JavaWeb--day6--MySQL(补漏)

(以下内容全部来自上述课程及课件)


本人安装、单表查询、多表查询、子查询均已实践过,可见尚硅谷-MySQL

图形化工具
1. 介绍
在命令行当中来敲这些SQL语句很不方便,主要的原因有以下 3 点:
- 没有任何代码提示。(全靠记忆,容易敲错字母造成执行报错)
- 操作繁琐,影响开发效率。(所有的功能操作都是通过SQL语句来完成的)
- 编写过的SQL代码无法保存。
在项目开发当中,通常为了提高开发效率,都会借助于现成的图形化管理工具来操作数据库。
目前MySQL主流的图形化界面工具有以下几种:

DataGrip是JetBrains旗下的一款数据库管理工具,是管理和开发MySQL、Oracle、PostgreSQL的理想解决方案。
官网: https://www.jetbrains.com/zh-cn/datagrip/
2. 安装
DataGrip这款工具可以不用安装,因为Jetbrains公司已经将DataGrip这款工具的功能已经集成到了 IDEA当中,所以我们就可以使用IDEA来作为一款图形化界面工具来操作Mysql数据库。
3. 使用
- 打开IDEA自带的Database
- 配置MySQL
- 输入相关信息
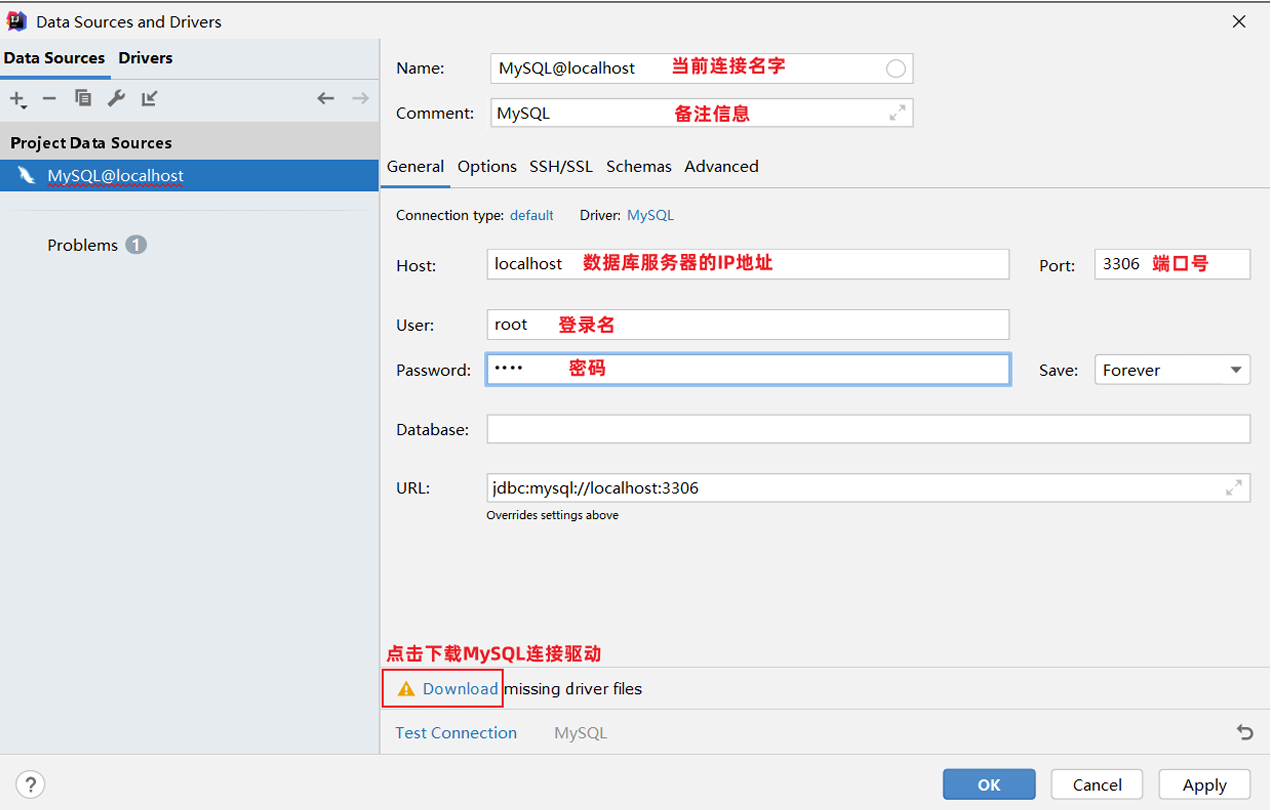
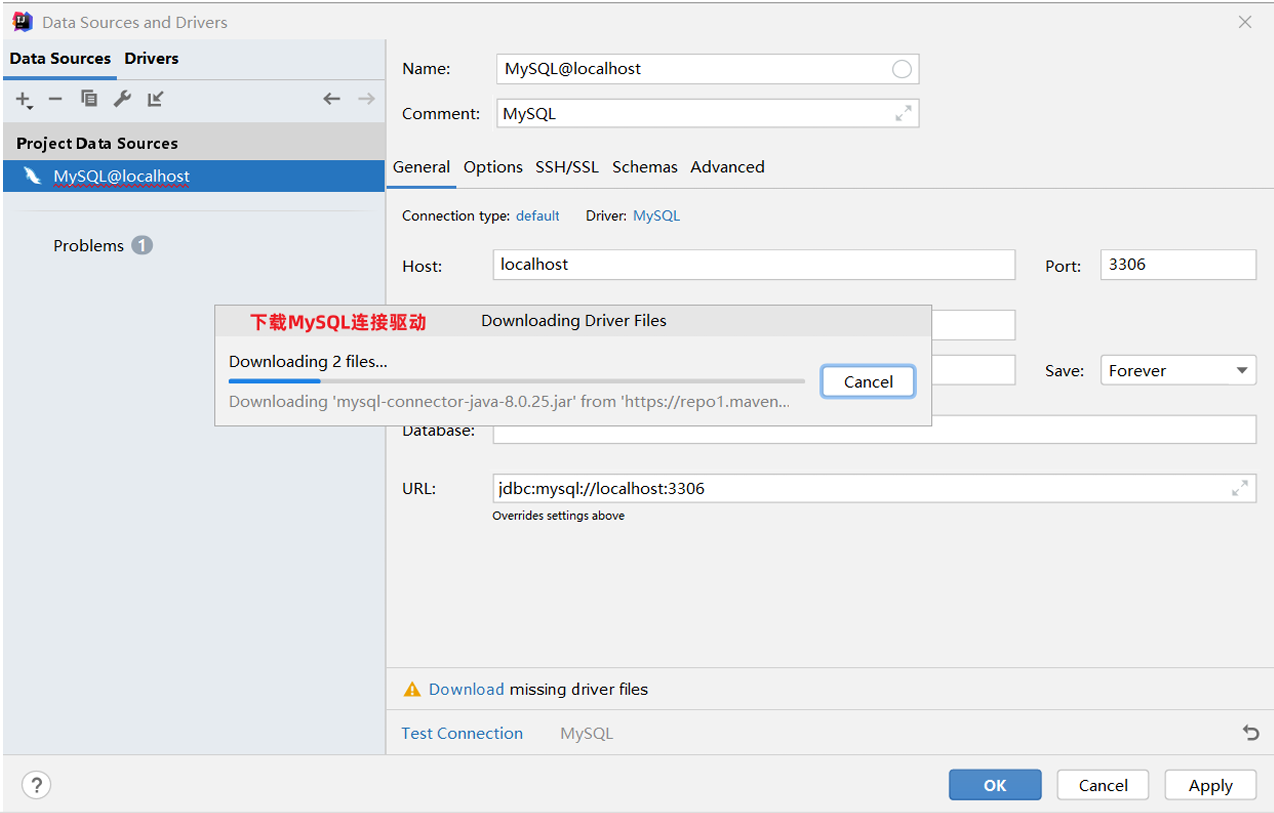
- 下载MySQL连接驱动
