webrtc之语音活动下——VAD人声判定原理以及源码详解
文章目录
- 前言
- 一、高斯混合模型介绍
- 1.高斯模型举例
- 1)定义
- 2)举例说明
- 2.高斯混合模型(GMM)
- 1)定义
- 2)举例说明
- 3)一维曲线
- 二、VAD高斯混合模型
- 1.模型训练介绍
- 1)训练方法
- 2)训练结果
- 2.噪声高斯模型分布
- 1)matlab代码
- 2)结果
- 2.人声高斯模型分布
- 三、VAD人声判断
- 1.高斯分布计算
- 1)公式
- 2)对应代码
- 2.人声判定策略
- 1)判断机制
- 2)重要阈值确认
- 3)整体流程
- 第一步:计算噪声/人声概率分布
- 第二步:噪声/人声比较
- 第三步:判断单个阈值
- 第四步:全局判定
- 四、模型更新
- 1.计算条件概率
- 2.获取噪声基线和均值
- 1)噪声基线的作用
- 2)确定噪声基线
- 3)获取噪声均值
- 3.更新噪声均值
- 1)短时更新
- 2)平滑修正
- 3)边界约束
- 4)策略意义
- 4.更新人声均值
- 5.更新人声方差
- 1)更新公式
- 2)代码解析
- 3)边界约束
- 6.更新噪声方差
- 7.模型分离
- 1)计算全局均值
- 2)计算差值
- 3)如果模型太近,强行拉开
- 4)限制模型漂移范围
- 五、hangover 机制
- 1.策略作用
- 2.整体流程
- 3.对应代码
- 1)非语音处理
- 2)语音
- 总结
前言
在上一篇文章中,介绍了VAD对于能量的计算原理和策略介绍。本篇文章中讲进一步介绍VAD中的人声/噪声决策,这是基于高斯混合模型,也就是GMM进行计算的。
本篇文章将会对照源码、结合图像进行介绍:
- GMM模型介绍(可以跳过)
- webrtc中VAD的高斯模型(包括来源以及使用)
- 人声/噪声决策以及在线更新机制
- hangover机制
本篇文章比较长,可以耐心观看。
|版本声明:山河君,未经博主允许,禁止转载
一、高斯混合模型介绍
如果对于高斯模型很熟悉那么可以跳过这一节,这里需要明白的是概率密度、区间概率和条件概率的区别。
1.高斯模型举例
1)定义
高斯分布(又叫正态分布)是一种常见的概率分布,它的概率密度也叫做似然函数(PDF)是:
p(x)=12πσ2exp(−(x−μ)22σ2)p(x)=\frac{1}{\sqrt{2\pi\sigma^2}}\exp\Big(-\frac{(x-\mu)^2}{2\sigma^2}\Big)p(x)=2πσ21exp(−2σ2(x−μ)2)
- μ\muμ为均值:分布的中心位置,数据大部分集中在它附近。
- σ2\sigma^2σ2表示方差:分布的宽度,数值越大,图像分布越平;数值越小,分布越尖。
而使用高斯分布计算区间概率公式为:
P(a<X<b)=∫abp(x)dxP(a<X<b)=\int_a^bp(x)dxP(a<X<b)=∫abp(x)dx
2)举例说明
假设有一门数学考试,100 分满分,有5个学生的成绩分别是60,70,80,75,6560,70,80,75,6560,70,80,75,65:
- 均值μ\muμ:μ=1N∑i=1Nxi=60+70+80+75+655=70\mu=\frac{1}{N}\sum_{i=1}^{N}x_i = \frac{60+70+80+75+65}{5}=70μ=N1∑i=1Nxi=560+70+80+75+65=70
- 方差σ2=1N∑i=1N(xi−μ)2=(−10)2+02+102+52+(−5)25=50\sigma^2=\frac{1}{N}\sum_{i=1}^{N}(x_i-\mu)^2=\frac{(-10)^2+0^2+10^2+5^2+(-5)^2}{5}=50σ2=N1∑i=1N(xi−μ)2=5(−10)2+02+102+52+(−5)2=50
那么现在还有一个学生
- 他的成绩为737373分的概率带入公式最终结果为:5.16%5.16\%5.16%
- 他的成绩在[70,75][70,75][70,75]分之间的概率带入公式为:26%26\%26%
2.高斯混合模型(GMM)
1)定义
GMM 就是多个高斯分布的加权和,它的概率密度公式是:
p(x)=∑k=1Kwk⋅N(x∣uk,σk2)p(x)=\sum_{k=1}^{K}w_k \cdot \Nu(x|u_k,\sigma_k^2)p(x)=k=1∑Kwk⋅N(x∣uk,σk2)
- kkk:高斯分布的个数
