HDFS基准测试与数据治理
1 基准测试
当搭建好HDFS集群后,我们想要了解集群的读写能力,可以通过HDFS基准测试来获取HDFS集群的读写性能。
在运行基准测试之前需要将“junit-4.11.jar”放入到提交任务节点的“$HADOOP_HOME/share/hadoop/common”目录下,在执行基准测试时需要使用到该包。
1.1 基准写测试
在namenode节点执行如下命令进行基准写测试:
[root@hadoop101 ~]# hadoop jar /opt/module/hadoop-3.3.6/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.3.6-tests.jar TestDFSIO -write -nrFiles 10 -fileSize 128MB
以上命令是基于Yarn提交MR 任务向HDFS中写入数据,-nrFiles执行写入的文件数量,-fileSize指定每个写入文件的大小为128M,运行结果如下:
INFO fs.TestDFSIO: ----- TestDFSIO ----- : write
INFO fs.TestDFSIO: Date & time: Wed Sep 10 14:37:57 CST 2025
INFO fs.TestDFSIO: Number of files: 10
INFO fs.TestDFSIO: Total MBytes processed: 1280
INFO fs.TestDFSIO: Throughput mb/sec: 8.31
INFO fs.TestDFSIO: Average IO rate mb/sec: 8.33
INFO fs.TestDFSIO: IO rate std deviation: 0.48
INFO fs.TestDFSIO: Test exec time sec: 80.42
以上命令运行后会在HDFS根路径中生成 benchmarks 目录,运行结果参数解释如下:
- Number of files:表示写入的文件个数,也是MapTask个数。
- Total MBytes processed:总共写入HDFS的数据量。
- Throughput mb/sec:每个MapTask 每秒平均吞吐量。
- Average IO rate mb/sec:每个文件的平均每秒IO 速率。
- IO rate std deviation:每个MapTask处理数据速度的方差,越大表示各个MapTask之间性能越不均衡。
- Test exec time sec:测试花费时长。
如果在一台HDFS DataNode上进行任务提交操作,速度快很多,主要原因是数据上传直接写入本地,经过的网络IO大大减少。
1.2 基准写测试
在hadoop101节点执行如下命令进行基准读测试(需要先执行写基准测试生成 benchmarks 目录数据):
[root@hadoop101 ~]# hadoop jar /opt/module/hadoop-3.3.6/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.3.6-tests.jar TestDFSIO -read -nrFiles 10 -fileSize 128MB
以上命令 -nrFiles 读取文件数量,-fileSize指定每个读取文件的大小为128M,运行结果如下:
INFO fs.TestDFSIO: ----- TestDFSIO ----- : read
INFO fs.TestDFSIO: Date & time: Wed Sep 10 15:09:02 CST 2025
INFO fs.TestDFSIO: Number of files: 10
INFO fs.TestDFSIO: Total MBytes processed: 1280
INFO fs.TestDFSIO: Throughput mb/sec: 165.08
INFO fs.TestDFSIO: Average IO rate mb/sec: 200.08
INFO fs.TestDFSIO: IO rate std deviation: 91.07
INFO fs.TestDFSIO: Test exec time sec: 38.75
读取数据的速度快于写入数据的主要原因是读取数据时每个task运行到数据所在节点上进行读取处理,相当于是数据本地化读取/写入数据,减少了网络之间数据传递,所以速度快。注意:HDFS 中数据读写和网络、磁盘、节点负载情况都有关系,测试结果可以多次测试获取平均值作为基准测试结果。
HDFS 基准读写测试完成后执行如下命令删除测试数据:
hdfs dfs -rm -r /benchmarks
2 数据丢失处理
2.1 namenode元数据丢失
这里说的NameNode元数据丢失主要指当NameNode上元数据出现意外删除情况,如何进行集群恢复。
启动HDFS集群后,通过HDFS WebUI查看Active NameNode节点,并kill对应进程,删除该NameNode节点元数据目录。
当kill掉对应的DataNode进程后,由于集群是HA模式,会自动切换其他Standby NameNode为Active状态。
然后,重启刚kill节点上的NameNode,由于删除了对应的元数据目录导致元数据目录丢失,会报错:
2025-09-10 17:31:35,795 ERROR org.apache.hadoop.hdfs.server.namenode.NameNode: Failed to start namenode.
org.apache.hadoop.hdfs.server.common.InconsistentFSStateException: Directory /data/hadoop/dfs/name is in an inconsistent state: storage directory does not exist or is not accessible.