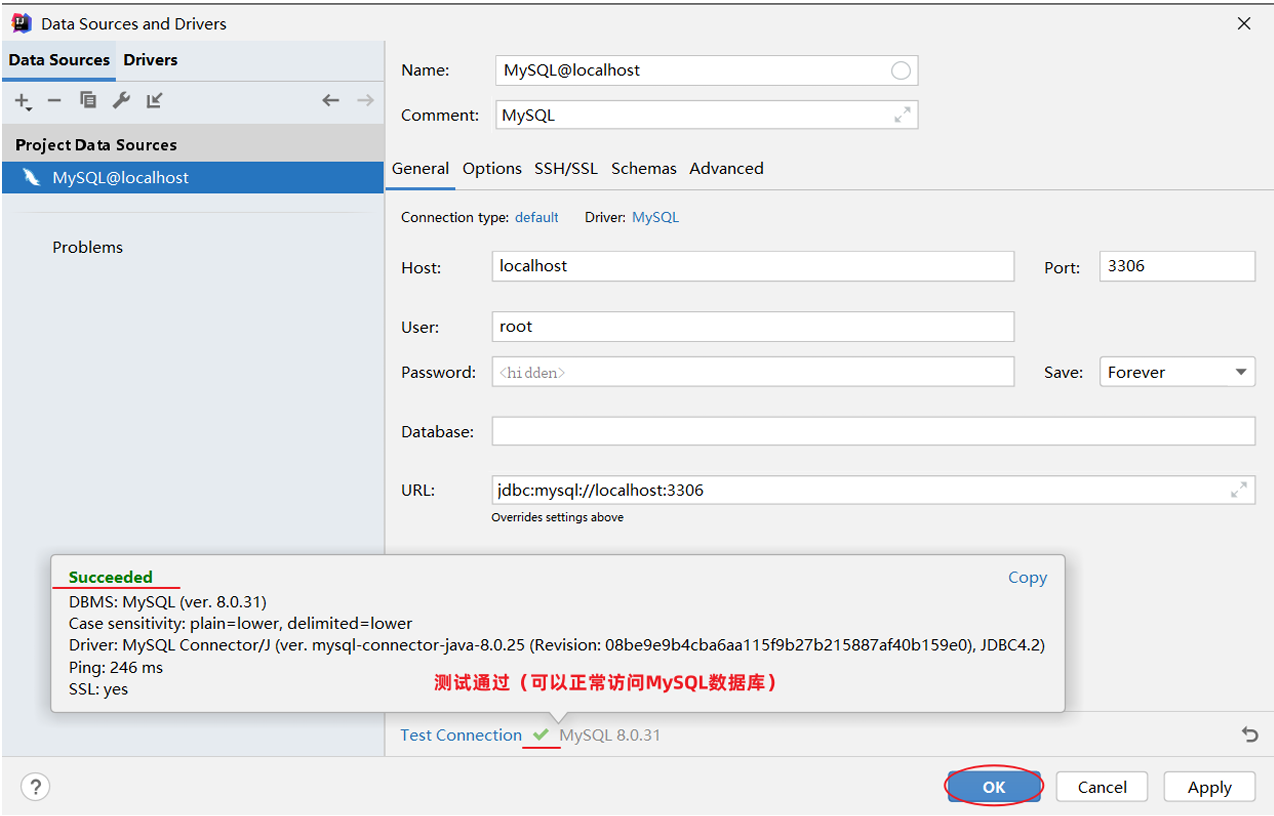
- 测试数据库连接
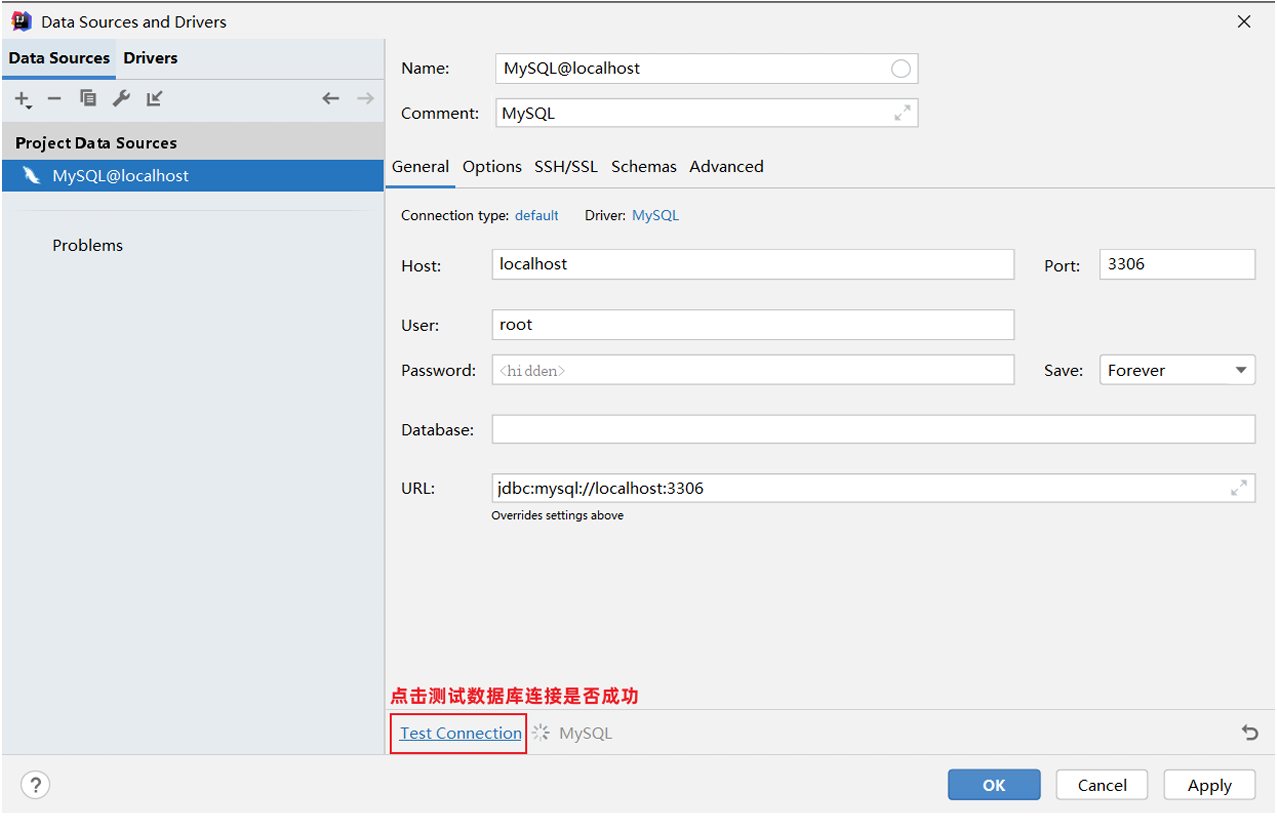
- 保存配置
4. 操作
创建数据库:
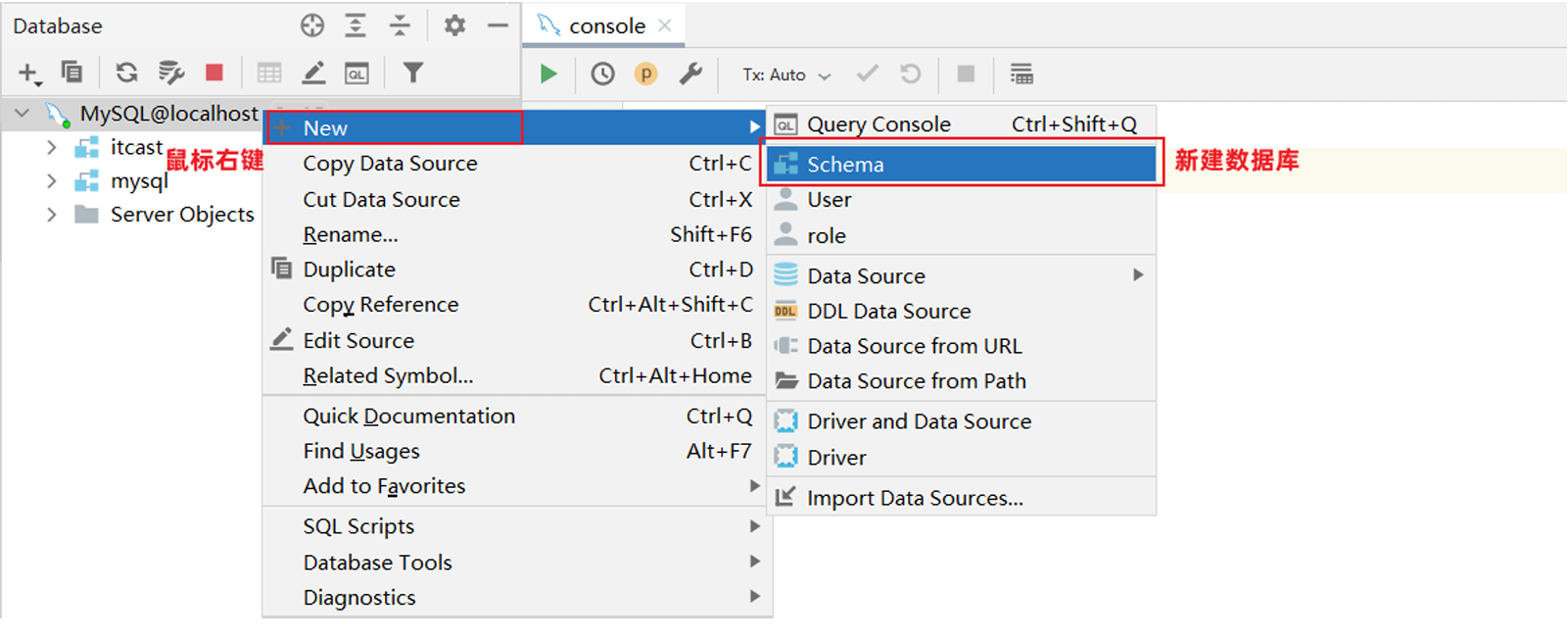
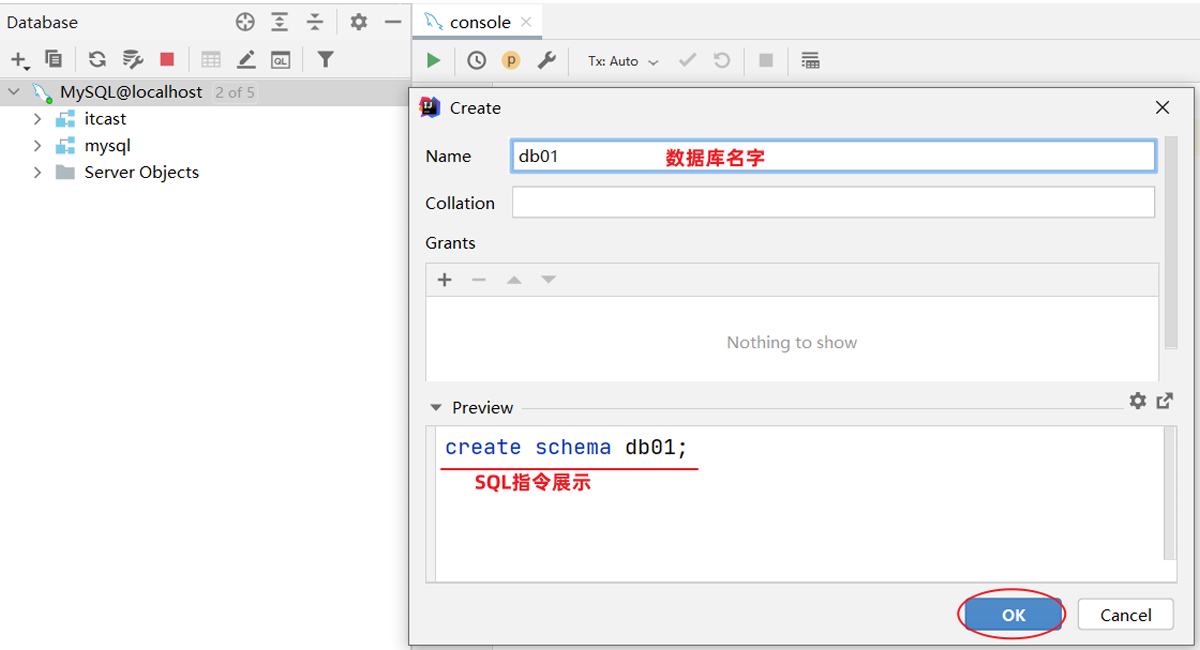
有了图形化界面工具后,就可以方便的使用图形化工具:创建数据库,创建表、修改表等DDL操作。
其实工具底层也是通过DDL语句操作的数据库,只不过这些SQL语句是图形化界面工具帮我们自动完成的。
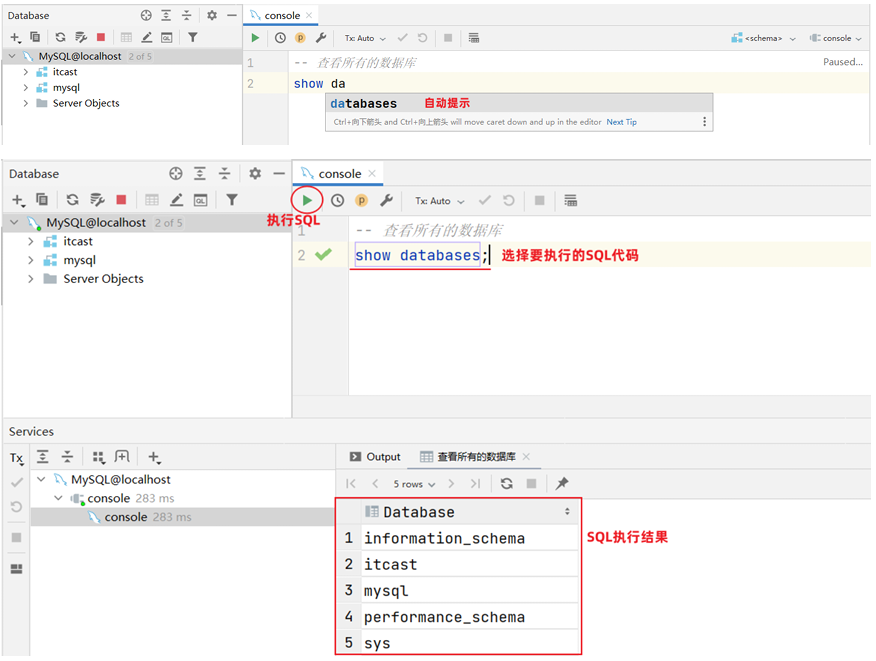
查看所有数据库:
多表设计
项目开发中,在进行数据库表结构设计时,会根据业务需求及业务模块之间的关系,分析并设计表结构,由于业务之间相互关联,所以各个表结构之间也存在着各种联系,基本上分为三种:
- 一对多(多对一)
- 多对多
- 一对一
1. 一对多
1.1 表设计
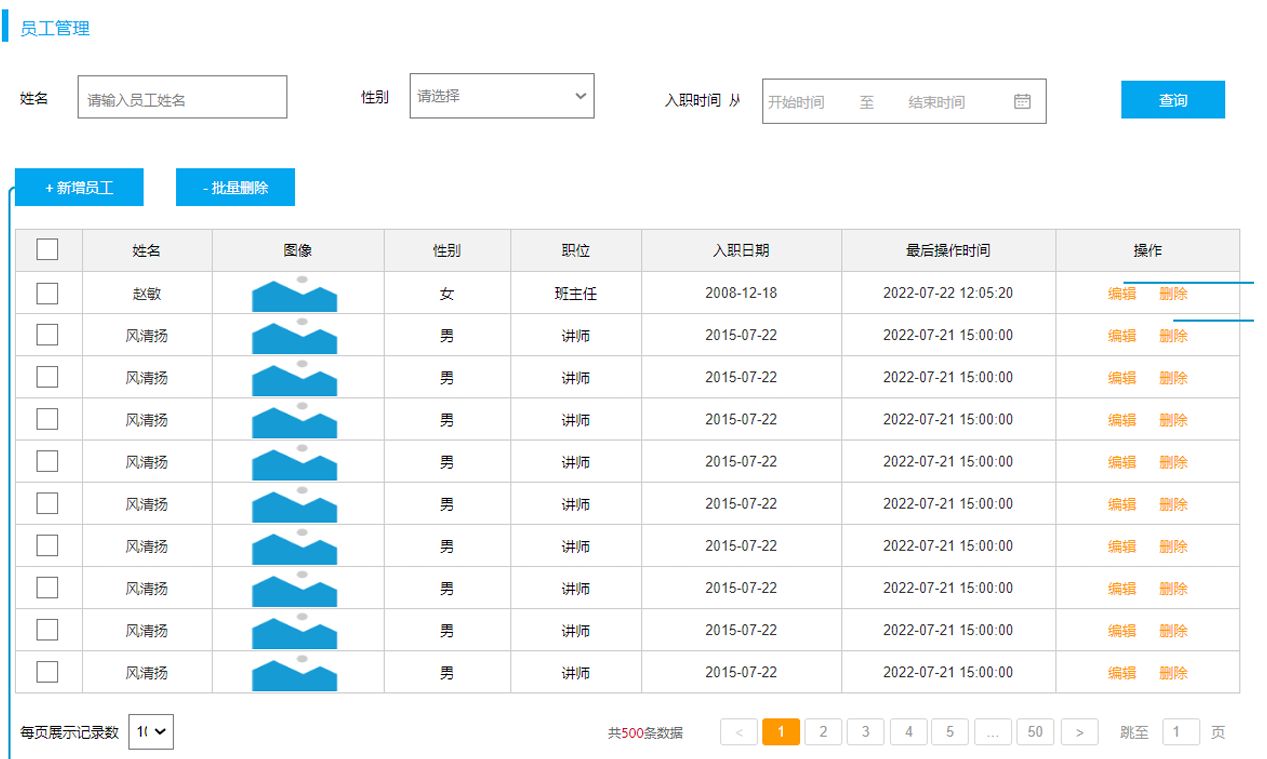
需求:根据页面原型及需求文档 ,完成部门及员工的表结构设计
- 员工管理页面原型:(前面已完成tb_emp表结构设计)
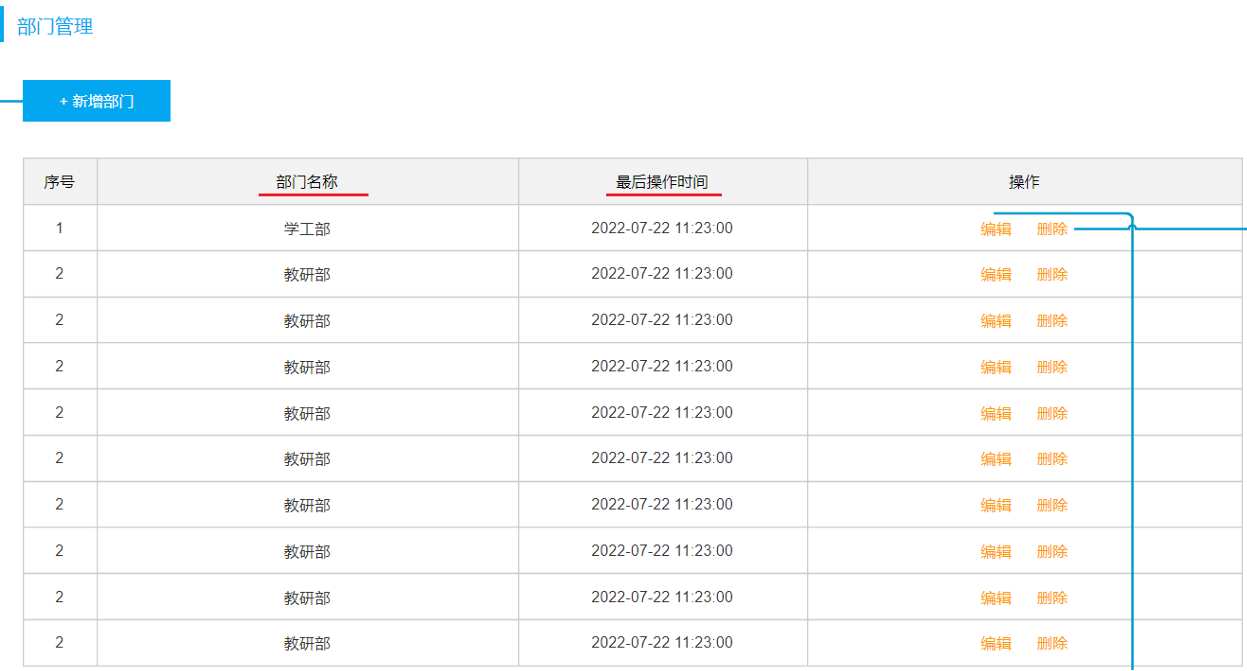
- 部门管理页面原型:
- 员工表 - 部门表之间的关系:
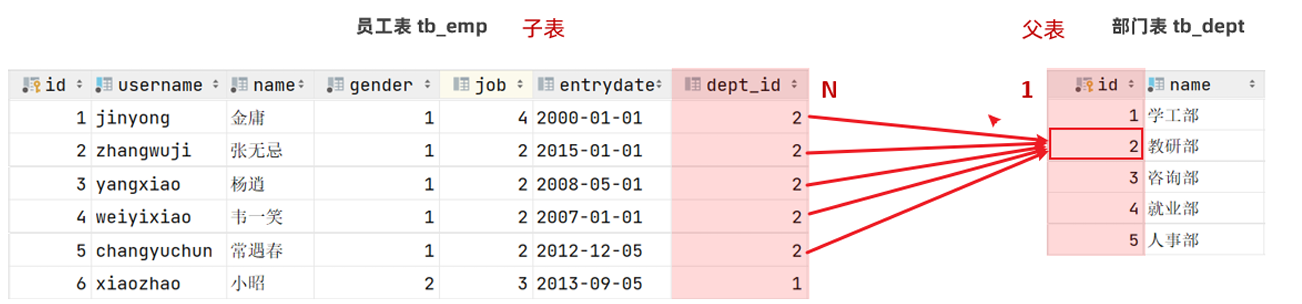
