【机器学习】梯度下降法及使用一元二次方程模拟使用梯度下降法的代码实现
梯度下降法
- 一、摘要
- 二、梯度下降法
- 三、线性方程中使用梯度下降法
一、摘要
文本主要讲述了梯度下降法作为机器学习中的一种优化方法,用于最小化损失函数。它并非直接解决机器学习问题,而是作为求解最优参数的工具。通过二维坐标图直观展示了梯度下降法的原理,即通过调整参数值来逐步减小损失函数值,直至找到最小值点。同时,强调了导数在梯度下降中的作用,即指示了损失函数随参数变化的趋势,从而指导参数调整的方向。
二、梯度下降法
-
概述
1.梯度下降法是机器学习领域的一种重要方法,用于优化目标函数。
2.梯度下降法用于最小化损失函数,而梯度上升法用于最大化效用函数。
3.梯度下降法是解决许多机器学习问题的常用工具,尤其是那些无法直接求解数学解的问题。 -
原理
1.梯度下降法
通过在损失函数上搜索最优解来最小化损失函数。
2.在二维坐标平面上,损失函数的最小值对应于参数θ的某个值。
3.通过计算损失函数对参数θ的导数,确定损失函数增大的方向,并沿其负方向移动。
4.移动的步长称为学习率α,其取值影响算法收敛的速度。
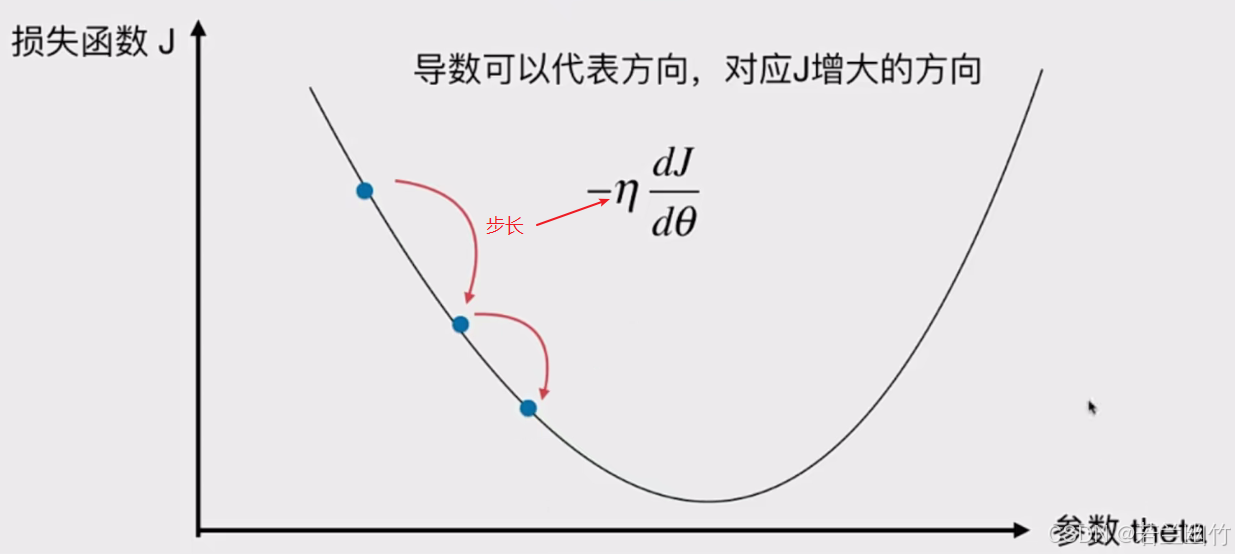
