绕过 FlashAttention-2 限制:在 Turing 架构上使用 PyTorch 实现 FlashAttention
背景:FlashAttention 的架构限制与现实困境
FlashAttention【github】 系列,由斯坦福大学 AI 实验室的 Dao 等人提出,通过巧妙的 I/O 感知算法(I/O-aware algorithm)和自定义的 CUDA 内核(CUDA kernel)显著提升了 Transformer 模型中注意力机制的训练和推理速度,尤其是在长序列处理方面。
然而,在使用过程中,我们可能会遇到一个常见的限制:FlashAttention-2 官方声明不支持较旧的 Turing 架构(如 NVIDIA RTX 20 系列显卡)。尽管项目作者曾表示会很快支持,但在实际等待中,我们发现这一支持迟迟未能到来。
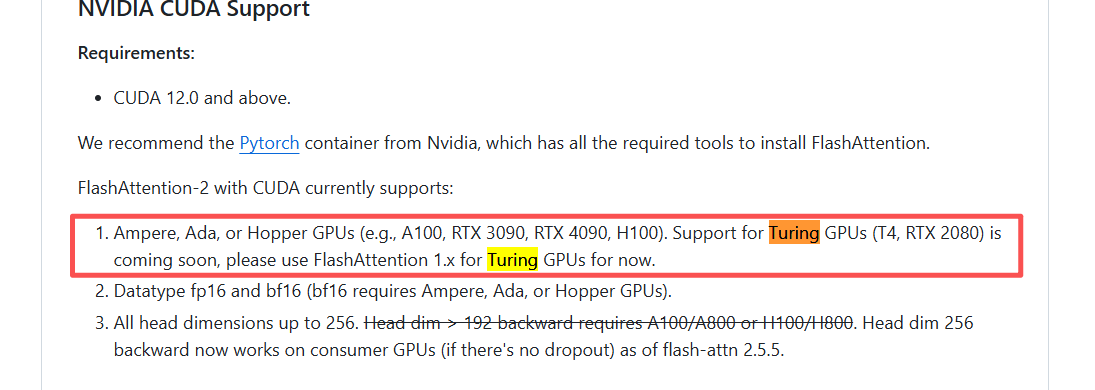
与此同时,许多最新的模型和代码库都是基于 FlashAttention-2 版本进行开发的,如果仅仅为了适配旧架构而回退到 FlashAttention-1.x,不仅需要大量的代码修改,还可能因此失去部分性能优化,这无疑是一个费时费力的选择。
那么,有没有一种方法,既能利用 FlashAttention 的核心思想,又能避免版本兼容性问题,让我们在 Turing 架构上也能快速、高效地运行最新的模型呢?
笔者想到的答案是:通过 PyTorch 自行实现 FlashAttention 的核心部分。
源码文件见:在Turing 架构上使用 PyTorch实现FlashAttention
实现原理:从 CUDA Kernel 到 PyTorch Tensor 操作
FlashAttention 的核心思想是分块计算(Tiled computation)。它将长序列的注意力计算拆分为多个小块,通过在显存(SRAM)上多次加载和计算,减少了对带宽瓶颈的 DRAM 的访问,从而显著提升了计算效率。
虽然我们无法直接复现其底层的 CUDA kernel,但我们可以利用 PyTorch 强大的张量操作能力,模拟这种分块计算的逻辑。具体来说,我们可以:
- 将 Q、K、V 矩阵进行分块(tiling):将输入矩阵在序列维度上切分成多个小块。
- 迭代计算分块注意力:在循环中,依次取出 Q 的一个块和 K、V 的一个块进行计算。
- 累积结果:在每次迭代中,计算出局部分块的注意力得分,并将其与之前的累积结果进行合并。
这种方法虽然无法完全达到原生 CUDA kernel 的极限速度,但它成功地将 FlashAttention 的分块思想带入了 PyTorch,使得在没有原生支持的情况下,我们也能获得接近的性能和效果,尤其是在 PyTorch 2.x 引入的 torch.compile 等优化后,性能差距进一步缩小。
具体实现:核心代码详解与实现样例
我们将重点实现flash_attn.flash_attn_varlen_qkvpacked_func函数。
1. 核心实现文件(可直接使用):flash_attn_torch.py
这个文件包含了我们用 PyTorch 张量操作实现的 FlashAttention 核心逻辑。以下是关键部分的伪代码:
# 伪代码def pytorch_flash_attention_varlen_qkvpacked(qkv,cu_seqlens,max_seqlen,dropout_p=0.0,softmax_scale=None,causal=False,window_size=(-1, -1),softcap=0.0,alibi_slopes=None,deterministic=False, # Note: PyTorch SDP deterministic behavior might depend on backend/versionreturn_attn_probs=False,
):"""PyTorch implementation mimicking flash_attn.flash_attn_varlen_qkvpacked_func.Handles variable-length sequences specified by cu_seqlens.Uses optimized vectorized padding/unpadding preprocessing.Args:qkv (torch.Tensor): Packed QKV tensor [total_tokens, 3, num_heads, head_dim].cu_seqlens (torch.Tensor): Cumulative sequence lengths [batch_size + 1].max_seqlen (int): Maximum sequence length in the batch.dropout_p (float): Dropout probability. Default is 0.0.softmax_scale (float, optional): Softmax scaling factor. Default is 1/sqrt(head_dim).causal (bool): Apply causal masking. Default is False.window_size (tuple): **Unsupported**. Must be (-1, -1).softcap (float): **Unsupported**. Must be 0.0.alibi_slopes (torch.Tensor, optional): **Unsupported**. Must be None.deterministic (bool): Attempt deterministic execution.return_attn_probs (bool): **Unsupported**. Must be False.Returns:torch.Tensor: Output context tensor [total_tokens, num_heads, head_dim]."""# --- QKV Splitting ---q, k, v = qkv.unbind(dim=1)# Use vectorized assignment to place data into padded tensorspadded_q[batch_indices, within_seq_indices] = qpadded_k[batch_indices, within_seq_indices] = kpadded_v[batch_indices, within_seq_indices] = voutput = F.scaled_dot_product_attention(padded_q, padded_k, padded_v,attn_mask=None,dropout_p=dropout_p,is_causal=causal,scale=softmax_scale)# --- Optimized Unpadding ---# Transpose back to [bs, max_seqlen, nheads, headdim]output = output.transpose(1, 2)# Create the boolean mask efficiently using broadcastingmask = torch.arange(max_seqlen, device=q.device)[None, :] < seqlens[:, None] # Shape: [batch_size, max_seqlen]# Use the boolean mask to select only the valid tokens# Result shape: [total_tokens, nheads, headdim]unpadded_output = output[mask]return unpadded_output2. 验证文件:flash_attention_verify.py