at org.apache.hadoop.hdfs.server.namenode.FSImage.recoverStorageDirs(FSImage.java:392)
at org.apache.hadoop.hdfs.server.namenode.FSImage.recoverTransitionRead(FSImage.java:243)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.loadFSImage(FSNamesystem.java:1236)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.loadFromDisk(FSNamesystem.java:808)
at org.apache.hadoop.hdfs.server.namenode.NameNode.loadNamesystem(NameNode.java:694)
at org.apache.hadoop.hdfs.server.namenode.NameNode.initialize(NameNode.java:781)
at org.apache.hadoop.hdfs.server.namenode.NameNode.<init>(NameNode.java:1033)
at org.apache.hadoop.hdfs.server.namenode.NameNode.<init>(NameNode.java:1008)
at org.apache.hadoop.hdfs.server.namenode.NameNode.createNameNode(NameNode.java:1782)
at org.apache.hadoop.hdfs.server.namenode.NameNode.main(NameNode.java:1847)
2025-09-10 17:31:35,798 INFO org.apache.hadoop.util.ExitUtil: Exiting with status 1: org.apache.hadoop.hdfs.server.common.InconsistentFSStateException: Directory /data/hadoop/dfs/name is in an inconsistent state: storage directory does not exist or is not accessible.
解决以上这个错误,只需要将其他NameNode节点上对应的元数据目录复制过来即可,假设当前NameNode在被kill之前有部分元数据没来得及同步给其他的StandbyNameNode,有可能造成数据丢失。具体操作如下:
[root@hadoop101 bin]# scp -r /data/hadoop/dfs/name 172.21.243.19:/data/hadoop/dfs/[root@hadoop103 logs]# hdfs --daemon start namenode启动NameNode进程后,该节点为Standby状态,可以参与正常的Active NameNode切换。
2.2 DataNode数据丢失
这里说的DataNode数据丢失处理是指当DataNode节点上的数据目录被意外删除后导致HDFS集群启动异常。默认在HDFS中数据存储会有3个副本,3个副本分别存在不同的DataNode节点上,每个DataNode节点存储数据的目录由hdfs-site.xml文件中的参数hadoop.tmp.dir来配置,默认为file://${hadoop.tmp.dir}/dfs/data 路径。
当意外删除HDFS数据所在DataNode节点数据时,由于HDFS集群中有该数据副本,所以重启HDFS集群后,这些删除的数据会自动复制还原回来。但如果所有DataNode节点上的数据目录被意外删除,重启HDFS集群后HDFS集群会进入安全模式。
解决以上问题需要先退出安全模式,然后执行“hdfs fsck”工具(fsck用于检查HDFS文件系统的完整性和一致性)查看并删除缺失block的数据文件,这样会导致这些文件数据丢失。
- 在datanode节点上删除数据目录
- 重启hdfs集群,可以看到集群进入到安全模式
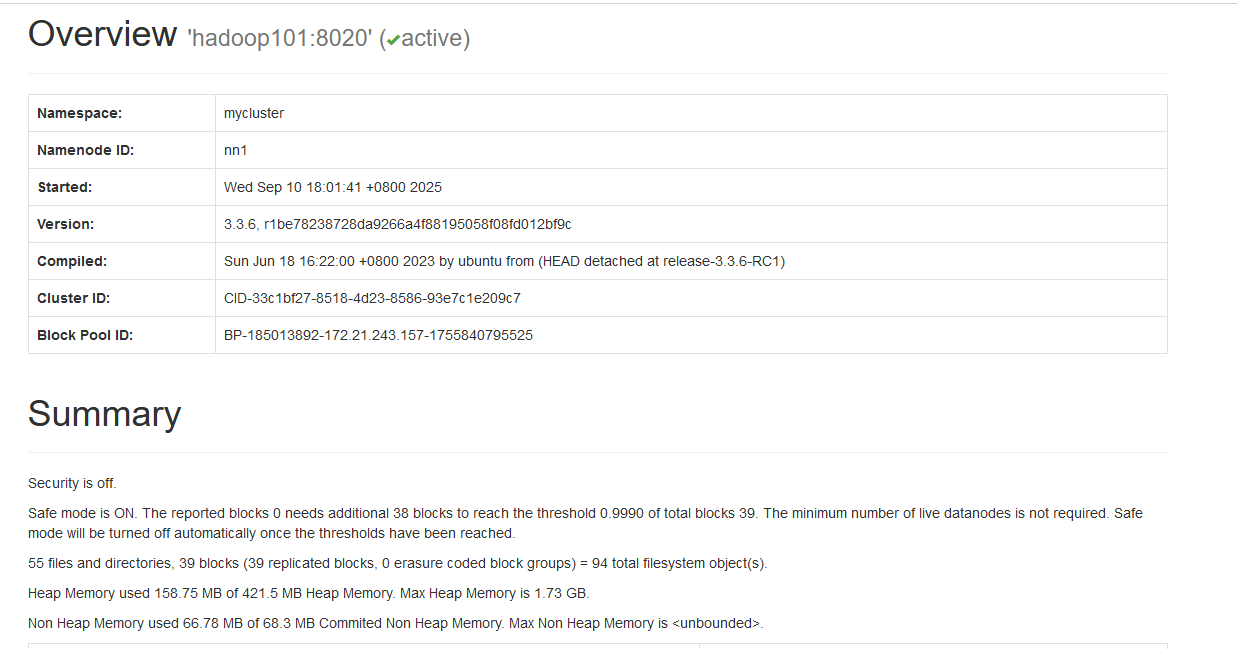
- 退出安全模式 hdfs dfsadmin -safemode leave