- wkw_kwk:每个分布的权重(比例,所有权重相加 = 1)
- uk,σku_k,\sigma_kuk,σk:第k 个高斯分布的均值和方差
- N(x∣uk,σk2)\Nu(x|u_k,\sigma_k^2)N(x∣uk,σk2):第k个高斯分布的概率密度函数 (PDF)
而此时我们计算某一个值属于哪一个高斯分布的过程叫做条件概率(责任度):
P(lk∣x)=lkp(x)=wk⋅N(x∣uk,σk2)p(x)P(l_k|x)=\frac{l_k}{p(x)}=\frac{w_k \cdot \Nu(x|u_k,\sigma_k^2)}{p(x)}P(lk∣x)=p(x)lk=p(x)wk⋅N(x∣uk,σk2)
2)举例说明
上文中是一个以成绩的例子进行计算高斯分布,但显然现实中要考虑的因素会更多:
- 一部分学生是学霸30%30\%30%,集中在85±585 \pm 585±5分附近
- 一部分学生是普通学生70%70\%70%,集中在65±1065\pm 1065±10分附近
那么由此可以得到:
- 学霸群体:均值u1=85u_1 = 85u1=85,标准差σ1=5\sigma_1= 5σ1=5,权重w1=0.3w_1= 0.3w1=0.3
- 普通学生:均值u2=65u_2 = 65u2=65,标准差σ2=10\sigma_2= 10σ2=10,权重w2=0.7w_2= 0.7w2=0.7
此时有一个学生成绩为70,那么他的条件概率分别为:
- P(l1∣x)=l1p(x)≈0.01067(1.07%)P(l_1|x)=\frac{l_1}{p(x)} \approx 0.01067(1.07\%)P(l1∣x)=p(x)l1≈0.01067(1.07%)
- P(l2∣x)=l2p(x)=1−P(l1∣x)≈0.98933(98.93%)P(l_2|x)=\frac{l_2}{p(x)} = 1- P(l_1|x) \approx 0.98933 (98.93\%)P(l2∣x)=p(x)l2=1−P(l1∣x)≈0.98933(98.93%)
很明显,该学生大概率属于普通学生
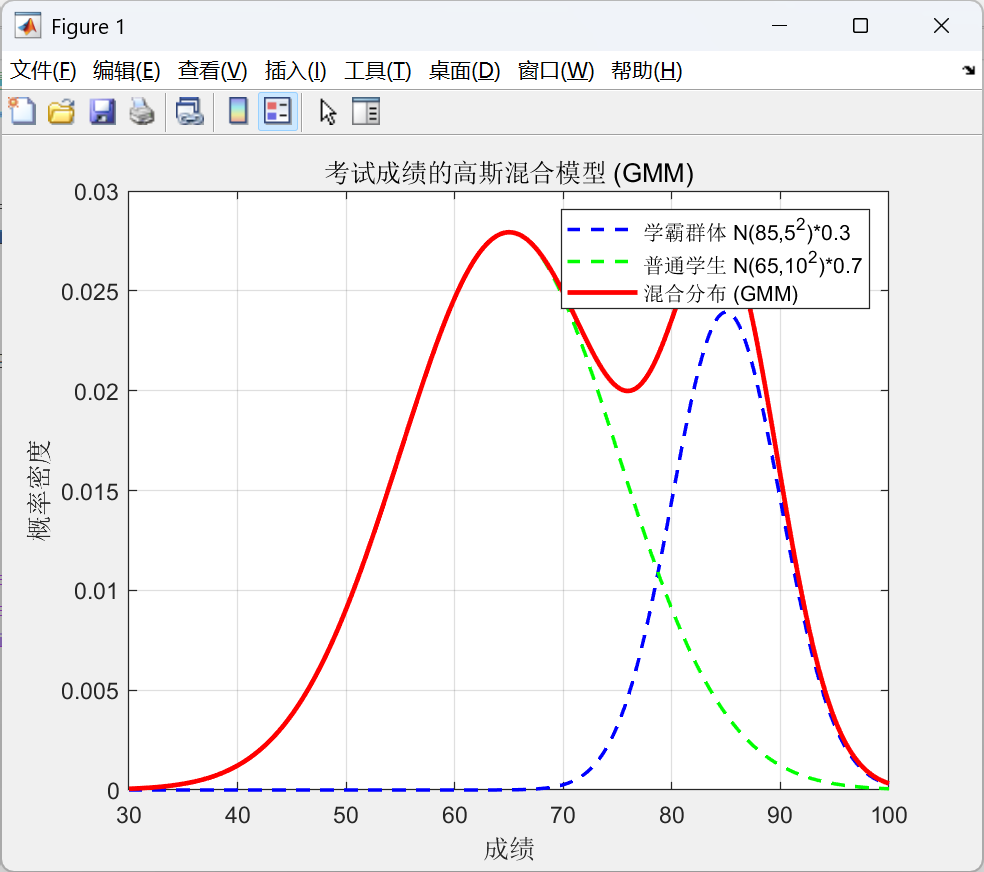
3)一维曲线
使用matlab画出曲线
x = linspace(30, 100, 500);% 学霸群体参数
mu1 = 85; sigma1 = 5; w1 = 0.3;
pdf1 = w1 * normpdf(x, mu1, sigma1);% 普通学生群体参数
mu2 = 65; sigma2 = 10; w2 = 0.7;
pdf2 = w2 * normpdf(x, mu2, sigma2);% 混合分布
pdf_mix = pdf1 + pdf2;% 绘制
figure;
plot(x, pdf1, 'b--', 'LineWidth', 1.5); hold on;
plot(x, pdf2, 'g--', 'LineWidth', 1.5);
plot(x, pdf_mix, 'r-', 'LineWidth', 2);
grid on;
legend('学霸群体 N(85,5^2)*0.3', ...'普通学生 N(65,10^2)*0.7', ...'混合分布 (GMM)');
title('考试成绩的高斯混合模型 (GMM)');
xlabel('成绩');
ylabel('概率密度');
二、VAD高斯混合模型
1.模型训练介绍
1)训练方法
webrtc关于VAD的高斯混合模型训练是一种离线训练,是通过以下几个步骤得到的:
- 准备数据
- 收集了大量的语音数据(各种语言、男女声、不同音量)
- 收集了大量的噪声数据(白噪声、街道、办公室、电话线路噪声等)
- 特征提取
- 对每一帧音频(10ms ~ 30ms)提取简单特征:子带能量、总能量、过零率
- 特征维度很低,不像是MFCC会有多个维度,但适合在嵌入式环境运行
- 拟合高斯分布
- 把“语音帧特征”丢进一个高斯混合模型训练器
- 把“噪声帧特征”丢进另一个 GMM 训练器
- 使用EM算法迭代得到每个分量的均值、方差、权重
- 量化和存储
- 得到的均值、方差、权重定点数存储(int16_t),方便在 C 代码里运行
- 该套参数固定写死在代码表里,运行时虽然会根据实际情况修改,但不会在运行后进行存储
由此我们也可以直觉看出来这套模型的明显的优缺点:
| 特性 | 优点 | 缺点 |