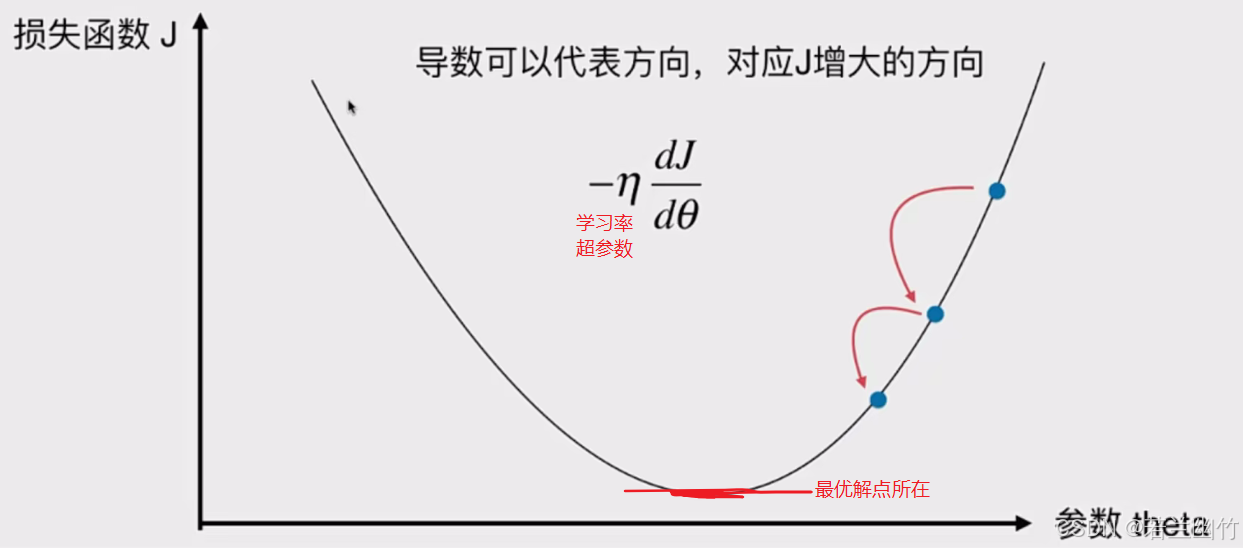
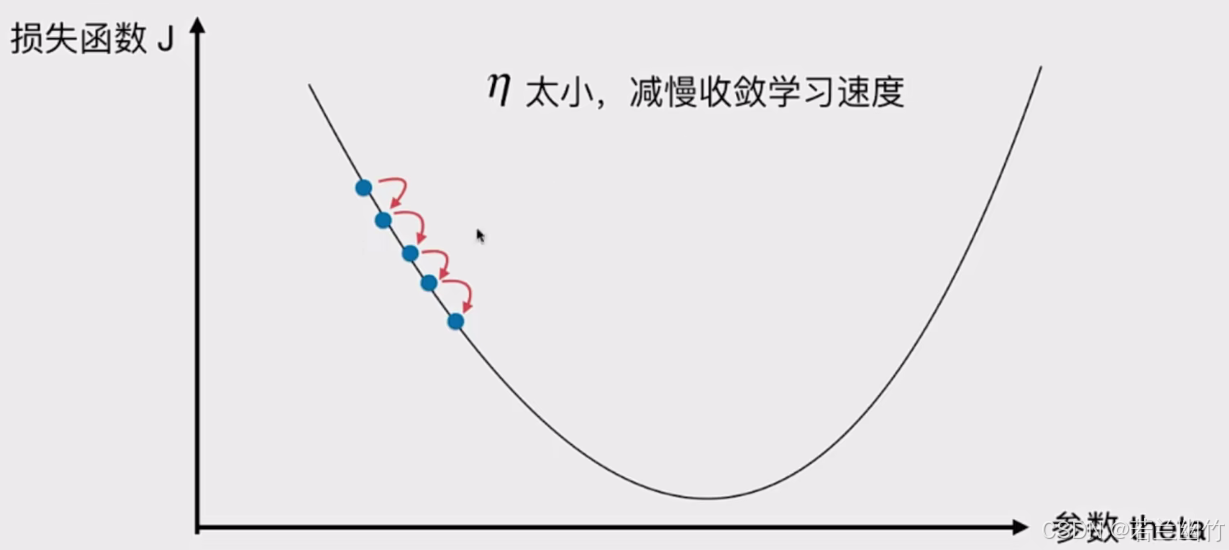
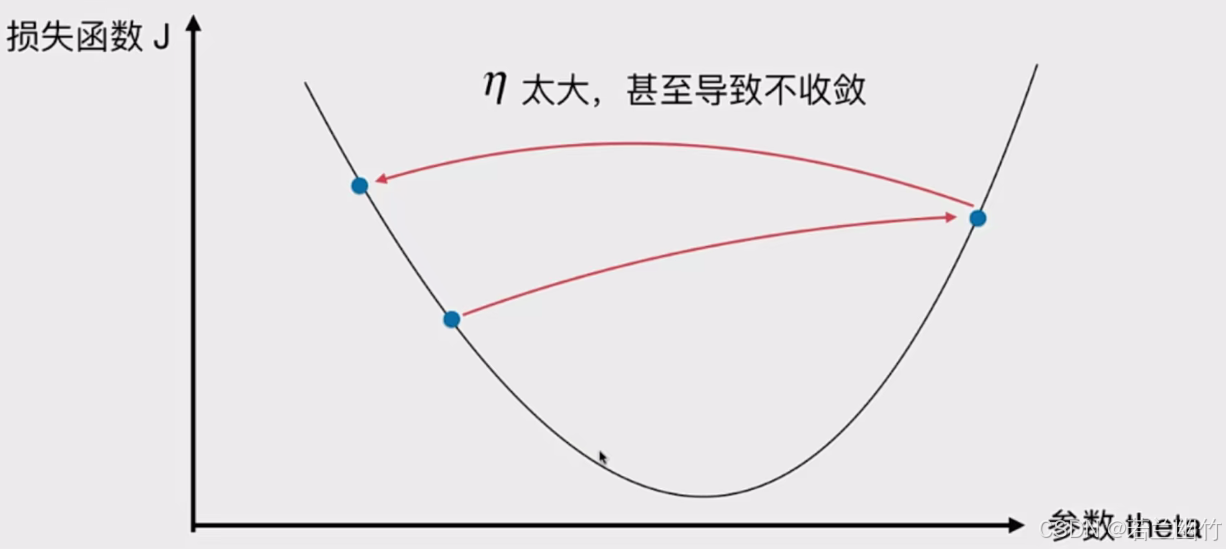
图中内容是关于机器学习中“学习率(η)”的知识点介绍:
1. 学习率(η)是在机器学习优化算法,尤其是梯度下降法中的一个超参数。
2. 它控制着每次参数更新的步长。如果学习率取值较小,算法会更谨慎地更新参数,虽然能保证算法的稳定性,但会使得收敛到最优解的速度变慢,需要更多的训练时间和计算资源。
3. 而如果学习率取值过大,参数更新的步长就会很大,这可能导致算法在搜索最优解的过程中“跳过”最优解,无法收敛,甚至出现发散的情况,也就得不到最优解。
4. 并不是所有函数都有唯一的极值点:
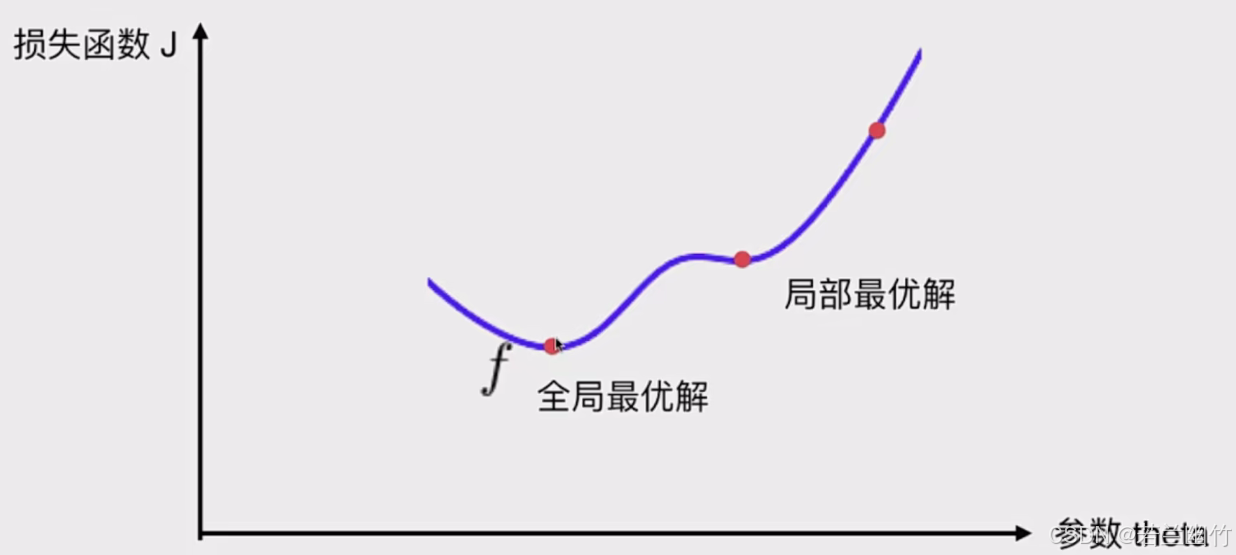
解决办法:
1. 多次运行,随机化初始点
2. 梯度下降法的初始点也是一个超参数 -
示例
1.通过示例说明梯度下降法的具体步骤,包括
计算导数、确定移动方向和步长。
2.梯度下降法的过程类似于球体在山谷中的滚落过程,直到到达谷底。
3.学习率α的取值过大或过小都会影响算法的性能,甚至导致无法找到最优解。 -
