PCIE基础学习之物理层学习基础
目录
逻辑物理层:
链路训练和初始化:
训练机制:
电气物理层:
有序集:
整体协议机制:
发起方:
接收方:
物理层是PCIE的最底层,TLP 和 DLLP数据包都要经过物理层才能发送给对方。在协议中将物理层的分为两个部分:逻辑部分和电气部分。
逻辑物理层主要包含数字处理,其中主要是将链路上的数据包采样,并串转换等处理;电气部分主要包含物理层的模拟电路接口,为每个通道提供差分驱动器和接收器。
逻辑物理层:
接收端接收到的TLP和TLLP会被物理层的buffer记录,在这个缓存中会对数据包加上start 和 end 字符,这样做是为了方便接收端能识别出边界。

在物理层中,数据包的每个字节都会被分割到链路所使用的所有通道里,这个过程叫做字节条带化。实际上,每个通道在链路上都是独立的串行传输路径,这些通道又在各自的数据接收端聚合。
在传输的过程中,每个字节都进行扰码。对于前两代PCIE来说,使用的编码方式是8b/10b。对于第三代,采用了128b/130b编码。
接收端接收到数据后解码,使用串并转换器将比特流转换成字节流,字节流再通过一个缓存跨时钟后,反条带化之后将所有通道内的字节聚合重新恢复成数据。
链路训练和初始化:
物理层的其他任务是将链路初始化以及训练。
链路训练是为了确保 发起端和接收端时钟同步,极性一致,链路宽度匹配以及速率吻合等。
训练机制:
链路训练通常会发送和接收特定的序列(sequence)来完成。发起端会发送一系列的训练符号,接收端会接收这些训练符号进行时钟恢复,符号锁定,极性检测等,然后将自身状态反馈给发起端。发起端如果发现不对就再次发起训练,直到优化完成。就像两个人反复确认一件事的细节一样。
该机制一般会涉及到几个步骤:
位锁定:接收端会从接收的串行数据中提取时钟信号,此时接收端内部的时钟恢复电路会不断调整,直到与发起端同步。
符号锁定:时钟同步之后,接收端会锁定数据的符号边界。
极性判断:由于插拔的卡槽连接翻转或者信号极性反转,接收端会自动检测发起端的极性并自动调整,以确保信号极性与发起端的一致。
链路交互:发起端和接收端会交互各自的链路通道信息,并选择一个 双方都支持的最大链路宽度。
通道翻转:发起端与接收端的通道存在物理翻转时,接收端会自动调整通道,以确保通道的连接顺序一致。
电气物理层:
物理层的发送器和接收器是通过一个交流耦合链路相连,在两设备连接的物理路径上有电容,让信号高频通过,阻塞低频部分。
由于发起端的接收端的参考电压可能不同,为了实现这个功能,串行总线常常会在物理层加入电容。
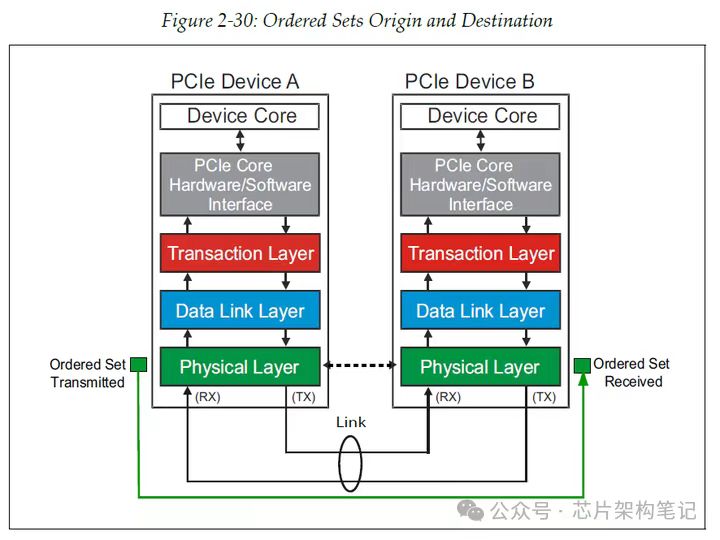
有序集:
有序集只在设备的物理层传输,起始于发送端的物理层,终止于接收端的物理层。 物理层的有序集并没有做成数据包的形式,它是一种物理层的数据流,英文称作Order set。
我们也称作它为PLP(physical layer packet)。 一个order set使用一个单独的COM字符作为起始,后面跟着3个及以上的其他字符用于定义传输信息,有序集在传输时只会终止于链路的对端设备,不会被switch路由到PCIE网络中。
有序集的长度是4字节的整数倍,主要参与链路训练,时钟补偿等,还可以指示链路进入或者退出低功耗状态。
整体协议机制:
发起方:
现在以一个内存读请求的例子讲述整个PCIE协议,这个请求过程从发起方发起内存读请求开始,直到发起方从完成方获得所请求的数据为止。
