彩笔运维勇闯机器学习--随机森林
前言
随机森林的出现,是为了解决决策树对训练数据过拟合的问题而出现的。决策树在训练的工程中,可以让每一个叶子节点的不确定性降为0(即熵或者基尼指数为0),这样做可能把训练数据中的偶然性、异常值或噪声也当成了“规 律”去学习了
对于复杂高维的数据,随机森林的算法可以更好的泛化能力
开始探索
scikit-learn
老规矩,先上代码,看看随机森林的用法
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_reportX, y = load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)clf = RandomForestClassifier(n_estimators=100, max_depth=3, random_state=0)
clf.fit(X_train, y_train)y_pred = clf.predict(X_test)
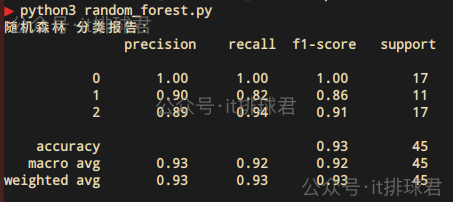
print("随机森林 分类报告:\n", classification_report(y_test, y_pred))
脚本!启动:
鸢尾花数据集
决策树那篇文章演示剪枝的时候,就使用了load_iris,它是 Scikit-learn 自带的一个内置数据集加载器函数,用于获取“鸢尾花数据集”,该数据集的信息:
- 150条样本
- 4个特征,
sepal length,sepal width,petal length,petal width,分别代表萼片长度、萼片宽度、花瓣长度、花瓣宽度 - 3个分类,Setosa、Versicolor、Virginica,标签值分别为
012
这是Scikit-learn提供的常用数据集,适用于学习、演示以及本人目前实在是找不到对应的数据来做练习 - -
深入理解随机森林
随机森林由许多决策树组成,每棵树都是在不同的样本和特征子集上训练出来的。最终结果通过“投票”(分类)或“平均”(回归)方式整合
- Bootstrap采样:有N条样本,每次随机抽取N条样本,并且是有放回抽样,那就意味着有些样本可能被抽取多次,有些一次也没有被抽取
- 假如原始集合D={x1,x2,x3,x4,x5}D=\{x_1,x_2,x_3,x_4,x_5\}D={x1,x2,x3,x4,x5},在一次有放回抽样中,样本为{x1,x2,x3,x5,x5}\{x_1,x_2,x_3,x_5,x_5\}{x1,x2,x3,x5,x5},那x5x_5x5被抽取了两次,x4x_4x4一次都没有被抽中,x4x_4x4被称为OOB(out of bag)样本
- 将抽取的样本训练成决策树,在训练的过程中,特征并不是全部考虑的,而是随机选取一部分特征进行划分,每棵树训练的过程中都不剪枝
- 训练N棵树之后之后
- 分类任务采用多数多数投票法,即少数服从多数。比如森林中有5棵决策树,对于样本进行预测,3个预测为
0,2个预测为1,那随机森林对于该样本的预测结果就是0 - 回归任务采用平均值,顾名思义,求和取平均
- 分类任务采用多数多数投票法,即少数服从多数。比如森林中有5棵决策树,对于样本进行预测,3个预测为
- 由于有一部分样本(OOB样本)一次也没有被抽取,可以使用这些样本进行评估,从而在不使用额外验证集的情况下评估模型性能
理解了决策树,就理解了随机森林。决策树,学习规则,直接预测结果;多棵决策树组成的集成模型,通过投票(分类)或平均(回归)得出最终结果
方差
方差是衡量数据离散程度的数学特征,方差越大,数据越分散,波动越大;方差越小,数据越集中,波动越小。在机器学习中,方差反应了模型对于训练数据变化的敏感程度,方差越大,对于噪声的变化越敏感,容易过拟合;方差越小,对于数据变化不敏感,泛化能力更强,但是有欠拟合的风险
决策树就是方差较大的模型,因为决策树会倾向于熵/基尼系数为0,它会一直分裂,导致树非常的深,并且数据稍有变化,就产生了完全不同的树结构。剪枝可以有效的避免高方差,预剪枝通过参数(最大深度,最小样本分裂数等),控制数的深度,后剪枝可以参数(ccp_alpha)减掉树枝,避免树过深
随机森林中是方差较小的模型,注意得益于它的抽样方式,通过Bootstrap采样,减少了特定训练数据的依赖,再加上最后分类是通过所有树投票,降低了单棵树带来的波动。其次不是所有特征,而是随机特征,带来树分裂的次数 减少
常用参数
| 参数 | 含义 | 备注 |
|---|---|---|
| n_estimators | 森林中树的数量 | 默认 100,建议:100~500,越多越稳但训练慢 |
| max_depth | 每棵树的最大深度 | 控制过拟合;常设为 5~30;默认 None |
| min_samples_split | 节点最小分裂样本数 | 控制过拟合,默认 2,设置大些可防止过拟合 |
| min_samples_leaf | 每个叶节点最少样本数 | 默认 1,设置大些让树更“平滑”,防止过拟合 |
| max_features | 每次分裂考虑的特征数 | 分类常用 ‘sqrt’,回归常用 ‘auto’ 或 ‘log2’ |
| bootstrap | 是否启用 Bootstrap 采样 | 默认 True;设为 False 表示使用全部数据(不推荐) |
超参数调优
在之前的篇章中,曾经提到过超参数的概念,这里再来详细讨论一下:超参数是模型训练之前就要设置的,模型无法自己去学习超参数,超参数往往决定着模型的泛化能力。比如上述的n_estimators max_depth等,合理的设置这些参数能够提高模型的泛化能力,减少过拟合
网格搜索
一种穷举搜索的方法,用来寻找在给定超参数空间中,使模型性能最优的参数组合。它尝试所有可能的参数组合,并对每一组组合进行模型训练与评估
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_splitX, y = load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)rf = RandomForestClassifier(random_state=0)
param_grid = {'n_estimators': [50, 100, 150],'max_depth': [None, 5, 10],'min_samples_split': [2, 4]
}
grid_search = GridSearchCV(estimator=rf,param_grid=param_grid,cv=5,scoring='accuracy',n_jobs=-1
)
grid_search.fit(X_train, y_train)print("最优参数组合:", grid_search.best_params_)
3个参数,n_estimators,max_depth,min_samples_split,分别将对应的取值进行穷举搜索训练,训练的参考准确率(accuracy),谁的准确率高,就使用对应的参数组合。在训练的过程中使用5折交叉验证
脚本!启动

