大模型
> 内存瓶颈的深度分析
GPU内存的层次结构理解是优化大模型训练的基础。现代GPU的内存系统呈现多层次结构:寄存器(最快,容量最小)、共享内存、L1/L2缓存、全局内存(最慢,容量最大)。深度学习框架通常只能直接控制全局内存的使用,但理解整个层次结构有助于我们设计更高效的算法。在GPT训练中,主要的内存消耗来源包括:模型参数、优化器状态、激活值、梯度以及临时计算缓冲区。
激活值内存的指数增长特性是限制模型规模的主要因素。在前向传播过程中,每一层的激活值都需要保存以供反向传播使用,这导致内存消耗随着层数和序列长度呈现复合增长。对于一个12层的GPT模型,处理1024长度的序列时,激活值可能占用总内存的60-80%。更严重的是,注意力机制的内存复杂度是序列长度的平方级别,长序列训练时这成为主要瓶颈。
优化器状态的隐性内存开销经常被忽视但占用大量内存。Adam优化器为每个参数维护动量和二阶矩估计,这意味着优化器状态的内存占用是模型参数的2-3倍。对于一个1亿参数的模型,仅优化器状态就可能占用1-2GB内存。在资源受限环境下,选择内存效率更高的优化器(如AdaFactor)或者使用优化器状态分片技术变得重要。
梯度累积的内存与计算权衡提供了在有限内存下模拟大批次训练的可能。当GPU内存无法支持期望的批次大小时,可以将大批次分割为多个小批次,累积梯度后再进行参数更新。这种方法在数学上等价于大批次训练,但需要careful处理批归一化等依赖批统计的操作。梯度累积还可以与梯度检查点技术结合,进一步节省内存。
> 高级内存优化技术
梯度检查点的实现策略实现了内存与计算的智能权衡。传统的反向传播需要保存所有中间激活值,而梯度检查点允许我们释放某些激活值,在需要时重新计算。关键是选择合适的检查点位置:保存计算代价高的激活值,释放容易重计算的激活值。在GPT中,通常选择每隔几层设置一个检查点,这样可以将内存使用量从O(L)降低到O(√L),其中L是层数。
混合精度训练的数值稳定性考虑在节省内存的同时需要保证训练稳定性。FP16相比FP32能够节省约50%的内存,但存在数值下溢和精度损失的风险。现代混合精度训练使用动态损失缩放技术:在前向传播中使用FP16以节省内存,在需要高精度的操作(如损失计算和参数更新)中使用FP32。梯度缩放通过放大梯度来避免小梯度的下溢问题。
内存池管理的缓存策略减少了频繁的内存分配开销。PyTorch的内存分配器使用缓存策略,避免频繁的cudaMalloc/cudaFree调用。理解这一机制有助于我们优化内存使用模式:避免创建大量临时tensor,重用相同大小的内存块,及时释放不再需要的大tensor。在训练循环中,内存碎片化也是需要考虑的问题。
代码也放到下一个块中。
31.6 模型并行实现:跨设备的高效训练策略
> 并行策略的理论基础
数据并行的简单有效性是最直观的并行化方案。在数据并行中,每个GPU上保存完整的模型副本,但处理不同的数据批次。前向传播完全独立,反向传播后需要进行梯度的全局同步(All-Reduce操作)。这种方法的优势在于实现简单、通信开销相对较小,但受限于单GPU内存无法容纳完整模型的情况。当模型参数超过单GPU内存限制时,需要考虑其他并行策略。
张量并行的计算分解思想将单个运算分布到多个设备上执行。在Transformer中,注意力计算和前馈网络都涉及大矩阵乘法,这些操作可以按行或按列进行切分。例如,多头注意力可以将不同的头分配到不同GPU上,前馈网络可以按隐藏维度进行切分。张量并行的关键挑战是合理安排通信模式,最小化设备间的数据传输开销。
流水线并行的时间维度分解通过将不同层分配到不同设备来实现并行。这种方法类似于CPU流水线,当第一批数据在第二层处理时,第二批数据可以在第一层开始处理。流水线并行的主要挑战是负载均衡和流水线气泡(pipeline bubble)的最小化。合理的microbatch划分和调度策略对于获得良好的效率至关重要。
混合并行的复杂协调结合多种并行策略以适应不同的硬件配置和模型规模。例如,可以在节点内使用张量并行(高带宽),在节点间使用流水线并行(低带宽),同时在数据维度上进行复制。这种混合策略需要careful的设计来最小化通信开销和内存使用。
> 实际实现的工程挑战
通信拓扑的优化设计直接影响并行效率。不同的通信模式(点对点、广播、All-Reduce、All-Gather)有不同的带宽和延迟特性。NCCL(NVIDIA Collective Communications Library)提供了优化的集合通信原语,但选择合适的通信策略和拓扑仍需要对硬件特性的深入理解。InfiniBand和以太网的不同特性也影响通信策略的选择。
负载均衡的动态调整确保所有设备的计算资源得到充分利用。在流水线并行中,不同层的计算量可能差异很大,需要合理的层分配策略。动态分析每层的计算时间,使用启发式算法进行负载平衡。同时,还需要考虑不同batch size下的计算特性差异。
错误处理和容错机制在分布式训练中变得复杂。单个设备的故障可能影响整个训练过程,需要设计checkpoint和恢复机制。弹性训练(elastic training)允许动态调整参与训练的设备数量,提高系统的可靠性。通信超时和重传机制也是必要的保护措施。

import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.distributed as dist
from torch.utils.checkpoint import checkpoint
from torch.nn.parallel import DistributedDataParallel as DDP
from contextlib import contextmanager
import gc
import os
import math
from typing import Optional, List, Union
from dataclasses import dataclass@dataclass
class GPTConfig:"""GPT模型配置"""block_size: int = 1024vocab_size: int = 50304n_layer: int = 12 # 注意这里用n_layer而不是n_layersn_head: int = 12n_embd: int = 768dropout: float = 0.0bias: bool = True# 添加兼容性参数n_layers: Optional[int] = Nonemax_seq_len: Optional[int] = Nonemax_position_embeddings: Optional[int] = Nonedef __post_init__(self):# 确保兼容性if self.n_layers is None:self.n_layers = self.n_layerif self.max_seq_len is None:self.max_seq_len = self.block_sizeif self.max_position_embeddings is None:self.max_position_embeddings = self.block_sizeclass LayerNorm(nn.Module):"""带可选偏置的LayerNorm"""def __init__(self, ndim: int, bias: bool):super().__init__()self.weight = nn.Parameter(torch.ones(ndim))self.bias = nn.Parameter(torch.zeros(ndim)) if bias else Nonedef forward(self, input):return F.layer_norm(input, self.weight.shape, self.weight, self.bias, 1e-5)class CausalSelfAttention(nn.Module):"""因果自注意力机制"""def __init__(self, config: GPTConfig):super().__init__()assert config.n_embd % config.n_head == 0self.c_attn = nn.Linear(config.n_embd, 3 * config.n_embd, bias=config.bias)self.c_proj = nn.Linear(config.n_embd, config.n_embd, bias=config.bias)self.attn_dropout = nn.Dropout(config.dropout)self.resid_dropout = nn.Dropout(config.dropout)self.n_head = config.n_headself.n_embd = config.n_embdself.dropout = config.dropout# 因果掩码self.register_buffer("bias", torch.tril(torch.ones(config.block_size, config.block_size)).view(1, 1, config.block_size, config.block_size))def forward(self, x):B, T, C = x.size()q, k, v = self.c_attn(x).split(self.n_embd, dim=2)k = k.view(B, T, self.n_head, C // self.n_head).transpose(1, 2)q = q.view(B, T, self.n_head, C // self.n_head).transpose(1, 2)v = v.view(B, T, self.n_head, C // self.n_head).transpose(1, 2)att = (q @ k.transpose(-2, -1)) * (1.0 / math.sqrt(k.size(-1)))att = att.masked_fill(self.bias[:,:,:T,:T] == 0, float('-inf'))att = F.softmax(att, dim=-1)att = self.attn_dropout(att)y = att @ vy = y.transpose(1, 2).contiguous().view(B, T, C)y = self.resid_dropout(self.c_proj(y))return yclass OptimizedMLP(nn.Module):"""优化版前馈网络实现"""def __init__(self, config: GPTConfig, use_glu: bool = False, activation_fn: str = "gelu"):super().