DPO 深度解析:从公式到工程,从偏好数据到可复用训练管线
目录
-
为什么是 DPO:从 RLHF 的复杂性说起
-
DPO 的核心原理:公式、直觉与对比
-
偏好数据如何构造:从 A/B 自博弈到 chosen/rejected
-
端到端落地:用 HuggingFace Transformers + TRL 跑通 DPO
-
评测与监控:win-rate、logprob-gain 与“坏例”追踪
-
进阶与变体:DPO β、参考模型、活跃学习与困难样本挖掘
-
工程最佳实践:多阶段流水线、LoRA/量化、可验证任务优先
-
常见陷阱:数据分布漂移、模式坍塌、长文惩罚与安全对齐
-
总结:DPO 不是“去 RL”,而是“把 RLHF 里最难的一段拿掉”
1. 为什么是 DPO:从 RLHF 的复杂性说起
在经典 RLHF 中,我们需要两步曲:先训练奖励模型(RM)来拟合人类偏好,再用 PPO 去最大化该奖励,同时用 KL 惩罚把策略拉回参考分布,避免模型“飘”。这条路有效,但工程链条长、超参多,还要求“采样—打分—反向传播”紧耦合,导致成本高与不稳定成为常态。PPO 的原始论文将“截断比率 + 近端目标”引入策略梯度以稳住更新,但依然要维护复杂的 RL loop。(arXiv)
DPO 的关键点在于:不显式训练 RM,不写环境;它把“偏好”直接写进一个对比式的分类目标里,用一个温度系数 β 对“偏好差”加权,等价于在 KL 正则下求解 RLHF 的最优策略。换句话说,DPO 是把 RLHF 的目标“闭式化”为一个可微的对比损失,训练流程与 SFT 几乎一样稳定,极大降低了工程复杂度。原论文明确给出了推导与实验对比。(arXiv)
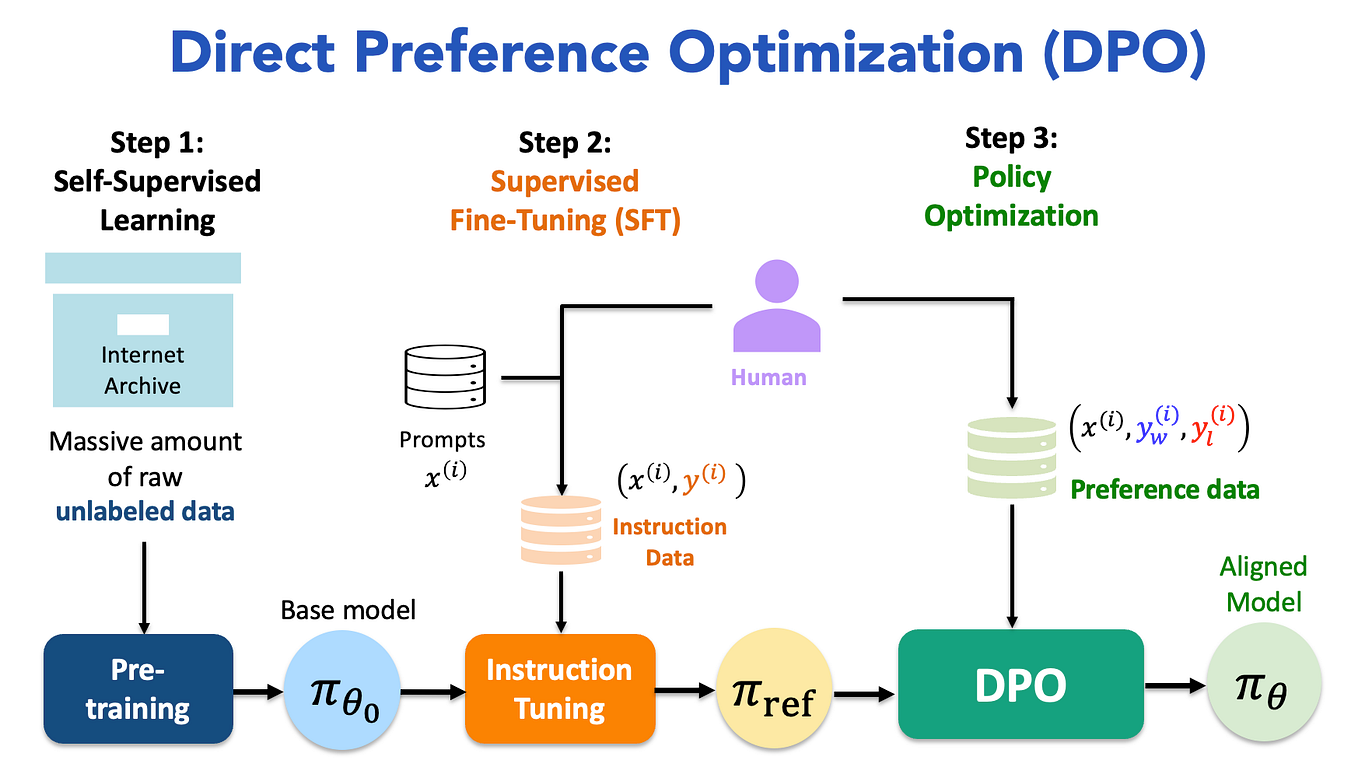
2. DPO 的核心原理:公式、直觉与对比
2.1 记号与目标
-
给定输入 xx,两段回答 y+y^+(更优,chosen)与 y−y^-(更差,rejected)。
-
参考策略(通常是 SFT 后的基模)记为 πref\pi_{\text{ref}},当前策略为 πθ\pi_\theta。
-
DPO 的目标:让 πθ\pi_\theta 相比 πref\pi_{\text{ref}} 更偏向 y+y^+ 而非 y−y^-。
2.2 经典 DPO 损失(简化)
-
直觉:提升“相对对数概率差”,并在 πref\pi_{\text{ref}} 框架下做对比;β 越大,偏好边界越“硬”。
-
与 PPO 的关系:PPO 需要 RM 给标量奖励并做 on-policy 更新;DPO 直接用偏好对,无需 RM,也不必维持在线采样回路。(arXiv)
2.3 与 SFT、RM/PPO 的对比
-
SFT:最像“模仿学习”——喂好样本,学它的分布;但不会显式区分好坏,只会拟合已有答案。
-
RM/PPO:可在线细粒度调参,但工程与稳定性成本高。
-
DPO:更像“成对排序 + 对比学习”,以最小代价把“更好 vs 更差”刻进策略分布。(arXiv)
3. 偏好数据如何构造:从 A/B 自博弈到 chosen/rejected
3.1 数据来源
-
人类偏好:人工标注 A/B 选优。
-
自我博弈:同一模型用不同温度/提示/随机种子生成多条路径,再用可编程裁判(数学验算、代码单测、RAG 事实一致性等)自动判胜负。
-
多模型互评:不同家族策略交叉对战,产出更强的“困难偏好对”。
3.2 构造要点
-
去重与清洗:过滤重复、极短/极长、不可判样本。
-
难例挖掘:保留分差接近但有明确胜负的 pair,对提升边际最有利。
-
分桶:数学/代码(可验证)与开放问答(事实一致/结构化)分开计分,避免偏见累积。
这一步的质量,几乎决定了 DPO 的上限。
4. 端到端落地:用 Transformers + TRL 跑通 DPO
下方给三段可直接运行的示例代码,每段≥30行,涵盖“构造偏好对 → DPO 训练 → 推理评测”。(若显存紧张,建议 4-bit + LoRA)
4.1 代码块 A:从 A/B 候选构造 DPO 偏好对(含启发式裁判,≈90 行)
# build_dpo_pairs.py
# -*- coding: utf-8 -*-
"""
从 A/B 候选生成 (prompt, chosen, rejected) 偏好对
- 数学题:数值校验
- 开放问答:关键词覆盖 + 列表结构 + 引用标记
"""
import re, json, random
from pathlib import Path
from dataclasses import dataclass
from typing import List, Dict, Optional@dataclass