|---|---|---|
| 计算效率 | 高,适合实时 | 无 |
| 模型复杂度 | 低,易实现 | 表达能力有限 |
| 多模态表示 | 可以区分静音/语音 | 只适合简单多模态 |
| 鲁棒性 | 可自适应噪声变化 | 对异常噪声敏感 |
| 时序建模 | 无 | 需要额外平滑 |
2)训练结果
webrtc中训练后的结果是以Q7格式分别存储在:
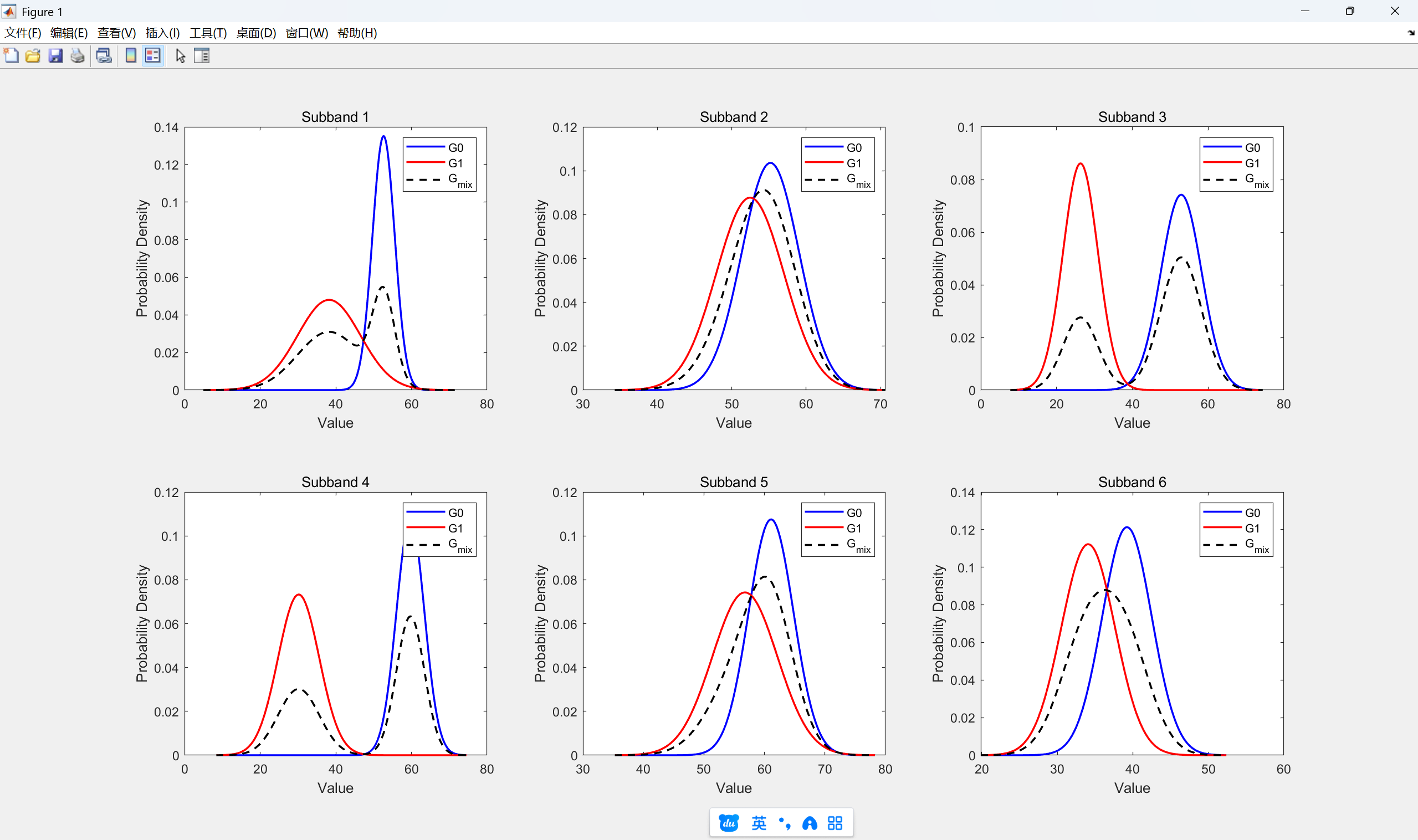
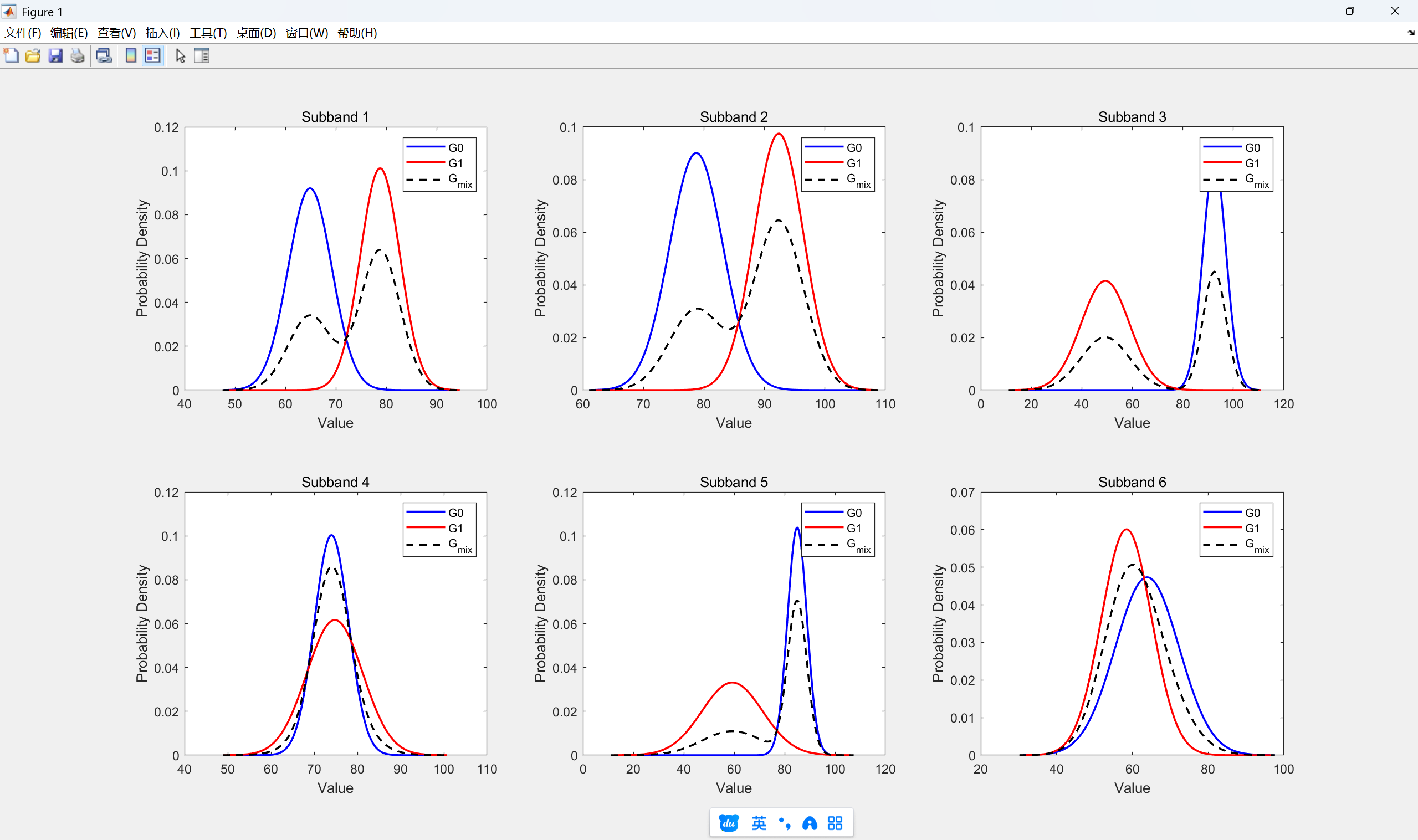
kNoiseDataWeights:噪声的两个高斯分布权重,表格中的G0和G1kNoiseDataMeans:噪声的两个高斯分布均值kNoiseDataStds:噪声的两个高斯分布的方差kSpeechDataWeights:噪声的两个高斯分布权重,表格中的G0和G1kSpeechDataMeans:噪声的两个高斯分布均值kSpeechDataStds:噪声的两个高斯分布的方差- G0:低幅度、常见特征,是频带特征里的主分量
- G1:高幅度、变化性更大的特征,是频带特征里的补充分量
| 频带 | 高斯 | Noise 权重 | Speech 权重 | Noise 均值 | Speech 均值 | Noise Std | Speech Std |
|---|---|---|---|---|---|---|---|
| 0 | G0 | 34 | 48 | 6738 | 8306 | 378 | 555 |
| G1 | 62 | 82 | 4892 | 10085 | 1064 | 505 | |
| 1 | G0 | 72 | 45 | 7065 | 10078 | 493 | 567 |
| G1 | 66 | 87 | 6715 | 11823 | 582 | 524 | |
| 2 | G0 | 53 | 50 | 6771 | 11843 | 688 | 585 |
| G1 | 25 | 47 | 3369 | 6309 | 593 | 1231 | |
| 3 | G0 | 94 | 80 | 7646 | 9473 | 474 | 509 |
| G1 | 66 | 46 | 3863 | 9571 | 697 | 828 | |
| 4 | G0 | 56 | 83 | 7820 | 10879 | 475 | 492 |
| G1 | 62 | 41 | 7266 | 7581 | 688 | 1540 | |
| 5 | G0 | 75 | 78 | 5020 | 8180 | 421 | 1079 |
| G1 | 103 | 81 | 4362 | 7483 | 455 | 850 |
在代码中,将会在WebRtcVad_InitCore接口中存储在VadInstT结构体中。
2.噪声高斯模型分布
下面将根据具体的参数,画出6个子带的两个高斯分布G0,G1图像,然后再根据权重进行G0和G1加权后的高斯混合图像。
1)matlab代码
clc; clear; close all;% 原始 Q7 数据
kNoiseDataMeans_Q7 = [6738, 4892, 7065, 6715, 6771, 3369, 7646, 3863, 7820, 7266, 5020, 4362];
kNoiseDataStds_Q7 = [378, 1064, 493, 582, 688, 593, 474, 697, 475, 688, 421, 455];
kNoiseDataWeights_Q7 = [34, 62, 72, 66, 53, 25, 94, 66, 56, 62, 75, 103];% 转为 Q0(浮点)
kNoiseDataMeans = double(kNoiseDataMeans_Q7) / 128;
kNoiseDataStds = double(kNoiseDataStds_Q7) / 128;
kNoiseDataWeights = double(kNoiseDataWeights_Q7); % 权重本身可以直接使用kTableSize = length(kNoiseDataMeans);