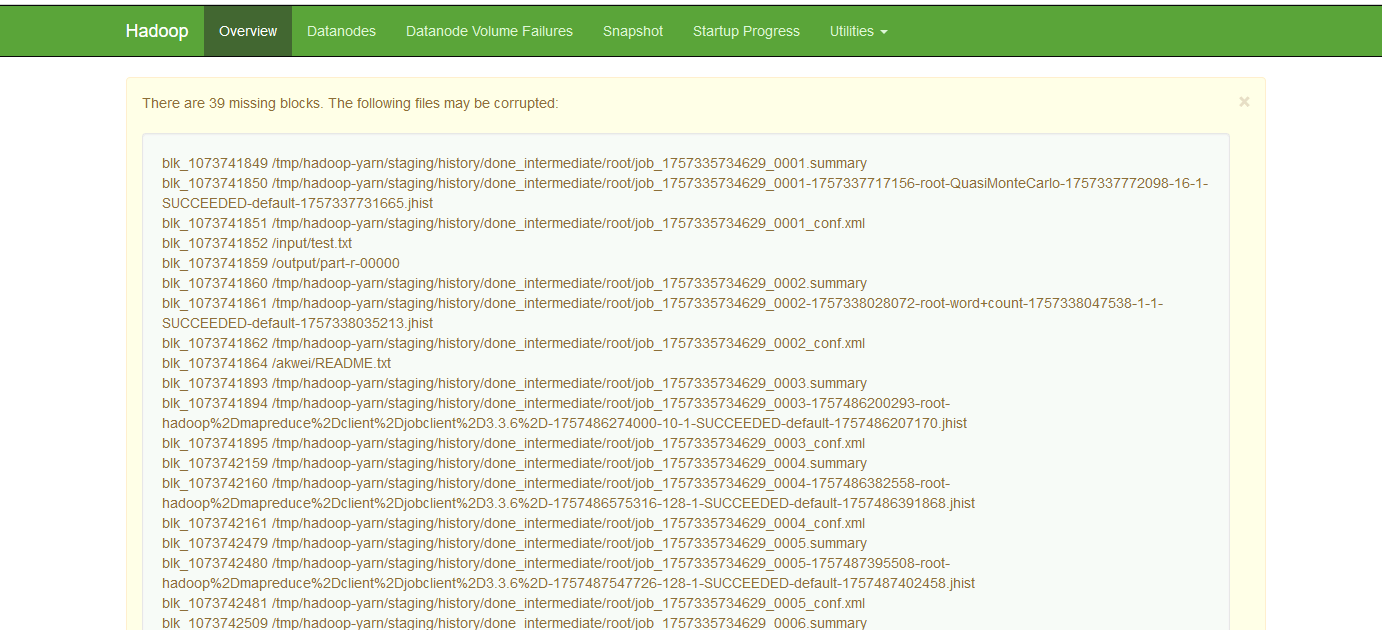
- 检查并删除缺失block的数据文件
#查看缺失文件 [root@hadoop101 ~]# hdfs fsck / #删除缺失文件,正常文件不会被删除 [root@hadoop101 ~]# hdfs fsck / -delete注意:通过“hdfs fsck / -delete”命令会将缺失block的文件删除掉,导致这些文件丢失。
3 纠删码策略
[root@hadoop105 data]# hdfs ec -listPolicies
Erasure Coding Policies:
ErasureCodingPolicy=[Name=RS-10-4-1024k, Schema=[ECSchema=[Codec=rs, numDataUnits=10, numParityUnits=4]], CellSize=1048576, Id=5], State=DISABLED
ErasureCodingPolicy=[Name=RS-3-2-1024k, Schema=[ECSchema=[Codec=rs, numDataUnits=3, numParityUnits=2]], CellSize=1048576, Id=2], State=DISABLED
ErasureCodingPolicy=[Name=RS-6-3-1024k, Schema=[ECSchema=[Codec=rs, numDataUnits=6, numParityUnits=3]], CellSize=1048576, Id=1], State=ENABLED
ErasureCodingPolicy=[Name=RS-LEGACY-6-3-1024k, Schema=[ECSchema=[Codec=rs-legacy, numDataUnits=6, numParityUnits=3]], CellSize=1048576, Id=3], State=DISABLED
ErasureCodingPolicy=[Name=XOR-2-1-1024k, Schema=[ECSchema=[Codec=xor, numDataUnits=2, numParityUnits=1]], CellSize=1048576, Id=4], State=DISABLED
对以上纠删码策略解释如下:
- RS-10-4-1024k
使用RS编码,每10个数据单元(cell)生成4个校验单元,共14个单元,只要14个单元中任意10个单元存在,就可以保证数据容错,每个数据单元大小为1024*1024。要求集群中有14个DataNode。
- RS-3-2-1024k
使用RS编码,每3个数据单元(cell)生成2个校验单元,共5个单元,只要5个单元中任意3个单元存在,就可以保证数据容错,每个数据单元大小为1024*1024。要求集群中有5个DataNode。
- RS-6-3-1024k
使用RS编码,HDFS中使用纠删码后,默认的编码方式。每6个数据单元(cell)生成3个校验单元,共9个单元,只要9个单元中任意6个单元存在,就可以保证数据容错,每个数据单元大小为1024*1024。要求集群中有9个DataNode。
- RS-LEGACY-6-3-1024k
与RS-6-3-1024类似,使用相对旧的算法实现。要求集群中有9个DataNode。
- XOR-2-1-1024k
使用XOR算法,每2个数据单元(cell)生成1个校验单元,共3个单元,只要3个单元中任意2个单元存在,就可以保证数据容错,每个数据单元大小为1024*1024要求集群有3个机架。
在HDFS中如果想要使用纠删码需要对相应的HDFS目录进行设置,当给某个目录设置了纠删码后,所有存储在当前目录下的文件都会执行对应的策略,默认只有“RS-6-3-1024k”策略开启,可以给目录直接设置该策略,如果想要使用其他策略需要开启。操作命令如下:
#HDFS中创建目录 aaa ,并指定纠删码策略
[root@hadoop101 ~]# hdfs dfs -mkdir /aaa
[root@hadoop101 ~]# hdfs ec -setPolicy -path /aaa -policy RS-6-3-1024k
Set RS-6-3-1024k erasure coding policy on /aaa #如果想要给目录指定其他纠删码策略,需要先enable
[root@hadoop101 ~]# hdfs ec -setPolicy -path /input -policy RS-3-2-1024k