class Example:prompt: strcand_a: strcand_b: strmeta: Optional[dict] = None # gold答案 / 证据 / 单测 等def last_number(text: str):m = re.findall(r"-?\d+(?:\.\d+)?", text)return float(m[-1]) if m else Nonedef math_score(ans: str, gold: Optional[float]) -> float:if gold is None: return 0.0pred = last_number(ans)if pred is None: return 0.0err = abs(pred - gold)if err <= 1e-6: return 1.0scale = max(abs(gold), 10.0)return max(0.0, 1.0 - err/scale)def openqa_score(ans: str, q: str) -> float:kws = set([w for w in re.split(r"[,。、;:,\s/]+", q) if len(w) >= 2])cov = sum(1 for w in kws if w in ans) / (len(kws) + 1e-6)has_list = 0.2 if re.search(r"(\n- |\n\d+\.)", ans) else 0.0has_cite = 0.1 if re.search(r"\[(参考|source|引用)\]", ans) else 0.0length = min(len(ans) / 600, 1.0)return float(0.5*cov + has_list + has_cite + 0.2*length)def judge(prompt: str, a: str, b: str, meta: dict) -> dict:s_a = max(math_score(a, meta.get("gold")), openqa_score(a, prompt))s_b = max(math_score(b, meta.get("gold")), openqa_score(b, prompt))# 平局打破:更结构化/更短一些的略优if abs(s_a - s_b) < 1e-3:s_a += 0.01 if len(a) < len(b) else 0.0if s_a >= s_b:return {"chosen": a, "rejected": b, "sc": s_a, "sr": s_b}return {"chosen": b, "rejected": a, "sc": s_b, "sr": s_a}def build_pairs(rows: List[Example], out_jsonl: str):keep = []for r in rows:res = judge(r.prompt, r.cand_a, r.cand_b, r.meta or {})# 严格过滤:不可判或差距过小的丢弃if max(res["sc"], res["sr"]) < 0.2 or abs(res["sc"] - res["sr"]) < 1e-3:continuekeep.append({"prompt": r.prompt,"chosen": res["chosen"],"rejected": res["rejected"],"score_chosen": res["sc"],"score_rejected": res["sr"]})Path(out_jsonl).write_text("\n".join(json.dumps(x, ensure_ascii=False) for x in keep),encoding="utf-8")print(f"[DPO] kept={len(keep)} -> {out_jsonl}")if __name__ == "__main__":toy = [Example("计算:27 + 15 = ?", "…因此答案为:42", "…最终答案:41", {"gold": 42.0}),Example("简述 HTTP/2 的核心改进","- 多路复用\n- 头部压缩(HPACK)\n[参考]","HTTP/2 更快。", {})]build_pairs(toy, "dpo_pairs.jsonl")
4.2 代码块 B:用 TRL 的 DPOTrainer 进行偏好微调(LoRA + 4bit,≈120 行)
# train_dpo.py
# -*- coding: utf-8 -*-
"""
用 TRL 的 DPOTrainer 训练偏好模型
- 4-bit 量化 + LoRA:单卡可运行 7B 级模型
- 输入:build_dpo_pairs.py 生成的 dpo_pairs.jsonl
"""
import os, json
from datasets import Dataset
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
from peft import LoraConfig, get_peft_model, prepare_model_for_kbit_training
from trl import DPOTrainer, DPOConfigDATA = "dpo_pairs.jsonl"