一对多关系实现:在数据库表中多的一方,添加字段,来关联属于一这方的主键。
1.2 外键约束
问题
-
表结构创建完毕后,我们看到两张表的数据分别为:
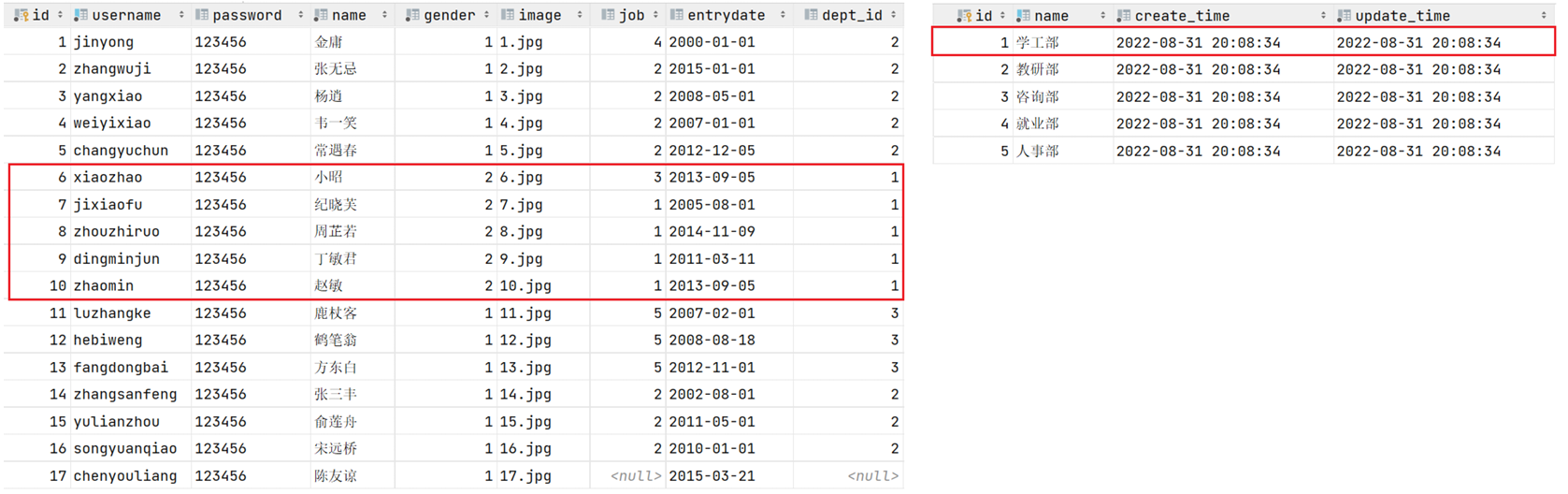
现在员工表中有五个员工都归属于1号部门(学工部),当删除了1号部门后,数据变为:
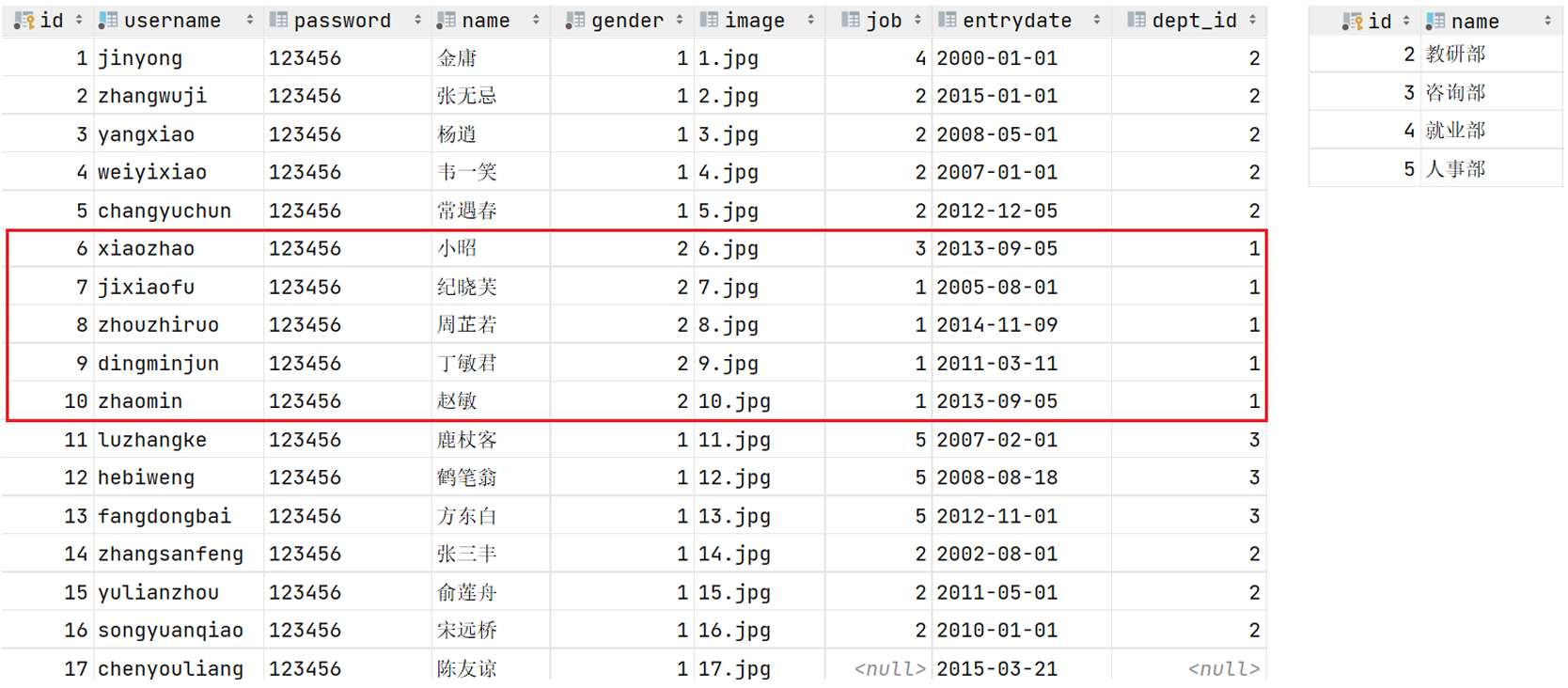
1号部门被删除了,但是依然还有5个员工是属于1号部门的。 此时:就出现数据的不完整、不一致了。 -
问题分析
目前上述的两张表(员工表、部门表),在数据库层面,并未建立关联,所以是无法保证数据的一致性和完整性的 -
问题解决
想解决上述的问题呢,我们就可以通过数据库中的 外键约束 来解决。
外键约束:让两张表的数据建立连接,保证数据的一致性和完整性。
对应的关键字:foreign key
外键约束的语法:
-- 创建表时指定
create table 表名(字段名 数据类型,...[constraint] [外键名称] foreign key (外键字段名) references 主表 (主表列名)
);-- 建完表后,添加外键
alter table 表名 add constraint 外键名称 foreign key(外键字段名)
references 主表(主表列名);
方式1:通过SQL语句操作