numBands = kTableSize / 2;figure;for band = 1:numBands% 提取 G0, G1 的参数mean0 = kNoiseDataMeans(2*band-1);mean1 = kNoiseDataMeans(2*band);std0 = kNoiseDataStds(2*band-1);std1 = kNoiseDataStds(2*band);weight0 = kNoiseDataWeights(2*band-1);weight1 = kNoiseDataWeights(2*band);% x 范围,取 ±4σx_min = min(mean0-4*std0, mean1-4*std1);x_max = max(mean0+4*std0, mean1+4*std1);x = linspace(x_min, x_max, 500);% 高斯分布G0 = (1/(std0*sqrt(2*pi))) * exp(-0.5*((x-mean0)/std0).^2);G1 = (1/(std1*sqrt(2*pi))) * exp(-0.5*((x-mean1)/std1).^2);% 加权混合Gmix = (weight0*G0 + weight1*G1) / (weight0 + weight1);% 绘图subplot(2,3,band);plot(x, G0, 'b', 'LineWidth',1.5); hold on;plot(x, G1, 'r', 'LineWidth',1.5);plot(x, Gmix, 'k--', 'LineWidth',1.5);title(['Subband ' num2str(band)]);legend('G0','G1','G_{mix}');xlabel('Value'); ylabel('Probability Density');
end
2)结果
2.人声高斯模型分布
和计算噪声高斯模型分布一样,只需要将matlab中代码替换即可,这里就不贴出代码,直接看结果:
三、VAD人声判断
在上一篇文章webrtc之语音活动上——VAD能量检测原理以及源码详解中,我们已经知道了:
- 检测模式的区别
- 帧长划分方法
- 6个非等宽频带的能量
- 频带划分的意义
1.高斯分布计算
1)公式
源码中关于PDF计算使用Q格式运算以保证精度,其计算公式为:
1σ⋅exp(−(x−m)22∗σ2)\frac{1}{\sigma} \cdot \exp\Big(-\frac{(x - m)^2} { 2 * \sigma^2}\Big)σ1⋅exp(−2∗σ2(x−m)2)
该接口的计算方式少了一个2π\sqrt{2\pi}2π,并且这里同样将log\loglog运算简化,因此它是一个相对值(比例),而缩放后的 PDF是用于相对比较,不是严格的概率密度,不会影响后续决策与更新。
2)对应代码
接口名为WebRtcVad_GaussianProbability,以下是参数和返回值:
input:频带能量,以Q4格式保存mean:噪声/人声的高斯均值,Q7格式std:噪声/人声的高斯方差,Q7格式delta:x−ms2\frac{x-m}{s^2}s2x−m,用于后续更新模型,Q11格式- 返回值:概率密度,Q20格式
2.人声判定策略
1)判断机制
VAD判断人声是双重机制:
- 局部判定: 捕捉某个子带特别强烈的语音
- 全局判定:要求整体证据够强
- 最终决策:两者取 OR,既保证灵敏度,又保证鲁棒性
2)重要阈值确认
在设置模式WebRtcVad_set_mode_core接口里,确定
individual:单个频带人声阈值范围,用于局部判定total:整体人声阈值阈值范围,用于整体
而对于不同帧长再进一步确定阈值,这里是在GmmProbability真正进行决策的地方进行确定。而对于:
- 短帧10ms:由于信息少,则使用高阈值以避免误判
- 中等20ms:阈值低,放宽一些
- 长帧30ms:本身信息稳定,为了避免太宽松 又设高
除此之外,在进行全局判定时,不同频带的权重存储在kSpectrumWeight中。
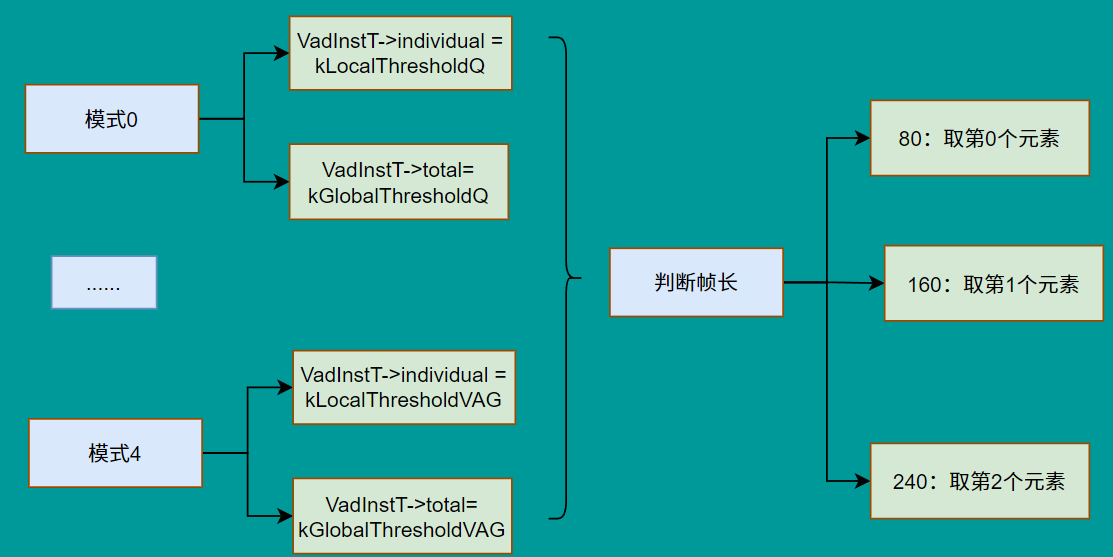
值得注意的是,这些阈值的由来是根据大规模实验 + ROC 曲线分析 + 主观听感测试 手工调出来的经验值。
3)整体流程
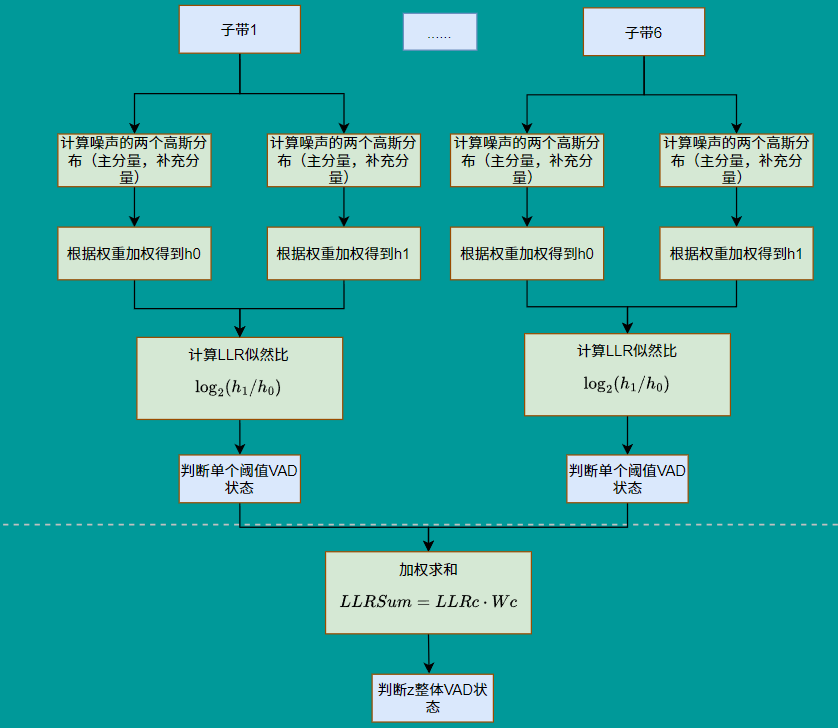
第一步:计算噪声/人声概率分布
同一段频带语音根据噪声/人声的高斯参数,分别进行计算主分量/补充分量的概率分布,再根据权值计算真正的概率密度,代码如下:
for (channel = 0; channel < kNumChannels; channel++) {h0_test = 0;h1_test = 0;for (k = 0; k < kNumGaussians; k++) {gaussian = channel + k * kNumChannels;tmp1_s32 = WebRtcVad_GaussianProbability(features[channel],self->noise_means[gaussian],self->noise_stds[gaussian],&deltaN[gaussian]);noise_probability[k] = kNoiseDataWeights[gaussian] * tmp1_s32;h0_test += noise_probability[k]; // Q27tmp1_s32 = WebRtcVad_GaussianProbability(features[channel],self->speech_means[gaussian],self->speech_stds[gaussian],&deltaS[gaussian]);speech_probability[k] = kSpeechDataWeights[gaussian] * tmp1_s32;h1_test += speech_probability[k]; // Q27}
第二步:噪声/人声比较
判断单个频带是否为人声使用的是似然对数比,也就是log2(Pr(X∣H1)Pr(X∣H0))\log2(\frac{Pr(X|H1)}{Pr(X|H0)})log2(Pr(X∣H0)Pr(X∣H1)),这么做的好处是:
- 避免概率数值太小引起数值问题
- LLR 的加和性质,可以进行多个频带综合判定
值得注意的是:这近似在数帧平均下通常偏差较小,但对极端 / 较小样本会产生偏差,所以后面通过局部+全局、hangover机制与模型更新来抵消误判。
这里的移位操作是为了简化log\loglog运算,用最高位表示为整数部分,用整数位的差值来近似log2(h1/h0)\log2(h1/h0)log2(h1/h0),核心代码为:
shifts_h0 = WebRtcSpl_NormW32(h0_test);shifts_h1 = WebRtcSpl_NormW32(h1_test);if (h0_test == 0) {shifts_h0 = 31;}if (h1_test == 0) {shifts_h1 = 31;}log_likelihood_ratio = shifts_h0 - shifts_h1;
第三步:判断单个阈值
如果单个频带的信号人声强烈,将会直接认定为语音,值得注意的是即使判断为人声了,还是会接着计算其他频带,这是为了更新模型。核心代码为:
if ((log_likelihood_ratio * 4) > individualTest) {vadflag = 1;}
第四步:全局判定
这里分为两部分
- 根据权重加合
- 整体阈值判断
其核心代码如下:
sum_log_likelihood_ratios +=(int32_t) (log_likelihood_ratio * kSpectrumWeight[channel]);.......vadflag |= (sum_log_likelihood_ratios >= totalTest);
四、模型更新
在进行模型更新时,需要考虑到平滑处理,所以这里运用到大量的平滑滤波的思想,见文章语音信号处理三十一——常用的时域/频域平滑滤波。
1.计算条件概率
首先获取各个频带噪声/人声在主分量和补充分量的条件概率,分别存储在ngprvec和sgprvec中。
如果h<0h<0h<0,那么默认该数值必然是主分量特征,以下是噪声的条件概率核心代码,人声类似:
h0 = (int16_t) (h0_test >> 12); // Q15if (h0 > 0) {tmp1_s32 = (noise_probability[0] & 0xFFFFF000) << 2; // Q29ngprvec[channel] = (int16_t) WebRtcSpl_DivW32W16(tmp1_s32, h0); // Q14ngprvec[channel + kNumChannels] = 16384 - ngprvec[channel];} else {ngprvec[channel] = 16384;}