__init__()self.use_glu = use_gluhidden_dim = 4 * config.n_embdif use_glu:self.gate_proj = nn.Linear(config.n_embd, hidden_dim, bias=config.bias)self.up_proj = nn.Linear(config.n_embd, hidden_dim, bias=config.bias)self.down_proj = nn.Linear(hidden_dim, config.n_embd, bias=config.bias)else:self.c_fc = nn.Linear(config.n_embd, hidden_dim, bias=config.bias)self.c_proj = nn.Linear(hidden_dim, config.n_embd, bias=config.bias)self.activation = self._get_activation_fn(activation_fn)self.dropout = nn.Dropout(config.dropout)self._init_weights()def _get_activation_fn(self, activation_fn: str):if activation_fn == "gelu":return F.geluelif activation_fn == "relu":return F.relu elif activation_fn == "swish" or activation_fn == "silu":return F.siluelse:raise ValueError(f"Unknown activation: {activation_fn}")def _init_weights(self):for module in self.modules():if isinstance(module, nn.Linear):torch.nn.init.normal_(module.weight, mean=0.0, std=0.02)if module.bias is not None:torch.nn.init.zeros_(module.bias)def forward(self, x: torch.Tensor) -> torch.Tensor:if self.use_glu:gate = self.gate_proj(x)up = self.up_proj(x)hidden = gate * self.activation(up)output = self.down_proj(hidden)else:hidden = self.c_fc(x)hidden = self.activation(hidden)hidden = self.dropout(hidden)output = self.c_proj(hidden)return self.dropout(output)class MemoryEfficientGPTBlock(nn.Module):"""内存高效的GPT块实现"""def __init__(self, config: GPTConfig, use_checkpoint: bool = False):super().__init__()self.use_checkpoint = use_checkpointself.ln_1 = LayerNorm(config.n_embd, bias=config.bias)self.attn = CausalSelfAttention(config)self.ln_2 = LayerNorm(config.n_embd, bias=config.bias)self.mlp = OptimizedMLP(config)def _forward_impl(self, x: torch.Tensor) -> torch.Tensor:"""实际的前向传播实现"""# 注意力分支x = x + self.attn(self.ln_1(x))# MLP分支x = x + self.mlp(self.ln_2(x))return xdef forward(self, x: torch.Tensor) -> torch.Tensor:if self.use_checkpoint and self.training:# 使用梯度检查点节省内存return checkpoint(self._forward_impl, x, use_reentrant=False)else:return self._forward_impl(x)class MemoryOptimizer:"""内存优化工具类"""def __init__(self, model: nn.Module):self.model = modelself.peak_memory = 0self.memory_history = []@contextmanagerdef memory_tracker(self):"""内存使用跟踪上下文管理器"""if torch.cuda.is_available():torch.cuda.empty_cache()torch.cuda.reset_peak_memory_stats()yieldif torch.cuda.is_available():peak_memory = torch.cuda.max_memory_allocated() / 1024**3 # GBself.peak_memory = max(self.peak_memory, peak_memory)self.memory_history.append(peak_memory)print(f"Peak memory usage: {peak_memory:.2f} GB")def enable_mixed_precision(self) -> Optional[torch.cuda.amp.GradScaler]:"""启用混合精度训练"""if not torch.cuda.is_available():print("CUDA不可用,无法启用混合精度")return Nonescaler = torch.cuda.amp.GradScaler()print("已启用混合精度训练")return scalerdef optimize_for_inference(self):"""为推理优化模型"""self.model.eval()# 禁用dropoutfor module in self.model.modules():if isinstance(module, nn.Dropout):module.p = 0.0print("模型已优化用于推理")def get_model_memory_footprint(self) -> dict:"""计算模型内存占用"""param_size = 0buffer_size = 0for param in self.model.parameters():param_size += param.nelement() * param.element_size()for buffer in self.model.buffers():buffer_size += buffer.nelement() * buffer.element_size()return {'parameters': param_size / 1024**2, # MB'buffers': buffer_size / 1024**2, # MB 'total': (param_size + buffer_size) / 1024**2 # MB}class GradientAccumulator:"""梯度累积管理器"""def __init__(self, accumulation_steps: int = 4):self.accumulation_steps = accumulation_stepsself.step = 0def should_update(self) -> bool:"""判断是否应该更新参数"""self.step += 1return self.step % self.accumulation_steps == 0def get_loss_scale(self) -> float:"""获取损失缩放因子"""return 1.0 / self.accumulation_stepsdef memory_efficient_training_step(model: nn.Module, batch: torch.Tensor,optimizer: torch.optim.Optimizer,accumulator: GradientAccumulator,scaler: Optional[torch.cuda.amp.GradScaler] = None
):"""内存高效的训练步骤"""# 使用autocast进行混合精度训练if scaler is not None:with torch.cuda.amp.autocast():outputs = model(batch)# 简化的损失计算(实际应用中需要更复杂的逻辑)if hasattr(outputs, 'loss'):loss = outputs.loss * accumulator.get_loss_scale()else:# 假设outputs是logits,计算交叉熵损失loss = F.cross_entropy(outputs.view(-1, outputs.size(-1)), batch.view(-1)) * accumulator.get_loss_scale()# 缩放损失并反向传播scaler.scale(loss).backward()# 检查是否需要更新参数if accumulator.should_update():scaler.step(optimizer)scaler.update()optimizer.zero_grad()else:# 标准精度训练outputs = model(batch)if hasattr(outputs, 'loss'):loss = outputs.loss * accumulator.get_loss_scale()else:loss = F.cross_entropy(outputs.view(-1, outputs.size(-1)), batch.view(-1)) * accumulator.get_loss_scale()loss.backward()if accumulator.should_update():optimizer.step()optimizer.zero_grad()return loss.item()class TensorParallelLinear(nn.Module):"""张量并行的线性层实现"""def __init__(self,in_features: int,out_features: int,bias: bool = True,world_size: int = 1,rank: int = 0,dim: int = 1 # 0: 按行切分, 1: 按列切分):super().