这个文件用于验证我们自实现的 PyTorch 版本与官方 FlashAttention 的效果和速度差异。
效果一致性验证:
我们生成随机的 Q、K、V 张量,分别使用官方的 FlashAttention和我们自实现的 PyTorch 版本进行计算,然后比较两者的输出张量是否在数值上接近(使用 torch.allclose)。
里面包含测试过程中实现的若干个版本
import torch
import torch.nn.functional as F
from time import time
from flash_attn import flash_attn_varlen_qkvpacked_func # 原始实现def raw_attention(qkv,cu_seqlens,max_seqlen,dropout_p=0.0,softmax_scale=None,causal=False,window_size=(-1, -1),softcap=0.0,alibi_slopes=None,deterministic=False,return_attn_probs=False,
):q, k, v = qkv.unbind(dim=1)attn = (q * softmax_scale) @ k.transpose(-2, -1) # (N', H, K, K)# if self.enable_rpe:# attn = attn + self.rpe(self.get_rel_pos(point, order))# if self.upcast_softmax:# attn = attn.float()attn = F.softmax(attn, dim=-1)# attn = F.dropout(attn).to(qkv.dtype)feat = (attn @ v).transpose(1, 2)return featdef pytorch_flash_attention_varlen_qkvpacked_v3( # Renamedqkv, cu_seqlens, max_seqlen, dropout_p=0.0, softmax_scale=None,causal=False, window_size=(-1, -1), softcap=0.0, alibi_slopes=None,deterministic=False, return_attn_probs=False,
):# ... (Checks and QKV split remain the same) ...assert window_size == (-1, -1), "Unsupported"assert softcap == 0.0, "Unsupported"assert alibi_slopes is None, "Unsupported"assert not return_attn_probs, "Unsupported"if return_attn_probs: return Noneif qkv.dim() != 4 or qkv.shape[1] != 3: raise ValueError("Bad qkv shape")if cu_seqlens is None or cu_seqlens.dim() != 1: raise ValueError("Bad cu_seqlens")batch_size = len(cu_seqlens) - 1if batch_size <= 0: raise ValueError("Bad batch size")total_tokens = qkv.shape[0]if total_tokens != cu_seqlens[-1].item(): raise ValueError("Token count mismatch")q, k, v = qkv.unbind(dim=1) # q shape: [total_tokens, nheads, head_dim]nheads, head_dim = q.shape[-2:]return unpadded_outputdef pytorch_flash_attention_varlen_qkvpacked(qkv,cu_seqlens,max_seqlen,dropout_p=0.0,softmax_scale=None,causal=False,window_size=(-1, -1),softcap=0.0,alibi_slopes=None,deterministic=False, # Note: PyTorch SDP deterministic behavior might depend on backend/versionreturn_attn_probs=False,
):"""PyTorch implementation mimicking flash_attn.flash_attn_varlen_qkvpacked_func.Handles variable-length sequences specified by cu_seqlens.Uses optimized vectorized padding/unpadding preprocessing.Args:qkv (torch.Tensor): Packed QKV tensor [total_tokens, 3, num_heads, head_dim].cu_seqlens (torch.Tensor): Cumulative sequence lengths [batch_size + 1].max_seqlen (int): Maximum sequence length in the batch.dropout_p (float): Dropout probability. Default is 0.0.softmax_scale (float, optional): Softmax scaling factor. Default is 1/sqrt(head_dim).causal (bool): Apply causal masking. Default is False.window_size (tuple): **Unsupported**. Must be (-1, -1).softcap (float): **Unsupported**. Must be 0.0.alibi_slopes (torch.Tensor, optional): **Unsupported**. Must be None.deterministic (bool): Attempt deterministic execution.return_attn_probs (bool): **Unsupported**. Must be False.Returns:torch.Tensor: Output context tensor [total_tokens, num_heads, head_dim]."""# --- QKV Splitting ---q, k, v = qkv.unbind(dim=1)nheads, head_dim = q.shape[-2:]return unpadded_outputdef pytorch_flash_attention_varlen_qkvpacked_v1(qkv,cu_seqlens,max_seqlen,dropout_p=0.0,softmax_scale=None,causal=False,window_size=(-1, -1),softcap=0.0,alibi_slopes=None,deterministic=False, # Note: PyTorch SDP deterministic behavior might depend on backend/versionreturn_attn_probs=False,