-- 修改表: 添加外键约束alter table tb_emp add constraint fk_dept_id foreign key (dept_id) referencestb_dept(id);
方式2:图形化界面操作
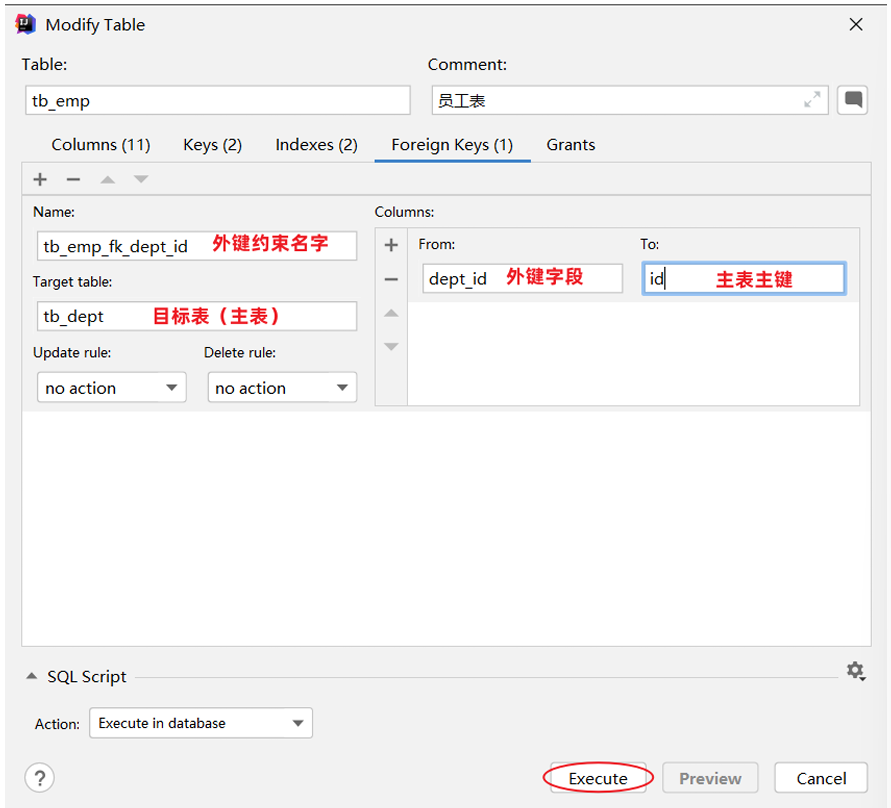
物理外键和逻辑外键
物理外键
- 概念:使用foreign key定义外键关联另外一张表。
- 缺点:
影响增、删、改的效率(需要检查外键关系)。
仅用于单节点数据库,不适用与分布式、集群场景。
容易引发数据库的死锁问题,消耗性能。
逻辑外键
- 概念:在业务层逻辑中,解决外键关联。
- 通过逻辑外键,就可以很方便的解决上述问题。
在现在的企业开发中,很少会使用物理外键,都是使用逻辑外键。 甚至在一些数据库开发规范中,会明确指出禁止使用物理外键 foreign key
2. 一对一

一对一关系表在实际开发中应用起来比较简单,通常是用来做单表的拆分,也就是将一张大表拆分成两张小表,将大表中的一些基础字段放在一张表当中,将其他的字段放在另外一张表当中,以此来提高数据的操作效率。
一对一的应用场景: 用户表(基本信息+身份信息)
- 基本信息:用户的ID、姓名、性别、手机号、学历
-身份信息:民族、生日、身份证号、身份证签发机关,身份证的有效期(开始时间、结束时间)
如果在业务系统当中,对用户的基本信息查询频率特别的高,但是对于用户的身份信息查询频率很低,此时出于提高查询效率的考虑,我就可以将这张大表拆分成两张小表,第一张表存放的是用户的基本信息,而第二张表存放的就是用户的身份信息。他们两者之间一对一的关系,一个用户只能对应一个身份证,而一个身份证也只能关联一个用户。