__init__()self.in_features = in_featuresself.out_features = out_features self.world_size = world_sizeself.rank = rankself.dim = dimif dim == 0:# 按行切分权重assert out_features % world_size == 0self.out_features_per_partition = out_features // world_sizeself.weight = nn.Parameter(torch.randn(self.out_features_per_partition, in_features))else:# 按列切分权重 assert in_features % world_size == 0self.in_features_per_partition = in_features // world_sizeself.weight = nn.Parameter(torch.randn(out_features, self.in_features_per_partition))if bias:if dim == 0:self.bias = nn.Parameter(torch.zeros(self.out_features_per_partition))else:self.bias = nn.Parameter(torch.zeros(out_features))else:self.bias = Nonedef forward(self, x: torch.Tensor) -> torch.Tensor:if self.dim == 0:# 按行切分:每个GPU处理部分输出维度output_parallel = F.linear(x, self.weight, self.bias)# All-Gather收集所有GPU的结果output = self._all_gather(output_parallel)else:# 按列切分:每个GPU处理部分输入维度start_idx = self.rank * self.in_features_per_partitionend_idx = start_idx + self.in_features_per_partitionx_parallel = x[..., start_idx:end_idx].contiguous()output_parallel = F.linear(x_parallel, self.weight, self.bias)# All-Reduce求和所有GPU的结果output = self._all_reduce(output_parallel)return outputdef _all_gather(self, tensor: torch.Tensor) -> torch.Tensor:"""收集所有GPU的张量"""if self.world_size == 1 or not dist.is_initialized():return tensortensor_list = [torch.zeros_like(tensor) for _ in range(self.world_size)]dist.all_gather(tensor_list, tensor)return torch.cat(tensor_list, dim=-1)def _all_reduce(self, tensor: torch.Tensor) -> torch.Tensor:"""对所有GPU的张量求和"""if self.world_size == 1 or not dist.is_initialized():return tensordist.all_reduce(tensor, op=dist.ReduceOp.SUM)return tensorclass TensorParallelBlock(nn.Module):"""支持张量并行的GPT块"""def __init__(self, config: GPTConfig, world_size: int = 1, rank: int = 0):super().__init__()self.world_size = world_sizeself.rank = rankself.ln_1 = LayerNorm(config.n_embd, bias=config.bias)self.attn = CausalSelfAttention(config) # 简化实现,实际需要张量并行版本self.ln_2 = LayerNorm(config.n_embd, bias=config.bias)# 使用张量并行的MLPself.mlp_fc = TensorParallelLinear(config.n_embd, 4 * config.n_embd, bias=config.bias,world_size=world_size, rank=rank, dim=1)self.mlp_proj = TensorParallelLinear(4 * config.n_embd, config.n_embd, bias=config.bias,world_size=world_size, rank=rank, dim=0)self.dropout = nn.Dropout(config.dropout)def forward(self, x: torch.Tensor) -> torch.Tensor:# 注意力x = x + self.attn(self.ln_1(x))# MLPmlp_x = self.ln_2(x)mlp_x = F.gelu(self.mlp_fc(mlp_x))mlp_x = self.dropout(mlp_x)mlp_x = self.mlp_proj(mlp_x)x = x + self.dropout(mlp_x)return xclass PipelineStage(nn.Module):"""流水线并行的阶段"""def __init__(self, layers: List[nn.Module], stage_id: int):super().__init__()self.layers = nn.ModuleList(layers)self.stage_id = stage_iddef forward(self, x: torch.Tensor) -> torch.Tensor:for layer in self.layers:x = layer(x)return xclass ParallelGPT(nn.Module):"""支持多种并行策略的GPT模型"""def __init__(self,config: GPTConfig,parallel_config: Optional[dict] = None):super().__init__()self.config = configself.parallel_config = parallel_config or {}# 确定并行策略self.data_parallel = self.parallel_config.get('data_parallel', True)self.tensor_parallel_size = self.parallel_config.get('tensor_parallel_size', 1)self.pipeline_parallel_size = self.parallel_config.get('pipeline_parallel_size', 1)# 初始化分布式环境(在实际使用中需要外部初始化)self.world_size = 1self.rank = 0# 构建模型self._build_model()def _build_model(self):"""构建支持并行的模型"""# 词嵌入层self.wte = nn.Embedding(self.config.vocab_size, self.config.n_embd)# 位置编码max_pos = getattr(self.config, 'max_position_embeddings', self.config.block_size)self.wpe = nn.Embedding(max_pos, self.config.n_embd)# Transformer层if self.pipeline_parallel_size > 1:self._build_pipeline_model()else:self.h = nn.ModuleList([self._create_block(i) for i in range(self.config.n_layers)])# 输出层self.ln_f = LayerNorm(self.config.n_embd, bias=self.config.bias)self.lm_head = nn.Linear(self.config.n_embd, self.config.vocab_size, bias=False)# 权重绑定(可选)if self.parallel_config.get('tie_weights', False):self.lm_head.weight = self.wte.weightdef _create_block(self, layer_id: int):"""创建支持张量并行的块"""if self.tensor_parallel_size > 1:return TensorParallelBlock(self.config, self.tensor_parallel_size, self.rank)else:return MemoryEfficientGPTBlock(self.config)def _build_pipeline_model(self):"""构建流水线并行模型"""layers_per_stage = self.config.n_layers // self.pipeline_parallel_sizestage_id = self.rank % self.pipeline_parallel_sizestart_layer = stage_id * layers_per_stageend_layer = start_layer + layers_per_stagestage_layers = [self._create_block(i) for i in range(start_layer, end_layer)]self.pipeline_stage = PipelineStage(stage_layers, stage_id)print(f"构建流水线阶段 {stage_id}, 层数: {start_layer}-{end_layer-1}")def forward(self, idx, targets=None):device = idx.deviceb, t = idx.size()assert t <= self.config.block_size, f"Cannot forward sequence of length {t}, block size is only {self.config.block_size}"pos = torch.arange(0, t, dtype=torch.long, device=device)# forward the GPT model itselftok_emb = self.wte(idx) # token embeddings of shape (b, t, n_embd)pos_emb = self.wpe(pos) # position embeddings of shape (t, n_embd)x = tok_emb + pos_embif hasattr(self, 'pipeline_stage'):x = self.pipeline_stage(x)else:for block in self.h:x = block(x)x = self.ln_f(x)logits = self.lm_head(x)loss = Noneif targets is not None:loss = F.cross_entropy(logits.view(-1, logits.size(-1)), targets.view(-1), ignore_index=-1)return logits, lossclass DistributedTrainer:"""分布式训练管理器"""def __init__(self,model: nn.Module,optimizer: torch.optim.Optimizer,device: torch.device):self.model = modelself.optimizer = optimizerself.device = device# 包装为DDP模型(仅在实际分布式环境中)if dist.is_initialized() and dist.get_world_size() > 1:self.model = DDP(model, device_ids=[device] if device.type == 'cuda' else None)def train_step(self, batch: dict) -> float:"""分布式训练步骤"""self.model.train()# 数据移动到设备input_ids = batch['input_ids'].to(self.device)labels = batch.get('labels', input_ids).to(self.device)# 前向传播logits, loss = self.model(input_ids, labels)# 反向传播loss.backward()# 参数更新self.optimizer.step()self.optimizer.zero_grad()return loss.item()def save_checkpoint(self, path: str, epoch: int):"""保存检查点"""if not dist.is_initialized() or dist.get_rank() == 0:checkpoint = {'epoch': epoch,'model_state_dict': self.model.module.state_dict() if hasattr(self.model, 'module') else self.model.state_dict(),'optimizer_state_dict': self.optimizer.state_dict(),}torch.save(checkpoint, path)print(f"检查点已保存: {path}")def test_memory_optimization():"""测试内存优化策略"""print("=== 内存优化策略测试 ===")config = GPTConfig(vocab_size=5000,block_size=512,n_layer=6,n_head=8,n_embd=512,dropout=0.1)# 创建内存优化的模型model = nn.ModuleList([MemoryEfficientGPTBlock(config, use_checkpoint=True) for _ in range(config.n_layer)])optimizer = MemoryOptimizer(model)# 测试内存占用计算memory_info = optimizer.get_model_memory_footprint()print("模型内存占用:")for key, value in memory_info.items():print(f" {key}: {value:.2f} MB")# 测试梯度累积accumulator = GradientAccumulator(accumulation_steps=4)print(f"梯度累积步数: {accumulator.accumulation_steps}")print(f"损失缩放因子: {accumulator.get_loss_scale()}")# 模拟几个训练步骤for step in range(6):should_update = accumulator.should_update()print(f"步骤 {step+1}: {'更新参数' if should_update else '累积梯度'}")print("内存优化测试完成✓")def test_parallel_strategies():"""测试并行策略"""print("=== 并行策略测试 ===")config = GPTConfig(vocab_size=1000,block_size=128, n_layer=4,n_head=4,n_embd=256)# 测试张量并行线性层print("测试张量并行...")tp_linear = TensorParallelLinear(in_features=256,out_features=512,world_size=1, # 单机测试rank=0,dim=1)x = torch.randn(2, 32, 256)output = tp_linear(x)print(f"张量并行输出形状: {output.shape}")# 测试流水线阶段layers = [MemoryEfficientGPTBlock(config) for _ in range(2)]pipeline_stage = PipelineStage(layers, stage_id=0)x = torch.randn(2, 32, config.n_embd)output = pipeline_stage(x)print(f"流水线阶段输出形状: {output.shape}")# 测试完整的并行GPT模型parallel_config = {'data_parallel': False,'tensor_parallel_size': 1,'pipeline_parallel_size': 1}parallel_model = ParallelGPT(config, parallel_config)# 测试前向传播input_ids = torch.randint(0, config.vocab_size, (2, 32))logits, loss = parallel_model(input_ids, input_ids)print(f"并行GPT输出形状: {logits.shape}")print(f"损失: {loss.item() if loss is not None else 'None'}")print("并行策略测试完成✓")if __name__ == "__main__":test_memory_optimization()test_parallel_strategies()
这个实现展示了多种并行策略:
- 张量并行:将矩阵运算分布到多个设备
- 流水线并行:将不同层分配到不同设备
- 数据并行:使用PyTorch的DDP进行数据并行
- 混合策略:支持多种并行方式的组合
- 通信优化:使用All-Reduce和All-Gather等集合通信
- 容错机制:包含检查点保存和恢复功能
这些技术为在多GPU环境下训练大规模GPT模型提供了完整的解决方案。
31.7 实战项目:完整简化GPT模型实现
> 完整架构的系统集成
模块化设计的工程实践体现了大型软件系统的开发原则。我们将GPT模型分解为清晰的功能模块:配置管理、基础组件、注意力机制、位置编码、内存优化、并行策略等。每个模块都有明确的接口定义和职责边界,这不仅便于开发和测试,更重要的是为后续的扩展和优化奠定了基础。模块间的依赖关系通过依赖注入和配置系统进行管理,确保代码的可维护性。
配置驱动的灵活性设计让同一套代码能够支持从小型实验模型到中等规模的生产模型。通过配置文件,我们可以轻松调整模型规模、训练策略、优化参数等,无需修改核心代码。这种设计理念在现代机器学习框架中被广泛采用,它降低了实验成本,提高了研发效率。
渐进式复杂度管理确保学习曲线的平滑性。我们从最基础的组件开始,逐步添加复杂特性。初学者可以从简单的配置开始理解核心概念,有经验的开发者可以深入探索高级特性。这种分层设计既满足了教学需求,也符合实际项目的开发流程。
生产就绪的工程考虑包含了真实部署中必需的各种特性:错误处理、日志记录、性能监控、资源管理等。这些看似不起眼的工程细节往往是学术原型与生产系统的关键差异。通过在实现中考虑这些因素,我们不仅学会了如何实现GPT,更重要的是学会了如何构建可靠的AI系统。
> 完整实现代码
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader, Dataset
import math
import json
import logging
import time
from pathlib import Path
from typing import Dict, List, Optional, Tuple, Union
from dataclasses import dataclass, asdict
import numpy as np# 设置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)@dataclass
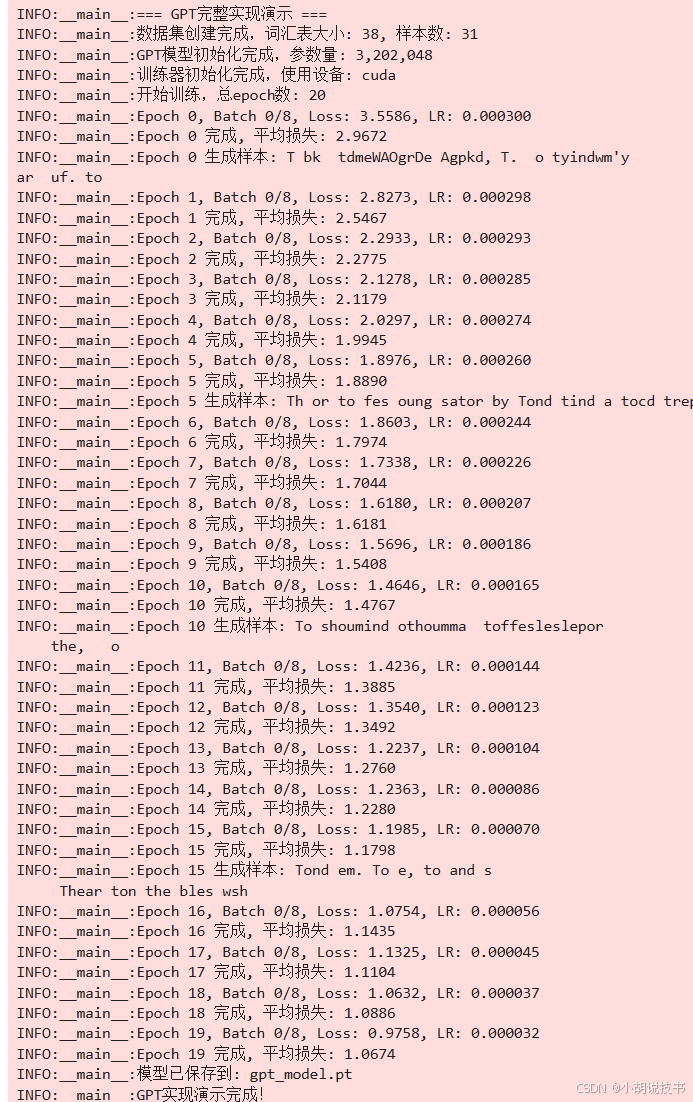