2.获取噪声基线和均值
1)噪声基线的作用
WebRTC VAD 和很多能量型 VAD 都是基于一个基本假设:在连续音频信号中,语音的能量通常高于环境噪声的能量。
而噪声基的含义是指:环境噪声在短时间或一段时间内的平均能量水平或特征值参考。
2)确定噪声基线
噪声基线的获取是一种中值滤波的思想。在接口WebRtcVad_FindMinimum中,它的大致流程为:
输入: feature_value, channel, self┌─► [1] 更新历史值的年龄
│ ├─ 遍历16个存储的最小值
│ ├─ age < 100 → age++
│ └─ age == 100 → 移除该值,数组前移,最后位置填充大数
│
└─► [2] 判断是否插入新值├─ feature_value 比数组中的某些值小│ └─ 找到插入位置 position│ └─ 从尾部往后移,插入新值,age=1└─ 否则丢弃(说明它不是最小16个之一)┌─► [3] 计算当前中位数
│ ├─ frame_counter > 2 → 取 smallest_values[2] (第3小)
│ └─ frame_counter <= 2 → 取 smallest_values[0] (最小值)
│
└─► [4] 平滑更新 mean_value[channel]├─ 如果 current_median < mean_value → α = 0.2 (快速下降)└─ 否则 α = 0.99 (缓慢上升)└─ mean_value[channel] ← α * mean_value[channel] + (1-α) * current_median[5] 返回 mean_value[channel]这里可以对照代码进行理解。
3)获取噪声均值
实现主要在WeightedAverage接口内,该接口的使用方法为:
- 输入主分量和补充分量的均值
- 输入对应的权重
- 输出计算后的均值
3.更新噪声均值
1)短时更新
WebRTC 里不可能每次都存很多帧再做完整的EM,并且GMM更新中webrtc希望带权,所以这里采用的是梯度递推进行更新,公式为:
μnoisenow=μnoiseold+η⋅γnow(x−μnoiseold)\mu_{noise}^{now} = \mu_{noise}^{old}+\eta\cdot \gamma_{now}(x-\mu_{noise}^{old})μnoisenow=μnoiseold+η⋅γnow(x−μnoiseold)
- η\etaη:权系数
- γnow\gamma_{now}γnow:当前频带当前分量的条件概率
由于篇幅原因,这里不做推导了,可以看看别的文章,或者可以私信博主
这里加权是并不希望噪声平均变化过快。对应代码为:
static const int16_t kNoiseUpdateConst = 655; // Q15
nmk2 = nmk;
if (!vadflag) {delt = (int16_t)((ngprvec[gaussian] * deltaN[gaussian]) >> 11);nmk2 = nmk + (int16_t)((delt * kNoiseUpdateConst) >> 22);
}
2)平滑修正
首先会用噪声基线减去频带噪声均值得到差值,再根据差值进行指数加权移动平均的思想,和当前帧的噪声均值相加为下一帧的噪声均值,对应代码:
ndelt = (feature_minimum << 4) - tmp1_s16;
nmk3 = nmk2 + (int16_t)((ndelt * kBackEta) >> 9);
值得注意的是:平滑修正不受vadflag影响
3)边界约束
即强制噪声均值不能小于某个最小值,和防止噪声均值过大,避免它被语音能量无限拉升。代码如下:
tmp_s16 = (int16_t) ((k + 5) << 7);if (nmk3 < tmp_s16) {nmk3 = tmp_s16;}tmp_s16 = (int16_t) ((72 + k - channel) << 7);if (nmk3 > tmp_s16) {nmk3 = tmp_s16;}
4)策略意义
对于nmk2会受到γ\gammaγ的影响,而γ\gammaγ并不是固定常数,而是随着当前帧的条件概率变动,一旦语音能量进入,更新方向就会发生错误。此时平滑修正的意义就体现出来:
- 短时更新可能受到语音污染,可能偏离真实噪声基线