注意事项
1.梯度下降法可能陷入
局部最优解,尤其是面对复杂函数时。
2.初始点的选择对梯度下降法的结果有重要影响,不同的初始点可能导致不同的最优解。
3.对于具有多个局部最优解的函数,多次运行梯度下降法并比较结果可以有助于找到更好的解。
三、线性方程中使用梯度下降法
- 线性回归中使用梯度下降法的目标:使 ∑ i = 1 m ( y ( i ) − y ^ ( i ) ) 2 \sum_{i = 1}^{m}(y^{(i)} - \hat{y}^{(i)})^{2} ∑i=1m(y(i)−y^(i))2损失函数值尽可能小。
- 线性回归法的损失函数具有唯一的最优解 。
- 代码实现:
-
导入相关依赖包并定义好损失函数方程且绘制出其图像:
import numpy as np import matplotlib.pyplot as plt # 定义损失函数中的x:取值[-1,6],样本数:141 plot_x = np.linspace(-1,6,141) # 定义损失函数中的y:二元一次方程y=(x - 2.5)**2 -1,其中2.5是自定义的,可取任意一个数 plot_y = (plot_x - 2.5)**2 -1 # 绘制当前损失函数在二维平面上的图像 plt.plot(plot_x,plot_y) plt.show()执行结果:
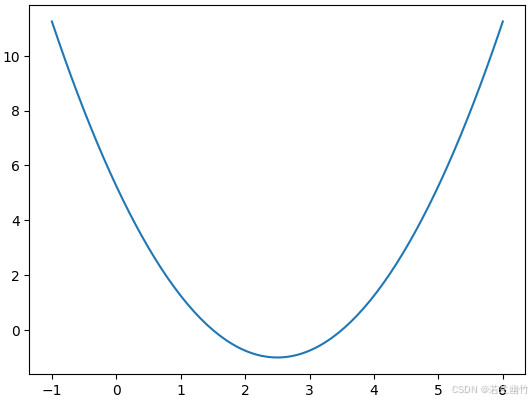
-
定义求损失函数的导函数和求损失函数值:
# 定义求导函数:得到梯度gradient值 def dJ(theta): return 2*(theta - 2.5) # 定义J对于theta的损失函数 def J(theta): try: return (theta-2.5)**2 - 1. except: return float('inf') # 返回float最大值 -
定义求损失函数最小值函数:
# 定义求损失函数最小值函数 # p_eta: 学习率,控制每次参数更新的步长,默认值为0.1 # p_epsilon: 收敛阈值,当两次迭代的损失函数差值小于该值时,认为算法收敛,默认值为1e-8 # p_theta: 参数的初始值,默认值为0.0 # n_iters:用于控制循环的参数,当无法找到最优解时,就终止,默认为1e4(10的4次方) def minJ(p_eta=0.1,p_epsilon=1e-8,n_iters=1e4,p_theta=0.0): # 定义局部变量,将传入的参数赋值给新的变量,方便后续操作 