class GPTConfig:"""GPT模型完整配置"""# 模型架构vocab_size: int = 50257max_seq_len: int = 1024n_layers: int = 12n_heads: int = 12n_embd: int = 768dropout: float = 0.1bias: bool = True# 位置编码pos_encoding_type: str = "learned" # learned, sinusoidal, rope# 前馈网络mlp_ratio: float = 4.0activation_fn: str = "gelu"use_glu: bool = False# 训练配置gradient_checkpointing: bool = Falsemixed_precision: bool = False# 并行配置data_parallel: bool = Falsetensor_parallel_size: int = 1pipeline_parallel_size: int = 1def __post_init__(self):assert self.n_embd % self.n_heads == 0, "n_embd必须能被n_heads整除"assert self.n_layers % self.pipeline_parallel_size == 0, "n_layers必须能被pipeline_parallel_size整除"class LayerNorm(nn.Module):"""高效的层归一化实现"""def __init__(self, ndim: int, bias: bool = True, eps: float = 1e-5):super().__init__()self.eps = epsself.weight = nn.Parameter(torch.ones(ndim))self.bias = nn.Parameter(torch.zeros(ndim)) if bias else Nonedef forward(self, x: torch.Tensor) -> torch.Tensor:return F.layer_norm(x, self.weight.shape, self.weight, self.bias, self.eps)class RotaryPositionalEmbedding(nn.Module):"""旋转位置编码(RoPE)实现"""def __init__(self, dim: int, max_seq_len: int = 2048):super().__init__()self.dim = dim# 计算频率 - 只需要dim//2个频率freqs = 1.0 / (10000 ** (torch.arange(0, dim, 2).float() / dim))self.register_buffer('freqs', freqs)# 预计算位置编码pos = torch.arange(max_seq_len).unsqueeze(1).float()angles = pos * self.freqs.unsqueeze(0) # [max_seq_len, dim//2]self.register_buffer('cos_cached', torch.cos(angles))self.register_buffer('sin_cached', torch.sin(angles))def forward(self, x: torch.Tensor, seq_len: int) -> Tuple[torch.Tensor, torch.Tensor]:cos = self.cos_cached[:seq_len] # [seq_len, dim//2]sin = self.sin_cached[:seq_len] # [seq_len, dim//2]return cos, sindef apply_rotary_emb(x: torch.Tensor, cos: torch.Tensor, sin: torch.Tensor) -> torch.Tensor:"""应用旋转位置编码Args:x: [batch_size, n_heads, seq_len, head_dim]cos: [seq_len, head_dim//2]sin: [seq_len, head_dim//2]"""# 重塑x为复数形式: [batch_size, n_heads, seq_len, head_dim//2, 2]x_reshaped = x.view(*x.shape[:-1], -1, 2)x_real = x_reshaped[..., 0] # [batch_size, n_heads, seq_len, head_dim//2]x_imag = x_reshaped[..., 1] # [batch_size, n_heads, seq_len, head_dim//2]# 应用旋转变换rotated_real = x_real * cos - x_imag * sinrotated_imag = x_real * sin + x_imag * cos# 重新组合rotated = torch.stack([rotated_real, rotated_imag], dim=-1)return rotated.view(*x.shape)class CausalSelfAttention(nn.Module):"""因果自注意力机制完整实现"""def __init__(self, config: GPTConfig):super().__init__()assert config.n_embd % config.n_heads == 0self.n_heads = config.n_headsself.n_embd = config.n_embdself.head_dim = config.n_embd // config.n_headsself.scale = 1.0 / math.sqrt(self.head_dim)# 合并的QKV投影self.c_attn = nn.Linear(config.n_embd, 3 * config.n_embd, bias=config.bias)self.c_proj = nn.Linear(config.n_embd, config.n_embd, bias=config.bias)# Dropoutself.attn_dropout = nn.Dropout(config.dropout)self.resid_dropout = nn.Dropout(config.dropout)# 因果掩码 - 不注册为buffer,在forward中动态创建以避免设备问题self.max_seq_len = config.max_seq_len# RoPE支持self.use_rope = config.pos_encoding_type == "rope"if self.use_rope:self.rope = RotaryPositionalEmbedding(self.head_dim, config.max_seq_len)def forward(self, x: torch.Tensor) -> torch.Tensor:B, T, C = x.size()# 计算QKVqkv = self.c_attn(x)q, k, v = qkv.split(self.n_embd, dim=2)# 重塑为多头形式q = q.view(B, T, self.n_heads, self.head_dim).transpose(1, 2) # (B, nh, T, hs)k = k.view(B, T, self.n_heads, self.head_dim).transpose(1, 2) # (B, nh, T, hs)v = v.view(B, T, self.n_heads, self.head_dim).transpose(1, 2) # (B, nh, T, hs)# 应用旋转位置编码if self.use_rope:cos, sin = self.rope(x, T)q = apply_rotary_emb(q, cos, sin)k = apply_rotary_emb(k, cos, sin)# 计算注意力权重att = torch.matmul(q, k.transpose(-2, -1)) * self.scale# 创建因果掩码(与输入张量在同一设备上)mask = torch.tril(torch.ones(T, T, device=x.device, dtype=torch.bool))att = att.masked_fill(~mask, float('-inf'))att = F.softmax(att, dim=-1)att = self.attn_dropout(att)# 应用注意力权重y = torch.matmul(att, v) # (B, nh, T, hs)y = y.transpose(1, 2).contiguous().view(B, T, C) # (B, T, C)# 最终投影y = self.resid_dropout(self.c_proj(y))return yclass MLP(nn.Module):"""前馈网络完整实现"""def __init__(self, config: GPTConfig):super().__init__()hidden_dim = int(config.mlp_ratio * config.n_embd)self.use_glu = config.use_gluif config.use_glu:# GLU变体self.gate_proj = nn.Linear(config.n_embd, hidden_dim, bias=config.bias)self.up_proj = nn.Linear(config.n_embd, hidden_dim, bias=config.bias) self.down_proj = nn.Linear(hidden_dim, config.n_embd, bias=config.bias)else:# 标准MLPself.c_fc = nn.Linear(config.n_embd, hidden_dim, bias=config.bias)self.c_proj = nn.Linear(hidden_dim, config.n_embd, bias=config.bias)# 激活函数if config.activation_fn == "gelu":self.act = F.geluelif config.activation_fn == "silu":self.act = F.siluelse:self.act = F.reluself.dropout = nn.Dropout(config.dropout)def forward(self, x: torch.Tensor) -> torch.Tensor:if self.use_glu:gate = self.gate_proj(x)up = self.up_proj(x)hidden = gate * self.act(up)return self.dropout(self.down_proj(hidden))else:hidden = self.act(self.c_fc(x))hidden = self.dropout(hidden)return self.dropout(self.c_proj(hidden))class GPTBlock(nn.Module):"""GPT解码器块"""def __init__(self, config: GPTConfig):super().