- 如果当前帧判定为非噪声,那么均值会被
kBackEta慢慢收敛回长期基线
4.更新人声均值
和更新噪声均值一样的梯度更新计算方法,只是区别是:
- 不需要进行长期拉回,因为人声是特征动态明显,不需要噪声基线作为参考
- 噪声的限幅控制是为了保证模型稳定,避免漂移到语音区,而人声限幅是跟随语音分布变化,防止过度漂移,所以限幅范围不同
- 人声均值向上取整而不是向下取整
smk2 = smk + ((tmp_s16 + 1) >> 1);
5.更新人声方差
1)更新公式
和上文一样,这里采用的是递推更新:
σnew=σold+η⋅wkσold((x−μold2)σold2−1)\sigma_{new}=\sigma_{old}+\eta\cdot \frac{w_k}{\sigma_{old}}\Big(\frac{(x-\mu_{old}^2)}{\sigma^2_{old}} -1\Big)σnew=σold+η⋅σoldwk(σold2(x−μold2)−1)
2)代码解析
tmp_s16 = ((smk + 4) >> 3);tmp_s16 = features[channel] - tmp_s16; tmp1_s32 = (deltaS[gaussian] * tmp_s16) >> 3;tmp2_s32 = tmp1_s32 - 4096;tmp_s16 = sgprvec[gaussian] >> 2;tmp1_s32 = tmp_s16 * tmp2_s32;tmp2_s32 = tmp1_s32 >> 4; if (tmp2_s32 > 0) {tmp_s16 = (int16_t) WebRtcSpl_DivW32W16(tmp2_s32, ssk * 10);} else {tmp_s16 = (int16_t) WebRtcSpl_DivW32W16(-tmp2_s32, ssk * 10);tmp_s16 = -tmp_s16;}tmp_s16 += 128; // Rounding.ssk += (tmp_s16 >> 8);
其中:
- wkw_kwk:来自于
sgprvec - η\etaη:为0.025,代码中体现在
WebRtcSpl_DivW32W16产生了0.1的分母,sgprvec[gaussian] >> 2产生了4的分母 tmp_s16 = ((smk + 4) >> 3):这里的加4原因是为了保证右移3位是向上取整保存精度
3)边界约束
方差值不能小于384
static const int16_t kMinStd = 384;
if (ssk < kMinStd) {ssk = kMinStd;}
6.更新噪声方差
和更新人声方差一样,区别在于更新步长的大小是根据偏移量决定的,不过范围大致在0.015~0.02 之间。
7.模型分离
为了防止speech GMM 模型和 noise GMM 模型的均值太接近而粘在一起,需要最终结合两者进行决策。
1)计算全局均值
noise_global_mean = WeightedAverage(&self->noise_means[channel], 0, &kNoiseDataWeights[channel]);
speech_global_mean = WeightedAverage(&self->speech_means[channel], 0, &kSpeechDataWeights[channel]);
- 对每个 channel,把各个高斯分量的均值做加权平均。
- 得到一个 全局 noise 平均值 和一个 全局 speech 平均值。
2)计算差值
diff = (int16_t)(speech_global_mean >> 9) - (int16_t)(noise_global_mean >> 9);
- speech 全局均值 − noise 全局均值。
- 如果差值太小,说明两个模型过于接近
3)如果模型太近,强行拉开
if (diff < kMinimumDifference[channel]) {tmp_s16 = kMinimumDifference[channel] - diff;// tmp1_s16 ≈ 0.8 * (缺口)// tmp2_s16 ≈ 0.2 * (缺口)// 把 speech 模型整体往上推一点speech_global_mean = WeightedAverage(&self->speech_means[channel],tmp1_s16, &kSpeechDataWeights[channel]);// 把 noise 模型整体往下拉一点noise_global_mean = WeightedAverage(&self->noise_means[channel],-tmp2_s16, &kNoiseDataWeights[channel]);