RemoteException: Policy 'RS-3-2-1024k' does not match any enabled erasure coding policies: [RS-6-3-1024k]. An erasure coding policy can be enabled by enableErasureCodingPolicy API. #开启指定的纠删码策略
[root@hadoop101 ~]# hdfs ec -enablePolicy -policy RS-3-2-1024k
#给 /aaa 目录设置 RS-3-2-1024k 策略
[root@hadoop101 ~]# hdfs ec -setPolicy -path /aaa -policy RS-3-2-1024k
Set RS-3-2-1024k erasure coding policy on /aaa注意:这里使用对应策略需要设置DataNode节点符合各个策略要求的DataNode节点,然后可以通过删除对应个数的DataNode数据存储目录来测试纠删码策略,当删除DataNode上数据块个数大于对应策略要求的最少数据块时会导致数据丢失。
纠删码优势可以减少数据存储空间的消耗,但同时会带来网络带宽和CPU资源的消耗,当进行数据恢复时需要去其他节点获取数据块和校验块然后通过大量CPU计算还原数据,所以一般冷数据存储可以采用纠删码存储,可以大大节省存储空间,但对于线上集群建议使用副本容错机制。
4 多目录
4.1 namenode多目录
HDFS集群中可以在hdfs-site.xml中配置“dfs.namenode.name.dir”属性来指定NameNode存储数据的目录,默认NameNode数据存储在${hadoop.tmp.dir}/dfs/name目录,“hadoop.tmp.dir”配置项在core-site.xml中。
我们也可以将NameNode存储元数据的目录设置为多个, 每个目录中存储内容相同,两者相当于是备份,这样可以增加元数据安全可靠性。例如:元数据目录设置2个,一个目录设置在A磁盘上,一个目录设置到B磁盘上,这样当磁盘A坏掉后,NameNode存储元数据也不会丢失。
具体配置可以按照如下步骤进行。
4.1.1 配置hdfs-site.xml文件
这里在hadoop101 NameNode节点上配置dfs.namenode.name.dir,指定两个目录。
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/name1,file://${hadoop.tmp.dir}/dfs/name2</value
</property>4.1.2 分发hdfs-site.xml
如果其他节点的NameNode节点磁盘目录和hadoop101节点一样,可以将配置好的hdfs-site.xml分发到其他节点,否则不需要分发,那么就只有hadoop101的NameNode节点按照此配置有2个元数据目录。
4.1.3 删除原集群数据
配置NameNode多数据目录需要重新格式化集群才能生效,所以在开始搭建集群的时候就要进行规划。现在已经有了HDFS集群,那么需要停止原有集群,删除原有集群zookeeper中数据和各个节点HDFS角色数据目录。
删除zookeeper中数据:
[root@hadoop101 ~]# zkCli.sh
[zk: localhost:2181(CONNECTED) 2] deleteall /hadoop-ha各个节点删除角色数据目录:
删除NameNode和DataNode数据目录
rm -rf /data/hadoop/*删除JournalNode数据目录
rm -rf /data/journal/*删除日志
rm -rf /opt/module/hadoop-3.3.6/logs/*
4.1.4 格式化集群
#在hadoop101上格式化zookeeper
[root@hadoop101 ~]# hdfs zkfc -formatZK #在每台journalnode中启动所有的journalnode,这里就是hadoop103,hadoop104,hadoop105节点上启动
hdfs --daemon start journalnode#在hadoop101中格式化namenode,只有第一次搭建做,以后不用做 [root@hadoop101 ~]# hdfs namenode -format #在hadoop101中启动namenode,以便同步其他namenode