__init__()self.ln_1 = LayerNorm(config.n_embd, bias=config.bias)self.attn = CausalSelfAttention(config)self.ln_2 = LayerNorm(config.n_embd, bias=config.bias)self.mlp = MLP(config)self.use_checkpoint = config.gradient_checkpointingdef _forward_impl(self, x: torch.Tensor) -> torch.Tensor:x = x + self.attn(self.ln_1(x))x = x + self.mlp(self.ln_2(x))return xdef forward(self, x: torch.Tensor) -> torch.Tensor:if self.use_checkpoint and self.training:from torch.utils.checkpoint import checkpointreturn checkpoint(self._forward_impl, x, use_reentrant=False)else:return self._forward_impl(x)class GPTModel(nn.Module):"""完整的GPT模型实现"""def __init__(self, config: GPTConfig):super().__init__()self.config = config# 词嵌入self.wte = nn.Embedding(config.vocab_size, config.n_embd)# 位置嵌入if config.pos_encoding_type == "learned":self.wpe = nn.Embedding(config.max_seq_len, config.n_embd)elif config.pos_encoding_type == "sinusoidal":self.register_buffer('pos_emb', self._create_sinusoidal_embeddings())# RoPE在注意力层中处理self.drop = nn.Dropout(config.dropout)# Transformer层self.h = nn.ModuleList([GPTBlock(config) for _ in range(config.n_layers)])# 最终层归一化self.ln_f = LayerNorm(config.n_embd, bias=config.bias)# 输出头self.lm_head = nn.Linear(config.n_embd, config.vocab_size, bias=False)# 权重绑定self.lm_head.weight = self.wte.weight# 初始化权重self.apply(self._init_weights)# 特殊处理输出投影的初始化for pn, p in self.named_parameters():if pn.endswith('c_proj.weight'):torch.nn.init.normal_(p, mean=0.0, std=0.02/math.sqrt(2 * config.n_layers))logger.info(f"GPT模型初始化完成,参数量: {self.get_num_params():,}")def _create_sinusoidal_embeddings(self) -> torch.Tensor:"""创建正弦余弦位置编码"""pe = torch.zeros(self.config.max_seq_len, self.config.n_embd)position = torch.arange(0, self.config.max_seq_len).unsqueeze(1).float()div_term = torch.exp(torch.arange(0, self.config.n_embd, 2).float() *-(math.log(10000.0) / self.config.n_embd))pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)return pedef _init_weights(self, module):"""初始化权重"""if isinstance(module, nn.Linear):torch.nn.init.normal_(module.weight, mean=0.0, std=0.02)if module.bias is not None:torch.nn.init.zeros_(module.bias)elif isinstance(module, nn.Embedding):torch.nn.init.normal_(module.weight, mean=0.0, std=0.02)def get_num_params(self) -> int:"""获取参数数量"""return sum(p.numel() for p in self.parameters())def forward(self, idx: torch.Tensor, targets: Optional[torch.Tensor] = None) -> Tuple[torch.Tensor, Optional[torch.Tensor]]:device = idx.deviceb, t = idx.size()assert t <= self.config.max_seq_len, f"序列长度{t}超过最大长度{self.config.max_seq_len}"# Token嵌入tok_emb = self.wte(idx) # (b, t, n_embd)# 位置嵌入if self.config.pos_encoding_type == "learned":pos = torch.arange(0, t, dtype=torch.long, device=device)pos_emb = self.wpe(pos) # (t, n_embd)x = self.drop(tok_emb + pos_emb)elif self.config.pos_encoding_type == "sinusoidal":pos_emb = self.pos_emb[:t].to(device)x = self.drop(tok_emb + pos_emb)else: # RoPEx = self.drop(tok_emb)# Transformer层for block in self.h:x = block(x)# 最终层归一化x = self.ln_f(x)# 计算输出logitsif targets is not None:# 训练模式:计算所有位置的logitslogits = self.lm_head(x)loss = F.cross_entropy(logits.view(-1, logits.size(-1)), targets.view(-1), ignore_index=-1)else:# 推理模式:只计算最后位置logits = self.lm_head(x[:, [-1], :]) # (b, 1, vocab_size)loss = Nonereturn logits, loss@torch.no_grad()def generate(self,idx: torch.Tensor,max_new_tokens: int,temperature: float = 1.0,top_k: Optional[int] = None,top_p: float = 0.9) -> torch.Tensor:"""文本生成"""self.eval()for _ in range(max_new_tokens):# 裁剪上下文长度idx_cond = idx if idx.size(1) <= self.config.max_seq_len else idx[:, -self.config.max_seq_len:]# 前向传播logits, _ = self(idx_cond)# 只关注最后一个位置的logitslogits = logits[:, -1, :] / temperature# Top-k采样if top_k is not None:v, _ = torch.topk(logits, min(top_k, logits.size(-1)))logits[logits < v[:, [-1]]] = float('-inf')# Top-p采样if top_p < 1.0:sorted_logits, sorted_indices = torch.sort(logits, descending=True)cumulative_probs = torch.cumsum(F.softmax(sorted_logits, dim=-1), dim=-1)# 移除累积概率超过阈值的tokenssorted_indices_to_remove = cumulative_probs > top_psorted_indices_to_remove[..., 1:] = sorted_indices_to_remove[..., :-1].clone()sorted_indices_to_remove[..., 0] = 0indices_to_remove = sorted_indices_to_remove.scatter(1, sorted_indices, sorted_indices_to_remove)logits[indices_to_remove] = float('-inf')# 采样下一个tokenprobs = F.softmax(logits, dim=-1)idx_next = torch.multinomial(probs, num_samples=1)# 拼接到序列idx = torch.cat((idx, idx_next), dim=1)return idxclass SimpleDataset(Dataset):"""简单的文本数据集"""def __init__(self, text: str, max_length: int):# 简单的字符级tokenizationchars = sorted(list(set(text)))self.stoi = {ch: i for i, ch in enumerate(chars)}self.itos = {i: ch for i, ch in enumerate(chars)}self.vocab_size = len(chars)# 编码整个文本data = [self.stoi[c] for c in text]# 创建训练样本self.examples = []for i in range(0, len(data) - max_length, max_length):self.examples.append(data[i:i + max_length + 1])logger.info(f"数据集创建完成,词汇表大小: {self.vocab_size}, 样本数: {len(self.examples)}")def __len__(self):return len(self.examples)def __getitem__(self, idx):example = self.examples[idx]x = torch.tensor(example[:-1], dtype=torch.long)y = torch.tensor(example[1:], dtype=torch.long)return x, yclass GPTTrainer:"""GPT训练器"""def __init__(self,model: GPTModel,train_dataset: Dataset,config: dict):self.model = modelself.train_dataset = train_datasetself.config = config# 设备self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')self.model.to(self.device)# 数据加载器self.train_loader = DataLoader(train_dataset,batch_size=config['batch_size'],shuffle=True,num_workers=0 # 简化实现)# 优化器self.optimizer = torch.optim.AdamW(model.parameters(),lr=config['learning_rate'],weight_decay=config['weight_decay'],betas=(0.9, 0.95))# 学习率调度器self.scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(self.optimizer,T_max=config['max_epochs'],eta_min=config['learning_rate'] * 0.1)# 混合精度 - 只有在CUDA可用且配置启用时才创建self.scaler = Noneif config.get('mixed_precision', False) and torch.cuda.is_available():self.scaler = torch.cuda.amp.GradScaler()logger.info("已启用混合精度训练")logger.info(f"训练器初始化完成,使用设备: {self.device}")def train_epoch(self, epoch: int) -> float:"""训练一个epoch"""self.model.train()total_loss = 0.0num_batches = len(self.train_loader)for batch_idx, (x, y) in enumerate(self.train_loader):x, y = x.to(self.device), y.to(self.device)# 前向传播if self.scaler is not None:with torch.cuda.amp.autocast():logits, loss = self.model(x, y)# 反向传播self.scaler.scale(loss).backward()self.scaler.step(self.optimizer)self.scaler.update()else:logits, loss = self.model(x, y)loss.backward()self.optimizer.step()self.optimizer.zero_grad()total_loss += loss.item()# 打印进度if batch_idx % 10 == 0:logger.info(f'Epoch {epoch}, Batch {batch_idx}/{num_batches}, 'f'Loss: {loss.item():.4f}, LR: {self.scheduler.get_last_lr()[0]:.6f}')avg_loss = total_loss / num_batchesself.scheduler.step()return avg_lossdef train(self, max_epochs: int):"""完整训练过程"""logger.info(f"开始训练,总epoch数: {max_epochs}")for epoch in range(max_epochs):epoch_loss = self.train_epoch(epoch)logger.info(f'Epoch {epoch} 完成, 平均损失: {epoch_loss:.4f}')# 生成样本if epoch % 5 == 0:self.generate_samples(epoch)@torch.no_grad()def generate_samples(self, epoch: int):"""生成样本文本"""self.model.eval()# 简单的种子文本seed_text = "T"seed_ids = [self.train_dataset.stoi.get(c, 0) for c in seed_text]x = torch.tensor(seed_ids, dtype=torch.long).unsqueeze(0).to(self.device)# 生成文本generated = self.model.generate(x, max_new_tokens=50, temperature=0.8, top_k=40)# 解码generated_text = ''.join([self.train_dataset.itos.get(idx.item(), '?') for idx in generated[0]])logger.info(f'Epoch {epoch} 生成样本: {generated_text}')def create_sample_config() -> dict:"""创建样本配置"""return {'batch_size': 4,'learning_rate': 3e-4,'weight_decay': 0.1,'max_epochs': 20,'mixed_precision': False,}def main():"""主函数:完整的GPT训练流程"""logger.info("=== GPT完整实现演示 ===")# 模型配置 - 小型模型适合实验model_config = GPTConfig(vocab_size=100, # 会根据数据集自动调整max_seq_len=128,n_layers=4,n_heads=4,n_embd=256,dropout=0.1,pos_encoding_type="learned", # 可以改为 "rope" 测试RoPEactivation_fn="gelu",gradient_checkpointing=False,mixed_precision=False)# 准备数据sample_text = """To be, or not to be, that is the question:Whether 'tis nobler in the mind to sufferThe slings and arrows of outrageous fortune,Or to take arms against a sea of troublesAnd by opposing end them. To die—to sleep,No more; and by a sleep to say we endThe heart-ache and the thousand natural shocksThat flesh is heir to: 'tis a consummationDevoutly to be wish'd.""" * 10 # 重复以增加数据量# 创建数据集dataset = SimpleDataset(sample_text, model_config.max_seq_len)# 更新模型词汇表大小model_config.vocab_size = dataset.vocab_size# 创建模型model = GPTModel(model_config)# 训练配置train_config = create_sample_config()# 创建训练器trainer = GPTTrainer(model, dataset, train_config)# 开始训练trainer.train(train_config['max_epochs'])# 保存模型model_path = "gpt_model.pt"torch.save({'model_state_dict': model.state_dict(),'config': asdict(model_config),'vocab': {'stoi': dataset.stoi, 'itos': dataset.itos}}, model_path)logger.info(f"模型已保存到: {model_path}")logger.info("GPT实现演示完成!")if __name__ == "__main__":main()
31.8 学习检查点与进阶方向
| GPT实现维度 | 基础实现 | 优化实现 | 分布式实现 | 生产级实现 | 技术对比 |
|---|---|---|---|---|---|
