WebDancer论文阅读
论文提出了一个端到端的agentic信息检索智能体的范式,能够适配大部分开源模型。
一、总览
包括四个阶段:(1)浏览数据构建,(2)轨迹采样。(3)用于有效冷启动的监督微调,以及(4)用于增强泛化的强化学习。
二、数据构建
1.QA对构建
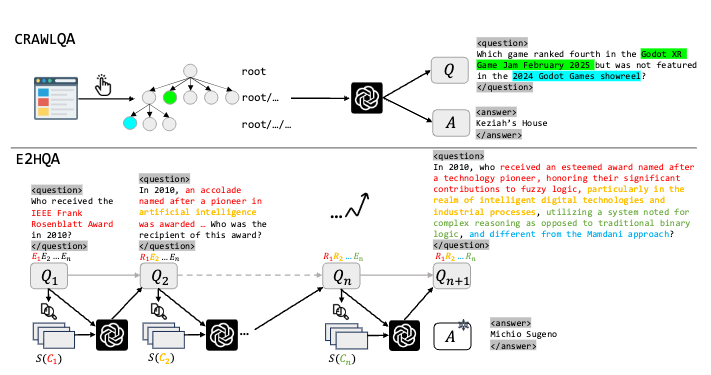
构建了crawlQA 和 e2hQA。
crawlQA是从网页爬取的,从根站点出发,递归访问子页面,最终使用GPT-4o合成问答对。
e2hQA从一个简单问题的一个实体出发,逐步将这个实体转换为一个子问题,通过这样逐步深入,控制搜索步骤。
2.智能体轨迹拒绝采样
基于react范式。这里只有三个动作(搜索、浏览,回答)

分别使用gpt-4o收集短cot,qwq-plus收集长cot。
使用三阶段的轨迹过滤框架进行拒绝采样

三、后训练
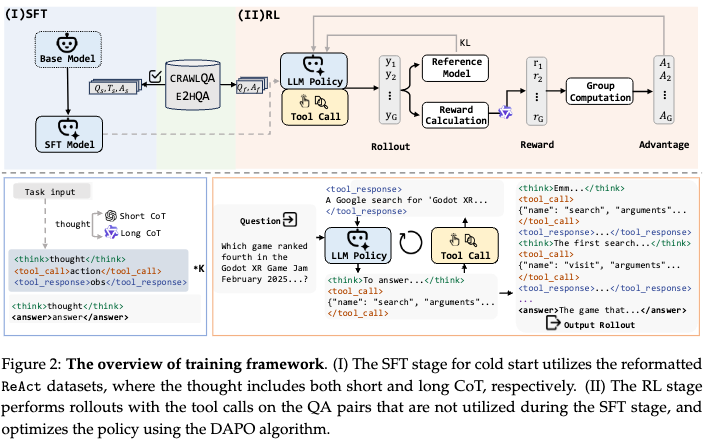
1.agent监督微调



2.agent的rl
采用DAPO算法

奖励函数设计方面,设计了格式和结果奖励,都是0/1。因为sft在格式上基本OK,所以占比是1:9。
四、结论和分析
高质量的轨迹数据对于智能体的有效 SFT 至关重要;
针对冷启动的 SFT 至关重要,因为智能体任务要求具备强大的多步多工具指令跟随能力。
强推理模型所使用的思考模式知识难以转移到小型指令
模型上。
强化学习(RL)能够实现更长的推理过程,并支持更复杂的 Agentic 动作。
Web 智能体在一个动态、不断演化的环境中执行任务,这种环境本质上难以稳定。