eta = p_eta epsilon = p_epsilon theta = p_theta i_itera = 0 while i_itera < n_iters: # 根据传入的theta计算出梯度,这里假设dJ函数已经定义好,用于计算梯度 gradient = dJ(theta) # 将上一次的theta赋值给一个变量,用于存储上一次theta的值,以便后续比较损失函数的变化 last_theta = theta # 重新计算当前的theta值,根据梯度下降的公式,让theta向梯度负方向前进一步 theta = theta - eta * gradient # 计算上一次和当前的损失函数的差值的绝对值是否小于Epsilon # 如果小于,则说明已经接近损失函数的最小值,认为算法收敛,退出循环 if(abs(J(theta) - J(last_theta)) < epsilon): break i_itera += 1 return theta, J(theta)执行结果:
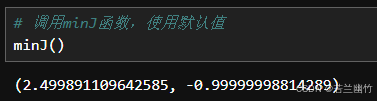
-
定义一个测试函数minJViewThetaChange,用于可视化损失函数的中theta沿着梯度负方向前进的二维平面图上的轨迹:
# 定义一个测试函数,用于可视化损失函数的中theta沿着梯度负方向前进的二维平面图上的轨迹 # p_eta: 学习率,控制每次参数更新的步长,默认值为0.1 # p_epsilon: 收敛阈值,当两次迭代的损失函数差值小于该值时,认为算法收敛,默认值为1e-8 # p_theta: 参数的初始值,默认值为0.0 # n_iters:用于控制循环的参数,当无法找到最优解时,就终止,默认为1e4(10的4次方) def minJViewThetaChange(p_eta=0.1,p_epsilon=1e-8,n_iters=1e4,p_theta=0.0,p_plot=plt): # 定义局部变量,将传入的参数赋值给新的变量,方便后续操作 eta = p_eta epsilon = p_epsilon theta = p_theta # 定义用于存储theta每次计算得到的值,用于绘制图片 theta_history = [theta] # 迭代次数 i_itera = 0 while i_itera < n_iters: # 根据传入的theta计算出梯度,这里假设dJ函数已经定义好,用于计算梯度 gradient = dJ(theta) # 