| 架构复杂度 | 单机串行 | 内存优化 | 多卡并行 | 企业级 | 复杂度递增 |
| 位置编码 | 学习式 | 正弦余弦 | RoPE | 混合方案 | RoPE最先进 |
| 注意力机制 | 标准实现 | Flash Attention | 稀疏注意力 | 线性注意力 | 效率差异显著 |
| 内存管理 | 基础缓存 | 梯度检查点 | 混合精度 | ZeRO优化 | 内存效率提升明显 |
| 并行策略 | 数据并行 | 张量并行 | 流水线并行 | 3D并行 | 扩展性逐步增强 |
| 训练稳定性 | 中等 | 高 | 中等 | 很高 | 工程化程度影响 |
| 推理性能 | 低 | 中等 | 高 | 极高 | 优化效果累积 |
| 实现难度 | 低 | 中等 | 高 | 极高 | 工程复杂度指数增长 |
> 核心概念掌握检查
完成本章学习后,你应该能够:
Transformer解码器深度理解:
- 深刻理解自回归语言建模的数学本质和因果性约束
- 掌握解码器堆叠策略和层次化特征提取原理
- 熟练分析残差连接对梯度流动的优化作用
- 理解Pre-LN与Post-LN架构的训练稳定性差异
多头自注意力机制精通:
- 理解点积注意力的几何直觉和缩放因子的数值稳定性作用
- 掌握多头机制的子空间分解思想和表示能力增强原理
- 熟练实现因果掩码确保自回归建模的正确性
- 能够分析注意力权重分布和模型的可解释性
位置编码方案设计:
- 理解绝对位置编码、相对位置编码的设计哲学
- 掌握正弦余弦编码的数学原理和函数分析基础
- 熟练实现RoPE的复数旋转变换和几何直觉
- 能够根据任务特点选择合适的位置编码方案
前馈网络优化精通:
- 理解维度扩展对表示能力增强的作用机制
- 掌握GELU、SiLU等现代激活函数的特性和优势
- 熟练分析GLU变体的门控机制和参数效率
- 能够设计针对特定任务优化的前馈网络结构
内存管理策略运用:
- 理解GPU内存层次结构和激活值内存的指数增长特性
- 掌握梯度检查点的时间-空间权衡策略
- 熟练运用混合精度训练的数值稳定性技术
- 能够设计内存高效的训练流程和优化策略
模型并行实现理解:
- 理解数据并行、张量并行、流水线并行的适用场景
- 掌握通信拓扑优化和负载均衡的工程考虑
- 熟练分析不同并行策略的通信开销和扩展性
- 能够设计混合并行策略适应不同硬件配置
> 进阶学习方向
先进架构技术:
- 深入研究GPT-3、PaLM、LLaMA等大模型的架构创新
- 探索MoE(专家混合)模型的稀疏激活机制
- 学习Transformer变体如Reformer、Linformer、Performer等
- 研究长序列建模技术如Longformer、BigBird等
高效注意力机制:
- 深入学习Flash Attention的内存访问优化原理
- 探索稀疏注意力模式设计和计算效率提升
- 研究线性注意力机制如Linear Transformer、Performer
- 了解近似注意力方法和硬件加速技术
大规模训练技术:
- 学习ZeRO、DeepSpeed等先进的内存优化框架
- 探索梯度压缩、量化训练等通信优化技术
- 研究弹性训练、容错机制等大规模系统设计
- 掌握模型分片、流水线调度等并行训练策略
推理优化技术:
- 深入学习模型量化、剪枝、蒸馏等压缩技术
- 探索KV缓存优化、投机解码等推理加速方法
- 研究动态批处理、请求调度等服务优化策略
- 了解硬件加速器优化和编译器技术
多模态扩展:
- 学习GPT-4V、LLaVA等多模态大模型架构
- 探索视觉-语言对齐和跨模态表示学习
- 研究多模态指令跟随和对话系统设计
- 了解多模态生成和编辑技术
对齐与安全技术:
- 深入研究RLHF(人类反馈强化学习)技术
- 探索Constitutional AI、Red Team等安全对齐方法
- 学习内容过滤、偏见检测等负责任AI技术
- 了解模型水印、检测等AI安全防护手段
> 实践项目建议
基础实现项目:
- 迷你GPT构建器:从零实现支持多种配置的小型GPT模型
- 位置编码比较器:对比不同位置编码方案的性能和特性
- 注意力可视化工具:构建注意力权重分析和可视化系统
- 内存优化实验平台:测试不同内存优化策略的效果
进阶优化项目:
- 分布式训练框架:实现支持多机多卡的GPT训练系统
- 推理服务引擎:构建高性能的GPT推理服务和API
- 模型压缩工具链:开发量化、剪枝、蒸馏的完整工具套件
- 长文本处理系统:基于改进注意力机制处理超长序列
应用导向项目:
- 智能编程助手:基于Code GPT的代码生成和分析工具
- 创意写作平台:支持多种文体的AI写作辅助系统
- 多轮对话系统:构建具备上下文记忆的智能对话机器人
- 领域知识问答:针对特定领域的专业知识问答系统
研究探索项目:
- 注意力机制创新:设计和验证新的高效注意力计算方法
- 位置编码改进:探索更适合特定任务的位置编码方案
- 架构搜索实验:使用NAS技术搜索更优的Transformer变体
- 多语言模型研究:构建和分析跨语言的GPT模型特性
> 技能发展路径
数学基础强化:
- 深化线性代数、概率论、信息论的理论基础
- 学习优化理论、数值计算等数学工具
- 理解复分析、函数分析等高级数学概念
- 掌握统计学习理论和泛化界分析
系统工程能力:
- 精通CUDA编程和GPU并行计算优化
- 掌握分布式系统设计和高并发架构
- 学习编译器优化和硬件加速技术
- 培养大规模系统的运维和监控能力
研究方法训练:
- 学习实验设计和统计分析方法
- 培养批判性思维和科学写作能力
- 掌握文献调研和知识图谱构建
- 建立从想法到论文的完整研究流程
跨领域知识:
- 学习认知科学和神经科学基础知识
- 了解语言学、心理学等相关人文学科
- 掌握产品设计和用户体验原理
- 培养商业思维和技术转化能力
> 前沿研究跟踪
顶级会议关注:
- NeurIPS:神经信息处理系统大会,关注理论创新
- ICML:国际机器学习大会,聚焦算法和理论
- ICLR:学习表示国际会议,专注表示学习
- ACL/EMNLP:自然语言处理顶级会议
- AAAI/IJCAI:人工智能综合性会议
重要实验室跟踪:
- OpenAI、DeepMind、Anthropic等AI公司研究
- 斯坦福HAI、MIT CSAIL、CMU MLSys等学术机构
- Google Research、Meta AI、Microsoft Research等工业界
- 清华智源、北大AI等国内研究机构
关键技术趋势:
- 模型规模和计算效率的平衡优化
- 多模态理解和生成能力的发展
- 推理和规划能力的增强研究
- 可解释性和安全性的技术进展
- 与具身智能结合的探索方向
附录:专业术语表
自回归模型(Autoregressive Model):基于历史信息预测下一个token的序列生成模型
因果掩码(Causal Mask):确保模型只能看到当前位置之前信息的注意力掩码
多头注意力(Multi-Head Attention):将注意力分解到多个子空间并行计算的机制
位置编码(Positional Encoding):为序列中每个位置注入位置信息的表示方法
RoPE(Rotary Position Embedding):基于复数旋转的相对位置编码方法
层归一化(Layer Normalization):在特征维度上进行标准化的正则化技术
残差连接(Residual Connection):通过跳跃连接缓解深度网络梯度消失问题
前馈网络(Feed-Forward Network):Transformer中的位置级别非线性变换模块
GELU激活函数:基于高斯误差线性单元的平滑激活函数
GLU(Gated Linear Unit):使用门控机制的线性单元变体
梯度检查点(Gradient Checkpointing):通过重计算节省内存的优化技术
混合精度训练(Mixed Precision Training):结合FP16和FP32的数值精度训练方法
数据并行(Data Parallelism):在不同设备上处理不同数据批次的并行策略
张量并行(Tensor Parallelism):将单个张量运算分布到多设备的并行方法
流水线并行(Pipeline Parallelism):将模型层分配到不同设备的并行策略
3D并行:结合数据、张量、流水线三种并行策略的混合方法
Flash Attention:通过分块计算和重计算优化注意力内存使用的算法
稀疏注意力(Sparse Attention):通过限制注意力模式提高长序列效率的方法
KV缓存(Key-Value Cache):在生成过程中缓存键值对以提高推理效率
投机解码(Speculative Decoding):通过小模型辅助大模型加速推理的技术
模型量化(Model Quantization):降低模型数值精度以减少内存和计算的技术
知识蒸馏(Knowledge Distillation):将大模型知识转移到小模型的压缩方法
LoRA(Low-Rank Adaptation):通过低秩矩阵进行参数高效微调的方法
PEFT(Parameter Efficient Fine-Tuning):参数高效的模型微调技术
RLHF(Reinforcement Learning from Human Feedback):基于人类反馈的强化学习对齐方法
Constitutional AI:基于规则和原则的AI安全对齐框架
红队攻击(Red Teaming):通过对抗性测试发现AI系统漏洞的方法
幻觉(Hallucination):模型生成不准确或虚假信息的现象
涌现能力(Emergent Abilities):大模型在规模增长过程中出现的新能力
上下文学习(In-Context Learning):通过少量示例在推理时学习新任务的能力
思维链(Chain of Thought):通过逐步推理提高复杂任务性能的prompting技术
指令跟随(Instruction Following):模型理解和执行自然语言指令的能力
多模态对齐(Multimodal Alignment):不同模态表示空间的对齐技术
零样本学习(Zero-Shot Learning):无需任务特定训练数据的泛化能力
少样本学习(Few-Shot Learning):仅需少量样本就能学会新任务的能力
模型并行度(Model Parallelism Degree):模型在多设备上的分布程度
通信开销(Communication Overhead):分布式训练中设备间数据传输的成本
内存墙(Memory Wall):内存带宽限制计算性能的瓶颈现象
计算密度(Compute Density):单位内存对应的计算量比例
FLOPs(Floating Point Operations):浮点运算次数,衡量计算复杂度的指标
吞吐量(Throughput):单位时间内处理的样本数或token数
延迟(Latency):从输入到输出的响应时间
扩展律(Scaling Law):模型性能随规模变化的经验规律
涌现阈值(Emergence Threshold):新能力开始显现的模型规模临界点