随机搜索
从给定的超参数空间中随机采样若干组参数组合进行训练和评估
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import RandomizedSearchCV, train_test_split
from sklearn.metrics import classification_report, accuracy_score
from scipy.stats import randintX, y = load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
rf = RandomForestClassifier(random_state=0)
param_dist = {'n_estimators': randint(50, 200),'max_depth': [None, 5, 10, 20],'min_samples_split': randint(2, 10),'max_features': ['sqrt', 'log2', None]
}
random_search = RandomizedSearchCV(estimator=rf,param_distributions=param_dist,n_iter=20,cv=5,scoring='accuracy',random_state=0,n_jobs=-1
)random_search.fit(X_train, y_train)
print("最优参数组合:", random_search.best_params_)n_iter是比较重要的参数,代码中它限制了要尝试20种不同的参数组合,在这其中选择准确率最高的

贝叶斯优化
当面对海量的参数时,穷举参数组合显然不再适合,而贝叶斯优化的做法构造一个模型,该模型用来模拟:超参数与用这一组超参数训练随机森林之后的准确率之间的关系,从而智能地选择下一组超参数进行评估。在每次尝试的过程中,都会记录超参数与随机森林准确率,最终选择准确率最高的那一组超参数
与随机搜索的不同,就在于超参数的选择,随机搜索顾名思义,采取随机的组合方式选择参数,而贝叶斯则是选择参数的过程是构建摸一个预测模型,对超参数和模型性能之间的关系进行建模,用模型来指导下一组参数应该选什么,从而更快、更高效地找到最优组合
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
from skopt import BayesSearchCV
from skopt.space import Real, Integer, CategoricalX, y = load_iris(return_X_y=True)
model = RandomForestClassifier(random_state=0)
search_space = {'n_estimators': Integer(50, 200),'max_depth': Integer(2, 20),'min_samples_split': Integer(2, 10),'max_features': Categorical(['sqrt', 'log2', None])
}
opt = BayesSearchCV(estimator=model,search_spaces=search_space,n_iter=30,cv=5,scoring='accuracy',n_jobs=-1,random_state=0
)
opt.fit(X, y)print("最优参数:", opt.best_params_)
小结
总结一下三种超参数调优的方法
| 方法 | 思想 | 优点 | 缺点 | 使用场景 |
|---|---|---|---|---|
| 网格搜索 | 穷举所有可能的参数组合 | 简单直观,易于并行 | 参数过多导致计算代价高,无学习能力 | 参数较少,对性能要求不敏感 |
| 随机搜索 | 随机采样参数组合 | 比网格搜索高效 | 不利用历史信息采样,随机性大 | 参数空间大,资源有限 |
| 贝叶斯优化 | 构建一个代理模型来预测每组参数组合的性能,并基于此智能选择下一个组合 | 样本效率高,可快速收敛最优解,特别适合开销大的模型 | 实现复杂,开销大 | 超参数空间大且训练开销高,希望精细调优性能 |
联系我
- 联系我,做深入的交流

至此,本文结束
在下才疏学浅,有撒汤漏水的,请各位不吝赐教…