BASE = os.environ.get("BASE", "Qwen/Qwen2.5-1.5B-Instruct")
OUT = os.environ.get("OUT", "./dpo_out")def load_pairs(p):return [json.loads(l) for l in open(p, "r", encoding="utf-8")]def to_dataset(rows): return Dataset.from_list(rows)def build_tok_model():tok = AutoTokenizer.from_pretrained(BASE, use_fast=True)if tok.pad_token is None: tok.pad_token = tok.eos_tokenquant = BitsAndBytesConfig(load_in_4bit=True, bnb_4bit_quant_type="nf4",bnb_4bit_compute_dtype=torch.float16, bnb_4bit_use_double_quant=True)model = AutoModelForCausalLM.from_pretrained(BASE,quantization_config=quant, device_map="auto")model = prepare_model_for_kbit_training(model)lora = LoraConfig(r=16, lora_alpha=32, lora_dropout=0.05, bias="none",task_type="CAUSAL_LM",target_modules=["q_proj","k_proj","v_proj","o_proj"])model = get_peft_model(model, lora)model.print_trainable_parameters()return tok, modeldef pack_for_dpo(ds, tok, max_len=768):def enc(txts): return tok(txts, max_length=max_len, truncation=True, padding=False, add_special_tokens=True)def mapper(ex):return {"prompt_input_ids": enc(ex["prompt"])["input_ids"],"prompt_attention_mask": enc(ex["prompt"])["attention_mask"],"chosen_input_ids": enc(ex["chosen"])["input_ids"],"chosen_attention_mask": enc(ex["chosen"])["attention_mask"],"rejected_input_ids": enc(ex["rejected"])["input_ids"],"rejected_attention_mask": enc(ex["rejected"])["attention_mask"],}return ds.map(mapper, batched=True, remove_columns=ds.column_names)if __name__ == "__main__":os.makedirs(OUT, exist_ok=True)rows = load_pairs(DATA); ds = to_dataset(rows)tok, model = build_tok_model()ds = pack_for_dpo(ds, tok)cfg = DPOConfig(output_dir=OUT,per_device_train_batch_size=2, gradient_accumulation_steps=8,learning_rate=1e-5, lr_scheduler_type="cosine", warmup_ratio=0.05,max_steps=300, logging_steps=10, save_steps=100,beta=0.1, max_length=768, max_prompt_length=512, max_target_length=256,report_to="none")trainer = DPOTrainer(model=model, ref_model=None, beta=cfg.beta,train_dataset=ds, tokenizer=tok, args=cfg)trainer.train()trainer.save_model(OUT); tok.save_pretrained(OUT)print(f"[DONE] saved -> {OUT}")
TRL 的
DPOTrainer与原论文一致,属于对比式优化,无需显式 RM;HuggingFace 文档与示例脚本可直接参考。(Hugging Face)