一对一 :在任意一方加入外键,关联另外一方的主键,并且设置外键为唯一的(UNIQUE)
3. 多对多

多对多的关系在开发中属于也比较常见的。比如:学生和老师的关系,一个学生可以有多个授课老师,一个授课老师也可以有多个学生。在比如:学生和课程的关系,一个学生可以选修多门课程,一个课程也可以供多个学生选修。
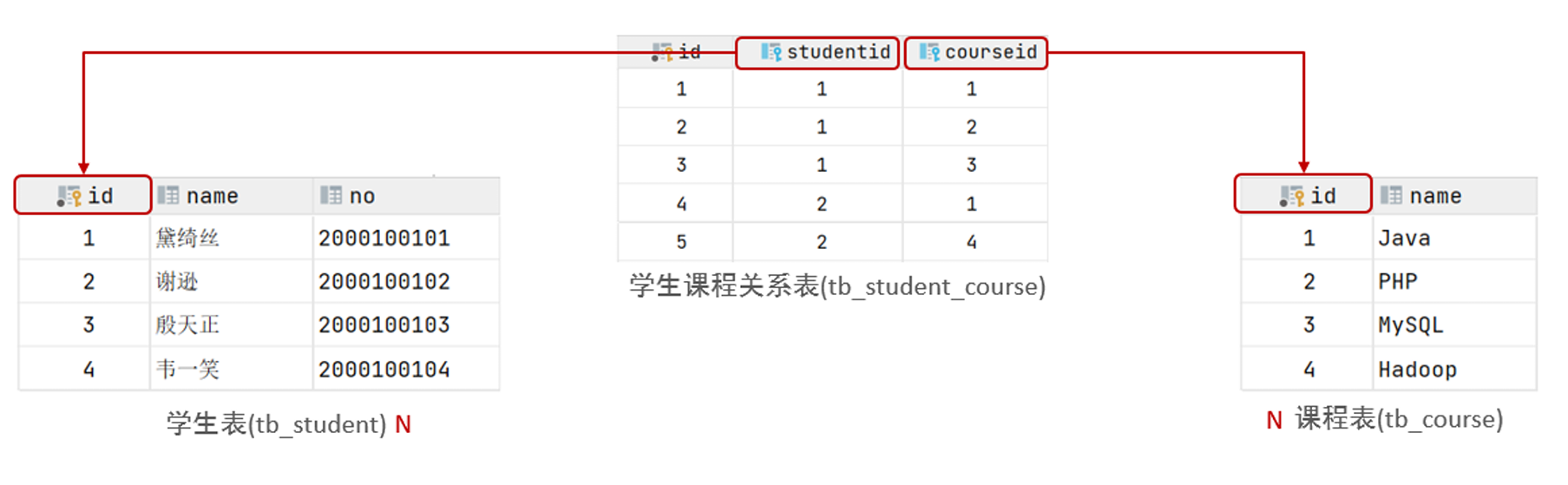
案例:学生与课程的关系
- 关系:一个学生可以选修多门课程,一门课程也可以供多个学生选择
- 实现关系:建立第三张中间表,中间表至少包含两个外键,分别关联两方主键
事务

1. 介绍
在实际的业务开发中,有些业务操作要多次访问数据库。一个业务要发送多条SQL语句给数据库执行。
需要将多次访问数据库的操作视为一个整体来执行,要么所有的SQL语句全部执行成功。如果其中有一条SQL语句失败,就进行事务的回滚,所有的SQL语句全部执行失败。
简而言之:事务是一组操作的集合,它是一个不可分割的工作单位。事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。
事务作用:保证在一个事务中多次操作数据库表中数据时,要么全都成功,要么全都失败。
2. 操作
MYSQL中有两种方式进行事务的操作:
- 自动提交事务:即执行一条sql语句提交一次事务。(默认MySQL的事务是自动提交)