首先发起方的设备核心层(软件层)向事务层发起一个请求,请求中包含了这些信息:32bit 或者64bit 的内存地址,事务类型,要读取的数据总理(以DW) 为单位,流量分类(traffic class) ,字节使能,属性等。
事务层使用这些信息来构建一个MRd TLP 。这个TLP的header大小为3DW 或者4DW,这取决于地址字段的大小(32位地址就是3DW,64位地址就是4DW) 。同时事务层会向Header中加入该请求方ID(BFD)。然后TLP将会被放入相应类型的虚拟通道中,等待被发送。一旦这个TLP被选中,那么流量控制逻辑 就会确认对端设备的接收buffer是否能够接收。之后 MRd TLP就会被发送到数据链路层。
在数据链路层,数据包被加上12bit的序列号 以及32bit的LCRC,并在replay buffer中保留这个TLP的副本,然后将数据发送至物理层。
在物理层里,数据包被加上start和end字符,然后再所有可用的通道上进行字节条带化,8b/10b编码 ,加扰,最终以差分形式输出给对端。
接收方:
接收方对输入的比特流完成串并转换后恢复成10bit,之后经过跨时钟缓存,10bit数据被解码恢复成字节,每个通道上的字节都会被解扰以及反条带化。物理层开始检测start 和 end 字符并把它们剥除,将剩下的TLP发送给链路层。
接收方链路层对该TLP进行LCRC校验,并检查序列号。检查没错时链路层会生成一乐Ack包,里面包含了与该MRd TLP相同的序列号,然后给Ack加上16bit的CRC组成一个Ack DLLP,将这个DLLP发给物理层,有物理层加上组帧符号并传送给发起方。
发起方的物理层接收到Ack DLLP之后,对其组帧符号进行检查和剥除,然后发到链路层。如果链路层CRC检查无错,它会用Ack DLLP内的序列号与replay buffer中的TLP副本的序列号作比较,匹配的TLP副本会从replay buffer中清除。相反,如果接收到Nak DLLP, 那么就会将匹配的这个MRd TLP进行重传。
除了产生Ack DLLP之外,接收端的链路层还会将TLP发送给它的事务层。在事务层中,TLP被放置于合适的虚拟通道接收缓存中,等待对TLP进行ECRC校验(可选),若是校验无错就会发送给软件层。
为了完成请求,接收端的设备核心层(软件层)完成数据访问之后会向它的事务层发送一个Cpld请求(completion with data) ,cpld中包含了于Mrd 相同的requester ID tag 以及事务类型和数据payload等。
事务层使用这个cpld请求中的信息构建一个CplD TLP ,这种TLP的header固定为3DW(CplD TLP使用requester ID进行路由,不会使用到64bit地址)。同时该事务层会将自身的completer ID加到 CplD TLP Header中。之后这个数据包被放到适合的虚拟通道发送缓存中,一旦虚拟通道的冲裁机制选中要发送的cpld TLP ,流量控制逻辑会先确认对端是否有可用空间,之后再发给链路层。
接收端的链路层同样会给数据包加上12bit 的序列号和32bit的LCRC,同时在自身的replay buffer中保留副本,之后将数据发送至物理层。
物理层加入同样的start和end字符并进行同样的硬件操作,最终发送给对端。
发起端接收到这个完成请求包并作一系列的解码,剥除后,其链路又会产生一个ack DLLP,以同样的方式发送给接收端,由接收端判断是否需要重传。
同时发起端的事务层校验TLP(ECRC可选),校验无错之后将收到的cpld TLP 的header和数据payload交给软件层,至此数据请求就全部完成了。