将上一次的theta赋值给一个变量,用于存储上一次theta的值,以便后续比较损失函数的变化 last_theta = theta # 重新计算当前的theta值,根据梯度下降的公式,让theta向梯度负方向前进一步 theta = theta - eta * gradient # 将每次计算得到的theta值放入theta_history历史数组当中 theta_history.append(theta) # 计算上一次和当前的损失函数的差值的绝对值是否小于Epsilon # 如果小于,则说明已经接近损失函数的最小值,认为算法收敛,退出循环 if(abs(J(theta) - J(last_theta)) < epsilon): break i_itera += 1 print("theta=",theta) print("J(theta)=",J(theta)) print("theta_history前100个:",theta_history[:100]) print("theta_history总长度:",len(theta_history)) # 绘制x,y值,即绘制损失函数曲线图 p_plot.plot(plot_x,J(plot_x)) # 绘制每个theta沿着gradient负方向前进时的曲线 p_plot.plot(np.array(theta_history),J(np.array(theta_history)),color='r',marker='+') # 将曲线显示出来 p_plot.show()执行结果:
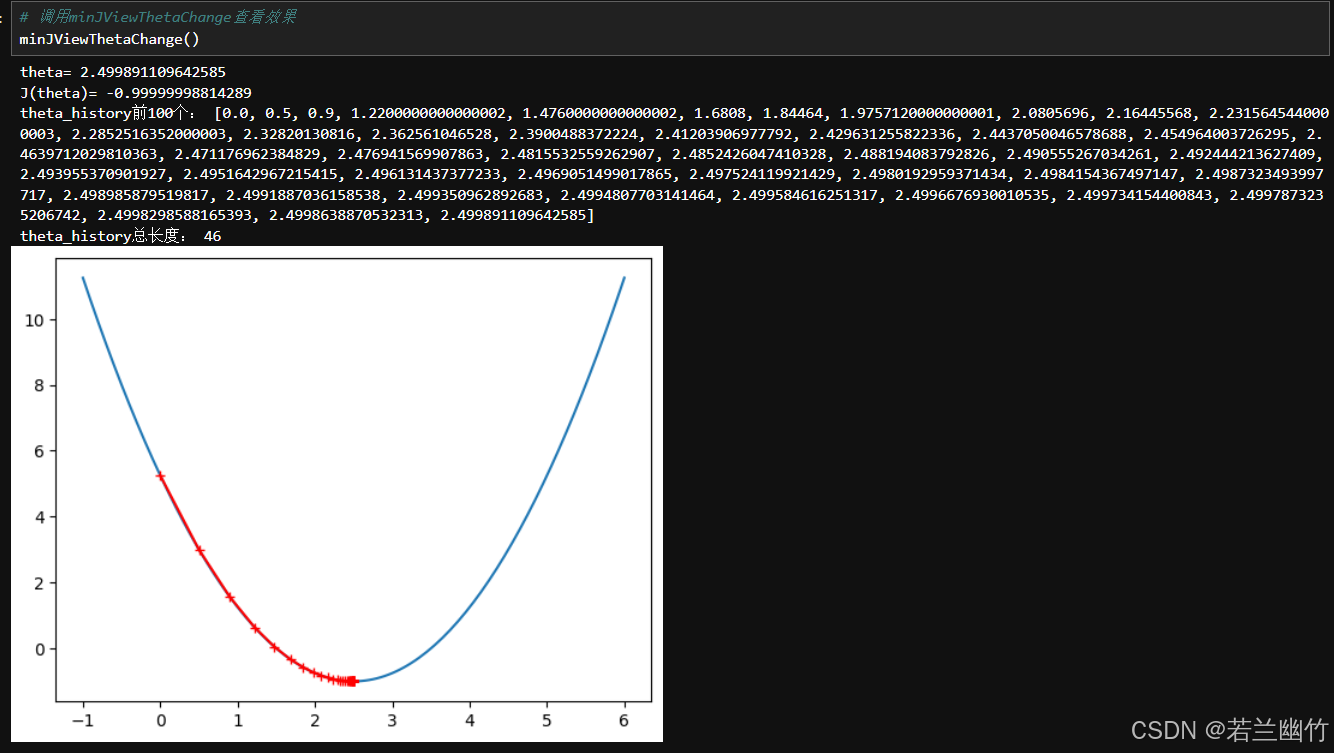
-
测试1:给定一个比较小的eta值(
0.01),看看学习率的变化轨迹:
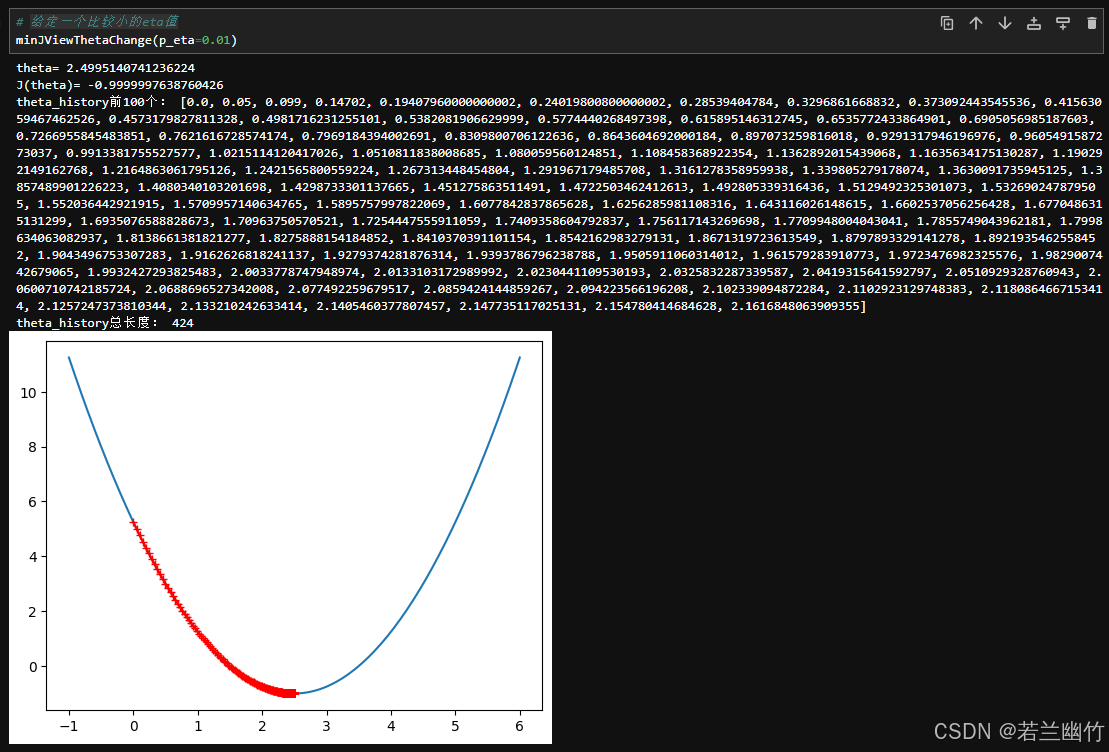
-
测试2:给定一个更小的eta值(
0.001),看看学习率的变化轨迹:
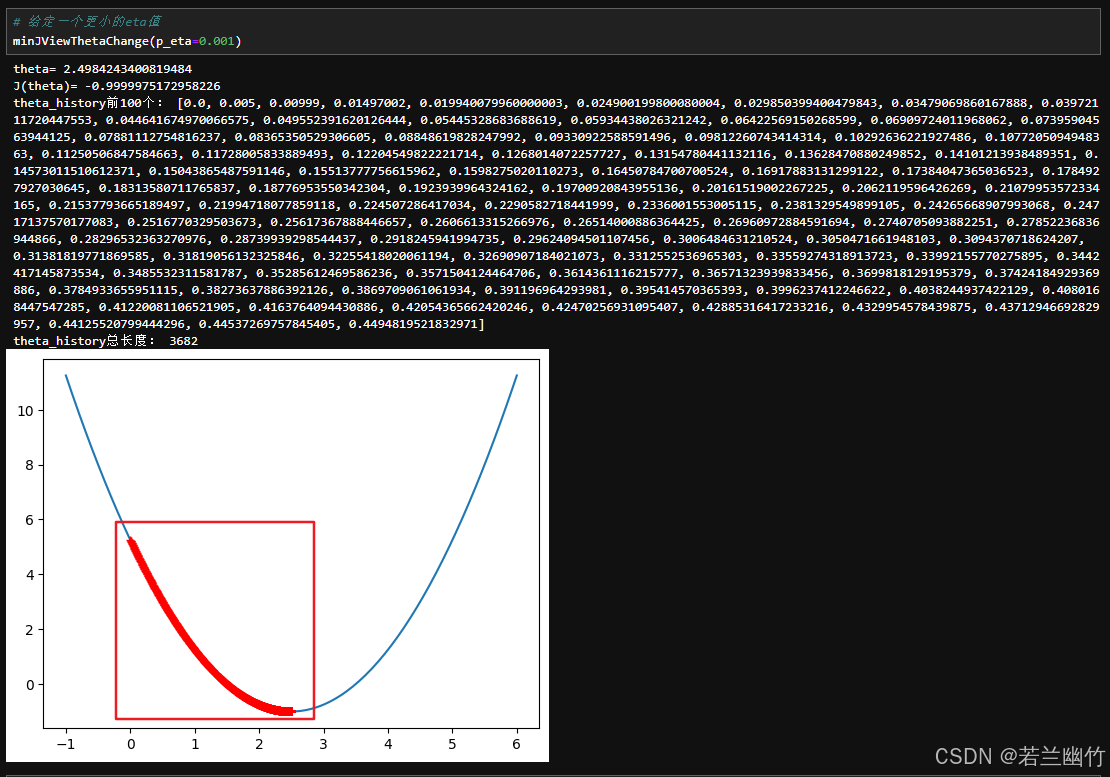
-
测试3:给定一个比较大的eta值(
0.8),看看学习率的变化轨迹:
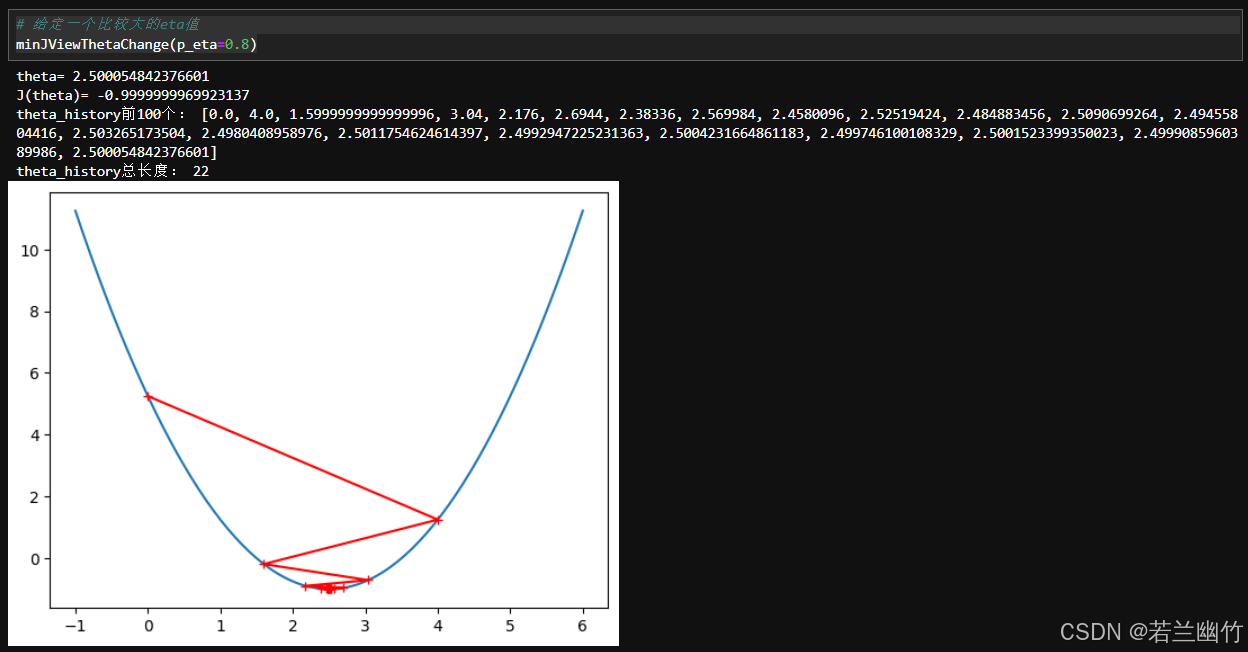
-
测试4:给定一个更大的eta值,看看学习率的变化轨迹:
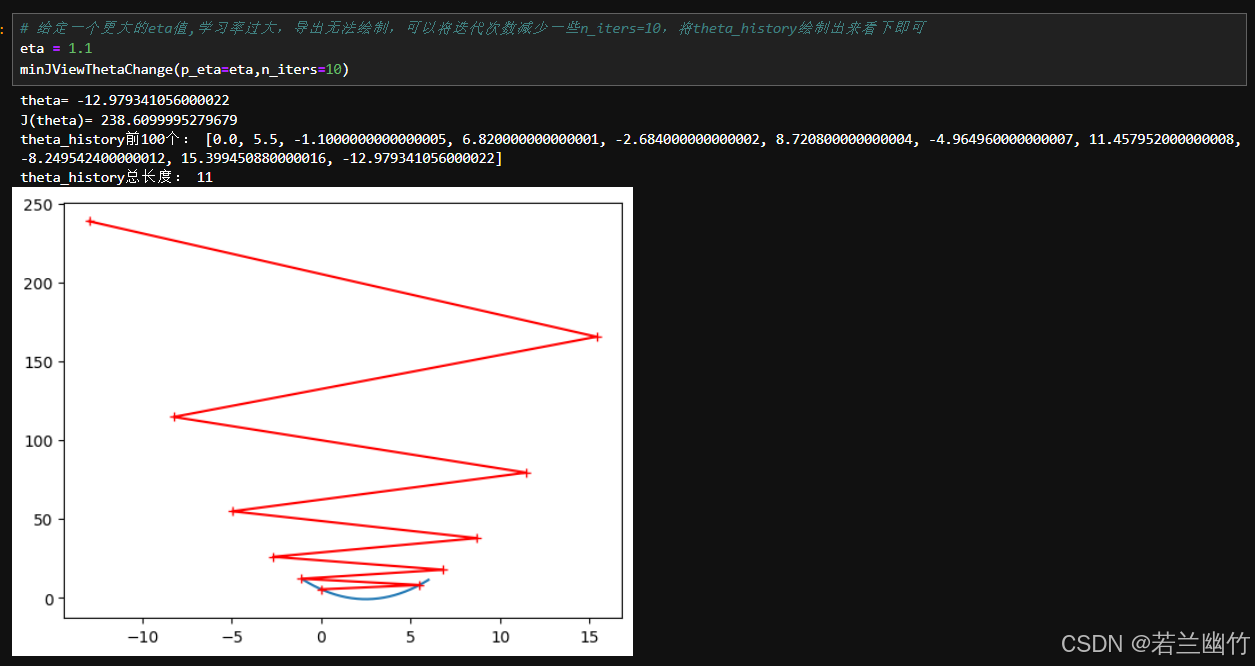
此时,如果调用minJ函数,得到的theta和损失函数的值都是nan:

到此,我们可以看出来,学习率eta不能大小,也不能太大,否则将无法使得损失函数收敛。
-