4.3 代码块 C:推理与“偏好提升”评测(win-rate / logprob-gain,≈70 行)
# eval_winrate.py
# -*- coding: utf-8 -*-
"""
离线评测:新策略 vs 参考策略 的胜率与对数概率提升
- 对每个 prompt 让两模各自生成
- 用与“构造阶段一致”的裁判打分
- 统计 win-rate,并计算 logprob 差值的均值
"""
import torch, json, math
from transformers import AutoTokenizer, AutoModelForCausalLM
from build_dpo_pairs import openqa_score, math_score, last_numberREF = "Qwen/Qwen2.5-1.5B-Instruct" # 参考
NEW = "./dpo_out" # 新策略(LoRA adapter 已保存)
DATA = "eval_prompts.jsonl" # {"prompt": "...", "gold": 42.0?}def gen(model, tok, prompt, sys="你是严谨助教", temp=0.7):ipt = tok(f"{sys}\n\n题目:{prompt}\n请逐步推理并给出结论:",return_tensors="pt").to(model.device)with torch.no_grad():out = model.generate(**ipt, do_sample=True, temperature=temp,top_p=0.9, repetition_penalty=1.05,max_new_tokens=256, eos_token_id=tok.eos_token_id,pad_token_id=tok.eos_token_id)text = tok.decode(out[0], skip_special_tokens=True)return textdef judge(prompt, ans, gold=None):s1 = math_score(ans, gold)s2 = openqa_score(ans, prompt)return max(s1, s2)def logprob(model, tok, prompt, ans):ids = tok(prompt + ans, return_tensors="pt").to(model.device)["input_ids"][0]with torch.no_grad():out = model(ids.unsqueeze(0), labels=ids.unsqueeze(0))# 负 NLL → 近似 logprob,总体趋势足够return float(-out.loss * ids.shape[0])if __name__ == "__main__":tok_ref = AutoTokenizer.from_pretrained(REF, use_fast=True)tok_new = AutoTokenizer.from_pretrained(NEW, use_fast=True)if tok_ref.pad_token is None: tok_ref.pad_token = tok_ref.eos_tokenif tok_new.pad_token is None: tok_new.pad_token = tok_new.eos_tokenmod_ref = AutoModelForCausalLM.from_pretrained(REF, device_map="auto")mod_new = AutoModelForCausalLM.from_pretrained(NEW, device_map="auto")wins, total, gains = 0, 0, []for line in open(DATA, "r", encoding="utf-8"):ex = json.loads(line); q, gold = ex["prompt"], ex.get("gold")a_ref = gen(mod_ref, tok_ref, q)a_new = gen(mod_new, tok_new, q)s_ref, s_new = judge(q, a_ref, gold), judge(q, a_new, gold)wins += 1 if s_new >= s_ref else 0; total += 1gains.append(logprob(mod_new, tok_new, q, a_new) - logprob(mod_ref, tok_ref, q, a_ref))print(f"[WIN-RATE] {wins}/{total} = {wins/total:.2%}")print(f"[LOGPROB Δ] mean={sum(gains)/max(1,len(gains)):.3f}")