- 手动提交事务:先开启,再提交
事务操作有关的SQL语句:
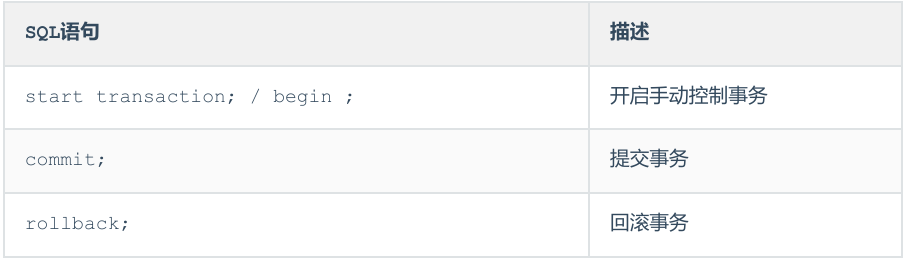
手动提交事务使用步骤:
- 第1种情况:开启事务 => 执行SQL语句 => 成功 => 提交事务
- 第2种情况:开启事务 => 执行SQL语句 => 失败 => 回滚事务
3. 四大特性(ACID)
-
原子性(Atomicity):事务是不可分割的最小单元,要么全部成功,要么全部失败。
-
一致性(Consistency):事务完成时,必须使所有的数据都保持一致状态。
-
隔离性(Isolation):数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行。
-
持久性(Durability):事务一旦提交或回滚,它对数据库中的数据的改变就是永久的。
-
原子性(Atomicity) :原子性是指事务包装的一组sql是一个不可分割的工作单元,事务中的操作要么全部成功,要么全部失败。
-
一致性(Consistency):一个事务完成之后数据都必须处于一致性状态。
如果事务成功的完成,那么数据库的所有变化将生效。
如果事务执行出现错误,那么数据库的所有变化将会被回滚(撤销),返回到原始状态。 -
隔离性(Isolation):多个用户并发的访问数据库时,一个用户的事务不能被其他用户的事务干扰,多个并发的事务之间要相互隔离。