[root@hadoop101 ~]# hdfs --daemon start namenode #高可用模式配置namenode,使用下列命令来同步namenode(在需要同步的namenode中执行,这里就是在hadoop102、hadoop103上执行): hdfs namenode -bootstrapStandby 4.1.5 启动HDFS集群并检查NameNode元数据目录
[root@hadoop101 dfs]# start-dfs.sh
Starting namenodes on [hadoop101 hadoop102 hadoop103]
Last login: Wed Sep 10 19:13:48 CST 2025 on pts/0
Starting datanodes
Last login: Wed Sep 10 19:14:29 CST 2025 on pts/0
Starting journal nodes [hadoop103 hadoop104 hadoop105]
Last login: Wed Sep 10 19:14:32 CST 2025 on pts/0
Starting ZK Failover Controllers on NN hosts [hadoop101 hadoop102 hadoop103]
Last login: Wed Sep 10 19:14:37 CST 2025 on pts/0
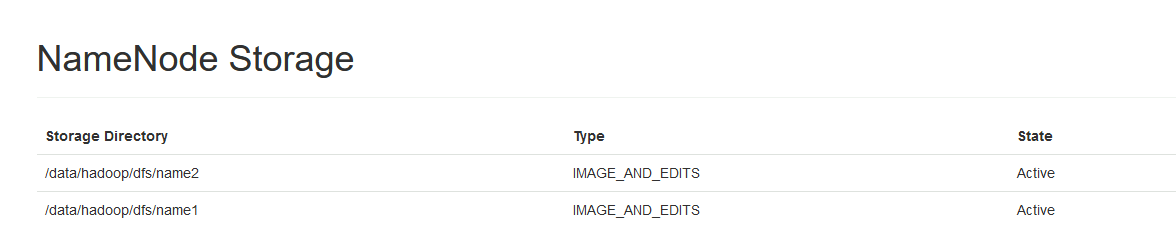
[root@hadoop101 dfs]# ls
name1 name2
我们也可以通过HDFS WebUI查看NameNode存储目录信息:
4.2 datanode多目录
DataNode负责存储HDFS数据,HDFS中数据默认存储在各个DataNode节点file://${hadoop.tmp.dir}/dfs/data 路径中,可以通过hdfs-site.xml文件中的参数hadoop.tmp.dir来配置,我们也可以给该参数配置多个路径,不同路径挂载到不同磁盘来解决datanode存储空间不足问题。
需要注意:hadoop.tmp.dir 设置多个路径后不需重新格式化HDFS集群,只需要重启即可生效。此外,DataNode多个路径中数据并不是副本关系,而是不同目录存储不同数据。
4.2.1 配置hdfs-site.xml文件
可以按照如下步骤给DataNode设置多个存储磁盘空间路径,由于VM中没有设置其他磁盘,这里直接给hadoop.tmp.dir参数设置两个不同的数据目录。
这里在hadoop104 DataNode节点上配置dfs.datanode.data.dir,指定两个目录。
<property>
<name>dfs.datanode.data.dir</name
<value>file://${hadoop.tmp.dir}/dfs/data1,file://${hadoop.tmp.dir}/dfs/data2</value
</property>4.2.2 分发配置文件
如果其他节点的DataNode节点磁盘目录和hadoop104节点一样,可以将配置好的hdfs-site.xml分发到其他节点,否则不需要分发,那么就只有hadoop104 的DataNode节点按照此配置有2个数据目录。
4.2.3 重启集群并检查DataNode数据目录
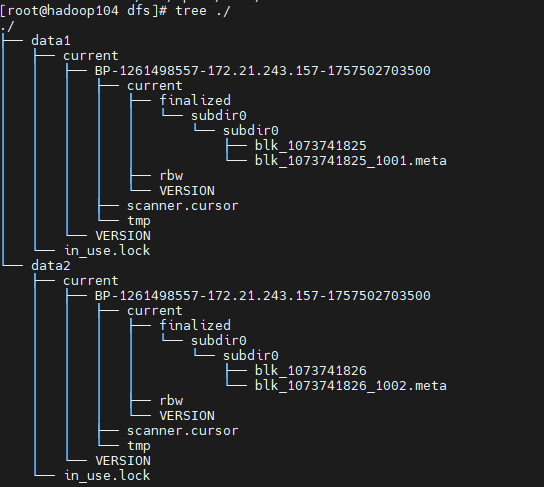
[root@hadoop104 dfs]# ls
data1 data2
向HDFS中存储数据时,HDFS会自动均衡负载(轮询方式)决定将数据块存储在哪个目录中。
第一次传文件
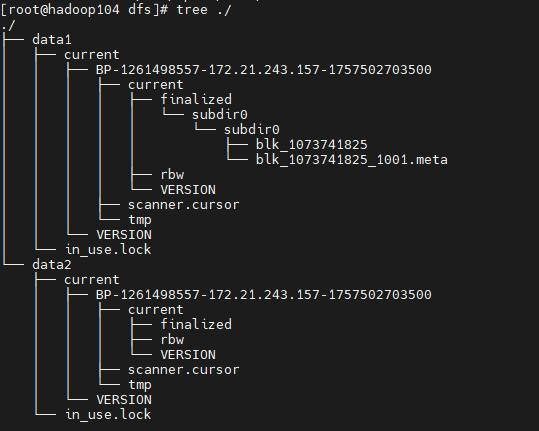
第二次传文件
5 异构存储
在Hadoop中,异构存储指的是根据数据的使用模式和特性,将数据分配到不同类型或特性的存储介质上。在企业中,HDFS中的数据根据使用频繁程度分为不同类型,这些类型包括热、温、冷数据,我们可以通过异构存储将不同类型数据根据存储策略存储在不同的介质中,例如:将不活跃或冷数据存储在成本较低的设备上(机械硬盘),而将活跃数据存储在性能更高的设备上(固态硬盘SSD),这样的存储策略通过平衡性能、成本和数据访问模式,提高了数据存储的效率和经济性。
5.1 数据存储类型及存储策略
HDFS中数据存储类型有如下几种:
- DISK:DISK存储类型表示数据存储在普通机械硬盘上,默认的存储类型。
- ARCHIVE:ARCHIVE存储类型通常用于归档数据,这些归档数据通常以压缩文件方式长期存储,具备存储密度高、不经常访问的特点,例如:历史备份数据。这类数据存储介质一般可选普通磁盘。
- SSD:SSD存储类型表示数据存储在固态硬盘上,相比于传统的机械硬盘,SSD具有更快的读写速度和更低的访问延迟。
- RAM_DISK:RAM_DISK存储类型表示数据存储在内存中模拟的硬盘中,由于内存的读写速度非常快,因此RAM_DISK存储类型通常用于对数据访问速度要求非常高的场景。
我们可以在hdfs-site.xml中配置dfs.datanode.data.dir配置项给DataNode配置数据存储目录,这些目录可以配置多个并可以指定以上不同的存储类型。当向HDFS中写入数据时,哪些数据存储在对应的存储类型中就需要根据HDFS中目录的存储策略来决定,这些存储策略需要用户来执行对应命令来指定。
HDFS中支持如下不同的存储策略:
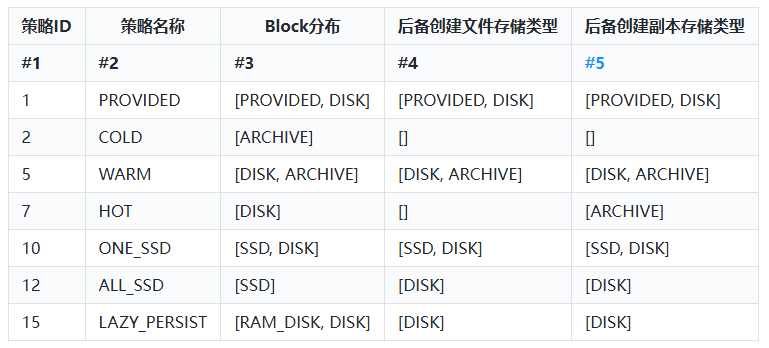
以上表格有如下两点解释:
- PROVIDED存储策略指的是在HDFS之外存储数据。LAZY_PERSIST存储策略指Block副本首先写在RAM_DISK中,然后惰性的保存在磁盘中。
- #3列表示该策略下Block的分别,例如:“[SSD, DISK]”表示第一个block块存储在SSD存储类型中,其他block块存储在 DISK 存储类型中。
- 关于#4列和#5列的解释如下:当#3列数据存储介质有足够的空间时,block存储按照#3指定的进行存储,如果空间不足,创建新文件和数据副本将按照#4和#5列中指定的介质存储。
- HOT存储策略是默认的存储策略。常用的存储策略有COLD、WARN、HOT、ONE_SSD、ALL_SSD几种。
5.2 HDFS存储类型配置
HDFS数据存储在DataNode中,设置HDFS存储类型与DataNode数据多目录设置一样,直接通过hdfs-site.xml文件中的参数hadoop.tmp.dir来配置,可以在目录前面指定“DISK、ARCHIVE、SSD、RAM_DISK”不同的存储类型,如果不配置默认所有存储类型为DISK。
在现有HDFS集群中,DataNode节点有3个(hadoop103~hadoop105),分别给每个DataNode节点设置多目录,并在不同的DataNode节点中给不同目录指定不同的存储类型。
| 节点 | 存储类型分配 |
| hadoop103 | DISK,ARCHIVE |
| hadoop104 | ARCHIVE,SSD |
| hadoop105 | SSD,DISK |
需要注意:hadoop.tmp.dir 设置多个路径后不需重新格式化HDFS集群,只需要重启即可生效。
按照如下步骤给DataNode设置多个存储磁盘路径及存储类型。
5.2.1 开启存储策略功能
在所有HDFS DataNode节点上,配置hdfs-site.xml文件中“dfs.storage.policy.enabled”配置项为true,该值默认为true,表示开启HDFS存储策略功能。
在hadoop103~hadoop105所有DataNode节点上配置hdfs-site.xml:
<property>
<name>dfs.storage.policy.enabled</name>
<value>true</value>
</property>5.2.2 配置hdfs-site.xml文件
修改hadoop103 DataNode节点上hdfs-site.xml中配置项dfs.datanode.data.dir,指定两个目录存储类型为DISK和ARCHIVE。
<property>
<name>dfs.datanode.data.dir</name>
<value>[DISK]file://${hadoop.tmp.dir}/dfs/disk,[ARCHIVE]file://${hadoop.tmp.dir}/dfs/archive</value>
</property>修改hadoop104 DataNode节点上hdfs-site.xml中配置项dfs.datanode.data.dir,指定两个目录存储类型为ARCHIVE和SSD。
<property>
<name>dfs.datanode.data.dir</name>
<value>[ARCHIVE]file://${hadoop.tmp.dir}/dfs/archive,[SSD]file://${hadoop.tmp.dir}/dfs/ssd</value>