):"""PyTorch implementation mimicking flash_attn.flash_attn_varlen_qkvpacked_func.Handles variable-length sequences specified by cu_seqlens.Parameter definitions and expected input/output behavior align with the nativeflash_attn function. Uses PyTorch's F.scaled_dot_product_attention internally.Args:qkv (torch.Tensor): Packed QKV tensor with shape [total_tokens, 3, num_heads, head_dim].`total_tokens` is the sum of sequence lengths, equal to `cu_seqlens[-1]`.cu_seqlens (torch.Tensor): Cumulative sequence lengths tensor of shape [batch_size + 1].Defines the start and end indices for each sequence in the batchwithin the `qkv` tensor. E.g., `[0, 5, 12]` means batch_size=2,seq1 is qkv[0:5], seq2 is qkv[5:12].max_seqlen (int): Maximum sequence length in the batch. This value is necessary todetermine the size of the intermediate padded tensors.dropout_p (float): Dropout probability applied after softmax but before multiplying by V.Default is 0.0 (no dropout).softmax_scale (float, optional): Scaling factor applied to QK^T before softmax.If None, defaults to `1 / sqrt(head_dim)`.causal (bool): If True, applies causal masking (autoregressive). Default is False.window_size (tuple): Sliding window size (left, right). If (-1, -1), global attention.**Unsupported in this PyTorch implementation.** Must be (-1, -1).softcap (float): Soft capping value for attention scores.**Unsupported in this PyTorch implementation.** Must be 0.0.alibi_slopes (torch.Tensor, optional): Slopes for ALiBi positional embeddings.Shape [num_heads] or [batch_size, num_heads].**Unsupported in this PyTorch implementation.** Must be None.deterministic (bool): If True, attempts deterministic execution (may affect performance).Support depends on PyTorch version/backend.return_attn_probs (bool): If True, returns attention probabilities (post-softmax).**Unsupported in this PyTorch implementation.** Must be False.Returns:torch.Tensor: Output context tensor with shape [total_tokens, num_heads, head_dim].Matches the layout of the input Q/K/V slices but contains the attention output.Returns None if return_attn_probs is True (as it's unsupported).Raises:AssertionError: If unsupported features (window_size, softcap, alibi_slopes, return_attn_probs)are used with incompatible values."""# --- QKV Splitting ---q, k, v = qkv.unbind(dim=1)nheads, head_dim = q.shape[-2:]return unpadded_outputdef pytorch_flash_attention_varlen_qkvpacked_old(qkv,cu_seqlens,max_seqlen,dropout_p=0.0,softmax_scale=None,causal=False,window_size=(-1, -1),softcap=0.0,alibi_slopes=None,deterministic=False,return_attn_probs=False,