一个事务的成功或者失败对于其他的事务是没有影响。 -
持久性(Durability):一个事务一旦被提交或回滚,它对数据库的改变将是永久性的,哪怕数
据库发生异常,重启之后数据亦然存在。
索引
1. 介绍
索引(index):是帮助数据库高效获取数据的数据结构 。
- 简单来讲,就是使用索引可以提高查询的效率。
测试没有使用索引的查询:

添加索引后查询:
-- 添加索引
create index idx_sku_sn on tb_sku (sn); #在添加索引时,也需要消耗时间-- 查询数据(使用了索引)-- 查询数据(使用了索引)
select * from tb_sku where sn = '100000003145008';
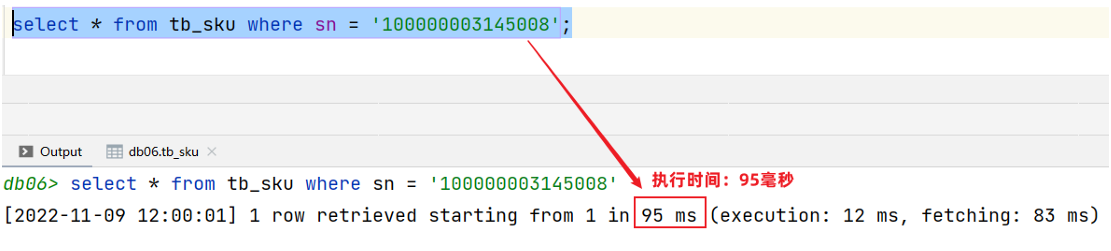
优点:
- 提高数据查询的效率,降低数据库的IO成本。
- 通过索引列对数据进行排序,降低数据排序的成本,降低CPU消耗。
缺点:
- 索引会占用存储空间。
- 索引大大提高了查询效率,同时却也降低了insert、update、delete的效率。
2. 结构
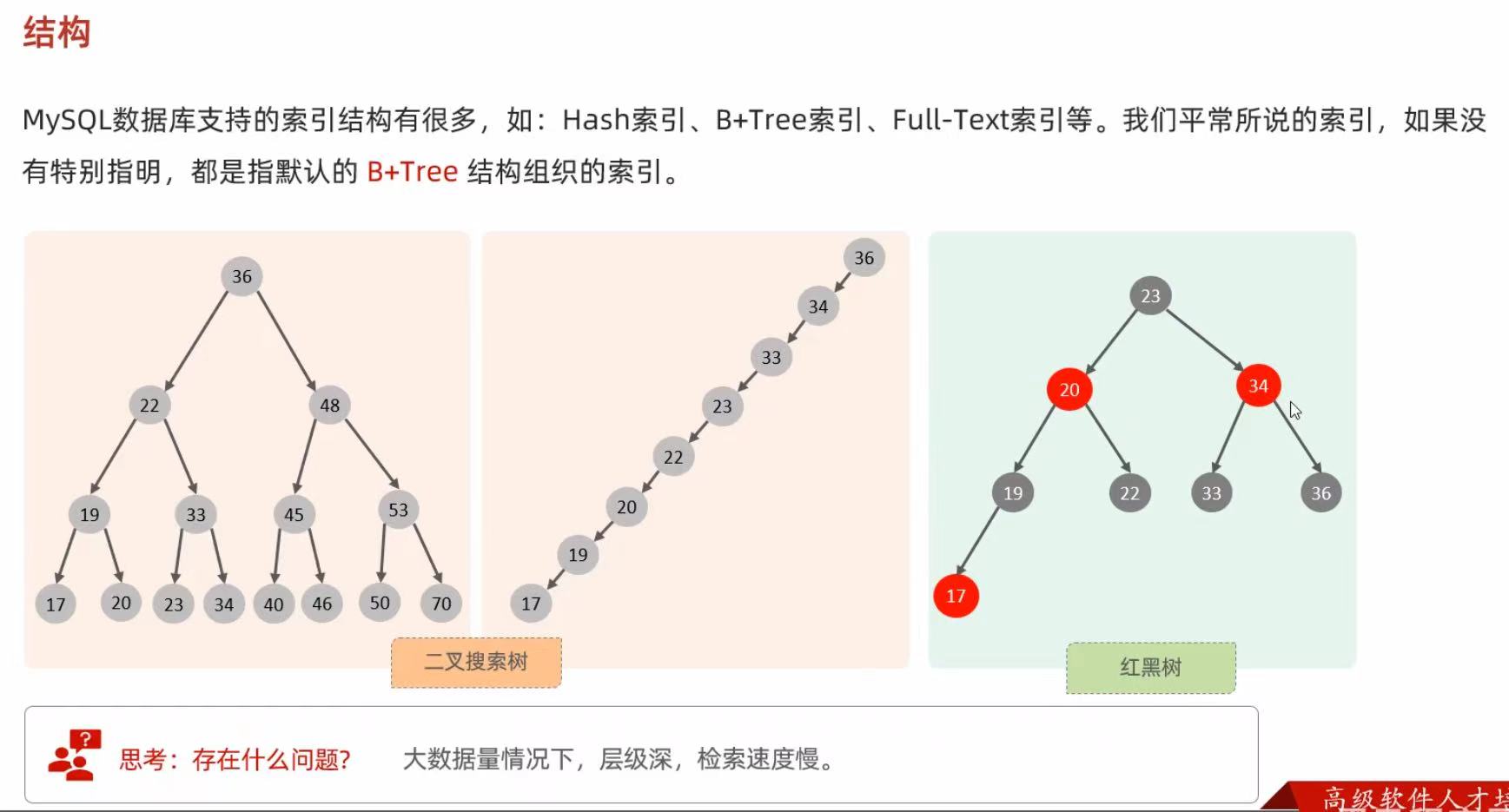
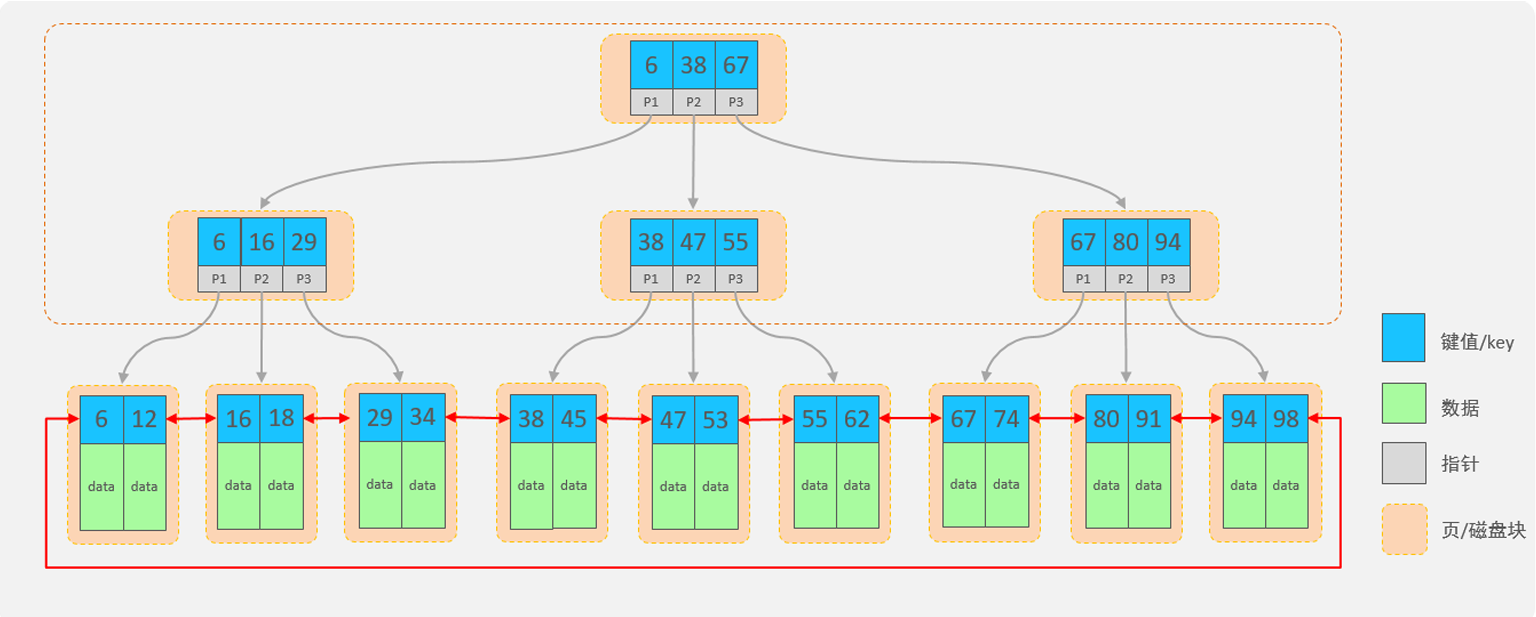
B+Tree结构:
- 每一个节点,可以存储多个key(有n个key,就有n个指针)
- 节点分为:叶子节点、非叶子节点
叶子节点,就是最后一层子节点,所有的数据都存储在叶子节点上