评测要点:裁判函数与训练期一致,避免“训练/评测不一致”的偏差;win-rate 趋势是最直观指标。
5. 评测与监控:win-rate、logprob-gain 与“坏例”追踪
-
Win-Rate(对战胜率):新策略 vs 参考策略在开发集的胜率;>55% 表明有效。
-
Logprob-Gain:新策略的输出对同分布 prompt 的对数似然提升。
-
错误画像:将“失败样本”分桶(数学、事实一致、结构化),定位奖励设计短板。
-
不可判比例:>15% 说明裁判过苛或数据噪声大,应放宽启发式或弃题。
6. 进阶与变体:β、参考模型、活跃学习、困难样本挖掘
-
β(temperature):0.05–0.2 常见。β 大→放大偏好差,对“接近边界”的样本更敏感,但过大会过拟合。
-
参考模型 πref\pi_{\text{ref}}:通常取 SFT 后的“稳态基准”;若为零参考,会失去 KL 约束,易漂移。
-
活跃学习(Active DPO):在线挑选最有信息量的 pair 优先标注/训练,减少样本量但提升效率。(arXiv)
-
DPO 变体:如 Offset-DPO 对样本赋权,不同来源的偏好对可有不同重要度。(arXiv)
-
综述:近两年 DPO 家族扩张迅速,系统性总结可参考最新 survey。(arXiv)
7. 工程最佳实践:多阶段流水线、LoRA/量化、可验证任务优先
-
多阶段训练
-
SFT → DPO(偏好) → 少量 RM/PPO(价值观对齐):DPO 负责“更聪明”,PPO 负责“更合人意”。
-
可对不同任务分桶 DPO,避免“一个裁判打天下”。
-
硬件与效率
-
单卡建议:4-bit(NF4)+ LoRA;梯度累积与混合精度配合减少显存占用。
-
大批量推理生成偏好对时,使用
generate()的流控与缓存策略。(Hugging Face)
-
可验证任务优先
-
数学、代码、抽取类任务优先导入 DPO;开放问答配合 RAG 证据一致性与简单 NLI。
-
不可判/争议样本宁可丢弃,减少噪声。
8. 常见陷阱:数据分布漂移、模式坍塌、长文惩罚与安全对齐
-
分布漂移:DPO 样本分布与线上实际差异大,赢在“裁判打法”,输在“真实任务”;需混入代表性开发集抽查。
-
模式坍塌:裁判过度奖励某种表达(如列表/模板),导致输出单一;解决:引入“多裁判 + 去相关正则”。
-
长文惩罚:过长输出会“堆砌分数”,需长度上限和轻微惩罚。
-
安全/价值观:DPO 不等于完全对齐,必要时以少量 RLHF(PPO) 做安全兜底。(arXiv)
-
flowchart LRSFT[SFT 基模] --> GEN[多路径生成]GEN --> JUDGE[可编程裁判]JUDGE --> DPO[(DPOTrainer)]DPO --> Policy[新策略]Policy -->|对战评测| Monitor[Win-Rate/Logprob]
参考链接(可靠外链)
-
DPO 原论文(Rafailov et al., 2023):https://arxiv.org/abs/2305.18290 ;PDF:https://arxiv.org/pdf/2305.18290 (arXiv)
-
TRL DPOTrainer 文档与示例:https://huggingface.co/docs/trl/main/en/dpo_trainer ;v0.9.x 版:https://huggingface.co/docs/trl/v0.9.6/en/dpo_trainer (Hugging Face)
-
Transformers 文档(生成与解码策略):https://huggingface.co/docs/transformers/en/main_classes/text_generation ;https://huggingface.co/docs/transformers/en/generation_strategies (Hugging Face)
-
PPO 原论文(Schulman et al., 2017):https://arxiv.org/abs/1707.06347 ;PDF:https://arxiv.org/pdf/1707.06347 (arXiv)
-
DPO 综述与进展:2024 Survey:https://arxiv.org/abs/2410.15595 ;2025 Survey:https://arxiv.org/abs/2503.11701 (arXiv)
-
Active DPO:在线/离线活跃学习框架:https://arxiv.org/abs/2503.01076 (arXiv)
9. 总结与互动
一句话:DPO 把“人类/自博弈偏好”从 RL 的循环里抽离出来,用对比损失把“更好 vs 更差”直接刻进策略分布,简化了 RLHF 最难的工程段,在推理/结构化任务上尤为高效。它不是对 RL 的否定,而是现实工程中的务实折中:
-
需要稳定、低成本提升“偏好一致性”时,先上 DPO;
-
需要在线细粒度和价值观安全时,再用少量 PPO 兜底。