</property>修改hadoop105 DataNode节点上hdfs-site.xml中配置项dfs.datanode.data.dir,指定两个目录存储类型为SSD和RAM_DISK。
<property>
<name>dfs.datanode.data.dir</name>
<value>[SSD]file://${hadoop.tmp.dir}/dfs/ssd,[DISK]file://${hadoop.tmp.dir}/dfs/disk</value>
</property>注意:以上各个DataNode节点配置的目录,没有涉及到真正的SSD磁盘,这里使用VM虚拟机没有其他额外磁盘,使用普通目录来模拟指定其他路径中的磁盘目录。
5.2.3 重启集群并检查DataNode数据目录
#hadoop103 DataNode节点检查数据目录,可以看到disk、archive目录
[root@hadoop103 hadoop]# ls /data/hadoop/dfs/
archive disk name1 name2 #hadoop104 DataNode节点检查数据目录,可以看到archive、ssd目录
[root@hadoop104 hadoop]# ls /data/hadoop/dfs/
archive ssd #hadoop105 DataNode节点检查数据目录,可以看到ssd、ramdisk目录
[root@hadoop105 hadoop]# ls /data/hadoop/dfs/
ramdisk ssd5.3 存储策略操作命令
5.3.1 列出hdfs支持的存储策略
[root@hadoop104 dfs]# hdfs storagepolicies -listPolicies
Block Storage Policies:BlockStoragePolicy{PROVIDED:1, storageTypes=[PROVIDED, DISK], creationFallbacks=[PROVIDED, DISK], replicationFallbacks=[PROVIDED, DISK]}BlockStoragePolicy{COLD:2, storageTypes=[ARCHIVE], creationFallbacks=[], replicationFallbacks=[]}BlockStoragePolicy{WARM:5, storageTypes=[DISK, ARCHIVE], creationFallbacks=[DISK, ARCHIVE], replicationFallbacks=[DISK, ARCHIVE]}BlockStoragePolicy{HOT:7, storageTypes=[DISK], creationFallbacks=[], replicationFallbacks=[ARCHIVE]}BlockStoragePolicy{ONE_SSD:10, storageTypes=[SSD, DISK], creationFallbacks=[SSD, DISK], replicationFallbacks=[SSD, DISK]}BlockStoragePolicy{ALL_SSD:12, storageTypes=[SSD], creationFallbacks=[DISK], replicationFallbacks=[DISK]}BlockStoragePolicy{LAZY_PERSIST:15, storageTypes=[RAM_DISK, DISK], creationFallbacks=[DISK], replicationFallbacks=[DISK]}5.3.2 查询对应目录的存储策略
在HDFS中创建目录 data,并查询该data目录的默认存储策略,可以通过命令“hdfs storagepolicies -getStoragePolicy -path <path>”来查询对应路径的存储策略。
将data.txt文件上传至HDFS /data目录下,然后通过“hdfs fsck -files -blocks -locations ”命令查询文件对应的block位置信息。
[root@hadoop105 ~]# hdfs fsck /data.txt -files -blocks -locations
/data.txt 25 bytes, replicated: replication=3, 1 block(s): OK