非叶子节点,不是树结构最下面的节点,用于索引数据,存储的的是:key+指针 - 为了提高范围查询效率,叶子节点形成了一个双向链表,便于数据的排序及区间范围查询
B+Tree有如下优点:
- 千万条数据,B+Tree可以控制在小于等于3的高度
- 所有的数据都存储在叶子节点上,并且底层已经实现了按照索引进行排序,还可以支持范围查询,叶子节点是一个双向链表,支持从小到大或者从大到小查找
3. 语法
- 创建索引
create [ unique ] index 索引名 on 表名 (字段名,... ) ;
案例:为tb_emp表的name字段建立一个索引
create index idx_emp_name on tb_emp(name);
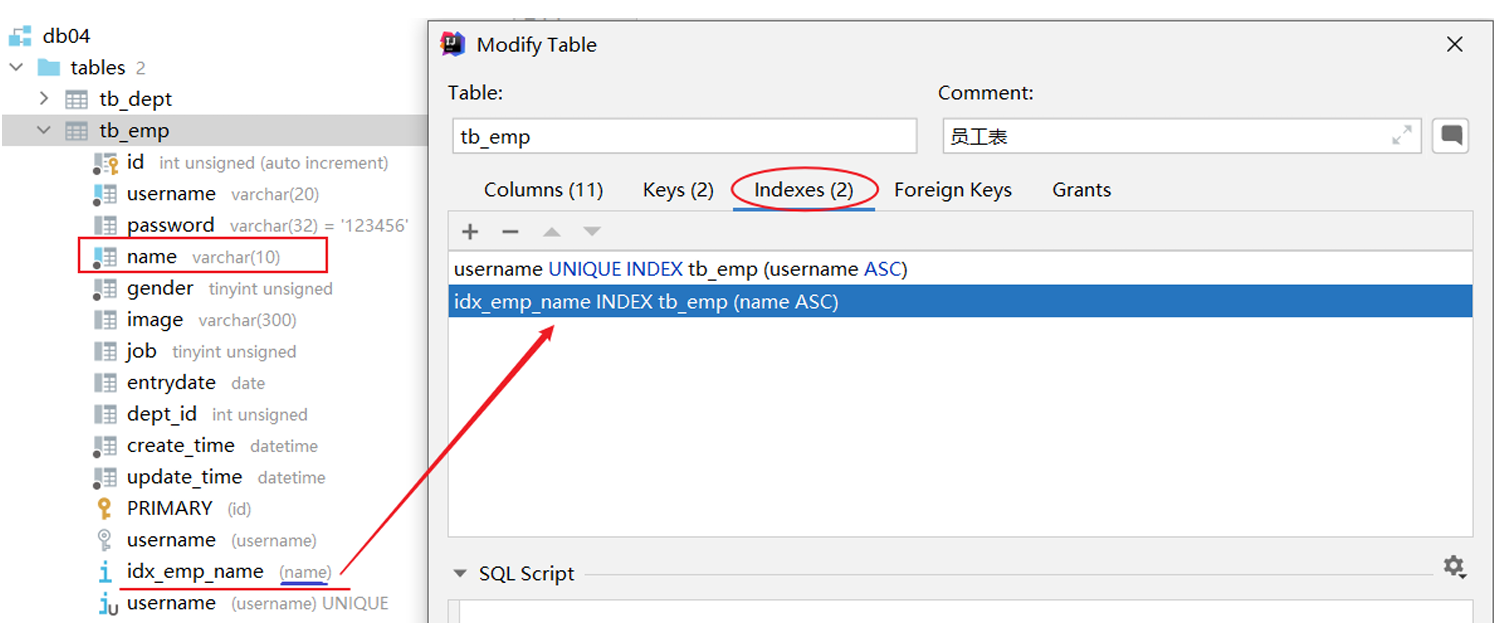
在创建表时,如果添加了主键和唯一约束,就会默认创建:主键索引、唯一约束

- 查看索引
show index from 表名;
案例:查询 tb_emp 表的索引信息
show index from tb_emp;
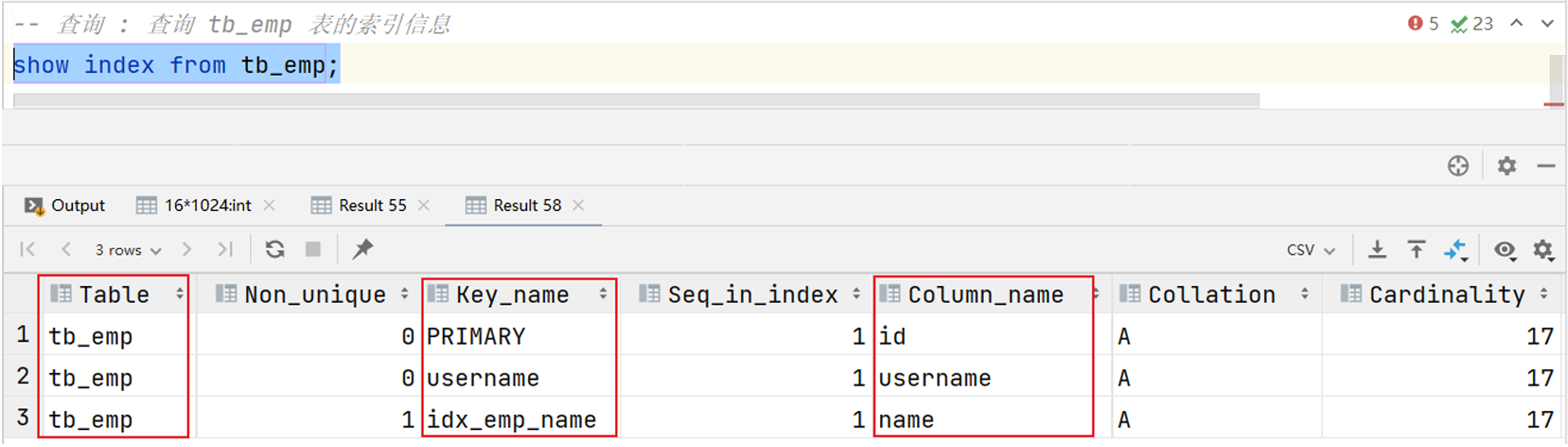
- 删除索引
drop index 索引名 on 表名;
案例:删除 tb_emp 表中name字段的索引
drop index idx_emp_name on tb_emp;
注意事项:
- 主键字段,在建表时,会自动创建主键索引
- 添加唯一约束时,数据库实际上会添加唯一索引