}
- 如果 gap 太小,就把 speech 往上推 80%,noise 往下拉 20%,强制保持至少
kMinimumDifference的区分度。 - 这样避免两个模型均值重叠,保持判决的鲁棒性。
4)限制模型漂移范围
if (speech_global_mean >> 7 > kMaximumSpeech[channel]) {// speech 上限...
}
if (noise_global_mean >> 7 > kMaximumNoise[channel]) {// noise 上限...
}
作用是给 speech 和 noise 均值设上界,避免模型被极端值推得太远。
五、hangover 机制
1.策略作用
WebRTC VAD 的hangover 机制,用来在语音刚结束时 延长一小段时间继续判为语音,避免抖动。
2.整体流程
检测到语音 → num_of_speech++├─ 如果 num_of_speech <= kMaxSpeechFrames → over_hang = overhead1└─ 如果 num_of_speech > kMaxSpeechFrames → over_hang = overhead2检测到非语音├─ 如果 over_hang > 0 → 继续输出语音, over_hang--└─ 如果 over_hang = 0 → 输出静音
其中:
- overhead1:给短语音的尾巴加一点点余量。
- overhead2:给长语音的尾巴加更长的余量。
- num_of_speech:用来区分当前语音段的“长/短”。
- over_hang:用来平滑语音和静音的切换,防止“断断续续”
3.对应代码
1)非语音处理
if (!vadflag) {if (self->over_hang > 0) {vadflag = 2 + self->over_hang;self->over_hang--;}self->num_of_speech = 0;
}
-
但 hangover 计数器
over_hang > 0:说明前面刚有语音 → 进入“延长语音”阶段- 把 vadflag 设置为
2 + self->over_hang(这里 2 是特殊标记,表明这不是直接检测出的语音,而是 hangover 延长出来的语音) over_hang--:计数器递减
- 把 vadflag 设置为
-
否则就彻底当作 silence
-
num_of_speech = 0:清零语音帧计数器
2)语音
else {self->num_of_speech++;if (self->num_of_speech > kMaxSpeechFrames) {self->num_of_speech = kMaxSpeechFrames;self->over_hang = overhead2;} else {self->over_hang = overhead1;}
}
num_of_speech++:累计连续语音帧数- 如果超过
kMaxSpeechFrames(最大语音帧数限制):- 把
num_of_speech固定到上限 over_hang = overhead2(长的 hangover 时间)
- 把
- 否则:
over_hang = overhead1(短的 hangover 时间)
总结
WebRTC VAD 展示了一个典型的“经典信号处理 + 工程优化”方案:
- 在特征层面,采用子带能量的对数刻画,使得语音与噪声分布更接近高斯;
- 在模型层面,使用固定参数的双高斯混合模型,结合局部和全局判决,提高鲁棒性;
- 在实现层面,大量利用 Q 格式、移位近似、预计算表,保证了低算力环境下的实时性;
- 在动态性上,通过逐帧更新和边界约束,使模型能逐渐适应环境变化。
当然,这种基于 GMM 的方法也有局限:在强噪声、非平稳噪声环境下可能误判,且阈值调优高度依赖经验。随着算力提升,DNN/RNN 基的 VAD 在鲁棒性上表现更优,但代价是更高的复杂度与延迟。
反正收藏也不会看,不如点个赞吧!