0. BP-187707191-192.168.179.4-1715610189467:blk_1073741837_1013 len=25 Live_repl=3 [DatanodeInfoWithStorage[192.168.179.6:9866,DS-5f383d24-b137- 4208-b63f-01ff76f44394,DISK], DatanodeInfoWithStorage[192.168.179.8:9866,DS-6a5907f2-3065-4ea6-a097-70e2b3be4f5e,DISK], DatanodeInfoWithStorage[192.168.179.7:9866,DS-ac3a21d4-5503-4c39-bf63-fe1bc596d1c5,ARCHIVE]]默认认的文件存储策略为HOT,将block数据存储在DISK存储类型中,由于集群中hadoop103、hadoop105节点有DISK存储类型,所以其Block副本会存在hadoop103和hadoop105节点,剩余一个block副本会根据“后备创建副本存储类型”选择ARCHIVE存储类型的节点hadoop104。也可以通过HDFS WebUI查看对应的文件block所在的节点信息。
5.3.3 创建HDFS路径并指定存储策略
[root@hadoop105 ~]# hdfs storagepolicies -setStoragePolicy -path /hot -policy HOT
[root@hadoop105 ~]# hdfs storagepolicies -setStoragePolicy -path /warm -policy WARM
[root@hadoop105 ~]# hdfs storagepolicies -setStoragePolicy -path /cold -policy COLD
[root@hadoop105 ~]# hdfs storagepolicies -setStoragePolicy -path /onessd -policy ONE_SSD
[root@hadoop105 ~]# hdfs storagepolicies -setStoragePolicy -path /allssd -policy ALL_SSD5.3.4 取消存储策略
取消目录的存储策略可以使用命令:hdfs storagepolicies -unsetStoragePolicy -path <目录>
6 回收站
HDFS中提供了类似window回收站的功能,当我们在HDFS中删除数据后,默认数据直接删除,如果开启了Trash回收站功能,数据删除时不会立即清除,而是会被移动到回收站目录中(/usr/${username}/.Trash/current),如果误删了数据,可以通过回收站进行还原数据,此外,我们还可以配置该文件在回收站多长时间后被清空。
按照如下步骤进行回收站配置即可。
6.1 修改core-site.xml
在HDFS各个节点上配置core-site.xml,加入如下配置:
<!-- 回收站文件存活时长 -->
<property>
<name>fs.trash.interval</name>
<value>1</value>
</property> <!-- 检查回收站间隔时间 -->
<property>
<name>fs.trash.checkpoint.interval</name>
<value>0</value>
</property>以上参数“fs.trash.interval”默认值为0,表示禁用回收站功能,设置大于0的值表示开启回收站并指定了回收站中文件存活的时长(单位:分钟)。
“fs.trash.checkpoint.interval”参数表示检查回收站文件间隔时间,如果设置为0表示该值和“fs.trash.interval”参数值一样,要求该值配置要小于等于“fs.trash.interval”配置值。
当执行删除命令后,可以看到数据被移动到“hdfs://mycluster/user/root/.Trash/Current/”目录下,通过HDFS WebUI也可看到对应的路径下文件。大约等待1分钟左右数据会自动从回收站中清空。如果想要还原数据需要手动执行命令将数据move移动到对应目录中。
注意:只有通过HDFS shell操作命令将数据文件删除后,才会进入回收站,如果在HDFS WebUI中删除文件,这种删除操作不会进入到回收站。