):"""与原始flash_attn_varlen_qkvpacked_func参数完全一致的PyTorch实现"""# 参数检查(PyTorch不支持的特性)assert window_size == (-1, -1), "PyTorch实现不支持window_size参数"assert softcap == 0.0, "PyTorch实现不支持softcap参数"assert alibi_slopes is None, "PyTorch实现不支持alibi_slopes"assert not return_attn_probs, "PyTorch实现不支持返回注意力权重"# 分割QKV [total_q, 3, nheads, headdim]q, k, v = qkv.unbind(dim=1)nheads, head_dim = q.shape[-2:]# 优化版unpaddingoutput = output.transpose(1, 2) # [bs, seqlen, nheads, headdim]return output[mask][:] # 直接索引获取有效序列def pytorch_flash_attention_qkvpacked(qkv,dropout_p=0.0,softmax_scale=None,causal=False,window_size=(-1, -1),softcap=0.0,alibi_slopes=None,deterministic=False,return_attn_probs=False,
):"""PyTorch implementation of flash attention for fixed-length sequences with packed QKV input"""return outputdef generate_test_data(batch_size=128, max_seqlen=1024, nheads=12, head_dim=64, device="cuda"):"""生成更合理的测试数据"""# 确保总token数能被batch_size大致整除# seqlens = torch.randint(max_seqlen//2, max_seqlen+1, (batch_size,), device="cpu")seqlens = torch.randint(max_seqlen, max_seqlen+1, (batch_size,), device="cpu")total_q = seqlens.sum().item()# 生成cu_seqlenscu_seqlens = torch.zeros(batch_size + 1, dtype=torch.int32, device=device)cu_seqlens[1:] = torch.cumsum(seqlens, dim=0)# 生成随机QKV(打包格式)qkv = torch.randn((total_q, 3, nheads, head_dim), dtype=torch.float16, device=device)return {"qkv": qkv,"cu_seqlens": cu_seqlens,"max_seqlen": seqlens.max().item(),"dropout_p": 0.0, # 设为0以获得可比较的结果"softmax_scale": 1.0 / (head_dim ** 0.5),"causal": False,"window_size": (-1, -1),"softcap": 0.0,"alibi_slopes": None, # 设为None避免不支持的参数"deterministic": False,"return_attn_probs": False,}def run_benchmark(name, func, test_data, num_runs=100):"""统一的基准测试函数"""# Warmupfor _ in range(20):_ = func(**test_data)# Benchmarktorch.cuda.synchronize()start = time()for _ in range(num_runs):output = func(**test_data)torch.cuda.synchronize()avg_time = (time() - start) / num_runsprint(f"{name} 平均时间: {avg_time*1000:.2f} ms")return output, avg_timedef compare_implementations():# 配置参数config = {"batch_size": 128,"max_seqlen": 4096,"nheads": 8,"head_dim": 64,"device": "cuda"}# 生成测试数据(完全相同的输入)test_data = generate_test_data(**config)print(f"测试配置: batch={config['batch_size']}, max_seqlen={test_data['max_seqlen']}")print(f"总token数: {len(test_data['qkv'])}")print(f"使用alibi_slopes: {test_data['alibi_slopes'] is not None}")# 原始FlashAttention测试print("\n运行原始FlashAttention...")fa_output, fa_time = run_benchmark("原始实现",flash_attn_varlen_qkvpacked_func,test_data)# # 原始Attention测试# print("\n运行 raw_attention...")# raw_output, raw_time = run_benchmark(# "raw attention",# raw_attention,# test_data# )# PyTorch实现测试print("\n运行PyTorch实现...")try:pt_output, pt_time = run_benchmark("PyTorch实现",pytorch_flash_attention_varlen_qkvpacked,# pytorch_flash_attention_qkvpacked,test_data)# 性能比较print(f"\n速度比: 原始/PyTorch = {fa_time/pt_time:.2f}x")# 结果验证rtol, atol = 1e-3, 1e-5is_close = torch.allclose(fa_output, pt_output, rtol=rtol, atol=atol)print(f"结果一致性: {is_close}")if not is_close:diff = (fa_output - pt_output).abs()print(f"最大差异: {diff.max().item():.6f}")print(f"平均差异: {diff.mean().item():.6f}")except AssertionError as e:print(f"\nPyTorch实现限制: {str(e)}")if __name__ == "__main__":import randomprint(f"测试设备: {torch.cuda.get_device_name(0)}")print(f"PyTorch版本: {torch.__version__}")print(f"FlashAttention可用: {torch.backends.cuda.flash_sdp_enabled()}\n")compare_implementations()
通过这些验证,我们能够确认自实现的 PyTorch 版本不仅在结果上与官方版本一致,同时在性能上也能达到可接受的水平。
总结
该实现已经在生产中应用,在T4卡上运行。